{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于ML-PCA-BP模型的多环芳烃拉曼光谱定量分析
[尹雄翼1  , 石元博
, 石元博1, * , 王胜君2 , 焦仙鹤2 , 孔宪明2 ]
, 石元博, 王胜君|
|


作者简介: 尹雄翼, 1996年生, 辽宁石油化工大学人工智能与软件学院硕士研究生 e-mail: 1399910036@qq.com
芘作为多环芳烃(PAHs)类物质广泛存在于自然环境中, 亲脂性强, 对人体有致癌影响。 因此, 食用油中芘的含量的判定对品质的把控具有深远的意义。 采用拉曼光谱与人工智能算法相结合进行多环芳烃的定量分析是当前的一个研究热点。 将一毫升食用油与不同固定浓度的芘液体混合制作样本, 然后制作薄层色谱板与金粒子, 采用薄层色谱和表面增强拉曼散射(SERS)光谱相结合的方法进行实验获得光谱数据, 选取自适应迭代加权惩罚最小二乘算法进行预处理, 再采用Multi parameter-Principal Component Analysis-Back Propagation Neural Network模型方法进行定量分析。 该模型首先在预处理后的光谱中选取两个特征峰进行分峰拟合获取特征峰的高度、 半高宽、 面积等参数。 将两个特征峰的拉曼数据与通过拟合获取的参数进行归一化再采用主成分分析获取关键参数, 将获取的关键参数作为输入层输入基于L2正则化的BP神经网络中, 输出预测浓度。 实验分别采用不同的算法进行浓度预测, 实验结果表明, 通过偏最小二乘算法预测的芘浓度, 其测试集决定系数 R2为0.58, 均方根误差(RMSEC)为1.85; 采用线性回归拟合特征峰面积与浓度的规律最终预测的芘浓度, 其测试集决定系数 R2为0.26, 均方根误差(RMSEC)为2.28; 采用Multi parameter-Principal Component Analysis-Back Propagation Neural Network模型预测芘浓度, 其测试集决定系数 R2为0.99, 均方根误差(RMSEC)为0.31, Multi parameter-Principal Component Analysis-Back Propagation Neural Network模型预测精准度更高, 误差更小。 模型是针对光谱数据信息与样本浓度之间非线性、 高维度的关系, 而建立的预测精度及建模效率均高于同类对比的算法模型。 模型拟合特征峰获取关键变量, 将关键变量与特征峰的拉曼位移都作为特征向量, 因此特征向量较为充分, 模型利用PCA提取拉曼光谱非线性特征并且采用基于L2正则化BP神经网络泛化力强的优点, 防止过拟合, 因此可以更加精准快捷地预测出芘的浓度。
Pyrene, a kind of polycyclic aromatic hydrocarbons (PAHs), widely exists in the natural environment. It has strong lipophilicity and carcinogenic effect on the human body. Therefore, the rapid analysis of pyrene content in edible oil has far-reaching significance for quality control. The quantitative analysis of polycyclic aromatic hydrocarbons using Raman spectroscopy and artificial intelligence algorithm is a current research hotspot. One milliliter of edible oil is mixed with pyrene liquid with different fixed concentrations to make samples, and then a thin-layer chromatography plate and gold particles are made. The experiment is carried out by combining thin-layer chromatography, and surface-enhanced Raman scattering (SERS) spectrum to obtain the spectral data. The adaptive iterative weighted penalty least square algorithm is selected for preprocessing, Then the Multi parameter-Principal Component Analysis- Back Propagation Neural Network model was used for quantitative analysis. Firstly, two characteristic peaks are selected in the preprocessed spectrum for peak fitting, and the parameters such as height, half-width, height and area of characteristic peaks are obtained. Normalized the Raman data of the two characteristic peaks and the parameters obtained by fitting, and then use the principal component analysis to obtain the key parameters. The obtained key parameters are input into the BP neural network based on L2 regularization as the input layer to output the predicted concentration. The experimental results show that the R2 determination coefficient of the test set is 0.58 and the root mean square error (RMSEC) is 1.85; The linear regression is used to fit the law between the characteristic peak area and pyrene concentration. The final predicted pyrene concentration has an R2 determination coefficient of 0.26, and a root mean square error (RMSEC) of 2.28; For the pyrene concentration predicted by the Multi parameter-Principal Component Analysis-Back Propagation Neural Network model, the R2 determination coefficient of the test set is 0.99, and the root mean square error (RMSEC) is 0.31. The multi-parameter principal component analysis-back propagation neural network model has higher measurement accuracy and less error. The model is aimed at the nonlinear and high-dimensional relationship between spectral data information and sample concentration. The prediction accuracy and modeling efficiency are higher than similar comparison algorithms. The model fits the characteristic peak to obtain the key variables and takes the Raman displacement of the variable and the characteristic peak as the characteristic vector, so the characteristic vector is sufficient. The model uses PCA to extract the nonlinear characteristics of the Raman spectrum and adopts the advantages of strong generalization based on L2 regularization BP neural network to prevent overfitting, so that it can predict the concentration of naphthalene more accurately and quickly.
