
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Transformer特征提取的A型恒星光谱子型分类算法
[李双川 , 屠良平
, 屠良平* , 李馨, 王莉莉]
, 屠良平, 李馨, 王莉莉]
|
|


作者简介: 李双川, 1996年生, 辽宁科技大学理学院硕士研究生 e-mail: 2831748529@qq.com
恒星光谱分类是恒星光谱分析的重要工作之一。 我国大型巡天项目LAMOST能够获得海量的恒星光谱数据, 为了对海量恒星光谱数据进行高效分类, 特别是对恒星光谱子型数据进行分类, 需要研究快速有效的恒星光谱自动分类算法。 提出一种基于Transformer特征提取的混合深度学习算法Bert+svm(简记为Besvm)实现A型恒星光谱子型的自动分类。 该算法将A型恒星光谱26个线指数作为输入特征, 应用Bert模型对26个线指数进行更深层次的学习, 通过学习26个线指数的内在关联, 进而提取到更有利于A型恒星光谱子型分类的特征。 提取好的新特征被输入到分类器算法支持向量机(简记为SVM)中, 进而对A型恒星光谱的三个子型A1、 A2和A3进行自动分类。 此前, SVM算法在恒星光谱分类任务中已经有过应用, 一些衍生的SVM算法在恒星光谱分类任务中也有较高的分类正确率。 相比从前应用到恒星光谱分类任务的SVM算法, 我们的混合深度学习算法受数据的信噪比影响较小, 使用低信噪比数据也能有较高的分类正确率, 并且所用数据量较少。 通过五组实验验证了该算法的有效性和优越性: 实验1用来对比选择优秀的核函数, 通过光谱数据的匹配实验, 最终选择了径向基核函数RBF; 实验2对比了Besvm算法和其他四种传统优秀算法的性能指标, 验证了Besvm算法的优越性; 实验3用来检验Besvm算法的稳定性; 实验4分析了数据量对Besvm算法的影响; 实验5分析了不同信噪比数据对Besvm算法分类正确率的影响。 综合实验结果分析表明, 提出的混合深度学习算法Besvm在规模较小且信噪比低的数据集上仍能保持较高的分类正确率。 Besvm总体分类错误率在0.01以下, 远低于经典传统机器学习算法LDA算法, BP神经网络算法, SVM算法和Xgboost算法的分类错误率0.7, 0.66, 0.65, 0.36.需要说明的是BP神经网络算法的分类正确率过于受限于隐层神经元的个数。
Stellar spectrum classification is one of the important tasks of stellar spectrum analysis. Chinese large-scale survey project LAMOST can obtain massive stellar spectral data. In order to efficiently classify massive stellar spectral data, especially stellar spectral subtype data, we need to study fast and effective stellar spectral automatic classification algorithms. This paper proposes a hybrid deep learning algorithm based on Transformer feature extraction, Bert+svm (abbreviated as Besvm), to classify the spectral subtypes of type A stars automatically. The algorithm takes 26 line indices of the spectrum of A-type stars as input features and uses the Bert model to perform a deeper learning of the 26 line indices. By learning the internal correlation of the 26 line indices, it extracts the spectrum more conducive to the A-type stars classification characteristics. The extracted new features are input into the classifier algorithm Support Vector Machine (SVM for short), and then the three subtypes A1, A2, and A3 of the A-type star spectrum are automatically classified. Previously, the SVM algorithm has been applied in the stellar spectrum classification task, and some derivative SVM algorithms also have a higher classification accuracy rate in the stellar spectrum classification task. Compared with the SVM algorithm previously applied to the stellar spectral classification task, our hybrid deep learning algorithm is less affected by the signal-to-noise ratio of the data, and the low-signal-to-noise ratio data can also have a higher classification accuracy. The amount of data used is relatively small. This paper verifies the effectiveness and superiority of the algorithm through five sets of experiments: Experiment 1 is used to compare and select excellent kernel functions, and through the matching experiment of spectral data, the radial basis kernel function RBF is finally selected; Experiment 2 compares the performance indicators of the Besvm algorithm with the other four traditional excellent algorithms verify the superiority of the Besvm algorithm; Experiment 3 is used to test the stability of the Besvm algorithm; Experiment 4 analyzes the influence of the amount of data on the Besvm algorithm; Experiment 5 analyzes the influence of different signal-to-noise ratios data on the classification accuracy of Besvm algorithm. The analysis of comprehensive experimental results shows that the hybrid deep learning algorithm Besvm proposed in this paper can still maintain a high classification accuracy rate on a small-scale data set with a low signal-to-noise ratio. The overall classification error rate of Besvm is below 0.01, which is much lower than the error rate of the classic traditional machine learning algorithm LDA algorithm, Bp neural network algorithm, SVM algorithm and Xgboost algorithm. The classification accuracy is too limited by the number of hidden neurons.
