







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
北方寒地水稻叶片磷素含量高光谱反演方法研究
[杨柳1  , 郭忠辉
, 郭忠辉1 , 金忠煜1 , 白驹驰1 , 于丰华1, 2 , 许童羽1, 2, * ]
, 郭忠辉]
|
|


作者简介: 杨 柳, 女, 1998年生, 沈阳农业大学信息与电气工程学院硕士研究生 e-mail: 475474313@qq.com
为了快速、 准确的检测北方寒地水稻叶片的磷素含量, 分析水稻的长势情况, 为精准施肥以及稻田的科学管理提供依据, 以北方寒地水稻为研究对象, 以小区实验为基础, 使用海洋光学HR 2000+光谱仪获取水稻叶片高光谱反射率数据, 采用钒钼黄比色法对水稻叶片磷素含量进行测定。 采用SG平滑与多元散射校正(MSC)两种方法对水稻叶片高光谱数据进行预处理, 并将预处理后的光谱数据使用连续投影法(SPA)与无信息变量消除法(UVE)两种算法进行特征选择。 采用SPA算法筛选得到的特征共有11个, 其中位于可见光波段处的有6个, 分别为411、 420、 428、 442、 467和689 nm; 近红外波段处有5个, 分别为797、 850、 866、 965和976 nm; UVE算法筛选得到的特征共47个, 均位于可见光波段范围内, 分布在405~603 nm之间。 分别将这两种方法筛选出的特征波段的反射率作为输入, 构建极限学习机(ELM), BP神经网络以及狼群算法优化的BP神经网络(WPA-BP)三种水稻叶片磷素含量反演模型并加以分析。 结果表明: 以UVE算法筛选的特征反射率为输入量构建的三种模型的验证集 R2在0.705 2~0.724 5之间, RMSE在0.017 4~0.020 4之间; 在相同的反演模型的条件下, 使用SPA算法筛选的特征反射率为输入量构建的模型预测效果更好, 三种模型的验证集 R2在0.726 4~0.829 3之间, RMSE在0.018 0~0.021 1之间; 另外, 在利用这两种算法筛选到的特征进行建模时, 对比三种模型的预测结果发现, 经过狼群算法优化后的BP神经网络模型的精度明显高于极限学习机和BP神经网络, 其验证集的决定系数 R2为0.803 4, RMSE为0.018 0。 鉴于此, 结合连续投影算法和狼群算法优化后的BP神经网络模型在北方寒地水稻叶片磷素含量高光谱反演中具有一定的优势, 可作为水稻叶片磷素含量的检测以及精准定量施肥的参考和借鉴。
In order to quickly and accurately detect the phosphorus content information of rice leaves in the cold northern region, analyze the growth of rice, and provide the basis for precision fertilization and scientific management of rice fields, this study takes rice in the cold northern region as the research object, based on the plot experiment, and uses the marine optical HR 2000+ spectrometer to obtain the hyperspectral reflectance data of rice leaves, the content of phosphorus in rice leaves was determined by vanadium molybdenum yellow colorimetry.SG smoothing and multiple scattering corrections (MSC) were used to preprocess rice leaf hyperspectral data. The spectral data were selected by using SPA and UVE. Eleven features were screened by the SPA algorithm, including 6 in the visible band (411, 420, 428, 442, 467 and 689 nm) and 5 in near-infrared band (797, 850, 866, 965 and 976 nm). A total of 47 features were obtained by the UVE algorithm, which was all located in the visible band range and distributed between 405 and 603 nm. Taking the characteristic reflectance selected by the two methods as input, three inversion models of phosphorus content in rice leaves were constructed and analyzed, including extreme learning machine (ELM), BP neural network and wolf pack algorithm (WPA-BP).The results show that the verification set R2 of the three models constructed with the characteristic reflectivity filtered by the UVE algorithm as the input is between 0.705 2~0.724 5 and RMSE is between 0.017 4~0.020 4; Under the condition of the same inversion model, the prediction effect of the model constructed by using the characteristic reflectivity filtered by SPA algorithm as the input is good. The verification set R2 of the three models is between 0.726 4~0.829 3, and RMSE is between 0.018 0~0.021 1; In addition, when using the features screened by the two algorithms for modeling, comparing the prediction results of the three models, it is found that the accuracy of the BP neural network model optimized by the wolf swarm algorithm is significantly higher than that of the ELM and BP neural network, and the determination coefficient R2 of the verification set is 0.803 4 and RMSE is 0.018 0. Because of this, the combination of SPA and WPA-BP has certain advantages in a hyperspectral inversion of phosphorus content in rice leaves in the cold northern region, which can be used as a reference for the detection of phosphorus content in rice leaves and accurate quantitative fertilization.
