{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外-可见光高光谱的堆叠泛化模型褐土有机质预测
[张秀全1  , 李志伟
, 李志伟1, * , 郑德聪1, * , 宋海燕1 , 王国梁2 ]
, 李志伟, 郑德聪, 宋海燕|
|


作者简介: 张秀全, 1980年生, 山西农业大学农业工程学院讲师 e-mail: zhangxiuq1980@126.com
准确预测农田土壤有机质含量有助于评估农田肥力状况, 为精准农业提供数据依据。 为解决单模型实现快速估测农田土壤表层有机质含量精度较低和泛化能力较弱的问题, 以山西省典型褐土农田表层土壤为研究对象, 基于近红外-可见光高光谱数据, 提出了一种堆叠泛化模型(SGM)用于预测有机质含量。 首先对原高光谱数据采用小波平滑, 对平滑数据进行倒数一阶微分、 对数倒数一阶微分变换, 采用相关系数与递归特征消除法进行特征波段提取。 同时, 引入机器学习中的集成学习随机森林Random Forest(RF)、 梯度提升决策树Gradient Boosting Decision Tree (GBDT)、 极限梯度提升eXtreme Gradient Boosting (XGBoost)、 AdaBoost 4个初级机器学习器模型通过5折交叉验证对有机质含量进行预测, 在初级学习器预测结果基础上, 采用随机梯度下降SGD (stochastic gradient descent)作为元学习器建立SGM堆叠泛化模型。 突破单模型精度较低和不稳定的制约, 实现有机质含量的快速稳定检测。 结果表明: 倒数一阶微分变换后的光谱信息与有机质含量具有较好的相关性, 相关性最大值达到了-0.611; 相比单模型, 堆叠泛化预测模型的决定系数(R2)和相对分析误差(RPD)分别为0. 819和2.256, 较其他算法平均决定系数(R2)和平均相对分析误差(RPD)分别提高了0.055和0.323; 平均绝对误差(MAE)、 均方根误差(RMSE)分别为1.742和2.308 g·kg-1, 较其他算法平均绝对误差(MAE)和平均均方根误差(RMSE)分别降低了0.406和0.389 g·kg-1, 优化效果明显, 可用于农田土壤表层有机质含量的有效估测。 研究成果可为农田土壤表层有机质含量的高光谱快速检测提供依据和参考。
Accurate prediction of soil organic matter content is helpful in evaluating farmland fertility and provide a data for precision agriculture. In order to solve the problems of low accuracy and weak Generalization ability of a single model for rapid estimation of organic matter content in farmland surface soil. The surface soil of typical cinnamon farmland in Shanxi Province was studied,a Stacked Generalization Model (SGM) was proposed based on VIS-NIR hyperspectral data for predicting organic matter content. Firstly, the original hyperspectral data are smoothed by wavelet, and the reciprocal derivative and logarithmic reciprocal derivative transform are performed on the smoothed data. The feature bands are extracted by correlation coefficient and recursive feature elimination method. At the same time, Ensemble learning Random Forest (RF), Gradient Boosting Decision Tree (GBDT) and eXtreme Gradient Boosting are introduced in machine learning (XGBoost), and Adaboost are used to predict organic matter content through 5-fold cross-validation. Based on the prediction results of the primary learner, Stochastic gradient Descent (SGD) is used as a meta-learner to establish the SGM stack generalization model. The limitation of low accuracy and instability of a single model is broken through to realize the rapid and stable detection of organic matter content. The results show a good correlation between the spectral information and organic matter content after the penultimate differential transformation, and the maximum correlation is -0.611. Compared with the single model, the decision coefficient ( R2) and relative analysis error (RPD) of the stacked generalization prediction model are 0.819 and 2.256, respectively, which are 0.055 and 0.323 higher than the average decision coefficient ( R2) and relative analysis error (RPD) of other algorithms, respectively. The mean absolute error (MAE) and root mean square error (RMSE) are 1.742 and 2.308 g·kg-1, respectively, which are 0.406 and 0.389 g·kg-1lower than those of other algorithms. The optimization effect is obvious. It can be used to estimate organic matter content in farmland soil surfaces effectively. The results can provide a basis and reference for the rapid detection of organic matter content in farmland soil surface by hyperspectral method.
