{kind=link}
{kind=link}
{kind=link}
高光谱结合离散二进制粒子群算法对久保桃可溶性固形物含量的检测
[张立秀 , 张淑娟
, 张淑娟* , 孙海霞, 薛建新, 景建平, 崔添俞]
, 张淑娟, 孙海霞, 薛建新, 景建平, 崔添俞]
|
|


作者简介: 张立秀, 女, 1995年生, 山西农业大学农业工程学院硕士研究生 e-mail: Z18503483861@163.com
可溶性固形物(SSC)是评价久保桃内部品质的重要指标。 传统的SSC检测有损、 费时、 费力; 快速、 无损检测久保桃的SSC含量对于其品质分级有着重要意义。 离散二进制粒子群算法(BPSO)是在标准粒子群算法(PSO)的基础上, 更新速度公式得到的, 具有精度高, 收敛快的特点, 多用于离散空间的优化问题。 基于高光谱技术结合BPSO算法及BPSO的组合特征波长选择算法对久保桃的SSC含量预测进行研究。 首先采集198个久保桃样本的高光谱信息, 获取久保桃900~1 700 nm范围内的光谱信息, 计算感兴趣区域的平均光谱作为有效光谱数据, 同时测量久保桃的SSC值。 采用K-S(Kennard-Stone)算法将样本划分为校正集(147个)和预测集(51个)。 使用BPSO特征波长选择算法对久保桃的原始光谱数据进行特征波长提取, 并与竞争性自适应重加权算法(CARS)、 连续投影法(SPA)、 无信息变量选择法(UVE)等特征波长选择算法比较。 同时为了避免单一算法建模中的不稳定问题, 提出了基于BPSO的一次组合(BPS0+CARS、 BPSO+SPA、 BPSO+UVE)和二次组合[(BPSO+CARS)-SPA]、 [(BPSO+SPA)-SPA]、 [(BPSO+UVE)-SPA]特征波长提取方法。 基于上述10种特征波长提取方法分别建立支持向量机(LS-SVM)模型和遗传算法(GA)优化的支持向量机模型(GA-SVM)模型。 结果表明, 基于BPSO算法提取特征波长建立的模型预测性能均高于其他单一特征波长方法, 建立的两种模型预测集决定系数
Soluble solids (SSC) are an important index to evaluate the internal quality of Kubo peach. Traditional SSC content detection is destructive, time-consuming and laborious. Rapid and nondestructive detection of the SSC content of Kubo peach is of great importance for its quality classification. Binary particle swarm optimization (BPSO) is obtained by updating the speed formula based on standard particle swarm optimization (PSO). BPSO has the characteristics of high accuracy and fast convergence and is mostly used in optimization problems in separate spaces. Taking Kubo peach as the research object. Basedon hyperspectral technology combined with BPSO and based on BPSO combined characteristic