






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱-图像特征融合的玉米品种精确识别
[杨冬风1  , 胡军
, 胡军2, * ]
, 胡军]
|
|


作者简介: 杨冬风, 女, 1977年生, 黑龙江八一农垦大学信息与电气工程学院副教授 e-mail: yangsansun@sina.com
近红外光谱(NIRS)技术在作物种子品种鉴别上具有一定的可行性, 但如果待测种子的存储时间不同, 识别模型的准确性会受到影响。 为了降低存储时间对识别模型的影响、 提高模型的预测能力, 将NIRS技术与图像处理技术相融合, 提取出与品种生理生化指标相关的光谱特征和与品种相关的表观图像特征。 为了提取出最优的光谱特征, 首先提出一种改进的后向间隔偏最小二乘(IM_BiPLS)光谱区间选择算法。 针对BiPLS分段数难以确定的问题, 让分段数在一定范围内变化, 以每个分段数所取得的组合区间建立模型的相关系数和交叉验证均方根误差之比作为评价指标, 该指标最大时的分段数所对应的波段组合为最优。 然后使用竞争自适应重加权法(CARS)去除IM_BiPLS所选波段中的无信息变量和共线性变量实现光谱特征优选。 为了提取与品种相关的表观图像特征, 首先使用基于最大熵和双重区域标记的图像分割算法完成不感兴趣区域去除和单粒种子图像分割; 然后提取单粒种子的形态、 纹理和颜色特征并计算出每个图像样本所有种子的统计平均特征。 最后使用CARS对这些特征进行深层次优选完成图像特征提取。 以10个黄色玉米品种为研究对象, 采集216个样本的NIRS数据和对应的图像。 针对光谱数据, 使用IM_BiPLS算法从全谱1 845个变量中选出了具有736个变量的波段组合, 使用CARS进一步从中优选出光谱变量29个。 针对图像数据, 提取出图像特征29个, 使用CARS进一步优选出图像特征11个。 分别以IM_BiPLS提取的光谱特征波段、 IM_BiPLS-CARS优选的特征波长、 图像特征(Image)、 CARS提取的图像特征(Image-CARS)以及IM_BiPLS-CARS优选的特征波长融合CARS提取的图像特征(Compound)为输入, 以样本对应的类别为输出, 建立BP神经网络模型。 测试结果表明Compound-BP模型的性能最佳, 训练准确率和验证准确率均为100%, 测试准确率为97.7%。 实验结果说明NIRS特征融合图像特征可以有效地提高识别模型的精度, 降低存储时间对模型的影响, 为实现玉米种子品种的无损、 快速、 精确识别提供参考。
Near-infrared spectroscopy (NIRS) technology has certain feasibility in identifying crop seed varieties, but if the storage time of the seeds to be tested is different, the accuracy of the identification model will be affected. In order to reduce the influence of storage time on the recognition model and improve the model's prediction ability, NIRS technology and image processing technology are combined to extract spectral features related to physiological and biochemical indicators of varieties and apparent image features related to varieties. In order to extract the optimal spectral features, an improved backward interval partial least squares (IM_BiPLS) spectral interval selection algorithm is proposed. Aiming at the problem that it is difficult to determine the number of segments of BiPLS, the algorithm changes the number of segments within a certain range and takes the ratio of the correlation coefficient of the model established by the combination interval obtained by each segment number and the root mean square error of cross-validation as the evaluation index. When the index is maximum, the band combination corresponding to the segment number is the best. The competitive adaptive reweighting method (CARS) removes the uninformative and collinear variables in the selected band of IM_BiPLS and further optimises the spectral features. In order to extract the apparent image features related to varieties, firstly, the image segmentation algorithm based on maximum entropy and double region marking is used to remove the regions of interest and segment the single seed image. Then a single seed's morphological, texture and color features are extracted, and the statistical average features of all seeds in each image sample are calculated. Finally, CARS are used to optimize these features to complete image feature extraction. Taking 10 yellow maize varieties as the research object, NIRS data and corresponding images of 216 samples were collected. For spectral data, use IM_BiPLS algorithm selects the band combination with 736 variables from 1845 variables in the full spectrum and uses CARS to optimize 29 spectral variables further; For image data, 29 image features are extracted, and 11 image features are further optimized by CARS. Respectively using the spectral feature band extracted by IM_BiPLS, the preferred feature wavelength extracted by IM_BiPLS_CARS, the image feature(image), the image feature extracted by CARS(image_CARS), and the fusion between IM_BiPLS_CARS and image_CARS(compound) as the input and the corresponding category of the sample as the output to set up BP neural network models. The test results show that the performance of the compound BP model is the best, the training accuracy and verification accuracy are 100%, and the test accuracy is 97.7%. The experimental results demonstrate that the fusion of NIRS features with image features can effectively improve the accuracy of the recognition model and reduce the impact of storage time on the model. This provide a reference method for achieving the non-destructive, rapid and accurate recognition of corn seed varieties.