快速、 高效、 规模化、 智能化获取土壤参数特征是实现精准农业最重要的基础工作之一, 如何利用高光谱进行土壤养分参数识别, 如何定量描述和预测土壤养分特征与高光谱数据之间的关系, 是精准获取土壤参数的关键[1]。 土壤有机质是评估土壤肥力的重要指标之一; 探究和揭示土壤有机质的高光谱响应规律, 定量估算土壤有机质含量可为检测评估土壤肥力提供有效的途径[2]。
土壤有机质高光谱预测模型主要有线性和非线性模型, 线性模型因其处理变量间存在共线性和非线性问题具有局限性[3, 4, 5, 6, 7, 8]。 因此目前, 机器学习已成为土壤有机质预测的主要方法, 其中, 随机森林(RandomForest, RF)、 支持向量机(support vector machine, SVM)、 极限学习机(extreme learning machine, ELM)、 BP神经网络(back propagation neural networks, BPNN)、 集成学习[9, 10, 11]模型都得到了广泛的应用。 SVM处理小样本效果较好, 在处理大规模样本数据训练效率较差; 神经网络需要大量参数, 不能观察其学习过程, 结果的解释力较差; 集成学习(Bagging, Boosting算法)通过构建多个弱学习器, 采用某种策略将多个学习器进行结合, 可获得比单一学习器更好的泛化性能, 降低误差率而被广泛应用; 单模型在模型结构和预测偏差上会存在不同程度的差异, 模型精度也会存在不稳定的问题, 堆叠泛化模型(Stacking)充分利用了组件学习器在模型结构和预测偏差上的差异程度, 弥补了已有的集成算法Bagging、 Boosting方法中基学习器受样本扰动的不足, 保证了集成学习的效果[12]。
对于有机质估测模型泛化能力的评估已有报道多采用留出法[13, 14], 该方法可能会因训练/测试集的划分数据分布不均导致的偏差对结果产生影响, 或因训练/测试集根据给定的比例进行分割导致的单次使用留出法使得估测结果不稳定, 或因训练集/测试集比例不合理导致估测结果不准确, 从而降低了评估结果的保真性[15]。
因此, 以山西省典型褐土农田表层土壤为研究对象, 获取土壤的可见光-近红外高光谱数据, 基于k折交叉验证进行初级学习器的训练采用堆叠泛化模型构建有机质高光谱估测模型, 并比较各初级学习器模型和堆叠泛化模型的估测精度, 以期为农田土壤表层有机质含量的高光谱快速定量估算提供科学依据和技术参考。
