





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
机器学习在乳腺癌荧光光谱诊断中的应用研究
[陈文静 , 许诺, 教召航, 尤家华, 王赫, 齐东丽, 冯瑜
, 许诺, 教召航, 尤家华, 王赫, 齐东丽, 冯瑜* ]
, 许诺, 教召航, 尤家华, 王赫, 齐东丽, 冯瑜]
|
|


作者简介: 陈文静, 女, 1995年生, 沈阳理工大学理学院硕士研究生 e-mail: cxjxwx1@163.com
乳腺癌是世界上对于女性非常危险的疾病, 其患病率逐年增长, 是世界妇女死亡的主要原因。 在大样本情况下, 乳腺癌临床诊断受优质医疗资源相对短缺的限制, 诊断周期长、 检测费用高。 因此, 高效、 准确、 性价比高的乳腺癌诊断方法具有广阔的应用前景, 为临床诊断迫切需求。 荧光光谱检测是一种可以表征细胞中物理和化学综合变化的方法, 可用于表征正常和癌变细胞的特征。 机器学习擅长从大量数据中挖掘有用信息, 是进行分类和预测的有效手段。 以往机器学习多使用包含部分生化信息的数据库训练模型, 易导致信息缺失。 荧光光谱是细胞多种物质的叠加光谱, 使用荧光光谱特征峰诊断乳腺癌存在量化不确定性问题。 因此, 提出了机器学习结合乳腺癌样本荧光光谱的诊断方法。 使用405 nm波长的激光, 采集了正常和癌变乳腺组织(已做出病理诊断)的荧光光谱数据, 以此作为数据集, 比较了K-近邻(KNN)、 支持向量机(SVM)、 随机森林(RF)三种算法对正常和癌变乳腺组织荧光光谱的分类能力。 判别结果显示: 与SVM算法相比, KNN和RF算法的准确率更高、 平衡召回率和精度的能力更强, 对乳腺癌荧光光谱的分类能力更好, 其准确性、 召回率、 精度以及F1-score函数结果均在95%之上, 更利于乳腺癌的诊断。 进而探讨了权重KNN(WKNN)算法对正常和癌变乳腺组织荧光光谱的分类能力。 WKNN较KNN算法的分类评估结果有小幅度提升, 且具有更好的抗噪和适应能力, 算法简单。 综上所述, 本文提出的机器学习结合荧光光谱的乳腺癌诊断方法, 精度高、 速度快、 性价比高, 是未来乳腺癌诊断方法的发展方向, 具有重要的临床应用价值。
Breast cancer is a very dangerous disease for women worldwide, its prevalence is increasing year by year, and it is the main cause of death among women worldwide. In the case of large samples, the clinical diagnosis of breast cancer is limited by the relative shortage of high-quality medical resources, the diagnosis cycle is long, and the detection cost is high. Therefore, efficient, accurate and cost-effective breast cancer diagnosis methods have broad application prospects and are urgently needed for clinical diagnosis. Fluorescence spectroscopy is a method that can characterize the combined physical and chemical changes in cells and can be used to characterize normal and cancerous cells. Machine learning is good at mining useful information from a large amount of data and is an effective classification and prediction method. In the past, machine learning mostly used databases containing some biochemical information to train models, which easily led to information loss. The fluorescence spectrum is the superimposed spectrum of multiple substances in cells, and the use of fluorescence spectrum characteristic peaks to diagnose breast cancer has the problem of quantitative uncertainty.Therefore, this paper proposes a diagnostic method combining machine learning with fluorescence spectra of breast cancer samples. The fluorescence spectrum data of normal and cancerous breast tissue (pathological diagnosis has been made) was collected as a data set, and K-nearest Neighbor (KNN), support vector machine (SVM), Random Forest (RF) three algorithms to classify the fluorescence spectrum of normal and cancerous breast tissue. The discriminant results show that compared with the SVM algorithm, the KNN and RF algorithms have higher accuracy, stronger ability to balance recall and precision, and better classification ability for breast cancer fluorescence spectra. The results of the F1-score function are all above 95%, which is more conducive to the diagnosis of breast cancer. Furthermore, the classification ability of the Weighted K-nearest Neighbor (WKNN) algorithm for normal and cancerous breast tissue fluorescence spectra were discussed. Compared with the KNN algorithm, WKNN has a small improvement in the classification evaluation results and has better anti-noise and adaptability, and the algorithm is simple. In conclusion, the breast cancer diagnosis method based on machine learning and fluorescence spectroscopy proposed in this paper has high accuracy, high speed and high-cost performance. It is the future development direction of breast cancer diagnosis methods and has important clinical application value.
