



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
应用最小角回归索套算法优选苹果糖度预测模型的建模样本和波长
[王昱麒 , 李斌, 朱明旺, 刘燕德
, 李斌, 朱明旺, 刘燕德* ]
, 李斌, 朱明旺, 刘燕德]
|
|


作者简介: 王昱麒, 女, 1999年生, 华东交通大学机电与车辆工程学院硕士研究生 e-mail: wangyuqisnewemail@163.com
糖度是评价苹果内部品质的重要指标之一。 建立苹果糖度预测模型时, 建模样本和波长的质量影响模型的准确性和后期的更新维护。 以90个苹果样本为研究对象, 采集350~1 150 nm波段共1 044个波长的苹果近红外漫透射光谱, 研究基于最小角回归索套算法(LASSOLars)优选建模样本和波长的有效性和可行性。 结合使用Norris平滑、 一阶微分和归一化变量排序对光谱预处理。 根据浓度排序划分样本集的75%为原始训练集(68个)和25%为预测集(22个), 使用LASSOLars建立优选训练集, 对比LASSOLars和蒙特卡罗无信息变量消除、 竞争性自适应重加权法, 从样本、 波长的数目和分布以及模型的结果进行对比分析。 结果表明, 优选训练集压缩了原始训练集16%的样本, 在不改变原始训练集平均水平的前提下, 更接近预测集分布, 没有削弱模型质量。 优选和原始的训练集交叉验证均方根误差RMSECV分别为0.460和0.491, 交叉验证决定系数$R_{CV}^{2}$分别为0.913和0.916, 预测集均方根误差RMSEP分别为0.462和0.471, 预测集决定系数$R_{P}^{2}$分别为0.909和0.906。 LASSOLars筛选出40个信噪比高的波长, 数目最少, 建立的模型效果最好, RMSECV, $R_{CV}^{2}$, RMSEP, $R_{P}^{2}$和RPD分别是0.933, 0.400, 0.944, 0.373和2.838。 基于LASSOLars优化建模样本和波长建立苹果糖度预测模型, 拓展了LASSOLars算法在子集选择方面的应用, 为优化、 更新和维护模型提供思路。
Sugar degree, one of the important indicators, is evaluating apples’ internal quality. When establishing a parsimonious model for analyzing apple sugar degree, the quality of calibrated samples and wavelengths affect the model’s accuracy, later update and maintenance.In this paper, 90 apples were taken as objects, a total of 1 044 wavelength points in the 350~1 150 nm spectra bands were collected. This paper studied the efficiency and feasibility of the Lasso implemented Least Angle Regression (LASSOLars) on sample and wavelength optimization.A combination of Norris derivative filtering, first-derivation and Variable Sorting for Normalization was used to preprocess. Considering the concentration ranking, split 75% of the sample dataset into the original train dataset (68 apples) and 25% into the test dataset (22 apples), and obtained the optimal train subset by LASSOLars. Compared LASSOLars with other two variables selection methods such as Monte Carlo Uninformative Variable Elimination and Competitive Adaptive Reweight Sampling respectively. Analyzing the model results, samples and wavelength sizes & distributions. The result shows that the optimal train subset compressed 16% of the original train dataset. At the same time, not changing the average level of the original train dataset, and the distribution was closer to the test dataset, the model quality was not weakened after reducing calibrated samples.The RMSECV of the optimal train subset and original train dataset were 0.460 and 0.491, the $R_{CV}^{2}$ were 0.913 and 0.916, the RMSEP were 0.462 and 0.471, $R_{P}^{2}$were 0.909 and 0.906. LASSOLars selected out 40 wavelength points, the least size with the best results and highest signal-to-noise ratio, RMSECV, $R_{CV}^{2}$, RMSEP, $R_{P}^{2}$and RPD were 0.933, 0.400, 0.944, 0.373, 2.838. Based on the samples and wavelengths optimization by LASSOLars, which expanded the application of LASSOLars in subset selection, and provides ideas for optimizing, updating and maintaining the model.