土壤样品采自山西省内农田表层土壤(0~0.2 m), 土壤类型均为褐土。 采样时间为2019年4月初, 农田作物种植之前。 按照等量、 随机5点混合的原则在每个采样单元相对中心的位置采集土壤样本, 共采集66个土壤样本。 所有样品手动清除杂物并自然风干, 将每份土样分为两份, 一份研磨过筛, 用于土壤有机质含量测定, 另一份直接用于高光谱图像采集。
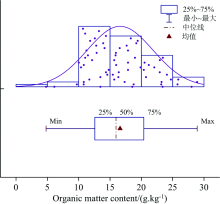
土壤有机质含量测定采用重铬酸钾-外加热法。 其土壤有机质含量统计结果如图1所示, 66个样品的有机质含量最小值为4.790 g· kg-1, 最大值为28.917 g· kg-1, 平均值为16.611 g· kg-1, 标准差为5.210 g· kg-1, 变异系数为31.61%, 有机质含量数据服从正态分布。
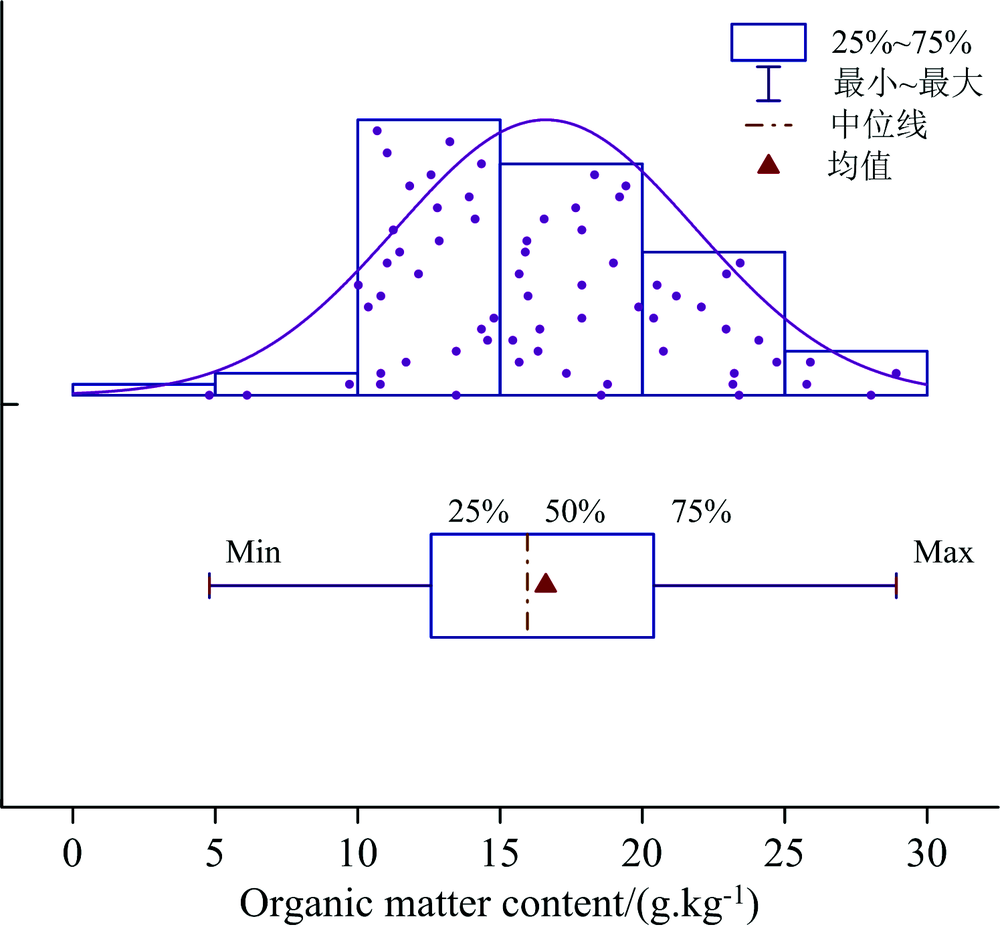 | 图1 土壤有机质含量统计Fig.1 Statistics of organic matter content in soil samples |
土壤近红外-可见光高光谱图像采集使用美国 Headwall Photonices公司的Starter Kit扫描平台, 光谱范围379~1 700 nm; 可见光和近红外光谱分辨率分别为0.727和4.715 nm。 土壤样本装入直径约3 cm, 深约1 cm的容器中, 抹平并压实, 放到移动扫描平台上扫描一次得到一幅高光谱图像。 平台参数设置: 平台物距20 nm, 移动速度15.55 mm· s-1, 曝光时间0.9 ms。
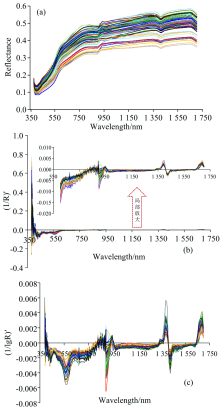
基于ENVI5.3软件, 获取每个土壤样本区像素点的光谱平均曲线, 作为该土壤样本的光谱曲线。 为了减少光谱测定过程中产生的误差, 进一步提高反射率数据与土壤指标之间的相关性, 基于Matlab2016b软件采取小波变换对光谱进行去噪平滑、 对去噪光谱数据(R)[图2(a)]分别进行倒数的一阶微分[(1/R)'][图2(b)]、 对数倒数的一阶微分[(1/lgR)']光谱变换[图2(c)]。
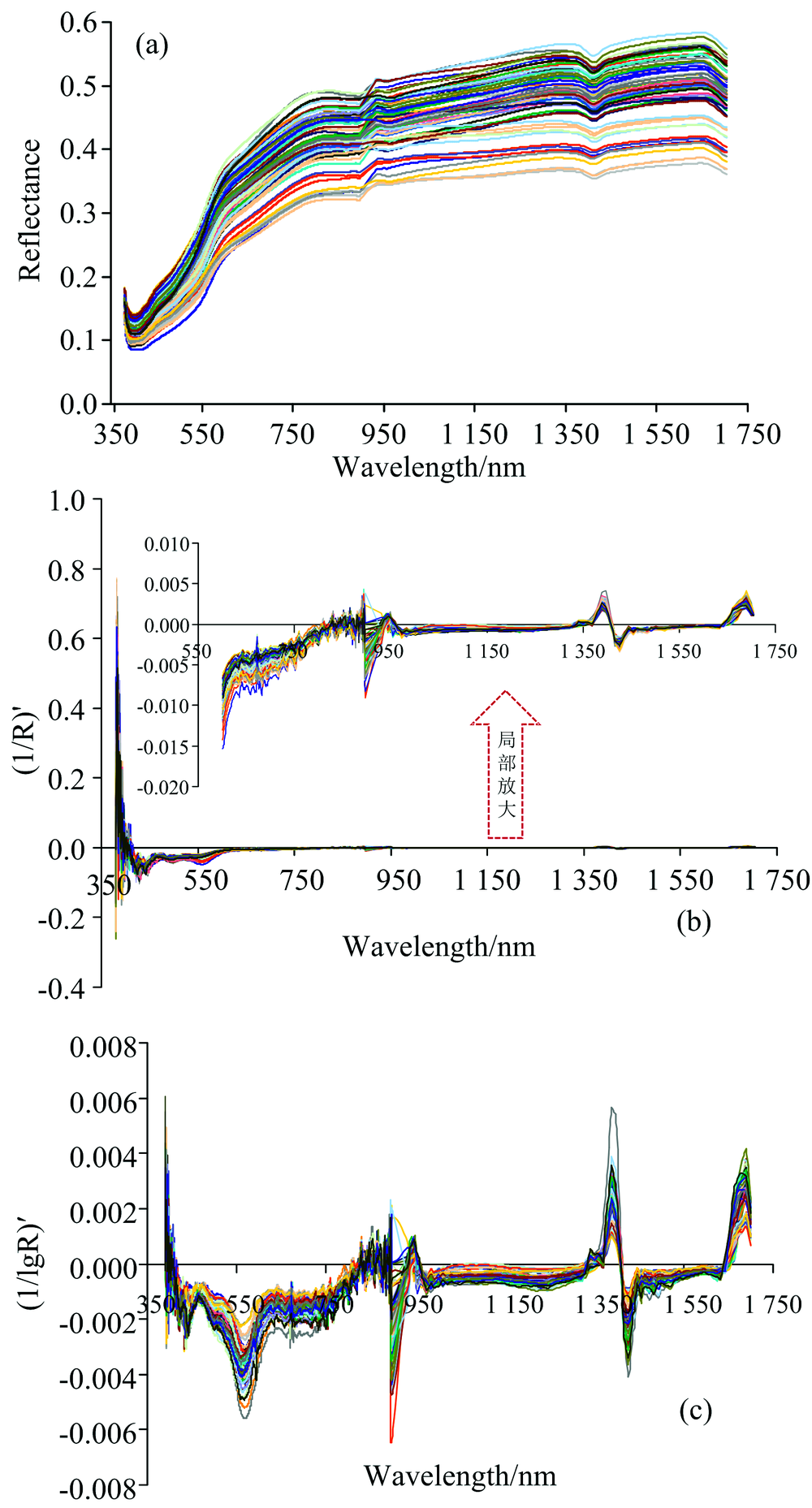 | 图2 反射率及其变换的土壤光谱曲线Fig.2 Soil spectral reflectance curves and its transformations |
