



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于AW-OPS高光谱波长选择方法的羊肉新鲜度检测
[赵停停1, 3  , 王克俭
, 王克俭1, 3, * , 司永胜1, 3 , 淑英2 , 何振学1, 3 , 王超1, 3 , 张志胜2, * ]
, 王克俭, 司永胜]
|
|


作者简介: 赵停停, 女, 1997年生, 河北农业大学信息科学与技术学院硕士研究生 e-mail: 2359960681@qq.com
高光谱数据中不仅含有关键性信息还存在一些干扰信息和无效信息, 带有干扰信息和无效信息的数据建立模型会降低效率和模型精度。 从全波段数据中提取特征波长是提高关系模型精度的有效方法。 有序预测选择(OPS)是一种依据信息向量选择有效波长变量的特征波长提取算法, 在特征波长变量筛选方面表现了较好地性能。 但由于建立模型时, 没有去除重要性较低的变量, 导致过多的无效变量参与到模型中, 降低了模型的准确率。 论文以羊肉高光谱数据作为研究对象, 提出了一种改进的特征波长变量选择方法, 基于信息向量和指数衰减函数的有序预测选择方法(AW-OPS)对羊肉新鲜度进行检测, 该算法通过光谱数据和理化值数据之间的关系来计算信息向量并对波长变量进行排序, 采用指数衰减函数(EDF)通过多次迭代去除一些信息向量绝对值比较低的波长变量, 最后在已获取的有效波长变量中逐渐增加波长点建立多元回归模型, 选取交叉均方根误差(RMSECV)最小值的波长变量子集为特征波长变量。 实验时, 将OPS法和AW-OPS法在选取特征波长变量后, 分别构建羊肉TVB-N的偏最小二乘(PLS)关系模型, 同时与全光谱波段PLS模型的效果相比较。 结果表明: OPS算法运行程序平均用时为175.9 s, 优选出370个特征波长变量, OPS-PLS模型相关系数( RP)平均为0.963 1, 均方根误差(RMSEP)平均为0.727; 而改进的有序预测选择法(AW-OPS)运行程序平均用时为57.6 s, 优选出275特征波长变量, AW-OPS-PLS模型平均提升到0.973 1, RMSEP平均降低为0.572 8; 全光谱波长数目为1 414个波长变量, 其PLS模型的平均为0.920 8, RMSEP平均为1.048 3。 AW-OPS-PLS模型相较于OPS-PLS模型测试精度提高了21.2%, 相较于全光谱-PLS模型, 测试精度提高了45%, 证明AW-OPS是一种有效特征波长变量筛选方法, 提高了OPS模型精度和程序运行效率, 降低了模型复杂度。
, WANG Ke-jian, SI Yong-sheng
Hyperspectral data contain not only critical information but also some interference information and invalid information, and using these data to build the model will reduce the reliability and accuracy of the relational model. Extracting feature wavelengths from full-band data is an effective way to improve the accuracy of prediction models. Ordered Predictive Selection (OPS) is a feature wavelength extraction algorithm that selects effective wavelength variables based on the information vector, and has shown good performance in feature wavelength variable screening. However, the model was built without removing the less important variables, resulting in too many invalid variables being involved in the model and reducing the model’s accuracy. The paper proposes an improved feature wavelength variable selection method based on an information vector and exponential decay function of ordered predictive selection method (AW-OPS) for lamb freshness detection, using lamb hyperspectral data as the research object. The algorithm calculates the information vector and ranks the wavelength variables by the relationship between the spectral data and the physicochemical value data. The exponential decay function (EDF) is used to remove some wavelength variables with relatively low absolute values of information vectors by multiple iterations. Finally, a multiple regression model was established by gradually adding wavelength points to the obtained effective wavelength variables, and the subset of wavelength variables with the lowest value of root mean square error (RMSECV) was selected as the characteristic wavelength variables. For the experiments, the partial least squares (PLS) relational models of lamb TVB-N were constructed by the OPS -and AW-OPS methods after selecting the characteristic wavelengths,respectively, and compared with the effects of FULL-PLS models. The results showed that the OPS algorithm took an average of 175.9 s to run the program, preferentially selected 370 characteristic wavelength variables, with an average OPS-PLS model correlation coefficient( RP)of 0.963 1 and an average root mean square error(RMSEP)of 0.727. while the improved ordered prediction selection method(AW-OPS)runs the program in an average time of 57.6 s, preferentially selects 275 characteristic wavelength variables, and the AW-OPS-PLS model RP improves to 0.973 1 on average, and RMSEP reduces to 0.572 8 on average. The number of full-spectrum wavelengths was 1 414 wavelength variables, and the average RP of its PLS model was 0.920 8, and the average RMSEP was 1.048 3. The AW-OPS-PLS model improved the test accuracy by 21.2% compared to the OPS-PLS model and 45% compared to the full-spectrum-PLS model, proving that the improved AW-OPS is an effective feature wavelength variable screening method that improves the accuracy of the OPS model and the efficiency of the program operation and reduces the complexity of the model.