郭守敬望远镜(LAMOST, 大天区面积多目标光纤光谱天文望远镜)是一架新类型的大视场兼备大口径望远镜, 即“ 王-苏反射施密特望远镜” , 是我国光谱巡天项目的开篇之作。 LAMOST光谱数据处理的官方软件流程是采用模板匹配的方法。 LAMOST自2011年10月先导巡天至2020年3月发布DR7数据, 发布光谱总数达到1448万条: 其中低分辨率光谱1 060万, 中分辨率非时域光谱101万, 中分辨率时域光谱287万, DR7高质量光谱(S/N> 10)达到1 143万条。 DR7数据的发布, 标志着LAMOST光谱发布正式进入千万量级时代, 成为了世界上最大的恒星光谱数据库, 为人类探索银河系做出了巨大的贡献。
LAMOST巡天项目的正式启动, 使人类可以获取海量的恒星光谱数据, 传统的人工光谱分类手段也就无法满足当下的科研需求。 幸运的是, 近些年机器学习、 深度学习领域出现大量优秀算法, 将该领域中的方法应用到恒星光谱分类, 可以成功解决人工光谱分类效率低的问题。 深度学习作为实现机器学习的一种技术, 更具智能化, 更具优越性, 更接近于人工智能。 随着深度学习的快速发展, 深度学习相关算法表现出更快、 更好、 更高效、 更具实用性的优良性能, 这让深度学习相关算法解决恒星光谱分类问题变为了可能。 本文应用深度学习领域中解决NLP任务的Transformer算法, 对A型恒星光谱数据进行特征提取, 然后应用经典机器学习算法SVM进行自动分类, 取得了良好的效果。
Transformer是一种依赖Self-attention来计算输入、 输出的转换模型, 它不使用序列对齐的RNN或者卷积。 这使得Transformer有更好的并行性, 且显著减少了提取A型恒星光谱特征的时间。 Bert是Transformer应用的一个实例, 自提出以来, 在NLP任务中表现优异, 现将其作为特征提取器应用到A型恒星光谱的分类任务中。 很多深度学习算法和机器学习算法已经成功应用到恒星光谱分类任务中, 但将解决NLP任务的算法应用到恒星光谱分类的先例为数不多, 本文所提出的混合深度学习算法Besvm即是对该系列优秀算法应用到A型恒星光谱子型自动分类任务的一次有益尝试。
SVM算法于1964年被正式提出, 在分类任务中表现优异。 由于其有良好的分类性能, 故被人们一直所关注。 在此之前, SVM在恒星光谱分类任务中已有过应用, 且一些衍生的SVM算法在恒星光谱分类任务中有着良好的实验效果。 鉴于此, 我们考虑将深度学习算法同SVM算法结合使用, 以此来实现对恒星光谱的自动分类。 因此, Besvm算法应运而生。
在此之前, 学者们已经搭建了许多优秀的恒星光谱自动分类算法。 Lu等提出了基于二维光谱特征的恒星光谱分类方法[1]; Zhang等提出了一种基于二维傅里叶光谱图像特征提取并进行恒星光谱分类的方法[2]; Li等提出基于17阶多项式拟合对光谱进行归一化处理后, 利用随机森林(RF)对恒星光谱进行分类的方法[3]; Kheirdastan等提出基于PNN的恒星光谱分类算法[4]; Du等提出胶囊网络的恒星光谱分类方法[5]。 Liu等提出基于深度卷积神经网络的恒星光谱分类算法, 该方法将传统的2D卷积神经网络修改为1D网络以适应光谱分类[6]。 Wang等提出利用深度神经网络对光谱进行特征提取, 然后再对光谱进行分类的方法[7]; Du等提出利用贝叶斯支持向量机(BSVM)对光谱子类数据进行分类的方法[8]; Sharma等提出利用卷积神经网络对恒星子型光谱进行分类的方法[9]。