多环芳烃(PAHs)广泛存在于自然环境中, 是由煤、 石油等有机物不完全燃烧产生的。 多环芳烃水溶性极低, 亲脂性强, 容易在生物体内富集, 作为一种持久性有机污染物, 具有很强的致癌性和突变反应[1]。 现阶段使用最多的PAHs定量方法主要是气相色谱-质谱法与高效液相色谱法, 这两种方法虽然敏锐度较强, 但分析仪器价格高昂、 操作复杂, 对使用环境的要求极高[2]。 然而在实际应用中, 具有即时、 方便、 廉价特征的检测策略是多环芳烃检测的关键[3]。 SERS光谱已成为一种强有力的检测技术, SERS的一个独特优势是, 可在痕量水平甚至单分子水平上分析物体分子结构的固有信息[4, 5, 6, 7]。 这使得SERS成为一种功能强大的非破坏性传感技术, 广泛应用于化学分析等领域[8, 9, 10]。 因此SERS拉曼光谱再结合人工智能算法检测食用油中的多环芳烃是当前较为科学的一种方法, 该方法充分利用了人工智能算法较强的计算能力与学习能力去发现光谱数据中潜在的规律。
李爱民等[11]利用激光诱导荧光分光光度计采集了所有样品的三维荧光光谱, 同时建立多维偏最小二乘(N-PLS)模型定量分析土壤中菲和蒽浓度。 Shen等[12]采用表面增强拉曼光谱与薄层色谱相结合的方法进行多环芳烃检测, 再采用多项式模型进行多环芳烃化学物浓度的定量分析; 陈新岗等[13]通过高斯函数分峰拟合获取特征峰的高度、 面积、 半高宽等关键参数, 再采用偏最小二乘算法预测甲烷气体浓度。 王聪等[14]通过特征峰面积与浓度建立线性关系预测浓度值。 以上文献方法中, 采用的算法无法完善地拟合出浓度与拉曼数据的非线性关系。
为了满足芘含量检测的高精度、 高效率等要求, 本文提出应用拉曼光谱技术结合ML-PCA-BP回归算法检测芘的浓度。 ML-PCA-BP模型充分利用PCA提取拉曼光谱非线性特征和 L2正则化BP 神经网络预测能力强, 泛化性好的优点。
柠檬酸钠(C6H5Na3O7, 比利时ACROS公司), 氯金酸(HAuCl4· 4H2O, 阿达玛斯试剂公司), 和2-硝基苯甲酸(C7H5NO4, 北京伊诺凯科技有限公司), 芘(C16H10, 国药集团化学试剂公司)。 实验中所用的己烷、 氯仿和乙酸乙酯均为分析纯, 羧甲基纤维素(CMC, 上海梯希爱化工贸易有限公司)和硅藻土。 食用油是从当地超市购买的, 所有实验均使用超纯水。
用于制备金纳米颗粒(Au NPs)的玻璃器皿首先在王水(HNO3/HCl, 1∶ 3, V/V)中浸泡20 min, 然后用超纯水清洗。 Au NPs 通过柠檬酸钠还原法制备。 将100 mL HAuCl4 (0.583 2 mmol· L-1) 水溶液在搅拌条件下加热回流。 然后, 将4.0 mL柠檬酸钠(1%)快速加入回流的溶液中, 继续回流30 min, 冷却至室温。 制备完成的球形金纳米粒子, 直径范围为50至60 nm。