品种是粮食生产的第一要素, 优良品种与普通品种的品质差异较大。 为了获取超额利润, 种子生产和流通过程中侵权套牌、 制售假劣的现象层出不穷, 影响农业生产、 损害种植者的利益、 威胁国家粮食安全。 玉米是我国种植面积最大和总产量最高的粮食作物, 是重要的饲料及工业原料, 玉米品种的精确识别是规范玉米种子市场、 保证玉米种子品质及相关产业健康发展的重要手段。 种子品种识别的方法主要有形态学方法、 荧光扫描鉴定法、 化学鉴定法、 电泳鉴定法和DNA分子标记法[1]。 形态学方法受专业人员主观影响大、 精度不高。 其他几种方法识别精度高, 但所需的时间较长, 需要用到各种分析仪器、 过程复杂、 非专业人员难以完成, 且均是有损检测。 近红外光谱(near infrared spectroscopy, NIRS)技术是一种无损、 快速的检测方法, 广泛应用于农作物种子质量检测上。 同一作物不同品种的种子之间存在着一定的理化差异, 可以通过NIRS反映出来, 因此一些学者采用NIRS鉴别种子品种[2, 3]。 这些研究表明NIRS在种子品种识别方面具有一定的可行性, 但是这些研究没有考虑到种子理化指标随存储时间的变化情况。 有报道研究了存储时间在玉米单籽粒近红外光谱真实性鉴定中对检测结果的影响。 研究结果显示, 正确鉴定率均呈逐月下降的趋势。 同一品种的同一种子批, 由储藏开始建立的品种真实性鉴定模型已无法对存储11个月后的该种子批进行高准确度的鉴定。 通过扩充建模样本集来增强模型的鲁棒性, 将鉴别的准确率提高到了95.03%。 此研究揭示了NIRS在种子品种鉴别中的短板, 虽然通过扩充样本集在一定程度上提高了模型的准确性, 但整个建模过程, 需要逐月采集数据, 操作繁复, 工作量大。 图像分析技术因其操作简单、 设备易得、 快速高效在种子品种分类方面应用较多[4]。 其分类主要依据种子的表观特征, 在品种外观差异较大时识别准确, 但对于外观特征十分相似的品种分类准确率低。 高光谱技术由于其可同时获取样品的光谱和图像信息、 可以单独分析种子不同部位的特性被大量应用于种子品种鉴别[5]。 但其高分辨率和高维性导致的数据量庞大、 数据复杂度高、 分析困难, 加之设备昂贵等, 限制了其推广和应用。
本研究采用中等数据融合策略将NIRS与图像技术结合起来, 提取出与品种生化指标具有相关性的光谱特征和与种子品种相关联的表观特征, 将二者互补地融合起来, 增强信息的可靠性和可解释性, 然后以此融合特征为输入, 建立预测准确率高、 泛化性能好的预测模型。 为实现玉米种子多品种、 高效、 无损、 快速、 精确的识别, 提供新的思路和技术方法支持。
实验用近红外光谱采集设备为德国Bruker公司Tango近红外光谱仪, 采用积分球漫反射测量方式。 设定采集的分辨率为8 cm-1, 样品和背景的扫描时间均为32 s。 谱区范围11 550~3 950 cm-1, 每条光谱采集的数据点数为1 845个, 采样间距为4.119 cm-1。 采集图像的设备为vivo iQOO Z5手机, 分辨率为6 400万像素。
