



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合ConvLSTM和多注意力机制网络的高光谱图像分类
[唐婷 , 潘新
, 潘新* , 罗小玲, 郜晓晶]
, 潘新, 罗小玲, 郜晓晶]
|
|


作者简介: 唐 婷, 女, 1994年生, 内蒙古农业大学计算机与信息工程学院硕士研究生 e-mail: tangting0915@126.com
近年来, 基于深度学习的模型在高光谱图像(HSI)分类方面效果显著。 针对小样本数据基于深度学习的高光谱图像分类方法分类精度不高的问题, 提出一种融合卷积长短期记忆(ConvLSTM)和多注意力机制网络的高光谱图像分类方法。 该方法分三个分支: 光谱分支、 空间 X分支和空间 Y分支分别提取光谱特征、 空间 X特征和空间 Y特征, 并将三个方向的特征融合进行高光谱图像分类。 由于ConvLSTM在学习有价值的特征和对光谱数据中的长期依赖关系建模方面表现出良好的性能, 所以在光谱分支中用了3个隐藏层、 卷积核大小为3×3、 通道分别为150、 100和60提取光谱信息。 在空间 X分支和空间 Y分支, 采用基于DenseNet和3D-CNN的Dense空间 X块和Dense空间 Y块分别提取空间 X特征和空间 Y特征。 为了增强特征提取, 在这三个分支中还分别引入了其特征方向的注意力机制, 针对信息丰富的光谱波段设计了光谱注意块, 信息丰富的像素点分别设计了空间 X和空间 Y注意块。 在三个公开的高光谱数据集上进行了实验, 即Indian Pines(IP)、 Pavia University(UP)和Salinas Valley(SV)数据集; 并对比了其他五种方法: 基于RBF径向核的支持向量机模型(SVM)、 更深更广的卷积神经网络模型(CDCNN)、 快速密集光谱-空间卷积网络模型(FDSSC)、 空谱残差网络模型(SSRN)、 双分支双注意力机制网络模型(DBDA)。 实验中, IP数据集上训练样本和验证样本的大小设为总样本的3%, UP和SV数据集上训练样本和验证样本的大小设为总样本的0.5%。 该方法和所有基于深度学习的方法, 批处理大小均设置为16, 优化器设为Adam, 学习率设置为0.000 5, 并动态调整学习率。 由于SVM直接利用光谱信息进行分类, 输入样本块像素大小为1×1, 其他基于深度学习方法的输入样本块像素均设置为9×9。 实验结果表明, 该方法能充分利用高光谱图像的光谱和空间特征, 在OA、 AA、 KAPPA等评价标准上均获得了更好的效果, 其中, 该方法的OA指标比次优的算法平均提高0.12%~2.04%。
In recent years, deep learning-based models have achieved remarkable results in the hyperspectral image (HSI) classification. Aiming at the low classification accuracy of deep learning-based HSI classification methods under limited sample data, this paper proposes an HSI classification method that combines ConvLSTM and a multi-attention mechanism network. The method is divided into three branches: spectral branch, spatial- X branch and spatial- Y branch to extract spectral features, spatial- X features and spatial- Y features respectively, and fuse the features in three directions for hyperspectral image classification. Since convolutional long short-term memory (ConvLSTM) shows good performance in learning valuable features and modeling long-term dependencies in spectral data, 3 hidden layers are used in the spectral branch, and the convolution kernel size is 3×3, the channels are 150, 100 and 60, respectively, to extract spectral information. On the spatial- X and spatial-Y branches, Dense spatial- X blocks and Dense spatial- Y blocks based on DenseNet and 3D-CNN are used to extract spatial- X and spatial- Y features, respectively. In order to enhance feature extraction, the attention mechanism of its feature direction is also introduced in these three branches, respectively. The spectral attention blocks are designed for the information-rich spectral bands, and a spatial- X attention block and a spatial- Y attention block are designed for the information-rich pixels, respectively. Experiments were conducted on three publicly available hyperspectral datasets, namely Indian Pines (IP), Pavia University (UP) and Salinas Valley (SV) datasets, and compared with five other methods: the SVM with RBF kernel (SVM), Going Deeper with Contextual CNN (CDCNN), Fast Dense Spectral-Spatial Convolution (FDSSC), Spectral-Spatial Residual Network (SSRN), Double-Branch Dual-Attention Mechanism Network (DBDA). In the experiments, the size of training and validation samples is set to 3% of the total samples on the IP dataset, and 0.5% of the total samples on the UP and SV datasets. For our method and all deep learning-based methods, the batch size is set to 16, the optimizer is set to Adam, the learning rate is set to 0.000 5, and the learning rate is dynamically adjusted. Since SVM directly uses spectral information for classification, the pixel size of the input sample block is 1×1, and the pixels of other input sample blocks based on deep learning methods are all set to 9×9. The experimental results show that the method in this paper can fully use the spectral and spatial characteristics of HSI, and achieve better results in the evaluation criteria such as OA, AA, and KAPPA. Among them, the OA index of the method in this paper is improved by 0.12%~2.04% on average compared with the suboptimal algorithm.
