



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
降维降噪处理对番茄早疫病潜育期高光谱识别效果的影响
[胡政1  , 张艳
, 张艳1, 2, * ]
, 张艳]
|
|


作者简介: 胡 政, 1996年生, 贵州大学大数据与信息工程学院硕士研究生 e-mail: 1778347059@qq.com
番茄早疫病感染性强、 破坏性大, 潜育期症前特征的检测识别是番茄早疫病监测预警和科学防治的关键。 在实验室以离体番茄叶片作为研究对象, 利用高光谱图像监测番茄叶片早疫病的病程演变情况, 结合可见光图像和光谱特征进行数据分析。 实验发现, 番茄叶片感染早疫病后其近红外光谱平均值和红边反射率随着时间不断降低, 且在接种36 h时已出现潜育期病症信息。 选择接种36 h的光谱数据作为番茄早疫病潜育期的建模数据, 分别利用了主成分(PCA)变换、 多元散射校正(MSC)对建模数据进行光谱降维或降噪处理, 进而建立梯度提升决策树(GBDT)和支持向量机(SVM)识别模型, 并导入数据进行训练识别。 讨论了PCA和MSC的预处理方法对梯度提升决策树(GBDT)和支持向量机(SVM) 模型识别效果的影响; 进一步讨论常见核函数对SVM识别模型的影响, 优选出预处理方法和识别模型的组合算法。 结果发现, PCA-GBDT、 PCA-SVM(高斯核)、 PCA-SVM(线性核)、 MSC-GBDT、 MSC-SVM(多项式核)这几类组合算法准确率均为95%以上, 能很好的实现番茄早疫病潜育期的光谱识别; 其中MSC-GBDT的识别召回率和准确率最好, 而PCA-SVM(高斯核)识别效率最高。 研究表明, 通过降噪处理后的番茄早疫病潜育期高光谱数据减少了噪声、 更加符合真实的分布、 具有较大的可信数据量, 配合简单的识别模型会导致识别能力不足, 而配合复杂的识别模型可达到一个较可靠的测试结果; 通过降维算法能使番茄早疫病潜育期高光谱数据的维度降低、 数据量减少; 降维后的特征能够表达出病变信息, 配合简单识别模型时识别效果好, 而配合过于复杂的识别模型会导致识别模型的过拟合。
Tomato early blight is highly infectious and destructive. The detection and identification of pre-symptom characteristics in the incubation period is the key to Tomato Early Blight monitoring, early warning and scientific control. In this paper, the evolution of early tomato blight was monitored by hyperspectral images, and the data were analyzed combined with visible light images and spectral characteristics. The results showed that the average value of near-infrared spectrum and red edge reflectance of tomatoes infected with early blight decreased with time, and the disease information of the incubation period appeared 36 hours after inoculation. This paper selected the spectral data of 36 h inoculation as the modeling data of Tomato Early Blight incubation period. The principal component (PCA) transformation and multivariate scattering correction (MSC) were used to reduce the spectral dimension or noise of the modeling data. Then the gradient lifting decision tree (GBDT) and support vector machine (SVM) recognition models were established, and the data were imported for training and recognition. The influence of PCA and MSC preprocessing methods on the recognition effect of gradient lifting decision tree (GBDT) and support vector machine (SVM) models is discussed. The influence of common kernel functions on SVM recognition models is further discussed, and the combination algorithm of preprocessing method and recognition model is optimized. The results showed that the accuracy of PCA-GBDT, PCA-SVM (Gaussian kernel), PCA-SVM (linear kernel), MSC-GBDT and MSC-SVM (polynomial kernel) was more than 95%, which could well realize the spectral recognition of Tomato Early Blight incubation period; Among them, MSC-GBDT has the best recognition recall and accuracy, while PCA-SVM (Gaussian kernel) has the highest recognition efficiency. The research shows that the hyperspectral data of the Tomato Early Blight incubation period after noise reduction reduces the noise is more in line with the real distribution, and has a large amount of data. The recognition ability will be insufficient, while combined with a complex recognition model, a higher test result can be achieved; The dimension reduction algorithm can reduce the dimension and amount of hyperspectral data in the incubation period of early tomato blight, and the features after dimension reduction can express the lesion information. When combined with a simple recognition model, the recognition effect is good, while with an overly complex recognition model, it will lead to over fitting the recognition model.
