
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高光谱成像技术识别番茄干旱胁迫
[贺露1  , 万莉
, 万莉2 , 高会议2, * ]
, 万莉, 高会议]
|
|


作者简介: 贺 露, 女, 1998年生, 安徽大学硕士研究生 e-mail: 781585321@qq.com;万 莉, 女, 1981年生, 中国科学院合肥物质科学研究院工程师 e-mail: wanli@iim.ac.cn;贺 露, 万 莉: 并列第一作者
番茄果实营养丰富备受人们喜爱。 番茄生长周期长, 需水量大, 水分含量是影响番茄植株生长发育的主要因素; 快速发现番茄植株水分亏缺状态, 对于科学有效地进行番茄的灌溉管理, 保障和提高番茄的产量和品质具有重要意义。 利用高光谱成像技术, 实时识别番茄叶片干旱胁迫程度, 提出了一种基于高光谱成像技术的番茄叶片干旱胁迫的识别方法。 首先, 选取红樱桃番茄为实验品种, 在室内培养12盆番茄幼苗。 在保证其他管理措施相同的基础上, 通过控制施水量来控制番茄的胁迫状态, 干旱胁迫程度设计3个处理(适宜水分、 中度和重度胁迫)。 分批次采集不同干旱程度番茄幼苗嫩叶在400~1 000 nm范围的高光谱图像, 并提取了每个样本的光谱和纹理特征。 使用标准化(Norm)、 多元散射校正(MSC)、 一阶导数(1st)和标准正态变量变换(SNV)四种预处理方法对光谱数据进行预处理去除光谱中的噪声。 使用连续投影算法(SPA)、 竞争性自适应重加权算法(CARS)以及竞争性自适应重加权算法结合连续投影算法(CARS-SPA)选取光谱重要特征波段, 用灰度梯度共生矩阵(GLGCM)提取番茄叶片的纹理特征, 用SPA选择纹理特征的重要变量。 融合重要光谱特征与重要纹理特征结合支持向量机(SVM)构建识别番茄干旱胁迫模型, 同时选用自适应增强算法(AdaBoost)与K-近邻(KNN)与SVM模型对比。 结果表明, 融合重要光谱特征与重要纹理特征后, 基于CARS-SPA波长选择的SNV-SVM模型具有最好的分类效果, 训练集的分类准确度(ACCT)为94.5%, 预测集的分类准确度(ACCP)为95%, AdaBoost模型分类效果次之ACCT为86.5%, ACCP为87%, KNN模型分类效果最差ACCT为81.5%, ACCP为79%。 因此, 该方法对番茄叶片干旱胁迫程度实时识别有较好的效果, 可为构建智能化的干旱胁迫分析技术提供参考。
Tomato is rich in nutrition, which most people love. It has a long growth cycle and requires a lot of water, and water content is the main factor influencing the tomato plant’s growth and development. It is of great significance to find out the water deficit state of tomato plants quickly for scientific and effective irrigation management of tomatoes, guaranteeing and improving the yield and quality of tomatoes. In this study, hyperspectral imaging technology was used to identify the degree of drought stress on tomato leaves in real-time, and a recognition method of drought stress on tomato leaves based on hyperspectral imaging technology was proposed. Firstly, a red cherry tomato was selected as the experimental variety, and 12 POTS of tomato seedlings were cultured in the laboratory. On the basis of ensuring the same as other management measures, the stress state of the tomato was controlled by controlling the amount of water applied. Then, three treatments (suitablewater, moderate and severe stress) were designed for the degree of drought stress. The hyperspectral images in the 400~1000nm range of young leaves of tomato seedlings with different drought degrees were collected in batches, and each sample’s spectral, texture characteristics were extracted. The spectral features were pre-processed using four methods, namely normalization (Norm), multiple scattering correction (MSC), first derivative (1st) and standard normalized variate (SNV) to remove noise from spectral data. The important feature bands of the spectral features were selected using the successive projections algorithm (SPA), competitive adaptive reweighting algorithm (CARS) and the competitive adaptive reweighting algorithm combined with the continuous projection algorithm (CARS-SPA). The texture features of tomato leaves were extracted by the Gray Level-Gradient Co-occurrence Matrix (GLGCM), and the important variables of texture features were selected by SPA. Finally, a support vector machine (SVM) was applied to fuse the above-mentioned various features to build a tomato drought stress recognition model, and Adaptive boosting (AdaBoost), and K-Nearest Neighbor (KNN) were used to compare and analyze with SVM model. The results showed that the SNV-SVM model based on CARS-SPA wavelength selection has the best classification effect after the fusion of important spectral features and texture features. The classification accuracy of the training set (ACCT) is 94.5%, and the classification accuracy of the prediction set (ACCP) is 95%. The adaBoost model had the second highest classification effect, ACCT 86.5%, and ACCP 87%. KNN model had the worst classification effect, with ACCT 81.5%, and ACCP 79%. Therefore, the method presented in this paper has a good effect on the real-time recognition of the drought stress degree of tomato leaves and can provide a reference for the construction of intelligent drought stress analysis technology.
