


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于改进1D-VD-CNN与近红外光谱数据的金银花产地溯源研究
[陈冬英1, 2  , 张昊
, 张昊1, 2, * , 张子龙1 , 余沐昕1 , 陈璐3 ]
, 张昊, 张子龙|
|


作者简介: 陈冬英, 女, 1989年生, 福建江夏学院电子信息科学学院讲师 e-mail: 863848737@qq.com
金银花是清热解毒必备良药, 市面上金银花来源复杂, 最著名的山东平邑产金银花在市场上常遭造假。 已有的鉴别方法大多耗时长、 成本高且操作复杂, 亟需一种快速高效的金银花产地溯源方法。 针对应用在金银花鉴别中的近红外光谱(NIRS)数据的一维卷积神经网络(1D-CNN)鉴别模型存在参数量过大、 模型效率过于低下、 计算复杂度高, 同时易产生过拟合问题, 对传统1D-CNN结构作出改进。 使用效率较高的VD(Very Deep)结构替代传统1D-CNN中隐含层结构, 并针对 NIRS 数据适应性改进, 使其可直接应用于一维NIRS数据。 改进分为三步: (1) 将特征层的设计转为2个约束优化设计: 第一约束条件设每个卷积层C值(卷积核与感受野的大小比值)为1/6, 可提高网络模型效率; 第二约束条件取顶层感受野大小为数据向量大小, 实现更深层数据特征提取, 并减小过拟合。 (2) 通过降采样把特征层输出特征向量缩小至较小的尺寸; (3) 使用两个1×5大小的卷积层和一个带有Dropout的池化层将数据大小降采样到只有一个矢量的向量替代分类作用的全连接层, 进而减小参数量。 采集河南、 山东、 河北、 重庆主要产地出产的金银花为样品500份。 测试光谱范围908~1 676 nm, 采用KS法对样品集预处理, 并用shuffle算法完成训练集、 验证集、 测试集划分, 构建基于改进1D-VD-CNN与近红外光谱的金银花产地鉴别模型。 结果表明, 1D-VD-CNN训练集与测试集准确率均达到100%, 损失值收敛为0.001附近。 与传统1D-CNN模型相比, 1D-VD-CNN模型的训练集与测试集准确率分别提升为约0.5%与1.4%, 参数量和FLOPs分别减少近1 M(兆)和20 M(兆)。 与原始光谱数据分析法和PLS-DA法对比分析, 表明1D-VD-CNN模型对金银花近红外光谱分类具有更高的效率和更好的识别性能。
Honeysuckle is an essential medicine for clearing away heat and detoxifying. However, the sources of honeysuckle on the market are complicated, and the most famous honeysuckle produced in Pingyi, Shandong, is often counterfeited. Most existing identification methods are time-consuming, costly, and complex to operate. Therefore, a fast and efficient way to trace the honeysuckle’s origin is urgently needed. The current one-dimensional convolutional neural network (1D-CNN) identification model based on honeysuckle near-infrared spectroscopy (NIRS) data has the problems of too many parameters and too low model efficiency, high computational complexity and is prone to overfitting. This paper improves the traditional 1D-CNN structure. We use the more efficient VD (Very Deep) structure to replace the hidden layer structure in the conventional 1D-CNN and make adaptive improvements for NIRS data so that the model can be directly applied to one-dimensional NIRS data. The improvement method is divided into three steps: firstly, the design of the feature layer is converted into two constraints optimization design: the first constraint is to set the C value of each convolution layer (the ratio of the size of the convolution kernel and the receptive field) to 1/6, which can improve the efficiency of the network model; the second constraint is to take the size of the top-level sensory domain as the size of the data vector, which can achieve feature extraction of deeper data and reduce overfitting. Secondly, this design minimizes the output feature vector of the feature layer to a smaller size through the downsampling operation. Finally, use two convolutional layers of size 1×5 and a pooling layer with dropout to downsample the data size to a vector of only one vector instead of a fully connected layer for classification, thereby reducing the number of parameters. In the experiment, 500 honeysuckles samples were collected from the main producing areas of Henan, Shandong, Hebei, and Chongqing. The spectral range used in the test is 908~1 676 nm. The sample set was preprocessed by the KS algorithm, and the training set, validation set and test set were divided by the shuffle algorithm. At last, a honeysuckle origin identification model based on improved 1D-VD-CNN and near-infrared spectroscopy was constructed. The results show that the 1D-VD-CNN training set and test set’s accuracy reach 100%, and the loss value converges around 0.001. Compared with the traditional 1D-CNN model, the training set and test set accuracy of the 1D-VD-CNN model are improved by about 0.5% and 1.4%, respectively, and the number of parameters and FLOPs are reduced by nearly 1 M and 20 M, respectively. At the same time, compared with the original spectral data analysis method and the PLS-DA method, it shows that the 1D-VD-CNN model has higher efficiency and better recognition performance for honeysuckle near-infrared spectral classification.
