

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于SSTransformer的恒星亚型光谱分类方法研究
[范雅雯 , 刘艳萍
, 刘艳萍* , 邱波, 姜霞, 王林倩, 王坤]
, 刘艳萍, 邱波, 姜霞, 王林倩, 王坤]
|
|


作者简介: 范雅雯, 女, 1999年生, 河北工业大学通信与信息系统专业硕士研究生 e-mail: 2234369773@qq.com
恒星的分类问题一直是天文研究的一大热点, 恒星的亚型分类对探究恒星演化、 稀有天体识别等具有重大意义。 针对LAMOST光谱亚型分类问题设计了SSTransformer (stellar spectrum transformer)分类模型, 该模型主要由三部分组成, 包括输入模块、 嵌入模块、 SST编码模块。 在输入模块中, 将光谱数据进行分块处理, 这些块经过线性投射层被映射为向量。 在嵌入模块中, 为了提取有用的数据特征, 将线性投射层的输出加入一个可学习的类别嵌入块, 为了保留位置信息, 再加入位置嵌入块, 之后将这些数据特征向量送入SST编码模块。 最后在SST编码模块中, 对数据特征进行提取处理, 并利用多层感知器结合新特征对恒星光谱进行分类。 采用的A、 F、 G、 K、 M型恒星光谱数据均来自LAMOST DR8中的一维低分辨率光谱, 35 256条一维光谱数据用于SSTransformer模型的训练, 8815条一维光谱数据用作模型的测试。 为了加快模型的收敛速度, 对数据采用Z-Score归一化处理。 由于是多分类问题, 实验采用了准确率、 精确率、 召回率、 F1-Score、 Kappa系数五个评价指标。 实验结果证明, 利用SSTransformer模型可实现对一维恒星光谱数据有效的筛选分类, 分类准确率达到98.36%, 比支持向量机(support vector machine, SVM)算法、 极端梯度提升(eXtreme Gradient Boosting, XGBoost)算法, 以及卷积神经网络(convolutional neural networks, CNN)的分类准确率更高。
The classification of stars has always been a hot topic in recent astronomical research. The classification of stellar subtypes is significant for exploring stellar evolution and identifying rare celestial bodies. This paper designs the SSTransformer (Stellar Spectrum Transformer) classification model for the LAMOST spectral subtype classification problem. The model mainly comprises three parts, including the input module, the embedding module, and the SST encoding module. In the input module, the spectral data is processed into blocks, which are mapped to vectors through a linear projection layer. In the embedding module, in order to extract useful data features, the output of the linear projection layer is added to a learnable category embedding block. In order to preserve the position information, a position embedding block is added, and then these data feature vectors are sent to the SST encoding module. Finally, the data features are extracted in the SST coding module, and the stellar spectrum is classified using the multilayer perceptron combined with the new features. In this paper,the spectral data of type A, F, G, K, and M starsis all from the one-dimensional low-resolution spectra in LAMOST DR8, 35256 pieces of one-dimensional spectral data are used for training the SSTransformer model, and 8 815 pieces of one-dimensional spectral data are used for testing the SSTransformer model. In order to speed up the convergence of the model, Z-Score normalization is used for the data. Because this is a multi-classification problem, the experiment adopts five evaluation indicators: accuracy rate, precision rate, recall rate, F1-Score, and Kappa coefficient. The experimental results show that the SSTransformer model can effectively screen and classify one-dimensional stellar spectral data, and the classification accuracy reaches 98.36%, which is higher than the support vector machine (SVM) algorithm, eXtreme Gradient Boosting (XGBoost) algorithm, and convolutional neural networks (CNN).
