


{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高斯混合模型扣除毛发SERS信号中增强基底的背景峰
[李伟1, 2  , 何遥
, 何遥1, 2 , 林东岳2 , 董荣录2, * , 杨良保2, * ]
, 何遥, 杨良保]
|
|


作者简介: 李 伟, 1994年生, 安徽大学物质科学与信息技术研究院硕士研究生 e-mail: weili_ahu@163.com
在利用表面增强拉曼光谱(SERS)对毛发中痕量物质进行分析时, 该SERS信号中毛发特征峰与增强基底背景峰会相互耦合。 在耦合情况下, 背景峰会被误识别为毛发特征峰, 导致待测物的识别错误, 此外具有高峰强特性的背景峰对毛发中微弱特征峰产生掩盖干扰。 因此, 背景峰的扣除是解决上述问题的重要途径, 但常规的扣峰方法会导致周围邻峰的严重失真。 针对上述问题提出了高斯混合模型, 该模型在表征SERS信号的同时又使得各特征峰相互独立, 在扣峰过程中对周围邻峰不产生干扰, 既实现干扰峰的扣除又保证了邻峰的微失真。 高斯混合模型的核心问题在于模型参数的求解, 文中提出了小波变换与共轭梯度法, 分别解决模型的初始参数问题及最优解问题。 小波变换通过映射放大SERS信号的细节信息, 充分提取该信号的细微特征信息, 将该特征信息作为模型的初始参数。 其中共轭梯度法是迭代优化方法, 将模型参数进行循环迭代优化, 最终收敛结果即为模型参数的最优解。 综上两种方法可准确建立高斯混合模型, 模型中单高斯函数为SERS信号的特征峰, 且两者的峰形保持一致。 在扣除SERS信号的背景峰时应遵循以下过程, 包括有效数据的提取、 模型建立和峰的扣除。 其中有效数据的提取是对空白与滴样的增强基底进行同位置检测, 由此得到一组SERS信号。 模型建立是通过高斯混合模型对滴样SERS信号进行表征, 该信号可由多个高斯函数表现。 最后利用空白增强基底的特征峰对滴样的SERS信号进行指认, 其中峰形相似且峰位相同的特征峰可扣除。 实验结果表明, 方差值比最小时, 高斯混合模型的峰位、 峰宽、 峰强等特征与毛发SERS信号基本相同, 此时高斯混合模型可准确表征毛发SERS信号的特征信息。 在对7组毛发进行扣峰实验时, 毛发SERS信号中背景峰扣除率达到50%~100%, 同时毛发的特征峰也得到有效提取。 在对真实毛发样本进行快速分析时, 该模型识别出了毒品曲马多。
In the analysis of trace substances in hair by Surface-Enhanced Raman Spectroscopy (SERS), the characteristic peaks of hair are coupled with the background peaks of the substrate. In the case of coupling, the background peaks are mistakenly identified as the characteristic peak of hair, resulting in the identification error of the analyte to be tested. In addition, the strong background peak has a masking interference on the weak characteristic peak in hair. Therefore, the background peak deduction is an important way to solve the above problems. However, the conventional peak deduction method always leads to serious distortion of the surrounding peaks. In this paper, a Gaussian mixture model is proposed. The model not only characterizes the SERS signal but also makes each characteristic peak independent of the other, and does not interfere with the adjacent peaks in the process of peak deduction, which realizes the deduction of interference peaks and ensures the micro distortion of adjacent peaks. The core problem of the Gaussian mixture model is the solution of model parameters. In this paper, wavelet transform and conjugate gradient methods are proposed to solve the model’s initial parameter problem and optimal solution problem. The wavelet transforms fully extracts the subtle feature information of the signal by mapping the detailed information of the amplified SERS signal and takes the feature information as the initial parameter of the model. The conjugate gradient method is an iterative optimization method, and the model parameters are iteratively optimized. The final convergence result is the optimal solution of the model parameters. In summary, the two methods can accurately establish the Gaussian mixture model, and the single Gaussian function is the characteristic peak of the SERS signal, and the peak shape of the two methods is consistent. The deduction of background peak should include the extraction of effective data, model establishment, and peak deduction. The effective data extraction is to detect the blank and sampled substrate in the same position, thus obtaining a set of SERS signals. The model was established to characterize the SERS signal of the sampled substrate by the Gaussian mixture model, which multiple Gaussian functions can express. Finally, the SERS signal of the sampled substrate was identified by the characteristic peaks of the blank substrate, and the characteristic peaks with similar peak shapes and the same peak position can be deducted. The results show that when the variance ratio is the smallest, the peak position, peak width, and peak intensity of the Gaussian mixture model are the same as those of the hair SERS signal. At this time, the Gaussian mixture model can accurately characterize the information of SERS signal of hair. In seven groups of hair peak deduction experiments, of the hair SERS signal background peak deduction rate reached 50%~100%, while the hair characteristic peak wasalso effectively extracted. The model was used to identify tramadol in the rapid analysis of real hair samples.