金银花属于忍冬科, 是植物忍冬的干燥花蕾或带初开的花。 在夏季花开放时采收、 干燥[1]。 金银花是清热解毒的必备良药之一[2]。 金银花的生产来源相对复杂, 全世界的忍冬属植物大概有200种, 其中我国有98种, 广泛分布在各省区[3]。 金银花最著名的产地为山东省临沂市平邑县, 被誉为“ 中国金银花之乡” 。 文献[4]通过HPLC(高效液相色谱)与紫外光谱(UV)法来测定14个不同产地的金银花所含化学物质: 绿原酸、 木犀草苷、 总酚酸以及总黄酮, 所得结果表明山东临沂产的金银花各化学物质含量均最高, 综合评价金银花以山东临沂平邑产地的质量最佳。 近年来受到疫情影响, 金银花价格不断上涨, 最为地道产地的山东平邑金银花药材在市场上常遭造假, 亟需一种快速高效的金银花产地溯源方法。
目前对金银花产地溯源的研究方法主要有性状鉴定法、 显微鉴定法、 DNA分子标记鉴定法、 高效液相法、 NIRS分析法等[5, 6, 7]。 这些方法都存在一定缺陷: 性状鉴定法需要多年识别经验和相关的知识扩充, 具有一定的主观性; DNA分子标记技术依赖分子生物学技术, 并且在鉴定过程中容易破坏样品结构, 鉴定过程复杂; 高效液相法法对待测样品的要求较高, 前期预处理较为复杂, 且检测成本高昂, 不适用于金银花的快速鉴别。
近红外光谱(near-infrared spectroscopy, NIRS)检测技术可获取生理活性物质中含氢基团(O— H、 N— H、 C— H)振动的合频、 倍频信息[8], 是一种快速、 高效、 绿色、 无损的检测技术[9]。 NIRS属于间接分析技术, 在使用中需要采取合适的模式识别方法建立合适的识别模型。 本工作综合机器学习与NIRS数据的优势, 将机器学习与NIRS数据相结合应用于金银花产地溯源研究。
近年来, 综合NIRS与传统机器学习模型已广泛应用于中药材定性分析。 因卷积神经网络(convolutional neural network, CNN)在高维数据中展现了强大的数据特征提取能力[10], 在图像分类[11], 目标检测[12]等任务中取得了巨大的成功。 文献[13]提出了一种一维卷积神经网络(1D convolutional neural network, 1D-CNN)来区分中药中的马兜铃酸及其类似物。 文献[14]改进了LeNet-5网络结构用于识别三个主要的烟叶生产区域, 训练集和测试集的准确率分别为98.6%和95.0%。 文献[15]建立了1D-CNN, 2D-CNN和PLS-DA识别烟叶的地理起源。 将1D-CNN应用在基于NIRS数据的金银花产地溯源研究未见报道, 仍处于初步探索阶段。
