








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
改进时间卷积网络的红壤有机质高光谱预测模型
[邓昀1, 2  , 牛照文
, 牛照文1, 2 , 冯琦尧1, 2 , 王宇1, 2, * ]
, 牛照文]
|
|


作者简介: 邓 昀, 1980年生, 桂林理工大学教授 e-mail: 574359451@qq.com
针对现有卷积神经网络土壤有机质(SOM)预测模型用在小样本数据集存在建模效果差, 预测精度不够高等问题, 为更加精准预测土壤SOM含量, 以广西国有黄冕林场和国有雅长林场采集的206个土壤样品为研究对象, 提出了一种改进时间卷积网络(SATCN)的红壤有机质高光谱预测模型。 对土壤样品进行Savitaky-Golay(SG)平滑以及一阶微分(1DR)、 二阶微分(2DR)、 标准正态变量(SNV)和多元散射校正(MSC)四种变换, 对比分析长短记忆网络(LSTM)、 偏最小二乘回归(PLSR)和支持向量机(SVM)在不同光谱预处理下的建模效果, 结果表明, 采用SG处理后的光谱一阶微分预处理方法, 建模效果最好; 在时间卷积网络(TCN)架构上, 采用浅层网络结构, 在TCN残差结构中加入自注意力层, 提高模型特征学习能力; 每个卷积核权重加入L2正则化, 防止过拟合; 选取一阶微分作为光谱预处理, 建立ResNet-13、 VGGNet-7、 时间卷积网络(TCN)和改进时间卷积网络(SATCN)四种模型, 对比分析四种模型建模效果, 以及SATCN模型在不同网络深度下模型建模效果。 结果表明, 在一阶微分光谱预处理的情况下, 浅层SATCN模型建模效果优于深层模型; SATCN模型中的自注意力残差结构, 不仅能够强化光谱序列重要特征, 模型特征学习能力和预测精度也有显著提高。 相比于CNN、 TCN等建模方法, 提出的SATCN模型建模效果最好, 拥有更高的精确度和极好的模型估测能力, 验证集的决定系数( R2)为0.943, 均方根误差(RMSE)为3.042 g·kg-1, 相对分析误差(RPD)为4.273。 综上所述, SOM含量的最佳预测模型是采用SG平滑后一阶微分光谱预处理基础上建立的SATCN预测模型, 对广西林地土壤有机质含量进行更加了精准预测。
The existing convolutional neural network soil organic matter (SOM) prediction models suffer from low modeling effectiveness and low prediction accuracy under small sample data sets. In order to predict the content of organic matter in the soil more accurately, this paper proposes a hyperspectral prediction model of red soil organic matter with an improved Self Attention Temporal Convolutional Network (SATCN) using 206 collected soil samples as the research object. In this paper, after Savitaky-Golay (SG) smoothing is performed on soil samples, four transformations are performed: first-order differential (1DR), second-order differential (2DR), standard normal variable (SNV) and multivariate scattering correction (MSC). The modeling effects of Long Short-Term Memory (LSTM), Partial Least Squares Regression (PLSR) and Support Vector Machine (SVM) under different spectral preprocessing were compared and analyzed. The results show that the first-order differential preprocessing method of the spectrum after SG processing has the best modeling effect. A shallow network structure is applied in the temporal convolutional network (TCN) architecture, a self-attention layer is added to the TCN residual structure to improve the model feature learning capability, and L2 regularization is added to each convolutional kernel weight to prevent overfitting. First-order differentiation is selected as the spectral preprocessing, and four models of ResNet-13, VGGNet-7, TCN and improved temporal convolutional network (SATCN) are constructed to compare and analyze the modeling effects of the four models, as well as the modeling effects of SATCN models at different network depths. The results show that the shallow SATCN modeling is better than the deep model in the case of first-order differential spectral preprocessing; the self-attention residual structure in the SATCN model not only enhanced the important features of the spectral sequence, but also significantly improved the model feature learning ability and prediction accuracy. Compared with modeling methods such as CNN and TCN, the proposed SATCN model has higher accuracy and excellent model estimation capability with a coefficient of determination ( R2) of 0.943, root mean square error (RMSE) of 3.042 g·kg-1, and relative analysis error (RPD) of 4.273 for the validation set. In summary, the best budget SOM content of this paper model is the SATCN prediction model based on the first-order differential spectral preprocessing after SG smoothing, which provides a more accurate prediction of soil organic matter in Guangxi woodlands.