根据公安部发布的《2020年中国毒情形势报告》, 截至2020年底, 中国现有吸毒人员180.1万名, 其中以冰毒、 海洛因为常见毒品类型, 大麻吸食人数逐年上升。 吸食毒品不仅损害吸毒者的身心健康, 也给家庭和社会带来严重危害, 如暴力伤害他人, 因此毒品检测对于禁毒工作至关重要。 毒品检测常以血液、 尿液、 毛发等生物检材作为检测对象, 其中毛发具有易获取易保存等特征, 优于其他生物检材。 毛发中毒品检测的常用方法包含有气相色谱质谱联用(GC-MS)[1]、 液相色谱质谱联用(LC-MS)[2]、 毛细管电泳[3]等, 这些方法在前处理、 检测时间、 专业操作等方面提出了较高要求, 具体表现为复杂性高、 时间长、 需专业人员操作等问题。 近年来, 表面增强拉曼光谱技术因可以实现对目标分子的痕量检测而一直备受关注, 其具有无损伤性、 指纹特征、 可重复性和高灵敏度等显著优点, 尤其在案发现场对可疑物进行高灵敏、 简便及快速检测, 特别在毒品检测领域得到广泛应用, 可检测出毛发中冰毒、 氯胺酮及曲马多等毒品。
表面增强拉曼光谱(surface-enhanced Raman spectroscopy, SERS)的增强原理是来自于贵金属(金、 银等)纳米材料(即增强基底)产生的电磁场增强, 以及吸附分子与纳米材料之间电荷转移产生的化学增强。 但在实际测试中, 通过化学合成方法制备的增强基底会使用大量的表面活性剂, 因此产生大量无用的背景信号。 例如, 以十六烷基三甲基溴化铵(CTAB)为表面活性剂合成的金纳米棒(AuNR)[4]的背景信号会对毛发及毒品特征峰产生干扰, 具体表现为背景信号特征峰对待测物的特征峰产生“ 掩盖” 与随机峰的干扰。 其中背景信号的“ 掩盖” , 具体表现为表面活性剂CTAB会在755与1 445 cm-1位置产生两个高峰强的特征峰, 在检测低浓度待测物时, 待测物的特征峰直接被背景峰抑制。 背景信号的随机峰干扰, 表现为不同增强基底在峰个数、 峰强度具有随机性。 在毛发检测中SERS信号是背景峰与毛发特征峰发生耦合, 对待测物的特征峰识别产生干扰。 因此, 需要微失真的扣峰方法, 对光谱中增强基底的背景峰进行扣除, 降低背景峰对毛发有效信号的干扰。 为实现扣峰法的微失真特性, 需要为SERS信号建立准确的数学模型。
在对SERS信号进行数学建模时, 常用的基函数是voigt函数[5, 6], 该函数对特征峰的波形具有较好的匹配性, 但该函数的解析参数含有4个, 其中半高宽参数提取易受SERS信号群峰干扰, 其次高斯-洛伦兹参数只在该函数中出现, 增加模型复杂度与计算量。 为获得准确的数学模型, 需要模型的参数邻近于SERS信号的特征信息(峰位、 峰强等), 其中K-S检验法[7]利用提取其中的半峰宽、 峰面积等特征信息作为模型初始参数, 但在该寻峰条件下弱峰识别无法保证, 其次SERS信号中耦合峰的半峰宽与峰面的提取易被干扰, 最终导致模型的初始参数赋值存在差异, 准确度难以实现。 同时初始参数的赋值也可提升模型的准确度, 故建立准确的数学模型需要最优参数解, 其中牛顿法是常用的参数优化方法[8], 二阶求导可使其迭代结果快速达到收敛条件, 但其较大计算数据量无法规避, 特别对于SERS信号这类的复杂峰, 该方法的运算效率急剧下降。
