
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱技术对南阳豌豆产地鉴别研究
[吴木兰1  , 宋萧萧
, 宋萧萧1, * , 崔武卫1, 2 , 殷军艺1 ]
, 宋萧萧, 崔武卫|
|


作者简介: 吴木兰, 女, 1997年生, 南昌大学食品学院硕士研究生 e-mail: wumulan1001@163.com
近红外光谱检测技术可反映样品内部含氢化学键伸缩振动与合频吸收信息, 具有分析速度快、 经济、 重现性好以及环境友好等优点, 常用于食品、 药品及材料领域的检测分析之中。 豌豆是世界上最重要的栽培作物之一, 种植、 分布广泛, 具有高淀粉、 高蛋白、 低脂质等营养特性, 长久以来受到消费者的喜爱。 为了明确不同产地豌豆的近红外光谱建模差异, 对不同产地豌豆进行建模分析。 研究采集了河南省南阳市不同地区42份豌豆样本, 首先测定了豌豆的营养成分(总淀粉、 蛋白质、 水分、 灰分及脂质), 再重点采用近红外光谱中的积分球漫反射技术, 在12 000~4 000 cm-1波段对不同豌豆样品进行光谱采集, 通过判别分析模型(DA)结合不同的预处理方法得到最优预处理数据, 结合主成分分析(PCA)、 偏最小二乘判别分析(PLS-DA)以及正交偏最小二乘判别分析(OPLS-DA)等方法, 对光谱特征差异进行分类分析, 从而构建并验证南阳豌豆的产地识别模型。 结果表明, 不同区域南阳豌豆的营养组分及含量总体差异较小(总淀粉36.30%~46.93%, 蛋白质16.37%~25.50%, 水分6.78%~9.16%, 灰分2.29%~3.38%, 脂质0.37%~1.43%); 基于近红外光谱建立的判别模型表明, DA模型判别分析准确率可达92.4%, 并且PCA、 PLS-DA以及OPLS-DA得到的模型预测能力分别为96.7%, 85.1%和83.6%, 表明以上模型均可实现南阳豌豆鉴别模型的建立。 此外, 通过变量重要性投影值法提取(VIP>1.0)筛选出的不同产地差异波段显示, 4 710~4 000, 5 320~5 200以及7 200~6 220 cm-1可作为南阳豌豆产地鉴别的特异性检测波段。 该研究可为构建不同区域豌豆产地鉴别、 追溯信息库提供方法学依据。
Near-infrared spectroscopy can reflect the internal hydrogen-containing chemical bond stretching vibration and ensemble frequency absorption information of the sample, with the advantages of high-speed, economical, reproducible and environmentally friendly analysis, commonly used in food, pharmaceuticals and materials detection for analysis. Peas are one of the most important cultivated crops in the world, widely grown and distributed, with nutritional properties such as high starch, high protein as well as low lipid content, which consumers have long loved. In order to clarify the modeling differences in the NIR spectra of peas from different origins, modeling analysis was performed on peas from different origins. In this study, 42 pea samples collected from different regions of Nanyang city, Henan province, were investigated. Firstly, pea samoles’ nutritional components (total starch, protein, moisture, ash, and lipid) were determined. Then, with an emphasis on using the integrating sphere diffuse reflectance technology in Near-infrared spectroscopy, the spectra of different pea samples were collected in the wavelength range of 12 000~4 000 cm-1. By combining different pre-processing methods with discriminant analysis models (DA) to obtain the optimal pre-processed data and combining principal component analysis (PCA), partial least squares discriminant analysis (PLS-DA) along with orthogonal partial least squares discriminant analysis (OPLS-DA), the differences in the spectral characteristics were screened and analyzed, constructing and verifying the identification models of Nanyang peas.The results show that the overall difference in nutritional composition and content of Nanyang peas in different regions is slight (total starch 36.30%~46.93%, protein 16.37%~25.50%, moisture 6.78%~9.16%, ash 2.29%~3.38%, lipid 0.37%~1.43%), and the results of the discriminant model established based on Near-infrared spectroscopy showed that the accuracy of discriminant analysis for the DA model could reach 92.4%. The predictive abilities obtained from PCA, PLS-DA and OPLS-DA models were 96.7%, 85.1% and 83.6%, respectively, indicating that the above models can achieve accurate classification and identification of geographical origin for Nanyang peas. In addition, the results of the different bands among different geographical origins screened by the variable importance projection (VIP>1.0) method showed that 4 710~4 000, 5 320~5 200 and 7 200~6 220 cm-1 could be used as specific detection bands to identify geographical origins of Nanyang peas. Therefore, this study can provide a methodological basis to construct a database for the identification and traceability of pea’s origin in different regions.