wavelength selection algorithm to study the SSC content of Kubo peach. Firstly,hyperspectral information of 198 Kubo peaches was collected to obtain the spectral curve of Kubo peaches in the range of 900~1 700 nm. Meanwhile, theSSC value of Kubo peaches was. Used (Kennard-stone) algorithm to divide samples into a correction set (147) and a prediction set (51). The BPSO feature wavelength selection algorithm is used to extract the feature wavelength from Kubo's original spectral data. It is compared with the Competitive Adaptive Reweighting algorithm (CARS), Successive projections algorithm (SPA), and Uninformative variable selection algorithm (UVE). A method of extracting characteristic wavelength based on BPSO is proposed for primary combination (BPS0+CARS, BPSO+SPA, BPSO+UVE) and secondary combination ((BPSO+ CARS)-SPA), (BPSO+SPA)-SPA), (BPSO+UVE)-SPA). Based on the10 characteristic wavelength extraction methods above. Established support vector machine (LS-SVM) model and the genetic algorithm (GA) optimized support vector machine (GA-SVM) model of Kubo peach SSC content. The results show that the prediction performance of the model based on the BPSO algorithm is higher than that of other single characteristic wavelength algorithm, and the coefficient of determination
“ 久保桃” 是水蜜桃的一种早熟品种, 果型大, 汁液多, 深受消费者喜爱[1]。 可溶性固形物(SSC)是评判鲜桃内部品质的主要指标[2]。 无损、 快速检测鲜桃可溶性固形物含量(SSC)有利于实现水果品质分级。
高光谱成像技术具有分辨率清晰, 波段数多的特点, 被广泛用于果蔬品质的无损检测[3]。 近年来, 高光谱技术结合相应的化学计量学方法评价新鲜水果的品质, 尤其是与口感相关的内部品质如可溶性固形物含量(SSC)、 成熟程度、 软硬程度、 含水量[4]等方面已经取得了重大进展。 Li[5]等利用近红外光谱技术结合连续投影法(SPA)建立了能够预测梨硬度和可溶性固形物含量的偏最小二乘(PLS)模型。 Fan[6]等将高光谱成像技术结合竞争性自适应重加权算法(CARS)建立能够预测苹果的可溶性固形物含量的模型。 Wang[7]等采用高光谱图像技术结合群采样裕度影响分析(GSMIA)预测了库尔勒香梨的可溶性固形物(SSC)含量。 目前采用高光谱技术结合离散二进制粒子群算法(BPSO)及基于BPSO组合算法提取光谱的特征波长, 建立最小二乘支持向量机模型, 研究久保桃的可溶性固形物含量(SSC)含量还未见报道。