由图2可知, 不同土壤有机质含量光谱反射率均随波长的增加而增加, 且随着波长的增加光谱反射率增长速度减慢; 在1 657 nm附近, 土壤反射率值达到极大值; 在379~425 nm之间、 1 393~1 426 nm之间、 1 657~1 700 nm 波段之间, 土壤光谱反射率随波长增加而下降, 在405和1 411 nm附近处存在明显的水分吸收峰。 经过倒数一阶微分和对数倒数一阶微分变换之后的光谱曲线的差异特征更加突出, 两种变换光谱曲线趋势基本一致。
1.3.1 SGD模型
随机梯度下降(stochastic gradient descent, SGD)[15]是一种无约束迭代优化算法, 其目标是一个线性评价函数
式(1)中, L为损失函数, 采用普通最小二乘法, R为正则化项, α > 0是一个非负超平面。
1.3.2 RF模型
随机森林(RandomForest, RF)[15]是一种元估计器, 采用Bootstraping随机有放回采样方法生成n个决策树模型, 对于单个决策树模型根据最小均方差进行分裂, 最终使用多棵树预测值的均值来提高预测精度和控制过拟合。 其核心目标函数为: Cα (Tt)=C(Tt)+α |Tt|, 其中, α 为正则化参数, |Tt|是子树T的叶子节点数量, C(Tt)为预测误差, 采用最小均方差度量, 即
1.3.3 AdaBoost模型
AdaBoost算法[15]是一种可以将弱学习器提升为强学习器的Boosting集成算法, 其算法使用加法模型[式(2)], 损失函数为指数函数[式(3)]其核心目标是每次迭代将当前基函数在训练集上的损失函数最小化, 据此得到每个样本的更新权重。
式中, x为输入样本, α m为权重系数, h为回归树。
1.3.4 GBDT模型
梯度提升决策树(gradient boosting decision tree, GBDT)[16]是一种迭代决策树算法。 模型定义为[式(4)]
式(4)中, x为输入样本; w为模型参数; h为回归树; α 为每棵树的权重。
GBDT每轮的训练是在上一轮的训练的残差[式(5)]基础之上进行训练的, 其核心目标是利用损耗函数的负梯度作为当前模型值。 GBDT模型损失函数为平方差[式(6)], 且平方损失函数是一个凸函数, 直接求导后得到训练样本均值
1.3.5 XGBoost模型