豌豆(Pisum sativum L.)又称青豆、 荷兰豆, 属豆科、 野豌豆族、 豌豆属[1]。 豌豆富含蛋白质、 碳水化合物、 粗纤维以及维生素B1、 B2、 C等营养成分, 具有良好的降低胆固醇、 降血压、 平衡血糖、 抗癌等功能性, 以及低致敏性, 因此豌豆及其加工制品可作为粮食、 饲料以及传统蛋白(来源于动物或大豆)的替代品[2, 3, 4, 5]。 豌豆原产于地中海及中亚细亚地区, 是世界上重要的栽培作物之一。 目前, 我国是仅次于加拿大的第二大豌豆生产国, 国内豌豆产区众多, 主要集中于河南、 四川、 湖北等地。 不同产地赋予豌豆不一样的品质, 河南省是我国农业大省, 也是我国豌豆主产区之一。 目前, 农产品产地溯源主要采用傅里叶变换红外光谱[6, 7]、 拉曼光谱[8]、 液相色谱[9, 10]、 电感耦合等离子体质谱(ICP-MS)[11]以及营养成分指纹图谱识别技术[12]等。 用来检测豆类来源的方法主要有红外光谱技术[13]、 ICP-MS[11]以及营养成分指纹图谱[12], 其中傅里叶变换红外光谱技术在产地溯源过程中具有高效、 快速、 无损等优点[14], 较为常用。
近红外光是指波数在12 000~4 000 cm-1范围内的电磁波, 可以对检测样品中的— CH, — OH, — NH, C=C及C=O等化学键振动及光谱叠加吸收, 形成稳定而复杂的吸收光谱, 光谱的特性与样品的组分存在特定关系[15]。 Patrizia Firmani等[16]通过近红外光谱技术结合化学计量学方法构建了大吉岭红茶的产地模型, 通过偏最小二乘判别分析(PLS-DA)和类类比分类(SIMCA)进行分析, 其中PLS-DA模型得到的模型判别率高达95.4%。 Hui等[17]通过化学计量学方法结合近红外光谱技术对三个产地的人参进行了产地溯源研究, 应用三种算法, 即偏最小二乘判别分析(PLS-DA), 类类比分类(SIMCA)和连续投影算法-线性判别分析(SPA-LDA)的软独立建模, 构建模型以辨别样品起源; 相比之下, 发现SPA-LDA优于PLS-DA和SIMCA, 辨别率高达100%。 还有学者将近红外光谱技术结合OPLS-DA以及SIMCA等化学计量学方法用于芦笋[18]、 罗非鱼片[19]、 枸杞[20]、 葡萄酒[21]、 苹果[22]等食品的产地溯源研究。 由此可见, 近红外光谱在农产品产地溯源中应用广泛, 但在豆类中应用极少, 此外样品的状态和测定条件对最适模型参数会产生影响, 因此选择适宜的测试条件以及光谱预处理手段非常关键。
