


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
综合光谱纹理和时序信息的油茶遥感提取研究
[孟浩然1, 2  , 李存军
, 李存军1, 3, * , 郑翔宇1, 2 , 宫雨生2 , 刘玉1, 3 , 潘瑜春1, 3 ]
, 李存军, 郑翔宇|
|


作者简介: 孟浩然, 1997年生, 北京市农林科学院信息技术研究中心和辽宁科技大学土木工程学院硕士研究生 e-mail: mhaorann@163.com
具有极高营养价值且被誉为东方“橄榄油”的油茶树是我国南方地区重要经济林, 我国是世界上油茶树分布最广的国家。 提取油茶种植分布和面积对林业部门开展油茶的宏观管理和生产指导具有重要意义。 以地处亚热带地物复杂且多山地丘陵的湖南省常宁市为研究区, 该区域分布有大量农田和森林, 且部分植被季节变化较大, 对油茶的遥感提取带来了很大挑战。 提出了基于春夏秋三期的GF-2号高分辨率卫星影像, 综合植被指数、 纹理特征、 PCA主成分3种特征, 以及春夏、 春秋、 夏秋、 春夏秋四种不同时序组合和随机森林(RF)算法共构建了17种分类场景(S1—S17), 运用随机森林(RF)、 支持向量机(SVM)、 最大似然(MLC)三种不同分类算法开展油茶遥感提取实验, 筛选出最优特征组合、 最佳分类季节与最优时序组合、 最优分类方法。 结果表明: 仅基于光谱信息分类精度低, 纹理特征的加入可大幅提升精度, 而PCA对于精度的提升效果微弱; 通过比较不同季节单时期的分类结果发现油茶提取精度最高的季节为夏季, 夏季单时期影像在最优特征组合(S8)中油茶生产者精度(PA)为94.06%, 油茶用户精度(UA)为92.57%; 在分类场景S10—S17中实验发现, 采用时序信息要比单时期影像有明显的精度提升, 时序组合分类精度由高到低依次为: 春夏秋、 春夏、 春秋、 夏秋; 综合光谱、 纹理、 时序信息通过随机森林(RF)、 支持向量机(SVM)、 最大似然(MLC)进行油茶提取, 随机森林算法分类精度总体表现最好。 采用春夏秋多时相遥感植被指数、 纹理、 PCA的随机森林方法(S17)是分类精度最高的方案, 总体精度(OA)和Kappa系数分别为96.85%和0.961 0, 油茶生产者精度(PA)为98.31%, 油茶用户精度(UA)为94.33%; 采用春夏时相遥感植被指数、 纹理的随机森林方法(S10)为兼顾计算效率与精度的最优方案, 总体精度(OA)和Kappa系数分别为95.62%和0.9458, 油茶生产者精度(PA)为96.93%, 油茶用户精度(UA)为95.09%。 所提出的最佳油茶遥感提取方案能够为亚热带地区油茶及其他经济林的遥感监测提供参考。
Camellia oleifera, which has high nutritional value and is known as oriental “olive oil”, is an important economic forest in southern China, and China has the widest distribution of Camellia oleifera in the world. Extracting the distribution and planting area of Camellia oleifera is significant for forestry departments to carry out macro-management and production guidance of Camellia oleifera. Changning City, Hunan Province, located in a subtropical zone with complex object features and many mountains and hills, is the study area. Many farmland and forests are distributed in this subtropic area, and some vegetation varies greatly in different seasons, which brings great challenges to remote sensing extraction of Camellia oleifera. This paper uses GF-2 high-resolution satellite images in spring, summer and autumn. Combining vegetation index, texture features, PCA principal components, and four different time series combinations in spring and summer, spring and autumn, summer and autumn, and random forest algorithm, 17 classification scenes (S1—S17) were constructed. Three classification algorithms, random forest, support vector machine and maximum likelihood, were used to carry out remote sensing extraction experiments of Camellia oleiferato select the optimal feature combination, classification season, time series combination and optimal classification method. The results show that the classification accuracy based only on spectral information is low, and the addition of texture features can greatly improve the accuracy, while PCA has a weak effect on improving the accuracy; By comparing the classification results of single-period remote sense data in different seasons, it is found that the season with the highest extraction accuracy of Camellia oleifera is summer. With the summer image of the optimal feature combination (S8), the producer accuracy of Camellia oleifera is 94.06%, and the user accuracy of Camellia oleifera is 92.57%. In the classification scenes S10—S17, it is found that the accuracy of using time series information is improved compared with that of single-period images, and the classification accuracy of time series combination from high to low is: spring, summer and autumn, spring and summer, spring and autumn, summer and autumn. Random Forest, Support Vector Machine and Maximum Likelihood are used to extract Camellia oleifera by integrating spectral, texture and time series information, and the classification accuracy of random forest algorithm is the best in general. The therandom forest method (S17) using multi-temporal remote sensing vegetation index, texture and PCA in spring, summer and autumn is the scheme with the highest classification accuracy. The overall accuracy and Kappa coefficient are 96.85% and 0.961 0 respectively, and the producer accuracy of Camellia oleifera is 98.31%, and the user accuracy of Camellia oleifera is 94.33%. The random forest method (S10) using remote sensing vegetation index and texture in spring and summeris the best scheme with calculation efficiency and classification accuracy. The overall accuracy and Kappa coefficient are 95.62% and 0.945 8, respectively. The producer and user accuracy of Camellia oleifera are 96.93% and 95.09%, respectively. The best remote sensing extraction scheme of Camellia oleifera proposed in this paper can provide a reference for remote sensing monitoring of Camellia oleifera and other economic forest extraction in subtropical areas.