羊肉的肉质细腻、 口味特别, 所含有的脂肪、 胆固醇含量相比于其他肉食类较少, 同时具有驱寒取暖的作用[1]。 由于羊肉成本高, 市面上的商贩为了谋取利益销售部分次新鲜羊肉甚至腐败羊肉, 这种“ 以次充好” 的问题需要应用技术手段有效地监管。 挥发性盐基氮是检测羊肉新鲜度的重要指标之一。 高光谱成像技术融合了计算机科学和化学计量学等多门学科, 具有清晰度高、 操作简便、 非破坏性等优势, 现已应用于农业[2, 3, 4]、 地质[5]、 医学[6]、 食品[7, 8, 9]等多个领域。 在高光谱数据构建关系模型后, 由于光谱数据有数千条波长, 波段是连续的, 容易导致数据信息的冗余性, 还有干扰信息, 这都会影响模型的效果。 因此, 从高光谱全部波段变量中选取特征波长对提高模型的稳健性和测试能力有着重要意义。
Assis等[10]通过有序预测选择法(ordered predictor selection, OPS)、 间隔偏最小二乘(interval partial least squares, iPLS)和反向区间偏最小二乘(backward interval partial least squares, biPLS)筛选木质素含量的关键性波长变量, 采用偏最小二乘法建立多元回归模型对甘蔗不同部位木质素含量进行测试, 结果表明OPS-PLSR模型的测试精度最高, 为最优模型。 Assis等[11]通过OPS算法筛选特征波长变量后, 建立偏最小二乘模型对咖啡的成分进行测试; 与遗传算法(genetic algorithm, GA)相对比, OPS算法可以有效地舍弃非信息性波长变量, 降低模型误差。 此外, Ellisson等[12]通过OPS算法和粒子群算法(particle swarm optimization, PSO)筛选特征波长变量后, 建立OPS-PLS和PSO-PLS模型测试石油的树脂、 沥青、 热燃烧值等含量, 结果发现OPS-PLS模型可以更加准确地测试石油的含量。 以上说明, OPS算法在光谱数据降维方面有着较好的效果。
尽管OPS算法可以较为有效地提取特征波长改进模型的测试结果, 但不足之处是, OPS算法运用有序波长变量建立多元回归模型时, 没有去除信息不足和重要性比较低的变量, 导致过多的无效变量参与到模型中, 降低了模型的准确率, 增加了模型的复杂性, 且算法需要多次迭代才能遍历完光谱数据集, 加大了数据运行的时间, 降低了程序运行效率。
综上, 本工作对OPS算法进行了改进, 将特征波长变量算法中信息变量与有序预测选择算法(OPS)和指数衰减函数(EDF)相结合, 设计了AW-OPS(advance weight ordered predictor selection, AW-OPS)。 该算法通过光谱数据和理化值数据之间的关系来获取信息向量并对波长变量进行排序, 在有序波长变量中采用指数衰减函数(EDF)去除信息向量绝对值较低的波长后, 进而获取有效性高的波长变量。 以冷鲜羊肉为研究对象, 采用AW-OPS算法进行特征波长变量选取, 建立羊肉挥发性盐基氮值(TVB-N)的PLS关系模型, 并与其他特征波长变量选择方法相比较, 以证明AW-OPS算法的有效性, 为加强羊肉食品安全的监管提供技术支持。