番茄植株适应力强、 易于种植, 是全世界产量最高的30种作物之一[1]。 在番茄的生长过程中容易遭到早疫病、 灰霉病、 晚疫病、 叶霉病等病害的胁迫, 其中番茄早疫病是危害最严重的病害, 该病主要在开花期发病, 结果期发病严重, 严重影响了产量和品质。 潜育期症前特征的检测识别是番茄早疫病监测预警和科学防治的关键。
通常对番茄早疫病的识别是人眼直接观察或利用显微技术进行病原鉴定。 传统识别方法经验性强、 灵敏度低、 费时费力, 难以实现快速灵敏检测。 近年来, 机器视觉[2, 3, 4]、 高光谱成像[5, 6, 7]、 红外热成像[8, 9]等成像技术以其无损、 快速的优点越来越多的应用于植物病害检测[11, 12]。 利用成像技术对番茄早疫病潜育期进行快速无损的检测, 具有重要的科学意义和广阔的应用前景。
鉴于作物病害潜育期症前特征的隐晦性以及高光谱图像数据特征的多维性, 对高光谱图像进行降噪或降维的预处理对作物病害潜育期症前特征的识别尤为重要。 为此, 以感染早疫病的番茄叶片作为检测对象, 研究降维降噪预处理对番茄早疫病潜育期的高光谱图像识别效果的影响。
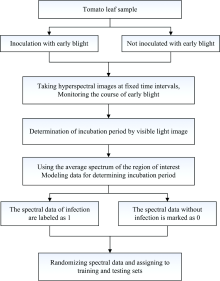
选取同一批番茄幼苗进行培育, 待幼苗生长至开花期, 选择离体叶片以刮伤涂抹菌液的方式涂抹早疫病菌(Alternaria solani), 利用高光谱成像系统以相同时间间隔(12 h)采集感染叶片和未感染叶片的高光谱图像, 利用温度湿度计监测实验温度和湿度条件, 确保实验室条件相对稳定。 通过连续动态监测接种后的番茄早疫病的病程演变情况, 结合可见光图像确定了本实验条件下番茄潜育期的时间范围(即接种病害直至出现人眼可明显识别病症的时间)为48 h; 再从潜育期图像中选出红边和平均光谱反射率变化明显的时间节点(36 h), 将该时间节点拍摄得到的高光谱图像作为识别模型的建模数据, 实验流程如图1所示。 其中, 在选择感兴趣区域时, 因为潜育期病害特征隐晦、 信息微弱, 所以感兴趣区选择不宜过大, 否则潜育期信息被大面积数据均衡化了, 本实验在接种点附近选择40× 40个像素点作为感兴趣区。
 | 图1 番茄早疫病高光谱数据集准备流程Fig.1 Preparation process of hyperspectral data set of tomato early blight |
鉴于实验可能存在接种失败的情况, 根据动态监测接种感染情况进行分类标注, 把其中最终出现病斑的样本图像标注为1, 而最终未出现病斑的样本图像标注为0, 随机打乱后按7∶ 3比例划分识别模型的训练集和测试集, 识别流程如图2所示。
 | 图2 番茄早疫病潜育期光谱数据处理与识别流程Fig.2 Spectral data processing and identification process of tomato early blight incubation period |