土壤有机质(SOM)是衡量土壤肥沃度的一个重要指标[1]。 它能够促进植物生长, 改善土壤物理性质。 快速、 准确获取土壤有机质含量对农业发展具有重要价值和意义。 然而, 传统的化学方法估算SOM含量成本高、 耗时长、 工作量大, 不能满足当前发展需求。 随着高光谱遥感技术的发展, 土壤养分含量预测具有了广泛的研究和应用基础[2]。 但是高光谱仪得到的光谱数据容易受到噪声、 基线漂移等因素的干扰, 导致建模效果不佳。 因此, 需要对光谱数据进行降噪, 数据变换来提高建模效果。 目前, 有许多学者都加入高光谱技术预测土壤养分的研究。 为了进一步探究光谱数据隐藏信息, 2016年, Lin等采用SG-MSC作为光谱数据预处理, 既降低噪声, 又消除基线漂移的影响, 有效减少光谱数据中无关和无用的信息, 显著提高光谱数据与测量值之间的相关性[3]。 2018年, 王海峰等采用灰色关联度(GCD)确定标准正态分布变换(SNV)光谱指标, 结合岭回归法(RR)建模, 建模精度R2为0.87[4]。 2020年, Shen等采用小波包降噪, 主成分分析(PCA)和偏最小二乘回归(PLSR)建模, 能够有效提高光谱数据质量和模型精度[5]。 由于深度神经网络擅长处理多维数据或较大数据, 2019年, Padarian等采用多任务卷积神经网络模型在LUCAS数据集上预测土壤性质, 结果表明深度学习模型仅适用于大规模光谱数据集, 对小样本数据集的预测结果较差[6]。 2020年, 谈爱玲等构建一维卷积神经网络(CNN)融合光谱, 对比机器学习模型建模效果更好[7]。 2021年, 钟亮等通过对比不同网络结构的卷积神经网络(CNN), 发现原始光谱的VGGNet-7建模效果最好, 建模精度R2为0.901[8]。
现有大多数研究采用机器学习方法建模, 需要进行降噪、 确定光谱指数、 数据降维和建模预测, 建模过程繁琐, 并且各波段间多重共线且关系复杂。 随着卷积神经网络发展, CNN强大的特征学习能力, 既简化了建模过程, 也提高了模型精度。 但是CNN用在小样本数据集的建模效果较差, 有预测精度不够高等问题, 本工作旨在探究一种能够快速、 准确估算土壤有机质(SOM)含量的深度学习模型。
先对样本数据进行SG降噪, 再进行不同的光谱预处理, 对比分析偏最小二乘回归(PLSR)、 支持向量机(SVM)、 长短记忆网络(long short-term memory, LSTM)三种模型在不同光谱预处理下建模效果, 确定较好的光谱预处理方法。 在此基础上构建一种改进时间卷积网络的红壤有机质高光谱预测模型。 为广西林地红壤有机质的定量遥感估测探索一种新方法。
研究区位于广西国有黄冕林场(109° 43'46″E, 24° 37'25″N)和国有雅长林场(106° 16'30″E, 24° 49'30″N), 都属于亚热带气候, 年均降雨量分别为1 750和1 057 mm, 年平均温度19和16.8 ℃。 本区土地利用类型为林地, 土壤类型为酸性沉积岩发育的红壤, 根据中国土壤分类法, 红壤来自泥盆纪的砂岩和砂岩页岩, 主要种植桉树、 杉树和松树为主。 由于缺乏有效土壤养分检测, 加上人为不合理种植, 导致林地土壤退化加剧。
研究区内树木生长均匀, 采用S形取样法采集了0~20 cm土层样品, 共采集了206个样本, 研究区内采样点如图1所示, 部分采样点在林场外围。 样本自然风干、 研磨, 均匀分为两部分, 一部分样本通过0.2 nm的土壤筛子过筛, 再通过重铬酸钾氧化加热, 测定SOM含量; 另一部分通过0.149 nm的土壤筛子, 采用ASD FieldSpec1 4 Hi-Res地面物体光谱仪获取高光谱数据, 波谱范围包括可见光和近红外区域(350~2 500 nm)。 为保证光谱数据的准确性, 每份土样光谱数据进行10次重复采样, 取其平均值作为样本实测曲线。 然后导入Excel中。 由于光谱数据在光谱仪测量范围两端有噪声, 将小于400 nm和大于2 400 nm波段进行去除。
 | 图1 研究区域采样点分布Fig.1 Sampling point distribution |
采用的建模方法为改进时间卷积网络(self attention temporal convolutional network, SATCN), 为解决CNN处理小样本数据集存在建模效果差, 预测精度不够高等问题, 对TCN进行以下三点改进: 一是考虑到小样本数据集随着网络层次加深容易产生过拟合且不稳定, 采用浅层网络结构; 二是考虑到样本数据噪声干扰, 采用自注意力残差结构来增强模型特征学习能力, 提高模型精度; 三是考虑到模型训练中会出现过拟合现象, 对权重W添加L2正则化, 提高模型泛化性。 土壤SOM含量预测模型的建立主要包括光谱预处理、 选择最佳光谱预处理和SATCN网络结构设计。 具体流程如图2所示。