具有极高营养价值的油茶树是我国特有的木本油料树种, 同时还是世界四大食用木本油料树种之一, 油茶树属于常绿小乔木, 世界范围内油茶只分布在我国南方以及南亚和东南亚少数地区, 其中我国种植范围占90%之多, 多分布于南方山区丘陵地带。 目前我国油茶种植面积超过430万hm2遍布我国南方14个省份, 其中湖南省油茶种植面积超过140万hm2, 年产茶籽105万吨, 其种植面积、 产量均居各地之首。 湖南省有51个贫困县种植了油茶, 总产值达到1 024亿元, 已在山区乡村振兴中发挥了重要作用。 近年来遥感技术的快速发展为油茶的面积提取和长势监测提供了契机。 区域油茶遥感监测能够辅助当地相关部门开展油茶种植生产管理、 提高生产效率, 对油茶估产、 收购、 电商销售以及农技服务等提供帮助。
遥感技术自诞生以来在农林业领域得到了广泛的应用, 其主要应用于大尺度农作物和森林的面积提取、 长势监测以及病虫害监测等工作。 近年来, 遥感被逐渐应用于茶园、 果园、 油茶等经济林的监测中。 王斌[1]等采用Landsat8遥感卫星影像结合随机森林算法对浙江省安吉县进行了县域尺度的茶园提取, 并取得了较好的提取结果。 陈健[2]等基于机载MASTER数据对果园进行叶面积指数的遥感反演。 徐晗泽宇[3]等基于Google Earth Engine平台收集了大量Landsat影像对赣南地区的柑橘果园进行遥感提取, 并分析了赣南地区柑橘果园在16年间的扩张动态。 油茶遥感监测研究应用尚处于起步阶段, 严恩萍[4]等利用无人机遥感采用Mask RCNN对油茶进行了产量的快速估算。 然而油茶地处我国热带和亚热带地区, 云雨天气较多, 不利于遥感影像的获取和解译, 同时地物破碎复杂, 给区域油茶的遥感提取工作带来了很大困难。 近年来光谱、 纹理、 时序信息被广泛应用于地物的遥感分类中, 三种信息的运用有助于提升复杂地物的分类精度。
植被指数在遥感影像分类中已经被广泛应用, 并且已经成为遥感影像分类中最基本最重要的特征。 张悦琦[5]等基于GF-6号卫星影像利用归一化植被指数(NDVI)精确提取了辽宁地区水稻的种植面积。 有研究采用归一化植被指数(NDVI)和归一化水体指数(NDWI)基于GF-1号WFV影像成功实现了水稻信息的提取。 赵庆展[6]等采用归一化植被指数(NDVI)、 归一化绿度差值指数(NDGI)、 绿色比值植被指数(GRVI)等植被指数实现了新疆地区防护林树种的分类。
高空间分辨率的遥感数据纹理信息较丰富, 但存在波段信息不够丰富的问题, 往往导致分类精度受到一定的限制, 因此单纯靠光谱信息进行地物的分类存在一定的缺陷, 在植被指数的基础上添加纹理信息可以有效提升植被的分类精度[7]。 如杨红艳[8]等基于无人机高光谱影像, 运用光谱和纹理信息相结合的方式成功实现了内蒙古地区荒漠草原植被的分类。 张超[9]等采用高分辨率影像结合纹理特征进行了制种玉米田的识别, 并解决了影像中作物纹理的方向性问题, 获得了较高的精度。
多时相遥感影像具有更丰富的物候信息[10]。 采用时间序列的遥感影像可以完成更高精度的地物提取[11, 12, 13], 多时相影像进行植被的分类工作可以有效降低“ 同物异谱” 和“ 同谱异物” 现象。 陶欢[14]等基于多时相GF-1影像, 通过构建时序NDVI特征集监测安徽省蚌埠市森林植被的分布情况和面积信息。 柏佳[15]等基于GF-1和Sentinel-2数据, 通过获得完整的Sentinel-2号NDVI时序数据, 实现了浙江省金华市武义县的茶园提取。 有报道采用36景GF-1影像, 构建时序NDVI特征, 通过对比不同时间尺度的时序NDVI光谱特征, 探究不同时序组合对内蒙古地区优势树种的分类精度, 证明了时间序列影像中所包含的物候信息对于树种的区分非常重要。
