






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于孪生网络模型的岩石光谱自动分类方法
[肖志强1  , 贺金鑫
, 贺金鑫1, * , 陈德博1 , 战晔2 , 逯燕乐1 ]
, 贺金鑫, 陈德博|
|


作者简介: 肖志强, 1996年生, 吉林大学地球科学学院研究生 e-mail: xiaozq19@mails.jlu.edu.cn
岩石光谱是岩石物理化学性质、 成分和结构的综合体现, 如今已经被广泛应用于岩石分类研究中。 岩石光谱数据具有高维的特征数量, 在样本数量有限的情况下训练时, 往往会产生维数灾难现象。 由于岩石光谱的数据收集困难, 这在产生极大的人力成本的同时也导致收集到的岩石光谱数据往往十分有限。 因此如何能够在样本数量较少时, 对岩石光谱数据取得较为准确的分类效果成为了如今热门的研究课题。 利用辽宁兴城地区的典型岩石光谱数据, 基于Python编程语言在训练样本较少的情况下构建了孪生网络分类模型, 并以Triplet Loss作为损失函数, 实现了3-way-1-shot分类模型, 在测试集上取得了97.8%的分类准确率。 同时使用了决策树、 随机森林、 支持向量机和K-近邻四种传统机器学习方法在相同训练样本下建立分类模型与之对比, 通过绘制学习曲线, 验证了这四种传统机器学习方法在小样本的情况下不具备良好的分类功能。 由于将原始光谱数据转化为图片数据之后并不会影响孪生网络模型的分类效果, 因此可以将岩石光谱分类问题转化为图像分类的问题, 进而使用图像分类的方法和手段。 实验结果表明, 孪生网络模型在岩石光谱样本数量较少的情况下仍然能够取得优秀的分类效果, 有效弥补了传统机器学习模型在小样本情况下的不足之处, 并且由于其数据的输入是成对的, 可以有效减小因训练样本过少而导致的过拟合问题。
Rock spectrum is the comprehensive embodiment of rock's physical and chemical properties, composition and structure. Now, it has been widely used in rock classification research. Due to the difficulty of collecting the data on the rock spectrum, it often needs to be collected manually, which not only causes great labor cost but also leads to the limited data on the rock spectrum collected. When the rock spectral classification model is trained with a limited number of samples, the dimensional disaster phenomenon will generally occur. That is, the accuracy of classification will decrease with the rise of the feature dimension, and the rock spectral data coincides with this feature, with a high dimensional number of features. Therefore, to achieve good classification results, a large number of training samples are needed to be used in the training of traditional rock spectral classification models, usually more times than the feature dimension. If the number of samples is small, we must reduce the features to obtain the ideal classification accuracy. Therefore, when the number of samples is small, obtaining a more accurate classification effect on rock spectral data has become a hot research topic. This paper collects the spectral data of typical rocks in Xingcheng, Liaoning Province. Based on the Python programming language, the Siamese Network classification model is constructed with few training samples, and the Triplet Loss is used as the loss function to realize the 3-way-1-shot classification model, and the prediction accuracy of 97.8% is achieved in the verification set. At the same time, four traditional machine learning methods, which include Decision Tree, Random Forest, Support Vector Machine and K-Nearest Neighbor, were used to establish the classification model under the same training samples and compared with them. By drawing the learning curve, it is verified that these four traditional machine learning methods do not have good classification functions in the case of small samples. Since converting the original spectral data into image data will not affect the classification effect of the Siamese Network classification model, the rock spectral classification problem can be transformed into the problem of image classification. Then the image classification methods and means can be used. The experimental results show that the Siamese Network classification model in the case of fewer rock spectral samples can still achieve excellent classification effect, which effectively makes up for the shortcomings of the traditional machine learning model in the case of small samples. Because the data input is paired, it can effectively reduce the overfitting problem caused by too few training samples.