乳腺癌是当今女性最常见和最危险的恶性肿瘤, 临床上用于乳腺癌的诊断方法也趋于多样化, 常见的诊断方法包括术前、 术中和术后诊断[1]。 X射线、 CT作为一种术前诊断技术, 被广泛应用于临床诊断, 对高密度乳腺组织不敏感, 而磁共振成像(MRI)耗时且性价比不高[2]。 术中冷冻乳腺癌诊断技术是术中诊断方法之一, 然而其准确性可能会受到年龄、 肿瘤大小和患者的乳房X线摄影钙化点情况的影响。 在术后诊断方面, 病理评估和形态学评估可提供重要的愈后信息, 在诊断和治疗领域具有至关重要的意义[3]。 乳腺癌的最终诊断主要依赖于经验丰富的专家, 诊断的结果有可能受到专家的主观因素影响。 因此, 快速、 准确、 客观的乳腺癌诊断方法是临床迫切需要的。
研究已经确定组织发生癌变时伴随着某些生化信息的变化, 该变化在光学域留下了光谱特征[4]。 荧光光谱是组织中多种发光基团的叠加光谱, 作为一种重要的光谱技术, 可在不损伤样本的条件下, 对样本中的发光基团进行检测, 在临床细胞生化信息检测中被广泛应用。 机器学习是对计算和可测量模型的逻辑调查, 使用Personal Computer(PC)框架来执行特定的任务, 而不使用表达方向[5]。 通常, 在没有完整信息的情况下, 机器学习算法利用部分已知信息解决了近似其最优行为策略的问题。 因此, 它能帮助很多疾病的诊断。
K-近邻(K-nearest neighbor, KNN)、 支持向量机(support vector machine, SVM)、 随机森林(random forest, RF)等机器学习或卷积神经网络等算法与数据库中的数据集相结合, 是目前乳腺癌诊断方法研究的热点[6]。 Sharma等[7]使用威斯康星州原始数据集与SVM, KNN、 RF、 NB方法相结合对乳腺癌数据进行了分类, 得到KNN算法在乳腺癌检测中最有效。 Ehsani等[8]采用UCI机器学习库的数据, 对稳健距离的KNN算法进行了研究, 得出结论为Hassanat和Sobolev距离测量方法表现较好, 准确率为96.7%。 