

{kind=link}
{kind=link}
{kind=link}
基于1D-CNN的近红外光谱分类算法研究
[蒲姗姗 , 郑恩让
, 郑恩让* , 陈蓓]
, 郑恩让, 陈蓓]
|
|


作者简介: 蒲姗姗, 女, 1998年生, 陕西科技大学电气与控制工程学院硕士研究生 e-mail: 1432671523@qq.com
近红外光谱(NIR)技术应用广泛, 但其建模精度容易受到光谱预处理算法的影响, 传统近红外光谱分析过程中, 预处理方法的选取主要靠人为经验, 有时会遗漏一些光谱特征。 提出了一种无需光谱预处理的一维卷积神经网络(1D-CNN)近红外光谱分类方法。 为了比较BP神经网络(BP)、 支持向量机(SVM)、 极限学习机(ELM)三种传统近红外光谱分析模型与一维卷积神经网络(1D-CNN)建模方法的分类效果, 在不同等级药品、 啤酒和不同种类芒果、 葡萄NIR数据集中进行了对比实验, 实验结果显示采用1D-CNN模型的分类准确率最高, 其中药品4分类、 啤酒2分类、 芒果10分类、 葡萄19分类的准确率分别为96.77%、 93.75%、 96.45%、 88.75%。 最后讨论了均值中心化(MC)、 标准化、 多元散射校正(MSC)、 标准正态变量变换(SNV)、 一阶差分、 二阶差分、 小波变换(WT)7种光谱预处理方法对不同模型的影响。 经过预处理后, BP神经网络、 SVM和ELM的分类准确率有明显的变化, 而1D-CNN模型的分类效果在预处理前和预处理后基本无变化, 且分类准确率依旧最高。 结果表明, 相比传统近红外光谱分类方法, 所提出的1D-CNN方法可实现对食品和药品NIR快速准确分类, 不需要任何的光谱预处理, 说明深度学习方法在近红外光谱处理领域中具有广阔的应用前景和研究价值。
Near-infrared (NIR) spectroscopy technology has been widely used in many fields, but spectral pretreatment algorithm easily affects its modelling accuracy. In traditional near-infrared spectroscopy analysis, the selection of pretreatment methods mainly depends on human experience, and sometimes some spectral information will be lost. Therefore, a near-infrared spectrum classification method of a one-dimensional convolution neural network (1D-CNN) without spectral pretreatment is proposed in this paper. In order to compare the classification effects of three traditional near-infrared spectral analysis models of BP neural network (BP), support vector machines (SVM) and extreme learning machine (ELM) with one-dimensional convolutional neural network (1D-CNN) modeling method, comparative experiments were carried out on NIR data sets of different grades of drug, beer, mango and grape. The experimental results show that the classification accuracy of the 1D-CNN model is the highest, among which the accuracy of drug 4 classification is 96.77%, beer 2 classification is 93.75%, mango 10 classification is 96.45%, and grape 19 classification is 88.75%. Finally, the effects of seven different spectral pretreatment methods, such as mean centralization (MC), standardization, multiple scatter correction (MSC), standard normal variable transformation (SNV), first-order difference, second-order difference and wavelet transform (WT) on different models are also discussed. After pretreatment, the classification accuracy of the BP neural network, SVM and ELM changes significantly, while the classification effect of the 1D-CNN model has no change before and after pretreatment, and the classification accuracy is still the highest. The results show that compared with the traditional NIR spectral classification methods, the 1D-CNN method proposed in this paper can realize the rapid and accurate NIR classification of food and drugs and does not need any spectral pretreatment. It shows that the deep learning method has broad application prospects and research value in NIR spectral processing.