苹果营养物质丰富, 药用价值高, 种植时间长, 遍及各大洲, 品种繁多, 是我国出口排名第一的水果。 开展基于苹果糖度快速检测分级技术研究具有重要意义。 近红外光谱分析具有简单, 快速, 无损、 效益高的特点, 与化学计量学结合建立定性和定量分析预测模型是农业食品领域的流行分析工具。 然而, 在光谱采集和建模过程中, 当建模样本和波长已经具有代表性后, 再引入建模样本和波长就会引入分析误差, 带来冗余, 覆盖有用的信息, 降低模型性能, 增加光谱分析的成本效益[1]。 选择合理有效的建模样本不仅可以改善上述问题, 当遇到模型界外样本时, 还便于更新和维护模型, 并且样本的选择在多元校正模型的传递中也非常重要[2, 3]。 因此, 对建模样本和波长进行优选是非常必要的。
Zhou等[4]表明, 在某些情况下, 与所有样本建立的模型相比, 在多元校正中使用代表性样本可以改善模型性能。 Nisha Shetty等[5]预测草中的氮浓度, 使用Puchwein提出的优选建模样本的方法, 从118个原始训练集样本中优选出19个样本, 建立了更为准确的PLS模型, 有效提高了NIR光谱分析的成本效益, 提高预测准确性。 周玉等[1]提出一种基于K均值聚类的分段样本数据选择方法, 利用该方法, 平均压缩训练集样本66.93%的前提下, 提高了BP网络、 LVQ网络和可拓神经网络分类器的性能。 虞欣等[6]提出了一种适用于训练样本选择的斜交因子模型方法, 将该方法应用于澳大利亚野外航空影像分类中, 精确度平均提高了3%, 精确度的波动从0.006 1下降到0.004 6。 李江波等[7]利用连续投影(SPA)算法可以最大限度消除共线性变量的特点, 将其应用在草莓可溶性固体含量预测模型的样本优选上, 经过竞争自适应重加权算法(CARS)优选波长, SPA优选样本及二次变量优选, 最终获得了25个波长和98个样本, 给出了最优的CARS-SPAS+V-MLR草莓SSC含量预测模型。
基于最小角回归的索套算法(LASSOLars)[8]作为一种子集选择算法, 常作为一种副算法应用到波长选择中弥补主波长选择算法波动性、 冗余性和计算量大等缺陷[9], 没有在选择样本上应用。 蒙特卡罗无信息变量消除(MC-UVE)[9]和CARS[7]算法是常用且典型的波长选择算法, 在近红外光谱波长选择后均取得了很好的建模效果。