 | 图2 算法整体流程Fig.2 Overall flow of algorithm |
为了降低数据维度, 对光谱数据进行重采样处理, 每10 nm间隔取平均值, 然后对重采样的光谱数据进行Savitaky-Golay(SG)方法[9]平滑降噪。 采用的预处理方法主要有原始光谱反射率(R)、 一阶微分(1DR)、 二阶微分(2DR)、 标准正态变量(SNV)和多元散射校正(MSC)。 所有数据处理均通过PyCharm、 SPSS26.0和Excel 2010完成。 对光谱反射率数据进行离差标准化(min-max normalization), 使结果映射到0~1之间。 见式(1)
式(1)中: X为样本数据; Xmax为样本数据最大值; Xmin为样本数据最小值; Xmax-Xmin为极差; X* 为样本数据归一化后的值。
当向模型中输入光谱序列时, 随着光谱序列不断增加, 会出现信息过载, 为了解决这个问题, 引入自注意力机制[11]。 对于光谱序列来说, 自注意力机制能够把输入的光谱序列中不同波段的信息联系起来, 对光谱数据的内部相关性更加敏感, 不仅减少对外部信息的依赖, 还能有效提高特征的学习能力; 另外有助于神经网络模型将输出SOM值与输入的光谱序列进行匹配, 计算相对的匹配度权重, 进一步提高神经网络模型准确率。 基本结构如图3所示, 实现步骤如下:
 | 图3 自注意力机制Fig.3 Self-attention mechanism |
步骤1: 输入光谱序列矩阵X, 进行不同的矩阵变换得到查询(Query-Q)、 键(Key-K)和值(Value-V)三个矩阵, 计算Q和K之间的相似度, 得到每个对应V的权重系数A;
步骤2: 对权重系数矩阵A进行softmax归一化操作得到权重系数矩阵A';
步骤3: 对权重系数A'和矩阵V进行加权求和, 得到注意力数值。
自注意力机制公式如式(3)[12]所示
式(3)中: dK表示矩阵K的维度。
卷积神经网络(CNN)是一种非线性模型, 通过卷积和池化结构提取出输入信息的主要特征, 因此模型具有出色的表征提取能力[13]。 卷积神经网络构建块主要包括卷积层、 池化层、 Dropout层和全连接层; 卷积层对输入的光谱序列进行卷积计算, 增强输入序列数据的某些特征, 降低噪声; 池化层通过减少数据量实现降维, 同时保留有效信息避免过拟合; Dropout层通过消除神经元之间的依赖, 增强泛化能力; 全连接层通过神经元将提取的特征进行非线性组合, 拟合数据分布。 时间卷积网络(TCN)是在卷积神经网络基础上进行改进, 形成一种创新的网络结构。 其结构主要包括膨胀卷积、 因果卷积和残差结构。 通过结合一维全卷积和因果卷积转化为适合序列数据的模型, 在动作分割与检测, 文本情感分类, 以及时间序列预测等领域有广泛应用。
自注意力残差结构在TCN残差结构的基础上加入自注意力机制, 使得网络模型不仅实现了跨层的传递信息, 还提高了模型特征学习能力, 结构如图4所示。 它包括两个扩张的卷积层和一个自注意力层, 在每层之后加Dropout来实现正则化。 对于输入的光谱序列, 每个膨胀卷积层的膨胀率随着层数的增加呈指数增长, 能够在不增加池化损失信息的情况下, 扩展模型中每层卷积核的感受野, 让每个卷积输出都包含较大范围的光谱信息, 将卷积输出通过自注意力层, 强化光谱数据的重要特征作为输出, 最后将其和提取的原始特征进行合并输出, 提高特征学习能力。
 | 图4 自注意力残差结构Fig.4 Self-attention residual structure |
采用浅层时间卷积网络, 并在其残差结构中加入自注意力机制, 使得模型特征学习能力有所提高, 能够满足光谱分析有机质含量的建模需求。 SATCN模型结构如图5所示, 模型主要包括两个卷积层, 一个池化层和一个自注意力残差结构。 每个卷积层权重都加入L2正则化, 防止模型过拟合, 选用Relu作为激活函数, 增强模型非线性表达能力, 避免网络训练过程中出现的梯度消失和梯度爆炸问题; 选用最大池化层位于第一个卷积层后, 通过池化简化网络复杂度、 减少计算量; 自注意力残差结构中每个膨胀卷积的膨胀系数分别为2和4, 为了提高模型特征学习能力加入自注意力机制; 在每个全连接层后加入Dropout层, 避免模型学习过程中出现过拟合; 最后输出样本有机质含量。 模型参数如表1所示。