以上恒星光谱分类方法, 均使用了大量的恒星光谱数据。 本文所提出的基于NLP深度学习特征提取器和SVM相结合的恒星光谱分类算法, 所用数据量较少, 但是分类效果良好, 对于不同信噪比数据均有较高的分类正确率。 实验证明本方法可靠、 高效、 稳定。
本算法工作原理如下: 将A型恒星光谱三个子型的线指数作为原始光谱特征, 输入到Bert算法中进行特征提取, 然后将提取出来的新光谱特征输入到SVM算法中进行自动分类。 工作原理如图1, 其中Xi表示输入, B表示Bert(Transformer特征提取过程), Ti表示提取出来的特征向量, S表示自动分类器SVM。
 | 图1 Besvm模型Fig.1 Besvm model |
Bert受到完形填空的启发, 通过“ masked language model” (MLM)预训练目标来缓解单向性约束问题。 Masked语言模型从输入中随机掩盖一些符号, 目标是基于上下文来预测掩盖的原始词汇id。 和left-to-right模型的预训练方式不同, MLM能够融合上下文的信息, 这样就可以训练一个深度的双向Transformer[10]。 对于恒星光谱线指数, Bert模型可以学习线指数隐藏的内在关联, 提取出更优的恒星光谱分类特征。
Transformer是一种encoder-decoder结构的模型。 这种模型摒弃循环结构依赖Attention机制来控制输入、 输出间的全局依赖关系。 每一步的解码, 模型都将先前生成的符号作为附加输入, 用以生成下一个符号, 即模型是自回归的。 Transformer整体架构看似复杂, 本质上是一个Seq2Seq模型结构。
Encoder的每一层有两个操作Self-Attention、 Feed Forward; Decoder每一层有三个操作Self-Attention、 Encoder-Decoder Attention和Feed Forward。 其中Self-Attention和Encoder-Decoder Attention均为Multi-Head Attention机制。
Attention函数为Transformer模型的核心函数, 其计算过程如式(1)
式(1)中headi=Attention(Q
假定训练集X={(x1, y1), …, (xN, yN)}, 共含N个样本, 其中xn∈ RK, 是K维特征向量, yn∈ {1, 2, …, M}, n=1, …, N代表类标签。 在此假定训练集数据共有M个类。 目标就是寻找决策函数y=f(x)进行新数据类别的预测。 训练集数据假定共有M个类, SVM方法的实质: 每两个类之间均构造binary SVM。
对于第i类和第j类来说, 训练一个binary SVM, 即运筹学领域解二次规划问题, 数学模型如式(2)