离散二进制粒子群算法(BPSO)具有精度高, 收敛快的特点, 能够快速筛选重要光谱特征[8]。 本工作选取久保桃为研究对象, 将光谱技术与基于BPSO算法形成的不同特征变量组合方法相结合, 建立久保桃的SSC含量检测模型。 先利用高光谱仪采集久保桃的高光谱数据, 之后采用BPSO算法、 竞争性自适应重加权算法(CARS)、 连续投影算法(SPA)、 无信息变量消除法(UVE)对久保桃的光谱数据进行特征波长筛选, 并进行建模分析, 同时依据算法之间优势互补的特点, 提出基于BPSO的一次组合与二次组合特征波长筛选方法, 建立遗传算法优化的支持向量机模型(GA-SVM)和最小二乘支持向量机模型(LS-SVM), 确定预测久保桃SSC含量的最优模型。 在久保桃SSC检测方面, 此(BPSO+SPA)-SPA-LS-SVM方法尚未见报道, 为久保桃SSC含量的无损检测提供了新的检测方法。
标准粒子群算法(PSO)是一种优化全局搜索能力, 解决组合优化存在问题的算法, 主要适用于处理优化连续空间内的问题。 在求解优化问题时, 搜索寻找空间中的任何一个最优的“ 粒子” 即可找到连续空间内问题的最优解, 任一粒子都有着决定其将要飞行方向的初始位置和决定其飞行距离的初始速度以及由优化函数决定的适应值。 在每一次找寻问题最合适的答案的迭代循环过程中, 每个粒子通过追踪单个极值和群体极值来更新自身的位置和速度[9]。 其速度和位置更新公式如式(1)和式(2)所示。
设: 粒子的目标搜寻空间为D维, N个粒子组成的种群X={x1, x2, …, xN}T, 则每个粒子可用R维向量表示: xi=(xi1, xi2, …, xiR)T。 粒子飞行速度vi=(vi1, vi2, …, viR)T该粒子当前最优解为pi=(pi1, pi2, …, piR)T, 该种群当前最优解gt=(gt1, gt2, …, giR)T。 其更新过程为
其中, i=1, 2, …, N为种群范围; d=1, 2, …, R为粒子群算法解的找寻空间; t为进化迭代数; r1, r2为均匀分布在[0, 1]之间的随机数; c1, c2为学习因子; w为惯性权重, 主要是描述每一个粒子上一代的速度对当前代速度的影响大小; pid为第i个粒子在D维空间搜索的最优位置点; pgd为整个种群在D维搜索到的最优位置点[10]。
标准粒子群(PSO)算法主要用来优化连续的空间最优解问题, 由于光谱数据是离散空间的优化问题, 而离散二进制粒子群算法(BPSO)是在标准粒子群算法(PSO)的基础上通过更新位置公式得到的, 主要用来优化离散空间约束问题, 因此采用BPSO算法来优化光谱数据问题。 BPSO算法采用了二进制编码, 其中的每个粒子均由二进制变量0与1表示, 每个粒子对应光谱的一种组合, 位置状态的改变用速度表示, 飞行速度
其中sigmoid型函数为
式(4)中,
将BPSO算法应用于筛选久保桃的光谱数据时, 每个粒子均对应着久保桃光谱数据的适应度值, pid和pgd是由粒子的适应度值来决定, 适应度值由适应度函数计算得到[13], 适应度函数与筛选出的光谱特征波长有相关性。 根据适应度函数将适应度值高的粒子优选出来。 每个粒子对应一种光谱的特征组合, 粒子的每一维对应一个波长, 根据式(3), 粒子的某一维取值为1时表示选择这一维光谱, 取值为0时表示不选择这一维光谱, 依次选出粒子对应的光谱数据特征组合, 即为筛选出的特征波长。