近红外光谱的波长范围为780~2 526 nm, 由于NIR技术具有快速、 准确、 易于使用和无损等特点, 在食品、 药品、 石化等多个领域[1]得到了普遍应用, 比如, 鉴别食品和药品的种类、 产地和真伪。 但NIR也存在信噪比低、 吸收强度弱、 光谱峰重叠等缺点, 因此, NIR建模方法的研究成为NIR分析的核心, 近些年来, 一些深度学习算法[2]常被用在近红外光谱的分析中。 NIR数据的化学分析处理通常使用基线校正、 乘法散射校正、 噪声去除和缩放等预处理方法, 可以减少仪器和实验伪影所带来的误差, 提高光谱分析的准确性和稳健性[3, 4]。 针对不同的NIR数据集需要不同的最佳预处理方法[5], 试错法需要消耗大量的计算资源。
卷积神经网络(CNN)作为一种经典深度学习网络模型, 属于前馈神经网络。 该方法的特点在于, 每一层中的神经元节点只对前一层局部区域中的神经元作出响应, 对比其他网络模型, 卷积操作的“ 局部连接, 权值共享” 特性可以使要优化的参数量大为减少, 从而大大提高模型的训练效率, 并且还可以进行强特征提取, 具有很强的模型表达能力, 现已可以很好地应用在二维图像识别、 视频分析、 药物发现[6]等领域。 近些年来, 深度卷积神经网络模型在一维近红外光谱分析领域也开始得到了研究与应用, 如采用基于深度卷积神经网络的土壤水分近红外光谱回归预测方法, 将一维的NIR信号进行预处理后变换成二维光谱矩阵来适应二维CNN模型结构, 方法复杂且耗费计算资源。 Liu等[7]提出一种对拉曼光谱数据的深度卷积神经网络(CNN)的多分类方法, 并且得到了很好的分类效果, 但研究对象是RRUFF矿物拉曼光谱。 Acquarelli等[8]提出了一种对振动光谱数据进行分类的浅层卷积神经网络, 但使用非标准的CNN框架, 只有一个隐藏的卷积层, 没有池化层。
本研究提出了一种适用于近红外光谱且无需数据预处理的一维卷积神经网络(1D-CNN)建模分析方法。 用四个近红外光谱数据集对1D-CNN方法进行测试, 并将1D-CNN模型与三种流行的传统建模方法(BP、 SVM、 ELM)的分类准确率进行了比较。 为了评估预处理对建模方法的影响, 采取了7种预处理策略(MC、 标准化、 MSC、 SNV、 一阶差分、 二阶差分、 WT)。 结果表明, 1D-CNN模型可以把光谱预处理、 光谱筛选和分类建模结合在一起, 使模型自主训练提取光谱特征, 不但减少了光谱建模步骤、 节约资源, 而且模型具有更好的性能。
数据集1: 在公开的310个药品NIR样本数据集上[8], 将样本根据药品活性物质浓度分为4类, 药品近红外光谱波长范围为700~2 500 nm。
数据集2: 以公共数据集的78个啤酒NIR样本为研究对象[8]。 包含Rochefort 8(1类)和Rochefort 10(2类)啤酒的啤酒数据集, 8号的酒精度是9.2%, 10号的是11.3%。
数据集3: 来自澳大利亚境的生长区域, 收集了4 685份具有参考值的芒果样品[9], 11 834条近红外光谱, 每个芒果扫描两次在每个颊最宽的部分(大约水果的中间)正交于内果皮平面, 芒果品种分为10种。
数据集4: 使用便携式分光光度计, 在非破坏性的野外条件下, 于1 600~2 400 nm的近红外光谱范围内进行光谱测量。 从19个葡萄品种的400片单独叶片的正面收集光谱[10], 葡萄分为19种。 4个数据集的近红外光谱分别如图1(a— d)所示。
 | 图1 四个数据集的近红外光谱图 (a): 药品NIR; (b): 啤酒NIR; (c): 芒果NIR; (d): 葡萄NIRFig.1 NIR profiles of the four datasets (a): Drug NIR; (b): Beer NIR; (c): Mango NIR; (d): Grape NIR |
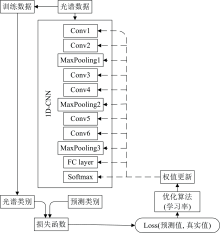
参考传统的AlexNet的卷积神经网络, 采用仿真试验调整和优化 CNN的结构和参数, 建立了一个针对NIR分类的一维卷积神经网络(1D-CNN)模型, 与现有的针对二维图像识别的卷积神经网络不同, 本文采用的卷积核为一维卷积核, 整个模型的结构及参数设定见表1, 包括6个卷积层、 3个最大池化层和1个全连接层。 卷积神经网络(CNN)是一种端到端的监督式神经网络, 通常包含输入层、 卷积层、 激活函数、 池化层、 全连接层, 而卷积层和池化层是整个网络的关键。 卷积层具有“ 局部连接, 权值共享” 的特点, 可以实现对输入近红外光谱数据特征的提取, 采用尺寸为1× 3的一维卷积核完成对一维近红外光谱信号的运算。 池化方法主要有最大池化(Max-pooling)和平均池化(Mean-pooling), 本研究选取最大池化, 筛选最重要的特征数据。 浅层卷积层的作用为对输入的光谱数据做预处理和光谱筛选, 连接浅层的池化层将经过浅层卷积层处理过的数据进一步进行筛选降维, 减少特征的数量。 中层和深层的卷积层将数据进一步抽象, 再通过最大池化筛选出抽象数据中最重要的特征, 减少网络参数的数量, 提高计算速度, 从而提升神经网络模型鲁棒性, 达到分类的目的。 一维光谱信号的卷积运算如式(1)所示。