番茄是一年生或多年生草本植物, 番茄果实营养丰富, 含有糖、 有机酸、 维他命C等对人体有益的营养物质, 可以生吃、 煮熟、 加工番茄酱等。 番茄原产于南美洲, 目前在中国广泛栽培, 中国番茄产量位居全球第一, 2019年西红柿产量全球占比达到34.78%[1]。 番茄的生长发育对水分要求较高, 适宜的水分能促进番茄的产量和品质, 番茄缺水会导致番茄硬度增加影响口感[2], 同时引起番茄脐腐病发病率升高产量降低。 传统的检测番茄是否出现水分亏缺方法是人工检测, 根据种植经验进行判断, 耗时久、 成本高。 由于叶片表现是植株水分亏缺的最直接证据, 因此通过高光谱成像结合叶片纹理特征分析番茄叶片, 能够快速判断整个植株状态, 评估植株干旱程度, 对于番茄灌溉管理给予一定的指导。
高光谱图像中有大量的图像与光谱信息[3], 具有快速、 高效和无损的特点, 近年来被广泛应用于检测农产品, 如用高光谱成像检测橙子可溶性固形物含量[4]、 黄瓜种子水分含量的快速预测与可视化[5]、 马铃薯氮胁迫程度分类[6]和涂层玉米识别[7]等。 在对番茄研究中, 夏吉安等人利用云计算技术在不同浇水处理下对两个品种番茄进行水分胁迫分类, 对于采集的番茄光谱使用不同模型进行全波段及特征波段对比分析, 结果表明全波段光谱的分类精度高于选择特征波段的分类精度[8], 利用云计算的MLPC模型分类精度最高, 两个品种的番茄模型分类精度为91.38%和91.63%。 王松磊等利用近红外高光谱快速诊断番茄叶片含水量及其分布[9], 基于Baseline-CARS-MLR模型在选取特征波长后预测效果最佳, 预测集相关系数为0.95, RMSEP为0.042, 可视化效果证明Jet色带对叶片水分含量可视化表征性较好。 黄玉萍等人对基于空间可分辨光谱的番茄成熟度分类判别方法进行了实验研究[10], 用自行开发的多通道高光谱成像探头采集番茄的空间可分辨光谱(SR), 基于SVMDA模型的番茄成熟度总体分类正确率为86.3%。 但是目前有关利用高光谱成像技术识别番茄干旱胁迫的研究仍较少, 融合叶片图像特征与光谱特征识别番茄干旱胁迫程度的研究更少见报道。
研究针对盆栽番茄幼苗适宜水分叶片、 中度干旱胁迫叶片和重度干旱胁迫叶片, 利用高光谱成像技术和机器学习方法融合叶片图像特征与光谱特征对番茄干旱胁迫进行分类识别, 构建最佳分类模型, 实时识别番茄叶片干旱胁迫程度, 以期为番茄早期干旱胁迫提供一种新的快速无损方法。
采用的是红樱桃番茄幼苗, 同批次在室内盆栽种植, 共培养12盆红樱桃番茄幼苗。 由于氮磷钾等营养物质的影响主要表现在成熟叶片上, 为了消除无关要素的影响, 选取番茄幼苗期嫩叶为研究对象, 分批次采集不同干旱条件下的幼苗期嫩叶高光谱图像。 番茄的干旱状态是逐渐发生的, 通过控制施水量来控制番茄的胁迫状态。 通过土壤温湿度传感器测量土壤含水率, 设置适宜水分(土壤含水率为15%~20%)、 中度干旱(土壤含水率为8%~15%)及重度干旱(土壤含水率为8%以下)3种不同干旱处理, 各处理的施肥时间、 施肥量、 管理措施相同。 每种干旱条件各选取100片番茄嫩叶, 共计选取300片叶片测定光谱数据。