本研究采集南阳市不同区域(即卧龙区、 方城县、 社旗县、 唐河县及新野县)42份豌豆样本, 测定了南阳豌豆的部分营养成分含量, 并建立基于近红外漫反射技术的四种判别模型(DA, PCA, PLS-DA及OPLS-DA), 为南阳豌豆溯源研究提供了理论依据, 也为今后不同区域杂豆的产地鉴别提供了方法学依据。
将所采集样品分为训练集、 验证集。 训练集42份南阳豌豆于2020年12月采集于南阳市卧龙区(11份)、 方城县(8份)、 社旗县(8份)、 唐河县(8份)、 新野县(7份), 样品采自各区、 县不同地点。 验证集24份豌豆于2021年3月于网站采购, 四川省(8份)、 云南省(8份)、 江苏省(8份), 样品外观形貌如图1所示, 样品信息见表1, 所有豌豆样品均为青豌豆。 采集后将样品粉碎, 过100目筛后装入自封袋中, 储藏于干燥器中备用。
 | 图1 不同采集地区豌豆外观形貌图Fig.1 Appearance and morphology of pea in different collection areas |
| 表1 豌豆采样信息 Table 1 Sample information of pea |
硫酸铜、 亚甲蓝、 酒石酸钾钠、 氢氧化钠、 亚铁氰化钾、 乙酸铅、 硫酸钠、 甲基红、 盐酸、 石油醚(30~60 ℃)等试剂均为分析纯。
Nicolet iS50 FTIR光谱仪(美国Thermo Fisher Scientific公司, 配有积分球模块、 OMNIC光谱采集软件和TQ Analyst化学计量学分析软件); K9840凯氏定氮仪(济南海能仪器股份有限公司); PrepASH229全自动水分灰分仪(瑞士Precisa公司); RE-52AA旋转蒸发仪(上海亚荣生化仪器厂); 恒温水浴锅(常州国华电器有限公司); DHG-9140A电热鼓风干燥箱(上海一恒科学仪器有限公司); 万分之一天平[中国北京赛多利斯科学仪器(北京)有限公司]; 皇代多功能粉碎机(永康市铂欧五金制品有限公司); 100目标准筛(长沙市思科仪器纱筛厂)等。
1.3.1 营养成分测定方法
淀粉含量: 参照GB5009.9— 2016。 准确称取3 g样品, 先用石油醚分5次洗除脂质, 再用85%乙醇分次洗去可溶性糖制成试样溶液。 再采用碱性酒石酸铜甲液以及碱性酒石酸铜乙液进行试样溶液的滴定, 至蓝色刚好褪去为终点, 记录样液消耗体积。
蛋白质含量: 参照GB5009.5— 2016。 准确称取样品1 g, 至消化管中, 再加入0.4 g硫酸铜, 6 g硫酸钾及20 mL硫酸于消化炉进行消化, 当消化炉温度达到420 ℃之后, 继续消化1 h, 此时消化管中的液体呈绿色透明状, 取出冷却后加入50 mL去离子水, 于自动凯氏定氮仪上实现自动加液、 蒸馏、 滴定和记录滴定数据。