式(2)中, i和j表示第i类和第j类之间的binary SVM参数; t表示i, j两类并集中的索引; ϕ 表示输入空间到特征空间的非线性映射。 在对上述规划进行求解时, 求解的是上述规划的对偶问题。
线指数用等值宽度的定义进行表示, 数学表达式如式(3)
式(3)中, fline(λ )和fcount(λ )是在伪连续谱上的流量, fcount(λ )为在伪连续谱上插值所获得的值。 表1列出了部分线指数及其伪连续谱波长范围[11]。
| 表1 部分线指数及其伪连续谱范围 Table 1 Partial line index and range of pseudo-continuum |
算法主要有三个模块, 分别为: 线指数提取、 特征提取、 分类。 具体流程如下:
Step 1: 我们从LAMOST-DR7星表中提取A型恒星光谱三个子型的线指数数据, 作为原始恒星光谱分类特征;
Step 2: 将提取出来的A型恒星光谱三个子型的线指数数据作为输入, 输入到Bert算法中进行特征提取, 用以得到更优的分类特征;
Step 3: 整合Bert算法的输出。 因为Bert模型是‘ token’ 级任务, 本文设置Head=128, 因此每条光谱所对应的26个线指数都会产生多个128维向量, 对所有128维向量的对应数据进行加权求和, 用以得到每条光谱数据所对应的128维向量;
Step 4: 将第三步整合好的新光谱特征作为输入, 输入到SVM算法中进行自动分类;
Step 5: 输出层算法SVM输出分类结果。
实验数据来自LAMOST-DR7星表。 本文分类任务: 对A型恒星光谱的三个子型A1、 A2、 A3进行自动分类。 我们从LAMOST-DR7星表中提取A1型光谱数据1 234条、 A2型光谱数据1 213条、 A3型光谱数据1 193条, 将这些光谱数据中的线指数作为原始光谱分类特征。 在多分类任务中, 如果使用机器学习算法作为分类工具, 针对同一个问题, 三分类任务往往有最好的实验效果。 为了同经典机器学习算法最好的实验结果进行比较, 本文进行三分类任务。
本文实验环境为python3.7, 涉及主要python模块有tensorflow1.14、 numpy1.21、 xgboost1.4.2。
4.2.1 实验1: 对比选择核函数
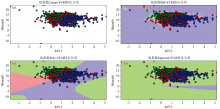
影响SVM算法分类正确率的原因有很多。 其中, 选取不同的核函数对分类正确率有重要影响, 因此选取恰当的核函数就成为了一个重要工作。 为了验证哪一个核函数最适合应用在恒星光谱数据上。 现进行一个匹配实验。 为了更好的可视化, 使用KP12和Hbeta60两个线指数进行一个简化A型恒星光谱分类任务, 将此两个线指数作为简化恒星光谱分类任务的两个分类特征。 在此简化恒星光谱分类任务中, 去测试哪个核函数最适合应用在A型恒星光谱数据上。 在图2中, 彩色圆点的颜色同背景颜色一致代表分类预测结果正确, 否则代表错误。
 | 图2 不同核函数分类比较图Fig.2 Comparison of classification of different kernel functions |