大天区多目标光纤光谱望远镜(LAMOST)是国际上口径最大的大视场望远镜[1], 也是光谱获取率最高的望远镜。 其中, LAMOST在八年巡天项目中获取的DR8数据集中包括了10 388 423条恒星光谱, 光谱的波长覆盖范围是369~910 nm。 恒星光谱可以反映着恒星不同的物理和化学性质, 而恒星光谱分类更是研究恒星光谱的热点问题, 它有助于搜寻识别稀有天体, 分析天体恒星运动[2]。 目前有很多恒星光谱分类方法, 最开始是西奇分类, 后来逐渐发展了哈弗系统、 摩根-肯那(Morgan-Keenan, MK)分类法、 基南系统等。 其中, 基南系统在哈佛系统的基础上将光谱通过恒星表面温度分为O、 B、 A、 F、 G、 K、 M七大类, 每一类又再细分为10个子类, 同时这也是目前最常用的分类方法。
近年来, 针对恒星光谱分类方法大致分为两种, 一是基于传统机器学习的分类方法, 二是基于深度学习网络的分类方法。 Liu[3]等提出一种基于类内散点和类间散点图的分类算法WBS-SVM(within-class scatter and between-class scatter support vector machine), 利用类内散点和类间散点表示训练集分布, 通过样本距离远近来做分类, 分类效果优于传统SVM算法。 Yue[4]等利用XGBoost算法, 通过区分重要光谱特征对亚矮星和矮星做二分类, 分类精度分别达到了97.22%、 97.24%。 姜斌[5]等利用基于属性值相关距离的K近邻算法(feature correlation difference k-nearest neighbor, FCD-KNN)进行A、 F、 M、 O型恒星光谱分类, 分类效果优于传统K邻近算法(k-nearest neighbors, KNN)。 但是, 传统机器学习的光谱分类方法通常以浅层的方式提取光谱特征, 对于海量的光谱数据来说, 深度学习算法利用数据驱动进行特征提取, 比传统机器学习算法更高效, 所提取到的特征鲁棒性更强。 Wang[6]等利用自动编码器从光谱中提取特征并恢复有缺陷的光谱数据, 使用softmax回归模型作为分类器对光谱进行分类。 Liu[7]等基于卷积神经网络提出1DSSCNN(stellar spectra convolutional neural networks)模型对A、 F、 G、 K、 M型恒星光谱分类, 实验结果表明模型的分类效果优于SVM、 随机森林(random forest, RF)和人工神经网络(artificial neural network, ANN)。 杜利婷[8]等提出一种新的基于胶囊网络的分类方法对F5、 G5、 K5型恒星光谱进行三分类, 将1D恒星光谱转化成2D傅里叶谱图像, 再利用胶囊网络对2D傅里叶谱图像进行自动分类, 最后模型的分类效果优于CNN中Inceptionv3网络的分类效果。 Lu[9]等提出一种基于卷积特征的支持向量机算法(convolutional feature and support vector machine algorithm, CFSVM), 利用卷积神经网络对测光图像进行特征提取, 再利用支持向量机算法对提取的特征进行分类, 最终恒星分类准确率达到了91.7%。
近年来Transformer结构作为研究自然语言处理(NLP)的首选网络架构, 已经被广泛应用于图像分类[10]、 目标检测[11]、 图像分割[12]等领域中。 在计算机视觉领域, Dosovitskiy[10]等提出的ViT(vision transformer)模型直接应用于图像块序列可以很好地执行图像分类任务, 这也为后续将Transformer应用于视觉问题奠定了基础。 同时, Transformer算法能够并行计算、 且稳健性高、 全局建模能力强, 所以本文在此基础上提出了SSTransformer网络架构用于恒星光谱的分类研究。 该模型可对A0, A5, F0, F5, G0, G5, K0, K5, M0, M5型恒星光谱进行自动分类, 并与SVM[13]算法、 XGBoost[14]算法及Liu[7]等用到的CNN算法进行对比验证, 实验结果表明SSTransformer算法的分类效果更好, 精度更高。
Transformer作为目前最流行的深度学习算法之一, 主要框架是由Encoder-Decoder结构组成。 在计算机视觉领域, Dosovitskiy[10]等对传统Transformer网络进行优化改进, 提出Vision Transformer算法, 该算法多应用于图像分类任务, 其主要结构包括: 输入层、 线性投射层(linear projection of flattened patches)、 Transformer编码模块(transformer encoder)等, 其中Transformer编码模块内含多层感知器(MLP)、 多头注意力机制(multi-head attention)、 层归一化(layernorm)。 网络模型首先将三通道数据集图片分割成片, 生成序列, 线性投射层对序列进行处理, 得到特征模块(patch embedding)。 然后, Transformer编码器进行特征提取, 利用分类符保存的权重作为输出。 最后, 经过多层感知器得到分类结果。