磷素以多种化合物形态参与生命代谢过程, 水稻茎叶中磷素含量一般在0.4%~1.0%之间。 磷素含量充足会增加水稻的分蘖数量, 增强代谢功能与抗逆性, 从而加速水稻成熟, 提高水稻产量; 相反, 水稻缺磷时, 植株颜色变暗, 叶片变窄甚至出现枯死现象, 分蘖数量减少, 影响水稻的发育[1]。 而在实际施肥中, 人们为了追求水稻的高产往往会选择过量的施用磷肥, 然而磷肥在当季的利用率仅能达到10%~25%之间[2], 剩余磷肥堆积在土壤当中, 随着磷肥积累量的增多土壤出现了富营养化的情况, 这样不仅会导致水稻减产, 还会影响生态环境。 因此, 解决水稻产量与磷肥施用量之间的矛盾关系, 实现水稻生产的“ 减肥增效” 是我们所面临的重要问题。 而传统的磷素分析测试过于耗费人力、 物力, 借助高光谱对水稻叶片磷素含量进行诊断不仅可以拓宽植物磷营养诊断的研究范围, 还可以弥补传统磷素营养诊断的弊端, 为大面积水稻磷营养诊断提供快速且准确的检测方法。 因此, 采用高光谱对水稻叶片磷素含量进行研究。
相对于其他养分参量, 磷素含量与光谱反射率间的关系较为复杂, 但是依然有很多学者对小麦、 柑橘、 苹果、 油菜等果蔬作物的叶片磷含量以及高光谱特征进行研究, 均取得了较好的反演结果。 除此之外, Osborne等[3]研究发现730~1 800 nm的可见光近红外光谱可以用于玉米磷素的诊断, 双波段组合参量具有更高的相关系数。 叶林蔚等[4]基于近红外高光谱技术结合非线性特征提取方法和建模算法实现了橡胶树磷元素含量的快速无损检测, 并发现以特征波段为输入变量构建的神经网络模型的预测精度最高。 但是至今关于水稻叶片磷素含量的反演研究依然相对较少。 林芬芳等[5]利用互信息理论分析出对水稻磷素含量的敏感波段为536、 630、 1 040、 551和656 nm, 研究表明BP人工神经网络建模的预测结果较好, RMSE为0.050 5, R2为0.989 2。 Mahajan等[6]研究发现对水稻中磷素含量敏感的波段为670、 700、 730、 1 090、 1 260和1 460 nm, 其中与磷素含量相关性最高的波长为1 460 nm, 利用光谱指数反演磷素含量的模型验证集精度为0.67。 班松涛等[7]采用无人机搭载高光谱成像仪获取水稻冠层高光谱影像, 并采样检测叶片磷素含量(LPC), 结果表明全生育期内LPC与462~718 nm范围内光谱反射率显著负相关, 使用神经网络和偏最小二乘回归模型均取得了较好的结果。
综上分析, 很多学者在利用高光谱反演作物磷素含量方面做了大量研究, 但是近年来水稻叶片磷素含量的高光谱反演研究相对较少, 可用来作为参考的依据依然很有限, 因此, 为进一步解决磷肥施用过量的问题, 提高水稻叶片磷素含量反演的准确性与适用性, 本研究以水稻为研究对象, 分析磷胁迫条件下水稻叶片高光谱变化规律, 建立一种北方寒地水稻叶片磷素含量高光谱反演模型, 作为水稻精准施肥以及大田管理的参考依据。