本工作针对亚热带地区植被复杂、 油茶遥感提取困难的问题, 将以上方法进行综合, 以湖南省常宁市东北部地区为研究区域, 综合春夏秋三个时期GF-2遥感影像的植被指数、 纹理特征、 PCA主成分, 分别研究单一特征、 多特征组合、 单一时相、 多时相组合等多种组合方案, 共17个分类场景, 探究分析不同特征不同时相对油茶分类精度的影响程度。 最后对比随机森林(RF)、 支持向量机(SVM)、 最大似然(MLC)三种分类方法的分类精度, 以期在特征组合、 时序组合和分类方法三个方面筛选出适合油茶遥感特征提取的最佳方案。
研究区位于湖南省衡阳常宁市, 北纬26° 07'— 26° 36', 东经112° 07'— 112° 41'。 如图1所示, 常宁市位于湖南省南部, 湘江中游南岸, 总占地面积约2 046 km2, 地势南高北低, 大致呈两极阶梯型分布, 境内多为山地和低矮的丘陵, 平原面积约占37%。 常宁市以水稻土、 红壤土、 紫色土、 黄壤土面积较大分布较广, 利用率最高。 该地区属于亚热带季风性湿润气候, 气候温暖湿润, 雨量充沛, 非常适合油茶的生长[16]。 常宁被誉为油茶之乡, 现有油茶种植面积近100万亩, 是全国油茶原产区和核心产区之一, “ 常宁油茶” 已成为国家地理标志保护产品。
 | 图1 研究区概况Fig.1 Overview of the study area |
常宁地区植被类型复杂, 既存在四季常绿森林又存在季节变色阔叶林, 同时还存在大量耕地, 季节变色阔叶林在春季与油茶光谱信息相似极易混淆, 而油茶种植园具有自己独特的纹理特征。
1.2.1 遥感数据预处理
选用2021年2.18号(春)、 6.26号(夏)、 9.28号(秋)三期GF-2号PMS影像开展油茶遥感监测。 GF-2PMS数据具有全色1 m, 多光谱4 m分辨率, 幅宽为45 km, 重访周期为5 d。 包含有1个全色波段和4个多光谱波段, 分别为: 全色0.45~0.90 μ m, 蓝波段 0.45~0.52 μ m、 绿波段0.52~0.59 μ m、 红波段0.63~0.69 μ m、 近红外波段0.77~0.89 μ m。 对GF-2数据进行预处理工作包括: 辐射定标、 大气校正、 正射校正、 图像融合、 几何精校正、 裁剪。 大气校正采用FLAASH大气校正模型; 正射校正基于ASTER GDEM数据进行, 在地理空间数据云网站可免费获得; 图像融合采用NNDiffuse算法, 针对国产GF-2影像, NNDiffuse算法比施密特正交化(GS)算法整体融合效果更好; 几何精校正基于0.6 m分辨率的google影像进行, 通过选取控制点, 采用仿射变换(RST)算法进行校正; 最后进行影像的裁剪, 得到研究区域面积为255 km2。
1.2.2 影像去云处理
6.26号影像云层覆盖率为2%, 为避免云层对实验结果的影响, 对云层进行去除。 在GEE平台内搜索和生成特定时间段内少云或无云的Sentinel-2影像, 该影像为L2A级影像, 对影像进行波段叠加、 相对几何校正处理, 将对应区域进行裁剪并重采样, 替换到GF-2影像的有云区域, 从而实现GF-2影像云层的去除。