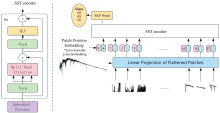
本文基于传统Transformer网络, 提出了SSTransformer模型。 SSTransformer的网络结构如图1所示, SSTransformer主要包括三部分: 输入模块、 嵌入模块、 SST编码模块。
 | 图1 恒星光谱分类SSTransformer结构Fig.1 The SSTransformer structure of stellar spectral classification |
1.2.1 嵌入模块
在输入模块中, SSTransformer对一维等长向量进行编码, 为了更好地实现信息编码, 输入光谱数据大小设为1× 3 700× 1。 经过多次实验发现, 利用1× 100的path处理数据, 将原来1× 3700的流量值变为1× 37个数块, 此时的实验效果最好, 同时这也作为SSTransformer有效输入序列的长度。 SSTransformer的所有层均使用固定维度为100的隐藏向量, 并使用一个线性投射层将数块映射到100维, 将该线性投射层的输出称为Patch Embedding[10]。 为了学习到有用的特征, 引入分类token([CLS]), 这是一个可学习的类别嵌入块(class embedding), 再加入位置嵌入模块(position embedding)用于保留位置信息[10], 具体公式表示为
式(1)中,
1.2.2 SST编码模块
SST编码模块用于特征提取, 其中多头注意力的头数设置为6, 并加入残差连接, SST编码层数也设置为6, SST编码层的结构表达式为
其中, MSA为多头注意力机制, MLP为多层感知器, LN为层归一化, a'i为多头注意力机制的输出结果, ai-1为SST编码层的输出结果, L为SST编码层的层数。 最后, 所有SST编码层循环完毕后, 取第6层中第一个位置上的分类token的输出作为整条数据的特征去做分类, 输出表达式为
式(4)中,
式(5)中, M为类别的数量; yic为符号函数, 若样本i的真实类别等于c取1, 否则取0; pic为观测样本i属于类别c的预测概率。 同时, 利用ModelCheckpoint参数设置保存SSTransformer最佳模型, 设置早停防止网络训练过拟合。
主要采用的是LAMOST DR8数据的低分辨率光谱。 由于有些光谱的流量值缺失或存在负值, 因此需要对光谱进行筛选, 本文将流量值存在负值或连续两个以上零值的光谱数据进行剔除, 最终获得了44 071条光谱; 之后按照8:2的比例将数据集分为训练集和测试集, 最终训练集为35 256条光谱, 测试集8 815条。 每条光谱的波长范围是369~910 nm, 然后对其均匀采样得到所需要的样本, 每条样本数据大小为1× 3 700, 具体情况如表1所示。
| 表1 各类光谱数据 Table 1 The data of stellar spectra |
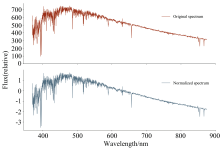
由于一维光谱的维数较高, 为保留完整的光谱信息且便于模型统一处理光谱, 对光谱进行同尺寸剪裁及Z-Score归一化处理, 使得数据均值为0, 方差为1, 数据归一化公式为
式(6)中, f为单样本, μ 为单样本的均值, σ 为单样本的方差, F* 为归一化后的单样本。 从数据集中选取一条光谱数据进行归一化处理后, 如图2所示。
 | 图2 原始与归一化后的恒星光谱波长流量图Fig.2 Raw and normalized stellar spectral wavelength flux maps |
为了证明SSTransformer模型和一维光谱在分类任务中的有效性, 本实验采用精确率(Precision)、 召回率(Recall)、 F1-Score、 Kappa系数、 准确率(Accuracy)五个指标评价模型的性能。 精确率(Precision)指被正确分类的亚型光谱条数与模型分类结果中亚型光谱条数的比值, 召回率(Recall)指被正确分类的亚型光谱条数与测试集中的亚型光谱条数的比值, F1-Score是精确率和召回率的调和平均数, 其计算公式为
准确率(Accuracy)为被正确分类的总光谱数量与测试集所有光谱条数的比值, Kappa系数同样作为总体一致性检验指标, 其计算公式为
式(8)中, K为Kappa系数, P0是每一类正确分类的样本数量之和除以总样本数, 也就是总体分类精度。 假设每一类的真实样本个数分别为a1, a2, …, ac, 而预测出来的每一类的样本个数分别为b1, b2, …, bc, 总样本个数为n, 则Pe的表达式为