 | 图5 SATCN模型结构Fig.5 SATCN model structure |
| 表1 SATCN参数设置 Table 1 SATCN parameter settings |
采用最统一、 最客观的模型评价标准, 其中包括决定系数(R2)、 均方根误差(RMSE)和相对分析误差(relative percent deviation, RPD)。 R2越接近1, 实测值和估测值之间越接近, 模型准确性就越高; RMSE越小, 说明实测值与预测值偏差小, 模型越稳定; RPD的范围分为四类: 当RPD< 1.4时, 模型不可靠; 当1.4< RPD< 2, 可以通过微调来提高模型预测性能; 当2< RPD< 3时, 模型有较好的预测性能; 当RPD> 3, 模型具有极好的预估性能。 见式(4)— 式(6)
式中: n为样本总数; yi和为第i个样本真实值和预测值;
实验环境为Windows10系统, NVIDIA GeForce RTX 2070处理器, 16G内存, Python3.8编程语言, Keras2.4.3框架。 LSTM、 CNN和TCN模型通过PyCharm软件中keras库使用Python3.8语言进行搭建, PLSR和SVM模型通过调用sklearn接口中对应的机器学习模块实现。
选用SPXY算法对206个土壤样本有机质含量进行数据集划分, 按照4:1的比例分为2个部分, 共得到165个训练样本集, 41个验证样本集。 土壤样品SOM含量统计特征见表2。 研究区206个样本的SOM含量为4.26~80.04 g· kg-1, 平均值为25.72 g· kg-1, 标准差为13.57, 变异系数52.76%(属于中等程度变异)。 峰度(kurtosis, K)是描述数据分布形态的陡缓程度; 偏度(skewness, S)是描述数据分布的偏斜程度[14]。 3个样本的峰度K< 3(KW=1.28, KT=1.25, KV=1.70)则表明数据分布有较低的峰值; 偏度均为正值(SW=0.91, ST=0.93, SV=0.86), 说明各样本数据呈正偏态分布。
| 表2 土壤有机质含量统计特征 Table 2 Statistical characteristics of SOM content |
不同SOM含量光谱曲线图如图6所示, SOM含量按照每10 g· kg-1进行分组, 取其光谱反射率平均值进行绘图。 由图6可以看出, 每组样本曲线趋势基本相同, 在400~1 320 nm波段内光谱反射率随着波长快速递增, 整体走势很陡; 在1 320~2 100 nm波段趋于平稳; 在2 100~2 400 nm波段呈下降趋势, 在900 nm附近存在受氧化铁的影响的吸收谷, 在1 430、 1 950和2 230 nm附近存在明显的水分吸收谷。 SOM含量为80~90与30~80 g· kg-1的6组曲线在480和1 860 nm附近有明显交叉现象, 并且在这波段内其土样有部分反射率要高于这6组土样, 在1 860~2 400 nm波段内高于SOM含量60~70和70~80 g· kg-1的土样。 有机质含量与光谱反射率大小有一定影响, 有机质含量越大, 光谱反射率值越小; 反之, 光谱反射率值越大。
 | 图6 不同SOM含量土壤样本的光谱曲线 注: 图中数值如20~30 g· kg-1等为有机质含量Fig.6 Spectral curves of soil samples with different SOM contents Note: The values in the graph such as 20~30 g· kg-1 etc. are organic matter contents |
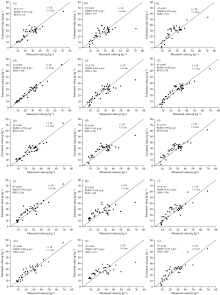