将一毫升食用油与固定浓度的芘溶液点在硅藻土板上, 距离薄层色谱板底部1.5 cm。 在室温条件下, 将其垂直放入流动相中进行样品分离, 然后使用紫外灯(254 nm)与碘色法追踪分析物的位置, 计算保留因子。 然后将3 μ L浓缩30倍金纳米粒子沉积在分析物斑点上。 利用Origin2017作图。 为了现场快速检测, 我们使用785 nm的激发激光的便携式拉曼光谱仪(BWS465-iRman; B& W-Tek, USA), 激光功率为30 mW, 积分时间2 s, 将拉曼光谱数据保存到csv文件中。
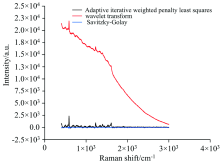
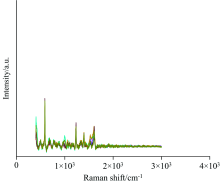
由于采集到的原始光谱图上存在很多噪声, 因此, 对光谱数据进行进一步的分析之前, 需要对光谱数据进行基线矫正和降噪等处理。 通过对比Savitzky-Golay平滑滤波、 小波变换和自适应迭代加权惩罚最小二乘等方法, 其实验结果为自适应迭代加权惩罚最小二乘预处理的方法结果最好, 如图1所示。 该方法是在惩罚最小二乘的基础上, 通过在迭代过程中自适应地调节拟合基线与原始信号之间残差平方和的权重, 快速灵活地找到不规则变化的基线并予以扣除。 随机选取9条原始数据使用自适应迭代加权惩罚最小二乘进行预处理, 结果如图2所示。
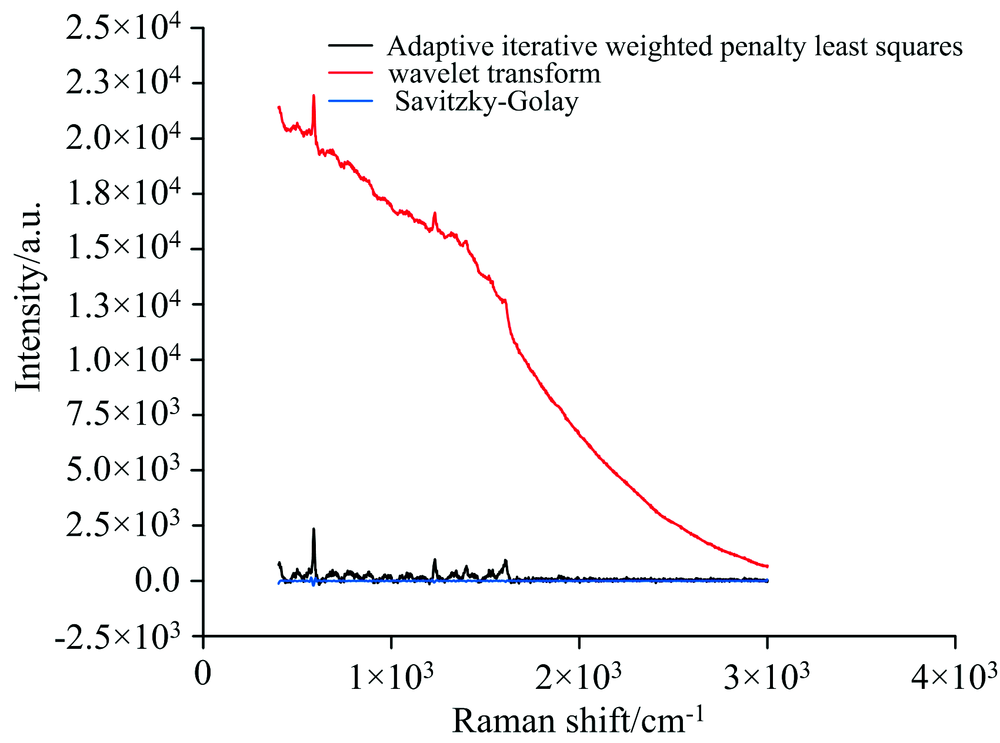 | 图1 预处理算法结果比较图Fig.1 Comparison chart of preprocessing algorithm results |
 | 图2 光谱预处理图Fig.2 Spectral preprocessing diagram |
拉曼光谱进行物质的定量分析是一个热门研究问题, 以往采用的方法无法完善地拟合化学物质之间的非线性关系。 为此本文方法充分利用PCA提取拉曼光谱非线性特征和BP神经网络预测能力强的优点, 提出一种ML-PCA-BP的拉曼光谱预测模型, 具体算法流程如下:
(1)对拉曼光谱的特征峰进行分峰拟合, 采用高斯函数作为基础算法, 拟合获取其峰的关键信息如高度、 半高宽、 面积, 根据拟合程度, 修改高斯拟合函数中参数初始值或者重新选择特征峰对应的起点与终点;
(2)对以拉曼位移作为特征变量的拉曼强度值与高斯拟合获得的参数组成的数据进行归一化处理;