BPSO算法有效解决了离散空间的优化问题, 但由于BPSO算法中采用的粒子是二进制数, c2r2(
实验样本采自山西省晋中市太谷区西山底村桃园, 品种为“ 早熟大久保” 。 为保证研究结果的可靠性, 采摘时选择大小均匀, 外形类似的久保桃, 共选取了198个久保桃样本。 利用Kennard-Stone算法按照3:1的比例随机分为147个校正集和51个预测集。
采用的光谱仪是“ 盖亚” 高光谱分选仪(北京卓立汉光仪器有限公司), 选用光谱波长范围为900~1 700 nm, 分辨率为5 nm。 实验样本曝光时间为20 ms, 样本到镜头的高度为22 cm, 电控移动平台前进的速度为2 cm· s-1, 黑白校正方式见参考文献[15]。 采集光谱所用软件为: SpecView图像采集软件, 处理数据软件为: ENVI4.7(ITT Visual in formagtion Solutions, Boudler, 美国), Matlab2016b(The MathsWorks, Natick, 美国)、 The Unscrambler X10.1(CAMO AS, Oslo, 挪威)、 Origin8.5(Origin Lab, 美国)。 SSC含量测量采用PAL-106糖度计(杭州齐威仪器设备有限公司)。
参照GB/T10788-89《水果、 蔬菜制品中可溶性固形物含量的测定》。 对每个久保桃实验样本的可溶性固形物含量(SSC)进行测定。 SSC值如表1所示。
| 表1 久保桃SSC的实测值(%) Table 1 Measured SSC values of Kubo peach (%) |
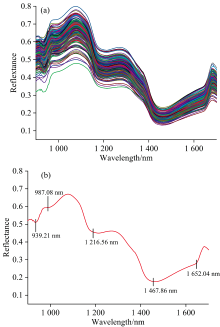
使用ENVI4.7软件提取久保桃样本中心位置80像素× 80像素的感兴趣区域, 经处理分析后得到久保桃样本的原始光谱曲线。 在原始光谱曲线的基础上, 计算了均值, 绘制了原始光谱曲线的均值曲线图, 并在均值曲线图上对特征吸收峰进行了相应的标注。 如图1所示。
 | 图1 样品光谱 (a): 原始光谱; (b): 平均光谱Fig.1 Spectra of samples (a): Original spectra; (b): Mean spectrum |
由图1知, 久保桃样本的光谱数据在1 216.56和1 467.86 nm处出现较为明显的吸收峰, 在939.21、 987.08和1 652.04 nm处出现小的吸收峰, 其中900~1 216.56 nm波段之间的吸收峰, 与久保桃表皮及桃果实细胞中叶绿素和类胡萝卜素的吸收有关, 1 216.56~1 700 nm之间的吸收峰, 与久保桃果实内部所含水分的多少与糖分含量有关, 分别属于O-H三级和二级倍频特征吸收峰[16]。
特征光谱变量的提取是为了提取原始全波段光谱中有用的波长信息, 以提高预测模型的精准性, 提取特征光谱变量时, 既要尽可能减少总的波长个数, 又要确保不遗漏重要光谱信息。
2.4.1 基于BPSO的特征光谱变量提取
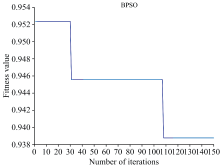
利用BPSO算法提取特征光谱变量时, 设置循环次数T为10次, 最大迭代次数150, 惯性因子初始值c1=c2=2, 最大速度vmax为6, 最大惯性wmax为0.9, 最小惯性wmin为0.4。 BPSO挑选特征波长过程中, 最优粒子适应值的变化曲线如图2所示。 横坐标表示迭代次数, 纵坐标表示适应度曲线。
 | 图2 BPSO提取特征波长过程Fig.2 Characteristic wavelength extraction process of BPSO |