近些年来, 机器学习技术的快速发展与应用深刻影响着各个领域, 也让不同行业的从业者和研究人员享受到了该项技术带来的便利性, 高光谱遥感领域也不例外。 通过对高光谱遥感在地质应用领域的调研来看, 国内外广大学者普遍采用机器学习及相关方法对岩石光谱进行分类, 而分类模型可以大致概括为两大类: 传统机器学习模型和神经网络模型。
传统机器学习模型: 传统的几类机器学习方法发展较为成熟, 受到众多学者的青睐, 这一点在岩石光谱分类应用研究上也得到了体现。 Pane等[1]使用了K-近邻(K-nearest neighbors, KNN)、 支持向量机(support vector machine, SVM)、 决策树(decision tree, DT)、 随机森林(random forest, RF)和多层感知器(multiLayer perceptron, MLP)等五种监督学习方法生成的模型, 对岩石光谱进行分类, 并在SVM方法上取得了最高的分类准确性。 刘烨等[2]提出一种基于岩石薄片图像的自动分类方法, 通过支持向量机方法建立特征空间与岩石类别之间的映射关系。 韦任等[3]通过二阶微分法对煤岩特征进行特征提取, 之后再用随机森林和支持向量机算法进行模拟, 取得90%以上的分类准确率。 Crowley等[4]使用最小二乘光谱波段拟合算法对光谱数据进行光谱绘制比对, 实现了远程识别八种不同的含盐矿物。
以上学者使用的都是单一模型, 为了能够将不同模型的优势结合到一起, 贺金鑫[5]等利用硬投票法融合了RF、 KNN与SVM三个机器学习模型, 硬投票法通过对不同模型的分类结果进行投票, 投票最多的分类结果将作为最终的分类结果, 最终融合的模型达到了99.17%的分类准确率。
神经网络模型: 早在1994年, Tanabe等[6]构建3层前向传播神经网络模型, 实现了对6种近红外蚀变岩石光谱的识别与分类, 识别准确率近100%。 2013年, Ishikawa等[7]在此基础上, 使用拉曼数据光谱库作为训练集, 得到一个人工神经网络矿物分类器, 并对橄榄石、 石英、 斜长石、 钾长石、 云母和几种辉石加以分类, 平均准确率达83%。 常项平[8]使用卷积神经网络结合像素的光谱和空间信息, 对明矾石、 高岭石、 蒙脱石和玉髓四种矿石进行深度监督分类, 取得分类精度达到90.58%。 Xu等[9]针对岩石光谱数据的复杂性, 基于深度学习神经网络提出了一种专门为2D光谱数据设计的新CNN架构。 满文婧等[10]通过Symlets小波变换将岩石光谱数据转换为频谱图, 作为深度卷积分类模型的基础数据, 再利用50层深度残差网络(ResNet50)模型对数据进行分类。