高光谱图像采集系统由高光谱仪(美国Headwall Photonics公司生产)、 卤素灯、 升降台、 黑色PVC板和计算机组成。 高光谱仪波长范围为400~1 000 nm, 波段数为272个波段, 焦距可调。 实验台左右各放置一个功率为75 W的卤素灯, 角度可调保证样本受光均匀。 将样本盆栽放置升降台后, 将目标叶片放置黑色PVC板上, 目的是隔绝其他叶片对目标叶片造成的干扰。 同时为了降低外界光线的影响, 实验室处在一个黑暗的环境。 叶片样本与镜头距离为30 cm, 曝光值设为45 ms。 首先将高光谱仪器进行30 min的预热使光源稳定, 30 min后将样本放在升降台上进行图像获取。 每个样本采集一张高光谱图像, 共采集300张高光谱图像。 采集图像之前, 还需要对高光谱图像进行黑白板校正, 减少暗电流、 噪声、 光照等不稳定因素的影响, 如式(1)所示。
式(1)中, I为校正后番茄叶片图像反射率; I0为原始图像反射率; B为黑板图像反射率; W为白板图像反射率。
对高光谱拍摄的番茄叶片选取感兴趣区域(region of interest, ROI), 并且提取ROI范围内平均反射率作为光谱特征。 提取流程为: 先对获取的图像进行格式转换得到灰度图像, 通过均值处理转化为二值化图像然后进一步分割得到感兴趣区域, 计算感兴趣区域叶片的平均反射率, 以此作为目标叶片的光谱特征。
对于番茄叶片, 图像特征选择纹理特征, 使用灰度梯度共生矩阵(gray level-gradient co-occurrence matrix, GLGCM)提取叶片的纹理特征。 GLGCM集中反映了图像中灰度与边缘的相互关系, 分类效果要比仅用了图像灰度信息的灰度共生矩阵好, 因为图像的主要信息就是由图像的边缘轮廓提供的。 GLGCM一共计算提取了十五个纹理特征量[11], 分别是小梯度优势(2)、 大梯度优势(3)、 灰度分布不均匀性(4)、 梯度分布不均匀性(5)、 能量(6)、 灰度平均(7)、 梯度平均(8)、 灰度方差(9)、 梯度方差(10)、 相关性(11)、 梯度熵(12)、 灰度熵(13)、 混合熵(14)、 惯性(15)和逆差矩(16), 计算公式如式(2)— 式(16)