实验材料为10个不同品种的黄色玉米种子, 其中一部分是黑龙江八一农垦大学农学院培育的自交系品种, 一部分购自大庆市萨中种子公司。 为了获得不同存储时间的样本数据, 将每个品种的种子分为3组, 自采购之日起半年时间内, 每隔2个月采集一组光谱和图像数据, 总共采集3次。 样本采集前剔除损伤、 变色、 形状奇异的种子。 样本的详细信息如表1所示。
| 表1 实验样本信息表 Table 1 Sample information table |
实验用近红外光谱仪Tango采集颗粒状样本时, 要求样本的容量要达到量杯容量的2/3, 因此每个样本的种子数量以达到量杯的2/3为宜, 对种子的粒数没有限定。 将每个样本重复装样3次(每次装样都要将样本翻动摇匀), 每次测3条光谱取平均。 所有样本光谱采集的环境条件相同: 温度22 ℃, 相对湿度30%。 样本光谱数据采集之后, 平铺在黑色的衬垫上, 采集图像。 使用vivo iQOO Z5手机, 后置微距摄像头分辨率为200万像素, 焦距2.4 mm, 将手机固定于支架, 样本散铺在黑色的衬垫上, 相机距衬垫15 cm, 设置1倍焦距, 日光散射环境下拍摄, 种子之间互不接触为宜。 每个样本反复平铺3次, 采集3张图像, 与3条光谱数据相对应。 光谱分析、 图像分析和建模采用的软件主要使用挪威CAMO公司的UnscrambX10.3和美国MathWorks公司的Matlab R2020。
1.2.1 基于IM_BiPLS和CARS的特征波长提取
后向间隔偏最小二乘法(backward interval patrial least squares, BiPLS)是一种波长区间选择算法, 通过依次减少信息量最少或共线性变量最多的区间来获取最优区间组合。 具体步骤如下:
(1)将整个光谱区间划分为n个等宽波段。
(2)顺序从n段光谱中留出一段, 在剩下的n-1段上进行PLS回归, 建立n个子模型。
(3)用交叉验证均方根误差RMSECV值作为模型评价指标, 删除RMSECV值最小的子模型所对应的预留段, 并以该子模型为第一个基模型。
(4)在余下的n-1段光谱中再依次留出一段, 在剩下的n-2段上进行PLS建模, 可得到n-1个子模型, 删除最小的RMSECV值所对应子模型的预留段, 并取该子模型为第二个基模型。 重复上述过程, 直至剩余一个波段。
(5)比较所有基模型的RMSECV值, 最小值所对应的区间组合为最优组合。
本方法以PLS作为算法的基础, 算法的效率较高, 得到的模型精度也较高, 在光谱区间选择中应用较多[6, 7]。 其难点在于区间分段数目的确定, 分段数目的大小将直接影响模型的性能。 为了找到最佳的分段数目, 本研究对BiPLS算法进行了改进。
让光谱分段数目在一个合理的范围内变化, 对于某一个分段数, 采用BiPLS找到最优光谱区间组合并计算出该组合所建立模型的RMSECV和模型的相关系数r。 设E=r/RMSECV, 以E为评价指标, E值越大说明所取区间与因变量的相关性越好, 校正集预测值与真实值之间的误差越小。 计算出所有分段数对应的E值, 最大的E值所对应的光谱区间组合为最优区间组合。 把改进后的算法称为IM_BiPLS算法。