选择高斯混合模型扣除SERS信号中背景峰。 高斯混合模型的基函数与SERS信号的特征峰高度拟合[9], 可表征出该信号的所有特征信息。 为建立该模型需要借助小波变换[10], 对特征信息(峰位、 峰宽)的提取具有高灵敏性, 可为模型提供初始参数, 并且也可为移动窗口型相似度法(HQI)公式提供峰宽数据, 计算出峰形相似系数, 确定待测物SERS信号的背景峰。 对于模型参数的最优解, 依托于共轭梯度法的迭代收敛解, 利用参数的最优解向量建立的高斯模型可分离重叠峰, 实现对背景峰的滤除, 且保证邻峰的微失真。 采用上述方法对真实毛发样品的SERS信号进行处理, 实验结果显示, SERS信号中CTAB的两个高强度特征峰被完全扣除, 同时毛发的特征峰也得到有效提取。
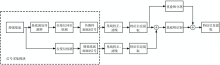
毛发样本的SERS信号中背景峰扣除遵循以下过程, 如图1所示。
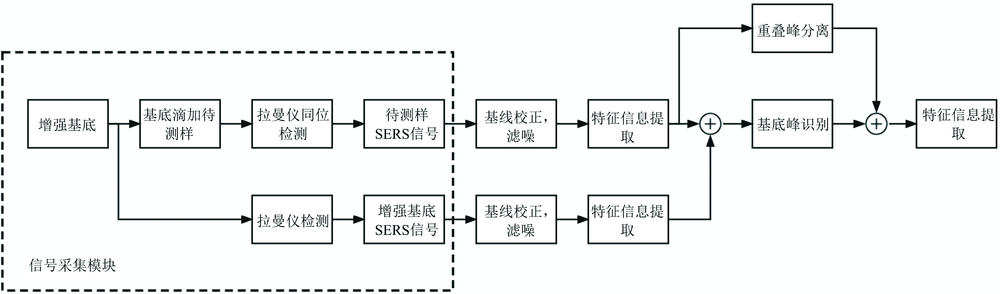 | 图1 SERS信号中增强基底背景峰的扣除流程图Fig.1 The flow chart of subtracting background peak of substrate in SERS signal |
(1) 有效数据的采集。 先后进行两次SERS信号采集, 分别对空白与滴样的增强基底进行检测, 检测时利用卡槽(固定装置)固定载样平台, 固定激光器探头, 可保证两次采集位于同一位置。
(2) 光谱数据处理与分析。 通过S-G滤噪算法[11]与airPLS基线校正算法[12, 13]对光谱进行预处理, 其中光谱分析采用小波变换、 求导等方法实现对SERS信号特征信息提取, 包括特征峰的峰位、 峰宽、 峰强、 峰数量等信息。
(3) 多峰耦合辨别。 基于移动窗口型HQI方法计算SERS特征峰的峰形系数, 扣除非耦合型背景峰, 避免待测物的有效特征信息被扣除。
(4) SERS信号中背景峰的扣除。 该过程依托高斯混合模型与共轭梯度法实现群峰分离与独立化, 实现多数背景峰的扣除, 且规避周围邻峰失真的现象。
SERS信号的特征提取主要采用小波变换与极值求解, 获取光谱信号的基本特征数据, 其中包括光谱特征峰的峰位、 峰宽和峰强。
在特征提取中连续小波变换算法具有信号放大特性, 其尺度参数的合适选择有助于凸显信号的细微变化, 故利用小波变换的此特性对SERS信号进行放大, 以表征信号中细微信息变化。 一维信号的连续小波变换公式
