

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于改进的反向匹配的拉曼光谱识别方法研究
[薛文东1, *  , 陈本能
, 陈本能1 , 洪德明1 , 杨振海1 , 刘国坤2 ]
, 陈本能|
|


作者简介: 薛文东, 1982年生, 厦门大学航空航天学院助理教授 e-mail: xwd@xmu.edu.cn
针对传统的反向匹配方法中存在的强弱峰权重差异和噪声峰的干扰问题, 提出了改进式反向匹配方法, 通过引入权重衰减函数来优化强峰和弱峰之间的权重占比关系, 使得谱图中各特征峰的权重分布在合理的范围内, 避免了强峰权重掩盖弱峰的情况; 通过概率分布函数动态滤噪的方法, 实现了噪声峰的自适应过滤, 从而提升了反向匹配方法的识别性能。 实验以大量的常规拉曼和表面增强拉曼的谱图为验证样本, 基于大型常规拉曼与表面增强拉曼数据库进行拉曼谱图识别验证。 实验表明该方法在大量数据测试下综合准确率达到91.52%, 相比于命中质量指数方法(51.08%)和传统的反向匹配方法(16.57%)有大幅度的提升。
Aiming at the weight difference between strong and weak peaks and the interference of noise peaks in the traditional reverse matching method (RMM), an improved reverse matching method (IRMM) is proposed in this paper. In this method, the weight attenuation function is introduced to optimize the weight proportion relationship between the strong peak and the weak so that the weight of each feature peak in the spectrum is distributed in a reasonable range, which avoids the situation that the weight of the strong peak masks the weak. Moreover, this method realizes the adaptive filtering of noise peaks by the method of dynamic noise filtering of the probability distribution function, which improves the recognition performance of the reverse matching method. In the experiment, many conventional Raman and surface-enhanced Raman spectra were used as verification samples, which were identified and verified based on a large database of conventional Ramanand surface-enhanced Raman. Experiments show that this method (IRMM) has a comprehensive accuracy rate of 91.52% under a large amount of data testing, which is greatly improved compared to the hit quality index method (HQI, 51.08%) and the traditional reverse matching method (RMM, 16.57%).