但是, 数据库中的数据只包含乳腺细胞的部分重要生化信息, 未包含细胞其他方面的特征信息。 多样本乳腺癌的诊断, 因受检测仪器及专业医师等因素限制, 时间及价格成本较高, 而目前使用的荧光光谱方法因部分荧光峰重叠面积较大检测效果不理想。 针对这一问题, 本文提出以课题组采集的正常、 癌变乳腺组织的荧光光谱数据为数据集, 利用KNN、 SVM和RF算法建立模型、 比较评估参数、 做出分析, 为发展在多样本状况下可临床应用的乳腺癌诊断提供方法和依据。
用于实验的乳腺组织切片由中国医科大学附属第一医院提供, 共60片, 28片正常组织, 32片癌变组织, 每片组织切片的厚度为10~20 μ m, 正常和癌症患者年龄范围为33~72岁。 乳腺组织切片采用免疫组织化学法染色(SP), 染色剂调配: 蒸馏水、 苏木素、 DAB A、 DAB B、 DAB C以体积比为5:1:1:1:1比例配制, 染色溶液时效为0.5 h, 需在该时间内完成光谱采集。
使用405 nm波长的激光(MDL-Ⅲ -405型号, 波长405 nm, 功率150 mW, 长春新产业光电技术有限公司)照射固定在二维平台上的乳腺组织切片样品, 样品发出的荧光光谱透过二向色镜(沈阳江博光学技术有限公司, 临界波长410 nm, 透射波长> 419 nm, 透过率> 80%, 反射波长360~405 nm, 反射率> 99%)被透镜聚焦到光纤探测器(QP400-2-SR型号, Ocean Insight公司), 光纤探测器将光信号传递给光谱仪(USB4000型光纤光谱仪, 光谱范围200~800 nm, 扫描速度4 500 scans· s-1, 分辨率0.8 nm, 采样间隔3.8 ms, 狭缝宽度为200 μ m), 经光电转换后传输到PC端。 为减少实验误差, 本实验每个乳腺组织样本分别检测十个不同的位置, 每一个位置采集三个光谱, 光谱积分时间为112 ms、 采集范围为450~750 nm, 以上实验均在黑暗、 室温条件下完成。
1.2.1 背景荧光光谱