极限梯度提升算法(eXtreme gradient boosting, XGBoost)[17]是一种Tree Boosting的可扩展可并行可高效率运算的机器学习系统。 其核心目标是添加新树并拟合伪残差以减少损失函数。 XGBoost的目标函数由梯度提升算法中的损失函数[式(7)]和正则化项[式(8)]组成。 其定义为
式中, n为训练函数的样本个数, l为单个样本的损失, Ω 为正则化项, γ 和λ 为设置参数, ω 为决策树中所有叶节点值构成的向量, T为叶节点个数。
1.3.6 SGM模型
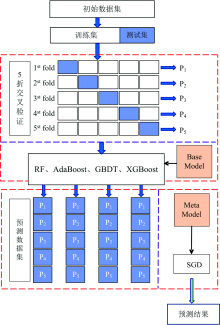
Stacking是一种分层模型集成框架[15], 其基本原理是由初始数据集训练出初级学习器, “ 生成” 一个由各初级学习器的输出构成的新数据集用于训练次级学习器, 产生一个比初级学习器具有同等或更好的预测性能的元模型。
本研究堆叠泛化框架(stacked generalization model, SGM)采用4个初级学习器GBDT、 RF、 Adaboost和XGBoost和一个元模型SGD。 为避免过拟合, 采用k折交叉验证方式(k取5), 用训练初级学习器未使用的样本来产生次级学习器的训练样本。 初始训练集D被随机划分为k个大小相似的结合D1, D2, …, Dk。 令Dj和
 | 图3 堆叠泛化模型Fig.3 Stacked generalization model |
各模型的实现均基于PyCharm平台, 各模型涉及的参数均采用默认参数。
模型预测能力及稳定性的评价通过决定系数(R2), 其值越接近于1, 模型精度越高; 绝对误差(AE)、 平均绝对误差(MAE)和均方根误差(RMSE), 其值越小模型准确性越高; 通过相对分析误差(RPD)进一步对模型的好坏进行评价, 当RPD> 2时, 说明模型可较好预测, 当 1.4< RPD< 2时, 说明模型可粗略预测, 当RPD< 1.4时, 说明模型无法预测[3]。
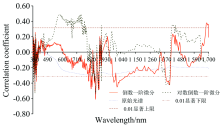
对原始光谱、 倒数一阶微分和对数倒数一阶微分与土壤有机质含量之间的相关性进行分析(图4)。 由图4可知, 有机质含量与原始光谱呈负相关, 相关系数曲线均比较平滑, 最大相关系数为0.297, 且各相关系数均未达到0.01显著性水平; 有机质含量与倒数一阶微分、 对数倒数一阶微分的相关系数变化起伏较大, 在正负值之间波动, 绝对最大相关系数分别为0.611和0.548, 说明倒数一阶微分和对数倒数一阶微分变换处理都可以将波段范围内一些隐藏有机质光谱吸收特征表现出来, 与对数倒数一阶微分相关系数相比倒数一阶微分与有机质含量的相关性更强, 且在0.01显著性水平下表现更为突出。 