水分含量: 参照GB5009.3— 2016。 取一定量的样品(0.5~1 g)于全自动多样品水分含量分析仪中, 105 ℃加热至恒重, 根据前后质量变化计算水分含量。
灰分含量: 参照GB5009.4— 2016。 取一定量的样品(0.5~1 g)于全自动多样品水分含量分析仪中, 550 ℃加热至恒重(前后两次质量差不超过0.5 mg), 仪器可直接显示灰分含量百分比。
脂质含量: 参照GB5009.6— 2016。 准确称取样品3 g, 转入滤纸筒内, 将滤纸筒放入索氏抽提器的抽提筒内, 由抽提器冷凝管上端加入石油醚使其回流至回收瓶体积的2/3处, 抽提6 h, 回收并挥干瓶内残余石油醚, 再于(100± 5) ℃干燥1 h, 于干燥器内冷却0.5 h后称量。
1.3.2 光谱采集方法
取适量(~2 g)过100目筛的豌豆粉末于石英器皿中, 以积分球漫反射方式采集近红外漫反射光谱原始光谱数据。 实验参数: 扫描的波数范围12 000~4 000 cm-1, 分辨率4 cm-1, 扫描次数为64次, 室温保持在(25± 3) ℃左右。
1.3.3 统计分析
所有营养成分测定实验均重复三次, 结果表示为平均值± 标准偏差。 统计学数据分析软件采用SPSS Statistics 22(IBM软件, USA)。 化学计量学分析软件采用TQ Analyst(美国Thermo Fisher Scientific公司); SIMCA-P 14.0(瑞典Umetrics公司)。
南阳地区豌豆的总淀粉、 蛋白质、 水分、 灰分及脂质含量见表2。 可以看出, 南阳豌豆淀粉含量占比最高(36.30%~46.93%), 其次为蛋白质, 其含量分布在16.37%~25.50%, 除卧龙区S1— S4以及社旗县S26— S27含量在16%左右外, 其余样品均在21%以上。 水分、 灰分和脂质含量相对较低, 分别为6.78%~9.16%, 2.29%~3.38%以及0.37%~1.43%。 可见, 南阳豌豆具有高淀粉、 高蛋白[23]、 低脂质等特性, 但不同区域间营养成分差异较小, 因此后续采用近红外光谱技术, 通过对其精细化学结构分析, 建立南阳豌豆产地鉴别模型。
| 表2 南阳市42份豌豆营养成分分析 Table 2 Analysis of nutrient composition of 42 pea species in Nanyang City |
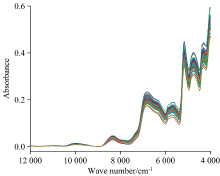
66份不同产地的豌豆所采集的近红外光谱图如图2所示。 分别采用判别分析模型、 主成分分析、 偏最小二乘判别分析以及正交偏最小二乘判别分析等四种分析方法建立产地鉴别模型。