拉曼光谱分析技术以其富含物质信息、 方便、 快捷和在线分析的特点被广泛应用于食品安全[1]、 环境检测[2]、 医药卫生[3]、 半导体工业[4]和石油化工[5]等领域。 作为一种光谱技术, 拉曼光谱对样品的检测是非破坏性和非侵入性的, 尤其是在常规拉曼的应用中, 几乎不需要特殊的样品制备技术, 即可对待测物质进行现场的检测和分析[6]。 但是现实生活中包含着庞大的物质种类, 很多不同物质的拉曼特征峰之间存在很多的相似之处, 这对谱图的识别增加了难度。 并且实际待测样品通常由多种物质组成, 导致拉曼谱图蕴含的信息往往耦合着大量且复杂的特征信号, 这进一步增加了识别难度。 因此如何有效地提取出拉曼谱图中的物质特征信息, 并实现快速准确的识别一直是拉曼检测技术的一个研究热点[7]。
目前拉曼光谱识别方法主要通过构建目标物质的拉曼谱图标准数据库或模型, 然后采用命中质量指数方法(HQI)[8]、 反向匹配方法(RMM)[9, 10]、 主成分分析方法[11]和深度学习方法[12, 13]等进行比对识别。 随着拉曼光谱仪的小型化和微型化, 拉曼光谱检测技术逐渐地从实验室走向民用的现场快速鉴别中, 其中HQI和RMM方法因算法稳定, 算力要求不高, 而被广泛地应用于手持式和便携式拉曼检测仪器中, 是目前主流的两种谱图识别算法。 HQI方法主要计算谱图间的整体相关性, 在纯物质的常规拉曼谱图检测中表现出较好识别能力, 但在表面增强拉曼和混合物的谱图识别中, 由于受到大量杂峰或信号增强等干扰因素, 检测效果不佳。 而RMM方法以标准谱图的谱峰为基准, 反向搜索待测谱图, 寻找相匹配的谱峰, 通过命中的谱峰权重计算相似度的大小, 这在一定程度上可以避免混合物中其他成分带来的信号干扰, 具有较强的抗干扰特性。 但是在RMM相似度的计算中, 谱峰权重通常以谱峰的强度来表示, 而强峰与弱峰之间可能会有数量级的差异, 从而导致弱峰权重可能完全被强峰掩盖, 容易出现误匹配。 并且RMM的识别效果还依赖于特征峰的准确筛选, 如果未能准确去除谱图中存在的大量噪声信号产生的干扰峰时会直接影响匹配结果的准确性。
本文针对传统的RMM方法中存在的问题提出一种改进式的反向匹配方法(IRMM), 针对以谱峰强度作为权重时可能出现的强峰和弱峰之间的数量级差异问题设计了一种特征峰权重衰减函数, 该模型可以根据命中的谱峰个数动态调整标准谱图中每个特征峰的权重, 使得特征峰之间的相对权重占比在合理的范围内; 并且, 针对谱峰中的噪声峰滤除, 本文设计了一种基于概率函数的动态滤噪方法, 该方法可以根据每张谱图噪声峰的正态分布情况, 自动计算出最优的滤噪阈值, 实现噪声峰的有效过滤。 本文主要从分析反向匹配方法存在的问题、 解决方案设计、 拉曼数据集和实验结果等几部分内容进行详细讨论。
反向匹配法是以纯物质的标准拉曼谱图数据库中的谱图为基准, 逐张去对比待测谱图的特征信息, 而不是用待测谱图去检索数据库, 其匹配流程如图1所示[10]。 首先待测样品和数据库中纯物质的拉曼谱图都需要经过数据预处理, 如滤波、 校正和基线扣除等; 然后通过寻峰算法[14]对谱图进行谱峰信息提取, 以获得各个谱峰的拉曼位移、 峰强或峰高等信息。 由于谱图中存在大量噪声, 导致获取的谱峰信息中可能含有噪声峰, 而噪声峰的存在会影响反向匹配方法的准确性, 通常以一个固定的峰强或峰高作为滤噪阈值, 将小于阈值的谱峰作为噪声滤除, 从而获得有效的特征峰信息; 紧接着用标谱数据库中第i张谱图的每个特征峰Ps(n)去比对待测谱图是否在对应位置存在特征峰P(n), 若存在则Ps(n)被标记为命中。 然后将标谱中所有命中的特征峰的峰强或峰高之和与标谱中所有特征峰的峰强或峰高之和求比值, 从而求得该标谱与待测谱图的相似度Ri。 遍历标谱数据库中所有谱图与待测谱图进行对比, 分别计算出相似度; 最后通过设定的阈值(如80%)将相似度大于阈值的物质标谱标记为匹配。