当前应用于NIRS数据定性分析的经典1D-CNN模型, 由于该模型结构简单, 需要增加足够多数量的卷积核数量来增加鉴别模型的分类性能, 不仅造成模型过于臃肿, 参数量巨大, 增加了模型的计算复杂度, 还增加了模型过拟合的风险。 为解决NIRS技术对金银花识别不足问题, 也为了提高 1D-CNN的性能, 本工作引入效率更高的VD结构, 以NIRS数据为基础, 设计基于改进的一维超深度卷积神经网络(one dimensional very deep convolutional neural network, 1D-VD-CNN)分类鉴别模型。 该模型具备对不同产地金银花的高精度鉴别能力, 符合实际中药质量鉴定的研究需求, 具有一定的应用前景。
实验采用的仪器是美国的微型近红外光谱仪(型号为MicroNIR 1700)。 样本是在收获旺季(5月— 9月), 从包括山东、 重庆、 河南与河北在内的我国主要金银花产地所采集的金银花。 样本覆盖地相对比较广, 各个地区均涵盖多个县乡。 最终获取的金银花NIRS数据共500个。 具体的样本集分类如表1。
| 表1 实验数据分配情况 Table 1 Distribution of experimental data |
光谱采集主要步骤: (1) 收集鲜品样本; (2) 经过烘干机将鲜品样本烘干(60 ℃); (3) 平铺已烘干的金银花样本, 平铺的厚度大于等于5 mm; (4) 采用漫反射原理, 把光谱仪对准金银花样本。 每扫描一次, 将光谱仪的光斑区移动一次, 重复以上步骤再采集一次, 各样本共进行五次采集并取均值, 最终获取样本的近红外光谱数据。
光谱仪采集的参数设置如下: 所采集的数据光谱波长908~1 676 nm, 每次光谱需要重复扫描次数设为50, 同时以8 000 μ s作为单次积分的时间。 所测光谱如图1所示。
 | 图1 金银花近红外光谱图Fig.1 Near-infrared spectrum of honeysuckle |
1.3.1 一维卷积神经网络(1D-CNN)
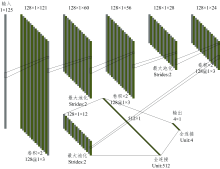
通过试错法得到一个适应于金银花NIRS数据分类效果良好的1D-CNN模型, 针对近红外光谱数据特点的同时简化模型复杂度和提高模型分类精度, 对LeNet-5进行了改进。 改进后的1D-CNN具体结构如图2所示。 