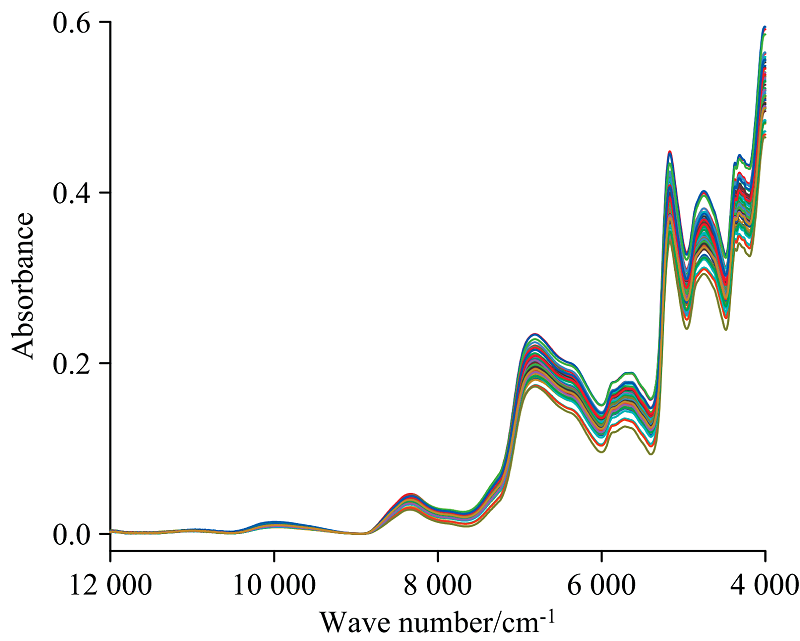 | 图2 豌豆近红外光谱图Fig.2 Near-infrared spectrum of pea |
2.2.1 DA模型建立
判别分析(discriminant analysis, DA)模型, 是根据观测到的某些指标对所研究的对象进行分类的一种多元统计分析方法[24, 25]。 将所采集的光谱图全部导入TQ Analyst软件, 通过选择乘法散射校正(multiplicative scatter correction, MSC)以及标准正态变量(standard normal variate, SNV)处理, 通过调节不同的处理方法, 即分别采用一阶导数、 二阶导数及Savitzky-Golay(SG)进行平滑处理, 将所得结果进行比较, 结果见表3。
| 表3 不同处理方式对DA模型的影响 Table 3 Influence of different processing methods on the DA model |
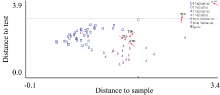
根据模型正确率最高原则进行最佳预处理方式的选择。 由表3可知, 仅采用SNV处理或采用SNV联合SG5-3, SG9-3以及SG13-3平滑处理后, 相对残差和为84.3%, 模型正确率最高, 达92.4%。 基于SNV处理所得的DA模型如图3所示。 图中正方形代表训练集豌豆, 三角形代表验证集豌豆, 可以看出, 66个样本中仅5个样本将验证集判别为训练集, 因而被判别为错误样本(红色箭头所示), 可见基于SNV处理所得的DA模型可准确实现南阳豌豆的产地别鉴别, 优于一阶导数、 二阶导数处理组。
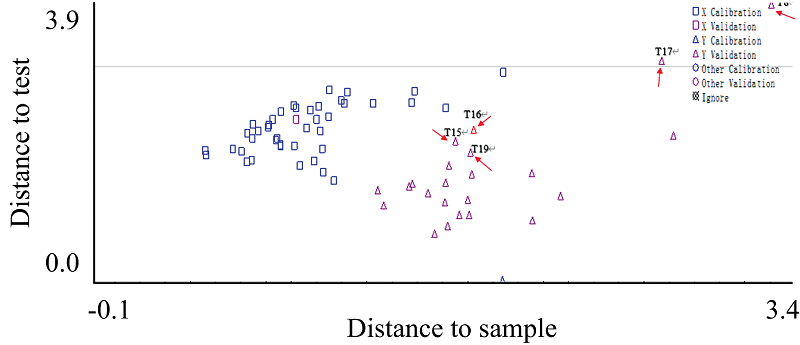 | 图3 基于SNV处理得到的DA模型 红色箭头指出的为错误样本Fig.3 DA model based on SNV processing The red arrow points out the wrong sample |
2.2.2 主成分分析
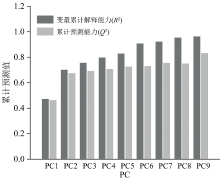
根据表3获取的最佳模型处理方式, 即对所采集的光谱数据进行SNV处理后导入SIMCA, 进行主成分分析(principal component analysis, PCA)。 PCA是一种应用广泛的无监督模式数据降维分析方法, 可有效揭示数据内部的结构和联系, 同时简化数据, 提高计算效率以及精度。 根据模型累计预测能力最高进行主成分的选择, 选取前若干个主成分分别作为化学计量学建立模型的输入变量进行建模(如前4个, 前5个, 前6个等等依此类推), 剔除异常样本后对模型的预测能力进行比较, 从而确定最佳主成分个数。 研究中选择4个主成分, 结果见表4, 模型预测能力为96.7%。