高光谱图像(hyperspectral image, HSI)中包含丰富的光谱和空间信息, 具有图谱合一且波段覆盖范围广的特性。 因此, 高光谱遥感对地观测技术被广泛的应用在很多不同的领域[1]。 然而, 由于HSI的复杂性和标记样本的稀缺性, 使得HSI的分类面临着一系列挑战。 如何高效的对小样本的HSI进行分类成为了研究重点。
早期的HSI分类一般采用传统机器学习的方法, 比如支持向量机(SVM)[2]等。 一般来说, 传统的方法仅利用了光谱特征, 由于外部环境的影响, 相同的地物可能会呈现出不同的光谱曲线, 不同的地物也可能表现出相同的光谱曲线, 即所谓的同物异谱、 异物同谱现象。
近年来, HSI分类方法引入了HSI的空间信息, 基于深度学习的HSI分类方法[3]也受到了广大学者的研究, 并取得了显著的成效。 卷积神经网络(CNN)是深度学习的一个重要分支, 已被广泛的应用于高光谱图像特征提取和分类[4]。 Chen等[5] 提出了三维卷积神经网络(3D-CNN)特征提取模型, 直接用高光谱图像端到端地提取光谱空间特征, 相比于2D-CNN提取的特征有着更高的类间可区分性, 从而有更好的分类效果。 Lee等[6]提出了一种具有更深更广网络(CDCNN)算法模型, 通过利用局部光谱-空间特征来预测每个像素的标签。 残差网络(ResNet)[7]和密集网络(DenseNet)[8]的出现解决了因网络加深带来的网络退化问题。 受ResNet的启发, Zhong等[9]提出了空谱残差网络(spectral-spatial residual network, SSRN), 连续利用光谱残差网络模块和空间残差网络模块对光谱和空间进行特征提取进而分类。 Wang等[10]提出了一种用于高光谱图像分类的端到端快速密集光谱-空间卷积(fast dense spectral-spatial convolution, FDSSC)网络模型, 通过构建密集光谱块和密集空间块自动提取HSI中丰富的光谱和空间特征。 受双分支多注意力机制(double-branch multi-attention mechanism network, DBMA)[11]的启发, Li等[12]提出一种用于HSI分类的双分支双注意力机制网络(double-branch dual-attention mechanism network, DBDA), 使用两个分支分别提取光谱和空间特征, 并在这两个分支上分别应用了两种类型的注意力机制, 然后将这两个分支提取到的光谱和空间特征融合进行分类。
长短期记忆网络(long short-term memory, LSTM)在处理大量计算机视觉任务中的长序列依赖方面具有明显优势, 尤其在自然语言处理方面应用广泛。 由于HSI是从整个光谱中集中采样的, 因此各种光谱带之间具有依赖关系。 Ienco等[13]提出了一种基于LSTM的模型来执行多时卫星图像的分类任务。 然而, LSTM在处理光谱-空间和空间-时间数据时具有局限性, 因为它需要将输入数据转换为一维形式, 这可能会导致基本空间信息的丢失。 为了克服LSTM的局限性, Shi等[14]用多维处理替换了LSTM中每个门的一维数据操作, 并引入卷积长短期记忆(convolutional long short-term memory, ConvLSTM)。 在ConvLSTM中, 2D和3D卷积滤波器可分别用于构造ConvLSTM2D和ConvLSTM3D。
由于目标在经过3D-CNN提取特征过程中, 像素特征之间被分配的权重是相同的, 不能有效地区分不同特征之间的重要程度, 从而降低了分类准确率。 为了解决以上问题, 引入了注意力机制[15]。 它可以在特征学习过程中, 选择性学习高光谱图像中的特征, 从众多信息中选择出对当前任务更关键的信息, 对不同特征分配不同的权重, 从而让分类效果更好。