竞争自适应重加权法(competitive adaptive reweighted sampling, CARS)的基本思想是“ 适者生存” , 逐步淘汰“ 不适应” 的变量。 该算法一般采用蒙特卡罗采样, 从校正集样本中选出一部分进行PLS建模。 通过自适应加权采样和指数衰减函数去除PLS模型中回归系数绝对值(权重)较小的点, 保留权重较大的点作为新的子集, 然后基于新的子集建立PLS模型, 经过多次计算, 选择PLS模型RMSECV最小的子集中的波长作为特征波长。 CARS广泛应用于各种变量的选择, 在光谱分析中尤其受学者们青睐[8, 9]。
CARS方法既可以对无信息变量进行有效去除又可以实现共线性变量的有效压缩, 不过当待选波长数目较大时, CARS进行蒙特卡罗采样具有很大的随机性, 很难保证能够采集到所有的变量组合。 因此在CARS优选特征波长之前, 采用有效方法降低待选波长的维数十分必要。 将IM_BiPLS与CARS相结合, 在IM_BiPLS优选的波段范围内进一步实现无信息变量去除和共线性变量压缩, 以达到最终优选出针对预测目标最为关键变量的目的。
1.2.2 基于最大熵和双重区域标记的图像分割算法
图像分割是图像特征提取的基础, 图像分割方法很多, 每种方法都有各自的优劣, 适用的情况也不尽相同。 为了实现群体种子图像中每个种子区域的准确分割, 提出一种基于最大熵和双重区域标记的图像分割算法。
基于最大熵的图像二值分割本质上是基于阈值的图像分割, 当目标和背景的平均熵之和为最大时, 可以从图像中获得最大信息量, 以此时的分割阈值为最佳阈值[10]。
图像二值分割后, 得到所有种子的二值区域, 为了得到单粒种子的二值图像, 需要进行区域标记。 采用像素标记法进行区域标记, 将二值图像中所有的像素值为255的连通区域用编号标记出来。 除了种子区域, 图像中面积较小的杂质区域或滤波去除不掉的噪声区域也同样会作为区域被标记, 区域分割时会将它们也分割出来。 因此在分割出种子区域之前, 需要将这些区域去除。 采用双重区域标记的方法以达到去除这部分区域获取单粒种子区域的目的。 首先进行第一次区域标记, 计算每个标记区域的面积; 将面积小于某个阈值的区域标号记录下来, 使用函数去除这部分区域。 然后进行第二次区域标记, 以每个标记的区域为模板与原图按位相与, 就得到单粒种子的RGB图像, 为后续的单粒种子特征提取做准备。
10个品种的玉米种子样本共采集216条NIR光谱数据, 原始光谱如图1所示。
 | 图1 原始光谱Fig.1 Raw spectrum |
样本的测量光谱中除了包含真实信息还包括与仪器响应、 测试条件和光的散射等有关的背景信息。 这些信息导致了光谱噪声和基线漂移, 会对模型的预测性能和稳健性产生或大或小的影响。 因此, 在建立种子品种分类检测模型之前, 进行光谱预处理十分必要。 为了选择最适合的预处理方法, 首先使用高斯滤波(guassian filter, GS)、 卷积平滑(savitzky-golay, SG)平滑、 多元散射校正(multiplicative scatter correction, MSC)、 标准正态变量变换(standard normal variate, SNV)方法及其组合对原始光谱进行预处理。 然后使用Kennard-Stone(KS)法将预处理后的样本光谱按4:1:1划分为训练集、 验证集和测试集, 建立全谱BP预测模型, 根据模型性能确定模型所采用的预处理方法。 不同预处理方法建模的结果如表2所示。