实验中影响组织荧光光谱的背景荧光主要来自于载玻片(1片或2片)和染色剂, 载玻片和染色剂的荧光光谱如图1(a)和(b)所示。
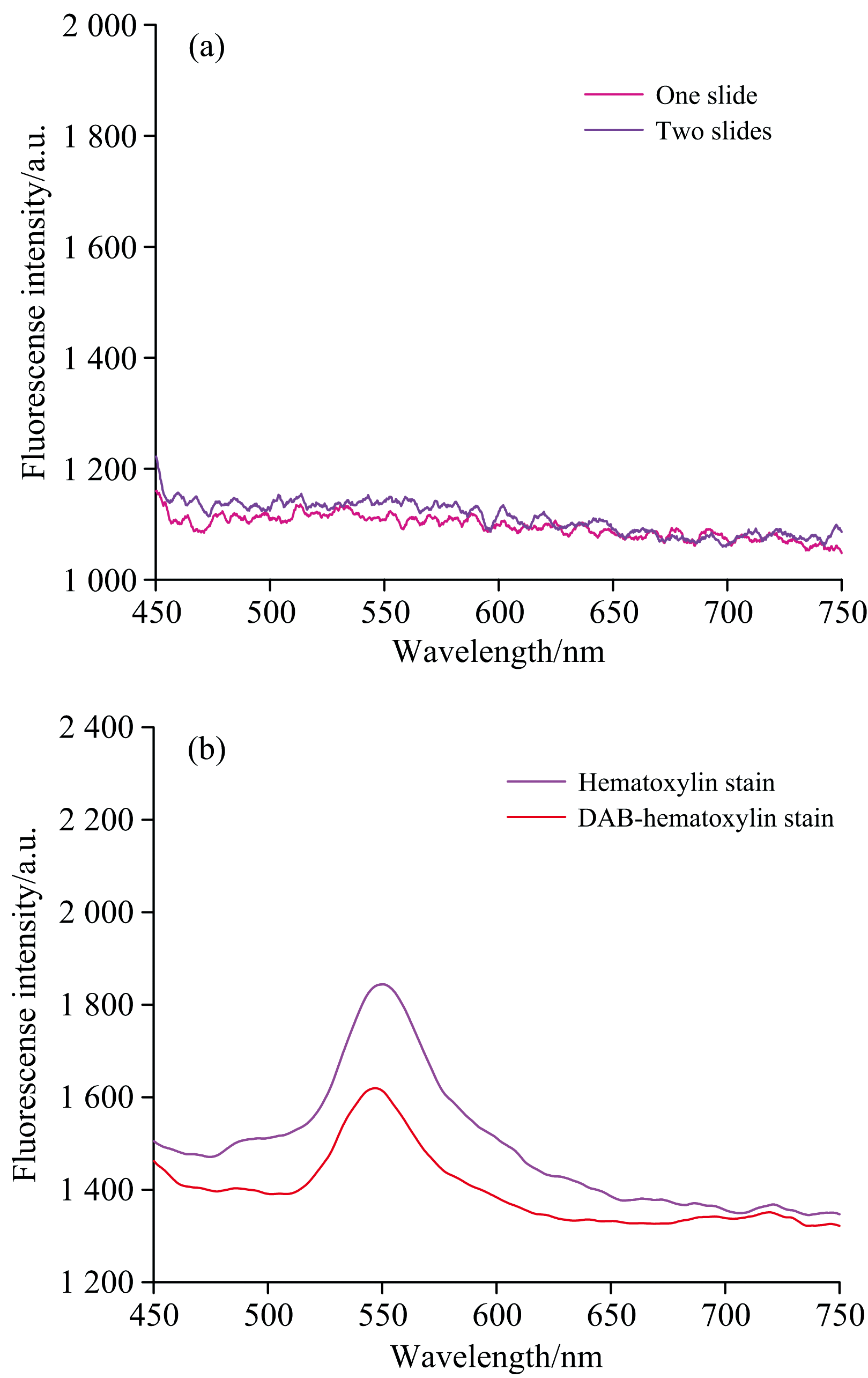 | 图1 载玻片(a)和染色剂(b)荧光光谱Fig.1 Fluorescence spectra of slide (a) and stain (b) |
由图1可知, 在波长为405 nm激光的激发下, 该组织切片所用的载玻片未产生背景荧光, 染色剂的荧光峰在551~555 nm波段。
1.2.2 组织荧光光谱
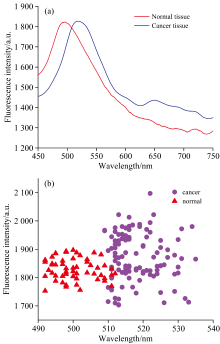
人体组织中含有多种发光基团生物大分子, 如胶原蛋白、 核黄素、 还原型辅酶, 当激光照射组织时, 所获取的荧光光谱是多种发光物质的重叠光谱[9, 10, 11, 12]。 图2(a)是正常和癌变乳腺组织的平均荧光光谱图, 图2(b)为所有组织样本荧光光谱主峰在450~540 nm波段的峰值-强度图。 由图2可知:
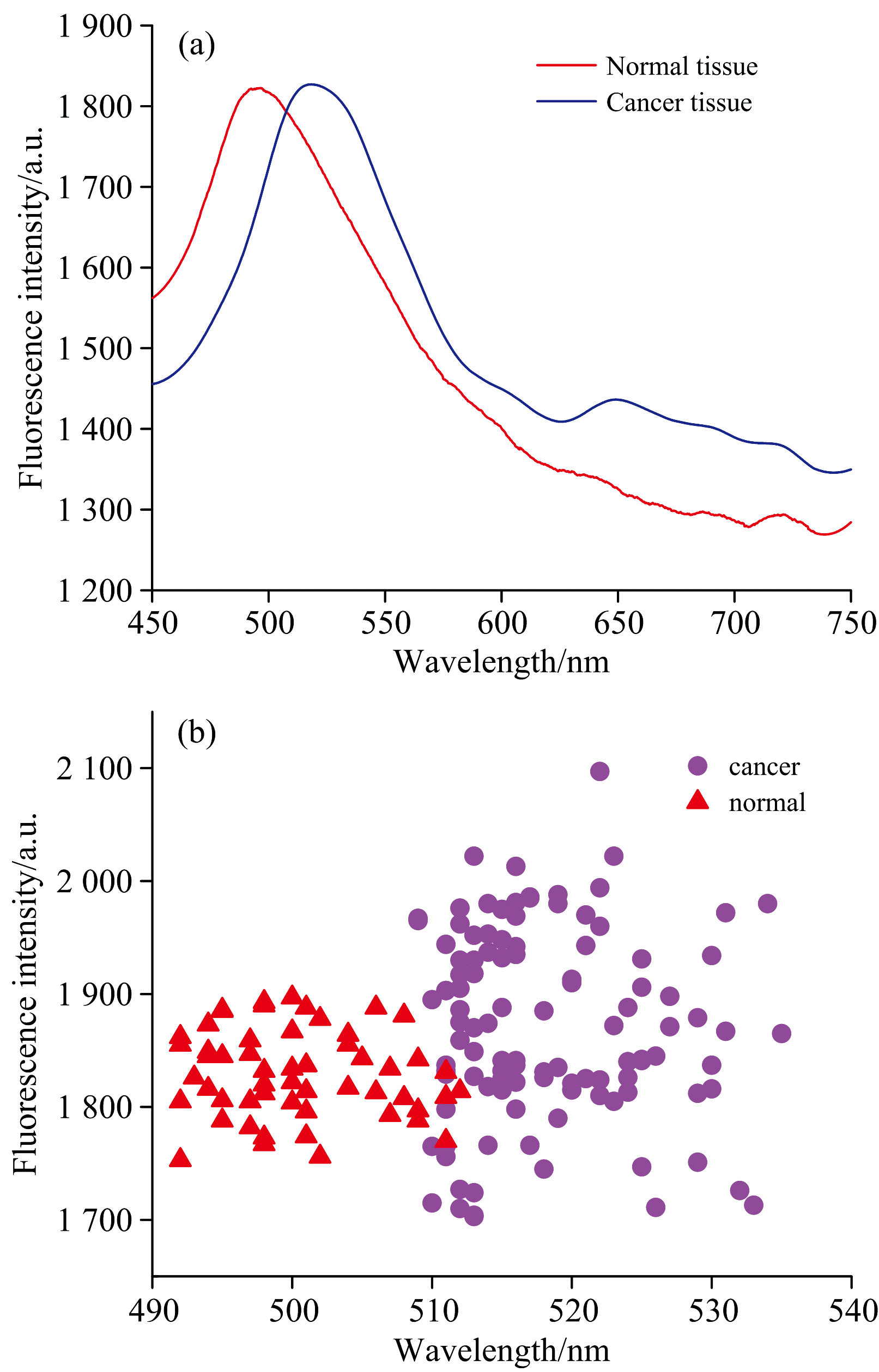 | 图2 正常组织和癌组织的荧光光谱Fig.2 Fluorescence spectra of normal and cancerous tissues |
正常组织主峰位于490~510 nm波段, 癌变组织主峰位于510~535 nm波段, 次荧光峰位于640~650 nm波段, 与正常组织荧光峰相比, 癌变组织荧光峰具有红移现象。
1.3.1 算法
选择KNN、 SVM和RF三种算法对正常和癌变乳腺组织荧光光谱数据进行分类。
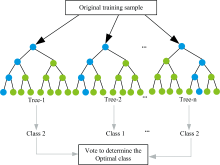
KNN算法是一种基于近邻、 有监督的机器学习算法, 具有样本需求小, 算法简单的优点[13, 14]。 原理是: 在特征空间中, 如果待测点相邻的K个相似样本中的大多数属于某一个类别, 则判断该待测点也属于这个类别, 在特征空间中, K相邻样本点的选择由待测点与所有样本点的距离决定。 假设由3个相邻样本点(K=3)和7个相邻样本点(K=7)对同一待测点的分类, 分类结果如图3所示。