用背脊和后腿部位的羊肉作样品, 购于河北省保定市唐县常见的一种小尾寒羊。 羊肉需要在24 h之内进行排酸处理, 然后将样品立即装入到保温箱中运送到实验室。 在无菌实验室把羊肉中的脂肪和肌膜去除, 并用无菌手术刀进行切块处理, 尽量保持羊肉样品表面平整, 将样本装入到自封保鲜袋中置于4 ℃恒温冰箱中储放, 每份样本大约20 g, 大小约为5 cmⅹ 5 cmⅹ 3 cm, 样本数量共计108个, 如图1所示。 每隔24 h分别取出背脊肉样品和后腿肉样品各4个, 参照国标GB/T 5009.228— 2016标准测定羊肉新鲜度指标(TVB-N值), 实验天数共计14 d。 将称取10 g样本肉, 切碎成肉糜放置锥形瓶中, 量取100 mL蒸馏水置于锥形瓶用玻璃棒搅拌, 浸泡30 min后过滤。 使用全自动凯氏定氮仪之前进行清洗、 排废, 仪器蒸馏时间为15 min, 量取10 mL的样本肉滤液及5 mL的氧化镁混悬液到消化管中, 蒸馏时间为5 min, 用0.01 mol· L-1标准盐酸溶液进行滴定终止, 每个羊肉样本重复测定TVB-N值3次, 取平均值作为TVB-N值的测定值。
 | 图1 实验样本Fig.1 Experimental samples |
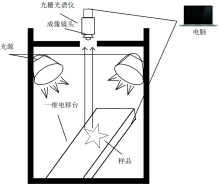
高光谱图像采集系统如图2所示, 系统主要包括: PC机、 海洋光学(Ocean Optics)的微型光谱仪NQ512-1.7(上海蔚海光学仪器有限公司)、 入口狭缝、 高功率卤钨灯的光源、 USB2000+的光栅、 CMOS的相机和WS-1光谱定标白板等装置组成。 光谱仪波长范围为320~1 000 nm。
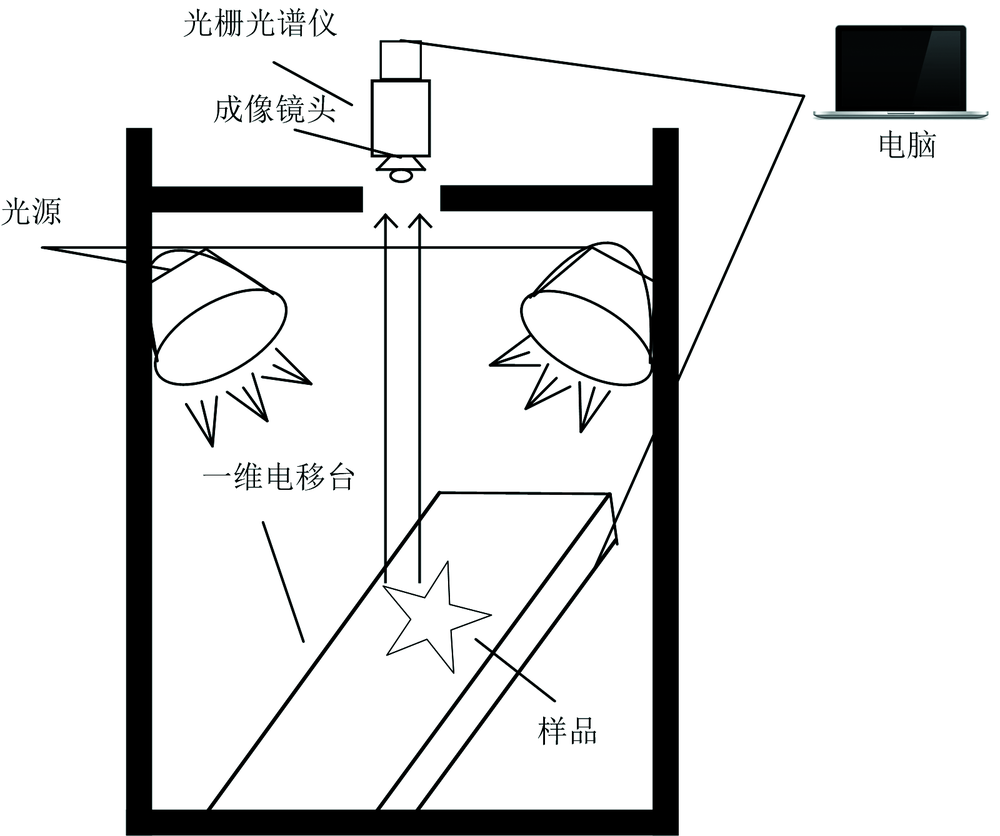 | 图2 高光谱图像采集系统Fig.2 Hyperspectral image acquisition system |
在采集光谱图像之前需要对光谱仪参数进行设置: 滑动平均宽度为3、 平均扫描次数为25次、 积分时间为150 ms、 探头角度为90、 样本到镜头距离为3 cm。 采集光谱图像数据的试验流程是: 首先打开光源预热30 min, 镜头对准白板, 把羊肉样本放在载物台上, 设置羊肉样本到镜头间的距离进行图像扫描, 整个试验操作过程都是在暗箱中完成。 由于暗箱中电流有噪声、 不稳定等原因对数据造成影响导致试验结果有误差, 因此试验之前需要进行黑白校正。
1.3.1 OPS算法
采集羊肉样品在400~900 nm波段范围的高光谱数据信息, 共有1 414个波长, 高光谱数据信息之间存在冗余性和共线性信息, 特征波长筛选可以实现光谱数据降维, 降低羊肉新鲜度模型的复杂度。
OPS是Reinaldo F Teó filo提出了一种将信息向量与有序预测选择相结合的特征波长变量选择算法, 具有简便和数据类型通用性强的特点。
OPS算法是通过信息向量获取一个包含光谱数据信息重要性高的波长变量; 依据全波段光谱数据和TVB-N值数据之间的关系获得信息向量; 获得所有信息向量及信息向量组合后, 根据信息向量元素的相应绝对值对光谱矩阵的变量进行区分, 绝对值越高, 对应的变量越重要; 从信息向量绝对值中对波长变量进行降序排序, 通过定义一个初始变量子集来建立第一个多元回归模型, 之后逐渐增加固定波长变量来建立新的多元回归模型, 并计算每一个子集模型的交叉验证均方根误差(RMSECV)参数; 最终选择特征波长变量是通过对比模型的RMSECV参数, 最小RMSECV参数的模型具有最佳预测能力的波长变量及相对应的最佳信息向量被选择为特征波长。