式(1)中,
| 表1 1D-CNN模型参数设置 Table 1 Parameter settings of 1D-CNN model |
网络模型通过信号前向传播, 将误差反向传递的方法加以训练, 而卷积神经网络的训练和优化则主要依靠损失函数(Loss function), 用预测值与真实值之间的偏差信息作为损失函数, 并通过信息反向传递更新连接权值。 使用Adam(adaptive moments estimation)优化器对模型进行优化, 待损失函数的值达到最小, 训练即完成并保存最优模型权重。 本文反向传播中采用的损失函数为交叉熵损失函数, 如式(2)所示。 为了实现一维卷积神经网络模型参数的快速更新和收敛, 将训练样本分成多个批次, 将批次样本大小设置为10。 1D-CNN模型的训练流程图如图2所示。
式(2)中, xm是训练的光谱数据, ym, n是第m个样本预测第n个数据的标签, pm, n是第m个样本预测第n个标签值的概率, M是总样本数, N为总标签类数。
 | 图2 1D-CNN模型的训练流程图Fig.2 Training flow chart of the 1D-CNN model |
基于Keras和Tensorflow框架, 用Python语言建立了一维卷积神经网络模型。 实验环境: Intel Core i9-10900KCPU; NVIDIA GeForce GTX 1080TiGPU; 32GB计算机内存。 为了实现数据的优化, 比较各种机器学习算法, 系统中配置了Numpy, Pandas, Sklearn, Matplotlib等Python 运算库, 可以大大加快神经网络的训练速度。
采用卷积神经网络算法构建模型, 首先用训练集将模型充分练习, 然后再用测试集验证模型效果, 将测试集数据输入到模型中即可进行类别预测, 采用准确率(accuracy, ACC)检验1D-CNN模型的预测效果, ACC是正确分类的样本数量与样本总数的比率, 一般情况下, 模型的准确率越接近于1, 说明模型的分类效果越好。 将损失函数的曲线图也一并表示出来, 损失函数值越趋向于0, 说明模型的性能越好。
为了验证本文提出的一维卷积神经网络模型近红外光谱分类效果, 对4个数据集进行了药品4分类, 啤酒2分类, 芒果10分类和葡萄19分类的实验, 将每个数据集以8:2的比例分为训练集(Train)和测试集(Test)。
由表2可以看出, 在药品4分类实验中, 未经预处理的原始数据在BP神经网络、 SVM、 ELM、 1D-CNN模型中的分类准确率分别为85.48%、 96.77%、 61.29%、 96.77%, 1D-CNN的分类准确率和SVM的分类准确率相同且最高。 但在啤酒2分类、 芒果10分类、 葡萄19分类实验中, 本文提出的1D-CNN模型的分类准确率为93.75%、 96.45%、 88.75%, 比BP、 SVM、 ELM三种传统建模方法的分类准确率更好更稳定。
| 表2 不同数据集在不同模型中的的分类准确率(%) Table 2 Classification accuracy (%) of different data sets in different models |
其中药品4分类、 啤酒2分类、 芒果10分类、 葡萄19分类在1D-CNN模型训练过程中的分类准确率(ACC)曲线与损失函数(LOSS)曲线分别如图3(a— d)所示, 可以明显的看出, 准确率趋近于1, 损失函数值趋向于0, 说明1D-CNN模型在四个NIR数据集中具有很好的鲁棒性和泛化能力。
 | 图3 分类准确率曲线与损失函数曲线 (a): 药品4分类; (b): 啤酒2分类; (c): 芒果10分类; (d): 葡萄19分类Fig.3 Classification accuracy curves and loss function curves (a): Drug 4 classification; (b): Beer 2 classification; (c): Mango 10 classification; (d): Grape 19 classification |