首先, 输入数据大小为1× 125, 经过2层(每层128个卷积核, 卷积核大小为1× 3)卷积层后, 得到相应的128个特征图, 每个特征图大小为1× 121; 然后对该特征图采用步长为2的池化操作, 获得128个特征图, 每个特征图的大小均为1× 60; 重复上述的卷积和池化操作3次后, 获得128个特征图, 各个特征图均为1× 12。 为了使全连接层能够处理所得数据, 对这些数据进行展平操作, 使数据大小从128× 1× 12变成1× 1 536, 最后经过两个全连接层输出分布概率, 获得分类结果。
 | 图2 1D-CNN模型的结构图Fig.2 Structure diagram of the 1D-CNN model |
1.3.2 改进隐含层的VD结构设计
在深度学习网络搭建中, 深度是提升网络表征能力的重要方向。 将传统一维卷积神经网络改进成一维超深度卷积神经网络(1D-VD-CNN)模型。 核心设计是将传统1D-CNN的隐含层分为两个部分— — 特征层和分类层。 传统1D-CNN的隐含层包含卷积层、 池化层及全连接层。 1D-VD-CNN模型具体设计如下:
(1)特征层的设计
鉴于对特征层的设计, 目前没有统一的理论依据, 因此对特征层的设计转换为约束优化设计。 主要包括两个约束条件: 学习能力和学习必要性。
①学习能力设计(第一约束条件)
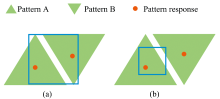
不同的卷积层设计方案, 学习能力不同。 如图3表示两种模式响应。 图中蓝色的方框代表卷积核。 图3(a)是模式A和B的输出及其空间关系, 卷积层可以组成或者检测更复杂的模式AB。 然而卷积层并不总是有学习更复杂模式的能力。
 | 图3 模式响应 (a): 模式A、 B输出及空间关系; (b): 卷积尺寸小于模式A、 B之间的响应Fig.3 Pattern response (a): The output and spatical relationshiop of moldes A and B; (b): Convolutional kernal size smaller than the response between modes A and B |
如图3(b)所示, 卷积核尺寸小于模式A和B之间的响应距离, 因此卷积层就无法组成或者检测更复杂的模式, 即卷积层无法获取到新的数据特征。 为了解决此问题有两种方法: 第一种是增大卷积核的尺寸; 第二种通过对数据进行步长为2的降采样来使两个模式之间的输出距离缩短一半。 因增大卷积核的尺寸, 会产生更大的计算量, 而降采样处理会减少计算, 但是会丢失部分的数据特征, 因所丢失的部分特征在可接受范围内, 因此采用第二种方法来恢复卷积层的学习能力。