| 表2 不同预处理方法的BP全谱模型建模结果 Table 2 Results of BP full spectrum prediction model with different pretreatment methods |
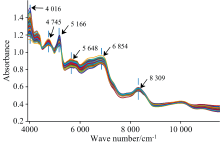
由表2可知, SG平滑消除随机噪声的效果较GS好, MSC消除样品颗粒大小和表面散射光的影响优于SNV, 组合预处理方法SG-MSC的模型表现最优, 训练集的准确率达到84.21%, 验证集的准确率达到81.25%, 测试集的准确率为78.13%。 组合预处理之后的光谱如图2所示, 与原始光谱相比吸光度范围减小, 吸收峰的位置更加清晰。 在波长4 016、 4 745、 5 166、 5 648、 6 854和8 309 cm-1处有6个的吸收峰。
 | 图2 SG-MSC预处理之后的光谱曲线Fig.2 Spectral curve after SG-MSG pretreatment |
对216个经过SG-MSC预处理之后的NIR光谱进行IM_BiPLS特征光谱区间选择, 自变量为216× 1 845的光谱矩阵, 因变量为216× 1的分类值矩阵(设10个品种玉米种子的类别值为1, 2, …, 10)。 将光谱区域分成n段, 令n从10变化到80, 为了提高算法效率, 让n的变化粒度为5, 即n=10, 15, 20, …, 75, 80。 以E=r/RMSECV作为评价指标, 当E最大时所对应的分段间隔为最优间隔, 所选出的区间组合为最优区间。 以n为自变量, r、 RMSECV、 E为因变量绘制模型性能随分段区间数变化曲线, 如图3所示。
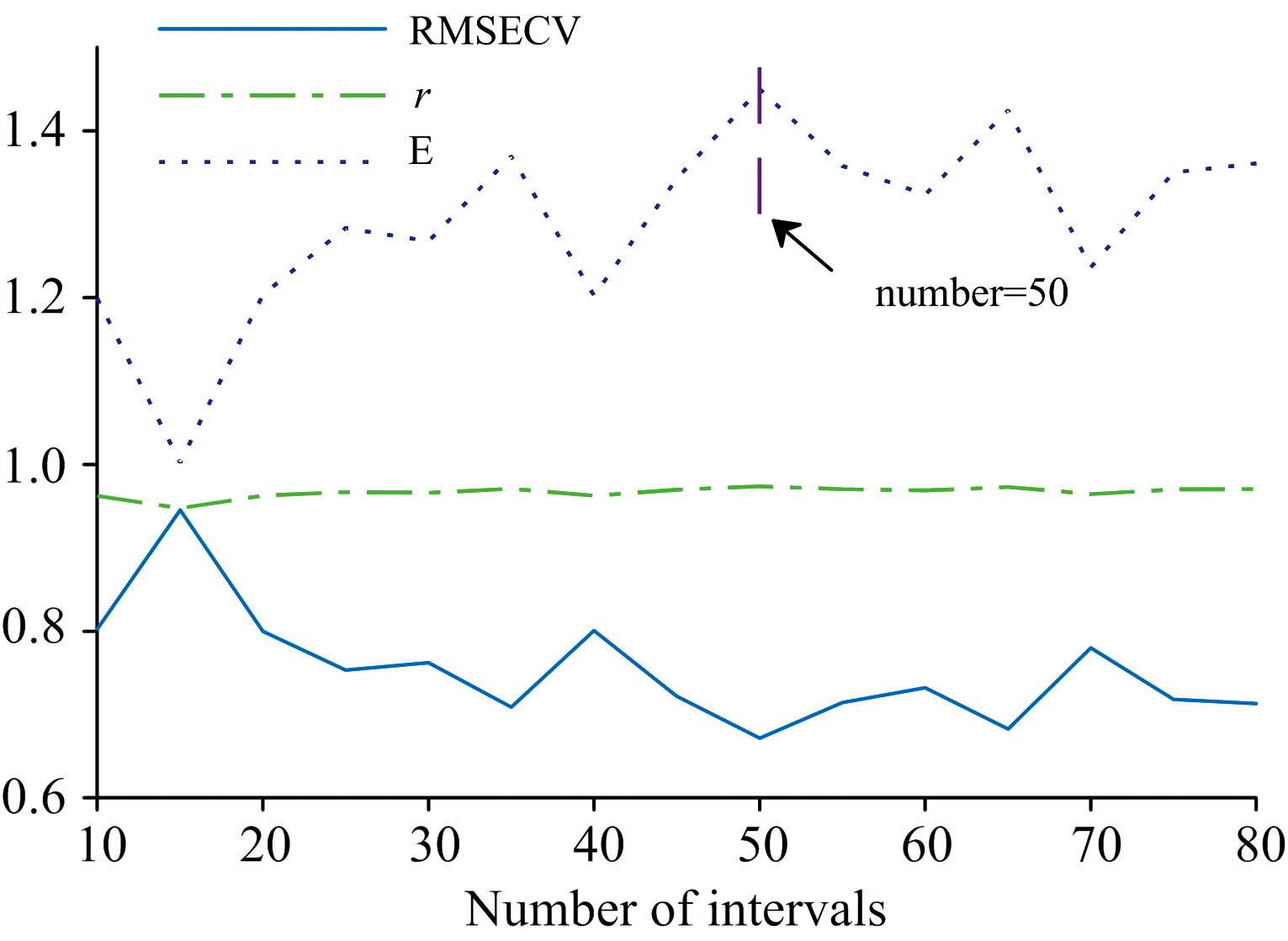 | 图3 IM_BiPLS分段数选择曲线Fig.3 Segment number selection curve of IM_BiPLS |
从图中可以看出, 当分段数为50时, 评价指标E达到最大值1.45。 区间选择的过程如表3所示。
| 表3 分段数为50时BiPLS区间选择过程 Table 3 Bipls interval selection process when the number of segment is 50 |
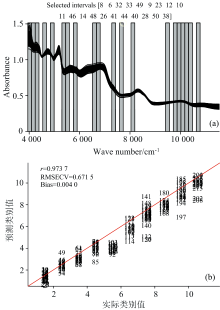
当剔除第29个区间后, 剩余区间组合的RMSECV达到最小值0.669 8, 此时优选出的间隔号组合为[8 6 32 33 49 9 23 12 10 11 46 14 48 26 41 44 40 28 50 38], 优选出变量数736个。 所选区间对应波段如图4(a)所示, 使用此波段组合建立PLS预测模型的预测结果如图4(b)所示。
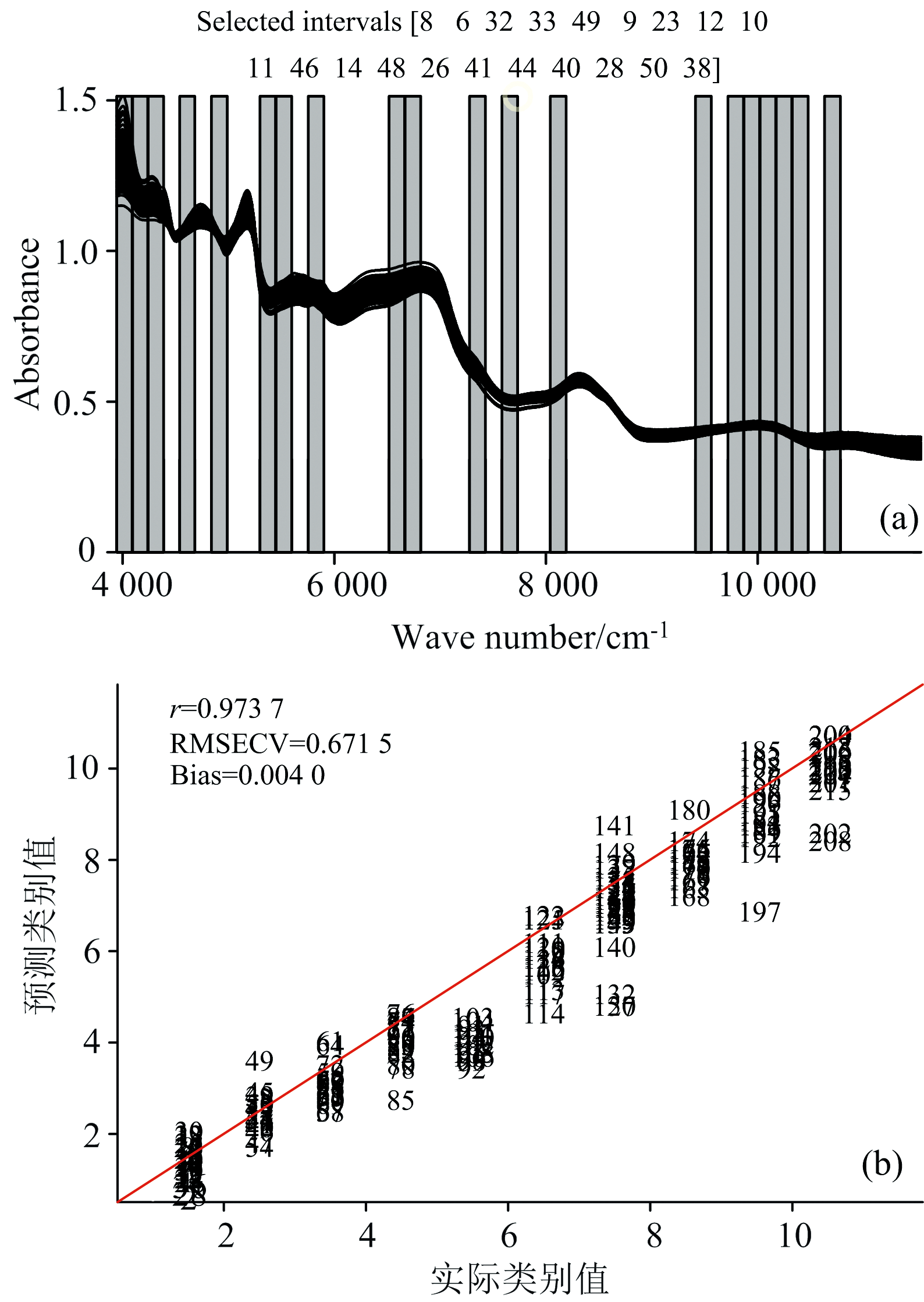 | 图4 分段数为50时IM_BiPLS所选区间(a)及PLS预测的结果(b)Fig.4 Selected sections (a) by IM_BiPLS when the number of segment is 50 and results of PLS prediction (b) |