高光谱图像采集过程中会有来自仪器与环境的干扰, 获得的光谱信号易存在噪声和基线漂移等干扰[12, 13], 为了提高信噪比与模型分类准确性, 采用标准化(normalization, Norm)、 多元散射校正(multiplicative scatter correction, MSC)、 一阶导数(first derivative, 1st)和标准正态变量变换(standard normalized variate, SNV)四种光谱图像处理方法对光谱进行预处理。 Norm将数据按照比例缩放、 平移, 使数据落入一个小的特定区间内, 它可以使光谱的每个特征对结果做出的贡献相同, 便于下一步建模处理。 MSC用于消除因颗粒分布不均匀及颗粒大小产生的散射, 修正光谱间的相对基线平移和数据校正, 有效增强有用的光谱信息。 1st, 对光谱直接求一阶导数消除由基线漂移或平缓背景引起的干扰, 提高数据分辨率和灵敏度。 SNV消除固体颗粒大小、 表面散射以及光程变化对光谱的影响。
使用的高光谱仪器采集272个波段光谱数据, 全波段数据有较多的冗余信息, 利用连续投影算法(successive projections algorithm, SPA)、 竞争性自适应重加权算法(competitive adaptive reweighting algorithm, CARS)以及竞争性自适应重加权算法结合连续投影算法(CARS-SPA)选取样本光谱的特征波段与纹理特征的重要变量。 SPA是一种使矢量空间共线性最小化的向前变量选择算法, 通过循环产生合适的参数, 建立多元线性回归, 优势在于提取全波段的几个特征波段, 能够消除原始光谱的冗余信息。 CARS是一种结合蒙特卡洛采样与偏最小二乘模型回归系数的特征变量选择方法, 能有效选出最优波段组合。 CARS-SPA是两者联合方法, 先用CARS筛选出部分特征波段, 再用SPA对特征波段进行选择能进一步减少光谱冗余信息。 同时在针对番茄叶片提取的15个纹理特征时也用到了SPA算法对特征变量进一步筛选, 提高模型分类准确率。
SVM, AdaBoost和KNN被用于构建分类模型, 实现番茄叶片干旱胁迫的分类。 SVM是一种基于统计学习理论的新型学习机[14], 具有分类效果好、 算法思想简单、 运算速度快等优点常用于模式识别、 分类以及回归分析。 它的主要原理是通过某种事先选择的非线性映射将输入向量x映射到一个高维特征空间z, 在这个空间中构造最优分类超平面, 从而使正例和反例样本之间的分离界限达到最大, 使得原本非线性可分的问题转化为在特征空间中线性可分的问题。
AdaBoost是一种提升方法, 它的主要优点是分类精度很高, 不容易发生过拟合。 主要原理是将多个弱分类器组合成强分类器, 前一个弱分类器分错的样本的权值会得到增强, 权值更新后的样本再次被用来训练下一个新的弱分类器, 各个弱分类器的训练过程结束后, 误差率低的分类器在最终分类器中占的比例较大, 反之较小, 形成强分类器。