为了衡量卷积神经网络每一层卷积层的学习能力, 本设计引入一个值C(C值为每一层卷积层的学习能力)
式(1)中, nconc为实际的卷积核值, nfield为感受野值, 即特征图大小。 如图4为1D-VD-CNN特征层模型, 总共有四大卷积层, 每两层中均加步长为2的下采样。 其中每层感受野大小采用数组表示, 如第一大层采用三个1× 3, 数组[2:2:12]表示范围为2到12, 每隔步长2取一个数, 即取数值2、 4、 6、 8、 10、 12。 当大小为1× k的卷积核, 在经过一次步长为2的下采样后, 它的nconc为1× 2k; 再经过一次步长为2的下采样后, 它的nconc为1× 4k, 即nconc经过n次步长为2的下采样后翻倍为1× 2nk。 式(1)C值表示该网络模型的学习能力, 若过小, 则无法提取足够的数据特征。 兼顾系统计算量与准确性的考虑, 根据经验, 本设计1D-VD-CNN的第一约束条件为: 每个卷积层的C≥ 1/6, 本设计取最佳下限值C=1/6。
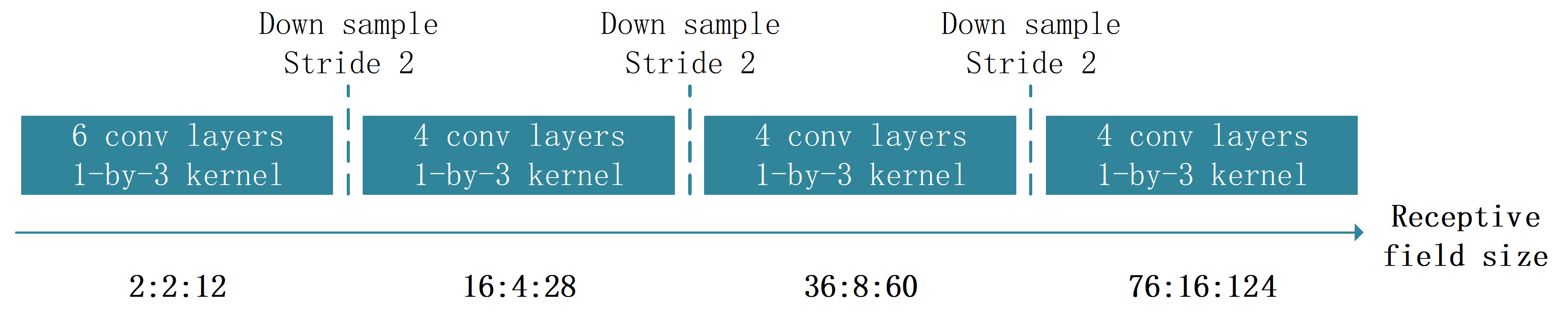 | 图4 1D-VD-CNN特征层模型Fig.4 Feature layer model of 1D-VD-CNN |
②学习的必要性设计(第二约束条件)
根据第一个约束条件设计, 加入更多维的卷积层, 并与下采样结合, 进而导致感受野的不断增长, 从而产生新的更为复杂模式。 然而当感受野的大小大于数据向量的长度时, 此时神经元便可看到全局数据。 因此即使增加深度, 数据亦不会出现新的或者更复杂的模式, 不仅不会提高性能, 同时还会增加过拟合风险。 本设计1D-VD-CNN的第二个约束条件为: 顶层的感受野大小等于数据向量的大小。
(2)分类层的优化设计
传统的分类层设计使用两个带有防止过拟合机制的全连接层, 第一个全连接层的通道数大小较大, 作用是整合特征层提取到的特征; 第二个全连接层的通道数大小对应数据种类的大小。 该设计的缺点如下:
①虽然两个全连接层都带有防止过拟合的机制, 但是需要足够的训练集数量, 否则模型易产生过拟合;
②第一个全连接层的通道数过大会增加模型的参数量和计算量。
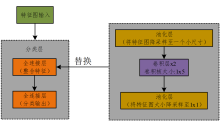
为了改进传统模式, 本设计进行优化, 优化方案过程如图5所示。 首先, 将特征层输出的特征向量通过降采样把模型缩小到一个较小的尺寸(1× 6, 1× 7或1× 8); 然后使用两个1× 5的卷积层和一个带有Dropout的池化层将数据大小降采样到一个只有一个矢量的向量大小; 最后使用一个分类作用的全连接层输出。