不同玉米品种的蛋白质含量、 脂肪含量、 碳水化合物等含量具有品种间差异, 可以通过这些有机成分的C— H、 N— H和O— H等含氢基团的吸收强度差异体现出来。 如图4(a)所示, 48、 49、 50三个间隔对应的波长在4 000~4 387 cm-1, 46对应的是4 531~4 684 cm-1, 44对应的是4 836~4 984 cm-1, 这部分波长对应脂肪的C— H键第一组合频和蛋白质中氨基酸亚甲基一级倍频的吸收范围; 40、 41对应的是5 293~5 590 cm-1, 38对应的是5 742~5 895 cm-1, 这部分波长对应玉米蛋白质N— H基团及淀粉O— H基团的合频吸收范围; 32、 33对应的是6 508~6 817 cm-1, 这部分波长对应玉米蛋白质N— H键伸缩振动的一级倍频; 28、 26对应的是7 279~7 423和7 575~7 732 cm-1, 这部分波长对应脂肪C— H键第二组合频吸收区域; 14对应的是9 408~9 557 cm-1, 蛋白质中氨基酸亚甲基组合频对应的吸收波段; 8— 12对应的是9 713~10 470 cm-1, 这部分波长对应淀粉甲基C— H基团三级倍频及组合频的吸收谱带。 水分子O— H键的两个特征谱带(组合频5 154 cm-1和伸缩振动的一级倍频6 944 cm-1)都被排除在特征波段之外, 分析认为种子的水分含量不仅不是品种的显著性标志而且是干扰因素。 区间6所对应的是10 630~10 780 cm-1, 是蛋白质中氨基酸亚甲基C— H键三级倍频的吸收波段。
综上所述, IM_BiPLS优选得到的特征波长分布与玉米种子生化物质构成有着高度的一致性, 具有明显的物理意义, 可以体现不同玉米品种之间的生化差异, 实现光谱数据的大幅度降维, 是一种有效的基于变量区间的光谱特征变量选择方法。
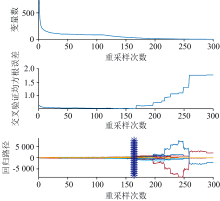
IM_BiPLS优选出了由736个变量构成的特征波段组合, 其中仍然包含一些无信息变量和一些共线性变量。 一方面, 这些变量会增加模型输入维度, 加大模型训练时间。 另一方面, 无信息变量对光谱分析没有积极作用, 会降低模型的预测精度; 共线性会影响模型的稳定性。 采用CARS对IM_BiPLS优选出的波段进行特征波长优选。 设置CARS的采样次数为300, 交叉验证的折数为10折, 重采样率设为0.8。 变量的选择过程如图5所示。
 | 图5 CARS变量选择过程Fig.5 CARS variable selection process |
当迭代次数为164时, 取得最小RMSECV值为0.510 8, 优选出变量29个。 在IM_BiPLS优选出的波段重构曲线上显示出这29个变量的位置, 如图6所示。
 | 图6 CARS选出的特征波长Fig.6 Characteristic wavelength selected by CARS |
经过CARS特征优选, 从736个波长中优选出29个特征波长, 去除了无信息变量和冗余变量, 极大地降低了模型输入的维数。 从图6可以看出, CARS几乎从IM_BiPLS所选出的20个区间的每个区间中都提取到了1特征波长, 个别区间提取2~3个特征波长, 也反过来验证了IM_BiPLS所选区间的正确性。