KNN是常见的分类技术之一, 简单易于实现、 精度高且对异常值不敏感, 核心思想是在训练集中数据和标签已知的情况下, 通过测量不同特征值之间的距离进行分类, 而且在决策样本类别时, 只参考样本周围K个“ 邻居” 样本的所属类别, 未标记样本的类别由距离其最近的K个“ 邻居” 投票来决定, 如果K个“ 邻居” 大多数属于某一个类别, 那么该样本也属于这个类别。
将番茄叶片样本分为3类, 水分适宜, 水分中度胁迫和水分重度胁迫, 定义标签分别为1, 2, 3。 每类各100片番茄叶片, 按照1∶ 2划分为预测集与训练集, 随机选取200个样本数据为训练集, 100个样本数据作为预测集。 分类模型的优劣是基于分类准确度(ACC)进行评估, ACCT表示训练集的分类准确度, ACCP表示预测集的分类准确度。 样本的划分、 数据的处理以及建模分析均基于Python软件(Python 3.10)实现。
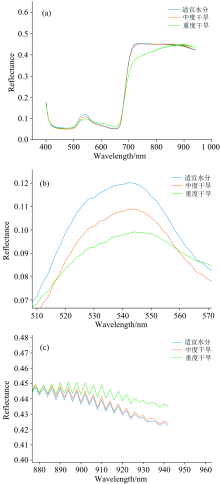
适宜水分、 中度和重度干旱处理的番茄嫩叶的平均反射光谱如图1所示。 从图1(a)中可以看出不同水分处理的叶片的反射光谱曲线走势基本一致。 在可见光区域番茄的反射率较低, 曲线平滑。 在660 nm波长附近处叶片反射率急剧上升。 在420~500 nm波段和570~660 nm波段处出现两个低反射区, 在520~560 nm波段处形成一个波峰, 700~900 nm为高反射率区域。 在540 nm附近的波峰和660 nm附近的波谷是番茄叶片叶绿素在可见光范围内的主要响应特征, 叶绿素对红光和蓝光波段的吸收使绿光波段反射突出[15], 不同程度的水分胁迫导致番茄叶片叶绿素含量和水分含量不同。 如图1(b)所示, 在可见光波范围内, 番茄嫩叶片反射率随着缺水程度增加而减少, 这也是因为含水量越高叶片叶绿素含量越高, 反射率也会增加。 如图1(c)所示, 在近红外光波范围内, 番茄嫩叶片反射率随着缺水程度增加而增加[16], 这与前人研究结果相同。
 | 图1 不同水分处理番茄叶片平均光谱反射曲线(a)、 可见光波范围放大图(b)、 近红外光波范围放大图(c)Fig.1 Average spectral reflection curves of tomato leaves under different water treatments (a), enlarged view in the range of visible light (b), enlarged view in the range of near infrared light (c) |