为了建立最优的近红外光谱模型, 需要花费了大量的时间和精力来比较不同的预处理方法, 特征提取方法和分类方法。 在本文中, 针对4个数据集, 对比了7种不同预处理方法在不同模型中的分类准确率, 选择了MC、 标准化、 MSC、 SNV、 一阶差分、 二阶差分和WT作为预处理。
首先, 对于药品的4分类实验, 分类准确率如表3所示, 在BP神经网络模型中, 经过MC、 MSC、 一阶差分和WT预处理后的分类准确率比原始数据的分类准确率高, 经过SNV和二阶差分后的分类准确率相比于原始数据的分类准确率有所下降; 在SVM模型中, 经过标准化后的分类准确率比原始数据的分类准确率高, 而经过MSC、 SNV、 一阶差分和二阶差分后的分类准确率相比于原始数据的分类准确率有大幅下降; ELM模型中, 经过MC、 标准化、 MSC、 一阶差分、 WT后的分类准确率比原始数据的分类准确率高, 而经过SNV和二阶差分后的分类准确率比原始数据的分类准确率降低不少; 对于1D-CNN模型, 经过预处理和未经过预处理后的分类准确率基本没有差异, 并且具有较高的分类精度。 可以得出, 1D-CNN模型在药品4分类实验中较之其他3种建模方法有较高的分类准确率, 且1D-CNN模型在分别经过7种不同预处理后的准确率比其他3种传统模型性能更加稳定, 说明预处理对1D-CNN的影响不大, 在1D-CNN模型中可以省略预处理的步骤, 节省时间。
| 表3 药品(4分类)在不同模型和预处理后的分类准确率(%) Table 3 Classification accuracy (%) of drugs (4) after different models and pretreatment |
在芒果10分类实验中, 由表4可以看出, 对于BP模型, 经过MC、 标准化、 MSC、 一阶差分、 二阶差分和WT预处理后的分类准确率比没有经过预处理的准确率有所提高, 经过SNV预处理后的分类准确率比原始数据的分类准确率低; 在SVM模型中, 数据经过不同的预处理后对模型的分类效果都有一定提升; 对于ELM模型, 经过MC、 标准化、 MSC和WT后的分类准确率比原始数据的准确率高, 其他预处理方法后的准确率都有大幅下降。 对于1D-CNN模型, 经过7种预处理后的分类准确率与原始数据的分类准确率差异不大。 同理, 由表5和表6可知, 在啤酒2分类、 葡萄19分类实验中, 选择不同预处理后的BP、 SVM、 ELM三种传统模型的分类准确率变化很大, 很不稳定, 而预处理对1D-CNN的分类效果几乎没有影响。 说明了合适的预处理会提高模型地分类效果, 反之就会降低其准确率, 而1D-CNN模型很好的解决了如何选择合适的预处理这一难题, 充分证明了1D-CNN模型可在略去预处理时使分类效果更好更稳定, 且比BP、 SVM、 ELM传统近红外光谱建模方法更为方便。
| 表4 芒果(10分类)在不同模型和预处理后的分类准确率(%) Table 4 Classification accuracy (%) of Mango (10) after different models and pretreatment |
| 表5 啤酒(2分类)在不同模型和预处理后的分类准确率(%) Table 5 Classification accuracy (%) of beer (2) after different models and pretreatment |
| 表6 葡萄(19分类)不同模型和预处理后的分类准确率(%) Table 6 Classification accuracy (%) of grape (19) after different models and pretreatment |
对传统的近红外光谱分类方法, 不同的预处理策略对模型有着不同的影响, 试错法又会占用很多时间, 而本文提出的1D-CNN模型可以很好的解决这个难题。 本文针对变量多、 冗余大、 非线性的NIR样本分类问题, 设计出了鲁棒性好, 分类准确率高的1D-CNN网络结构, 利用食品和药品NIR数据集进行两分类和多分类的研究, 进行了BP、 SVM、 ELM和1D-CNN不同模型的对比实验, 并用不同预处理方法对不同模型的分类准确率进行了比较, 结果表明1D-CNN模型不仅具有更好的分类精度和稳定性, 而且减少了预处理操作步骤节省了时间, 优势更加明显。 两分类模型可较准确地对不同浓度的啤酒进行快速识别分类, 多分类模型可用于药品不同含量活性物质的分类识别和芒果及葡萄的种类鉴别, 并且此分类模型还可以推广到其他物品的近红外光谱分析中。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|