(3)使用主成分分析的方法处理归一化后的数据, 进行降维提取关键参数;
(4)将训练样本的关键参数输入到BP神经网络进行训练, 采用梯度下降算法, 并初始化权重值与偏置值, 为了提高泛化能力采用L2正则化优化BP神经网络; 并且可以根据预测值的误差修改主成分个数、 网络中的参数, 获得最优网络结构, 最终进行浓度预测。
如图2显示了不同浓度的拉曼光谱, 从图中可以明显地看出拉曼位移范围[571.74~598.31]与[1 214.50~1 249.43]有明显的波形, 主要是由于芳环的伸缩模式和CH面内弯曲振动而造成的, 因此属于芘的特征峰。
为提高浓度的预测精度, 从图形中获取特征峰的一些关键参数。 光谱图中每个谱峰都具有明确的物理意义且携带不同的物理信息, 在[571.74~598.31]与[1 214.50~1 249.43]范围内是芘的特征峰。 在且考虑量子力学修正可知拉曼散射强度与样品单位体积内的散射分子数(样品浓度)成正比。 式(1)中采用高斯函数对定位的两个谱峰进行分峰拟合, 由式(1), 式(2)可获得各不同频移位置处谱峰的面积、 半高宽和峰高等参数, 得到特征量参数如表1。
| 表1 光谱图高斯分峰拟合特征参数 Table 1 Characteristic parameters of Gaussian peak division fitting of spectrogram |
其中, y为拉曼散射强度; z为拉曼频移; A为拉曼谱峰高度; xc为谱峰中心偏移量; FWHM为谱峰半高宽。 得到全部特征量参数如表1。
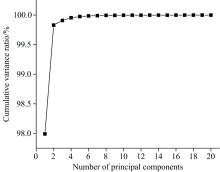
主成分分析(PCA)主要对数据的协方差矩阵进行特征分解, 从而得到相应的特征值与特征向量, 在实现数据维数缩减的同时保留数据的主体信息。 研究中, 由于特征向量较多, 为了加快运算速率, 所以利用PCA对SERS图范围为[571.74~598.31]与[1 214.50~1 249.43]的特征峰数据与拟合特征峰获得的高度、 半高宽、 面积等参数进行主成分分析。 提取出关键的特征信息, 降低维度, 从图3中可以发现, 即保留3个主成分以后其贡献率达到99.9%。 主成分选取的个数越多, 包含的信息越全面。
 | 图3 主成分方差分析图Fig.3 Principal component analysis of variance |
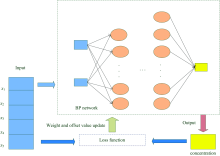
 | 图4 神经网络结构图Fig.4 Neural network structure diagram |