试验于2021年6月至9月在辽宁省鞍山市海城市耿庄镇沈阳农业大学水稻试验基地(东经122° 43'33″, 北纬40° 58'44″)进行, 水稻品种为北粳1705。 水稻试验田分为11个小区如图1所示, 设有4个氮肥梯度, 氮肥施入量分别为0、 600、 900和1 200 kg· hm-2。 由于水稻叶片氮-磷吸收具有互作效应[8], 水稻对磷素的吸收会随着氮肥施入量的不同发生变化, 从而水稻磷素含量(LPC)具有差异性, 因此实验中未对磷肥设置梯度, 各小区施入量相同均为1 080 kg· hm-2, 其他管理措施全部相同。
 | 图1 试验田小区分布图Fig.1 Diagram of the experimental plot layout |
自2021年6月起在水稻的全生育期进行采样, 采样间隔为3~5 d, 采样前准备好自封袋并按照小区进行标记, 在试验田的每个小区中随机选择一穴水稻作为样本点进行破坏性采样, 将选择的样品装入自封袋带回实验室, 去除根部, 保留叶片部分, 将叶片经过105 ℃杀青2 h、 90 ℃下低温烘干、 称量并粉碎。 将粉碎后的样品装入带有标号的信封并统一存放于干燥器皿。
1.2.1 水稻叶片高光谱信息获取
水稻叶片光谱数据均使用HR 2000+光谱仪获取, 使用光谱仪配套的Ocean View软件采集光谱反射率, 该光谱仪生产于美国的海洋光学公司, HR 2000+可采集的光谱范围是400~1 000 nm, 它的分辨率是0.461 0 nm。 采集样品光谱前对仪器使用自带的白板进行校正, 为了减小误差, 严格按照每隔10 min进行一次白板校正。 在采集叶片光谱数据时, 探头需要紧紧贴在叶片上, 避免太阳光等因素带来的干扰[9]。
1.2.2 水稻叶片磷素浓度测定
检测水稻叶片磷素浓度方法为钒钼黄比色法。 测定前将磨好的样品去除杂质, 称量0.3~0.4 g样品放入锥形瓶中, 加入水、 硫酸以及高氯酸-硝酸混合液进行消解, 消解后放入容量瓶作为待测液。 取部分待测液放入50 mL容量瓶中, 加入二硝基酚指示剂与氢氧化钠溶液进行混合, 直至溶液颜色变为黄色, 调制好后加入钒钼酸铵显色剂并加水定容。 放置一段时间后, 利用比色皿对溶液的分光度进行测定, 根据吸光度值计算磷素含量[10]。
1.2.3 光谱数据预处理
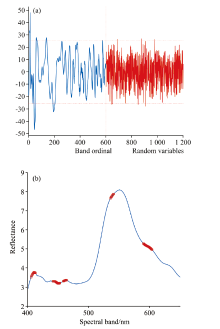
高光谱数据的采集过程中由于基线漂移、 样品不均匀、 散射以及人为操作等影响, 光谱曲线会存在一些包含在信号中的少量噪声。 SG平滑在过滤噪声时不会改变信号的形状及宽度, 而多元散射校正(multiplicative scatter correction, MSC)可以有效的消除由于散射水平不同带来的光谱差异, 从而增强光谱反射率与磷素含量之间的相关性[11], 鉴于此, 结合两种方法对光谱数据进行降噪处理。 经过SG平滑处理后的图像与原始图像形状大致相同, 而多元散射校正在消除光谱差异时, 利用理想光谱对经过SG平滑处理的光谱数据的基线平移以及偏移现象进行了修正, 两种方法处理后的的光谱图像如图2所示。