从图2所示, 在确定高光谱数据的训练集和测试集后, 对数据集分别进行PCA降维处理和MSC降噪处理, 再建立GBDT识别模型和SVM识别模型。 利用准确率、 召回率和识别时间作为识别模型的评价指标, 分别比较PCA降维处理和MSC降噪处理对SVM模型和GBDT模型的识别结果, 并讨论不同核函数对支持向量机识别效果的影响, 以期提升识别效果、 优化识别模型, 从而优选出预处理方法和识别模型的组合算法。
高光谱成像是利用光源照射放置在电控移动平台上的样品, 并通过光谱相机捕获样品的反射光, 伴随着电控移动平台带动样品运行, 最终获得具有图像信息和光谱信息的三维数据立方。 采集番茄叶片高光谱图像时, 为保证图像清晰不失真, 尽量减少干扰, 需在采集前打开系统电源预热两分钟左右并调整系统采集参数, 经预实验确定曝光时间约为15 ms、 采集速度为1 cm· s-1、 采集距离为15 cm, 实验时将样本放置在电控平移台上, 利用光谱仪对检测样本进行采集。
高光谱成像系统采集的光谱主要取决于光源的光谱、 强度、 光谱仪的衍射率和被测物的反射率等, 为避免拍摄环境的影响, 可利用式(1)对采集的原始数据进行校正
式(1)中, S为原始样品的反射率, D为背景的反射率, W为白板的反射率。
当番茄叶片遭到早疫病胁迫时, 其叶肉组织遭到破坏、 叶绿素和水分丢失, 从而引起叶片表面产生枯萎和变黄等现象。 病害潜育期是指从病菌侵入寄主后建立寄生关系起, 到出现明显的病变特征的这一时期[13]。 本实验利用可见光图像和感兴趣区灰度直方图为参照, 结合病症演变过程, 从而判定番茄早疫病潜育期的时间节点。 图3是番茄叶片感染早疫病后不同时间节点的可见光图像和感兴趣区域灰度直方图的情况。
 | 图3 番茄叶片早疫病可见光图像特征的演变Fig.3 Evolution of visible light image characteristics of tomato leaf early blight |
可见光图像可以记录人眼观察的效果, 灰度直方图能客观反映感兴趣区灰度图中的像素的统计分布, 揭示早期病症的灰度特点。 在本实验中, 番茄叶片接种后, 直到48 h才从可见光图像和感兴趣区域灰度直方图看到叶片表面出现病变特征, 因此接种后0~48 h都属于番茄早疫病的潜育期。 值得注意的是, 接种48 h后的叶片, 发现叶片的中心接种区域出现黑色病斑, 周围伴随着离散的黑色小点; 在接种60 h后可观察出病斑沿着叶脉方向进行扩散, 黑色小点向周围呈现圆形扩张; 在接种48 h后, 感兴趣区域灰度直方图显示, 低亮度区(亮度范围为0~50)的像素逐渐增多, 最高亮度值的像素数持续显著减少, 最大值从140降低到80到120。