1.2.3 地面调查数据
为了保证在卫星影像上面选择样本区域的准确性, 在研究区进行实地调查, 采用便携式GPS定位设备记录油茶园的位置信息, 误差在5 m以内。 将采集到的点位信息导入Arcgis来确定油茶园的位置。 主要地物包括: 油茶、 四季常绿森林、 季节变色阔叶林、 农田、 村镇及道路、 水体共六种地物。
1.3.1 分类特征
(1)植被指数
植被指数利用植被对不同波段光之间有不同的反射和吸收作用这一特点, 通过波段运算来反映不同植被之间的差异。 选择4个植被指数作为光谱特征, 分别为归一化植被指数(NDVI), 比值植被指数(RVI), 归一化绿度差值指数(NDGI), 绿色比值植被指数(GRVI)。 植被对不同波段光有不同的吸收和反射, 对中心波长为450 nm的波段(蓝波段)和650 nm的波段(红波段)有吸收作用, 在中心波长为540 nm的波段(绿波段)有小幅度反射谷, 而在中心波长为820 nm的波段(近红外波段)有极强的反射谷。 归一化植被指数(NDVI)利用绿色植被对于近红外波段高反射, 对红光波段强吸收的特点, 很好地突出了绿色植被, 归一化植被指数是被用于植被分类最为广泛的植被指数之一[见式(1)]。 比值植被指数(RVI)对植被覆盖密集区反应敏感, 因此能够很好地区分植被和非植被如式(2)。 归一化绿度差值指数(NDGI)和绿色比值植被指数(GRVI)运用了植被对绿波段的反射作用, 突出体现绿色植被, 见式(3)和式(4)
式(1)— 式(4)中, ρ nir表示近红外波段, ρ r表示红波段, ρ g表示绿波段。
(2)纹理特征
油茶园多分布在低矮丘陵以梯田的形式存在, 具有很明显独特的纹理特征, 当地农田多以不规则块状形式存在, 同样具有较为明显的纹理特点, 地物之间在纹理分布方面具有一定的差异。 通过灰度共生矩阵(gray level co-occurrence matrix, GLCM)计算了8个纹理特征参数, 分别是均值(mean)、 方差(variance)、 协同性(homogeneity)、 对比度(contrast)、 相异性(dissimilarity)、 信息熵(entropy)、 二阶矩(second moment)、 相关性(correlation)。 灰度共生矩阵以7× 7为纹理计算窗口, 基于GF2影像的全色波段数据进行计算。
为了避免纹理信息过多造成特征冗余从而降低计算效率, 采用随机森林算法对8个纹理信息进行重要性评价, 通过判断样本X对袋外数据(OOB)误差的影响程度来判定每个特征的重要性, 重要性得分越高说明该特征对分类结果影响程度越大。 当树的数量设置为100时结果基本稳定。 分别对三期影像的纹理特征进行特征重要性计算, 纹理特征重要性排序如图2所示, 其中(a)为2.18号纹理特征重要序列; (b)是6.26号纹理特征重要序列; (c)是9.28号纹理特征重要序列。
 | 图2 纹理特征重要性 (a): 2.18号影像纹理特征重要性排序; (b): 6.26号影像纹理特征重要排序; (c): 9.28号影像纹理特征重要排序Fig.2 Weight of texture features (a): Image texture feature importance raking on February 18; (b): Image texture feature importance raking on June 26; (c): Image texture feature importance raking on September 28 |