 | 图2 经处理的光谱数据图像Fig.2 Preprocessed spectral data |
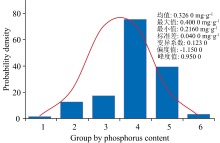
去除误差样本后, 最终保留有效数据171组, 将171组数据利用SPXY算法分成训练集与验证集, 得到训练集120组, 验证集51组, 磷素浓度统计结果如表1所示。 从图3可以看出, 样本数据均值为0.360 0 mg· g-1, 最大值为0.400 0 mg· g-1, 最小值为0.216 0 mg· g-1, 标准差为0.040 0 mg· g-1, 变异系数为12.783 0%, 峰度值为0.950 0, 小于10, 偏度值为-1.150 0, 绝对值小于3, 由此可知171组水稻叶片磷素含量数据基本符合正态分。
| 表1 水稻叶片磷素含量的数据集统计 Table 1 Statistics of phosphorus content in rice leaves for different data sets |
 | 图3 水稻171组叶片磷素含量的概率密度函数Fig.3 Probability density function of phosphorus content in leaves of rice group 171 |
经过预处理后的光谱数据依然是高维度数据集, 光谱波段之间存在大量的冗余信息且具有较强的相关性, 后续处理较为困难, 因此, 对水稻叶片光谱数据进行特征选择是提高模型准确性的关键。 本研究采用连续投影法与无信息变量消除法两种方法进行特征选择: 连续投影法已经广泛应用于多种作物的光谱特征波长的选取, 该算法不仅能筛选出共线性小且包含样本光谱关键信息的特征波段, 更重要的是能降低波段间的冗余度, 减少模型输入量的个数, 从而降低模型的训练时间[12]。 而无信息变量消除法是一种基于偏最小二乘法模型回归系数的降维方法[13, 14], 该方法的光谱矩阵由样本数据的光谱矩阵和随机噪声矩阵两部分组成, 以混合后的光谱矩阵为输入构建反演模型。
分别将采用连续投影法(successive projections algorithm, SPA)与无信息变量消除法(uninformation variable elimination, UVE)选取出的特征的反射率作为输入, 以实测水稻叶片磷素含量作为输出构建极限学习机(extreme learning machine, ELM)、 BP神经网络以及狼群算法优化的BP神经网络(Wolf Pack Algorithm, WPA-BP)三种反演模型。 