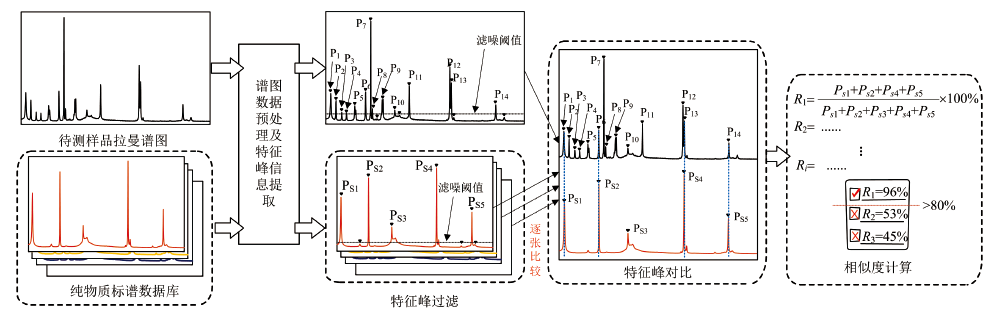 | 图1 反向匹配的基本流程图Fig.1 Basic flow diagram of RMM |
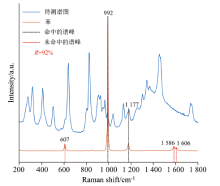
反向匹配方法以标准谱图数据为基础, 反向搜索待测谱图的谱峰数据, 这在很大程度上可以避免待测谱图中包含的其他物质的谱峰干扰。 但是, 强峰与弱峰的强度可能会有几个数量级的差异, 这将导致弱峰的权重可能被强峰完全掩盖, 容易造成误匹配。 如图2所示, 含乙酸异丁酯样品中误检出苯, 反向匹配计算出的相似度为92%, 强峰(992 cm-1)与弱峰(607, 1 586和1 606 cm-1)的强度存在数量级差异导致了弱峰权重被掩盖, 从而造成错误的匹配结果。 如果以匹配的谱峰数量为基数计算相似度, 又会过度增大弱峰的权重, 因为强峰基本不会消失, 而弱峰容易在采集中丢失, 从而容易造成漏匹配的问题。
 | 图2 含乙酸异丁酯样品中误检出苯Fig.2 Sample of isobutyl acetate mistakenly detected benzene |
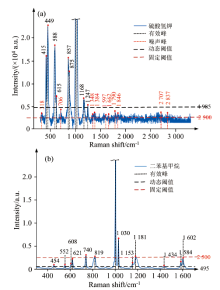
其次, 由于不同物质的拉曼散射效应差异很大, 可以通过样品处理、 调整谱图采集参数和使用滤波等方法来提高谱图质量, 其中控制采集谱图的积分时间是常用的一种方法[15]。 但是随着积分时间的增加, 谱图中噪声峰的强度也会随之增大。 反向匹配通常以一个固定的峰强或峰高作为滤噪阈值, 而这并不能精准地将噪声峰滤除, 甚至可能会滤除有效的特征峰。 如图3所示, 图3(a)和(b)分别为硫酸氢钾和二苯基甲烷的拉曼谱图, 受积分时间的影响, 二者的噪声幅度有较大的不同, 若以2 500为固定的滤噪阈值, 从图3(a)可以看出硫酸氢钾仍有大量噪声峰未被过滤, 而图3(b)二苯基甲烷却有部分有效特征峰被过滤, 由此可以看出用传统的反向匹配方法在噪声峰的过滤上存在较大的问题, 会直接影响匹配的准确性。
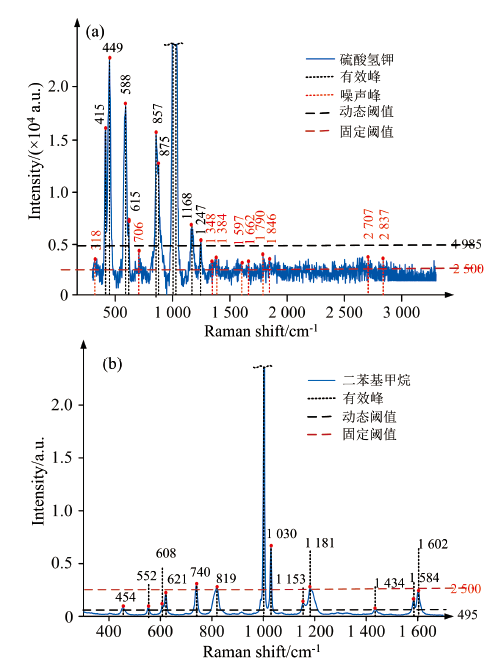 | 图3 不同噪声强度的谱图的滤噪情况 (a): 硫酸氢钾; (b): 二苯基甲烷Fig.3 Noise filtering effect of spectra under different noise intensities (a): Potassium bisulfate; (b): Diphenylmethane |
针对传统反向匹配方法中, 存在的强峰和弱峰的权重合理设置问题, 本研究提出了一种基于衰减函数的权重优化方法。 从反向匹配方法存在的问题分析中可以看出, 物质的强拉曼特征峰在采样中不容易消失, 而弱拉曼特征峰可能会因为样品浓度低或仪器灵敏度差等原因导致部分消失, 因此在待测样品的拉曼谱图的比对中如果物质的强特征峰不匹配, 则表示有很大的概率不含有该物质。 相比之下, 如果弱特征峰不存在, 则表示有相对较小的概率不含有该物质。 从这个角度分析, 在计算相似度的时候强特征峰的权重应该比弱特征峰高, 但是如果直接以峰强或峰高作为权重因子则有可能导致强弱峰的权重相差太大, 此时比对结果基本由强特征峰决定, 而弱特征峰的作用基本被忽略, 从而容易导致误匹配, 尤其是在物质的拉曼特征峰个数较少的情况下该表现更为明显。 为此, 需要对强峰进行衰减, 对弱峰进行适当增强, 使得强峰和弱峰的权重在可比的数量级范围内。 因此需要构造一个关于特征峰强度(或峰高)的权重曲线, 使得强峰权重能够得到抑制, 弱峰权重能够适当提高, 并且随着特征峰个数的变化加重或减轻对谱峰权重的影响效果。 为此, 本研究根据对数函数和指数函数的特征, 构造了一种谱峰的权重衰减函数[式(1)], 以实现特征峰的权重随强度和数量的变化而有效增强或衰减。