| 表4 主成分及模型预测能力 Table 4 Principal components and model predictive ability |
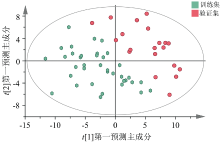
基于SNV处理所得的PCA-X模型如图4所示。 图中六边形代表训练集豌豆, 圆形代表验证集豌豆。 可以看出训练集豌豆与验证集豌豆能较好的区分两组样本, 并无重合区域, 说明该模型可实现对南阳豌豆的鉴别。
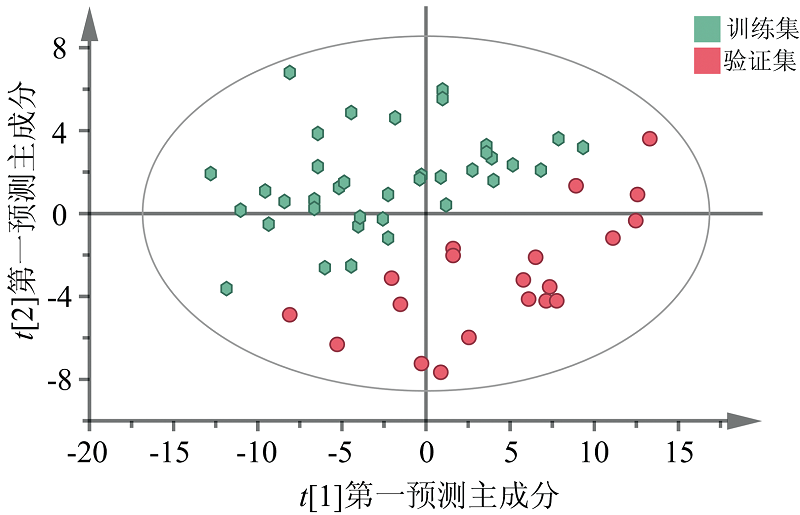 | 图4 主成分得分图Fig.4 Principal component score plot |
2.2.3 偏最小二乘判别分析
偏最小二乘判别分析(partial least-squares discrimination analysis, PLS-DA)是一种有监督模式的判别分析统计方法。
SNV处理后根据累计预测能力最强进行主成分数的选择, 选择6个主成分, 结果见表5。 剔除异常样本后用PLS-DA算法进行建模, 结果如图5所示。 该模型自变量累计解释能力(R2X)为98.7%, 因变量累计解释能力(R2Y)为91.1%, 累计预测能力(Q2)为85.1%。
| 表5 PLS-DA模型的主成分选择 Table 5 The choice of the principal components of the PLS-DA model |
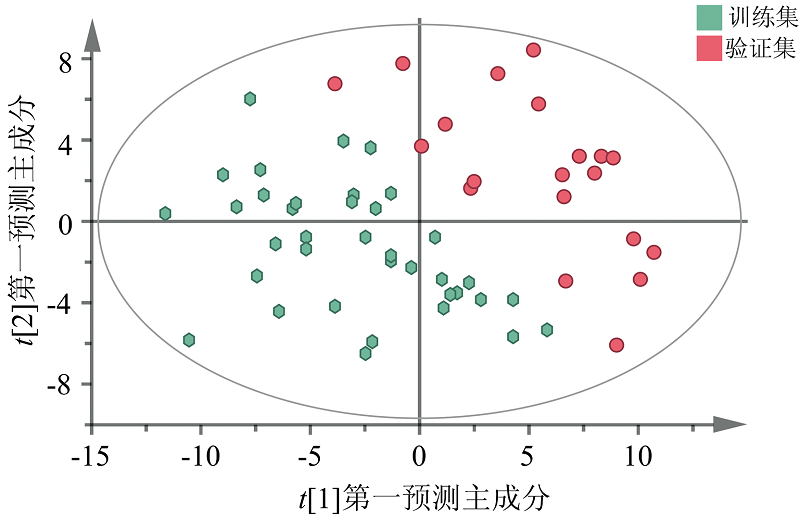 | 图5 PLS-DA模型二维得分图Fig.5 Two-dimensional score plot of PLS-DA model |
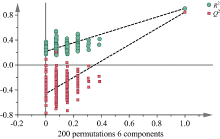
为了验证PLS-DA模型的可靠性, 对模型进行置换检验, X矩阵不变, 对Y矩阵变量随机排列200次得到置换检验结果(图6)。 可以看出, 置换检验中的Q2在纵坐标上的截距小于0, R2和Q2回归线的斜率均大于0, 说明该模型不存在过拟合, 此模型可靠。