1.3.2 信息向量
目前衡量波长变量的重要性由信息向量进行判断, 常见的信息向量有回归系数向量(β )、 变量投影重要性向量(vip)、 残差信息向量(sqr)、 线性相关系数向量(cor)、 协方差向量(cov)等。 虽然特征波长选择方法和信息向量有很多种, 但每种特征波长选择方法只采用其中一种信息向量作为波长变量重要性决策的依据, 而忽略了其他信息向量对关系模型的影响, 关系模型可能会出现过度拟合的现象。 针对这种现象, 将由多个信息向量及两两组合的信息向量判定变量重要性, 两两组合的信息向量进行归一化处理, 综合分析了多个信息向量对光谱数据的影响。
信息向量是通过光谱数据和理化值数据之间的关系计算获得, 用β , vip, sqr, cor, cov和weight值等来表示, 这些数据可以衡量波长变量的重要性, 计算如下:
① β 为回归系数向量, 表示自变量X(光谱数据)对因变量y(理化值数据)的影响, 可以通过偏最小二乘拟合计算得到
偏最小二乘的原理是K维中的X空间, 其中每个X列表示一个坐标轴。 如果每个截面的一条线和一个方向由A维超平面表示, 则X空间投影到正交轴上, 同时投影的数据位置去解释Y空间的值使得方差最大。 β 的绝对值越大, 因变量y受自变量X的影响越大, 选取绝对值比较大的波长变量, 建模测试能力越强。
② vip为变量投影重要性向量, 用来评价自变量X(光谱数据)解释因变量y(理化值数据)的重要性, 根据解释能力的大小来选取自变量。
vip是基于PLS模型计算的信息向量。 式(2)中n为自变量光谱数据的数量, m为PLS模型中潜在变量的数量, Ch为第h个主成分, r(y, Ch)为主成分之间的相关系数Ch对因变量y的重要性, wkj为特征向量wk的第j个分量。 若主成分Ch解释因变量y的能力越强, 并且自变量X对Ch作用又大, 代表自变量X解释因变量y的重要性较大。 因此vip绝对值越大, 自变量的重要性越高, 选取重要性较高的波长变量建立模型, 提高模型的准确率。
③ sqr为残差信息向量, 用来度量原始光谱与重建光谱之间的差异, 其中包含光谱变量的重要相关信息。
在建立PLS模型时, 可以根据PLS的主成分获得一个重构矩阵
④ cor为线性相关系数向量, 用来评价自变量X(光谱数据)和因变量y(理化值数据)之间的线性相关的向量。
式(5)中Xi为第i个自变量,
⑤ cov为协方差向量, 表示协方差矩阵的对角线值, 用来衡量两个变量之间的总体误差。
cov通过偏最小二乘法计算得到的信息向量, 式(6)中XTYYTX为矩阵中的对角线值, 各个变量的对角线值便构成了协方差向量, 协方差值越大, 两个变量之间相关性越强, 用这些值的变量建立模型, 提高模型精度。
⑥ weight为权重向量, 通过非线性迭代偏最小二乘算法获得的权重向量, 选取比较大的weight绝对值的波长变量参与建立模型中, 降低模型的复杂性。
1.4.1 对OPS算法的改进
在OPS算法中, 建立模型前没有去除重要性比较低和信息不足的变量, 导致过多的无效变量参与到模型中, 使模型具有较大的复杂性, 降低了模型的准确率, 针对这点, 对OPS算法进行改进。