式(1)中, W为调整后的特征峰权重, S为特征峰的强度, Smax为特征峰中最大的强度, Nmatch为待测谱图和标准谱图相匹配的特征峰个数, λ 为在0~1.0之间的可调比例系数。
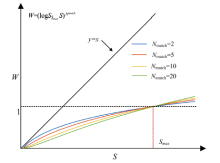
为验证该函数对特征峰权重的调节效果, 以匹配的特征峰个数Nmatch分别为2, 5, 10, 20为例, 权重衰减函数曲线如图4所示。 由于特征峰的强度S为大于1的数, 且Smax≥ S, 因此对数函数在以Smax底数和以S为真数值时, 为斜率小于1的增函数, 从而确保了谱峰的权重与谱峰强度(或高度)为衰减关系, 并且衰减后的权重W将被缩放到1内, 最大谱峰的权重始终为1, 起到了归一化的作用。 其次, 从图中单条曲线可以看出, 随着S的增加, 斜率逐渐由大变小, 从而实现了弱峰权重衰减较小, 强峰权重衰减较大的功能。 此外, 从多条曲线的趋势可以得出, 匹配峰个数较少时(Nmatch较小), 曲线的斜率变化较大, 即弱峰的权重衰减较缓和, 而强峰的权重衰减更严重。 这是因为当物质的匹配峰的个数较少时, 比较容易出现误判, 因此要提高弱峰的权重, 以确保很少的特征峰中, 弱峰的贡献不被忽略。
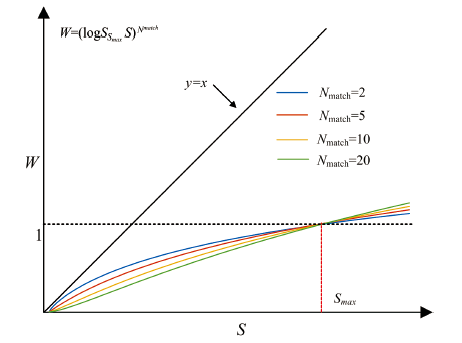 | 图4 不同谱峰命中个数的权重衰减函数曲线Fig.4 The function curves of weight for the different hit number of peaks |
经权重衰减函数处理后, 优化后的反向匹配的相似度计算公式如式(2)所示
式(2)中, Sj为标准谱图中各个特征峰的谱峰强度, N为标准谱图的特征峰个数, Si为标准谱图中与待测谱图相匹配的各个特征峰的谱峰强度, Nmatch为相匹配的特征峰个数, Smax为特征峰中最大谱峰强度, λ 为可调比例系数。
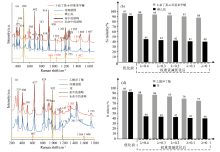
经过衰减函数优化后的反向匹配对比效果如图5(a)所示, 权重未优化前含3-叔丁基-4-羟基苯甲醚样品误匹配碘乙烷, 具有较高的匹配度(R=91%), 这是因为碘乙烷标谱中被匹配到的两个特征峰(499和1 201 cm-1)的信号掩盖了未被匹配上的弱峰信号, 从而导致误判。 而图5(b)为衰减函数优化后的结果, 当λ 取值不同时, 反向匹配中相似度的变化情况。 从图可以看出, 经过权重衰减优化后, 错误匹配的碘乙烷的相似度从原来的91%快速降到了40%附近, 而正确匹配的3-叔丁基-4-羟基苯甲醚相似度保持在80%以上。 这主要是因为误匹配的碘乙烷的相似度主要由强峰(499和1 201 cm-1)决定, 其他占比小的弱峰(950, 1 050和1 432 cm-1)都未被匹配, 当通过权重衰减函数调整后, 强峰的权重被减弱, 未匹配的弱峰权重增加, 使得弱峰对相似度的影响变大, 所以碘乙烷的相似度变化较大; 而正确匹配的3-叔丁基-4-羟基苯甲醚只有少数几个弱峰(526, 1 074和1 394 cm-1)没有被匹配, 所以即使弱峰权重被增强, 对相似度的影响也较小。 从图中还可以得出随着λ 值减少, 弱峰权重逐渐增加, 而谱图中未被匹配的都是弱峰, 所以相似度呈现下降趋势。 如图5(c)和(d)所示的含乙酸异丁酯误匹配到苯的情况与图5(a)和(b)相似, 经衰减函数处理后误匹配的苯的相似度快速下降。 实际匹配过程中, k的取值可根据匹配的谱峰个数进行动态调整, 使得衰减函数的效果达到最优。 引入权重衰减函数处理后的误匹配谱图的相似度出现了明显的降低, 而正确匹配的谱图变化较小, 说明该权重衰减函数能够有效实现强弱特征峰的权重平衡, 提高反向匹配方法的识别准确性。