光谱数据的适应度曲线变化和筛选误差成正比, 随着迭代次数的增加, 适应度曲线呈下降趋势, 模型误差也在减小, 当误差下降到最低值时, 筛选出的特征波长变量即为最优特征波长, 最终基于离散二进制算法提取了114个特征波长。 分别为: 899、 905、 911、 918、 924、 927、 931、 940、 943、 950、 953、 959、 962、 982、 985、 988、 994、 998、 1 004、 1 010、 1 023、 1 036、 1 052、 1 055、 1 058、 1 061、 1 064、 1 071、 1 074、 1 084、 1 093、 1 103、 1 128、 1 131、 1 135、 1 141、 1 144、 1 151、 1 154、 1 163、 1 170、 1 189、 1 192、 1 208、 1 227、 1 230、 1 233、 1 243、 1 249、 1 265、 1 287、 1 297、 1 303、 1 310、 1 319、 1 322、 1 326、 1 329、 1 335、 1 348、 1 351、 1 357、 1 364、 1 367、 1 386、 1 396、 1 402、 1 412、 1 418、 1 427、 1 437、 1 446、 1 453、 1 456、 1 459、 1 475、 1 485、 1 488、 1 491、 1 500、 1 507、 1 513、 1 520、 1 526、 1 539、 1 554、 1 561、 1 570、 1 574、 1 586、 1 589、 1 593、 1 596、 1 612、 1 615、 1 618、 1 621、 1 624、 1 628、 1 631、 1 634、 1 637、 1 640、 1 643、 1 647、 1 656、 1 659、 1 662、 1 666、 1 669、 1 672、 1 681、 1 688和1 700 nm。
2.4.2 基于CARS、 SPA、 UVE的特征光谱变量提取
对久保桃样本的原始全波段光谱数据分别采用竞争性自适应重加权算法(CARS)[17]、 连续投影算法(SPA)[18]、 无信息变量消除算法(UVE)[19]从原始光谱数据中提取特征波长, 最终采用CARS算法挑选了43个特征波长, SPA算法挑选了12个特征波长, UVE算法挑选了79个特征波长, 结果如表2所示。
| 表2 不同选择方法筛选出的特征波长 Table 2 Characteristic wavelengths screened by different selection methods |
由表2可知, CARS算法筛选出的波长存在着信息冗余的问题, SPA算法提取的变量数过少, UVE算法存在着间断性连续的筛选, 导致筛选的波长不具有代表性。 因此为了弥补单一特征波长提取算法存在的不足, 后续采用基于BPSO的特征变量组合算法对久保桃的特征光谱数据作进一步筛选。
2.4.3 特征变量的组合
由前四种单一算法筛选出的特征波长可知, BPSO算法筛选出特征光谱仅为局部最佳特征波长, 且变量数目过多。 CARS、 SPA、 UVE算法存在着不稳定, 变量数过少和连续筛选的问题。 因此文章提出基于BPSO的组合算法, 建立LS-SVM模型和GA-SVM模型。 各个方法提取的有效波长变量个数如表3所示。 提取的有效波长如表4所示。
| 表3 不同特征提取方法提取到的特征变量数 Table 3 Number of feature variables extracted by different feature extraction methods |