以苹果样本为研究对象, 基于苹果的近红外漫透射光谱, 探讨基于LASSOLars方法优选建模样本和波长的有效性和可行性, 分析了原始训练集和优选训练集建立的模型性能、 样本分布; 比较LASSOLars波长选择算法与MC-UVE和CARS变量选择方法用于关键波长选择的效果, 以期提高苹果糖度预测模型的准确性。
实验使用的所有苹果均购于某商业苹果园, 苹果运达实验室后人工剔除存在损伤或缺陷的样品, 共挑选出90个苹果样本进行表皮清洁、 干燥, 在果柄端每间隔90° 均匀标记4个位置和编号, 如图1所示。 样本置于实验室环境下存放24 h达到室温后采集光谱和理化参数测量。
 | 图1 样本编号示意图Fig.1 The samples marked for measurements |
采用由本课题组自主研发动态在线近红外漫透射检测装置(见图2), 光谱仪波长范围为350~1 150 nm, 光照强度、 积分时间和装置运动速度设置为6.5 A、 120 ms和0.5 m· s-1。 光谱采集的具体步骤如下: 首先打开装置运行半小时后, 按照编号顺序和位置顺序, 逐一将待测水果以果柄果萼连线与输送系统运行方向一致的位形, 放置于黑色果杯上, 随传送带运到与水平位置呈45° 固定且对称分布在两侧的10盏12 V/100 W的卤素灯下, 样本被照射后的漫透射光谱数据由正下方的光纤探头接收, 光谱仪将光纤探头传递的信号处理后再传入计算机保存下来。 重复上述过程4次, 采集全部90个苹果的4个位置的光谱。 对每个样本的4条光谱求平均作为该样本的光谱。
苹果样品的糖度值采用折射式数字糖度仪(PR-101a, 日本)测量, 测量过程为: 用水果刀切下四个光谱采集部位的部分果肉, 将果肉挤出果汁, 滴在糖度仪的测量位置, 测得苹果此位置的糖度值。 取四个位置的平均糖度值作为该苹果样品的糖度值。
 | 图2 近红外在线检测系统Fig.2 On-line NIR detection system |
样本集划分前, 采用3σ 法[10]检测糖度异常样本, 未发现有异常样本。 根据糖度值从大到小对所有样本重新排序, 采用浓度梯度法[11]按3:1划分原始训练集(raw training set)和预测集(test set), 以保证训练集样本的浓度范围涵盖整个预测集的浓度范围。 因此, 90个样本中训练集样本68个用于训练糖度预测模型, 预测集样本22个用于对模型预测性能进行评判。
1.4.1 基于最小角回归的索套算法
使用最小角回归(Lars)求解实现索套(LASSO)模型的方法叫基于最小角回归的索套算法(the least absolute shrinkage and selection operator implemented least angle regression, LASSOLars)。 LASSO是基于L1正则项的子集选择算法, 它的损失函数定义如式(1)