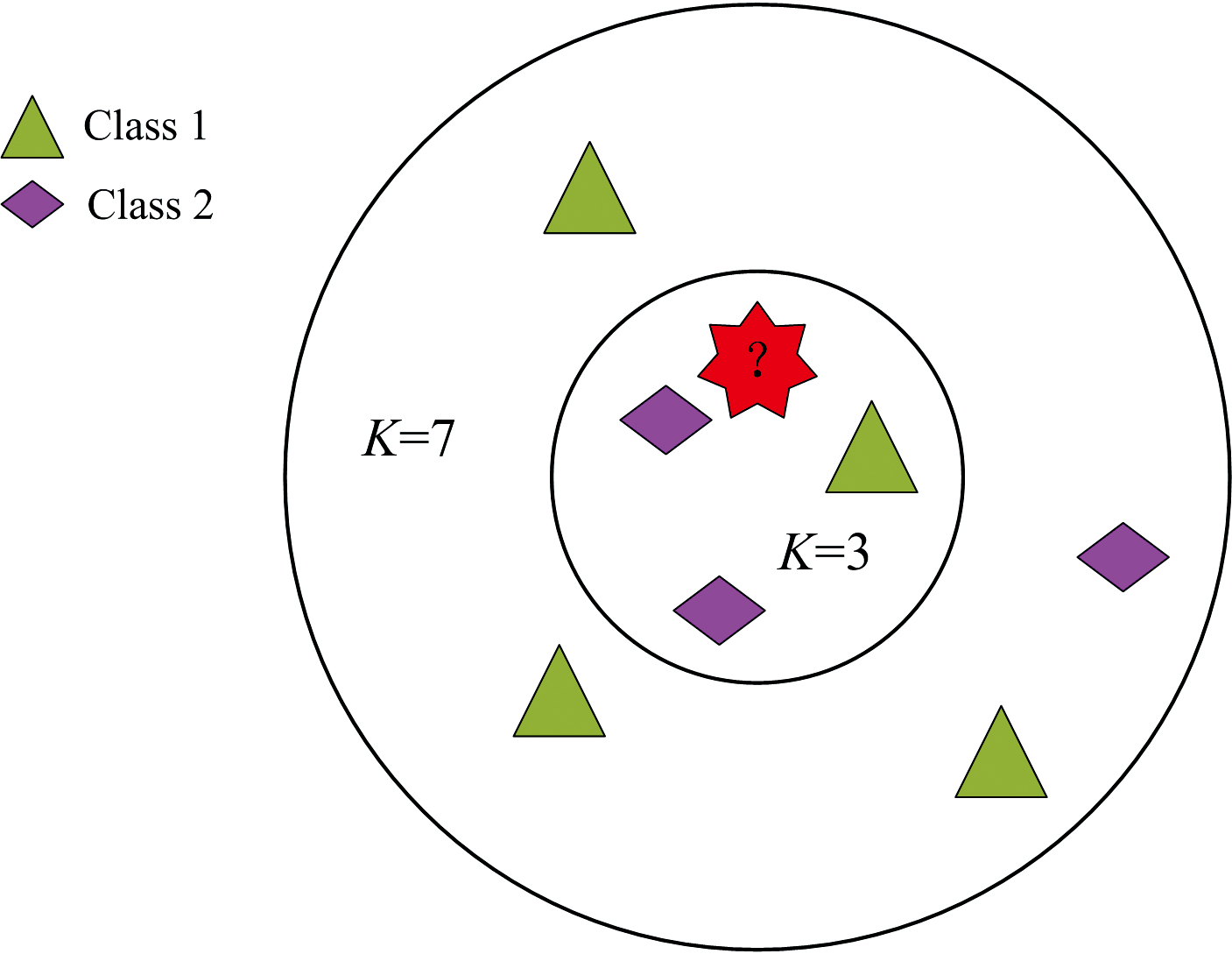 | 图3 KNN算法分类示意图Fig.3 KNN algorithm schematic diagram |
SVM算法作为一种有监督的算法, 在应对小样本、 高度非线性问题方面具有强大的优势。 其思想方法为利用间隔最大化实现分类最优化。 核函数将原始特征变换映射到高维空间, 构建出最优超平面(要求超平面与不同类别样本集的距离为最大), 训练集不同类型的样本点分布在最优超平面两侧, 测试集的判别类别由距离最优超平面最近的样本点确定[15]。 图4为SVM算法分类示例图, 假设正负样本分别位于H1, H2两侧, Margin代表分类平面间的最大分类间隔。 本文利用RBF核函数构建最优超平面, 惩罚函数C取值范围为0.0~1.0, 多次试验后将其值设置为1.0。
 | 图4 SVM算法最优分类超平面示例图Fig.4 Hyperplane example of SVM algorithm optimal classification |
RF算法是一种灵活、 易于实现、 没有超参数调整的监督型学习算法。 其思想为集成学习, 即随机从数据集中有放回的抽取N个样本, 每个样本随机选取k个特征, 最终选择最佳属性作为节点建立决策树[16]。 随机森林方法不会从数据集中最有意义的属性分支确定所选择的节点, 而是通过从每个节点中选择随机检索到的最佳属性分支确定所有节点。 RF算法多用于分类和回归问题, 对于分类问题, 其输出的类别是由个别树输出结果的众数所决定[17]; 在回归问题中, 将每一棵决策树的输出进行平均得到最终的回归结果。 RF算法原理图如图5所示。
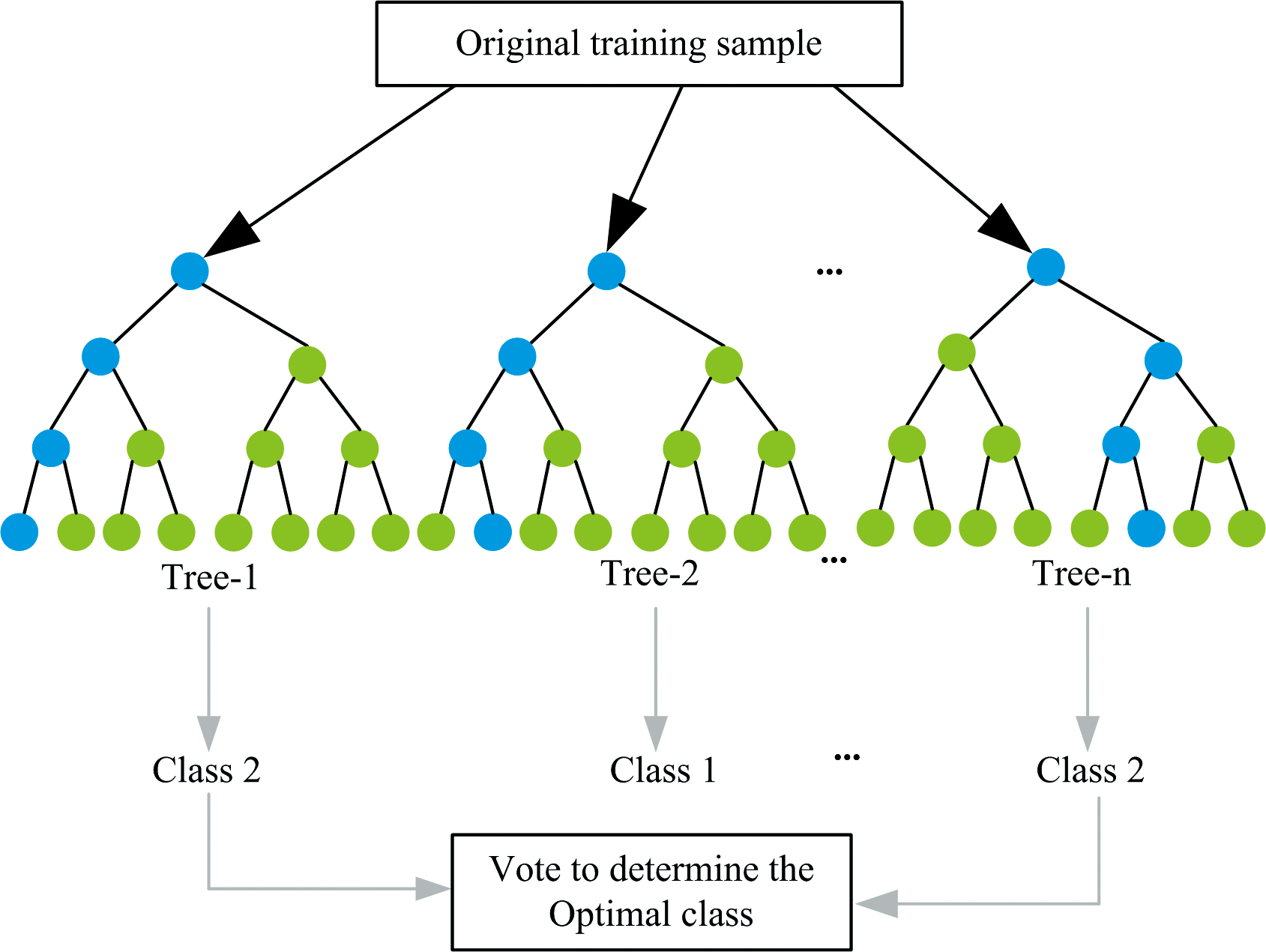 | 图5 RF算法的决策原理Fig.5 RF algorithm decision principle |