式(1)中, Ψ a, τ (t)为小波函数, 参数a为小波函数的尺度参数, 参数τ 为平移参数, Ψ (t)为小波基函数, 不同的小波基函数选择直接影响光谱细节信息的放大。 其中Mexican Hat小波基是由高斯函数二阶求导得出, 波形具有高斯函数特征, 与SERS特征峰具有相似性, 故选择Mexican Hat函数作为小波函数, 小波基公式如式(2)
基于上述小波变换方法提取SERS特征峰信息。 利用小波变换求解出目标物SERS信号的变换信号, 通过对变换信号进行极值求解, 得到相应的极值点, 其中极大值点经峰位校正后是特征峰的峰位, 极小值为特征峰的峰宽始末点。 以下为SERS信号特征信息提取具体流程:
(1) 放大信号, 求峰顶与峰谷位置。 对SERS光谱信号f(x)进行小波变换为WTf(a, τ ), 并进行极值求解, 极小值记为X1, 极大值记为X2。
(2) 准确峰位计算。 对SERS光谱信号f(x)进行极值求解, 记为X3。
(3) 峰位校正。 对比两个极大值集X2与X3, 其中元素差的绝对值小于参数a, 则X3集内元素为SERS信号峰位准确值X4。
(4) 峰宽始末位置判别。 对于满足条件X1i≤ X4j≤ X1(i+1), 则峰宽记为PW=X1(i+1)-X1i。
拉曼光谱仪检测的SERS信号包含背景峰与毛发特征峰, 两者相互耦合, 现需从耦合峰中识别出背景峰。 背景峰的识别依托于两次信号采集, 即分别对增强基底与毛发样本进行SERS信号采集, 将两组数据置于同一拉曼位移空间进行对比, 根据增强基底的SERS信号指认毛发样的SERS信号中增强基底背景峰。 背景峰辨别重点在于背景峰是否包含有毛发的特征信息, 若该特征峰是由背景峰与毛发特征峰高度耦合而成, 并且不能分离, 则该耦合峰予以保留, 故背景峰的显著特征为不含毛发的特征信息。 通过以下步骤辨别背景峰:
(1) 峰位相同, 即两信号在同一拉曼位移处出现特征峰。
(2) 峰形变化的相似性比较。 若两信号在同一位置出现特征峰, 就会有耦合效应, 背景峰会因毛发特征峰的叠加而产生波形畸变, 故波形变换是耦合峰判断的重要依据。 计算出两信号的峰宽并集, 即两信号的最小峰宽范围, 如式(3)
式(3)中, n代表峰宽交集长度, WP1与WP2分别代表背景峰的峰宽与毛发中某特征峰的峰宽。
移动窗口型HQI公式计算局部区域内两信号形状变化的相似系数, 如式(4)
式(4)中, f1k为待测物的SERS信号, f2k为增强背景的SERS信号,
毛发SERS信号中背景峰以独立峰与重叠峰形式显现, 针对独立峰情况, 无需考虑邻峰干扰, 对于重叠峰而言, 暴力扣除直接导致邻峰的严重畸变。 针对峰失真问题, 需要重叠峰分离算法, 将重叠峰分离成多个独立峰, 且峰间相互独立, 有效抑制峰间干扰。 重叠峰分离算法是对毛发SERS信号进行数学建模, 该函数模型可表征拉曼光谱的特征信息, 而数学模型建立需要解决两个问题, 即模型的选择与模型参数的求解。 首先, SERS信号的数学模型选用高斯混合函数, 该函数的基函数为高斯函数, 参数少且易计算, 依托于函数波形与SERS信号特征峰高度拟合, 再通过对模型初始参数的合理性设置, 可表征SERS光谱的所有特征信息。 同时, 为降低该模型计算的复杂度, 需要拉曼光谱的特征信息等先验知识, 进而实现数学模型的量化。 量化型高斯混合模型公式如式(5)