为了探究不同光谱预处理对线性模型、 非线性模型和神经网络模型的建模效果, 选取PLSR、 SVM和LSTM三种模型进行对比分析。 以验证集为例, 本文对比了5种光谱预处理分别在PLSR、 SVM和LSTM这三种模型进行土壤SOM含量估算, 其结果如图7所示。 图中可以看出, 从不同的光谱预处理来看, 采用光谱一阶微分来构建模型, 相比于其他预处理方法, 可以明显提高模型的精度, 并且其估测值和实测值更加接近1:1线, 1DR能够较好的体现光谱数据隐藏信息, 是较好的光谱预处理方法, 这也与国佳欣等[15]采用一阶微分作为光谱预处理, 相关性和相关系数明显提高的结论相似。 从不同模型来看, 非线性模型(LSTM和SVM)在不同光谱预处理上模型建模效果都要优于线性模型(PLSR), 在其他光谱预处理上LSTM建模效果要优于SVM。 图中可以看出, 当SOM含量小于30 g· kg-1时, 多数样本模型预测结果偏高; 当SOM含量大于30 g· kg-1时, 多数样本模型预测结果偏低。 由于SOM含量在70~80 g· kg-1的样本在480~1 860 nm波段内光谱反射率有部分高于SOM含量为30~40、 40~50、 50~60、 60~70和80~90 g· kg-1的样本, 导致SOM含量在30 g· kg-1附近特征混合, 容易导致神经网络模型预测不准确。
 | 图7 不同光谱预处理下各模型SOM含量实测值与估测值比较Fig.7 Comparison of measured and estimated SOM contents of each model under different spectral pretreatments (a): LSTM(R); (b): PLSR(R); (c): SVM(R); (d): LSTM(1DR); (e): PLSR(1DR); (f): SVM(1DR); (g): LSTM(2DR); (h): PLSR(2DR); (i): SVM(2DR); (j): LSTM(SNV); (k): PLSR(SNV); (l): SVM(SNV); (m): LSTM(MSC); (n): PLSR(MSC); (o): SVM(MSC) |
为了探究SATCN模型在小样本数据集上建模效果, 从以下两个方面进行对比分析: 一是由于SATCN模型采用的自注意力残差结构, 选取具有残差结构的ResNet-13[8]、 TCN网络模型进行对比分析; 二是选取现有在小样本数据集上建模效果较好的VGGNet-7[8]网络结构进行对比分析。 为保证CNN、 TCN和SATCN模型之间有可比性, 设置固定的模型函数和超参数: 激活函数Relu, 优化器Nadam, Loss为均方误差(MSE), 批处理大小为64, 学习率为1× 10-4, epochs为600, 最后全连接层和Dropout层参数分别为200、 0.3、 100、 0.3、 1。
通过分析不同光谱预处理对模型精度影响, 证明平滑处理后的一阶微分变换为较好预处理方法。 在此基础上构建ResNet-13、 VGGNet-7、 TCN和SATCN模型进行对比实验, 实验结果如表3所示。 4种模型在数据集上R2> 0.91, RMSE< 4 g· kg-1, RPD> 3, 说明4种模型都具有很好的估测能力。 不同模型在数据集上预测指标如图8所示, 从图中来看, VGGNet-7在训练集和验证集上各项评价指标都是低于其他模型, 建模效果在四种模型是较差的, 原因可能是其他模型中的残差结构能够更好的提取数据集的主要特征。 从不同残差结构来看, ResNet-13模型精度和建模效果要低于TCN和SATCN, 原因是其拥有较深的网络结构, 导致模型的精度降低; TCN的残差结构中拥有膨胀卷积提高卷积核的感受野, 能够更好的对样本数据特征进行提取, 模型精度和性能都有所提升; SATCN模型预测精度最高为0.943, RPD大于4, 其他模型RPD大于3, SATCN模型预测精度和估测能力有明显提升, 说明残差结构加入自注意力机制, 强化重要特征, 提高特征学习能力和模型精度, 这也与石磊等[16]利用自注意力机制强化重要特征, 提高分类精度结论相似。
| 表3 不同模型土壤有机质估算模型精度 Table 3 Accuracy of soil organic matter estimation models |
 | 图8 不同模型在数据集上建模效果 (a): 训练集; (b): 验证集; (c): 不同的神经网络建模精度对比Fig.8 Modeling effects of different models based on the dataset (a): Training set; (b): Validation set; (c): Comparison of the accuracies of different neural networks |