通常人眼只看到400~700 nm波段的可见光, 该波段可直接反映出作物表面的可见光特征如枯黄、 损伤等。 本实验用的高光谱仪的工作波段为400~1 000 nm, 其中700~1 000 nm是人眼无法直接观测到的波段, 该波段能够反映出作物更深层次的生理特征, 如作物的蛋白质、 水分含量、 叶肉细胞的变化等[14]。 为动态监测感染番茄早疫病的叶片高光谱数据随时间的变化情况, 每隔12 h对100个染病样本进行拍摄, 对每一次拍摄得到的高光谱图像进行校正后, 选取图像中接种点附近的40× 40个像素点作为感兴趣区域, 并计算每次拍摄得到的所有样本的平均光谱, 计算公式如式(2)和式(3)
式中, Ma为感兴趣区域的平均光谱, Si为感兴趣区域的第i个像素点的光谱数据, N为像素点的总数为1 600; Mp为每次拍摄得到的所有样本平均光谱, T为每一次拍摄样本的总数为100。
将前5次拍摄的所有样本平均光谱进而对比12~60 h内的光谱变化情况, 如图4所示。
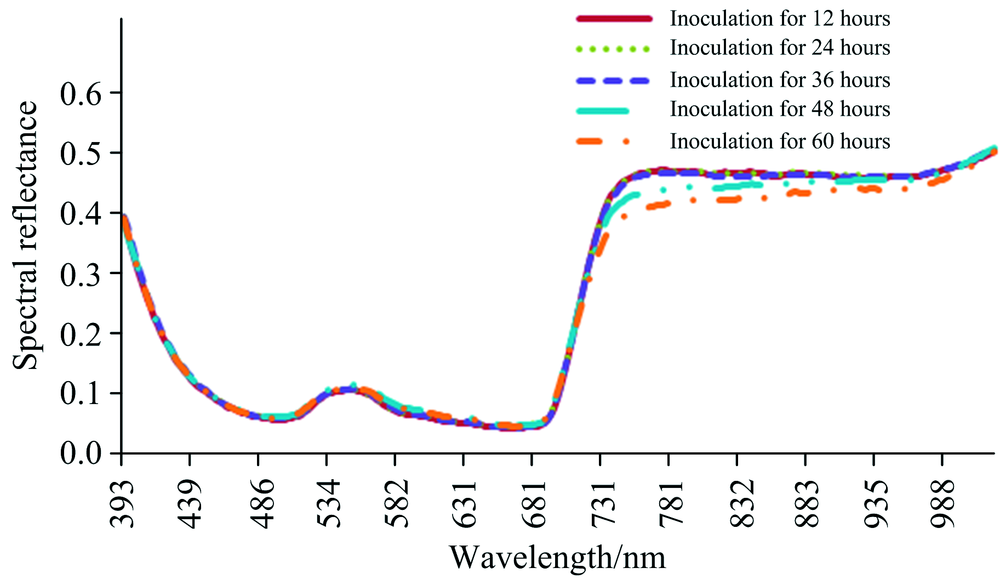 | 图4 番茄早疫病光谱变化曲线Fig.4 Spectra of diseased tomato leaves (early blight) |
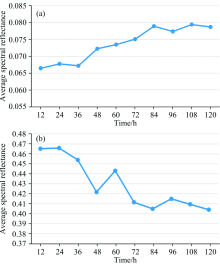
从图4中可看出所有样品的光谱反射率具有相同的变化趋势, 光谱曲线的反射峰发生在550 nm附近, 反射低谷在680 nm附近; 同时发现在可见光波段范围内的550~700 nm和近红外波段范围内的750~900 nm均发生较明显的变化, 因此对该波段的光谱反射率求平均后, 观察其平均值在12~120 h内的分布情况, 如图5所示。
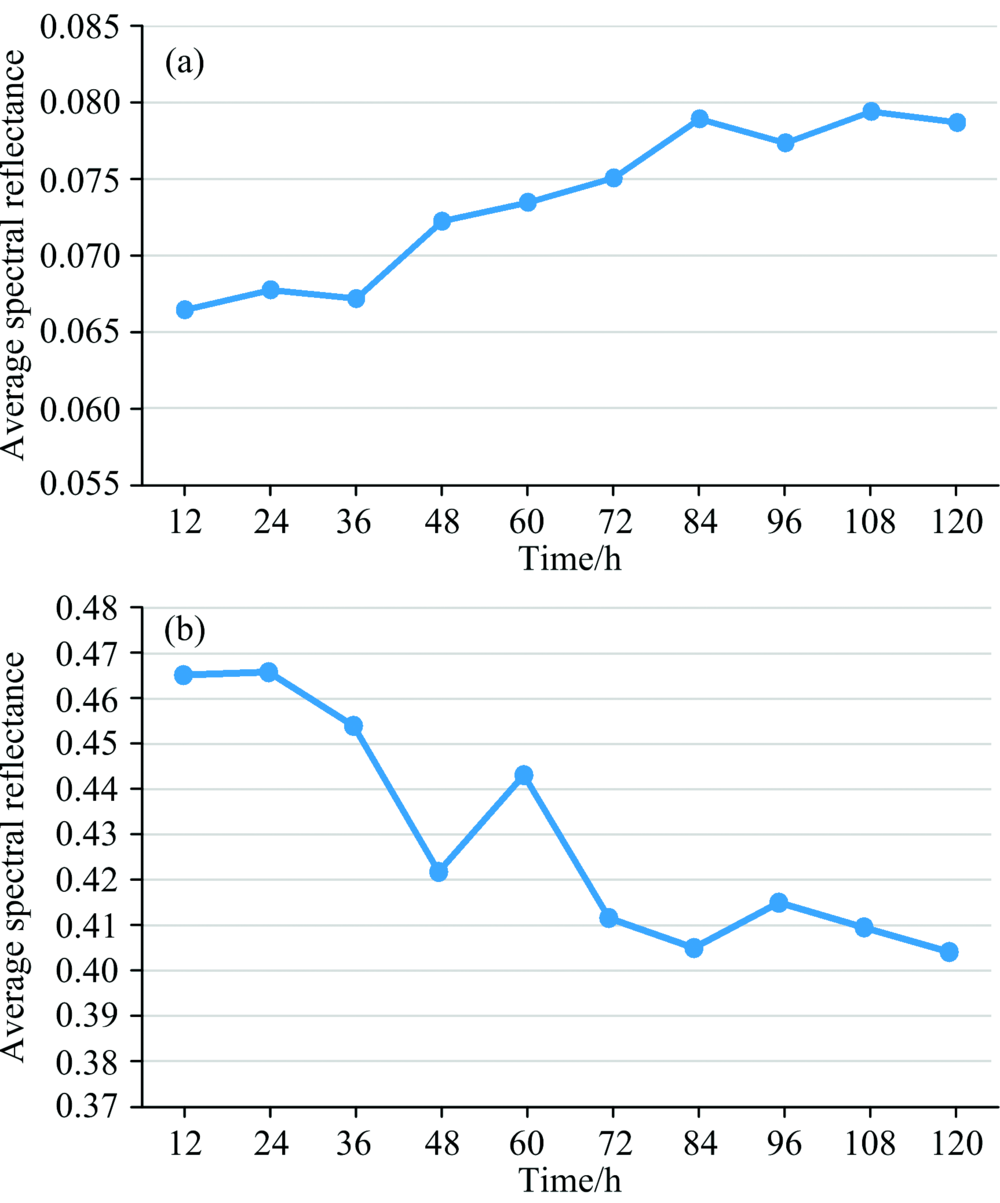 | 图5 光谱平均反射率随时间的变化关系 (a): 550~700 nm; (b): 750~900 nmFig.5 Variation of spectral average reflectance with time (a): 550~700 nm; (b): 750~900 nm |
从图5(a)中可以看出550~700 nm接种早疫病叶片的光谱平均反射率随着时间的变化逐渐升高, 产生这种变化的原因是病害后番茄叶片的自我保护机能得到激发, 促使叶片内部的叶绿素、 类胡萝卜素发生变化; 从图5(b)中可以看出750~900 nm接种早疫病叶片的光谱平均反射率随着时间的变化逐渐降低, 产生这种变化的原因是, 病害出现会使得叶肉组织遭到破坏, 蛋白质和水分丢失。
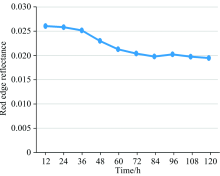
红边是绿色植物在670~760 nm之间反射率增高最快的点, 红边的反射率变化能反映出番茄叶片的活性变化[15], 如图6所示。
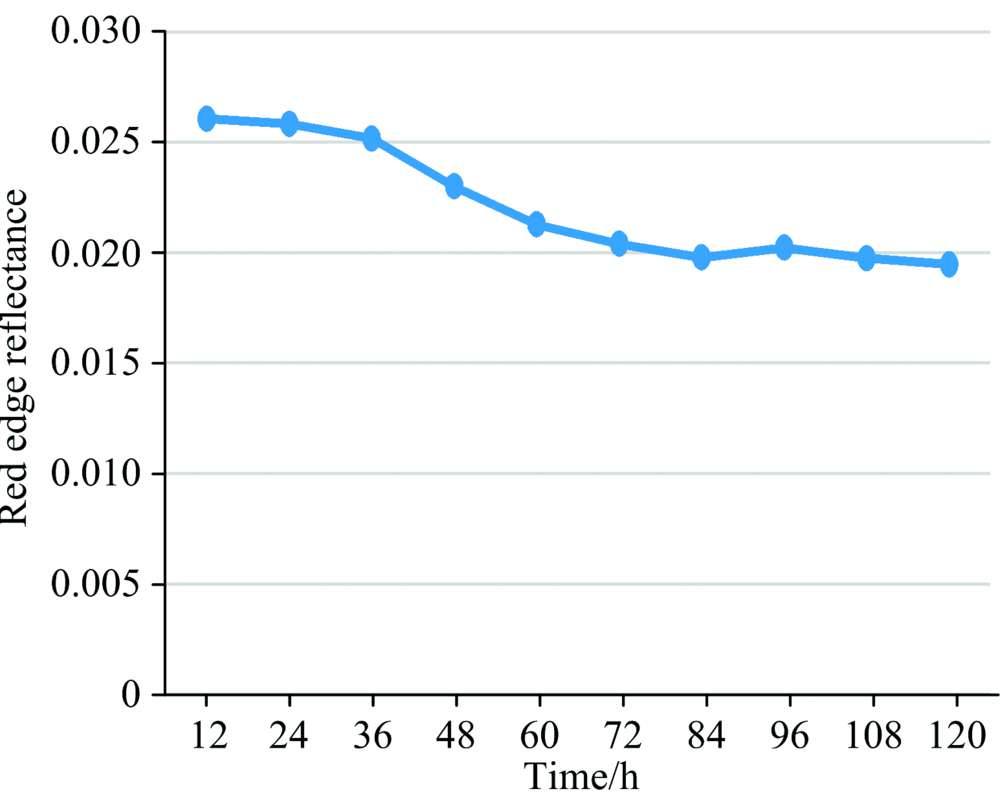 | 图6 红边反射率随时间的变化关系Fig.6 Variation of red edge reflectance with time |