也有学者二者兼用, 并做了相关对比分析。 Liu等[11]建立了基于矿物光谱的卷积神经网络(CNN)分类模型, 并与SVM模型做对比, 认为该神经网络能够提取更加丰富的光谱特征, 因此在分类结果上更具有优越性。
总之, 该领域目前的大部分做法是将光谱数据进行预处理后利用机器学习方法进行岩性分类, 之后再使用大量样本数据来进行模型训练; 但若在样本数量较少的情况下, 则容易因为训练不充分而导致分类结果不够准确, 或者是出现过拟合现象。 因此, 本文利用辽宁兴城地区的典型岩石光谱数据, 基于Python编程语言构建了孪生网络分类模型, 以实现小样本情况下岩石光谱的自动分类。
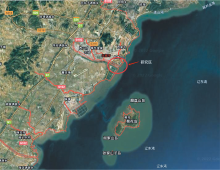
兴城市位于辽宁省西部, 地处北温带, 属亚湿润季风气候, 交通方面由京哈高速公路纵贯全境, 西南方向通往秦皇岛市, 东北方向连接葫芦岛和锦州市(图1)。
 | 图1 研究区卫星遥感图像Fig.1 Remote sensing image of the study area |
兴城地区地层为典型的华北地台沉积类型, 且地层较为完整, 主要包括太古宇岩石单元、 中、 新元古界, 古生界, 中生界和新生界。 在大地构造上, 兴城位于下辽河-渤海断陷盆地和辽西断陷山地两大构造单元的过渡带之间。 兴城地区位于华北克拉通, 由于晚古生代末期— 中生代受到了古亚洲洋俯冲、 扬子克拉通大陆深俯冲、 古太平洋板块俯冲等作用的影响, 导致岩浆活动强烈, 形成了分布广泛的岩浆岩。 区内岩浆岩主要分布在台里海滨、 钓鱼台海滨、 七里坡尖山、 华山镇、 夹山西、 首山等地区。 兴城地区主要出露的变质岩为接触变质岩和断裂带动力变质岩, 主要分布在台里海滨地区和华山镇路线。 研究区出露的沉积岩较为丰富, 以砂岩、 泥岩、 碳酸盐岩为主, 主要分布在葫芦岛、 月亮山、 团山子和夹山等地。 研究区的岩性分布如图2所示。
 | 图2 研究区岩性分布图[5]Fig.2 Distribution of rocks in the study area |