常见的核函数有四种: linear核函数, RBF核函数, poly核函数, sigmoid核函数。 由于A型恒星光谱数据不是线性数据, 因此应用线性核在A型恒星光谱数据上是不合适的。 由图2(a)可以看出, 线性核函数将A1型恒星光谱, A2型恒星光谱, A3型恒星光谱错误的分为了一类, 这显然是不合适的。 在gamma=10的情况下, 从图2可以看出, RBF核函数、 poly核函数、 sigmoid核函数, 效果最好的是图2(b)所示核函数, 即RBF核函数。 图2(c)所示poly核函数, 在A1(绿色)和A3(蓝色)类中包含大量A2(红色)样本。 图2(d)所示的sigmoid核函数, 基本上将A2(红色)、 A3(蓝色)样本归为了A1(绿色)类。 poly核函数, sigmoid核函数应用在恒星光谱数据上时, 误差较大。
因此, 从分类正确率的角度来看, 选择RBF核函数作为A型恒星光谱分类任务的核函数。
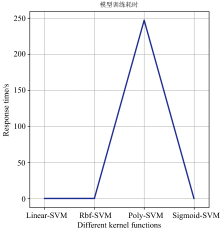
在gamma=10的情况下, 从图3可以看出, poly核函数耗时最长, 其余三个核函数耗时趋近于0。 因为只有两个分类特征, 数据量相对较少, 因此程序运行响应时间不会过长。 从响应时间上看, 也可以选择RBF核函数作为A型恒星光谱分类任务的核函数。 综合评价后, RBF核函数最适合应用在A型恒星光谱分类任务中, 因此在接下来的A型恒星光谱分类实验中, SVM算法均使用RBF核函数。
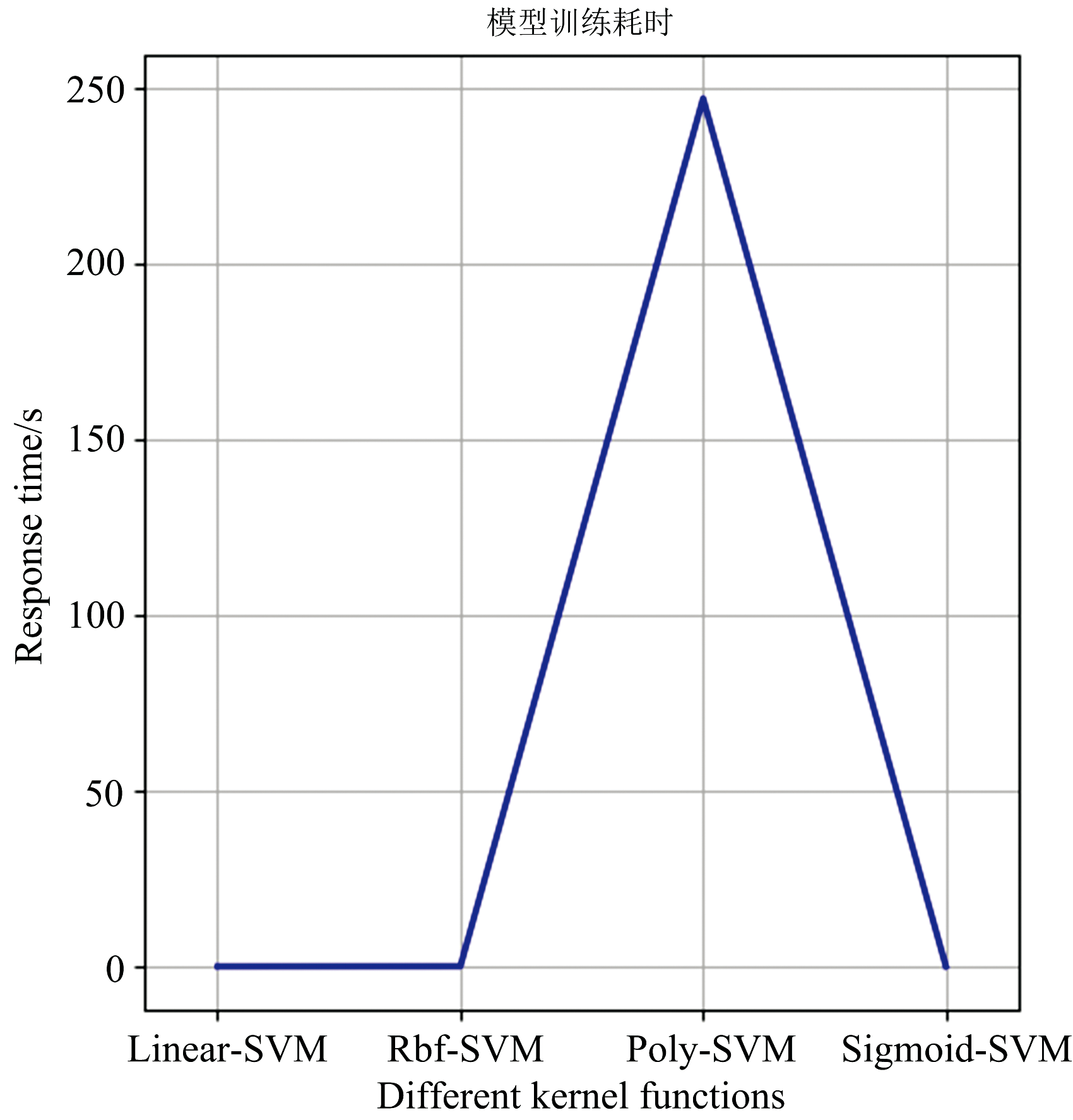 | 图3 不同核函数时间消耗图Fig.3 Time consumption diagram of different kernel functions |
4.2.2 实验2: Besvm算法和传统算法比较
基于相同的数据, 采用对比实验的形式, 考查LDA, BP神经网络, SVM, Xgboost, Besvm五种算法的分类错误率。 LDA, BP神经网络, SVM, Xgboost算法在前人的研究中表现优异, 故用作本文的对比实验。 选用A1型恒星光谱、 A2型恒星光谱、 A3型恒星光谱r波段信噪比大于30的各300条数据作为本次实验数据, 同时将900条数据做好标签。 需要说明的是, 带标签数据是否打乱顺序对本文各算法的最终分类正确率是有影响的。 我们发现, 将此900条带标签实验数据打乱顺序后进行实验, 可以降低分类错误率。 因此, 在接下来的实验中, 本文均将带标签的数据打乱顺序。 本次实验, 各算法所设置参数如表2, 表3所示, 其中RBF表示径向基核函数。 各算法分类错误率如表4所示。
| 表2 Xgboost, Bert算法设置参数值 Table 2 Xgboost, Bert algorithm setting parameter values |
| 表3 SVM、 BP神经网络算法设置参数值 Table 3 SVM, BP neural network algorithm setting parameter values |