式(5)中, 参数n由先验知识进行量化。
高斯混合模型参数的最优解可让模型极限接近SERS光谱, 故模型建立的根本是模型自身参数的优化问题, 采用共轭梯度法优化该模型, 如式(6)
式(6)中, x为高斯混合模型的参数向量, g为参数向量的梯度方向, S参数向量的共轭梯度方向。 该优化方法基本原理是循环迭代逼近最优解, 达到阈值后中断循环, 输出最优解。 为降低优化方案的计算量与复杂度, 需要已提取的峰位、 峰强等特征信息对循环体初始参数进行赋值, 使循环体初始参数接近最优值。
金纳米棒增强基底; 真实毛发样本(安徽省公安厅提供); 氢氧化钠(国药集团化学试剂有限公司); 环己烷(国药集团化学试剂有限公司)。
检测仪器: 手持拉曼光谱仪(CASA18T1, 安徽中科赛飞尔科技有限公司); 分析平台: MATLAB R2016b软件, 操作系统为Windows 10, 8G内存, 计算机处理器为Intel(R) Core(TM) i5-9300H CPU@2.40GHz。
(1) 取30 mg发根毛发, 剪碎至2~4 mm, 加入2 mL离心管。
(2) 向离心管中加入1 mL 5%的NaOH溶液, 85 ℃加热10 min裂解。
(3) 滴加200 μ L环己烷, 剧烈振动, 进行萃取, 然后8 000 rpm离心2 min。
(4) 吸取上层清液10 μ L, 滴加至增强基底表面, 等待干燥。
有效数据的采集是分别对空白与滴样的增强基底进行检测, 获得的数据分别为增强基底的SERS信号与毛发样本的SERS信号, 两者为有效数据组。 采集积分时间为5 000 ms, 激光功率为250 mW, 识别方法选择特征峰匹配, 信噪比设置为800。 7组检测数据如图2(a, b)。
 | 图2 增强基底(a)和毛发(b)的SERS光谱数据Fig.2 The SERS spectral data of substrate (a) and hairs (b) |
共轭梯度法与牛顿法均可应用于高斯混合模型的最优参数求解, 其中共轭梯度法在数据计算量存在明显优势, 而牛顿法在收敛速度较为优秀。 以下通过实验对两种优化方法进行合适性评测, 评价标准分别为迭代次数、 运算时间、 方差值比, 其中方差值比是SERS信号与高斯混合模型的方差在解参数和初始参数两点的比值, 能有效凸显高斯模型参数优化程度, 数值小说明参数优化靠近最优解。 其中迭代次数与运行时间的数值小说明该优化方法更适合求解高斯函数模型参数。 对毛发与增强基底建立的高斯混合模型是同一数学模型, 为降低计算量, 故以增强基底的SERS信号进行实验, 比较两种优化方法合适性, 实验结果见表1。