整体来看适宜水分与中度干旱处理的番茄嫩叶反射率在730~880 nm保持平坦, 而后慢慢减少。 而重度干旱处理的番茄嫩叶反射率在650~880 nm都处于增加的状态, 而后趋于平坦。 这可能是缺水改变了细胞结构导致叶片形状发生改变, 引起了反射光谱曲线的变化。 这些光谱差异证明了使用高光谱成像技术识别番茄干旱程度的可行性。 但是在400~700 nm三类干旱胁迫的番茄叶片反射率曲线相近, 在全波段光谱范围适宜水分与中度胁迫的反射率曲线极为相似, 只存在反射率值的差别, 仅仅依据光谱信息可能无法准确识别番茄干旱胁迫程度, 需要对光谱数据进一步处理并且补充番茄叶片的纹理特征来提升模型的准确性。
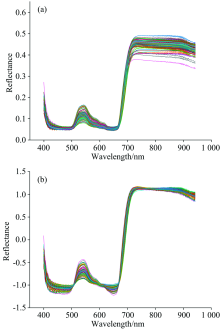
光谱预处理算法与分类算法结合的分类结果如表1所示。 由表可知, 四种不同的预处理方法对比原始光谱都能有效的提高模型分类准确率。 对于SVM模型除了1st预处理算法是小幅度提升准确率, 其他三种预处理算法都可以将准确率提高至90%以上, SNV-SVM模型的预测集准确率最高为92%。 对于KNN模型来说, 虽然四种预处理算法都能将分类精度提高至75%以上, 但模型总体分类效果不佳, 预测集准确率最高为79%。 对于AdaBoost模型, 1st-AdaBoost, MSC-AdaBoost和SNV-AdaBoost都能将其预测集分类准确率提高至85%以上, 而Norm-AdaBoost只能小幅度提升其准确率。 整体来看, SNV-SVM分类准确率最高, 模型分类效果最好。 使用SNV方法处理的光谱曲线如图2(e)所示, 从图2(a)和图2(b)中可以看出, 预处理之后的光谱相比于原始光谱更加集中, 增强了光谱数据中有用的光谱信息, 增加了不同干旱状态番茄叶片光谱反射率的区别。 因此采用SNV为光谱数据预处理方法, 后续数据处理均基于SNV预处理基础。
| 表1 基于全光谱的番茄干旱程度分类结果(%) Table 1 Classification results of tomato drought degree based on full spectrum (%) |
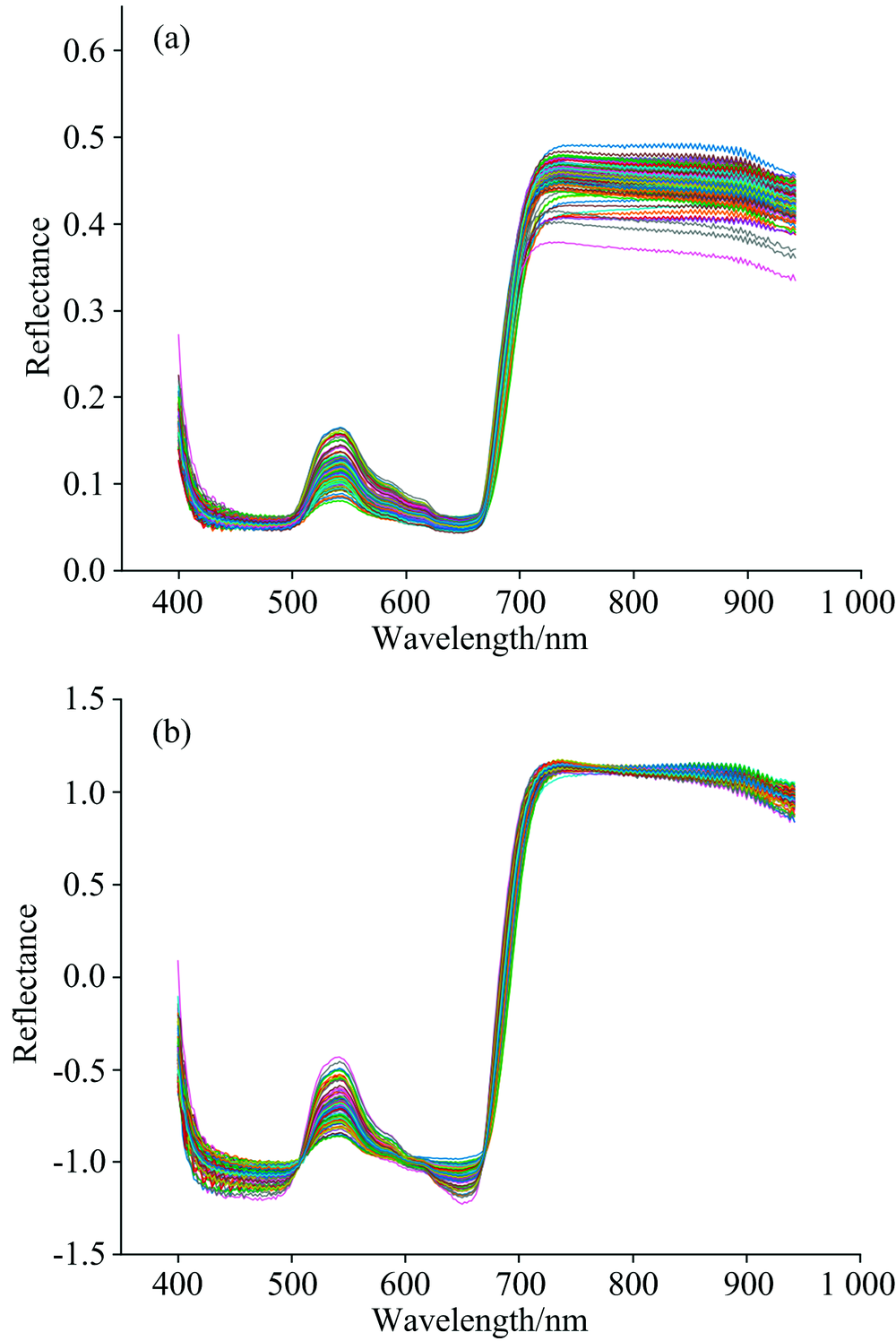 | 图2 适宜水分处理的番茄嫩叶原始反射光谱(a), SNV预处理光谱(b)Fig.2 Original reflectance spectra (a) and SNV pretreated spectra (b) of tomato tender leaves with suitable water treatment |
全光谱包含的信息比较冗余, 虽然分类效果较好但是会影响分类模型的稳健性增加模型运算时间, 耗时久。 利用CARS, SPA以及CARS-SPA算法能选出重要波段, 减少干扰信息, 选择结果如表2所示。 SPA在设置选择区间内获取了12个光谱重要波段, CARS算法得到67个重要波段。 CARS-SPA是先使用CARS算法对全光谱进行降维再使用SPA选取最终特征, 最终选取了28个特征波段, 得到的RMSE最小值为0.282。 CARS-SPA选择结果如图3所示。