| 表4 对比实验中各算法分类错误率 Table 4 Comparison of the classification error rate of each algorithm in the experiment |
由本次实验结果可以看出: 在分类错误率上, 所提出的混合深度学习算法Besvm分类错误率比LDA算法低0.698, 比BP神经网络算法低0.657, 比SVM算法低0.645, 比Xgboost算法低0.361, Besvm算法远远优于其他四个算法。 LDA算法分类错误率最高, 比分类效果次好的Xgboost算法高出0.337。 通过本次实验, 证明了混合深度学习算法Besvm的分类有效性。
4.2.3 实验3: 检验Besvm算法的稳定性
验证混合深度学习算法Besvm的稳定性。 与实验2相同, 同样基于相同的数据, 采用对比实验的形式, 考查LDA, BP神经网络, SVM, Xgboost, Besvm五种算法的分类错误率。 注意, 本次实验与实验2所用数据不同。 在A型恒星光谱数据r波段信噪比大于30的1808条数据中, A1型恒星光谱、 A2型恒星光谱、 A3型恒星光谱再各随机选取300条作为本次实验的输入。 各算法分类错误率如表5所示。
| 表5 稳定性实验中各算法分类错误率 Table 5 Classification error rate of each algorithm in the stability experiment |
由本次实验结果可以看出: 本文所提出的混合深度学习算法Besvm分类错误率比LDA算法低0.679, 比BP神经网络算法低0.612, 比SVM算法低0.645, 比Xgboost算法低0.371, Besvm算法远远优于其他四种算法。 LDA算法分类错误率还是最大, 比Xgboost算法高出0.31。 SVM算法、 Xgboost算法同实验2相比分类错误率均略有升高, 但错误率波动范围不大, 分别提高0.002、 0.011, 属于正常波动范围。
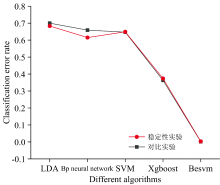
综合实验2和实验3可以看出, 两次实验Besvm算法分类错误率较LDA、 BP神经网络、 SVM、 Xgboost四种算法都低很多。 从图4可以看出, 使用相同数量但是不同的实验数据时, Besvm算法的分类错误率基本没有波动, 均有最高的分类正确率, 因此得出结论: Besvm算法的稳定性很好。
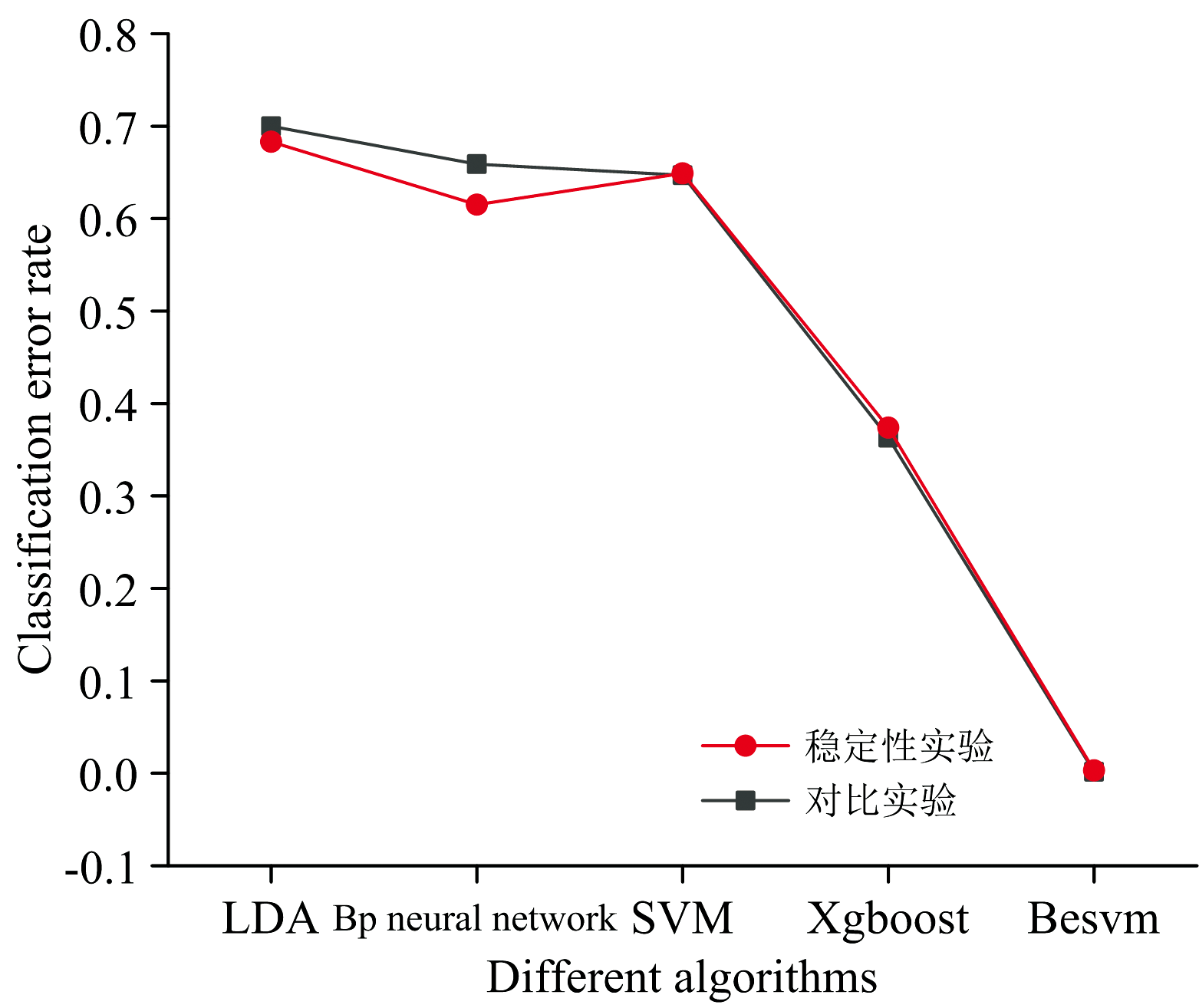 | 图4 实验2和实验3分类错误率对比图Fig.4 Comparison diagram of classification error rate of stability experiment |
张枭等[11]在以恒星光谱线指数作为分类特征, 应用Xgboost算法进行恒星光谱分类时, A型恒星光谱分类正确率为0.94, 该研究使用了221 024条数据。 考虑到本文只使用了900条数据, 因此该文的实验结果应该远远好于本篇文章Xgboost算法0.63的分类正确率。 但是, Besvm算法在小数据量的情况下, 分类正确率在0.99以上, 高出该研究5个百分点, 这可以证明, 本文所提出的混合深度学习算法Besvm有较好的分类性能。