从而全面系统地验证了模型的性能。
本文的程序在Tensorflow 2.5框架下采用python语言编写, 运行在3.60 GHz Intel(R)Core(TM) i7-11700K CPU、 11GB内存和64位Windows系统的桌面上, 并使用RTX 2080ti GPU加速计算。
将预处理后的光谱作为SSTransformer模型的输入, 直接输入到模型中进行训练, 最后将十类恒星光谱分类。 由表2可以看出M0型光谱的分类精度最高, K5型光谱的召回率最高, G0型光谱的F1-Score最高。 总体来看, 每一类的恒星光谱精确率、 召回率、 F1-Score值都较高, 说明SSTransformer可以准确地区分一维恒星光谱的亚型。
| 表2 恒星亚型光谱分类结果 Table 2 Spectral classification results of stellar subtypes |
本文采用的对比方法有CNN[7]、 SVM[13]、 XGBoost[14]算法。 其中, CNN算法结构主要由输入层、 隐藏层、 输出层组成。 隐藏层中的卷积层用来提取数据特征, 池化层采用最大池化的方法来减少参数, 降低网络复杂度, 实验采用三层卷积, 三层池化, 卷积层与池化层交替出现, 得到的特征经过全连接层, 最后经过softmax的激活函数进入输出层; SVM的算法类型为C-SVC, 核函数采用径向基函数; XGBoost算法采用树模型作为基分类器, 树的深度为6。
如图3, 将四种算法得到的分类结果以混淆矩阵表示, 从图中可以看出绝大部分预测结果都与对应类别一致。 但是, 对于这四种算法来说, 都存在F0、 F5类恒星分类准确率略低的问题。 由图4可以看出, 这极有可能是由于部分F0和F5型恒星光谱的谱线特征存在较大的相似性, 导致模型在学习过程中容易混淆这两类恒星, 从而影响最后的分类效果。
 | 图3 不同方法实验结果的混淆矩阵 (a): SVM实验结果混淆矩阵; (b): XGBoost实验结果混淆矩阵; (c): CNN实验结果混淆矩阵; (d): SSTransformer实验结果混淆矩阵Fig.3 Confusion matrix of experimental results of different methods (a): Confusion matrix of SVM experimental result; (b): Confusion matrix of XGBoost experimental result; (c): Confusion matrix of CNN experimental result; (d): Confusion matrix of SSTransformer experimental result |
 | 图4 F0型与F5型恒星谱线特征图 (a): F0型恒星谱线特征图; (b): F5型恒星谱线特征图Fig.4 Stellar spectral line features of F0-type and F5-type (a): Stellar spectral line features of F0-type; (b): Stellar spectral line features of F5-type |
同时, 利用准确率Accuracy、 Kappa系数对总体进行评价分析, 由表3可以看出, SSTransformer对十类亚型光谱分类准确率高达98.36%, Kappa系数高达98.16%, 比SVM、 XGBoost、 CNN算法分类的准确率值、 Kappa系数值要高。 而当光谱数据量较大时, SVM、 XGBoost算法需要较大的时间和空间开销, 获得最佳模型时CNN与SSTransformer算法的训练时间相对较少。 因此, 对于大规模光谱数据来说, 深度学习算法比传统机器学习算法更加高效, 特征提取能力更强。
| 表3 实验结果对比 Table 3 Comparison of experimental results |
将Transformer算法应用于恒星光谱亚型分类问题中, 从而进一步提升恒星光谱分类精度。 文章提出的SSTransformer算法对LAMOST DR8数据中A、 F、 G、 K、 M五类及其亚型恒星光谱进行自动分类, 采用准确率、 精确率、 召回率、 F1-Score、 Kappa系数五个指标评价训练模型的性能。 从分类结果中对比发现SSTransformer算法可有效提取一维光谱数据特征, 对光谱的自动筛选分类准确率较高。 与深度学习CNN算法、 传统机器学习的SVM算法和XGBoost算法相比, SSTransformer网络对于恒星光谱分类准确率高达98.36%。 该方法不仅提高了光谱分类精度, 同时打破了传统光谱分类网络中的复杂操作, 模型结构更加简单, 特征提取能力更强。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|