| 表2 不同特征算法选择的光谱重要波段 Table 2 Important spectral bands selected by different feature algorithms |
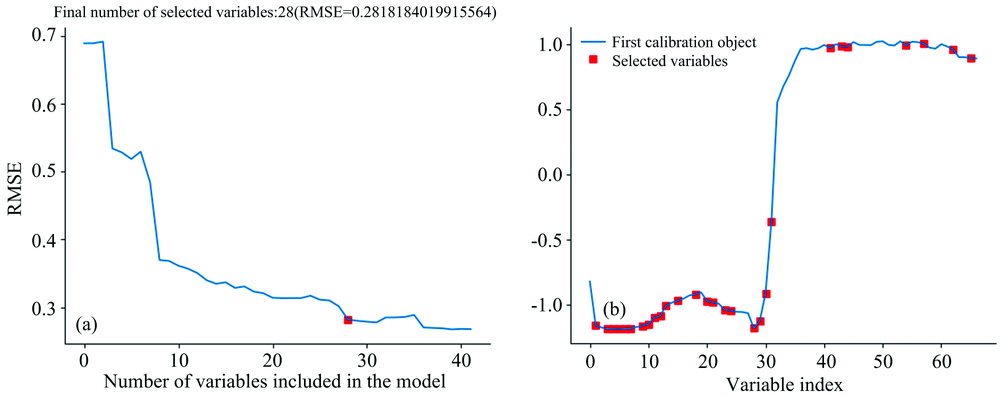 | 图3 利用CARS-SPA算法提取的特征波段图Fig.3 Feature bands extracted by CARS-SPA algorithm |
基于重要波段光谱的分类结果如表3所示。 从结果来看, 对于全光谱特征, SVM的分类效果最好, ACCT 和ACCP分别为98.5%和92%, AdaBoost分类效果次之ACCT 和ACCP分别为92%和86%, 而KNN的分类效果最差, 其ACCT和ACCP分别为85%和79%。 对于利用CARS算法选择的重要波段建模分析, KNN模型分类效果对比全光谱数据结果有所提升, 但准确度不高, ACCT和ACCP分别为85.5%和81%。 SVM和AdaBoost模型分类效果对比全光谱数据小幅度下降。 利用CARS-SPA算法选择的重要波段构建的SVM和KNN模型分类结果都较好, 其中CARS-SPA-SVM分类效果最好, ACCT和ACCP分别为90.5%和90%。 对SPA算法选择的重要波段建模分析, 三种分类模型的分类效果对比全光谱和另外两种重要波段选择方法较差, 其中AdaBoost分类效果最差, ACCT和ACCP分别为80.5%和73%。 故选择CARS-SPA为重要波段提取算法。 整体看, 除了KNN模型, 利用光谱特征波段建立的分类模型的分类准确度相较于全光谱特征的分类准确度较差, 可能是选择出来的光谱变量不能表达出全光谱信息, 需要融入更多信息提升分类准确度。
| 表3 基于重要波段光谱的番茄干旱程度分类结果(%) Table 3 Classification results of tomato drought degree based on important spectral bands (%) |
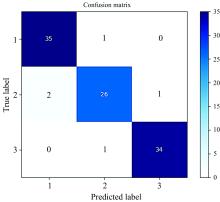
为了提高模型的分类准确度, 融入了番茄的纹理特征。 使用GLGCM方法选取了番茄的15个纹理特征, 同时为了减少信息冗余, 提高准确度使用SPA算法对纹理特征进行重要变量提取。 对纹理特征选取了8个纹理特征变量, 分别为小梯度优势、 灰度分布的不均匀性、 梯度分布的不均匀性、 能量、 灰度分布的均方差、 梯度熵、 混合熵、 逆差矩。 对光谱与纹理特征融合构建模型, 结果如表4所示。 