本文提出一种融合ConvLSTM和注意力机制网络的高光谱图像分类算法。 该网络包括光谱、 空间X和空间Y三个分支, 并在三个分支上分别应用了光谱注意力机制、 空间X注意力机制和空间Y注意力机制来强化特征提取。 最后采用三个分支的融合运算进行HSI分类。 由于HSI是一个结合了光谱和空间信息的3D数据立方体, 其中空间分辨率与光谱分辨率相比较浅。 它只能提供关于图像像素之间几何关系的较少细节。 因此, 光谱信息对于准确识别地物的种类更为重要。 而各种光谱带之间具有依赖关系, 所以在光谱分支应用了ConvLSTM来提取特征。 在空间X和空间Y分支分别应用了基于DenseNet和3D-CNN的Dense空间X块和Dense空间Y块来特取特征。 实验结果表明, 相比于其他5种经典的算法, 本方法对小样本HSI分类更有效。
1.1.1 LSTM
相比一般的神经网络来说, 递归神经网络(recurrent neural network, RNN)是一种用于处理序列数据的神经网络。 然而, RNN不能解决长序列训练过程中的梯度消失和梯度爆炸问题。 LSTM是一种特殊的RNN, 相比普通的RNN, LSTM能够解决梯度消失和梯度爆炸问题, 以及更好的预测序列数据。 LSTM通过一个记忆单元替换了一个循环隐藏节点, 起到了状态信息累加器的作用。 各种自定参数的控制门可以从该单元中检索、 更新和清除数据。 使用门和存储单元的主要优点之一是它们允许调节信息流, 使梯度可以跨越多个时间步长而不会爆炸或消失。
LSTM最重要的概念就是三个门: 输入门it、 遗忘门ft、 输出门ot; 以及两个记忆: 长记忆ct、 短记忆ht。
式(1)中, σ 和tanh是激活函数, xt为输入, ht-1为输出。 Wi、 Wf、 Wo和Wc, 分别表示输入门、 遗忘门、 输出门和长记忆的权重, bi、 bf、 bo和bc表示偏置。
1.1.2 ConvLSTM
ConvLSTM是LSTM的一种变体, 为了构建时空序列预测模型, 同时掌握时间和空间信息, ConvLSTM将LSTM中的全连接权重改为卷积, 也就是矩阵乘法变成了卷积计算。 在ConvLSTM中, 输入到状态和状态到状态的转换是利用卷积运算来执行的。 在LSTM单元的每个门处, 矩阵乘法被卷积运算代替。 这样, 通过在多维数据中进行卷积操作来捕获基础空间特征。 ConvLSTM和LSTM之间的主要区别在于输入维数。 由于LSTM输入数据是序列, 因此不适用于空间加序列数据, 例如卫星、 雷达图像数据集, ConvLSTM更适用于图像类数据作为其输入。
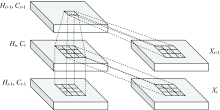
ConvLSTM的内部结构如图1所示。 其中X1, …, Xt为输入, C1, …, Ct为输出, H1, …, Ht为隐藏状态, 都是三维的数据tensor。 除了需要增加卷积运算之外, ConvLSTM的数学公式类似于式(1)中的LSTM。 ConvLSTM中完成数据处理和传输的三个门, 可以更好的利用HSI中的光谱信息。 与使用滑动窗口提取空间信息的 CNN相比, ConvLSTM除了实现层间处理外, 还实现了层内数据处理。
 | 图1 ConvLSTM内部结构图Fig.1 The inner structure of ConvLSTM |
1.1.3 注意力机制
注意力机制源于对人类视觉系统的研究[16]。 研究发现, 人类在感知事物的时候, 视觉系统会快速浏览全局画面, 然后根据需要有选择性地关注某一特定信息并集中关注它, 同时忽略其他无关紧要的信息。 不同的光谱波段和空间像元对提取特征的贡献是不同的, 将注意块应用于光谱和空间特征提取, 能够增强光谱和空间中重要信息的权重, 从而提高分类精度。
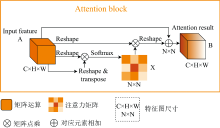
注意块的结构如图2所示。 图中注意力映射X∈ RN× N是直接从初始输入A∈ RC× H× W计算出来的, 其中C表示输入通道的数量, H× W是输入块的大小, N× N表示光谱或空间注意块(光谱注意块中N为C, 空间X注意块中N为H, 空间Y注意块中N为W)。 首先, 将A与AT进行矩阵乘法运算, 得到注意力映射X∈ RN× N, 将softmax层连接为
式(2)中, xji表示第i个通道对第j个通道的影响。 其次, 将XT与A的矩阵乘法结果变形成RC× H× W。 最后, 通过参数α 对重构后的结果进行加权, 并加上输入特征图A, 得到最终的注意力输出特征图B∈ RC× H× W
式(3)中, α 初始化为零, 可以逐步学习并分配更多的权重。 最终的注意力输出特征图B包含了所有特征的加权总和。