选取每一期影像重要性得分排名前三名的纹理特征作为分类特征, 如图2(a, b, c)所示, 三期影像的纹理特征选取结果汇总如表1所示。
| 表1 不同时期影像纹理特征选择 Table 1 Selection of image texture features in various periods |
(3)PCA主成分
主成分分析是一种数据降维的算法, 通过去除特征之间的冗余信息得到若干个不相关的特征也就是主要成分, 从而起到数据降维的作用。 GF-2影像包含4个波段, 分别是蓝波段、 绿波段、 红波段、 近红外波段, 采用PCA主成分变换方法分别对三个时期影像的四个波段进行主成分变换, 最终得到: 2.18号影像前两个主成分PCA1和PCA2包含全部波段98.67%的信息; 6.26号影像前两个主成分PCA1和PCA2包含全部波段99.43%的信息; 9.28号影像前两个主成分PCA1和PCA2包含全部波段的98.99%的信息, 能充分反映地物信息, 因此选取每期影像的前两个主成分PCA1和PCA2作为分类特征。
1.3.2 分类方法
采用随机森林(RF)、 支持向量机(SVM)、 最大似然(MLC)三种分类方法进行实验。 随机森林算法是运用集成学习的思想, 将多棵决策树进行集成, 决策树是其基本单元[17], 采用有放回(bootstrap)随机采样方法抽取n个样本进行训练, 最终通过每棵决策树的投票结果来确定最终的分类结果。 随机森林的特点是能够有效的在大数据集上运行, 具有很高的预测精度; 运行效率高; 稳定性强。 支持向量机(SVM)是一种基于统计学习的监督分类方法, SVM可以自动寻找那些对类别区分能力较大的支持向量, 将类别间的差别最大化, 支持向量机具有优秀的泛化能力和较高的分类精度。 最大似然(MLC)算法是通过计算待分类样本属于各类别的概率, 将该样本归于最大概率的一组从而实现分类, 最大似然算法具有应用简单、 速度快、 效率高的优点。 很多学者对三种分类方法的分类精度进行了研究, 在使用不同的遥感数据研究不同的分类对象时, 这三种分类算法都会表现出不同的分类精度[16], 研究目标的变换会对分类方法的精度产生一定的影响。 本研究对不同的分类算法进行评估, 以筛选出最适合油茶作物的分类方法。
基于0.6m分辨率的google影像, 结合地面实测数据选择训练样本, 共选择了230个训练样本用于训练, 选择了487个验证样本进行精度的验证。
1.3.3 分类场景
利用植被指数、 纹理特征、 PCA、 时序组合以及随机森林(RF)算法共构建了17种分类场景, 如表2所示, (a)是2.18号纹理特征重要序列; (b)是6.26号纹理特征重要序列; (c)是9.28号纹理特征重要序列。 场景S1— S9包含三种特征组合(1): 植被指数; (2): 植被指数+纹理特征; (3): 植被指数+纹理特征+PCA主成分。 场景S10— S17是基于优选特征组合建立的时序组合, 包含四个时序组合: (1)春夏、 (2)春秋、 (3)夏秋、 (4)春夏秋。
| 表2 分类场景 Table 2 Classification scenarios |
对分类结果的精度评价采用四个指标, 分别是总体分类精度(overall accuracy, OA)、 Kappa系数、 生产者精度(producer accuracy, PA), 用户精度(user accuracy, UA)。 四个指标基于混淆矩阵进行计算, 如式(5)— 式(8)。