| 表1 牛顿法与共轭梯度法对高斯混合模型的参数求解效果比较 Table 1 Comparison of newton method and conjugate gradient method in solving parameters of Gaussian mixture model |
表1实验结果表明共轭梯度法更适合求解高斯混合模型的参数。 表中第3列是方差值比[f(x)/f(x0)]的实验结果, 牛顿法与共轭梯度法的方差值比相同, 说明两种方法的参数解集较为接近, 都为高斯混合模型的有效解。 表中第2列的迭代次数比较中, 牛顿法的迭代次数远小于共轭梯度法的, 说明牛顿法的收敛速度明显快于共轭梯度法, 主要原因在于该方法是以二阶求导进行收敛, 收敛速度较快。 在第4列的运算时间比较中, 共轭梯度法的计算时间远小于牛顿法, 主要原因在于牛顿法运算中需要求解海森(Hessian)矩阵及其逆矩阵, 出现较大计算量, 并且随着SERS光谱的特征峰增多, 牛顿法的计算量不是线性增加, 而是呈现几何级增长, 即运算时间按照几何级增加, 故牛顿法的求解效率远低于共轭梯度法。 通过以上比较, 共轭梯度法迭代次数较多, 但运算量较低, 整体运算效率得到提升, 故共轭梯度法适合求解高斯混合模型的参数。
由上述实验结果可知, 共轭梯度法适合求解高斯混合模型的参数, 但需要选择合适的初始参数。 当共轭梯度法的参数被任意初始参数赋值时, 易出现迭代发散现象, 说明模型建立失败。 为规避发散现象, 需对初始参数进行优化。 故对毛发SERS信号的特征信息(峰位、 峰强等)进行提取, 采用该特征信息作为初始参数, 使得初始参数接近最优参数解。 初始参数的优化效果见表2。
| 表2 共轭梯度法的参数优化效果比较 Table 2 Comparison of parameter optimization effects of conjugate gradient method |
表2结果表明, 通过不断优化初始参数可提升共轭梯度法的运算效率。 实验中将毛发SERS信号的峰位、 峰强逐步设置为初始参数(见表2中前3组数据), 其中实验组3的初始参数完全由峰位、 峰强等特征组成。 由前3组实验结果可看出, 共轭梯度法的迭代次数、 运行时间明显降低, 且方差值比也逐步减少, 说明初始参数优化有利于迭代过程与结果。 再对实验组3的初始参数作小幅度修改(见表2中第4组数据), 实验结果显示迭代次数、 运行时间出现不同程度增加, 且方差值比增加至2.19, 与上一组实验结果相比, 说明所得的参数解集非最优解。 综上所述, 当利用毛发SERS信号的特征信息对初始参数进行优化时, 共轭梯度法的迭代速率与运算结果得到提升。