用于测量岩石光谱的仪器为美国FieldSpec-3型便携式实测光谱仪, 所测波长从350 nm的可见光范围分布到2 500 nm的短波红外范围。 可见光的光谱测量间隔为1.4 nm, 分辨率约为3 nm; 短波红外的间隔为2 nm, 分辨率为6.5~8.5 nm[12]。
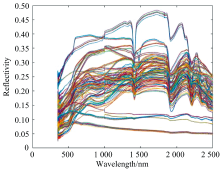
 | 图3 总样品数据集的岩石光谱反射率Fig.3 Spectral reflectance of the whole samples |
目前取得砂岩类、 花岗岩类、 灰岩类三大类岩石光谱数据共690条, 经过整理后得到细粒黑云母二长花岗岩10条数据, 中细粒二长花岗岩15条数据, 中粒二长花岗岩15条数据, 细粒二长花岗岩30条数据, 花岗斑岩15条数据, 含斑黑云角闪二长花岗岩10条数据, 中粒黑云母二长花岗岩20条数据, 二长花岗岩20条数据, 中粗粒黑云二长花岗岩10条数据, 黑云母二长花岗岩20条数据, 鲕状灰岩40条数据, 灰岩25条数据, 安山质凝灰岩20条数据, 白云岩15条数据, 结晶灰岩20条数据, 含角砾晶屑岩屑凝灰岩30条数据, 青灰色白云岩30条数据, 灰黑色鲕状灰岩90条数据, 燧石条带白云岩40条数据, 白云质灰岩130条数据, 中粒岩屑长石砂岩25条数据, 灰白色长石石英砂岩10条数据, 中粗砾长石石英砂岩10条数据, 含砾石英砂岩, 20条数据灰色中粒长石石英砂岩10条数据, 长石石英砂岩10条数据。
获得的岩石光谱数据具有以下特点: 三种岩石在1 900 nm处的光谱中存在强吸收谷, 花岗岩和砂岩在约1 400 nm处存在水蒸气吸收带(如图4和图6所示); 花岗岩的总体反射率为0~0.5, 石灰岩为0~0.7, 砂岩为0~0.6; 石英砂岩、 白云石和其他岩石在2 200 nm处有一个由羟基吸收引起的吸收谷, 砂岩在900 nm处有铁离子吸收带, 灰岩在2 300 nm处产生碳酸根离子的特征吸收[5]。
 | 图4 花岗岩光谱反射率Fig.4 Spectral reflectance of granite |
 | 图5 灰岩光谱反射率Fig.5 Spectral reflectance of limestone |
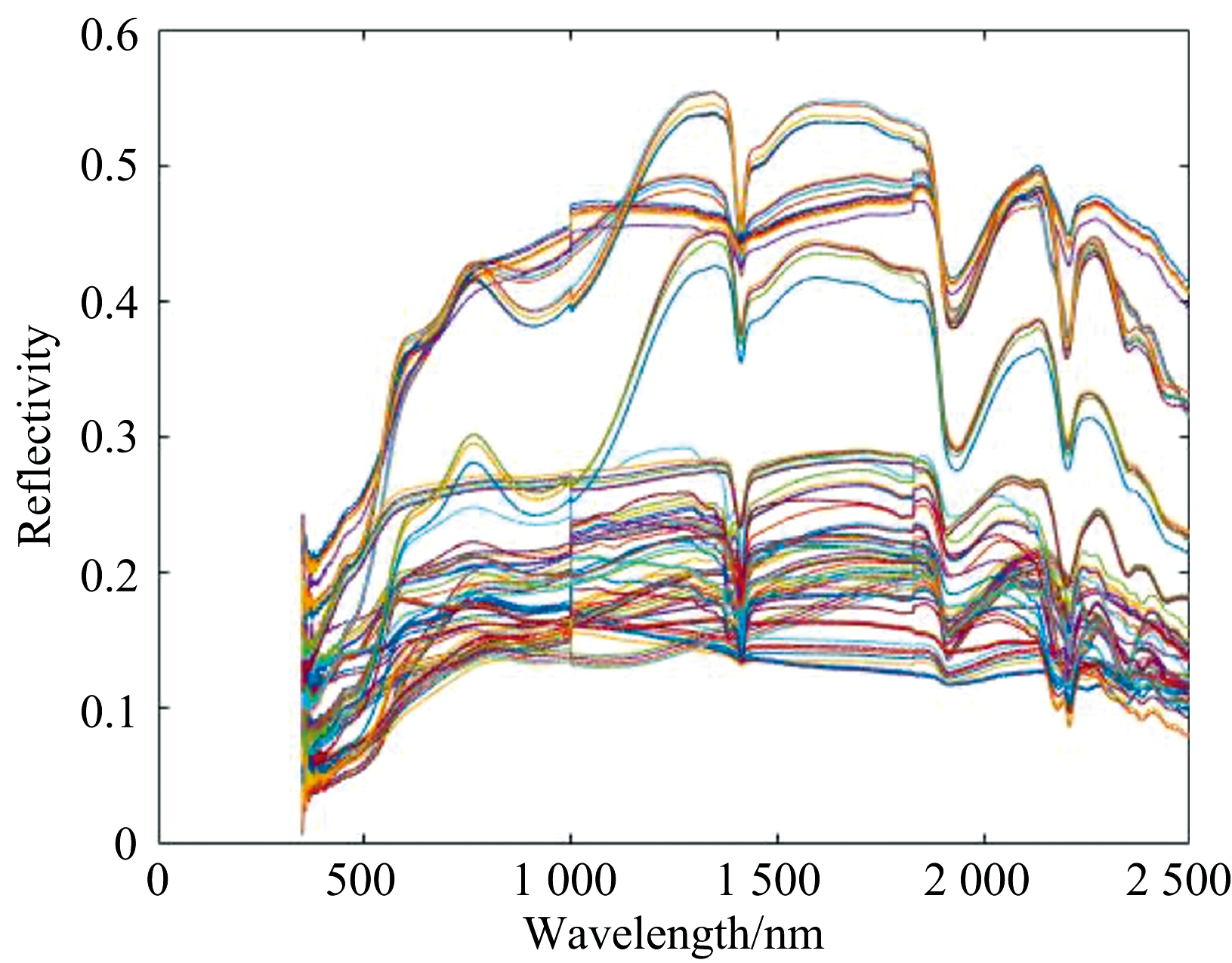 | 图6 砂岩光谱反射率Fig.6 Spectral reflectance of sandstone |