狼群算法(wolf pack algorithm, WPA)最早于2011年提出, 2013年吴虎胜等[15]提出一种全新的狼群算法, 该算法具有并行性与种群多样性, 可以在同一时间从多个相互独立的点出发进行搜索从而提高算法的效率。 该算法将狼群分为头狼、 探狼和猛狼三类, 分别模拟狼群的游走、 召唤和围攻三种行为, 具有胜者为王、 强者生存的更新机制[16]。
鉴于此, 本研究使用狼群算法对BP神经网络进行优化, 弥补BP神经网络在权值选择上的随机性, 容易陷入局部最优解, 影响模型精度的缺陷, 同时加快BP神经网络的收敛速度, 提高搜索效率。
狼群算法规则:
(1)头狼: 在初始化过程中, 将最优的输出值作为头狼所在位置, 在每一个迭代过程中将最优狼所代表的函数值与头狼进行比较, 若优于头狼则取而代之, 若多个优狼值相等, 则随机选择一个;
(2)探狼: 随机选取除头狼外, [n/α +1, n/α ]之间的整数作为探狼个数Ssum, 计算探狼i的函数值, 并与头狼进行比较, 若Ylead< Yi, 该探狼代替头狼, 若Ylead> Yi, 探狼向各个方向前进一步记为stepa, 向第p(p=1, 2, …, h)个方向前进后探狼i的位置为
该探狼的函数值为
(3)猛狼: 头狼到达最佳位置后向Mnum=N-Ssum-1匹猛狼进行召唤, 猛狼以步长stepb靠近头狼, 如果在靠近途中找到函数值Yi> Ylead则该猛狼代替头狼重新发起召唤, 如果没有找到则直到与头狼距离达到如式(2)时停止并等待围攻指令;
(4)围攻: 头狼所在位置即为猎物所在位置Gk, 对于第k代狼群, 狼群的围攻行为表示为
式(3)中, stepc为围攻步长, 如果人工狼所感知到的被围攻的猎物浓度小于自身位置, 则不发起围攻行为。
 | 图4 狼群算法优化BP神经网络过程图Fig.4 Process diagram of BP neural network optimized by Wolf pack algorithm |
2.1.1 连续投影法(SPA)选取特征
图5为采用连续投影法对水稻叶片光谱特征进行选择的结果, 由图6可知, 随着特征个数的增加, 交叉验证均方根误差逐渐降低, 到达最低时的特征个数为11, 从波段数为11之后又呈上升的趋势, 由此可知特征波段个数太少或者过多都不利于水稻叶片磷素含量的正确确定, 因此确定最佳光谱波段数为11, 这11个特征波段分布在400~1 000 nm之间, 分别为411、 420、 428、 442、 467、 689、 797、 850、 866、 965和976 nm, 将选择出的特征波长对应的反射率作为3个模型的自变量引入模型。
 | 图5 SPA算法选取的光谱波段Fig.5 The spectral bands selected by SPA |