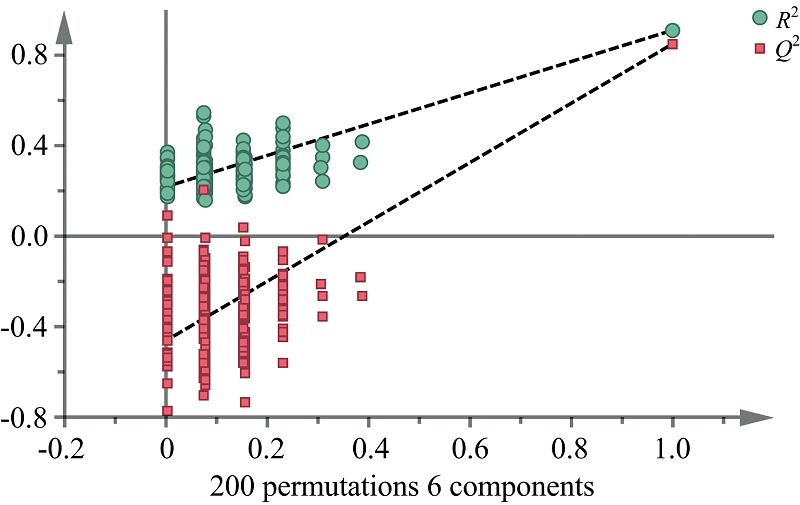 | 图6 置换检验验证的直观效果 横坐标表示与原模型的相似度, 纵坐标表示R2和Q2的值Fig.6 Intuitive effect of random permutation test (200 times) The abscissa represents the similarity to the original model, and the ordinate represents the values of R2 and Q2 |
2.2.4 正交偏最小二乘判别分析
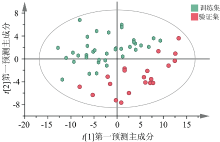
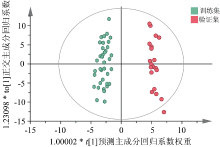
本部分构建OPLS-DA判别模型, 也是一种有监督模式的数据降维建模方法[18], 可以去除自变量X中与分类变量Y无关的数据变异, 分类信息集中于一个主成分中。 同样, 根据累计预测能力最强进行主成分数的选择, 选择9个主成分进行建模分析, 成分选择如图7所示。 从图7可知, 本研究中的OPLS-DA模型的累计自变量解释能力(R2X)为96.7%, 累计预测能力(Q2)为83.6%, 表明OPLS-DA分析模型可实现理想的区分效果。 OPLS-DA模型的二维得分图如图8所示, 可以看出, 训练集和验证集区分效果显著。
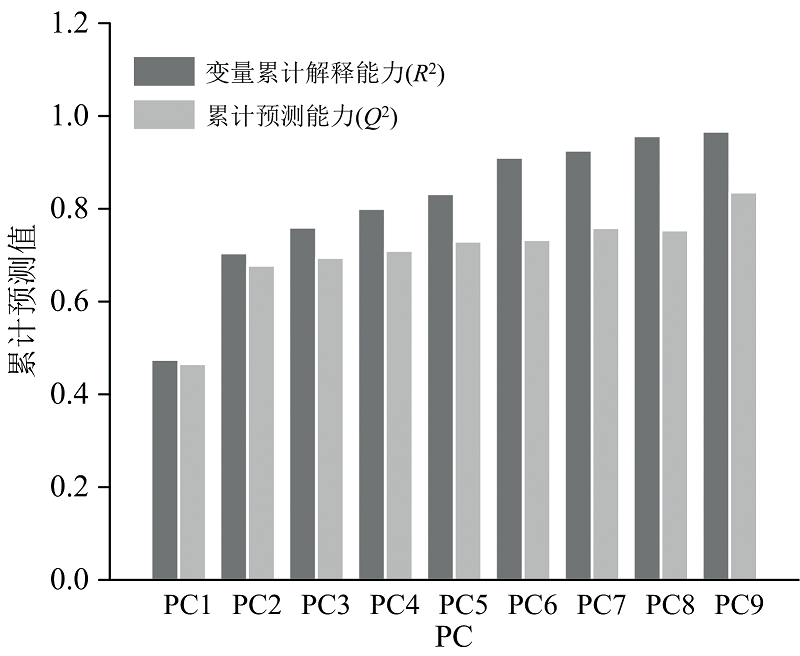 | 图7 OPLS-DA模型主成分选择柱状图Fig.7 Principal component selection histogram of OPLS-DA model |
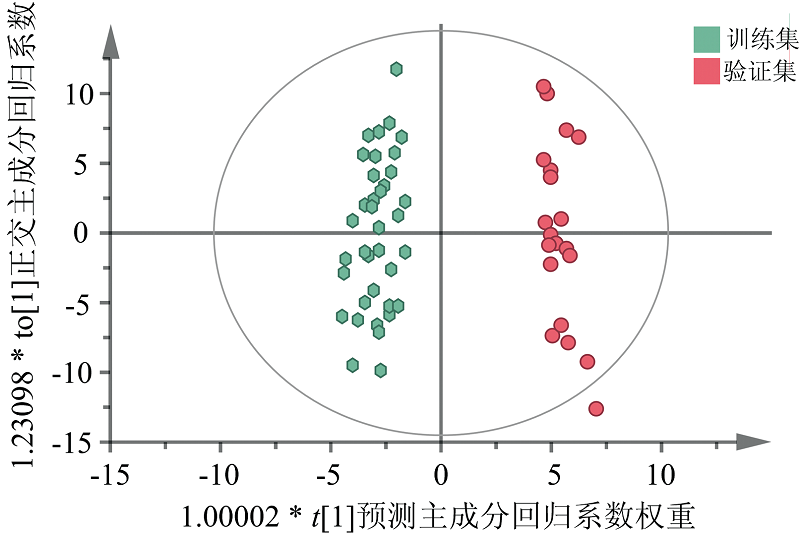 | 图8 OPLS-DA模型二维得分图Fig.8 Two-dimensional score plot of OPLS-DA model |
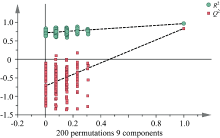
为了验证OPLS-DA模型的可靠性, 对模型进行置换检验, X矩阵不变, 对Y矩阵变量随机排列200次得到置换检验验证图(图9)。 可以看出, 置换检验中的Q2在纵坐标上的截距小于0, R2和Q2回归线的斜率均大于0, 说明该模型不存在过拟合, 此模型可靠。
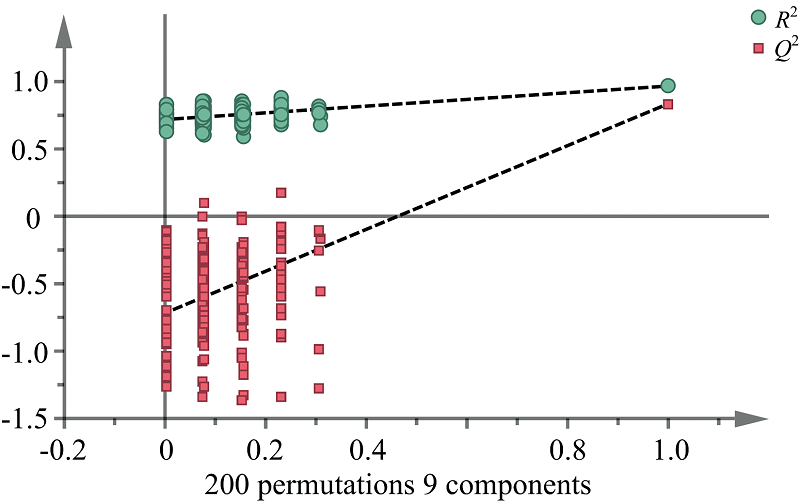 | 图9 置换检验验证的直观效果Fig.9 Intuitive effect of random permutation test (200 times) |