α 是控制LASSO估计的正则化程度和子集大小的参数。 由于L1正则项绝对值的形式, 该方法在子集选择时直接将一些系数β j压缩为0。 Lasso在高维数据集上具有优势, 擅长处理复共线性数据, 确定最有效的子集[12]。 缺点是它是一种计算量大的有偏估计, 即通过增大预测偏差来减小方差产生误差较小的估计值[13]。 最小角度回归可以加速计算并使LASSO产生偏差小的解。
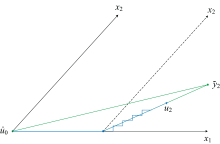
Lars在连续的循环中建立估计值
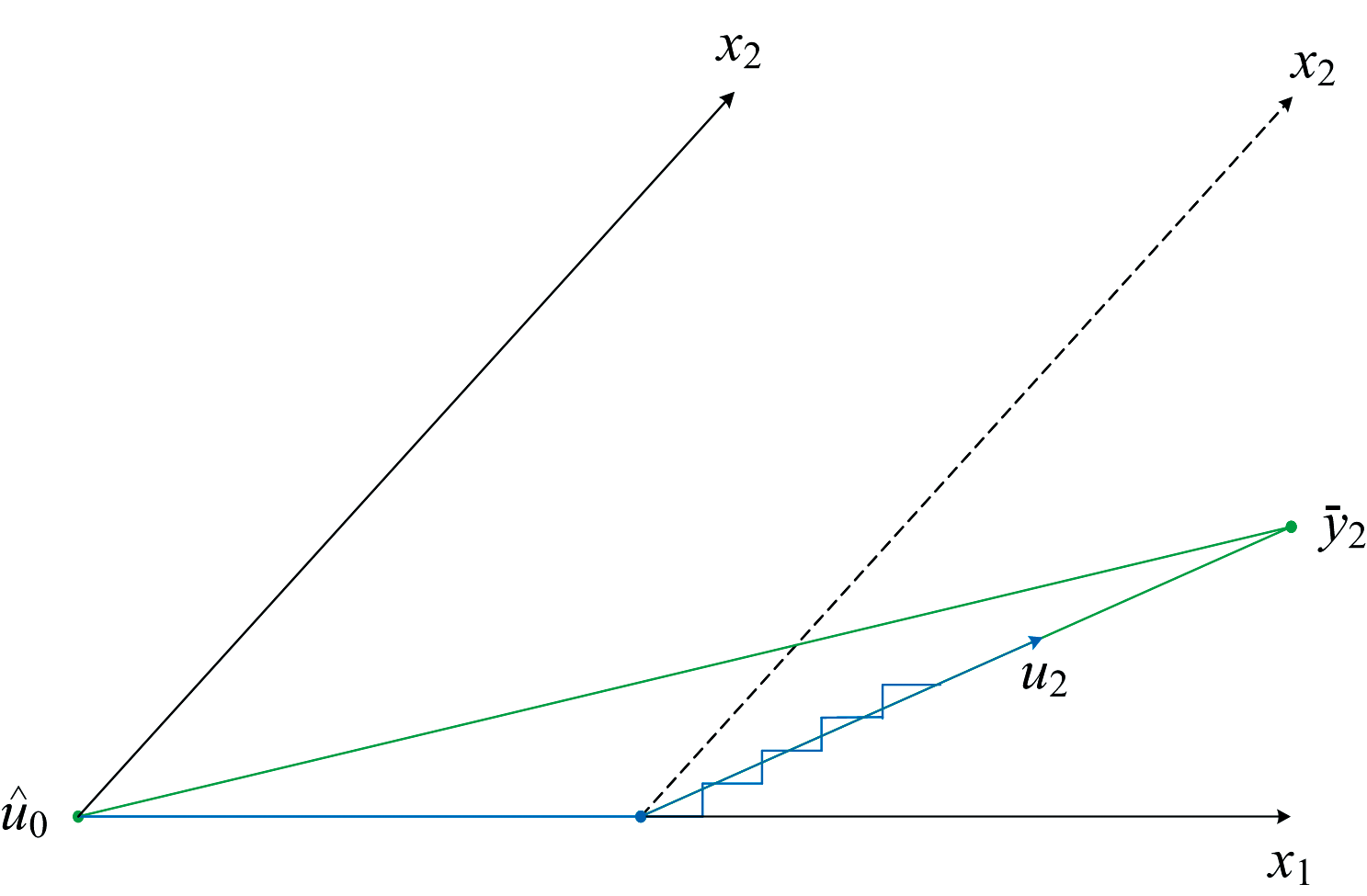 | 图3 具有2个变量的Lars算法Fig.3 Lars with 2 variables |
采用LASSOLars对波长进行选择外, 最关键的是用来对训练集样本进行优选, 建立优选训练集(optimal train set), 基本原理如图4所示。
 | 图4 LASSOLARS样本选择原理Fig.4 Principle of sample selection by LASSOLars |
1.4.2 竞争性自适应重加权算法
竞争适应性重加权采样法(competitive adapative reweighted sampling, CARS)是一种基于PLS回归系数绝对值大小的迭代强制性竞争的波长选择方法。 每次迭代前采用蒙特卡洛采样方法(MCS)按固定比例从样本集中重新随机选择训练集样品, 计算出PLS模型中每个波长对应的回归系数bi, 每个波长对应的加权权重ω i。 采用指数衰减函数按由波长数和迭代次数计算的比率对波长进行快速强制性剔除后, 再使用适应性重加权采样方法对波长进行竞争性选择。 最终得到迭代次数N个波长子集, 然后采用交互验证方法对波长集进行评估, 选用RMSECV值最小时对应的波长子集作为最后的选择结果。 计算过程中将N设为常用的50次, 用该方法作为参考方法比较研究LASSOLars的波长选择性能。
1.4.3 蒙特卡洛无信息变量剔除