为此, 选取倒数一阶微分光谱数据作为有机质含量预测光谱数据, 并采用递归特征消除法进行敏感波段选取, 最终选取394.925、 849.175、 849.901、 850.628、 851.355、 852.082、 853.535、 1 020.65、 1 034.800、 1 378.970、 1 383.680、 1 388.400和1 393.110 nm 13个波段的光谱值作为预测有机质含量的特征波段。
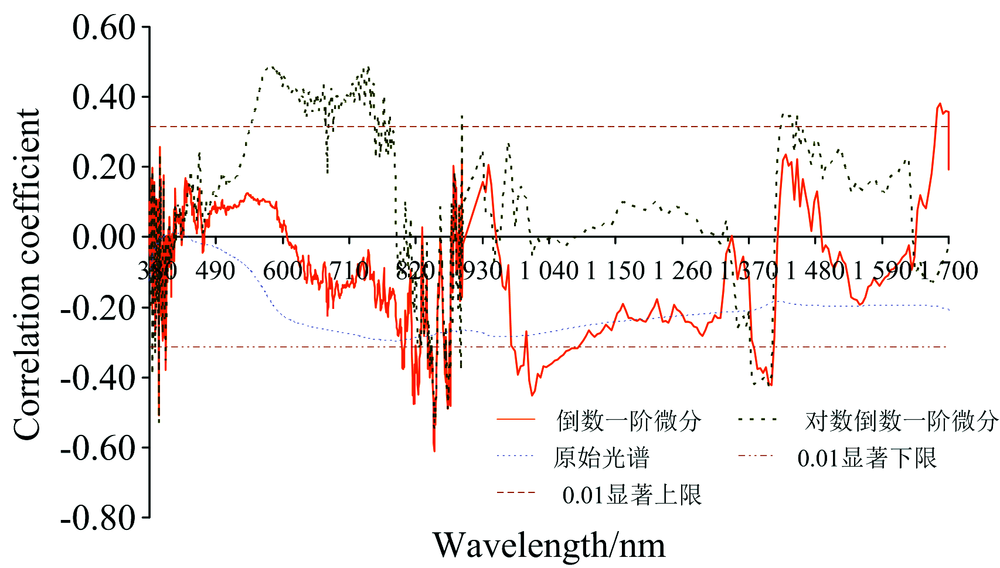 | 图4 有机质含量与光谱相关系数Fig.4 Correlation coefficients of organic matter content and spectral reflectance |
将通过相关性与递归特征消除法筛选出的敏感波段作为RF, GBDT, XGBoost和AdaBoost回归模型的输入值, 以土壤有机质的含量作为目标值, 将RF, GBDT, XGBoost和AdaBoost回归模型的预测值作为SGM模型的输入值, 以土壤有机质含量作为目标值, 预测精度结果如表1所示。
| 表1 模型预测精度对比分析 Table 1 Comparison of estimation accuracies |
通过预测结果可以看出, 4个初级学习器模型的决定系数R2由大到小依次为: GBDT(0.776), RF(0.774), AdaBoost(0.773), XGBoost(0.733)与4个初级学习器模型相比, 基于SGM构建模型的拟合优度R2最高达到了0.819, 均优于其他4个模型。
4个初级学习器模型的平均绝对误差(MAE)和均方根误差(RMSE)由小到大依次为: GBDT(2.067), RF(2.165), AdaBoost(2.171)和XGBoost(2.187); 与4个初级学习器模型相比, 基于SGM构建模型的平均绝对误差MAE和均方根误差RMSE值最低分别为1.724和2.308, 均低于其他4个模型; SGM模型的决定系数R2和相对分析误差RPD较其他算法平均R2和平均RPD分别提高了0.055和0.323, 平均绝对误差MAE、 均方根误差RMSE分别为1.742和2.308 g· kg-1, 较其他算法平均MAE和平均RMSE分别降低了0.406和0.389 g· kg-1, 优化效果明显, 表明SGM模型的有机质预测具有较好的精度与准确性。