为了降低模型的复杂度, 提高模型的测试精度, 提出了一种基于信息向量和指数衰减函数的有序预测选择算法(AW-OPS)。 AW-OPS算法在有序波长变量中采用指数衰减函数(EDF)进行强制去除信息向量绝对值比较低的变量后(波长变量重要性比较低的波长)来构建多元回归模型。
1.4.2 指数衰减方法优选的波长变量
倘若尚未去除信息向量绝对值比较低的变量参与到建立模型中, 会增加模型的复杂性, 也会影响模型的效果。
本工作的改进是: 在有序波长变量中采用指数衰减函数(EDF)进行删除一些重要性比较低和信息不足的波长变量, 然后再构建模型。 EDF每次迭代保留率并不是一样, 最初, 含有信息向量绝对值比较低的波长变量将会被迅速去除, 这阶段称作“ 粗略选择” 。 随着信息向量绝对值比较低的波长变量的减少, 去除速度会降低, 为了避免波长变量重要性高的变量被去除, 这是一个“ 精准选择” 的阶段。 因此使用指数衰减函数(EDF)来强制去除信息向量绝对值比较低的变量, 这样可以节省数据的运行时间, 降低模型的复杂性。 在指数衰减函数(EDF)运行过程中为了避免光谱变量信息的丢失, 设置了至少80%的波长变量保留率。 波长变量保留率的定义为
式(7)中, i为迭代次数(i=1, 2, 3, …, N), N可以设置为50的迭代次数。 p为变量总数。 其中a和k分别是第一次循环和第N次循环时样本集建模的数目, 遍历所有的变量, 第m次设置为只遍历两个变量, 用来构建模型的数目, 所以r1=P, rN=
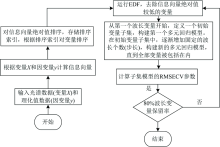
1.4.3 算法流程
AW-OPS算法依据信息向量绝对值的大小来衡量波长变量的重要性, 信息向量的绝对值越大, 波长变量的重要性越高, 优选信息向量绝对值大的变量为特征波长变量。
AW-OPS算法的主要步骤如下:
Step1: 根据光谱数据(变量X)和理化值数据(因变量y)计算信息向量。
Step2: 根据信息向量的绝对值进行降序排序, 并存储排序索引。 根据排序索引对变量进行排序。
Step3: 采用指数衰减函数(EDF), 强制去除信息向量绝对值比较低的变量。
Step4: 去除信息向量绝对值比较低的有序变量后, 从第一个波长变量开始, 定义一个初始变量子集个数, 构建第一个多元回归模型。
Step5: 定义一个固定变量个数(步长)来增加初始变量子集, 然后建立一个新的多元回归模型。 每次增加一个步长来扩大变量子集的大小, 直到模型把全部变量包括在内。
Step6: 计算各个子模型的交叉验证参数, 确定最佳变量子集。
AW-OPS算法流程图如图3所示。
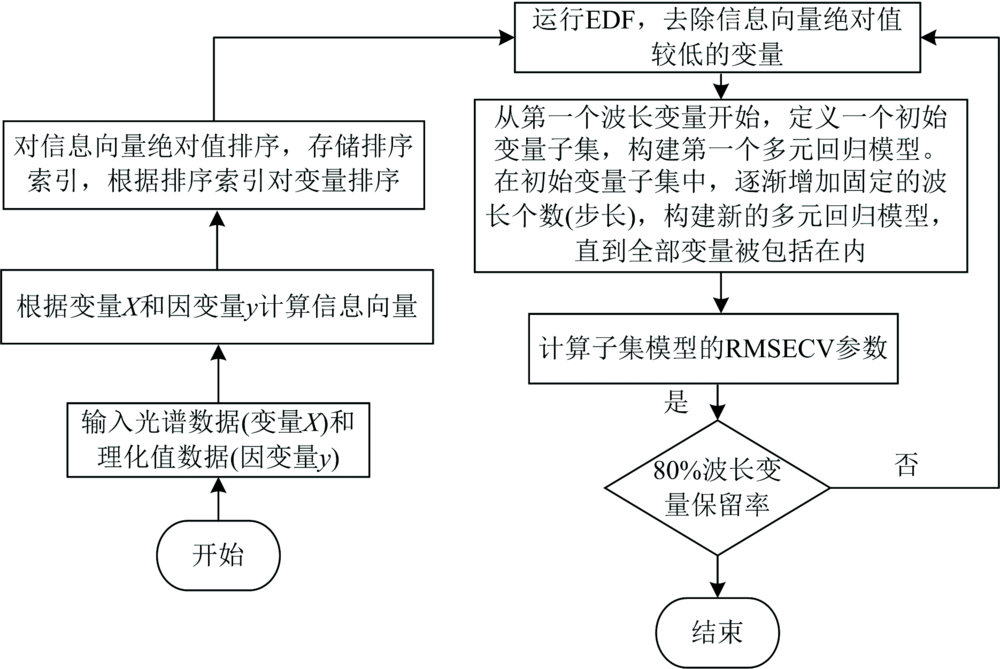 | 图3 AW-OPS算法流程图Fig.3 AW-OPS algorithm flow chart |
本文共使用21个信息向量包括信息向量组合, 这些向量组合通过归一化后将一个向量乘以另一个向量获得, 同时比较所有信息向量选取的特征波长变量建立模型的效果, 在根据各个子集模型的交叉均方根参数(RMSECV), 确定最佳变量子集及最佳信息向量。
选取特征波长变量以交叉验证均方根误差(RMSECV)最小值时为评价指标, RMSECV值越小, 代表从全波段选取有效波长和关键性波长变量越多。 RMSECV可以使用式(10)计算