其中, N表示训练样本的个数, n表示分类类别数; 总体精度OA指所有类别被正确分类的验证点数占总体验证点数量的百分比; Kappa系数是用来评价分类结果与真实结果一致性的指标, 其值在0-1之间, 其值越大说明一致性越好, 分类精度越高; 生产者精度是指该类别的真实数据被正确分类的概率; 用户精度是指落在该类别的检验点被正确分为该类的比例。
用随机森林算法(RF)对不同特征组合进行分类(场景S1— S9), 得到分类结果如表3所示。
| 表3 不同特征组合分类结果 Table 3 Statistics of classification results of different feature combinations |
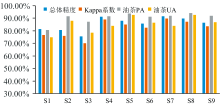
如图3所示, 在三期影像中, 分类精度最高的特征组合均为: 植被指数+纹理特征+PCA, 但是植被指数+纹理特征+PCA相对于植被指数+纹理特征精度提升微小。 因此, 此次实验表明: 纹理特征对于油茶提取精度的提升具有很大影响, 可大幅提高分类精度; PCA主成分的加入也可提升分类精度, 但是在植被指数和纹理特征的基础上再加入PCA主成分精度提升微弱。
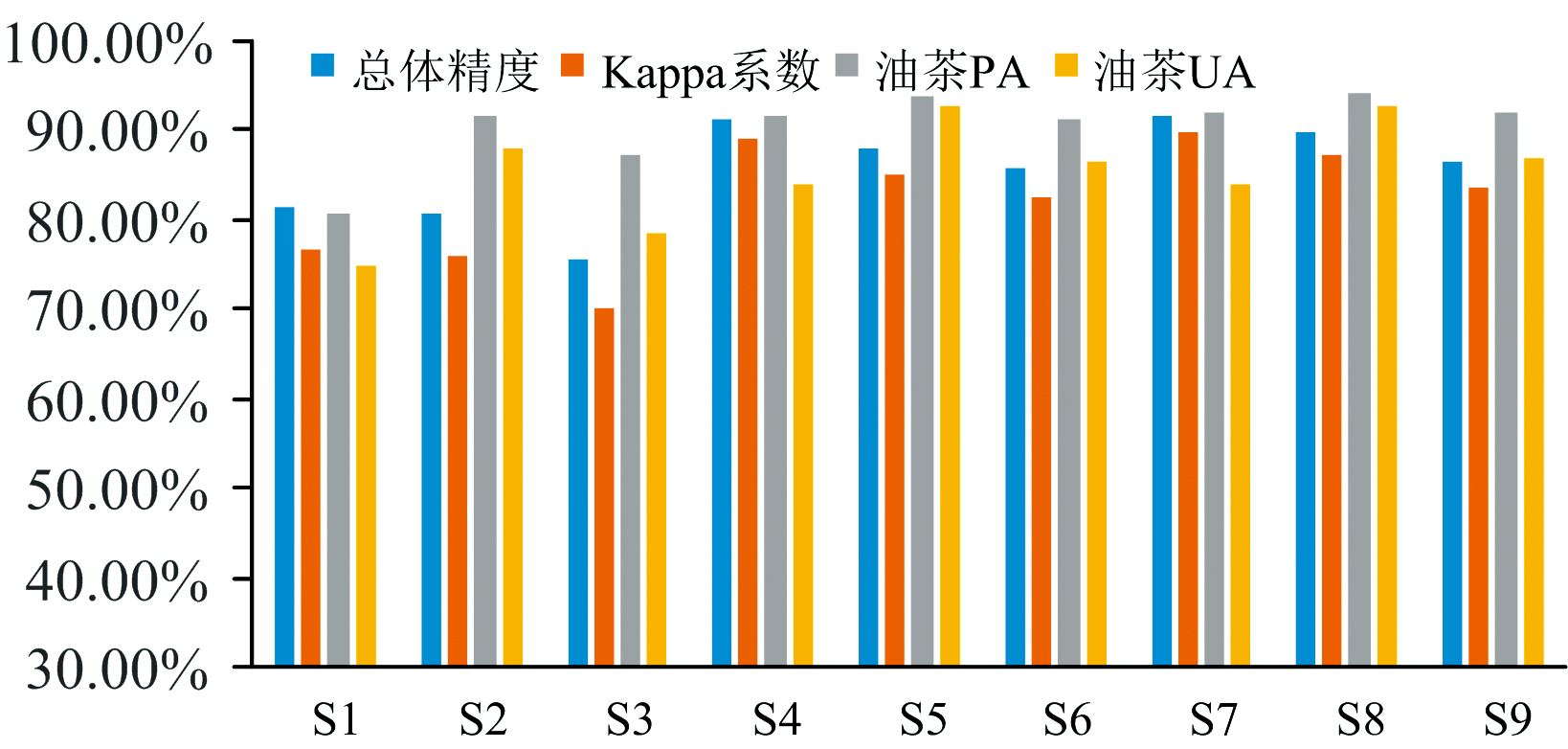 | 图3 不同特征组合分类精度对比Fig.3 Comparison of classification accuracy of different feature combination |
通过对比S7— S9发现: (1)2.18号(春季)影像的总体分类精度最高, 为91.68%, 但油茶的分类精度较低, 油茶生产者精度PA为91.90%, 油茶用户精度UA为84.01%, 原因是2月份时, 当地的变色阔叶林与油茶具有很相似的光谱特征, 导致油茶和变色阔叶林错分情况严重。 (2)6.26号(夏季)总体分类精度略低于2月份, 但是油茶分类精度最高, 油茶生产者精度PA为94.06%, 油茶用户精度UA为92.57%, 原因是夏季阔叶林变为绿色, 与油茶的区分度变大, 因此更有利于油茶的分类, 但是其光谱信息与常绿森林和农田接近, 导致了三者之间有大量的错分现象, 并且此三种地物具有很大的分布面积从而使得总体精度降低。 (3)9.28号(秋季)影像总体分类精度最低, 原因是变色阔叶林仍处于绿色状态, 光谱值与常绿森林区分度不大, 再加上秋季农田变化比较复杂, 光谱差异较大, 容易与多种地物混淆, 导致错分现象严重。 综上所述, 单期影像中最有利于油茶提取的季节是夏季。
与单时期影像相比, 多时相影像会包含更丰富的物候信息, 场景S1— S9的实验表明, 植被指数+纹理特征(S4— S6)的特征组合与植被指数+纹理特征+PCA(S7— S9)的特征组合分类精度相当, 后者(S7— S9)略高于前者(S4— S6)。 以这两种特征组合方案里面的特征为基础, 构建时序特征组合, 分别为春夏、 春秋、 夏秋、 春夏秋, 从而构建了8种分类场景分别为S10— S17(见表2)。 如表4所示为8种分类场景(S10— S17)的分类结果。
| 表4 时序组合分类结果 Table 4 Classification results of time series combination |