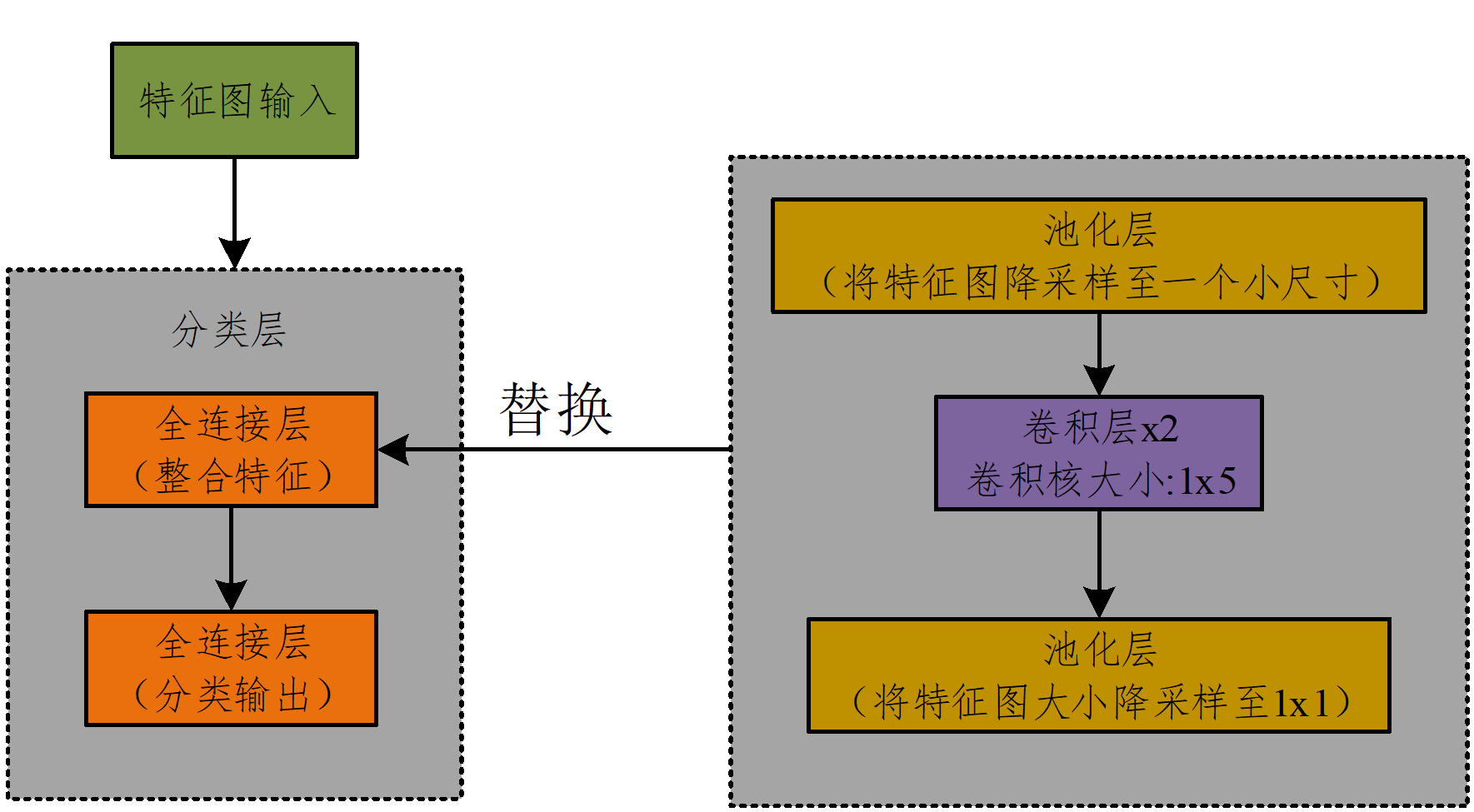 | 图5 分类层优化设计Fig.5 Optimal design of classification layer |
由于两个卷积核的大小相比于特征图太大, 而全连接层主要功能是对前面几层提取到的特征作加权和, 因此可以替代原来的全连接层, 进而减少参数量。
1.3.3 改进的 1D-VD-CNN 网络结构模型
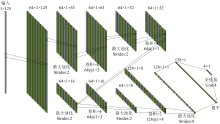
根据上述理论设计了一个改进1D-VD-CNN的网络模型, 网络的设计结构如图6所示。 图中的64@1× 3表示有64个通道, 每个通道的数据大小为1× 3。 首先, 数据经过一系列的卷积和池化操作后, 将特征图的大小降低至1× 8这样一个较小的尺寸; 然后, 采用两层卷积核大小为1× 5的卷积层替代1D-CNN模型中神经元数量为512的全连接层; 最后用一个池化层将特征图大小降低至1× 1, 并通过全连接层输出分布概率得到分类结果。
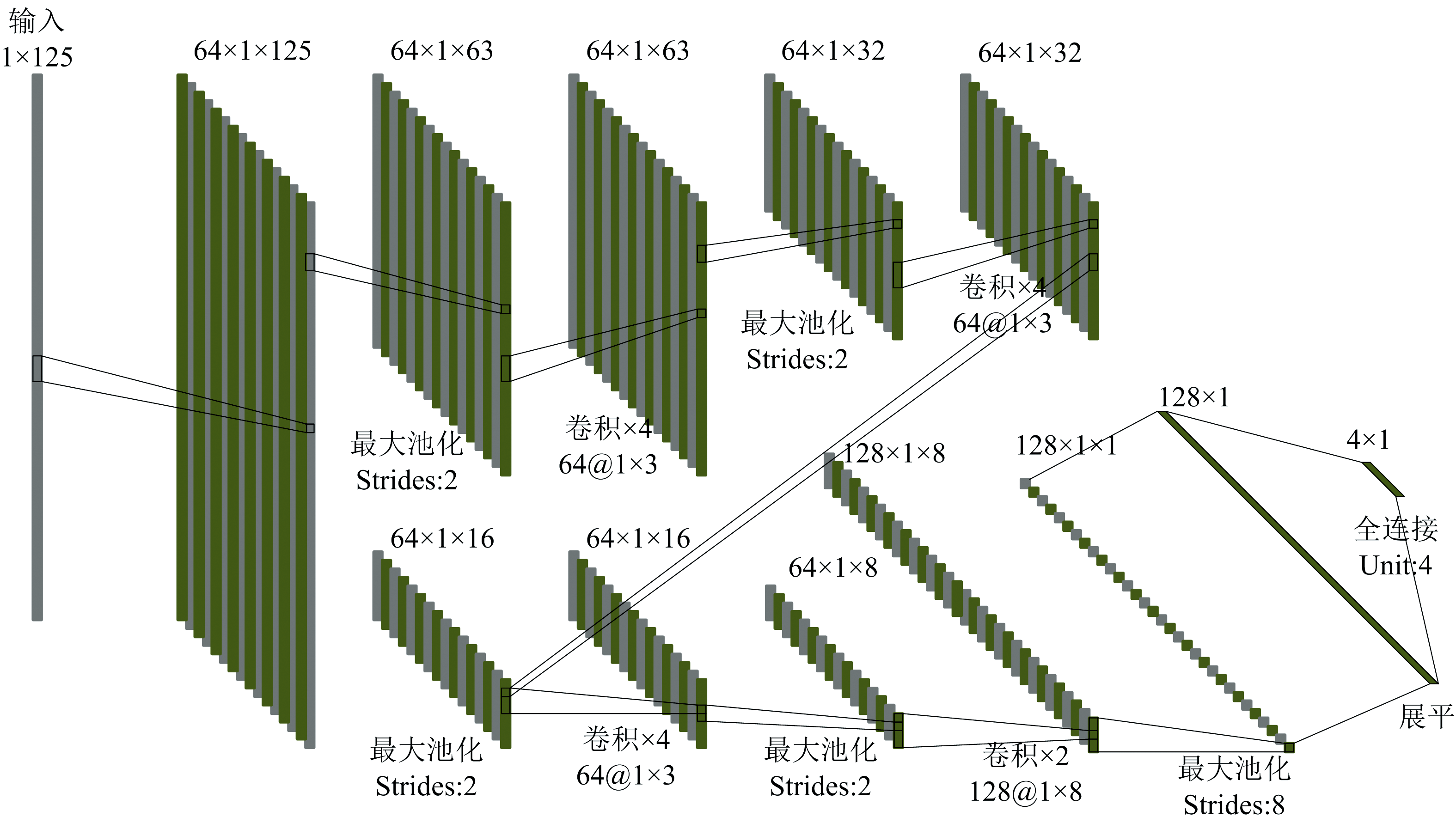 | 图6 1D-VD-CNN网络结构Fig.6 Network structure of 1D-VD-CNN |
该模型的复杂性通过浮点运算FLOPs (floating-point operations)[14]进行评价。 FLOPs的本质是计算模型中的乘加数[15]。 卷积层的FLOPs计算公式如式(2)
式(2)中, kw表示卷积核宽度, kh表示卷积核的高度, cin表示输入通道数, cout表示输出通道数, 相当于卷积核的数量, H和W分别表示特征向量的宽和高。
卷积层的参数量由式(3)计算
式(3)中, kw是卷积核的宽度, kh是卷积核的高度, cin是输入通道数, cout是输出通道数。
NIRS数据是一维序列, 相应的卷积核高度kh和特征图高度H均为1。 因此, 简化方程式(1)和式(3)如式(4)和式(5)。
主要采用准确率(Accuracy, ACC multilabel)评价模型的性能。 多标签任务的准确度是通过对每一类别的TP和TN进行求和, 然后除以预测样本的总数进行计算, 计算公式如式(6)
式(6)中, TP和TN分别表示将正类预测为正类数量, 将负类预测为负类样本数量。 FP和FN分别表示将负类预测为正类, 将正类预测为负类。