为了筛选产地鉴别模型中的关键波段, 在PLS-DA以及OPLS-DA模型中根据变量重要性投影值法(variable importance in projection, VIP), 选取VIP值大于1的波段[25]。 发现在PLS-DA模型中, VIP值大于1的波段集中分布在7 200~4 000 cm-1范围内。 4 440~4 200 cm-1位置处的吸收峰表示C— H(CH3, — CH2)伸缩振动和弯曲振动; 4 600 cm-1处的吸收峰为蛋白质中C=O伸缩振动和酰胺Ⅱ 谱带的合频吸收区, 4 700 cm-1附近含有蛋白质中N— H伸缩振动和酰胺Ⅰ 区的谱带吸收; 5 210~5 050 cm-1为游离O— H伸缩振动和弯曲振动, 5 200 cm-1附近为蛋白质伯酰胺CO— NH中C=O伸缩振动的二级倍频吸收区, 5 180 cm-1是淀粉与纤维素中O— H伸缩振动和H— OH变形振动的组合频吸收区; 6 020~5 550 cm-1为CH3和CH2伸缩振动的一级倍频, 6 620~6 250 cm-1为氢键键合NH伸缩振动的一级倍频, 6 710~6 500 cm-1为游离N— H基团伸缩振动的一级倍频, 6 800 cm-1附近吸收峰是— CH2为二级振动引起的, 与样品中氨基酸的种类和含量有关, 7 140~7 040 cm-1为游离OH的伸缩振动的一级倍频[26, 27]。 同样的, 在OPLS-DA模型中VIP值大于1的波段主要集中于4 710~4 000, 5 320~5 200, 6 620~6 250, 6 710~6 500以及7 140~7 040 cm-1。 综合上述两种模型所获结果可以看出, 鉴别模型的关键波段集中在4 710~4 000, 5 320~5 200以及7 200~6 220 cm-1。
基于近红外光谱技术结合化学计量学分析, 确定了最佳的光谱预处理方法, 建立的判别分析模型判别率可达92.4%。 依照南阳豌豆指纹图谱的光谱特征差异, 选择4个主成分数通过PCA-X算法对南阳豌豆建立产地识别模型, 剔除异常样本后模型预测能力为96.7%; PLS-DA以及OPLS-DA模型对南阳豌豆的预测能力分别为85.1%和83.6%, 表明本研究所建立的南阳豌豆产地鉴别模型的拟合程度及预测能力可准确实现南阳豌豆产地的分类鉴别。 特征波段中的特征峰大都代表着水分、 蛋白质以及碳水化合物, 为豌豆中的主要营养成分, 也是实验结果产生的原因。 在今后的研究中, 可以结合化学计量学探究不同产地杂豆的淀粉、 蛋白质以及水分等营养成分之间的关系, 建立定量研究; 针对本研究所得的特征波长, 结合质谱分析技术, 进一步进行相关性分析, 以解析模型判别机制, 为今后开展豌豆或其他区域杂豆类产地鉴别提供依据。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|