 | 图2 注意块结构图Fig.2 Structure of attention block |
本网络结构如图3所示。 本方法融合了ConvLSTM和注意力机制, 分三个分支: 光谱分支、 空间X分支和空间Y分支, 分别提取光谱特征图、 空间X特征图和空间Y特征图。 然后将三个特征图进行融合运算得到分类结果。
 | 图3 本网络结构图Fig.3 Structure of the proposed method |
本方法中使用了Mish激活函数, Mish是一个自正则化的非单调激活函数。 Mish具有无上界有下界的特点, 即正值可以达到任何高度, 避免了由于封顶而导致的饱和。 有轻微的负值允许更好的梯度流, 而不是像ReLU那样输入负数则完全不激活, 而且平滑的激活函数允许信息更好的输入神经网络, 从而得到更好的准确性和泛化性。
在空间X和空间Y分支中, 采用了基于DenseNet[8]和3D-CNN的Dense空间块来分别提取空间X和空间Y特征。 DenseNet是一种密集连接, 每个层都会接收其前面所有层作为其额外的输入。 DenseNet极大的减少了网络的参数量, 加强了特征在网络中的传播, 可以有效缓解梯度消失的问题。
以Indian Pines(IP)数据集为例, 输入样本块大小为9× 9× 200。 首先, 经过一个3D-CNN层和带Mish激活函数的BN层, 得到大小为(9× 9× 97, 24)的特征图。 9× 9× 97表示3D立方块的高度、 宽度和深度, 24表示时间序列。 然后将大小为(9× 9× 97, 24)的特征图分别输入到光谱分支、 空间X分支和空间Y分支。 在光谱分支中, 先将大小为(9× 9× 97, 24)的特征图变形为(97× 9× 9, 24), 然后经过3个隐藏层, 卷积核大小为3× 3, 通道分别为150、 100和60, 最终得到大小为9× 9× 60的特征图。 然后, 将特征图变形为(9× 9× 1, 60), 再输入到光谱注意块中以强化光谱特征。 注意块的详细介绍见1.1.3节。 最后, 采用BN层和Dropout层来提高稳定性和鲁棒性, 再通过全局平均池化层, 得到1× 60的特征图。
在空间X分支中, 首先经过一个Dense空间X块, 每个3D-CNN在Dense空间X块中有12个通道, 卷积核大小为3× 1× 1。 经过Dense空间X块后, 由式(2)计算得到特征图的通道增加到60条, 此时特征图的大小为(9× 9× 97, 60)。 然后, 用3D-CNN和带Mish激活函数的BN层将特征图变形为(9× 9× 1, 60), 再将变形后的特征图输入到空间X注意块, 以强化特征提取。 最后, 经过BN层、 Dropout层和全局平均池化层得到1× 60的特征图。
空间Y分支的特征提取过程与空间X分支类似, 区别之一是3D-CNN的卷积核大小不同, 在Dense空间Y块中, 卷积核大小为1× 3× 1。 此外, 在空间Y注意块中注意力映射也不同。
最后, 将得到的光谱特征图、 空间X特征图和空间Y特征图进行串联运算, 串联运算可以使光谱特征、 空间X特征和空间Y特征保持独立。 然后通过全连接层和softmax层得到分类结果。
选取3个公开的高光谱数据集进行实验, 即Indian Pines (IP)数据集、 Pavia University (UP)数据集和Salinas Valley (SV)数据集。
IP数据集是由AVIRIS传感器在印第安纳州拍摄, 数据有224个波段, 有效波段200个, 图像尺寸为145× 145像素, 共有16个地物类别。 UP数据集是由ROSIS获取, 数据有103个波段, 图像尺寸为610× 340像素, 共有9个地物类别。 SV数据集是由AVIRIS传感器在加州Salinas Valley拍摄, 数据有效波段为204个, 图像尺寸为512× 217像素, 共有16个地物类别。
实验对比了其他5种方法, 以验证本方法的有效性。 有基于深度学习的CDCNN[6]、 FDSSC[10]、 SSRN[9]和DBDA[12]方法, 还有基于RBF内核的SVM方法[2]。 所有实验都在配置了16GB内存和NVIDIA GeForce RTX 1080Ti GPU的同一平台上执行。 基于深度学习的方法用PyTorch实现, SVM方法用sklearn实现。