为了进一步探讨在不同深度下SATCN模型的建模效果, 实验结果如表4所示。 不同网络深度下SATCN模型在数据集上建模效果如图9所示, 从图中可以发现, 模型在训练集上, 随着SATCN模型中残差块数量(1~4)增加, R2和RPD逐渐变小, RMSE逐渐增大, SATCN效果最好R2为0.967, RMSE为2.457 g· kg-1, RPD为5.291; 但在验证集上, R2和RPD逐渐变小, RMSE逐渐变大, SATCN效果最好R2为0.943, RMSE为3.042 g· kg-1, RPD为4.273。 说明随着SATCN模型网络层次加深, 模型的精度和稳定性逐渐降低。 SOM含量在验证集上实测值与估测值比较如图10所示, 图中可以看出大部分样本估测值都均匀的分布在1:1线附近。
| 表4 不同模型土壤有机质估算模型精度 Table 4 Model accuracies of soil organic matter estimation by different models |
 | 图9 不同网络深度下SATCN模型在数据集上建模效果 (a): 训练集; (b): 验证集; (c): 模型精度对比Fig.9 Effectiveness of SATCN modeling on datasets with different network depths (a): Training set; (b): Validation set; (c): Accuracy comparison |
 | 图10 基于SATCN模型的验证集SOM含量实测值与估测值比较Fig.10 Comparison of the measured and estimated SOM contents of the validation set based on SATCN model |
综合以上方法的建模预测结果可以发现, 部分光谱预处理方法能够提高模型精度, 尤其是1DR光谱预处理建模效果较好。 采用自注意力残差结构的SATCN模型, 比现有小样本数据集上建模效果较好的VGGNet-7模型建模精度提高了2.8%。 相比于具有残差结构的ResNet-13和TCN模型, 其建模精度分别提高2.9%和1.7%。 综合来看, 本研究区SPXY样本集划分方法结合1DR光谱预处理方法建立的土壤SOM含量SATCN模型结果最优。
本工作构建SATCN模型的土壤高光谱预测模型, 未考虑其他环境因素, 仅利用光谱反射率数据预测土壤SOM含量, 结果证明SATCN模型建模精度较高、 建模效果较理想。 在实际应用过程中可以不考虑环境条件, 采用SATCN模型建模, 能够有效减少工作量。 由于本研究区为两个国有林场, 该模型具有一定的适应性, 但是对不同地区、 不同土壤类型采用SATCN模型预测土壤属性, 其适应性需要进一步验证。
从广西国有黄冕林场和国雅长林场采集了206个土壤样品, 对土样数据进行不同的预处理, 对比分析PLSR、 SVM和LSTM三种模型在不同光谱预处理下建模效果, 确定较好的光谱预处理方法。 在此基础上构建一种改进时间卷积网络的红壤有机质高光谱预测模型。 该研究的结论可以归纳为以下几点:
(1) 对比其他光谱预处理方法, 采用SG平滑处理后一阶微分变换, LSTM、 PLSR和SVM三种模型R2分别提高6.3%~13.8%、 9%~27.5%和10.5%~23.6%, 说明1DR是较好的光谱预处理方法, 部分非线性模型建模效果要优于线性模型。
(2) 在不同网络对比中, SATCN模型比VGGNet-7、 ResNet-13和TCN模型, 验证集上模型R2分别提高了2.8%、 2.9%和1.7%; RMSE分别降低了0.698、 0.718和0.448; RPD分别提高了0.759、 0.816和0.548; 说明SATCN网络模型能够强化光谱序列重要特征, 提高模型特征学习能力, 模型精度也得到提高。 但是随着SATCN模型中残差块数量增加, 模型精度和稳定性下降, 因此, 浅层SATCN模型建模效果要优于深层模型。
(3) 相比于CNN、 TCN等建模方法, SATCN模型建模效果最好, 拥有更高的精确度和极好的模型估测能力, 验证集的决定系数(R2)为0.943, 均方根误差(RMSE)为3.042 g· kg-1, 相对分析误差(RPD)为4.273。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|