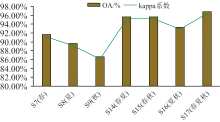
如图4所示, 时序组合后的总体分类精度OA和Kappa系数比单时期的分类精度有大幅提升, 说明物候信息对于油茶分类工作具有重要影响, 原因是当地有较多季节变色阔叶林, 阔叶林季节变化较大; 当地有大片的农田, 农田地物较为复杂, 不同季节的光谱信息差异较大, 比较容易导致油茶的错分; 而油茶为常绿小乔木, 四季变化不大。
 | 图4 时序组合与单期影像分类精度对比Fig.4 Comparison of classification accuracy between time sequence combination and single period image |
通过不同时序的精度对比可以发现, 物候信息对当地油茶提取精度影响很大, 其中精度最高的是春夏秋时序组合; 其次是春夏时序组合, 春夏时序组合略微高于春秋时序组合; 精度最低的是夏秋时序组合。
在两两时序组合中, 以S14— S16分类结果为例, 春夏时序组合分类精度最高, 总体分类精度OA为95.68%, Kappa系数为0.946 4, 油茶生产者精度PA为97.11%, 油茶用户精度UA为94.91%; 春秋时序组合略低; 夏秋时序组合精度最低; 原因是春季万物处于待生长状态, 植被指数处于很低的水平, 而夏季是各植被生长最为旺盛的时候, 春夏物候差异很大, 包含更丰富的物候信息, 因此春夏时序组合具有最高的分类精度; 而秋季各植被仍处于生长较为茂盛的状态, 夏秋之间的物候差异较小, 所包含的物候信息相对较少, 导致夏秋时序组合精度最低。
春夏秋时序组合总体分类精度、 油茶PA和kappa系数最高, 总体分类精度为96.85%, Kappa系数为0.961 0, 油茶PA为98.31%, 较春夏时序组合分别提升了1.17%、 0.014 6和1.2%; 原因是春夏秋三个时序组合包含的物候信息更加丰富, 更能增加各类地物之间的区分度。
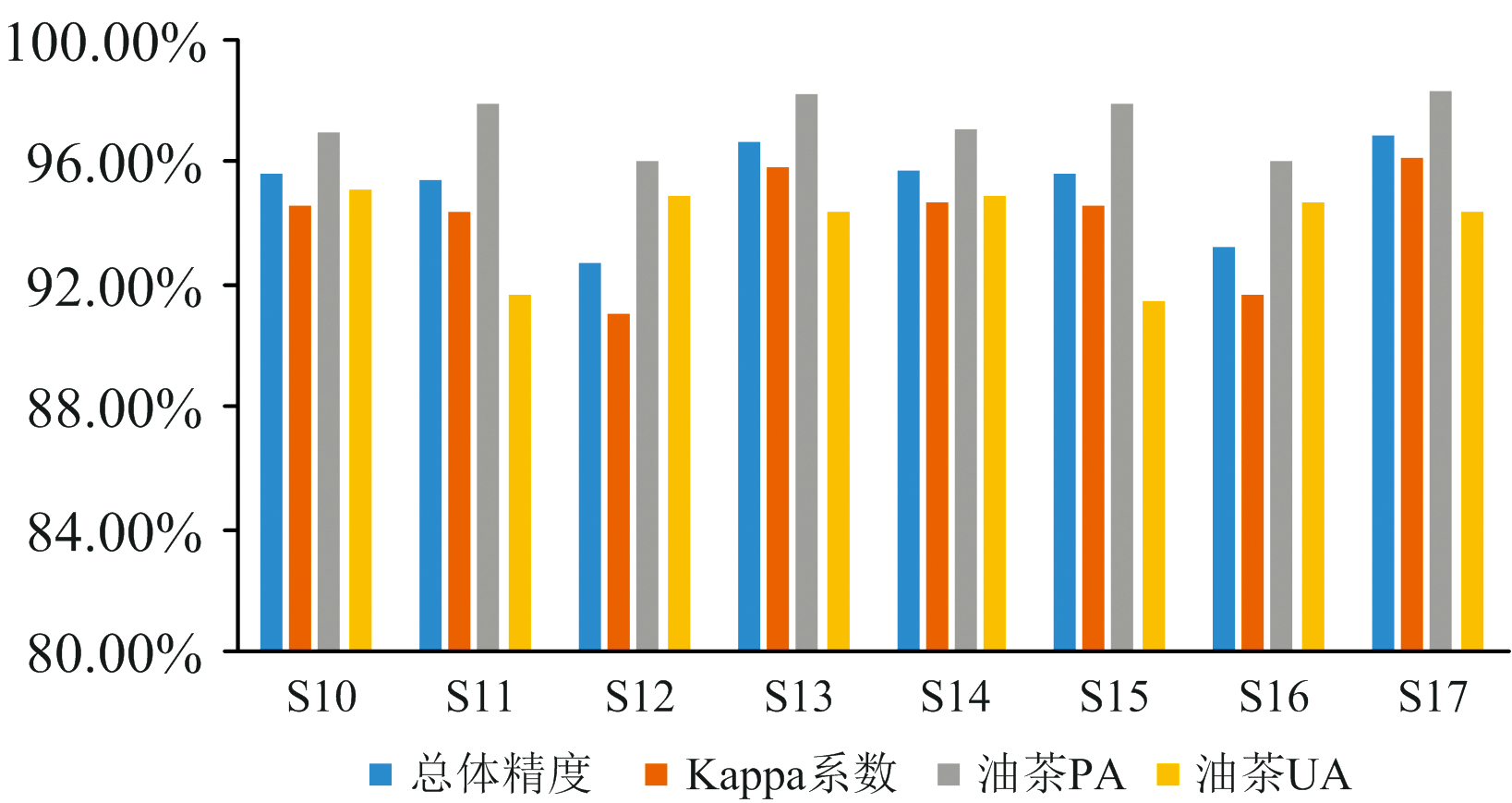 | 图5 不同时序组合之间分类精度对比Fig.5 Precision comparison between different time sequence combinations |
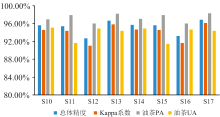
由于场景S10与S17分类精度相差不大, 并且S10具有分类特征少, 效率高的优势, 选择S10和S17两种分类场景中的特征和时序组合对随机森林(RF)、 支持向量机(SVM)、 最大似然(MLC)三种分类方法进行精度的对比。 赵庆展[6]等指出, 由于在面对不同的分类树种以及不同数据源时, 三种分类方法的精度会有差异, 因此将三种分类方法进行对比很有必要, 以期得出最适合油茶的分类方法。 表5为场景S10和S17在三种不同分类方法下的分类精度。
| 表5 不同分类方法精度对比 Table 5 Precision comparison of different classification methods |
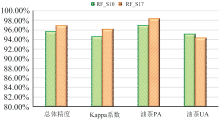
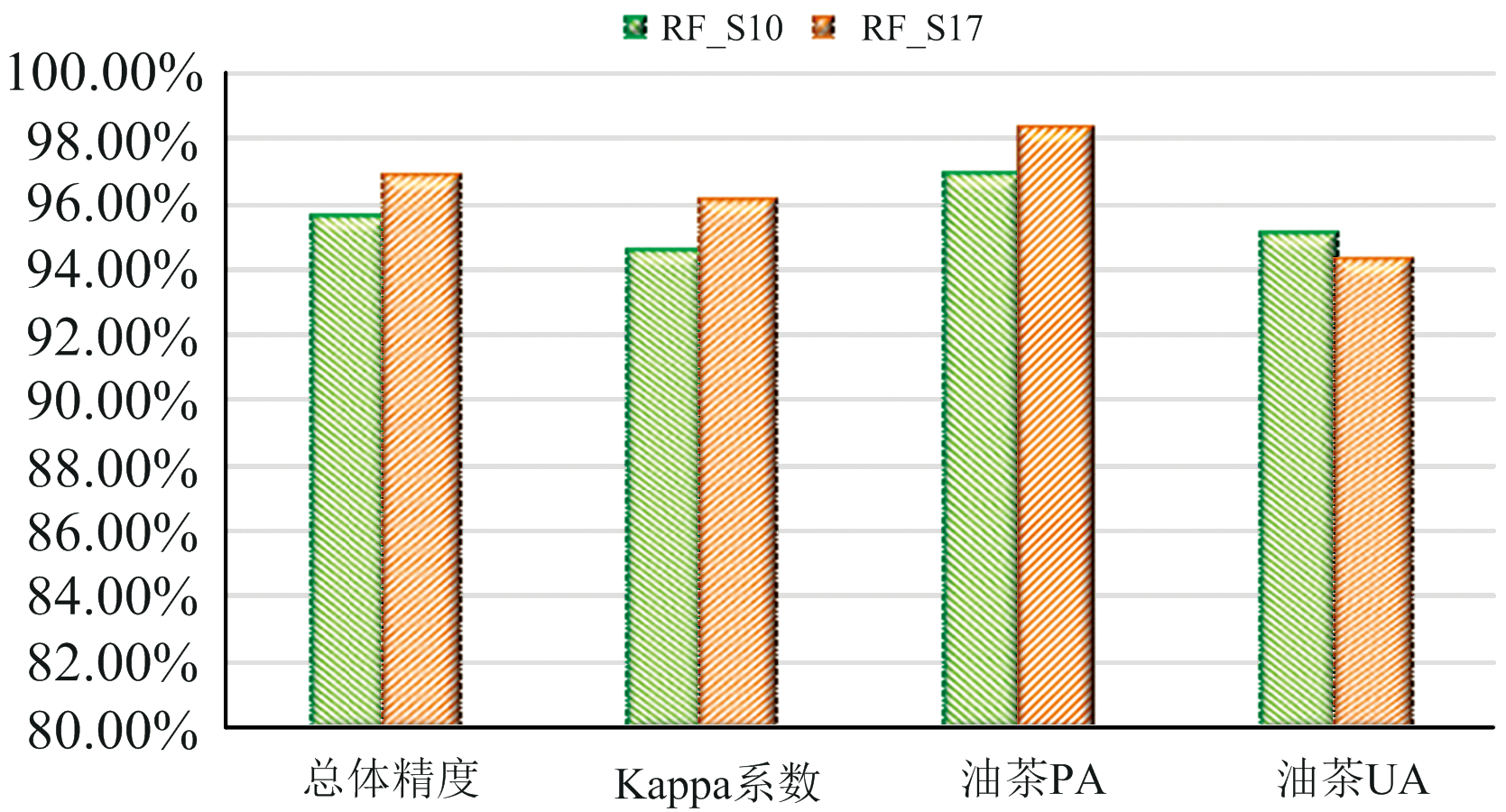