输入样本大小设置: 由于SVM方法直接利用光谱信息进行分类, 因此输入样本大小为1× 1× p, 为了更好的进行对比实验, 其他基于深度学习的方法使用相同的输入样本大小, 即9× 9× p, 其中p为光谱带的数量。
实验中所有基于深度学习的方法以及本方法, 批处理大小设置为16, 优化器设为Adam, 学习率设置为0.000 5, 并动态调整学习率。 每种方法独立进行10次迭代, 实验结果取10次迭代结果的平均值。 epoch的总数设置为150, 每个epoch的步长为30。 在训练过程中, 选择验证集上准确率最高的模型作为输出, 如果在验证集上的准确率一致, 则选择在验证集上损失最小的模型输出。 每次迭代保存最好的模型, 如果下次迭代的模型更好, 则替换上一次保存的模型, 否则不替换。
训练样本和验证样本的大小被设定在较小的水平。 对于IP数据集, 选择3%的样本进行训练, 3%的样本进行验证。 对于UP和SV数据集, 选择0.5%的样本进行训练, 0.5%的样本进行验证。 这样选择的原因是, 实验结果的区分度最大。 如果都选择最少的或者最多的训练样本比例, 实验结果的偶然性较大, 区分度不大。
在IP数据集中, 有效样本的总数为10 249个, 训练集和验证集的大小均为307个, 分别占总样本的3%, 测试样本为9 635个。
IP数据集的分类结果如表1所示, 分类图见图4。 实验结果表明, 本方法在OA和Kappa指标上均取得了最好的分类精度, OA为93.54%, AA为91.01%, Kappa为0.926 4。 CDCNN方法准确率最低, OA仅达到了64.21%, 因为CDCNN方法只注重了二维空间信息, 忽视了光谱信息。 其次分类效果比较差的是基于RBF的SVM方法, OA为68.75%, 因为其方法仅利用了光谱信息。
| 表1 使用3%训练样本的IP数据集的分类结果 Table 1 Classification results by using 3% of the training samples for IP dataset |
 | 图4 使用3%训练样本的IP数据集的各个方法分类图 (a): 伪彩图; (b): 对应标签; (c): SVM (68.75%); (d): CDCNN (64.21%); (e): FDSSC (92.85%); (f): SSRN (91.59%); (g): DBDA (91.32%); (h): 本方法 (93.54%)Fig.4 Classification results of each method using 3% training samples for IP dataset (a): Origin image; (b): Ground truth; (c): SVM (68.75%); (d): CDCNN (64.21%); (e): FDSSC (92.85%); (f): SSRN (91.59%); (g): DBDA (91.32%); (h): Proposed method(93.54%) |
在UP数据集中, 有效样本的总数为42 776个, 训练集和验证集的个数均为210个, 分别占总样本的0.5%, 测试样本大小为42 356个。
UP数据集的分类结果如表2所示, 分类图见图5。 实验结果表明, 本方法在三个指标上均取得了最佳的分类结果, OA为95.60%, AA为94.22%, Kappa为0.941 5, OA比DBDA高出4.81%。 DBDA由于将光谱和空间分成了两个分支, 这个方法默认将二维空间信息看成一个特征向量, 则忽视了三维空间的三维六向的特点, 从而没有充分考虑到三维空间的特性。
| 表2 使用0.5%训练样本的UP数据集的分类结果 Table 2 Classification results by using 0.5% of the training samples for UP dataset |