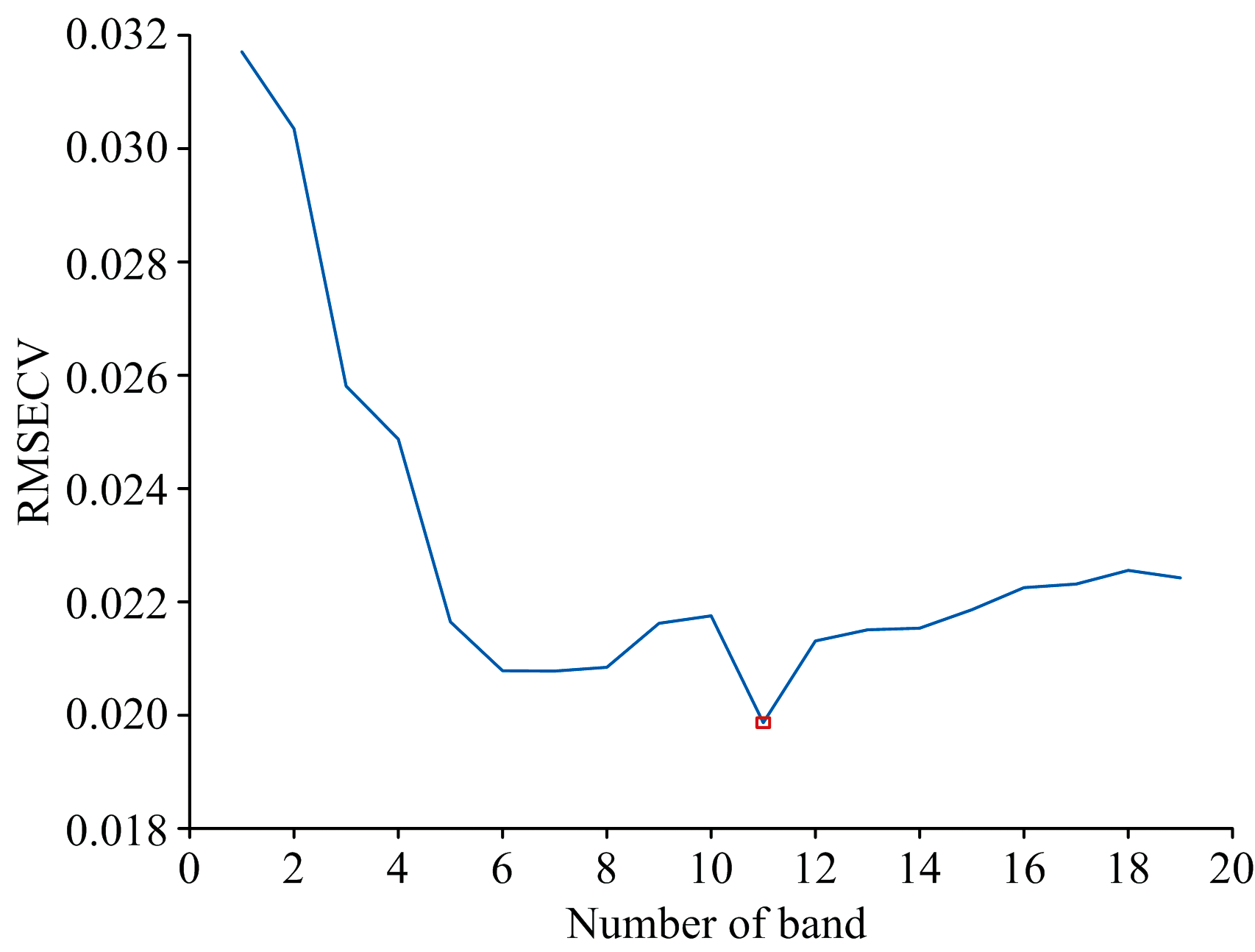 | 图6 最佳光谱变量个数Fig.6 Optimal number of spectral variables |
2.1.2 无信息变量消除法(UVE)选取特征
利用UVE对水稻叶片光谱数据进行特征波段筛选, 筛选结果如图7(a)所示: 竖排代表波段分割线, 左边蓝色线代表171个混合信息矩阵, 右边红色线代表UVE算法随机产生的噪声信息矩阵。 上下两条横排实线为正负阈值上下限, UVE算法筛选出的特征位于两条横实线之外, 实线外的数值所对应的变量用于建模, 共计47个, 分布在405~603 nm之间, 为了清晰的展示这47个特征的分布情况, 只保留了400~650 nm波段的图像, 如图7(b)所示。
 | 图7 UVE算法的筛选结果Fig.7 Filtering result of UVE |
对比分析SPA和UVE两种算法筛选到的光谱特征波段, 可以看出两种方法筛选到的特征大致分布在相同范围内, 为水稻叶片磷素含量的敏感区间。 采用UVE算法选取到的水稻叶片光谱特征有47个, 而经过SPA算法提取后仅保留了11个特征, 因此, 采用SPA算法可在筛选水稻叶片光谱特征的同时有效的降低变量的维数, 进而降低模型的复杂度。
2.2.1 极限学习机(ELM)与BP神经网络反演建模
水稻叶片光谱反射率经过SPA算法和UVE算法两种方法降维后, 将选择的特征的反射率作为模型的自变量, 水稻叶片磷素含量作为目标变量, 分别构建ELM与BP神经网络反演模型, 表2中给出两种模型的评价指标。
| 表2 ELM与BP神经网络反演模型评价指标 Table 2 Evaluation indexes of ELM and BP neural network inversion models |
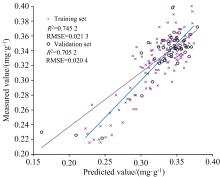
图8和图9为ELM模型的预测结果图, 由表2可知以UVE算法筛选的47个特征波长的反射率作为输入构建的ELM反演模型的训练集的决定系数为0.745 2, RMSE为0.021 3, 验证集的决定系数R2为0.705 2, RMSE为0.020 4。 以SPA算法筛选的11个特征波长的反射率作为输入构建的ELM反演模型的训练集的决定系数R2为0.774 2, RMSE为0.019 5, 验证集的决定系数R2为0.726 4, RMSE为0.020 9。
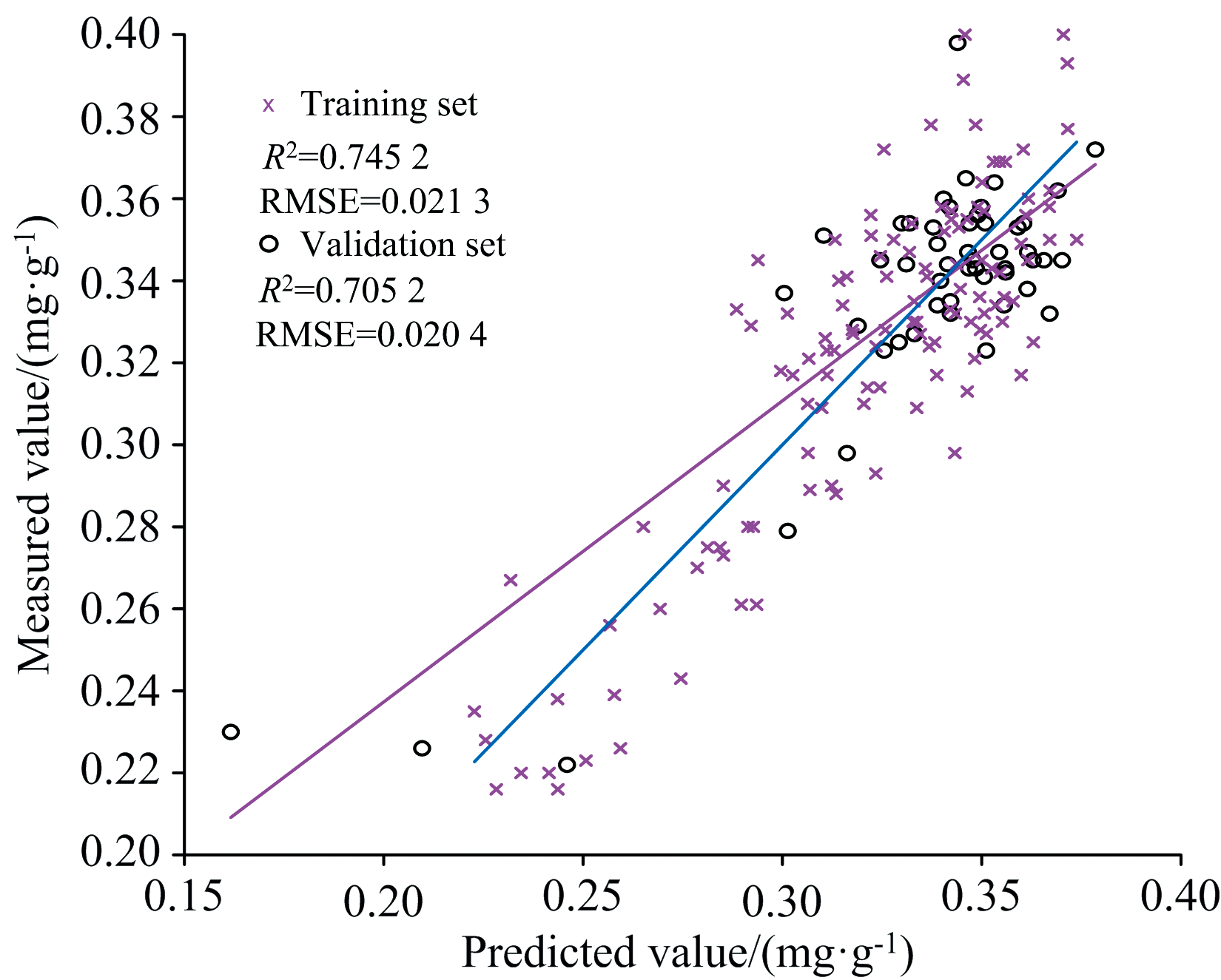 | 图8 UVE-ELM预测模型Fig.8 UVE-ELM predictive modeling |
 | 图9 SPA-ELM预测模型Fig.9 SPA-ELM predictive modeling |
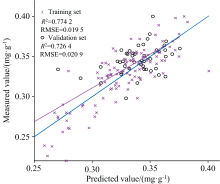