如图6可见, 在S10和S17中, 随机森林(RF)算法均具有最高的总体分类精度和Kappa系数; 在S10中, 随机森林(RF)算法的总体精度OA、 Kappa系数、 油茶PA三个指标均最高, 油茶UA略低于最大似然(MLC)算法, 仅落后1.15%; 在S17中, 总体精度OA、 Kappa系数两项指标最高, 油茶生产者精度PA略低于支持向量机(SVM)算法, 仅落后0.31%, 油茶UA略低于最大似然(MLC)算法, 落后2.53%。 综合考虑, 随机森林算法具有更高的分类精度和稳定性, 是最适合油茶提取的分类方法。
 | 图6 不同分类方法精度对比Fig.6 Precision comparison of different classification methods |
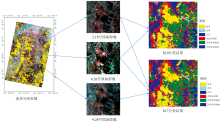
针对不同的用途和需求, 最终推荐两种油茶的提取方案, 第一种方案是S10(春夏时序+植被指数+纹理特征+RF); 第二种方案为S17(春夏秋时序+植被指数+纹理特征+PCA主成分+RF)。 如图8所示, S10精度略低于S17, 但是S10特征组合和时序组合少, 运算速度快效率高, 同时精度较高, 总体精度OA达到了95.62%, Kappa系数达到了0.945 8, 油茶PA达到了96.93%, 油茶UA达到了95.09%, 满足大多数生产需求, 适合大规模的生产工作。 S17中特征组合和时序组合最为复杂, 运算速度相对较慢, 但是精度最高, 适合对精度要求较高的科研工作。 如图7所示为两种方案下的分类结果。
 | 图7 油茶提取结果Fig.7 Extraction results of camellia oleifera |
 | 图8 两种优选分类方案精度对比Fig.8 The accuracy comparison of the two optimal classification schemes |
(1)纹理特征可以大幅提升油茶分类精度, 对复杂地物分类是重要的分类特征(见表2场景S4— S6)。 在植被指数和纹理特征的基础上, PCA的加入只能略微提升分类精度, 精度提升效果微弱(见表2场景S7— S9)。
(2)在单时期影像中, 春季的油茶提取精度最低, 油茶生产者精度(PA)为91.90%, 油茶用户精度(UA)为84.01%; 而夏季油茶的提取精度最高, 油茶生产者精度(PA)为94.06%, 油茶用户精度(UA)为92.57%; 三期影像进行不同的时序组合可以大幅度提升复杂地物的分类精度; 在两两时序组合中, 春夏时序组合精度最高, 春秋时序仅次于春夏, 而夏秋时序精度最低。 春夏秋时序组合精度高于两两时序组合, 即: 春夏秋> 春夏> 春秋> 夏秋。
(3)随机森林(RF)、 支持向量机(SVM)、 最大似然(MLC)三种油茶遥感提取算法中综合表现最好的是随机森林(RF)算法。 随机森林算法不仅精度高同时运算速度也较快。
(4)S17分类方案具有最高的分类精度, 总体分类精度(OA)、 Kappa系数、 油茶PA、 油茶UA分别为96.85%、 0.961 0、 98.31%、 94.33%, 可用于高精度的科研工作; S10分类方案具有更高的运算效率, 精度也较高, 兼顾了精度和计算效率, 总体精度(OA)、 Kappa系数、 油茶PA、 油茶OA分别为95.62%、 0.9458、 96.93%、 95.09%, 可用于高效率的生产工作。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|