 | 图5 衰减函数效果对比 (a): 权重优化前含3-叔丁基-4-羟基苯甲醚样品中误检出碘乙烷; (b): 权重优化前后含3-叔丁基-4-羟基苯甲醚样品误匹配碘乙烷相似度变化; (c): 权重优化前含乙酸异丁酯样品中误检出苯; (d) 权重优化前后含乙酸异丁酯样品误匹配苯相似度变化Fig.5 Comparison of different attenuation function effect (a): Sample of 3-tert-butyl-4-hydroxyanisole mistakenly detected iodoethane before weight optimization; (b): Similiarity change of sample of 3-tert-butyl-4-hydroxyanisole mistakenly detecting iodoethane while weight optimization; (c): Sample of isobutyl acetate mistakenly detected benzene before weight optimization; (d): Similarity changes of sample of isobutyl acetate mistakenly detected enzene while weight optimization |
针对反向匹配的特征峰过滤中, 采用固定阈值过滤噪声峰方法容易导致谱图特征峰提取错误的问题, 本文根据噪声基本满足正态概率分布的特征, 提出了动态阈值滤除噪声峰的方法, 以实现噪声峰的自适应过滤[16]。 由于谱图中的噪声分布是随机的, 所产生的噪声峰的强度会随着积分时间的改变而增强或减弱, 但其统计学分布基本都集中在一个区域内, 且呈现出正态分布的特征。 因此, 可以通过划定噪声峰强度分布的集中区域, 计算出用于过滤的阈值, 实现符合统计学分布的绝大部分噪声峰的过滤。 设计的动态阈值自适应滤除噪声峰方法的原理如图6所示, 首先对含有大量噪声峰的拉曼谱图数据[图6(a)]求一阶导数, 从而确定谱图中所有极大值点的位置[图6(b)]。 极大值点的位置表示可能含有的谱峰, 因此通过极大值点的位置反向搜索并计算出其在谱图中的对应的真实峰高h[图6(c)], 然后利用直方图对所有峰高进行统计, 再用正态分布函数对直方图进行拟合分析[图6(d)]。 由于绝大部分噪声的强度具有正态分布的特点, 并且噪声峰密集, 而特征峰数量相比于噪声峰很少, 因此将直方图正态分布拟合的谱峰密集的一定区域判定为噪声峰集中区, 而区域外的谱峰判定为特征峰。 最后根据划分的区域边界, 确定动态滤噪的阈值, 实现在不同等级噪声强度下的自适应滤噪。
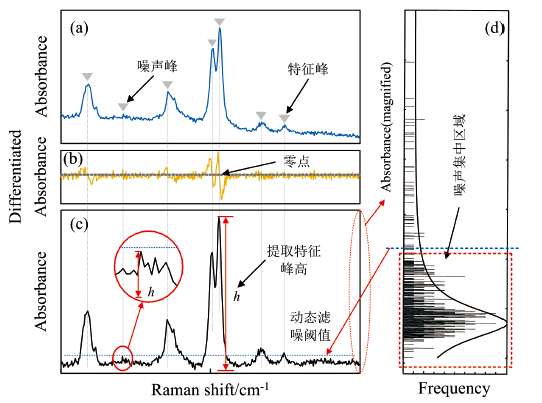 | 图6 动态阈值自适应滤噪方法实现原理 (a): 原始拉曼谱图; (b): 一阶导数谱; (c): 基线扣除后的谱图; (d): 对扣除基线后的峰高进行直方图统计和分布拟合Fig.6 Implementation principle of dynamic threshold adaptive noise filtering method (a): Original Raman spectra; (b): Spectrum after first-order derivative; (c): Spectrum after baseline subtraction; (d): Histogram statistics and fitting for peaks height after baseline subtraction |