蒙特卡洛无信息变量剔除(Monte Carlo uninformative variable elimination, MC-UVE)是一种基于全谱PLS模型回归系数稳定性的波长选择方法。 该方法首先采用蒙特卡洛采样法对样本子集进行采样, 然后根据稳定性对所有波长进行排序; 根据经验设定阈值, 按照排序逐步剔除稳定性小于阈值的波长建立一系列子模型, 然后通过比较子模型的预测效果确定建模波长; 预测效果的统计量一般选择训练集的交叉验证均方根误差, 该值最小的子模型对应的子集即为最终的建模波长。 该方法同样作为参考方法用于LASSOLars波长选择性能的比较研究。
1.4.4 模型评价
采用训练集交叉验证决定系数(determination coefficient of cross validation,
式(2)— 式(4)中, n表示参与建模的训练集或预测集的样本数, yi和
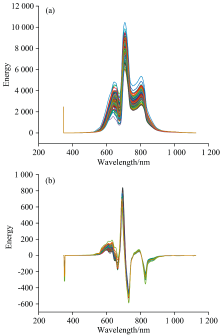
图5(a)是90个样本的原始近红外光谱, 光谱吸收特征的变化反映了苹果内部不同组分信息含量的差异。 从波形上看, 各样本光谱波形基本相同, 都存在三个波峰和两个波谷, 波峰的位置都在650、 720和800 nm附近, 波谷的位置都在680和750 nm附近。 650 nm处的波峰和680 nm处的波谷可能与样本成熟度有关: 650 nm处于醇类物质吸收带, 成熟果实中醇类物质含量高, 吸收峰强; 680 nm处于叶绿素的吸收带, 成熟果实叶绿素含量少, 吸收峰弱。 720 nm附近的吸收峰主要与碳氢键伸缩振动5倍频有关, 主要反映样本内部的碳水化合物的含量的差异。 处于750 nm的波谷和800 nm的吸收峰主要与O-H三倍频振动有关, 含水量影响了光子的吸收。
 | 图5 样本原始光谱(a)和预处理后的光谱(b)Fig.5 Original (a) and preprocessed (b) spectra |
常规光谱预处理方法包括滤波: Norris平滑滤波(Nwd(0))、 Norris一阶微分滤波(Nwd(1))、 Norris二阶微分滤波(Nwd(2))和散射校正: 多元散射校正(multiplicative scatter correction, MSC)、 归一化变量排序[15](variable sorting for normalization, VSN)。 不同预处理方法处理结果如表1所示。 通过建立PLS模型分析, Nwd(1)和VSN结合的预处理效果最好, 经预处理后的光谱如图5(b)所示。
| 表1 原始训练集不同预处理结果对比 Table 1 Comparison of different preprocessing methods for the original train dataset |