由图6可知红边反射率随着时间降低, 在36~72 h变化较快, 72 h后变化平缓。 且在潜育期0~48 h范围内, 其图5(b)和图6中的36 h时可看出曲线发生明显下降现象, 说明了近红外光谱平均反射率和红边可以反映出番茄早疫病潜育期的病变信息; 因此, 将36 h拍摄得到的高光谱数据作为模型训练、 测试的番茄早疫病潜育期的数据。
高光谱数据的维度多, 且维度之间存在较高的冗余和噪声。 对光谱的预处理有以下三种方法: 第一种是降维处理, 通常选择PCA算法去除冗余, 增加特征的表达能力, 但一味降低维度会使信息丢失; 第二种是降噪处理, 通常选择MSC算法, 提高高光谱数据的信噪比, 但容易导致微弱且有用的信息丢失; 第三种是既降维又降噪处理, 能极大减少数据量, 但针对番茄早疫病潜育期的微弱病害光谱信息, 会使病害信息大量丢失, 导致算法的识别率不高, 不适合对番茄早疫病潜育期的光谱数据进行处理; 因此, 本实验的预处理算法分别选择PCA降维和MSC降噪, 进行比较分析。
PCA目标是选择少于原始数据维度数量的单位正交基, 让原始番茄叶片高光谱数据变换到单位正交基上后, 协方差为0, 投影后方差尽可能大。 通过求协方差矩阵并将其相似对角化, 得到特征值特征向量, 并根据特征值从大到小将对应的特征向量排列, 用排列好的特征向量组成的矩阵乘以原始数据矩阵就得到降维后数据[16]。
番茄叶片接种早疫病和未接种早疫病在36 h时拍摄得到的高光谱数据均具有256个光谱维度, 通过主成分变换后保留98%的重要光谱信息, 维度降低到3维数据, 分别代表第一主成分(pc1)、 第二主成分(pc2)、 第三主成分(pc3), 绘制3维数据分布的三视图如图7所示。 其中, 五角星表示番茄叶片接种早疫病36 h并处于早疫病潜育的光谱数据经主成分变换后的分布, 圆点表示未接种早疫病的光谱数据经主成分变换后的分布。
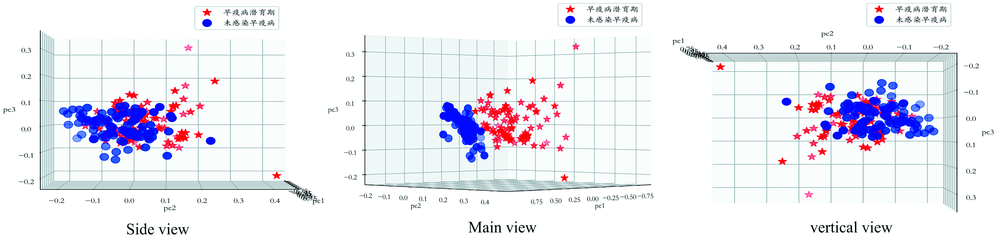 | 图7 PCA变换数据分布三视图Fig.7 Three views of PCA transformation data distribution |
由图7可见, 在三维空间接种和未接种区域的光谱数据是可分的, 说明通过算法模型识别具有可行性, 同时发现二者的部分数据点分布紧密, 光谱信息具有极大的相似性。
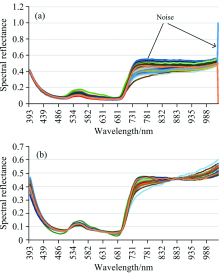
原始的光谱数据会因为番茄叶片的湿度、 颗粒度等差异使高光谱数据的基线偏移从而产生噪声[17], 如图8(a)所示。 通过MSC能够有效的消除番茄叶片的物理状态影响, 提高光谱数据的信噪比, 数学计算公式如式(4)和式(5)
式(4)和式(5)中Ai为每条光谱, mi为各光谱倾斜偏移量, A为输入原始光谱数据的平均光谱, bi为各光谱相对于平均光谱的线性平移量, Ai(MSC)为校正后的光谱数据。