共轭梯度法的初始参数设置不仅对迭代次数、 计算量产生影响, 还对高斯混合模型的建模产生影响, 具体表现在初始参数对模型的峰位、 峰宽、 峰强等特征产生影响。 利用表2中第3和4实验组的初始参数对高斯混合模型进行赋值, 为展示模型建立的效果, 将模型与毛发SERS信号进行比较, 如图3。
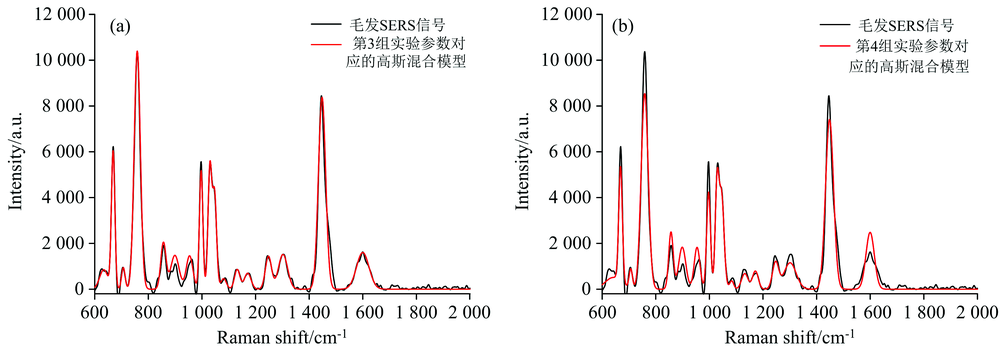 | 图3 共轭梯度法的初始参数优化对高斯混合模型的影响 (a): 第3组; (b): 第4组Fig.3 Effect of initial parameter optimization on modeling of Gaussian mixture model (a): The third set; (b): The fourth set |
图3展现了在不同初始参数下, 高斯混合模型的建模效果, 图3(a, b)中高斯混合模型的初始参数分别对应表2中第3和4组实验数据。 由左图观察到高斯混合模型的峰位、 峰宽、 峰强、 峰形等特征与毛发SERS信号保持一致, 说明拟合较准确。 而图3(b)高斯混合模型的峰位、 峰强和峰形等特征与毛发SERS信号存在差异, 说明拟合相对不准确或模型建立发生了失真, 故图3(a)的初始参数利于高斯模型的建立。 综上所述, 将毛发SERS信号的特征信息作为初始参数时, 高斯混合模型的峰位、 峰强、 峰宽、 峰形等特征与毛发SERS信号相匹配。
毛发SERS信号包含毛发特征峰、 增强基底背景峰及目标物(毒品分子)的特征峰, 其中增强基底的背景峰是无信息峰, 在峰的强度与峰的个数两个层面对周围有效峰产生干扰。 采用高斯混合模型对真实毛发的SERS信号进行处理, 扣除该信号中增强基底的背景峰。 实验结果如图4。
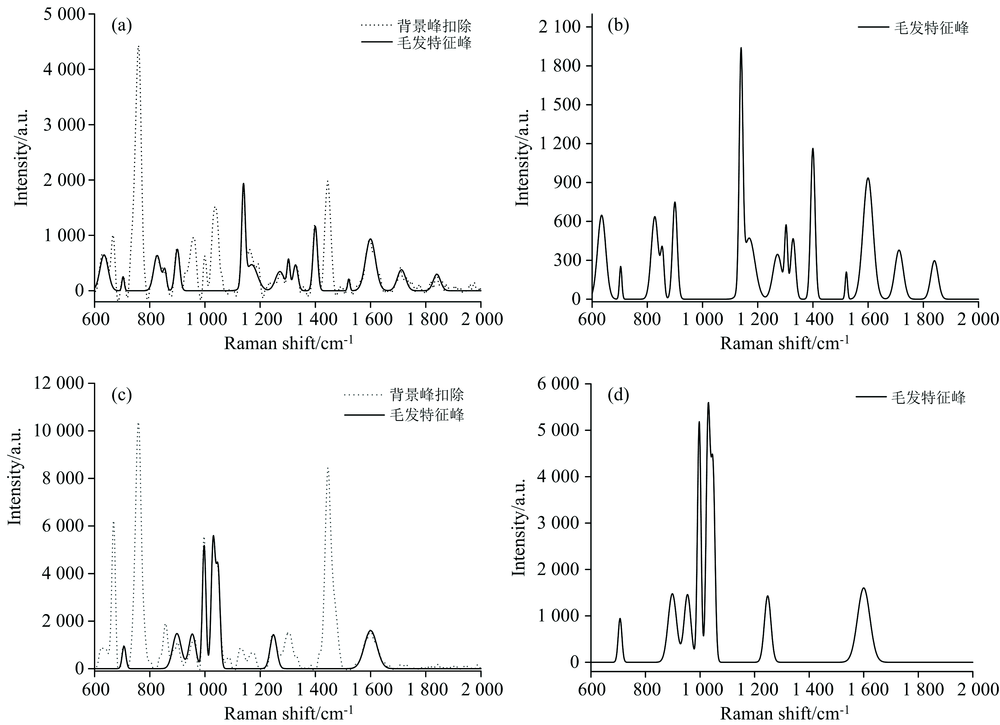 | 图4 毛发SERS信号的背景峰扣除及特征信息提取 (a): 样本1; (b): 样本1及毒品; (c): 样本2; (d): 样本2及毒品Fig.4 Background peak deduction and feature information extraction of SERS signal of hair (a): Sample 1; (b): Sample 1 and drug molecules; (c): Sample 2; (d): Sample 2 and drug molecules |
图4(a)和(c)两图的虚线峰代表毛发SESR信号中被扣除的背景峰, 图4(b)和(d)的特征峰是从毛发SERS信号中提取出的毛发及毒品分子的特征峰, 图4(b)中包含氯胺酮分子的650 cm-1特征峰, 图4(d)中包含曲马多的特征峰。 观察图4(a)和(c), 均包含有755与1 445 cm-1虚线峰, 该峰的峰强明显高于周围峰的峰强, 此时对毛发的弱峰产生“ 掩盖” 影响, 将其扣除后, 弱小峰可得到有效凸显, 有效解决背景峰的“ 掩盖” 问题。 