| 表4 组合降维特征提取方法提取到的特征波长 Table 4 Feature wavelengths extracted by combined dimension reduction feature extraction method |
2.5.1 GA-SVM模型
遗传算法(GA)是一种模拟自然进化的自适应优化搜索方法, 具有高适应度, 高效率, 快速搜索的特点[20]。 引入GA优化SVM模型的超参数, 可以将GA算法的优势应用于SVM模型中, 获得时间短, 效率高的优化模型, 从而获得更准确的预测。 设置遗传算法(GA)的最大遗传迭代数为100, 种群规模数量为20, 采用5折交叉验证方式, 得出最优惩罚因子(Cost)记为c和核心参数(gamma)记为r。 利用GA-SVM算法建立判别模型优化参数BestC和Bestg和预测结果如表5所示。
| 表5 不同变量优选方法建立的GA-SVM模型参数优化及预测结果 Table 5 Parameter optimization and prediction results of GA-SVM model established by different variable optimization methods |
由表5可知, 四种单一特征波长提取方法建立的GA-SVM模型中, BPSO提取的114个特征波长所建模型精度最高, 校正集的决定系数
2.5.2 LS-SVM模型
最小二乘支持向量机模型(LS-SVM)建模方法, 主要针对SVM的目标参数r和σ 2进行全局寻优, 使得均方根误差RMSEC取得最小值的原理[21]。 不同特征光谱变量优选方法建立的LS-SVM预测结果见表6。
| 表6 不同变量优选方法建立的糖度LS-SVM模型预测结果 Table 6 Prediction results of sugar LS-SVM model established by different variable optimization methods |
由表6可知, 单一特征波长提取方法建立的LS-SVM模型中, BPSO提取的114个特征波长所建模型精度最高, 校正集的决定系数
2.5.3 模型对比分析
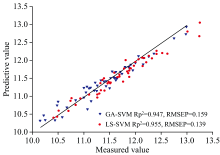
综合表5, 表6可知, 基于BPSO组合方法建立的两种模型都取得了较好的预测结果, (BPSO+CARS)-SPA-GA-SVM模型的校正集的决定系数
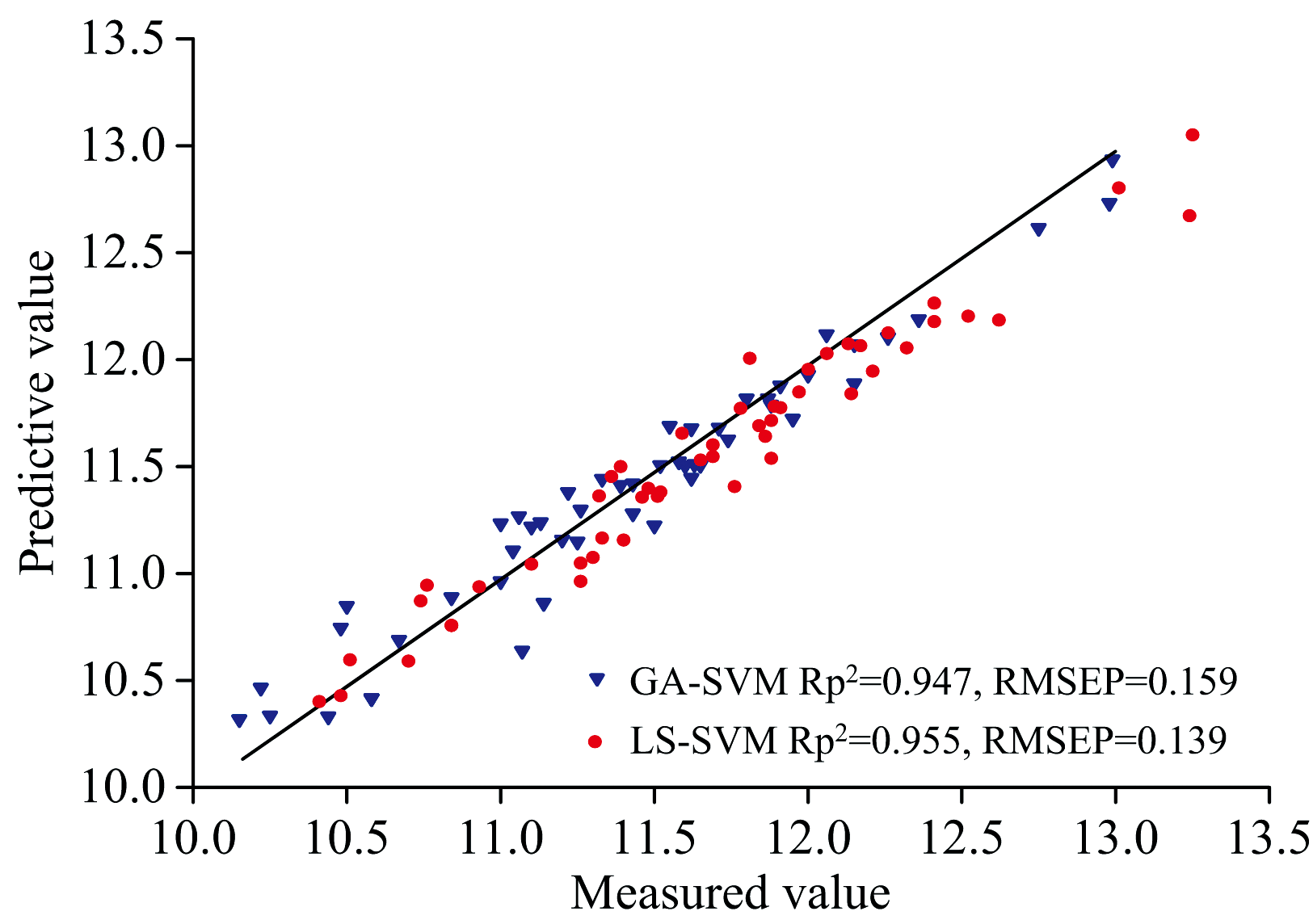 | 图3 两种模型的预测结果图Fig.3 Prediction results of the two models |
基于高光谱技术结合离散二进制粒子群算法(BPSO)及基于BPSO的组合特征波长选择方法建立模型, 以实现久保桃可溶性固形物含量(SSC)的快速, 无损检测, 研究结果如下:
(1)与常规特征波长提取算法CARS、 SPA、 UVE比较, 基于BPSO算法建立的两种模型预测性能均比较好, 预测集决定系数均达到了0.97以上。
(2)基于BPSO的组合特征波长提取算法中(BPSO+SPA)-SPA算法在波长数量较少的情况下建立的LS-SVM模型最好, 其校正集的决定系数
王铭海[22]使用近红外漫反射光谱技术无损测定多品种桃的可溶性固形物含量时, 采用移动窗口偏最小二乘法(MWPLS)提取了105个特征波长, 建立多种桃样本的可溶性固形物含量模型, 其模型校正集与预测集的决定系数
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|