1.3.2 评估方法
为了比较KNN、 SVM和RF算法对于乳腺组织荧光光谱的分类能力, 本文使用准确性、 召回率、 精度和F1-score函数四个指标评估算法的分类性能。
准确率: Accuracy=
该公式表达了该系统正确分类的性能。
召回率: Recall=
召回率, 也称为回忆和真阳性率, 是该数据集中实际为真阳性的样本被分类为阳性的概率。 召回率分数越高, 代表算法将癌变组织荧光光谱判断准确的能力越强。
精度: Precision=
精度是检索到的相关实例的分数(实际真正), 是衡量预测正确样本中真实为乳腺癌组织荧光光谱的概率。
F1-score函数: F1=
F1-score函数表征了分类算法对精确度和召回率的综合平衡能力。
在以上公式中[5, 18], TP(True Positive)和FP(False Positive)分别为检测乳腺组织荧光光谱的真、 假阳性, TN(True Negative)和FN(False Negative)分别为检测乳腺组织荧光光谱的真、 假阴性。
使用实验采集的正常和癌变乳腺组织荧光光谱数据作为数据集, 以Python 3.7.0版本为平台, 建立KNN、 SVM和RF算法模型。 算法的准确率、 召回率、 精度和F1-score函数指标结果如图6所示。 KNN和RF算法的性能指标结果均在95%之上, SVM算法的性能指标数据在90%以上。 KNN算法无抽象化步骤, 且依赖周围K个样本点而非类域判别待测点类别, 更适合类域交叉或较多重叠的数据集; RF算法是基于Bagging思想的一种算法, 基决策树采用CATR方法, 每棵树分类时的GINI指数下降来判断数据中各个特征值的重要性并排序, 最后做出最优选择; SVM算法通过最优超平面将数据映射为线性可分、 再做类别判断, 而乳腺组织荧光光谱是多个肩峰部分重叠, 正常与癌变乳腺组织间的荧光光谱有部分面积重叠且存在背景荧光, 因此, 对乳腺正常和癌变组织荧光光谱分类时, 可优先选择使用KNN和RF算法。