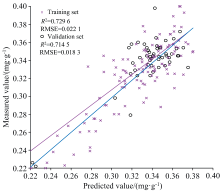
图10和图11为BP神经网络模型的预测结果图, 由表2可知以UVE算法筛选的特征作为输入构建的BP神经网络反演模型的训练集的决定系数R2为0.729 6, RMSE为0.022 1, 验证集的决定系数R2为0.714 5, RMSE为0.018 3。 以SPA算法筛选的特征作为输入构建的BP神经网络反演模型的训练集的决定系数R2为0.787 6, RMSE为0.019 7, 验证集的决定系数R2为0.759 2, RMSE为0.021 1。
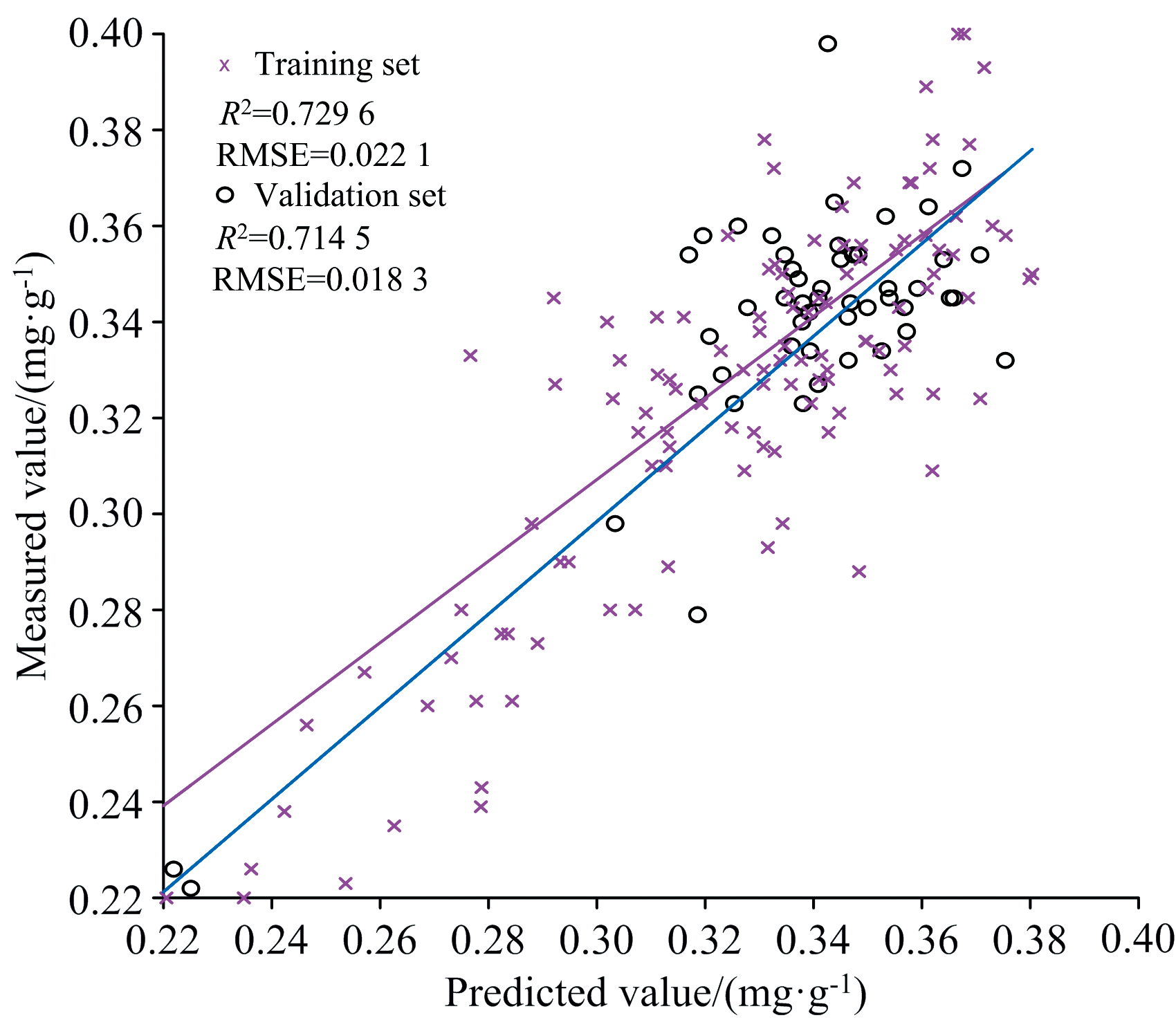 | 图10 UVE-BP神经网络预测模型Fig.10 UVE-BP neural network predictive modeling |
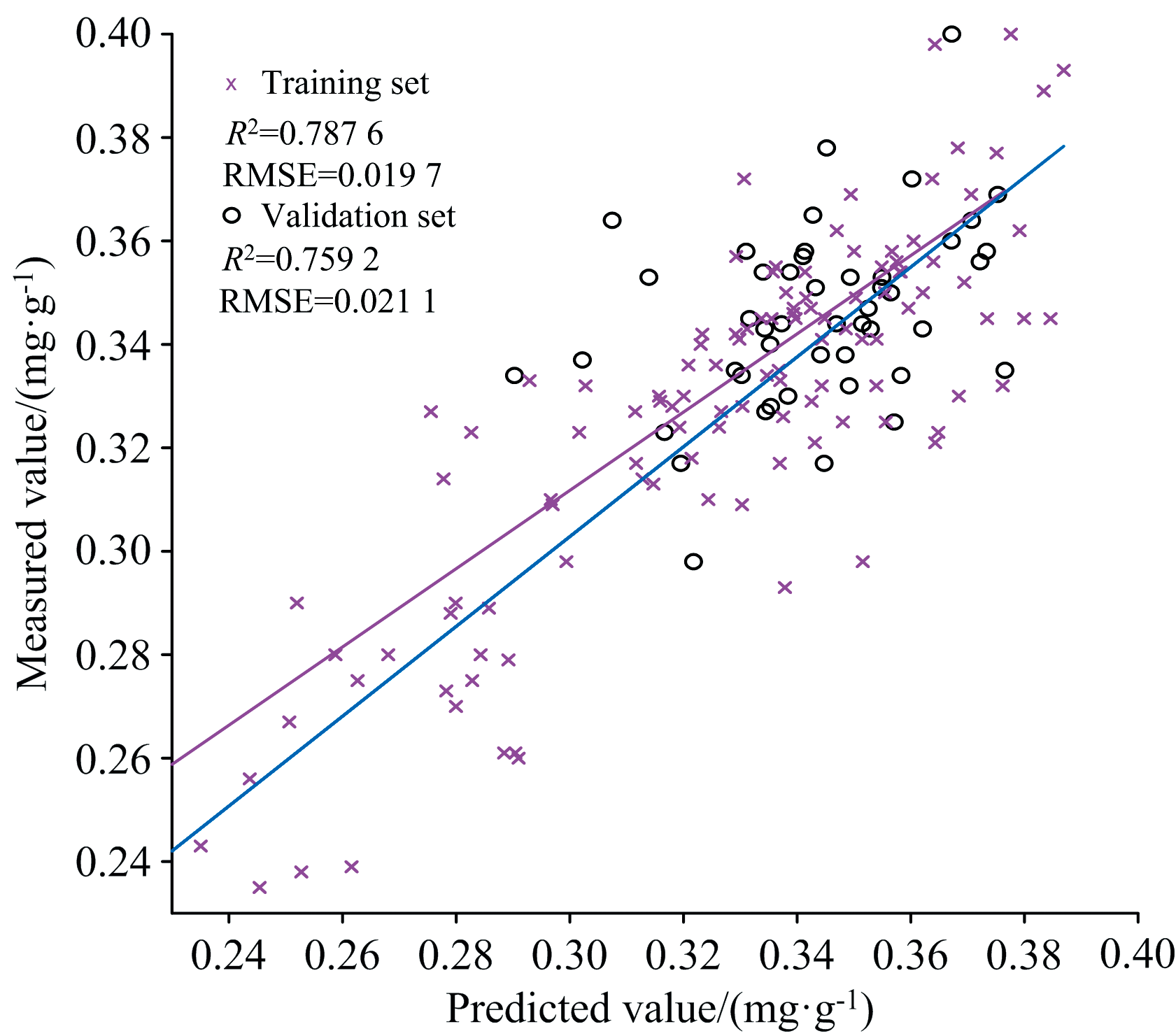 | 图11 SPA-BP神经网络预测Fig.11 SPA-BP neural network prediction |
根据以上分析进一步显示了相较于UVE算法, 以SPA算法为基础构建水稻叶片磷素含量反演模型更具有优势。 而通过对比ELM模型和BP神经网络模型的结果发现, 无论是以UVE算法还是SPA算法挑选出的特征波长的反射率作为输入, BP神经网络模型的预测结果都更高一些, 模型的测试集R2提高了0.013 4, 验证集R2提高了0.032 8。 原因可能在于ELM具有收敛速度慢, 训练过程长等缺点, 但是BP神经网路自身存在容易得到局部最优解的缺陷, 因此, 本研究以BP神经网络为基础, 对其进行优化, 从而获得预测效果更好的反演模型。
2.2.2 狼群算法优化BP神经网络(WPA-BP)反演建模
经过狼群算法优化后的BP神经网络模型结果如图12和图13所示。 从图中可以看出, 以UVE算法筛选的特征波长作为输入构建的WPA-BP反演模型的训练集的为0.733 6, RMSE为0.021 8, 验证集的决定系数R2为0.724 5, RMSE为0.017 4。 以SPA算法筛选后的特征波长反射率为输入时, 训练集决定系数R2为0.829 3, RMSE为0.017 2, 验证集的决定系数R2为0.803 4, RMSE为0.018 0。 相比于ELM和BP神经网络模型, 模型的验证集R2提高了0.044 2, RMSE降低了0.003 1, 预测精度有了一定的提升, 说明采用狼群算法优化BP神经网络在水稻叶片磷素含量反演上具有一定优势。 原因在于使用狼群算法对数据进行搜索时, 随机性与被选择的概率会大大提高, 同时狼
 | 图12 UVE-WPA-BP神经网络预测Fig.12 UVE-WPA-BP neural network prediction |