式(10)中, n是样本数量, yi是样本实际值,
模型的评价标准分别包括测试集和训练集样品对模型的评估, 选用相关系数(R)和均方根误差(RMSE)进行评价, 若测试集的R接近于1, 测试均方根误差(RMSEP)越小, 表示模型测试能力越强, 若训练集的R接近于1, 训练均方根误差(RMSEC)越小, 表示模型训练能力越高。
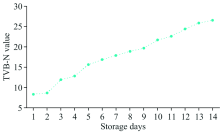
测定羊肉样品在14 d内TVB-N含量的平均变化, 如图4所示。 从图4中明显地看出, 随着储存天数的增加, 样品中的TVB-N含量呈升序趋势。 前4天样品的平均TVB-N含量相对较低, 表明样品处于新鲜状态, 第5天样品的平均TVB-N含量为15.55 mg· (100 g)-1, 表明样品已经处于次新鲜状态, 第10天样品的平均TVB-N含量为21.67 mg· (100 g)-1, 表明样品已经处于腐败状态。 样品中TVB-N逐渐增加的变化反应了羊肉从新鲜到腐败阶段。 羊肉品质发生变化的原因是羊肉中的糖原被微生物细菌消耗掉, 然后羊肉中的蛋白质被降解, 随着细菌数量的增加, 羊肉中的TVB-N含量逐渐增加, 导致羊肉的品质逐渐腐败。
 | 图4 羊肉样品中TVB-N含量的平均变化趋势图Fig.4 Mean trend of TVB-N content in lamb samples |
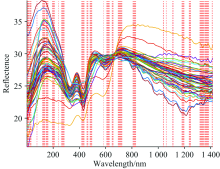
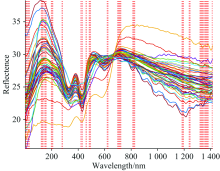
利用高光谱成像系统扫描羊肉样本提取反射率, 图5(a)为羊肉样本在400~900 nm波段下的光谱曲线。 其中, 550和580 nm附近的吸收峰主要与冷鲜羊肉中含有血红蛋白有关[13]。 试验采集的光谱数据除样本自身信息外, 还包含了基线漂移和噪音以及其他信息, 为了消除这些信息的干扰来提高分辨率和灵敏度。 采用S-G卷积平滑结合多元散射校正预处理方法校正光谱曲线如图5(b)所示。
 | 图5 原始光谱曲线图及预处理后的光谱曲线图 (a): 原始光谱曲线图; (b): S-G结合MSC处理后的光谱图Fig.5 Original spectra and pre-processed spectra of lamb samples (a): Original spectral graph; (b): S-G and MSC pre-processed |
将108个羊肉样本集按照X-Y共生距离法(sample set partitioning based on joint X-Y distances, SPXY) 3∶ 1的比例划分[14], 选取其中81个样本光谱数据和理化值数据作为训练集, 剩余的27个样本光谱数据和理化值数据作为测试集。
2.3.1 OPS选取特征波长变量结果
如上所述, 首先对OPS进行参数初始化设置, 排序后全波段中定义一个初始波长变量个数为10, 固定波长变量个数(步长)为5, 交叉验证次数为10, 最大主成分个数为10, 开始运行程序。
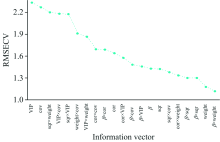