 | 图8 光谱数据MSC预处理 (a): 原始光谱; (b): MSC处理后数据Fig.8 MSC preprocessing of spectral data (a): Original spectra; (b): MSC preprocessed spectra |
具体实现过程为: 首先计算输入原始光谱数据的平均光谱A, 然后每条光谱数据Ai和平均光谱A进行回归运算求得线性平移量bi和倾斜偏移量mi, 最后每条原始光谱Ai减去线性偏移量bi同时除以倾斜偏移量mi。 经过MSC预处理后的光谱数据如图8(b)所示。
从图8中可以看出, MSC处理后的光谱数据, 仍然保留原先的物理意义和光谱形状, 相对于原始光谱数据各个光谱数据之间的距离变小, 消除了噪声, 使得光谱数据更加符合真实的分布。
识别模型从构成上分为两类, 一类是由单一的分类器构成的识别模型, 如SVM、 逻辑回归、 BP神经网络等[18, 19, 20], 优点是结构简单、 数据处理速度较快, 缺点在于对于复杂的数据输入容易欠拟合、 准确率不高; 另一类是由多个分类器根据串、 并联的方式集成的识别模型, 如GBDT、 随机森林、 极限森林等[21, 22], 识别时需要综合考虑各个分类器的识别结果, 优点是对复杂的输入数据能够较好的识别、 具有较高的准确性和鲁棒性, 缺点是模型识别速度较慢、 容易过拟合。 本文选取的识别模型是以SVM为代表的单一的分类器构成的和以GBDT代表的多个分类器集成的识别模型。
SVM是一种线性分类模型, 对高光谱数据识别过程可分为训练和测试阶段, 训练阶段是通过求解方程(6), 得到最大决策边界L。
式(6)中: w, b, C是待求参数, X是输入光谱矩阵, y是输入标签。
求解过程是通过Karush-Kuhn-Tucker (KKT)条件, 将带不等式的优化问题转换成带等式的优化问题, 然后利用泰勒公式转换成不带条件的优化问题, 最后利用其强对偶的关系求解出最大的决策边界。 预测阶段, 利用训练阶段求解出的决策边界将输入番茄光谱数据划分为1(番茄叶片早疫病潜育期)和0(未感染早疫病)类。
对于线性不可分的数据, SVM可以通过核函数变换来实现分类, 常用的核函数有线性核函数、 多项式核函数、 高斯核函数。 其中多项式和高斯核函数对于低维线性不可分的数据是通过将数据转换到高维进行划分、 应用最广泛的就是高斯核函数, 无论是小样本还是大样本、 高维或者低维。
GBDT算法是一种集成算法, 其思想是通过组合多个分类效果不好的弱分类器形成一个分类效果好、 鲁棒性强的强分类器[23]。 集成分类算法往往运算量大, 而决策树分类算法运算简单, 可以人为控制算法的强弱(决策树的深度), 因此GBDT选择决策树作为弱分类算法进行集成。 模型进行训练时具体步骤为:
(1)计算初始值
(2)通过
(3)通过残差r寻找决策树最小均方误差(MSE)分裂点;
(4)跟据分裂点和残差公式计算负梯度
(5)更新F0(X)为F1(X)=F0(X)+rmj;
(6)等遍历完所有决策树时, 终止循环此时得到的残差最小, 否则继续执行(2)— (6)。