同时, 将图4(a)和(c)两图分别与(b)和(d)两图进行比较, 其中(b)和(d)两图峰的个数明显少于(a)和(c)两图, 缺少的峰均为增强基底的背景峰, (b)和(d)两图在一定程度上规避了峰个数的干扰。 尤其如图4(c)和(d)所示, 两图在707, 997和1 248 cm-1三个位置均出现特征峰, 表明毛发中含有新型精神活性物曲马多的成分, 但图4(d)更容易识别出毛发中含有曲马多毒品成分。
现对7组毛发SERS信号进行背景峰扣除实验, 观察不同毛发样品的峰扣除效果, 可通过背景峰的扣除比例进行评价, 比例越高则背景峰扣除的越多, 其中背景峰扣除比例由背景峰的扣除数量与总数量的比值得到。 表3表明了7组毛发样品的背景峰扣除情况。
| 表3 不同毛发SERS信号的背景峰扣除情况 Table 3 Background peak deduction of SERS signals from different hairs |
表3中第2列数据显示不同增强基底的背景峰总数量存在差异, 说明增强基底对毛发特征峰的干扰具有不稳定性。 同时, 表3中第4列数据显示不同增强基底的背景峰扣除比例不一致, 说明毛发中增强基底的背景峰存在完全扣除与部分扣除两种情况。 其中标号为1, 2和3的毛发样本的扣除比例达到100%, 说明毛发SERS信号中增强基底背景峰被完全扣除, 主要原因是755与1 449 cm-1处的两个背景峰特征明显, 易于识别和扣除。 其中标号为4, 5, 6和7的毛发样品的扣除比例50%~60%, 说明毛发SERS信号中增强基底的部分背景峰被扣除, 主要原因是增强基底出峰数量较多, 除在759与1 449 cm-1两个峰的特征明显, 其余峰的峰强偏弱, 且峰位与毛发特征峰的峰位相近, 出现高度耦合。 经上述分析可知, 背景峰的扣除与两个因素有关, 分别是背景峰特征的强弱及峰的耦合度, 而这两种因素又具有随机性, 故背景峰扣除比例的范围不局限于上述各表中。
提出了一种基于高斯混合模型扣除背景峰的方法, 可扣除毛发SERS光谱中增强基底的背景峰, 并提取出毛发中毒品分子(氯胺酮, 曲马多)的特征峰。 首先, 选择高斯混合模型的参数优化方法, 通过对比迭代次数与运算时间, 共轭梯度法的运算效率是牛顿法的200倍, 且运算结果一致, 可以得出共轭梯度法优于牛顿法。 其次, 对高斯混合模型的初始参数进行设置, 将小波变换的特征信息设置为初始参数, 运算时间控制在2 s, 模型运算效率最高。 最后, 运用建立的高斯混合模型对7组不同类型真实毛发样品进行实验, 背景峰扣除率达到50%~100%, 并且邻峰失真较小, 毛发的特征峰得到有效提取。 此方法有望应用于复杂体系中痕量物质的SERS光谱特征峰的提取, 减少误差, 提高识别的正确率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|