为验证动态阈值滤噪的效果, 对图3的两份谱图数据进行基线扣除[17]等预处理后, 进行动态自适应滤噪, 将所有谱峰进行直方图统计和正态分布拟合后, 设定拟合区域的95%面积左右为噪声集中区域, 从而计算出图3(a)的动态滤噪阈值为4 985, 图3(b)为494。 由结果可知, 图3(a)的噪声峰很强, 导致固定的峰高阈值未能将较强的噪声峰滤除, 而采用动态峰高阈值的操作能准确将噪声峰滤除从而保留有效的特征峰信息; 相比之下, 图3(b)的噪声强度较弱, 部分特征峰也较弱, 固定阈值时容易将这些弱特征峰错误地滤除, 而采用动态阈值的方法, 滤噪阈值随噪声强度而变化, 自动调整下来, 从而保证噪声过滤的同时能将弱特征峰有效地保留下来。
数据库: 本研究构造的常规拉曼(NRS)谱图标准数据库和表面增强拉曼(SERS)标准数据库共含有2 927种纯化合物的拉曼光谱, 这些化合物主要是常用的原料, 共包含2 616张常规拉曼谱图和1 384张表面增强拉曼谱图, 常规拉曼谱图采集自2 610种纯物质, 而表面增强拉曼谱图采集自317种纯物质(支持信息表S1)。 该数据库主要是利用B& W TEK公司的i-Raman Plus高端拉曼光谱仪采集建立的, 激发的激光波长为785 nm。
测试集: 测试集主要包含两部分数据, 一部分为实验室制作的在常见的酒水饮料中单独添加不同浓度的苯二氮卓类和毒品类药物组成的混合物样品所采集的表面增强拉曼谱图, 该部分数据使用OPTOSKY公司的手持式拉曼光谱仪ATR6500采集, 在支持信息表S2中列出了具体的物质组成情况。 另外一部分为收集自不同厂家的5种便携式拉曼光谱仪所采集的195种物质的507张拉曼谱图, 这些厂家为B& W TEK, OCEANHOOD, OPTOSKY和MoBe。 由于常规拉曼谱图和表面增强拉曼谱图具有较大的差异性[18], 为测试改进的反向匹配方法的通用性, 该部分的测试集中包含了常规拉曼谱图和表面增强拉曼谱图。 其中, 包含137种物质的355张常规拉曼谱图和58种物质的152张表面增强拉曼谱图。 需要说明的是, 收集自不同仪器的待测谱图所使用的待测样品和光谱仪器均无相关性, 待测谱图均有标签注明对应样本实际含有的主要物质, 在支持信息表S3中汇总了相关信息。
首先, 将本文提出的改进的反向匹配方法与传统的反向匹配方法以及命中质量指数方法分别应用于实验室制作的混合物表面增强拉曼谱图的测试集(支持信息表S2)与数据库(支持信息表S1)的比对分析中, 验证各方法的识别准确性。 由于待测谱图和标准谱图来源于不同仪器, 因此在使用命中质量指数(HQI)的计算前进行了相对强度校准[19]。 各方法的相似度计算范围均为0~1.0, 本文将匹配阈值设置为0.8, 在与数据库中所有标准谱图的相似度比对中, 相似度大于等于阈值时为匹配, 小于阈值时为不匹配。 支持信息表S2中记录了命中质量指数(HQI)、 传统的反向匹配方法(RMM)和改进后的反向匹配方法(IRMM)对于常见的酒水饮料中单独添加不同浓度的苯二氮卓类和毒品类药物组成的混合物样品所采集的拉曼谱图在数据库中的匹配情况, 其中部分物质的识别结果如表1所示。 由表1所示部分物质的识别结果可知, HQI在纯物质的识别中具有较好的匹配效果, 而对于混合物的识别, 由于无法排除其他物质的拉曼信号干扰, 因此无法给出可靠的识别结果。 而RMM方法容易出现多匹配, 即匹配结果中包含正确匹配的物质和误匹配的物质。 相比之下, IRMM方法可以很好地识别混合物中的成分, 可以准确地排除传统的RMM方法中误匹配的物质。