通过上速步骤能看出GBDT是一个串行的集成训练分类器, 通过计算当前模型损失函数的负梯度值去训练新加入的分类器, 然后将训练好的分类器以累加的形式结合到现有模型中, 能很好的降低模型的欠拟合。
3.3.1 基于MSC和PCA的模型识别
针对番茄早疫病潜育期病害, 从接种36 h和不接种早疫病的番茄叶片高光谱图像中各抽取100幅图像, 提取所有图像中番茄叶片接种点附近40× 40的像素点的平均光谱, 总共200条光谱数据, 随机打乱后, 以7∶ 3的比例分为训练数据和测试数据。 将原始光谱数据经MSC预处理后分别作为线性核、 多项式核、 高斯核等不同核函数情况下SVM和GBDT模型的输入, 为保证模型结果的稳定性以识别100次后的平均值做为模型的最终结果, 识别结果如表1所示。
| 表1 基于MSC降噪处理的SVM和GBDT模型识别结果 Table 1 Recognition results of SVM and GBDT models based on MSC noise reduction |
从表1中发现GBDT识别模型相比SVM识别模型, 其在训练集和测试集上的准确率和召回率均最好, 分别为100%, 100%, 99%和97%, 同时发现SVM(高斯核函数)在训练集和测试集上的召回率和准确率都过低, 分别为74%, 49%, 70%和45%, 出现严重的欠拟合现象, 说明通过降噪处理后的番茄叶片高光谱数据依然具有较大的数据量, 识别模型过于简单会导致识别能力不足, 但配合复杂的识别模型可达到一个较高的测试结果。
通过PCA变换能够去除番茄叶片高光谱图像中波段间的相关性, 提升特征的表达能力, 降低输入数据的数据量。 模型的输入数据采用与基于MSC预处理的模型识别的同一批数据并进行同样选择与划分, 进行PCA变换, 将变换后得分超过98%的主成分特征向量作为模型的输入, 同样为保证模型结果的稳定性以重复识别100次后的平均值做为模型的最终结果, 识别结果如表2所示。
| 表2 基于PCA降维处理的SVM和GBDT识别模型结果 Table 2 Results of SVM and GBDT recognition models based on PCA dimensionality reduction |
从表2中可以看出, SVM模型相比于GBDT模型的过拟合现象弱, 这是由于降维算法能使得输入数据的维度低, 数据量小, 配合简单识别模型SVM时, 识别效果好, 但配合复杂模型GBDT时模型往往出现较严重的过拟合现象; SVM(高斯核)在测试集上的准确率最好为97%, 但GBDT的召回率要高于SVM的召回率, 其在测试集上的召回率为97%。
3.3.2 综合比较与分析
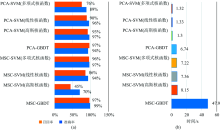
模型的评估选择准确率、 召回率和模型识别时间, 通过准确率可以衡量识别模型判别正负样本能力情况, 正确率越大, 判别出正确的正负样本的个数就越多, 反之越少; 通过召回率可以衡量判别出感染番茄早疫病叶片在判别正确的样本中占比情况, 占比越大判别出真正感染番茄早疫病叶片越多, 反之越少; 最后结合模型识别时间可以衡量模型识别的效率, 如图9所示。