为了最大化地保留种子图像的有用信息, 采用最大熵法对原始图像进行二值分割。 以J(1)(自交系565的第一个样本)样本为例, 样本的原始图像和分割后的图像如图7所示。
 | 图7 原始图像(a)和最大熵二值分割图像(b)Fig.7 Original image (a) and maximum entropy binary segmentation image (b) |
从图7中可以看出, 使用最大熵法保留了大量信息, 籽粒图像中灰度值较低的部分也被完整的分割出来, 但黑色衬垫的纹理反光信息、 小面积的杂质区域也被保留下来, 表现为白点块状区域。 采用双重区域标记的方法清理区域, 并对清理之后的二值图像进行区域标记, 计算种子区域的最小外接矩形, 结果如图8所示。
 | 图8 区域清理结果(a)和种子区域最小外接矩形(b)Fig.8 Region cleanup result (a) and seed region minimum circumscribed rectangle (b) |
取出每粒种子的区域并以之为模板与原图按位相与, 得到单粒种子的RGB图像。 为了消除种子边缘可能存在的误差, 在最小外接矩形的长和宽的基础上增加4个值为0的像素, 分割出第一个区域对应的玉米种子的二值图像和彩色图像如图9所示。
 | 图9 单粒种子二值模板(a)和单粒种子的彩色图像(b)Fig.9 Single seed binary template (a) and color image of single seed (b) |
从J(1)图像分割出来的单粒玉米种子图像文件如图10所示。 由于种子大小不一, 分割出来的单粒种子图像大小也各不相同。 得到单粒种子的图像之后, 计算其形态特征、 纹理特征和颜色特征。 然后对一个图像样本中所有种子的特征数据统计求平均作为该样本的图像特征。 采用的特征有: 面积、 周长、 圆形度、 中心距(7个矩)、 灰度共生矩阵(4个属性)、 局部二元模式(local binary pattern, lbp)特征(10个)、 颜色特征(9个), 总计33个特征。 由于中心距中ϕ 4-ϕ 7的数值数量级小于10-5, 可以近似为0, 因此将其去除, 最终用于建模的特征为29个。 这29个特征的数量级差异较大在建模之前对其归一化。
 | 图10 样本J(1)分割生成的种子文件Fig.10 Seed files generated by sample J(1) segmentation |
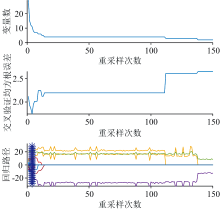
为了进一步降低特征维数, 使用CARS对这29个特征进行优选, 去除共线性和冗余特征。 设置CARS的采样次数为150, 交叉验证的折数为10折, 重采样率为0.8。 变量的选择过程如图11所示, 当迭代次数为4时, 取得最小RMSECV值为1.743 78, 优选出变量11个, 分别为面积、 周长、 lbp3、 lbp4、 lbp6、 lbp8、 颜色矩b1、 颜色矩g1、 颜色矩r2、 颜色矩g2和颜色矩b2。
 | 图11 CARS图像特征优选Fig.11 Image feature optimization by CARS |