在进行金银花近红外光谱数据的输入之前, 采用KS法进行样本预处理。 取所收集的500个不同产地的金银花样本为模型建立和评估的研究对象。 随机选取20%的样本数据作为模型的测试集, 80%的样本数据为模型的训练集, 其中训练集再随机切分成 20%的验证集作为模型选择的验证依据, 训练集中80%作为模型的训练数据。 因此, 样本数据共划分成3个数据集, 分别为训练集, 验证集和测试集。 采用训练集数据建立模型, 验证集数据作为模型选择, 测试集用于最终验证模型分类。 金银花不同产地样本的数据集划分详细信息如表2所示。
| 表2 金银花不同产地样本的数据集划分 Table 2 Data set division of honeysuckle samples from different origins |
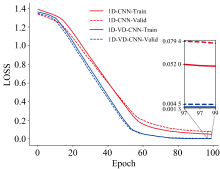
在不降低性能的情况下, 降低1D-CNN的复杂度。 为了验证改进后的1D-VD-CNN对金银花NIRS数据集的产地识别性能, 分别建立了基于KS预处理方法的1D-CNN和改进1D-VD-CNN进行对比。 数据集按表2划分。 性能评价指标根据1.4节进行实验计算。 模型训练过程中的损失值和准确率分别如图7和图8所示。
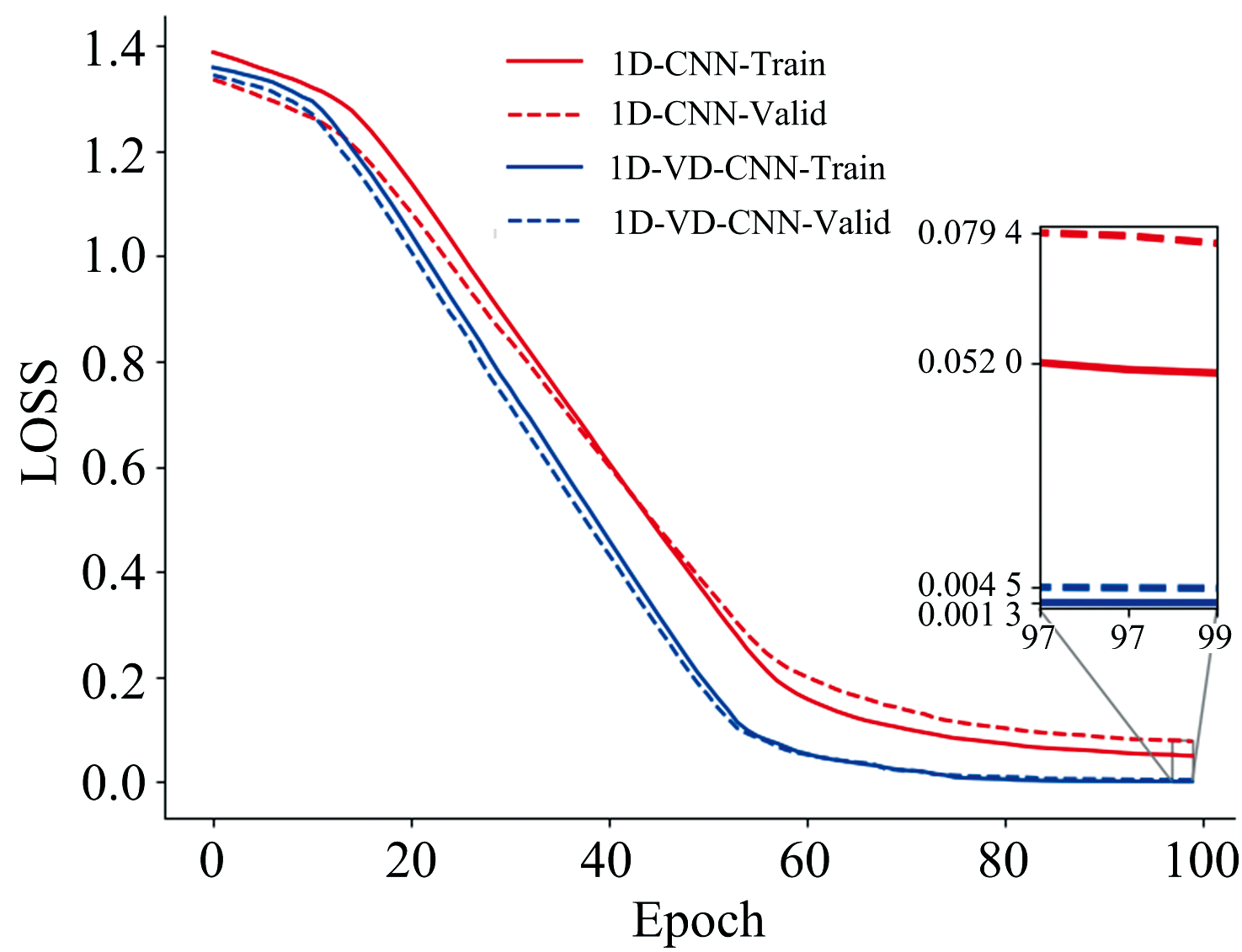 | 图7 改进的1D-VD-CNN和1D-CNN的损失值Fig.7 The Loss of improved 1D-VD-CNN and 1D-CNN |
 | 图8 改进的1D-VD-CNN和1D-CNN的准确率Fig.8 The Accurate of improved 1D-VD-CNN and 1D-CNN |
图7中改进1D-VD-CNN相较传统1D-CNN的损失值下降更快。 当训练次数达到100时, 训练集和验证集的损失值分别为0.004 5和0.001 3, 分别比传统1D-CNN模型降低了0.074 9和0.050 7。 1D-VD-CNN模型对验证集的损失函数值要小很多, 1D-CNN模型的损失函数值收敛于0.05附近, 而1D-VD-CNN模型的损失函数值收敛于0.001附近, 表明1D-VD-CNN比1D-CNN具有更好的学习能力, 可以提取更多的数据特征, 对未知的数据也有更强的识别能力。
由图8可知, 改进的 1D-VD-CNN的测试集和训练集上升最快, 均可以达到1, 相比与传统1D-CNN模型, 训练集和验证集准确率更高。 该模型可以更准确、 无损地实现金银花NIRS数据不同产地的识别。