进一步从相对分析误差RPD分析可知, SGM模型和GBDT模型的RPD分别为2.256和2.023, 表明SGM模型和GBDT模型均可以较好的对有机质含量进行预测, 且SGM模型预测要优于GBDT; RF, XGBoost, AdaBoost模型的RPD小于2, 表明其可以进行粗略的预测。
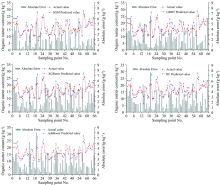
分析5种模型各个样本的预测值与实际值的绝对偏差, 并确定预测值与测试集真实值之间的绝对值误差。 结果如图5所示。
 | 图5 各模型样本预测值、 实际值及绝对偏差Fig.5 The predicted value, actual value and absolute deviation of different models |
从图5中可以看到, 各模型绝对误差最大值由大到小依次为AdaBoot模型为8.012 g· kg-1、 RF模型为7.583 g· kg-1、 XGBoost模型为6.718 g· kg-1、 GBDT模型为6.472 g· kg-1、 SGM模型为5.199 g· kg-1; 各模型绝对误差最小值由大到小依次为GBDT模型为0.062 g· kg-1、 RF模型为0.055 g· kg-1、 AdaBoot模型为0.049 g· kg-1、 XGBoost模型为0.048 g· kg-1、 SGM模型为0.028 g· kg-1; 各模型绝对误差标准差由大到小依次为XGBoost模型为1.700 g· kg-1、 RF模型为1.635 g· kg-1、 AdaBoot模型为1.621 g· kg-1、 GBDT模型为1.534 g· kg-1、 SGM模型为1.514 g· kg-1; 表明SGM模型对于有机质含量的预测较稳定。
进一步将绝对误差分为5个等级, 分别为≤ 1.00, (1.00, 2.00), (2.00, 3.00), (3.00, 4.00), > 4.00进行频率分布统计, 其结果如表2所示。
| 表2 各模型不同绝对误差频率分布统计 Table 2 Statistics of frequency distribution of different absolute errors |