BP神经网络不仅具有非线性映射能力、 自适应能力、 泛化能力和较强的容错能力, 还因其采用并行计算的方式具有较高的处理速度, 被广泛应用于农作物品种识别[11, 12]。 分别以IM_BiPLS提取的光谱特征波段、 IM_BiPLS-CARS优选的特征波长、 图像特征(Image)、 CARS提取的图像特征(Image-CARS)以及IM_BiPLS-CARS优选的特征波长叠加CARS提取的图像特征(Compound)为输入, 以样本对应的类别为输出, 建立BP模型。 各模型建立前, 首先将输入数据归一化; 然后采用随机样本分配的方式, 设定训练集、 验证集和测试集之比为3:1:1, 样本数分别为130、 43和43。 隐层采用sigmoid激活函数, 输出层采用softmax损失函数, 训练算法采用比例共轭梯度反向传播算法, 最大迭代次数设为1 000。 模型的最佳隐层节点数根据经验公式和数据实测综合确定, 所依据的经验公式为
式(1)中, m为隐层节点数; n为输入层节点数; l为输出层节点数; α 为1~10之间的常数, 本研究中统一取4。
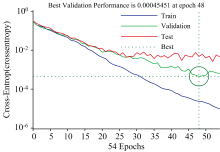
从表4可以看出, Compound-BP模型的性能最佳, 训练准确率和验证准确率均为100%, 测试准确率为97.7%。 Compound-BP模型的最佳验证表现如图12所示, 当迭代次数为48时, 其最佳验证交叉熵为0.004 545 1。
| 表4 模型性能对比 Table 4 Comparison of model performance |
 | 图12 Compound-BP模型的最佳验证表现Fig.12 Best validation performance of Compound-BP |
本研究旨在寻找无损、 高效、 快速、 精确的玉米种子品种识别方法。 针对近红外光谱在玉米种子品种鉴别时因存储时间不同而导致的模型性能不佳的问题, 本研究以种子的图像特征弥补近红外光谱特征的不足, 显著提高了模型的稳定性和预测精度。 研究表明: IM_BiPLS方法可以有效地寻找到最佳的分段数目, 为后续的特征波长优选准备优质的选择范围。 IM_BiPLS与CARS相结合, 优中选优, 可以高效地实现近红外光谱数据的波长优选。 使用群体玉米种子的统计平均特征作为群体种子图像样本的特征, 降低了因个别表观特征特异的种子带来的识别误判的可能性, 提高了识别模型的健壮性。 本研究在玉米种类不是很多, 样本存储时间跨度不是很大的情况下可以实现玉米种子品种的精确识别, 如果想真正地实现技术和方法的推广和应用, 还需要进一步做到:
(1) 建立玉米品种NIRS采集和图像采集标准, 以此标准建立玉米种子近红外光谱库和图像库作为品种的“ 另类指纹库” 。 在建立NIRS库时, 加入不同存储时间的样本以提高模型的泛化能力和鲁棒性。
(2) 建立便携式近红外光谱-图像采集系统, 实现光谱、 图像数据的同步采集。 从算法复杂度和效率方面进一步优化本算法, 建立在线玉米品种精确识别模型。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|