| 表1 支持信息表S2中部分物质(SERS)的匹配结果 Table 1 Matching results of some substances (SERS) in supporting information (S2) |
根据表1中的匹配结果存在的准确匹配和多匹配的情况, 将准确识别的结果定义为SCIR, 对存在多匹配的结果定义为MCIR, 对其余结果即无匹配或错误匹配情况定义为NIR[20], 则对支持信息表S2识别的统计结果如表2所示。 由表2中的汇总结果可知, HQI在混合物的表面增强拉曼谱图识别中准确识别率仅有14.81%, 这是由于混合物的拉曼谱图由多种物质的谱峰信号叠加组成, 在HQI的计算中存在较大的干扰。 而RMM方法以标准谱图的谱峰为基准反向搜索待测谱图, 这在一定程度上避免了其他物质的拉曼信号干扰, 识别准确率达到44.44%, 但多匹配情况较为严重, 达到55.56%。 而IRMM方法的准确率高达96.30%, 多匹配情况基本没有, 识别准确率大幅提升。
| 表2 支持信息表S2识别结果统计 Table 2 The statistics of matching results of S2 |
为了进一步验证本文提出的改进IRMM算法的识别性能, 进行了大量的常规拉曼和表面增强拉曼样本数据的匹配测试, 将三种识别方法分别应用于收集自不同仪器的待测谱图(支持信息表S3)的比对分析中, 验证各方法对于实际样本的识别效果。 由于支持信息表S3包含的样本数据量很大, 因此实验数据的统计结果中未列出多匹配中错误匹配的物质名称, 只统计待测谱图是否正确匹配物质和是否存在多匹配情况, 实验的具体结果见支持信息表S3, 统计结果如表3所示。
| 表3 支持信息表S3识别结果统计(单位: %) Table 3 The statistics of matching results of S3 (Unit: %) |
首先, 由表3的统计结果可知, 基于标准谱图数据库的应用中, IRMM方法对常规拉曼和表面增强拉曼谱图的识别准确率(SCIR)分别为90.14%和94.74%, 说明该方法不仅在常规拉曼谱图的识别中表现良好, 而且对表面增强拉曼的识别同样有效, 并且相比于RMM方法和HQI方法的识别准确率均有大幅度的提升。 而HQI方法在常规拉曼(60.56%)和表面增强拉曼(28.95%)谱图的识别中有较大的差异。 传统的RMM方法在常规拉曼谱图的识别中准确识别的概率只有4.79%, 而多匹配的情况非常严重, 占94.37%。 这主要是由于常规拉曼标准谱图数据库中的标准物质数量有上千种, 并且很多物质特征峰比较尖锐, 存在大量的特征峰重叠问题, 使得匹配的准确度急剧下降到4.79%, 而在表面增强拉曼的标准数据库谱图数量较少, 多匹配的情况为55.92%。 相比之下, 本文提出的IRMM方法在常规拉曼和表面增强拉曼中多匹配的问题有较大的改善, 仅为7.89%和5.26%, 并且综合匹配结果的准确性从16.57%提升到了91.52%, 因此匹配的准确度有大幅度的提升。
从传统的反向匹配方法存在的特征峰权重和噪声峰过滤问题入手, 提出了改进式的反向匹配方法, 通过引入权重衰减函数来优化强峰和弱峰之间的权重占比关系, 使得谱图中各特征峰的权重分布在合理的范围内, 避免了强峰权重掩盖弱峰的情况; 通过概率分布函数动态滤噪的方法, 实现了噪声峰的自适应过滤, 从而提升了反向匹配方法的识别性能。 实验将该方法与HQI和传统的反向匹配方法进行了对比分析, 以常规拉曼和表面增强拉曼的大量样本数据为实验数据进行匹配的准确性能测试, 实验表明该方法在大量数据测试下综合准确率达到91.52%, 相比于HQI方法(51.08%)和传统的反向匹配方法(16.57%)有大幅度的提升, 并且能有效地降低RMM方法中存在的多匹配问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|