模型加入纹理信息后, 模型分类结果对比使用原始光谱数据均获得大幅度提升, 其中KNN模型的分类精度较差ACCP为79%, AdaBoost模型的分类精度较好ACCP为87%, SVM模型的分类精度最高, ACCT和ACCP分别为94.5%和95%。 对于SVM模型, 具体分类的混淆矩阵显示在图4, 可直观的看出每类样本的错分情况。 其中, 第二类(中度胁迫)的样本被错分为第一类(适宜水分)样本较多, 说明第一类和第二类样本的相似度较高, 是影响番茄干旱程度鉴别准确度的主要因素。
| 表4 融合光谱、 纹理特征的番茄干旱程度分类结果(%) Table 4 Classification results of tomato drought degree by integrating spectrum and texture features (%) |
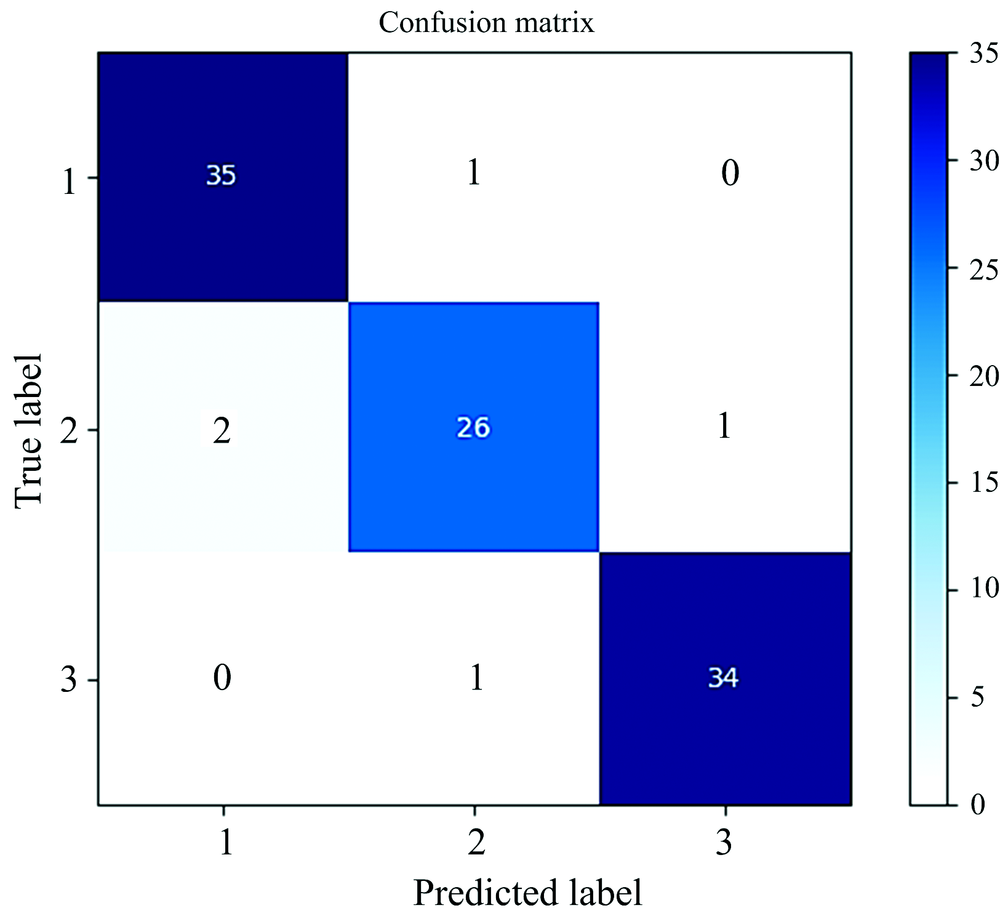 | 图4 光谱与纹理重要变量融合的SVM模型分类混淆矩阵图Fig.4 Classification confusion matrix diagram of SVM model based on the fusion of spectral and texture important variables |
以红樱桃番茄幼苗期的嫩叶为研究对象, 通过控制施水量使其处于不同的干旱胁迫状态; 使用高光谱仪获得其400~1 000 nm的高光谱图像, 提取反射率与纹理信息, 使用Norm, MSC, 1st和SNV四种预处理方法对光谱数据进行预处理去除光谱中的噪声; 并且使用SPA, CARS以及CARS-SPA选取光谱重要特征波段, 用SPA选择纹理特征的重要变量。 融合光谱与纹理特征数据并建立模型实现对番茄干旱状态的分类。 主要结果如下:
(1)基于全光谱数据的模型分类, SVM-SNV和AdaBoost-SNV分类较好ACCP结果都能在85%以上, SVM-SNV分类最好ACCP可以达到92%。
(2)基于重要波段数据的模型分类, 其分类准确率会低于全光谱数据的分类。 使用CARS-SPA算法提取的28个重要波段具有最好的分类效果, 其ACCP可达到91%。
(3)基于重要波段光谱信息融入纹理特征的模型, 模型分类效果得到提升。 分类效果最好的模型是CARS-SPA-SVM, 其ACCP可达到95%。
综上所述, 融合重要波段与纹理特征的番茄干旱状态分类, 去除了全光谱中的冗余信息, 简化了数据并且实现了番茄干旱状态的准确鉴别, 为番茄早期干旱胁迫识别与灌溉管理提供了科学依据。 在今后的研究中, 将对其他农作物进行进一步分析, 建立适用性更强的干旱胁迫识别模型。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|