表2为90个苹果样本糖度值统计结果。 由表2知, 90个样本糖度值分布较为均匀(标准差为1.206 4), 原始训练集和预测集的糖度值范围分别为9.625~15.9和9.775~15.875° Brix, 训练集范围涵盖了预测集, 有利于建立一个较好的预测模型。 训练集和预测集均值相差不到0.1° Brix, 无偏标准差相差超过0.05° Brix, 训练集离散程度小, 直接建模容易过拟合, 对建模样本进行优选有助于提高模型准确度。
| 表2 苹果糖度统计结果 Table 2 The statistical results of Brix value of apple |
有效合理地消除一些样本有助于建立一个稳健的校正模型。 根据图4所述的LASSOLars样本优选原理进行样本选择。
在执行LASSOLars样本优选的过程中, 计算所有样本的平均光谱作为参考光谱, 根据参考光谱建立不同的样本子集, 采用不同的样本子集建立PLS回归模型, 根据各模型计算的RMSECV、 RMSEP和拟合情况决定最佳的优选训练集。
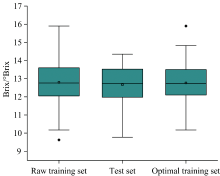
表3是分别用原始训练集和LASSOLars优选训练集建立的PLS模型结果。 根据表3, 优选训练集所建PLS模型的模型质量低(2.468 7< 2.513 3), 这是由于模型质量在RMSECV没有明显差别时, 标准差越大, RPD值越大。 从均方根误差和决定系数看LASSOLars-PLS模型的建模样本数减少了11个后并没有削弱模型预测性能。 图6所示是样本的箱线图, 优选训练集样本分布几乎没有改变原始训练集的平均水平, 分布程度则与预测集趋于一致。
| 表3 苹果糖度统计结果 Table 3 The statistical results of Brix value of apple |
 | 图6 样本的箱线图Fig.6 Sample box chart |
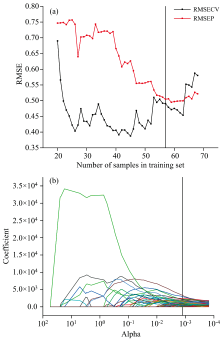
图7是LASSOLars样本选择的过程, 图中黑色竖线表示最佳的优选训练集所对应的建模样本数和α 值, PLS模型的因子数LVs默认为20, 从包含20个样本的优选训练集开始逐次向后建立模型。 图7(a)表示在变量优选的过程中不同样本子集建立模型的均方根误差曲线图。 