1.5.1 原始光谱数据转换
在进行训练孪生网络模型之前, 需要将岩石光谱数据转化为类似于图片的样本数据, 以便作为模型训练的输入。 原始岩石光谱数据具有2 154维特征, 将其转化成48× 48大小的单通道图片, 由于是进行相似度比较, 将原始的线性特征关系转换为空间特征关系之后对结果并不会造成影响。 转换后的岩石光谱数据如图7所示。
 | 图7 转换前后的岩石光谱数据Fig.7 Rock spectral data before and after conversion |
将转换后的细粒二长花岗岩、 中粒岩屑长石砂岩和鲕状灰岩三类共95条数据作为孪生网络模型的测试集, 除了这三类之外的白云岩、 灰岩、 二长花岗岩等23类岩石共595条数据则作为其训练集。 而对于四种传统机器学习方法, 则直接使用三类岩石类型的原始光谱数据, 以6∶ 4拆分为训练集和测试集, 从而保证测试集的一致性。
1.5.2 孪生网络
孪生网络是有两个输入端的类神经网络架构, 与一般学习模型只有对一个输入端进行分类有所不同, 孪生网络会学习两个输入端的相似度, 其结构如图8所示。
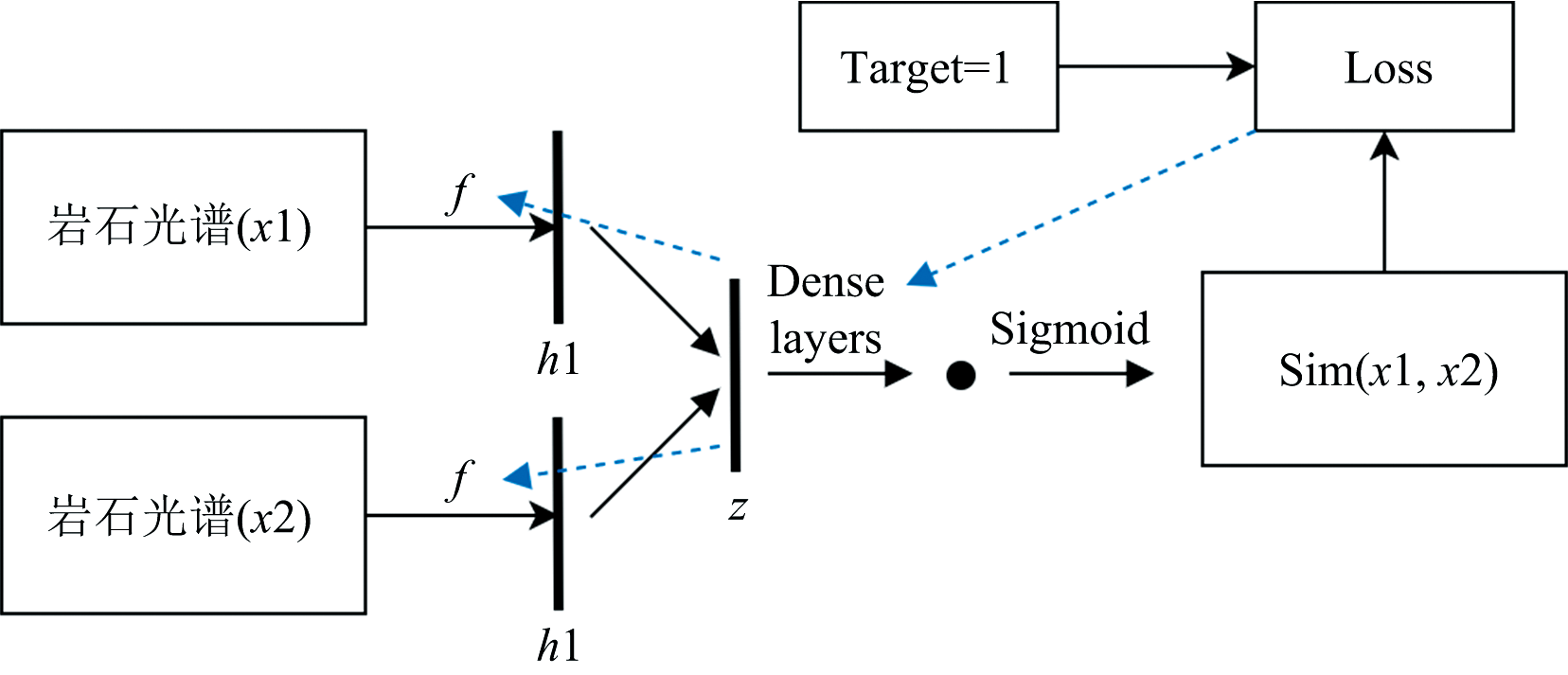 | 图8 孪生网络示意图Fig.8 Siamese network diagram |
具体的孪生网络结构如图9所示, 孪生网络由3个不带池化层的卷积单元组成, 每个卷积单元又分为4层, 首先通过ReflectionPad2d来对输入的张量进行填充, 之后通过Conv2d二维卷积层进行特征提取, 激活函数选择ReLU能够提高网络的收敛能力, 最后通过加入批标准化(batch normalization)层使得网络更加稳定。
 | 图9 孪生网络结构图Fig.9 Siamese network structure diagram |
1.5.3 分类模型构建
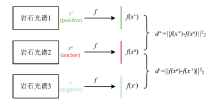
损失函数选择使用Triplet Loss, 在构建训练集时, 需每次从数据集中选取3条数据。 首先从数据集中随机选取一类岩石光谱数据作为锚点(Anchor), 再从锚点数据所在类别中随机抽取另一条光谱数据作为正样本(Positive), 然后排除锚点所在类别, 从数据集中随机选取一条岩石光谱数据作为负样本(Negative)。 将锚点光谱数据、 正样本光谱数据和负样本光谱数据分别输入搭建好的用于提取图片特征的卷积神经网络, 得到三个特征向量f(x+)、 f(xa)和f(x-)。 分别计算f(xa)和f(x+)、 f(xa)和f(x-)二范数的平方d+和d-, 即d+=‖ f(x+)-f(xa)