以信息向量为波长变量指标, 采用OPS算法后所有信息向量用相对应的特征波长变量参与构建模型的RMSECV值的变化趋势如图6所示。
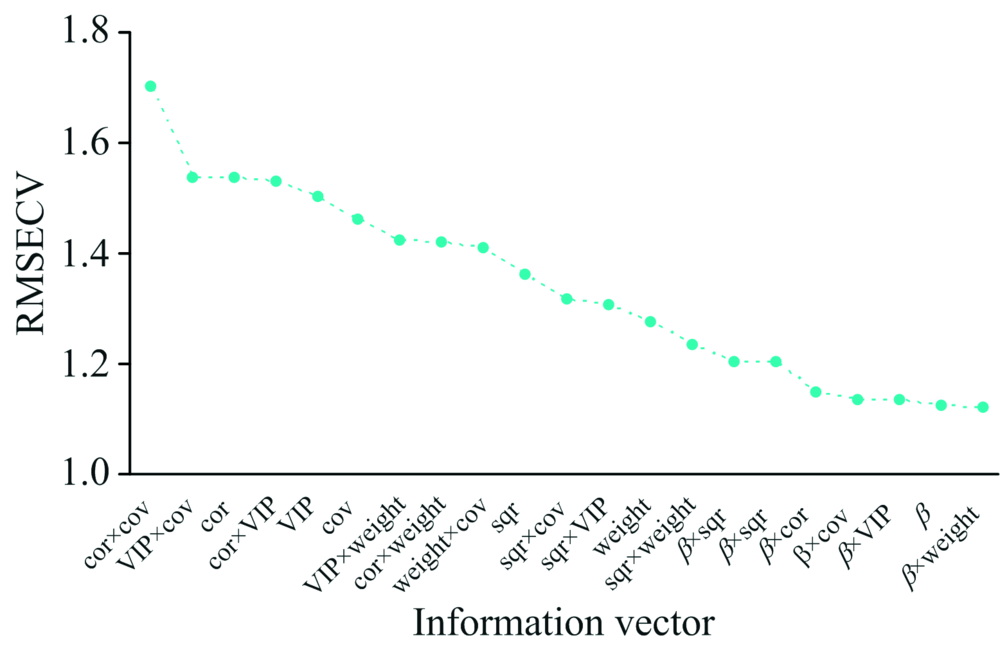 | 图6 采用OPS法后RMSECV的变化Fig.6 Changes of RMSECV after applying OPS method |
由图6分析可知, 选择RMSECV最小值的信息向量为最佳信息向量, 满足条件为β × weight信息向量其最小值1.119 0。 最佳信息向量选取的特征波长变量结果如图7所示, 选出的波长变量数目为370个波长。
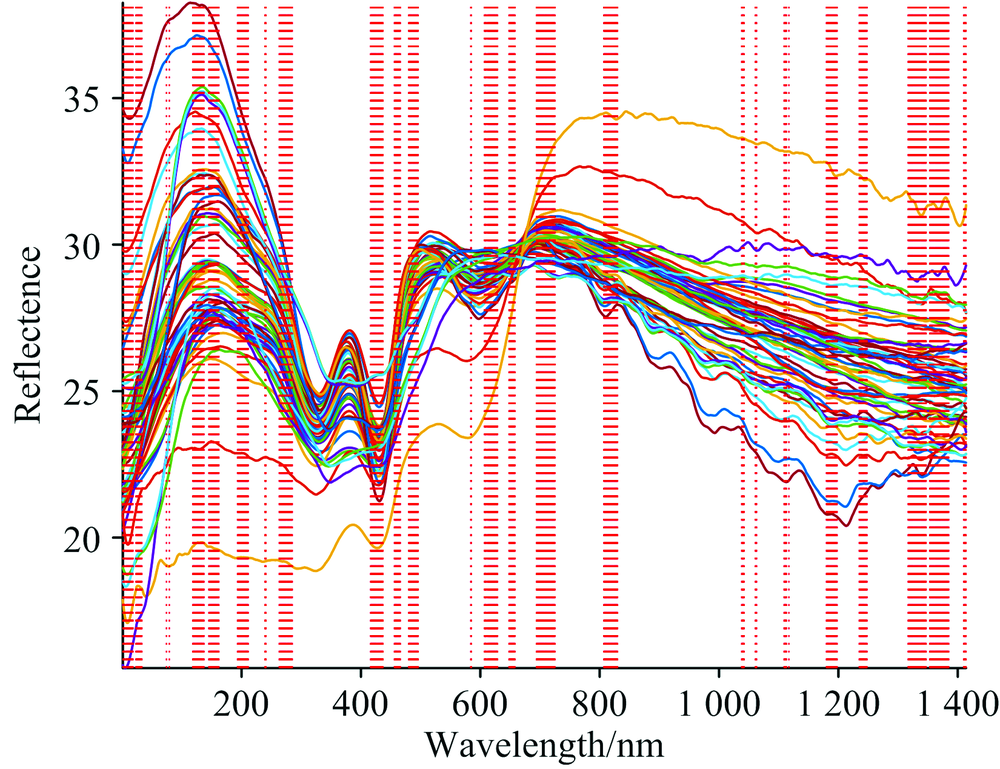 | 图7 OPS算法筛选的特征波长变量结果Fig.7 Results of characteristic wavelength variables screened by OPS algorithm |
2.3.2 AW-OPS选取特征波长变量结果
首先采用AW-OPS算法对全光谱数据筛选特征波长变量, 为节省数据运行时间, 全光谱数据采用指数衰减函数, 将指数衰减函数的迭代次数设置为50, 100, 150和200次, 得到结果如表1所示。
| 表1 不同迭代次数的运行结果 Table 1 Running results of different iterations |
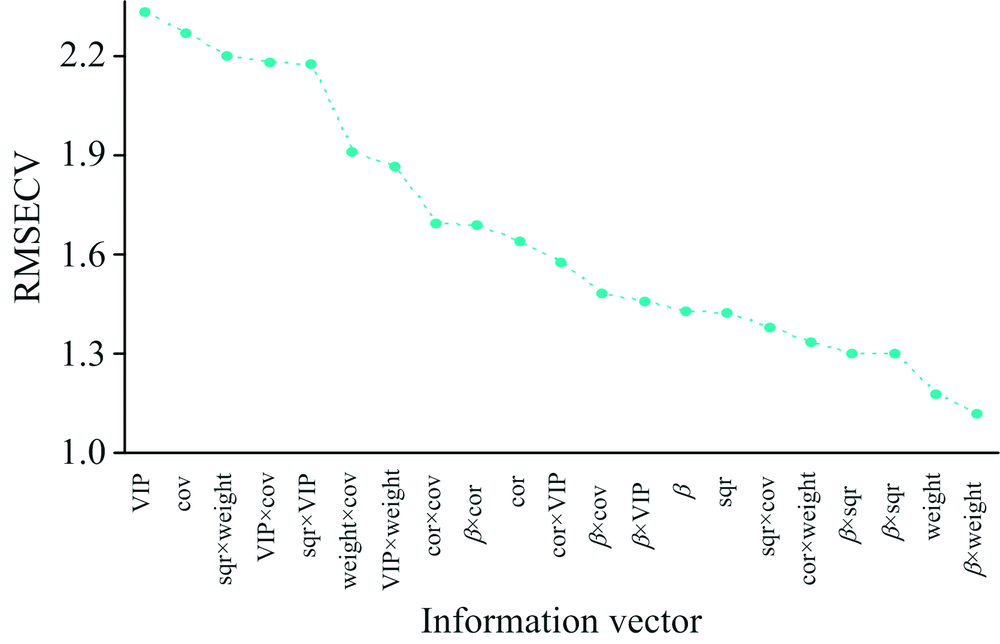
由表1可知, 当EDF设置为50次时, RMSECV值最小。 在该情况下构建多元回归模型, 采用AW-OPS算法后所有信息向量选取相对应的波长变量建立多元回归模型的RMSECV值的变化趋势如图8所示。
 | 图8 采用AW-OPS法后RMSECV的变化Fig.8 Changes of RMSECV after adopting AW-OPS method |
分析图8发现, RMSECV值进行降序排序, β × weight信息向量选出的波长变量所建立的多元回归模型的RMSECV值是最低值1.115 7, 为最佳信息向量, 证明该信息向量从全光谱波段中选取的有效性波长变量最多, 信息向量选取的相应变量为特征波长变量。 β × weight信息向量采用EDF后, 随着迭代次数的增加波长变量的变化如图9所示。
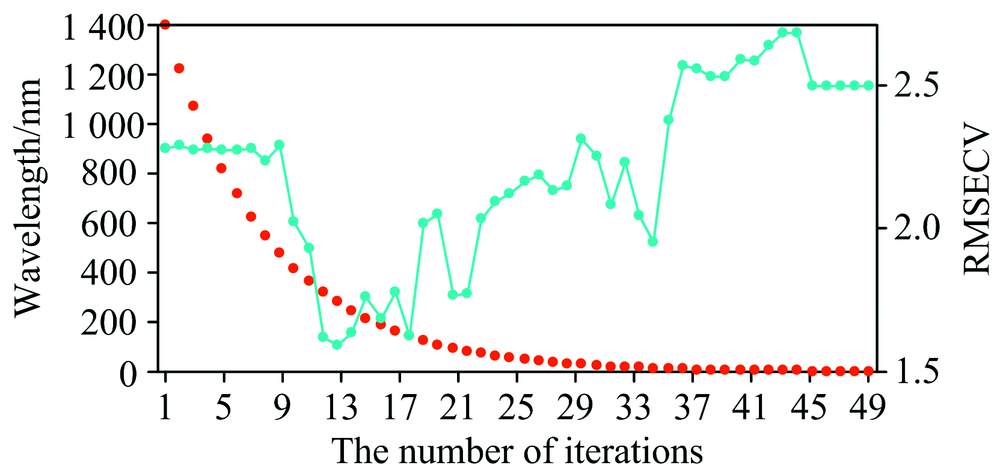 | 图9 β × weight向量采用EDF后波长变量和RMSECV的变化 黄线: 波长变量数; 蓝线: RMSECVFig.9 The changes of wavelength variables and RMSECV of β × weight vector after using EDF yellow line: Number of wavelength variables; blue line: RMSECV |
从图9可以看出, β × weight信息向量采用EDF后, 随着迭代次数的增加, 保留波长变量由全光谱1 414个波长点逐渐减少到2个波长, 经过多次迭代, 每次迭代都会删除信息向量绝对值比较低的波长变量, 保留重要性较高的变量。 当迭代次数为13时, RMSECV值最小, 波长变量为284个波长, 用这些波长建立多元回归模型。