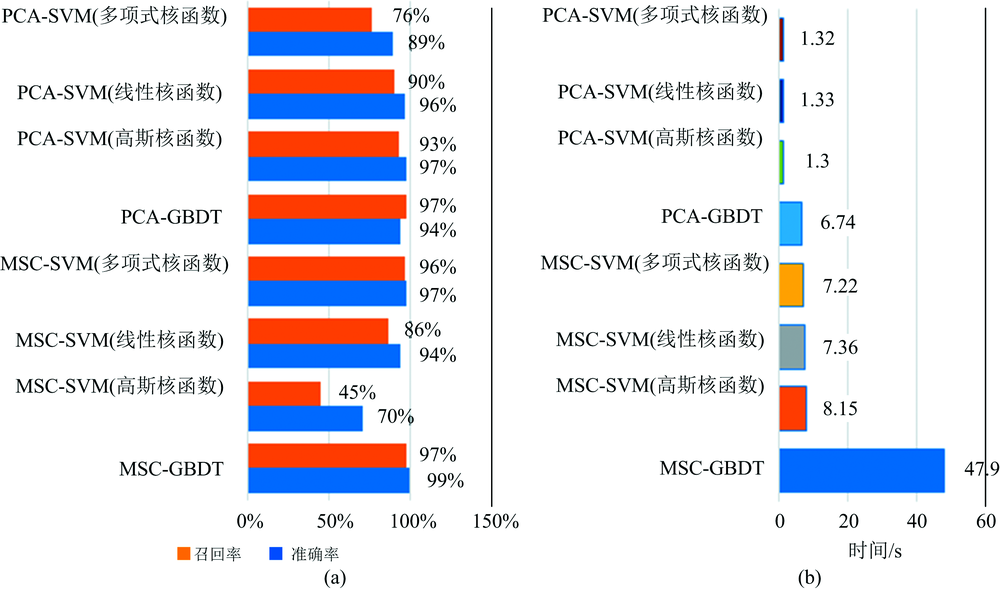 | 图9 识别模型综合比较与分析 (a): 测试集的准确率与召回率; (b): 识别时间Fig.9 Comprehensive comparison and analysis of recognition models (a): Accuracy and recall of test set; (b): Identification time |
从图9(a)中发现PCA-GBDT、 PCA-SVM(高斯)、 PCA-SVM(线性)、 MSC-GBDT、 MSC-SVM(多项式)均能较好实现番茄早疫病潜育期光谱数据的识别, 识别准确率均为95%以上; 其中SMC-GBDT在测试集上的准确率和召回率表现得最好, 分别为99%和97%, 但从图9(b)中观察SMC-GBDT识别需要用时47.9 s。 PCA-SVM(高斯核函数)的识别准确率和召回率为97%和93%, 较低于SMC-GBDT, 但用时只需要1.3 s, 因此PCA-SVM(高斯核函数)识别的效率最高。
基于高光谱成像技术对番茄早疫病潜育期的光谱进行了识别, 分析了番茄早疫病随着时间变化的病变特征规律, 综合比较了PCA、 MSC对GBDT和线性核、 多项式核、 高斯核等不同核函数情况下SVM识别模型的影响。
(1)利用高光谱图像监测番茄早疫病的病程演变情况, 结合可见光图像和光谱特征确定潜育期时间节点和潜育期建模数据, 发现番茄叶片感染早疫病后的近红外光谱平均值和红边反射率随着时间不断降低, 在接种早疫病菌36 h时能反映早疫病潜育期病变信息。
(2)当预处理算法为MSC降噪时, SVM(高斯核)在训练集和测试集上的召回率和准确率都过低, 出现严重的欠拟合现象, 但GBDT在测试集和训练集上表现都最好, 说明通过降噪处理后的光谱数据依然具有较大的数据量, 配合过于简单识别模型会导致识别能力的不足, 而配合复杂的识别模型可达到一个较高的测试结果; 当预处理算法为PCA变换时, SVM(高斯核)相比GBDT, 其在测试集上的准确率较好, 为97%, 但GBDT的召回率要高于SVM, 其在测试集上为97%, 说明降维算法能使得输入数据的维度低, 数据量小, 配合简单识别模型时, 识别效果好。
(3)MSC-GBDT在测试集的识别准确率和召回率表现得最好, 分别为99%, 97%, 但MSC-GBDT识别需要用时47.9 s。 PCA-SVM(高斯核)在测试集的识别准确率和召回率为97%和93%, 较低于MSC-GBDT, 但用时只需要1.3 s, 因此, PCA-SVM(高斯核)识别的效率最高。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|