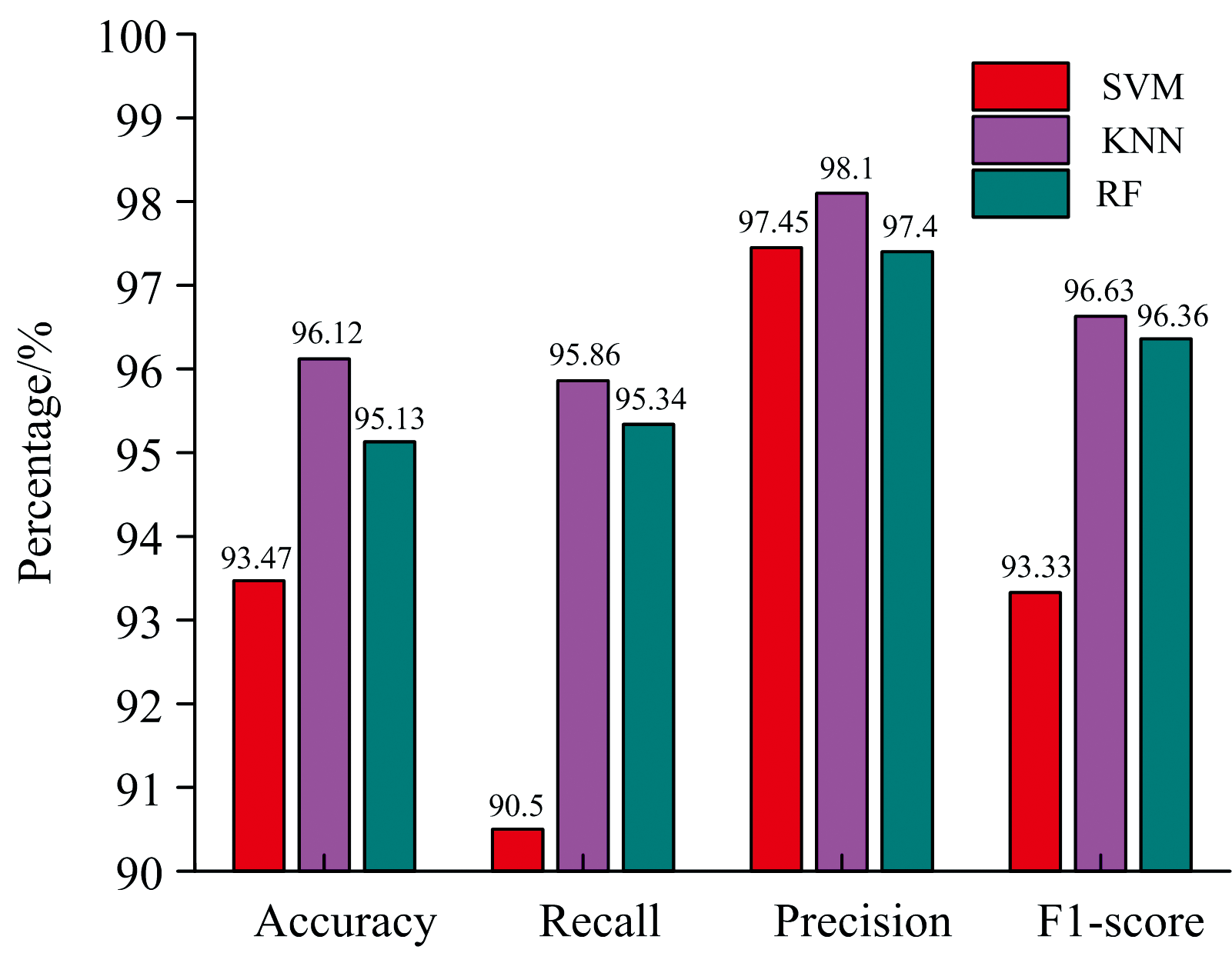 | 图6 KNN、 SVM和RF算法的性能比较Fig.6 Performance comparison of KNN, SVM and RF algorithm |
为了更好地理解算法性能, 本文又给出了三种分类算法的ROC(receiver operating characteristic, ROC)曲线, 称为受试者工作特性曲线, 该曲线的横、 纵坐标分别为假阳性率和真阳性率。 ROC曲线简单、 直观, 综合说明了每种算法对精度、 准确性的平衡能力[19]。 通过比较分类模型的ROC曲线, 可以很容易地丢弃缺陷模型, 选择最优模型进行分类。 由图7可知, 与SVM算法相比, KNN和RF算法对乳腺癌变组织的荧光光谱更加敏感, 对此类数据分类时更具有优势。
 | 图7 KNN、 SVM和RF算法的ROC曲线Fig.7 ROC curve of KNN, SVM and RF algorithm |
KNN算法具有小样本、 精度高的优势, 可用少量标记数据训练高性能分类模型[20], 但未考虑不同样本点的特征权重以及测量鲁棒性, 在一定程度上缺乏对不同样本特征的适应能力, 为了考虑不同特征样本点的权重, 本文提出了加权KNN(weight KNN, WKNN)算法。 WKNN算法分类过程简单, 对不同样本点给予不同的权重, 对测量偏差较大的样本削弱其权重[21]。 距离越近, 特征的权重越大, 分类能力越强。 乳腺组织的荧光光谱特征峰较为集中, 距离倒数权重具有临近点权重较大, 稍远距离样本点权值迅速衰减的优点。 因此, 选择距离倒数权重。 设dist为待预测样本点与某个训练集样本点之间的距离, W为权值, 权重核函数为