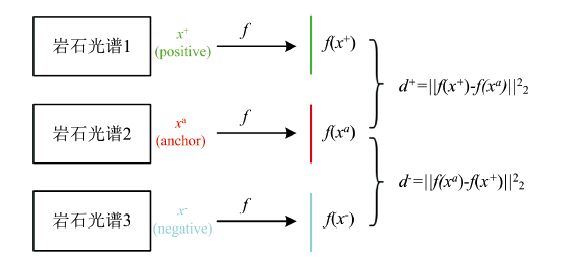 | 图10 Triplet Loss计算过程Fig.10 Triplet Loss calculation process |
在结果精度评估中, 选取了分类准确率和Kappa系数作为衡量标准, 结果如表1所示。 从模型在测试集上的预测准确率可以看出, 孪生网络的预测准确率为97.8%, 同时其Kappa系数为0.96, 分类效果优于传统的决策树、 随机森林、 支持向量机和K-近邻四种机器学习模型。 并且与传统机器学习不同的是, 其训练集使用的是白云岩、 灰岩、 二长花岗岩等23类岩石共595条数据, 并且是成对输入, 极大增加了训练集, 有效缓解了模型过拟合问题。 测试集则使用细粒二长花岗岩、 中粒岩屑长石砂岩和鲕状灰岩这三类岩石共95条数据, 相较于四种传统机器学习方法在其测试集上的表现, 孪生网络模型在数据量更大的测试集上取得了更高的分类准确率, 体现了孪生网络模型在小样本分类方面的优越性。
| 表1 岩石光谱分类结果 Table 1 Classification result of rock spectra |
在辽宁兴城地区实测的不同岩石反射光谱数据特征基础之上, 分别利用决策树、 随机森林、 支持向量机和K-近邻, 以及孪生网络模型进行了岩石光谱特征自动分类方法研究。 从实验结果可以看出: (1) 将原始光谱数据转化为图片数据之后, 并不会影响孪生网络模型的分类效果, 进而可以将岩石光谱分类问题转化为图像方面的问题, 使用图像处理相关的工具和方法; (2) 在样本数量较少的情况下, 孪生神经网络模型的分类效果显著优于四种传统机器学习模型; (3) 由于孪生网络的训练集可以与测试集不同, 因此能够将数量更多的其他岩石光谱数据用作训练, 并且是成对输入, 能够有效缓解因训练样本不足而导致的过拟合问题。 在后续研究工作中, 将对相同大类岩石类型下的不同子类岩石光谱做分类, 以期能够在小样本情况下取得同等优秀的分类效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|