从图中可以看到, 建模样本数为20时, RMSECV最大; 建模样本数为21~52时, 模型RMSEP远大于RMSECV, 可能由于参与建模的样本数不够令模型对信息的拟合关联度不够, 模型还要继续训练, 在建模样本数大于39时, 模型的泛化能力随建模样本数增加而增强; 建模样本数大于63后, RMSECV超过RMSEP, 模型过拟合。 建模样本数为53~62时, 模型的RMSEP继续减小, RMSECV增加但二者的方差减小, 即模型对训练集和预测集样本的预测能力趋于一致, 在建模样本数为55个时, RMSECV和RMSEP的方差最小, 建模样本数为57个时, 方差第二小, RMSECV和RMSEP继续减小。 因此, 最佳的优选训练集确定为57个样本, 此时的模型对训练集和预测集样本的预测能力一致, 误差相对较小。 图7(b)表示LASSOLars对训练集68个样本系数α 的压缩情况, 保留系数α 不为0的样本。
 | 图7 LASSOLARS样本选择Fig.7 Samples election by LASSOLars |
为进一步精简模型, 表4分别给出了LASSOLars、 MC-UVE和CARS算法在苹果优选训练集上的表现情况。 CARS运行过程中选择的波长数变化很大, 模型质量自然也不稳定, 表4显示的是CARS运行过程中模型预测结果较好的一次。 从表4中可发现, 三种算法选择的波长数相差很大, 选择后的波长所建立的PLS模型因子数一致, 对训练集样本的拟合能力和对预测集样本的预测能力都很优秀, LASSOLars是选择的波长数最少, 模型质量最高的波长选择方法。
| 表4 不同波长选择算法的PLS模型 Table 4 PLS modeling results by using different wavelength selection algorithms |
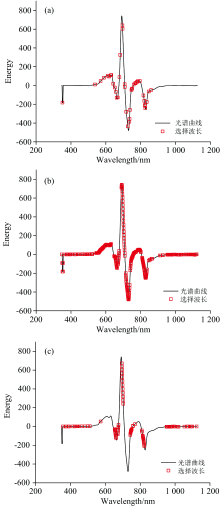
图8[(a)、 (b)和(c)]分别是LASSOLars、 MC-UVE和CARS算法选出的波长的分布情况, 可以看出LASSOLars选择的特征波长最少, 预测结果最好。 从分布情况来看, LASSOLars和MC-UVE算法选中的波长分布的位置与波峰、 波谷一致, CARS在650 nm波峰和750 nm波谷附近几乎没有选择, 这可能是CARS算法的预测表现不及LASSOLars和MC-UVE算法的原因。 从波长的有效性来说, MC-UVE和CARS算法选择的波长分散, 在有效波长外选择了很多信噪比低的波长, 影响了模型的精度和稳定性, 而LASSOLars算法保留了有效波长, 压缩了信噪比低的波长。 基于LASSO-Lars优选的建模样本和波长建立的模型获得了最好的预测结果, 图9是该模型对优选训练集和预测集的预测结果。