模型的训练次数太小会导致欠拟合, 太多又会导致过拟合, 因此在保证模型训练运行次数尽量小和效果尽量好的前提下, 本设计两个模型均选择100次训练。 表3是两个模型的性能指标和复杂度对比。 1D-VD-CNN与1D-CNN比较, 其训练集准确率(ACC)提升约0.5%, 测试集准确率提升约1.4%, 参数和FLOPs分别减少近1 M和20 M。 这表明 1D-VD-CNN比1D-CNN更有效, 性能更优。 由此表明, 对NIRS数据的隐含层结构的修改提高了效率并降低了复杂度。 在数据有限的情况下, 单纯通过增加模型的容量来提高模型的性能是非常昂贵的, 但是适当增加宽度可以大大提高CNN模型的效率。 以上对实验结果的对比和分析表明, 改进的1D-VD-CNN模型对金银花近红外光谱分类具有更高的效率和更好的识别性能。
| 表3 两个模型的评价指标对比 Table 3 Comparison of evaluation indicators of the two models |
为了比较改进的1D-VD-CNN与传统化学计量学方法的性能, 分别建立了原始光谱数据分析及输入NIRS经KS预处理后的PLS-DA模型与1D-VD-CNN模型进行对比验证。 在PLS-DA模型中R2X(解释矩阵信息的百分比)和Q2(建模后模型的预测能力)分别为0.956和0.867。 测试集的实验结果如表4所示。 将改进的1D-VD-CNN与原始光谱数据、 PLS-DA模型进行比较, 改进的1D-VD-CNN的性能更优越。 表明对于有限的高维数据, 所提出的模型比不使用特征提取算法的传统化学计量方法具有更强的分类性能。
| 表4 与传统化学计量学方法的对比 Table 4 The performances of improved 1D-inception-CNN and traditional chemometric methods |
本设计提出一种基于NIRS的改进1D-VD-CNN模型识别金银花产地。 根据NIRS数据的特点, 去掉了传统1D-CNN结构中的全连接层, 同时通过将大卷积1× 5, 用2个1× 3小卷积替代, 每2个小卷积中加入一个步长为2的下采样, 增加卷积层至8个。 通过与传统的结构化1D-CNN模型以及传统化学计量学方法PLS-DA的对比, 表明改进的1D-VD-CNN模型在保证高精度识别性能的同时降低了复杂度, 具有更好的高维数据分析能力。 基于NIRS技术的改进型1D-VD-CNN模型可以快速有效地对金银花进行产地溯源, 使得金银花的鉴别工具更具有实用性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|