采用最佳信息向量β × weight选取的特征波长变量结果如图10所示, 选取的特征波长变量数为275个。 与OPS法相比较, AW-OPS法选取的特征波长数目更少, 原因是OPS利用信息向量选取了建模效果较好的波长, 而AW-OPS能够使用信息向量和EDF相结合实现快速删除无效变量, 因此AW-OPS的选取特征波长优势更加明显。 选取的特征波段主要分布在422.2~434.1、 465.7~525.1、 573.5~600.1、 642.4~645.8、 669.3~714.1、 828.6~848.9和870.9~900.3 nm范围, 而550和580 nm附近是引起TVB-N值变化的血红蛋白的吸收波长, 表明AW-OPS选取的特征波长的光谱信息与冷鲜羊肉的TVB-N值具有相关性。
 | 图10 最佳信息向量选取波长变量的结果Fig.10 The result of selecting wavelength variable of optimal information vector |
OPS算法和AW-OPS算法的性能参数对比结果如表2所示。 AW-OPS算法的性能参数均优于OPS, 波长数由370降为275, 数据运行效率为57.63 s, RMSECV值也是三种特征波长算法中最小值, 大大节省了数据的运行时间, 提高了数据运行效率。
| 表2 不同波长变量方法的性能比较 Table 2 Performance comparison of different wavelength variable methods |
为比较3种不同特征波长构建PLS模型效果, 分别对OPS和AW-OPS选取的特征波长数据和理化值数据建立的PLS模型, 并与全波段光谱数据构建的PLS模型结果对比, 建立PLS模型效果如表3所示。
| 表3 不同波长变量方法的PLS模型效果 Table 3 PLS model effect of different wavelength variable methods |
经过表3结果分析, 3种不同的波长变量算法在提取特征波长后构建的PLS模型效果都要高于全光谱, AW-OPS算法PLS模型的相关系数R和均方根误差RMSE均优于OPS-PLS模型, 且效果最佳。 OPS-PLS模型的RP为0.963 1, RMSEP为0.727 0, 而AW-OPS-PLS模型RP提升到0.973 1, RMSEP下降到0.572 8, 提高了模型测试精度, 降低了模型误差。
利用高光谱技术获得羊肉样本在400~900 nm波段下的光谱数据, 提出将信息向量和指数衰减函数(EDF)相结合的有序预测选择法— — AW-OPS, 该算法主要通过EDF快速删减信息向量绝对值比较低的波长变量, 最终获得含有重要性光谱信息的波长变量。 在相同条件下对比OPS-PLS模型效果的影响, 同时与全波波段光谱数据的PLS模型相比较。 结果显示, AW-OPS-PLS的模型效果最佳。 AW-OPS算法从全波段数据中提取了关键波长, 简化模型的同时提高了模型测试精度, 降低了模型复杂度, 同时也节省了光谱数据的运行时间。 证明AW-OPS是一种有效特征波长变量筛选方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|