核函数的作用是将距离转化为权值, const为常数, 为了避免极端值的出现。 图8(a)为const取不同数值时WKNN算法的指标结果, 由图2(a)可知乳腺正常和癌变组织主光谱特征峰在505~513 nm处具有重叠面, 重叠面中心稍远两侧的样本点, 权重临近判别类型可以显著区分, 因此, const取3.0时分类效果较好。 图8(b)为KNN和const取3.0时WKNN算法性能结果。 不同距离的样本点赋予不同权重使WKNN算法具有更好的抗噪性能和适应能力, 提取乳腺组织荧光光谱特征信息的能力更强。 WKNN算法比KNN算法的分类结果有小幅提升, 分类过程较为简单, 可考虑作为一种用于正常和癌变乳腺组织荧光光谱分类的算法。
 | 图8 KNN和WKNN算法的性能比较Fig.8 Performance comparison of KNN and WKNN algorithm |
机器学习结合荧光光谱技术可以实现对乳腺癌的诊断。 使用波长为405 nm激光获取乳腺正常和癌变组织切片的荧光光谱, 以荧光光谱数据作为数据集, 使用KNN、 SVM、 RF三种算法作为分类模型对乳腺组织是否癌变做出诊断。 结果表明: 与SVM算法相比, KNN和RF算法更适合用于乳腺癌荧光光谱的分类, KNN分类结果在准确率、 召回率和F1-score方面较为优异, 其结果分别为96.12%、 95.86% 和97.30%, RF算法性能比KNN算法稍弱, 指标结果均在95%之上。 WKNN算法易于实现且适应能力和抗噪能力强, 与KNN算法相比, 分类具有优化效果且算法简单, 指标提升范围在0.02%~0.68%内, 因此, 可考虑将WKNN用于乳腺癌荧光光谱的分类。 与数据库中的乳腺组织生化数据信息相比, 实验采集的正常和癌变乳腺组织荧光光谱数据因受电源电压, 细胞环境等多种因素的影响, 具有更多噪声, 导致本实验所得结果与使用数据库数据的分类结果平均性能相比低1.55%~3.94%, 但本实验所得算法指标均在90%以上, 因此, 可用于乳腺组织荧光光谱的分类。 综上, KNN、 RF和WKNN算法是对乳腺组织荧光光谱分类较好的选择, 机器学习结合乳腺组织荧光光谱可用于乳腺癌的诊断。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|