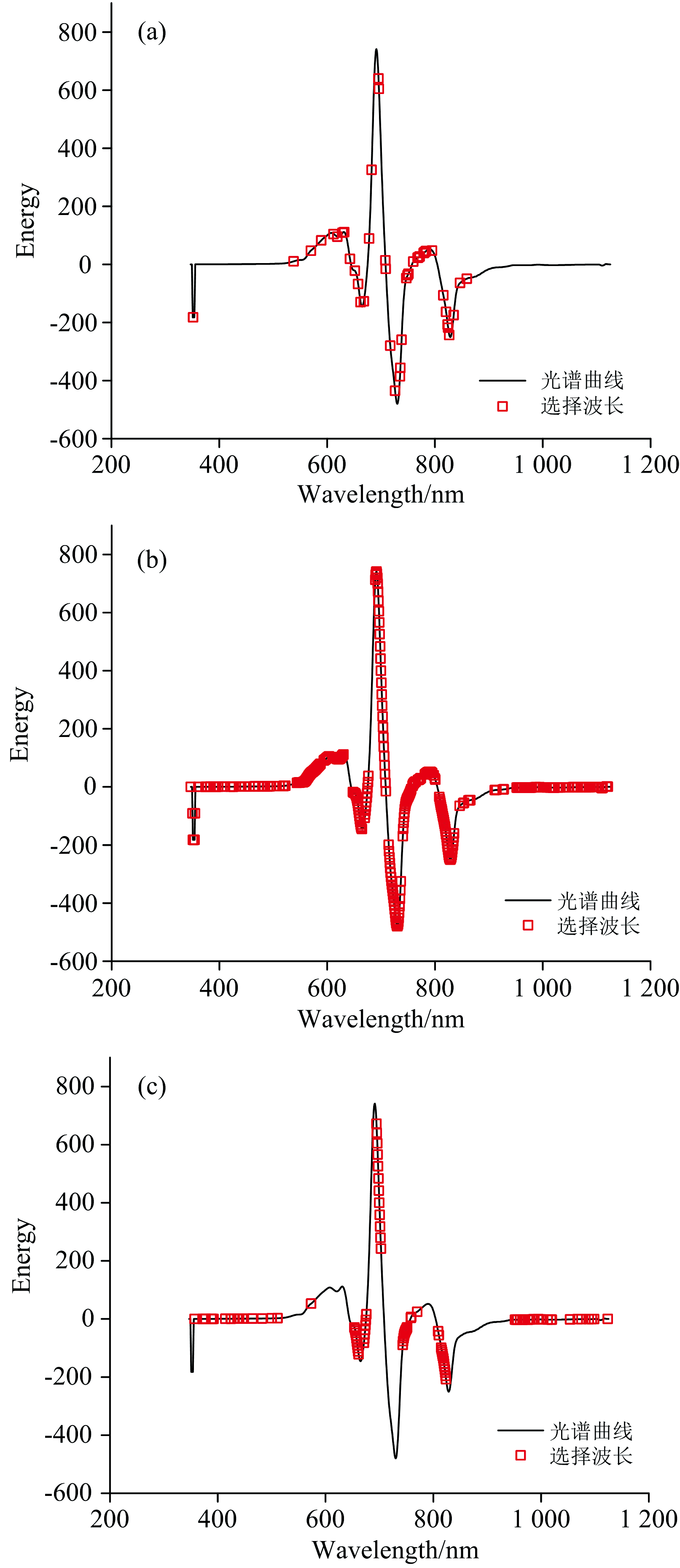 | 图8 基于LASSOLars (a), MC-UVE (b), CARS (c)的 特征波长选择Fig.8 Characteristic wavelength selected by (a) LASSOLars, (b) MC-UVE, (c) CARS |
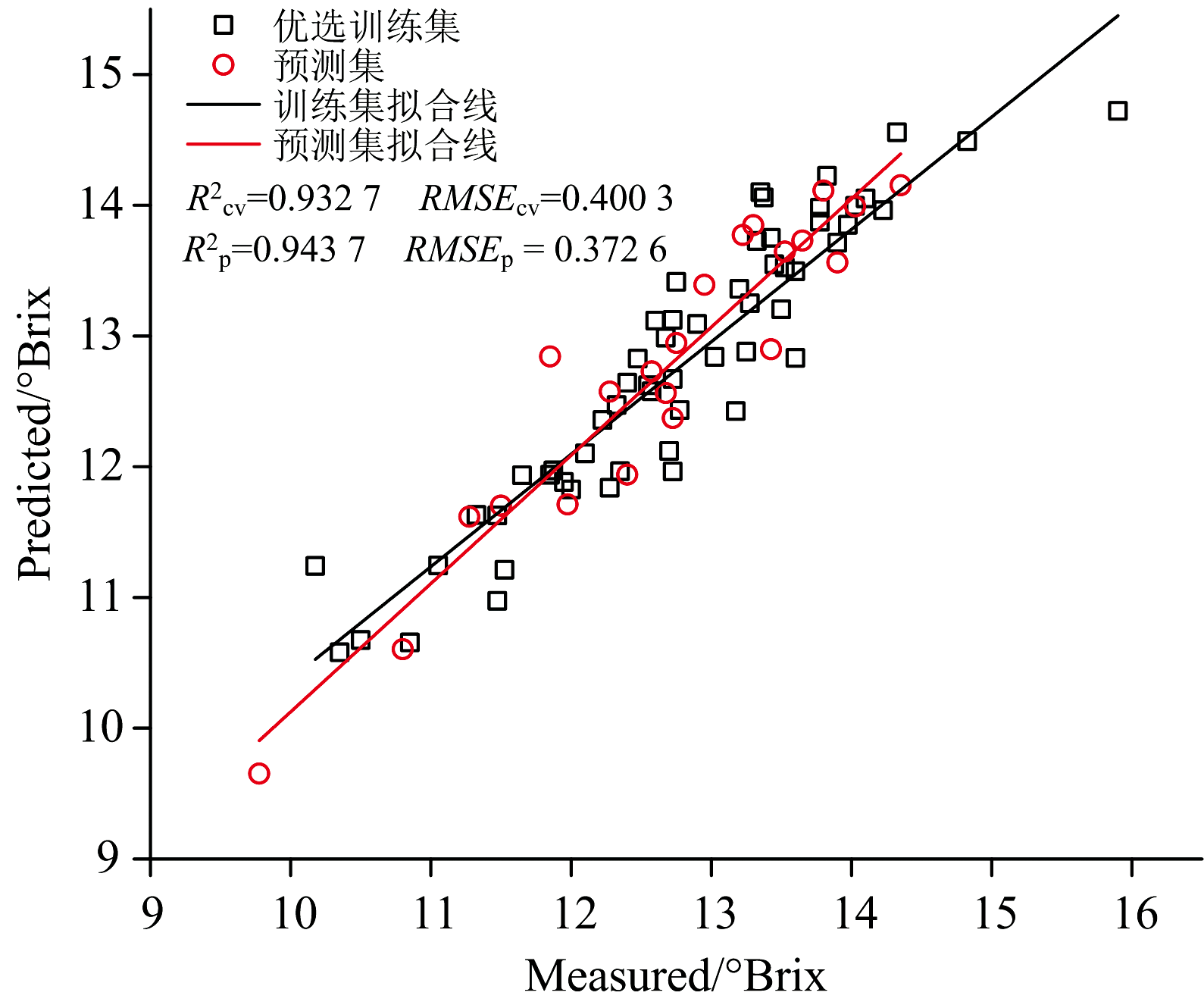 | 图9 LASSOLars-PLS模型对优选训练集和预测集的预测结果Fig.9 Comparison of Brix values between measured and predicted by LASSOLars-PLS model |
采用LASSOLars对训练集样本和波长进行优选, 为了验证该方法的有效性, 对比了原始训练集和优选训练集所建模型的性能和样本分布, 对比了LASSOLars与常用的MC-UVE、 CARS这三种波长选择算法的选择效果。 结果表明, 采用LASSOLars对训练集样本和波长进行优选的效果最佳, 从68个原始训练集中优选出57个建模样本, 1044个波长中优选了40个波长就可以给出最优的预测模型。 优选的57个训练集样本与原始训练集相比, 没有改变训练集的平均水平, 而样本分布程度与预测集更接近, 交叉均方根误差RMSECV从0.491 3减小到0.460 1。 使用该方法优选建模样本并不会削弱模型的训练效果, 预测均方根误差RMSEP从0.470 7减小到0.462 3, 有效减小了模型的泛化误差。 LASSOLars优选出40个波长数, 远小于MC-UVE算法的418个波长和CARS算法的104个, 且这40个波长均分布在信噪比高的波峰波谷处, 在信噪比低的波长处没有选择。 LASSOLars-PLS对优选训练集和预测集的预测效果最好, 其次是CARS-PLS、 MC-UVE-PLS, LASSOLars波长优选后建立的模型质量最好。 实验表明, LASSOLars方法对训练集样本和波长进行优选是有效可行的, 模型质量优于原始训练集和全谱波长, 所选建模样本分布更合理, 波长信噪比高, 提高了模型的精度, 拓展了LASSOLars的应用范围。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|