BP神经网络模型主要需要确定以下参数: 神经网络的层数, 输入层、 输出层、 隐藏层的节点个数, 各层神经元的激活函数, 训练方法。
(1)参数初始化: 权重值与偏置值使用正态分布生成初始值;
(2)输入层: 设置5个神经元, 为PCA算法获取的5个特征参数;
(3)隐藏层: 设置10层, 分别为300, 270, 240, 210, 180, 150, 120, 90, 60, 30;
(4)输出层: 一个神经元代表浓度;
(5)激活函数: 激活函数采用relu, 输入层到隐藏层与隐藏层内部均采用relu函数, 隐藏层到输出层采用全连接, 无激活函数;
(6)迭代优化器: adam函数, 动量项的梯度下降法;
(7)损失函数: 均方方差损失函数(MSE);
(8)正则化: L2正则化, 主要进行权重值的修改。
神经网络输入层表示为
式(3)中, i=1, 2, …, t, t为输入层神经元的个数, x为主成分分析获得的特征向量。
随之隐藏层第一层的的表达式为
设
以及输出层的公式为
式(6)中, k为输出层的层数,
m个训练样本的损失函数为
式(7)中, d为真实值, y为预测值, i=1, 2, …m样本个数。
紧接着进行L2正则化的损失函数
式(8)中, λ 是一个超参数, 范围[0, 1], w则是我们训练的深井网络中每一层的权重矩阵。
根据损失函数反向修改权重的表达式
进一步可以推导出
式(10)中, α 为学习率。
根据损失函数反向修改偏置量的表达式
(1)采用了薄层色谱和表面增强拉曼散射(SERS)光谱相结合的方法已成功地用于从食用油样品中识别多环芳烃, 拉曼光谱数据保存到csv文件中;
(2)使用自适应迭代加权惩罚最小二乘算法进行光谱预处理;
(3)将光谱数据进行分峰拟合获取高度、 面积、 半高宽等关键参数;
(4)数据集分成测试集与训练集, 数据集可以描述为一个X阶矩阵(n× d), 包含n个长度为d的光谱, 其中d是在[571.74~598.31]与[1 214.50~1 249.43]之间测量到的光谱点与两个峰对应的高度、 面积、 半高宽等参数, 选取10条数据作为测试集;
(5)将高斯拟合的参数与两个峰的特征变量进行归一化, 再进行主成分分析, 依据结果误差依次进行调整主成分个数;
(6)最后将主成分分析获得的特征参数输入基于L2正则化BP神经网络进行训练, 获得最终的预测浓度。
最终基于ML-PCA-BP模型预测出来的芘浓度的预测值与真实值的均方根误差为0.31, 说明真实值与预测值两者的数值十分接近, 预测的浓度相对精准。
为了评价模型的性能, 分别使用相对决定系数R2和均方根误差(RMSE)对模型的预测精度进行了分析。