由表2可知, SGM模型对于有机质含量预测的绝对误差小于1.00 g· kg-1占到41.18%, 小于2.00 g· kg-1占到60.29%, 均高于其他4个模型; 绝对值误差超过4.00 g· kg-1占的比例最大的为XGBoost模型(19.7%), 比例最小的为SGM(10.29%); 表明SGM模型对于有机质含量的预测精度较高。
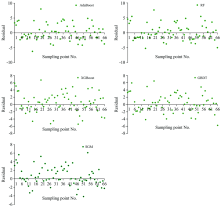
随机性和不可预测性是任何回归模型的关键组成部分, 通过残差图对模型的合理性及数据的可靠性进行检验(图6), 由图6可知, 5个模型的残差均为随机分布, 不存在异方差特征, 残差不包含可预测的信息, 表明5个模型均为合理预测模型。
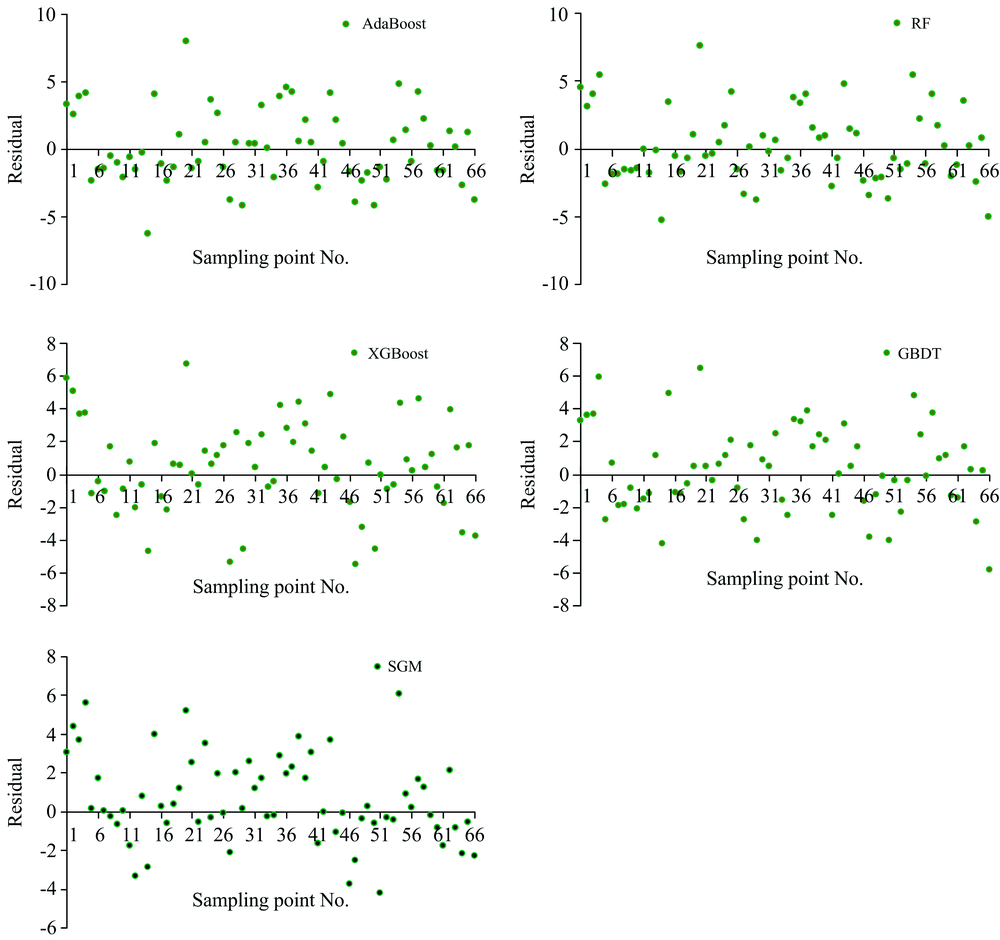 | 图6 各模型残差分布图Fig.6 The residual distribution of each model |
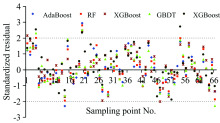
通过标准化残差图对预测数据残差序列正态性进行检验(图7)。
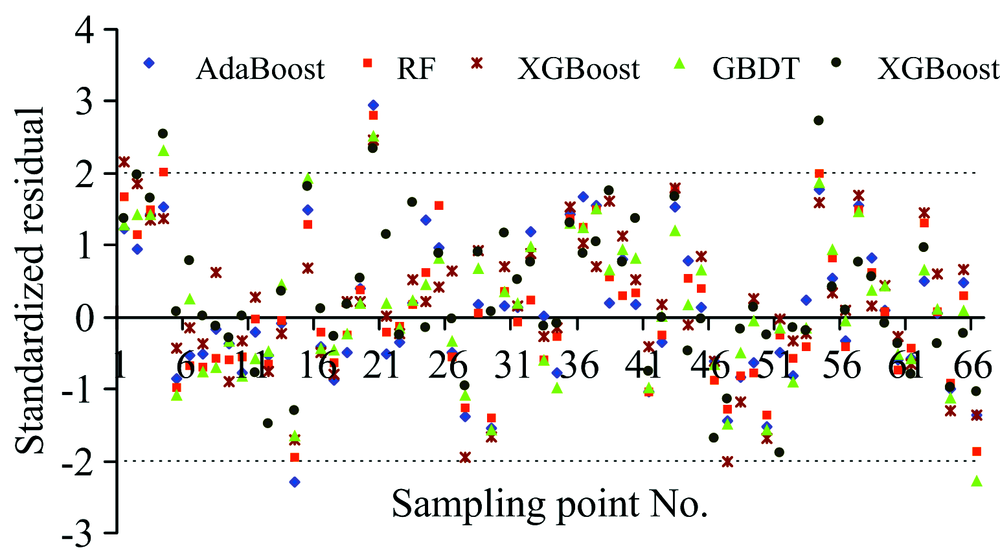 | 图7 各模型标准化残差分布图Fig.7 Standardized residual distribution of each model |
由图7可知, 5个模型均达到了95%的标准化残差在-2~2之间, 表明其残差服从正态分布。
以山西省典型农田褐土土壤样品为研究对象, 对表层有机质的可见光-近红外高光谱光谱特征进行分析, 构建了SGM模型对有机质含量进行估测, 主要结论如下:
(1)通过倒数一阶微分和对数倒数的一阶微分变换增强了光谱特征, 提高了光谱反射率与土壤有机质间的相关性, 分别由原最大相关性的-0.297, 增加到-0.611和 0.548。
(2)堆叠泛化模型(SGM)对有机质的预测精度和预测准确性均优于单模型(GBDT、 RF、 AdaBoost、 XGBoost); SGM模型RPD高于2, 且明显高于4个单模型, 可以显著提高预测精度。 结果表明, SGM模型优于目前在相同数据集上的Boosting集成方法, SGM模型对于土壤有机质含量高光谱预测具有明显优势, 扩展了机器学习模型在土壤养分预测中的应用。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|