 | 图5 使用0.5%训练样本的UP数据集的各个方法分类图 (a): 伪彩图; (b): 对应标签; (c): SVM (83.75%); (d): CDCNN (82.53%); (e): FDSSC (93.56%); (f): SSRN (91.94%); (g): DBDA (90.79%); (h): 本方法 (95.60%)Fig.5 Classification results of each method using 0.5% of training samples for UP dataset (a): Origin image; (b): Ground truth; (c): SVM (83.75%); (d): CDCNN (82.53%); (e): FDSSC (93.56%); (f): SSRN (91.94%); (g): DBDA (90.79%); (h): Proposed method(95.60%) |
在SV数据集中, 有效样本的总数为54 129个, 训练集和验证集个数均为263个, 分别占总样本的0.5%, 测试样本大小为53 603个。
SV数据集的分类结果如表3所示, 分类图见图6。 实验结果显示, 本方法在OA和Kappa指标上均取得了最好的分类结果, OA为96.02%, AA为97.49%, Kappa为0.955 6。 其次, 分类效果比较好的是FDSSC方法, 其方法在AA上取得了最好的分类精度, AA为97.89%, OA为95.90%, OA比SSRN提高了3.22%, 因为FDSSC采用密集连接代替剩余连接, 提高了网络的性能。 本方法虽然有些类别上的分类精度比不上FDSSC, 但OA比FDSSC高。
| 表3 使用0.5%训练样本的SV数据集的分类结果 Table 3 Classifiction results using 0.5% of the training samples for SV dataset |
 | 图6 使用0.5%训练样本的SV数据集的各个方法分类图 (a): 伪彩图; (b): 对应标签; (c): SVM (87.15%); (d): CDCNN (76.25%); (e): FDSSC (95.90%); (f): SSRN (92.68%); (g): DBDA (94.72%); (h): 本方法 (96.02%)Fig.6 Classification results of each method using 0.5% training samples for SV dataset (a): Origin image; (b): Ground truth; (c): SVM (87.15%); (d): CDCNN (76.25%); (e): FDSSC (95.90%); (f): SSRN (92.68%); (g): DBDA (94.72%); (h): Proposed method(96.02%) |
提出了一种融合ConvLSTM和注意力机制的高光谱图像分类算法, 该算法由3个分支组成, 即光谱分支、 空间X分支和空间Y分支。 光谱分支由ConvLSTM和光谱注意块组成。 空间X分支和空间Y分支由Dense空间块和空间注意块组成。 采用三个分支的融合运算进行分类。 ConvLSTM在处理计算机视觉任务中的长序列依赖关系方面效果较好, 由于各种光谱带之间具有依赖关系, 在光谱分支中使用ConvLSTM能够更好的利用HSI中光谱信息。 在空间X和空间Y分支中, 采用基于DenseNet和3D-CNN的Dense空间块来分别提取空间X和空间Y特征。 Dense空间块加强了空间特征在网络中的传播, 有效缓解了梯度消失的问题, 可以更好的提取HSI中的空间信息。 并且本算法结合了注意力机制, 通过改变原始特征的权重, 强化核心贡献弱化次要贡献, 有效提升了高光谱图像的分类精度。 在3个公开的高光谱数据集Indian Pines、 Pavia University和Salinas Valley数据集上, 对比其他5种主流的分类效果比较好的方法, 本方法均取得了更好的分类精度, 尤其是在训练样本非常有限的情况下。
未来的工作方向是将所提方法应用于实际的工程应用中去, 发现和解决实际应用中可能会面临的问题。 此外, 缩短训练时间以及在边缘服务器上进行优化部署也是一个极具吸引力的挑战。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|