式(13)中,
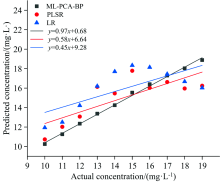
从图5可以看出, ML-PCA-BP模型预测值与真实值的函数表达式为y=0.97x+0.68; 偏最小二乘的表达式为y=0.58x+6.64; LR(linear regression)的函数表达式为y=0.45x+9.28。
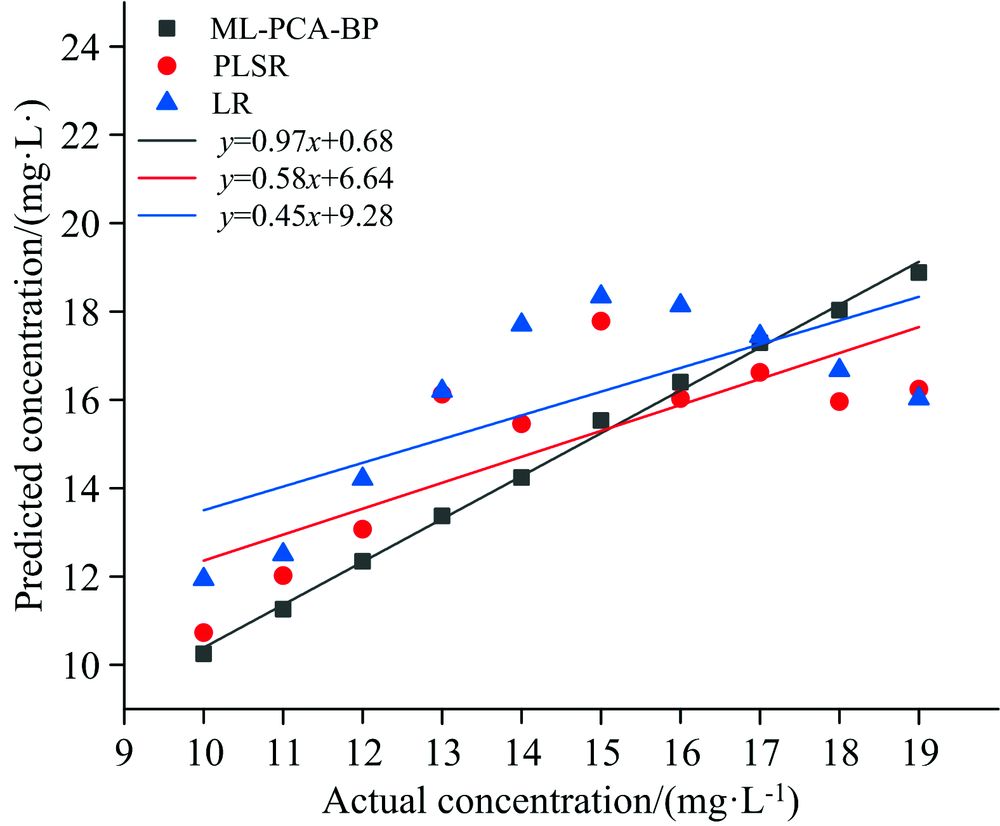 | 图5 测试集芘预测浓度与真实浓度之间的关系Fig.5 Relationship between predicted pyrene concentration and actual pyrene concentration in test set |
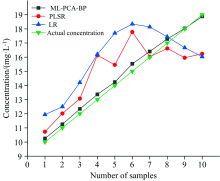
根据图5和表2中, ML-PCA-BP, PLSR, LR三种算法的对比, 其中ML-PCA-BP的决定系数R2最接近1, 拟合的线性回归方程最优, 预测值与真实值的斜率接近为1, 从图6中和表2中可以发现ML-PCA-BP的预测值与真实值距离最为相近, 其次是PLSR, LR的预测值与真实值相对较远, ML-PCA-BP均方根误差最小为0.31, PLSR算法的均方根误差为1.85, LR的均方根误差为2.28。 从以上的图表中则可以看出ML-PCA-BP算法的预测最为精准。
| 表2 模型对比表 Table 2 Model comparison |
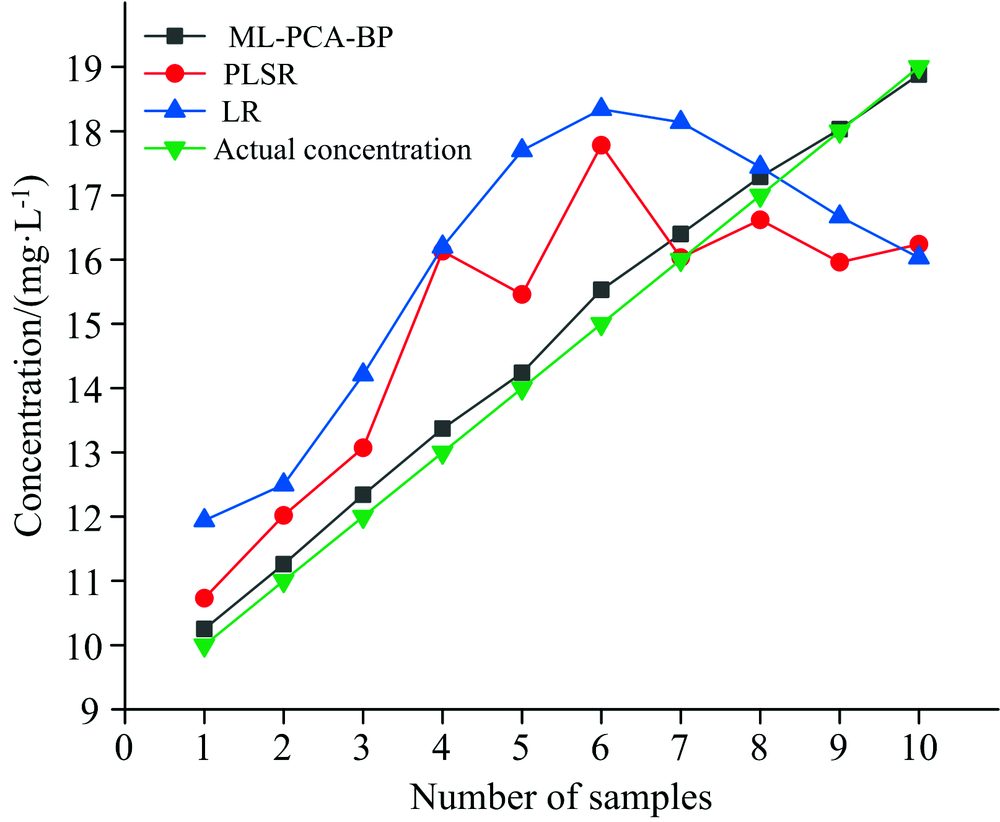 | 图6 真实值与实测值对比Fig.6 Comparison between real value and measured value |
ML-PCA-BP模型相比于LR算法能够较好提取光谱的非线性特征, 相比于PLSR算法具有较好的泛化能力与较强的预测能力, 因此ML-PCA-BP模型可以更加准确快速地检测出多环芳烃的浓度。
开展了芘定量分析研究, 通过ML-PCA-BP模型预测芘的浓度。 相比于使用的偏最小二乘, 线性回归等方法, 本模型的算法取部分特征峰数据简化了运算的复杂程度, 添加了其他重要的参数变量, PCA充分提取了光谱的非线性特征, L2正则化的BP神经网络又具备较强的泛化能力。 但是BP神经网络相对还是较为简单, 无法更为准确地得到光谱数据与浓度之间的关系。 未来可以选取更为精确的神经网络模型进行相关浓度的预测。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|