 | 图13 SPA-WPA-BP神经网络预测Fig.13 SPA-WPA-BP neural network prediction |
群算法的全局收敛性强且具有较高的容错性, 较好的弥补了BP神经网络容易陷入局部最优解的缺陷, 从而提高了模型的精度, 稳定性及泛化能力。
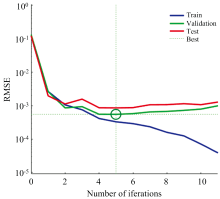
WPA-BP的网络误差训练曲线如图14所示, 从图中可以看出训练集的误差曲线呈降低趋势, 验证集的误差曲线逐渐降低至最低点后趋于平稳又逐渐上升, 在第5次迭代时达到期望误差, 说明经过狼群算法确定BP神经网络的权值和阈值可以减少BP神经网络自身的搜索时间, 从而提高算法的搜索效率, 节省了运行时间。
 | 图14 WPA-BP网络训练误差曲线预测Fig.14 Training error curve of WPA-BP network prediction |
水稻叶片磷素含量与光谱波段之间的关系是非线性的, 利用机器学习算法在分析二者关系方面更具有优势, 并且检测磷素含量的传统方法不仅需要破坏性采样还存在操作复杂、 耗时长等缺点。 而利用机器学习算法在能够满足方便省时、 快速准确的分析要求的同时还具有操作步骤简便、 准确度高等优点。 因此, 以水稻为研究对象, 利用海洋光学HR2000+测得水稻叶片的光谱数据, 采用钒钼黄比色法测定水稻叶片磷素含量, 对比分析采用的UVE与SPA两种降维方法以及ELM、 BP神经网络以及WPA-BP三种模型的反演结果, 得到以下结论:
(1)采用UVE算法共筛选到47个光谱特征, 分布在405~603 nm处; SPA算法筛选出11个特征, 分别为411、 420、 428、 442、 467、 689、 797、 850、 866、 965和976 nm。 在相同的模型预测条件下, 以SPA算法筛选的特征波长为输入时, 模型的测试集R2高于UVE算法0.095 7, 验证集的R2高于UVE算法0.078 9, 证明了SPA算法在提取水稻叶片光谱特征建立反演模型上的优越性。
(2)相较于ELM, BP神经网络模型的反演效果更好, 训练集R2为0.787 6, 提高了0.013 4, 验证集的决定系数R2为0.759 2, 提高了0.032 8, 因此, 以BP神经网络为基础对其进行了优化。
(3)以相同的光谱特征波段作为输入构建WPA-BP反演模型时, 训练集R2为0.829 3, RMSE为0.017 2, 验证集的决定系数R2为0.803 4, RMSE为0.018 0。 相较于BP神经网络, 验证集的R2提高了0.044 2, RMSE降低了0.003 1, 证明了使用狼群算法对BP神经网络进行优化可以提高模型对水稻叶片磷素含量的预测能力。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|