4.2.4 实验4: 考查数据量对Besvm算法的影响
分别使用A型恒星光谱r波段信噪比大于30的1 200、 1 500、 1 808条实验数据进行本次实验, 并同实验2的结果一起进行比较分析。 同样采用对比试验的形式, 考查LDA, SVM, Xgboost, Besvm四种算法的分类错误率。 同样将全部数据进行标签分类, 然后将带标签数据打乱顺序。 在使用1 808条实验数据时, 各算法分类错误率如表6所示。
| 表6 数据量实验中各算法分类错误率 Table 6 Classification error rate of each algorithm in the data volume experiment |
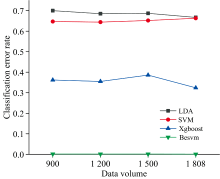
本次实验结果显示, 混合深度学习算法Besvm分类效果依旧最好, 随着数据量的加大, 分类错误率分别为0.001 578、 0.001 349、 0.001 346和0.000 79。 Xgboost算法随着数据量的加大分类错误率分别为0.362、 0.355、 0.386和0.324。 SVM算法随着数据量的加大分类错误率分别为0.647、 0.644、 0.652和0.663。 对于SVM算法, 1 808条A型恒星光谱数据或许还是较少, 无法体现随着数据量加大而分类错误率下降的趋势。 选择SVM算法作为输出层算法的原因详见4.2.5节。 可以看出, 在使用相同实验数据的情况下, Besvm算法要远远优于Xgboost、 SVM算法。
由实验2、 实验3、 实验4可以看出, LDA、 SVM算法分类错误率较高, 在0.6以上。 Xgboost算法分类错误率维持在0.3~0.4之间。 而本文提出的混合深度学习算法Besvm, 分类错误率一直维持在很低的水平。 需要说明的是, BP神经网络算法的分类错误率过于受限于隐层神经元的个数, 随着数据量的变化, 分类错误率变动幅度较大, 故没有将其展示在图5中。 从图5可以看出, 数据量的变化对Besvm算法影响很小, 这验证了Besvm在A型恒星光谱分类任务中的优越性和稳定性。
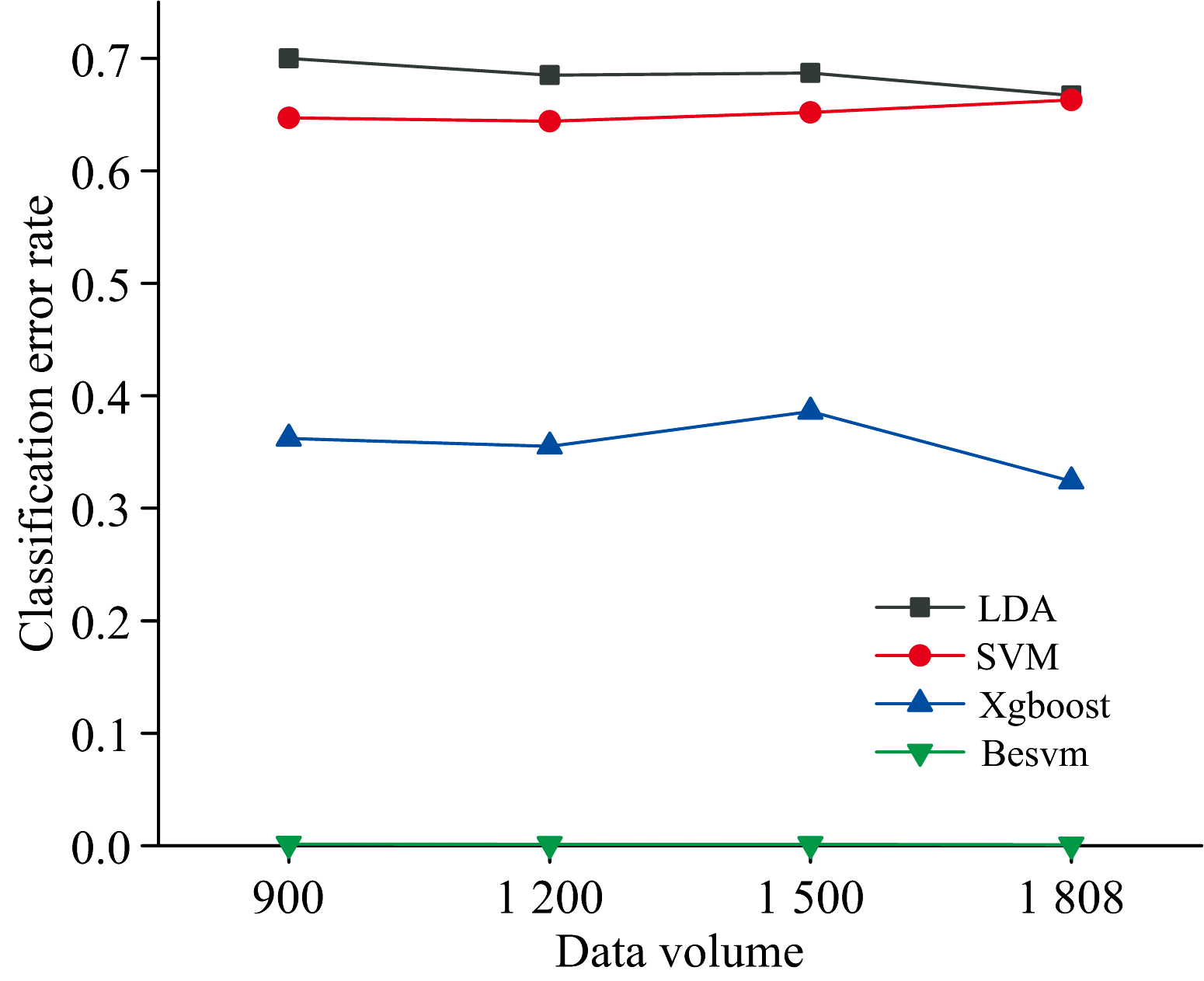 | 图5 数据量实验各算法分类错误率对比图Fig.5 Comparison diagram of classification error rate of each algorithm in data volume experiment |
Liu等提出过类似的特征提取器+SVM的恒星光谱分类算法。 在对F型恒星光谱的三个子型F2、 F5、 F9进行分类时, 使用上万条恒星光谱数据, 分类正确率为0.794 6。 本文提出的Besvm算法的分类正确率一直在0.99以上。
4.2.5 实验5: 考查不同信噪比数据对Besvm算法的影响
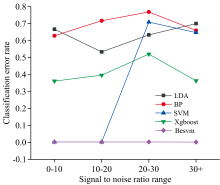
考查使用不同信噪比数据对LDA, BP神经网络, SVM, Xgboost, Besvm五种算法分类错误率的影响。 前人研究的恒星光谱分类算法, 有些受限于恒星光谱的数据量; 有些受限于算法本身的局限性; 还有些受限于光谱数据的质量。 本实验考查使用不同信噪比数据是否对本文提出的混合深度学习算法Besvm有影响。 使用不同信噪比区间的恒星光谱线指数数据进行本次实验。 所用信噪比区间为: (0, 10)、 (10, 20)、 (20, 30)、 (30, ∞ )。 每个信噪比区间所对应的数据量分别为: 634、 621、 574、 900.实验结果如图6所示。 从图6可以看出, 不同信噪比数据对SVM算法影响最大, 相较于使用(10, 20)信噪比区间的数据, 在使用(20, 30)信噪比区间数据时, SVM算法分类错误率有大幅度变动。 Xgboost算法的分类错误率一直在0.3以上, 最高不超过0.6。 LDA算法、
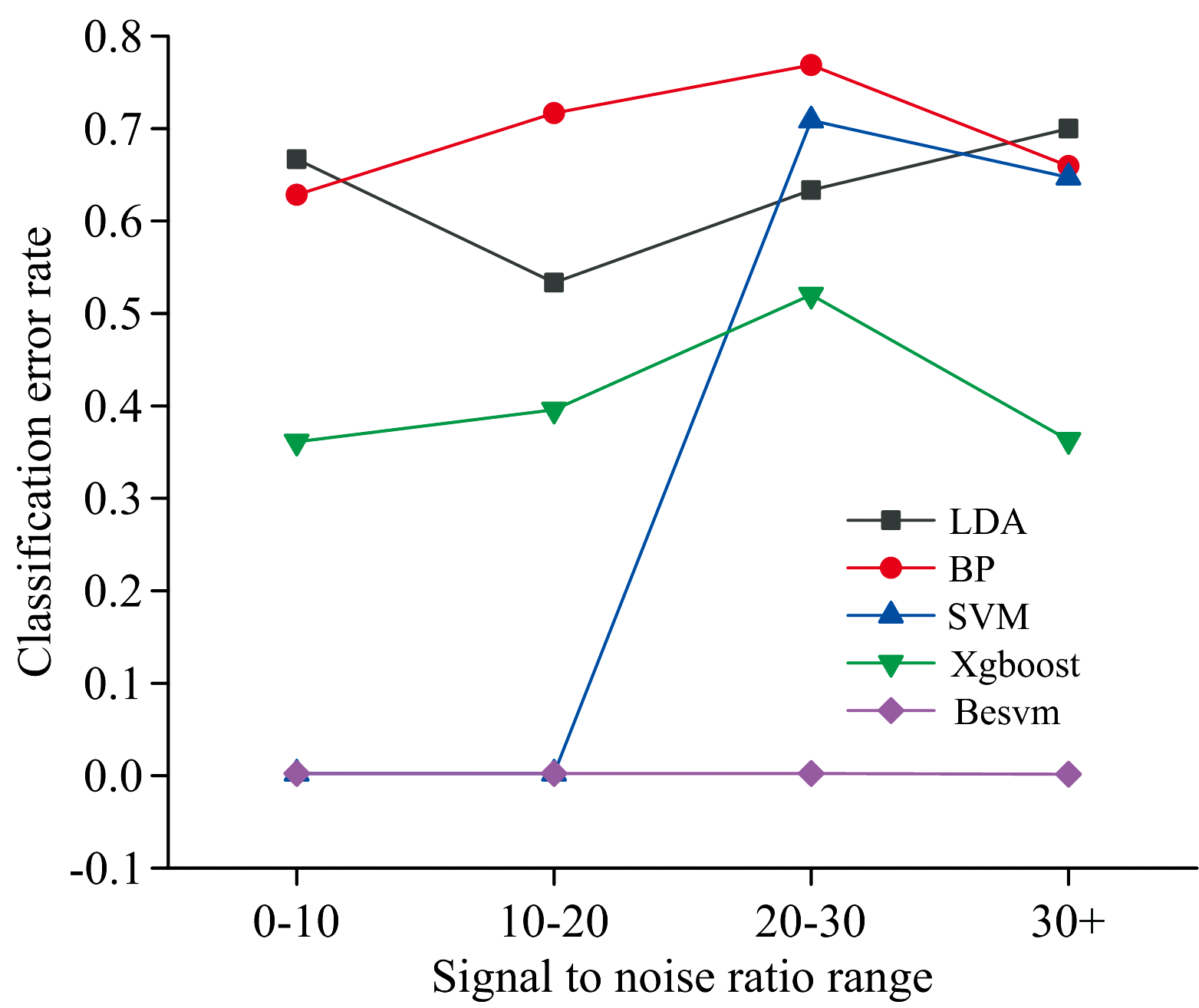 | 图6 基于不同信噪比数据的各算法分类错误率图Fig.6 The classification error rate of each algorithm based on different signal-to-noise ratio data |
BP神经网络算法的分类错误率也出现了不同情况的波动。 而使用不同信噪比数据混合深度学习算法Besvm分类错误率变动不大, 分类错误率一直维持在一个很低的水平。 因此, 得到结论: Besvm算法不受数据信噪比的影响, 在低信噪比数据上也能有很高的分类正确率。
通常情况下, 高信噪比数据往往能有好的实验结果, 但SVM算法在本文的高质量数据上表现不佳。 虽然进行了较为系统的调参过程, 但还认为是调参的过程未能将参数调整到最优状态所导致。 SVM算法在本文的低信噪比数据上能有很低的分类错误率, 又考虑到学者们使用SVM算法进行类似的分类任务时, SVM算法有良好的表现, 所以选择了SVM算法作为输出层算法。
恒星光谱分类是天体研究领域的热点问题。 在恒星光谱分类的众多方法中, SVM以其优良的分类性能搏得了人们的广泛青睐。 在恒星光谱分类领域, 传统算法的分类正确率基本也可达到0.85及以上, 但是本文传统算法的分类错误率过高, 其原因可能有两点: ①本文所使用的恒星光谱数据量较少, 因为不能从星表中提取更多的实验数据; ②天文数据自身存在极大的不确定性导致实验结果不理想。 第二点也可能是导致传统算法在使用高信噪比光谱数据时, 其分类错误率反而比使用低信噪比数据的分类错误率高的原因。 这也间接证明了本文提出的基于Transformer特征提取的混合深度学习算法Besvm在恒星光谱分类任务中的优越性。 经过实验验证, RBF核函数最适合应用在本文的A型恒星光谱数据上, Besvm算法在规模较小且信噪比低的数据集上仍能保持较高的分类正确率, 在Bert所对应的Head=128情况下, 分类错误率保持在0.01以下, 远远低于LDA算法的0.7、 BP神经网络算法的0.659、 SVM算法的0.647和Xgboost算法的0.363, 体现了混合深度学习算法Besvm的优越性能。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|