
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
模糊协方差学习矢量量化的茶叶品种分类研究
[李晓1  , 陈勇
, 陈勇2 , 梅武军3, * , 武小红2, * , 冯亚杰1 , 武斌4 ]
, 陈勇, 武小红, 冯亚杰|
|


作者简介: 李 晓, 2001年生,江苏大学卓越学院本科生 e-mail: lixiao2001521@163.com
茶叶是全球最受欢迎饮品之一, 且具有丰富的营养价值, 但目前市面上的茶叶鱼龙混杂, 难以辨别。 因此, 快速准确的分类方法对茶叶进行鉴别具有重要的研究意义。 由于大多数化合物基频吸收带均出现在波长为2 500~25 000 nm的中红外区域, 茶叶的中红外光谱中含有大量关于茶叶品种的特征鉴别信息, 利用这一显著特点可以对其进行分类。 提出模糊协方差学习矢量量化(FCLVQ), 该算法在GK(Gustafson-Kessel)聚类的基础上, 引入学习向量量化(LVQ)中学习速率的概念, 用以控制模糊类中心的更新速率。 FCLVQ结合中红外光谱, 通过不断迭代计算样本模糊隶属度值和模糊聚类中心, 实现对茶叶的快速精准分类。 选取市场上的峨眉山茶叶、 优质竹叶青茶叶、 劣质竹叶青茶叶作为实验对象。 将实验对象分为3组(每个品种各1组), 每组32个, 共计96个样本。 利用FTIR-7600型傅里叶红外光谱分析仪分别采集每组样本的中红外光谱数据, 每组样本采集三次, 取其平均值作为样本的红外光谱数据。 首先, 由于原始光谱含有噪声数据, 故使用多元散射校正(MSC)作降噪预处理; 其次, 由于光谱数据维数高达1 868维, 采用主成分分析(PCA)将光谱数据降至14维, 其14个主成分的累计贡献率为99.74%; 然后将降维后的光谱数据使用线性判别分析(LDA)进一步降至2维, 同时提取数据中的鉴别信息; 最后运行模糊C均值聚类算法(FCM), 将其运算得到的聚类中心作为FCLVQ的初始聚类中心参与迭代, 设置模糊隶属度的权重指数 m=2, 最终分类准确率高达95.25%。 将FCM算法、 GK算法、 模糊Kohonen聚类网络(FKCN)算法与FCLVQ算法的运行结果进行对比, FCM, GK和FKCN的分类准确率分别为90.91%, 92.41%和90.91%。 结果表明, 与其他三个算法相比较, FCLVQ在 m=2, 主成分个数为14时有着更好的分类效果, 可以用来实现对茶叶品种的准确分类。
Tea, with much nutrition, is one of the most popular drinks in the world. Good and bad tea are mixed at the market, so it is difficult to make a classification among them. Therefore, using a fast and accurate method to identify tea varieties is meaningful. Most chemical compound's fundamental frequency absorption bands are within the wavelength range of 2 500~25 000 nm (Mid-infrared region). Large amounts of feature discriminant information in the mid-infrared spectra of tea can be applied to classify tea varieties. This paper proposed a fuzzy covariance the learning vector quantization (FCLVQ) based on the Gustafson-Kessel (GK) clustering. It introduces learning rate of learning vector quantization (LVQ) to control the update rate of cluster centers. Combined with mid-infrared spectroscopy, FCLVQ realizes fast and accurate identification of tea varieties by iteratively calculating the fuzzy membership values and fuzzy clustering centers of samples. Three different kinds of tea(i. e. Emeishan tea, high-quality bamboo-leaf-green tea and low-quality bamboo-leaf-green tea) were selected as 96 samples in total at the market. Each variety corresponds to one group, which consists of 32 samples. The Fourier mid-infrared spectra were collected using an FTIR-7600 spectrometer, and the average spectral data were computed as the final experimental spectra. Firstly, the original spectral data contained noise data, so they were pretreated with multiplicative scattering correction(MSC) to reduce noise. Secondly, principal component analysis(PCA) was employed to reduce the dimensionality of data from 1 868 to 14, and the cumulative contribution of the 14 principal components was 99.74%.Thirdly, the dimensionality of the processed data was reduced to 2, and the discriminant information was extracted by linear discriminant analysis(LDA). Finally, fuzzy C-means clustering(FCM) was run to get initial cluster centers for FCLVQ. The experimental results showed that when the weight index m=2, the accuracy rate of FCLVQ was 95.25%. On the condition of m=2, for the same spectra, the classification accuracy rates of FCM, GK and fuzzy Kohonen clustering(FKCN) were 90.91%, 92.41% and 90.91% respectively. The experimental results showed that compared with the other three algorithms, FCLVQ had a better classification accuracy when m=2 and the number of principal components were 14. Thus, it can be used to classify different tea varieties.
茶叶作为全球的最受欢迎饮品之一, 在人们生活中占有重要地位。 茶叶具有丰富的营养成分, 如: 茶多酚、 茶色素、 茶多糖、 茶氨酸等, 应用于食品、 医学、 化工等多个领域。 从茶叶中提取的茶多酚具有良好的抗氧化性和抑菌活性, 利用这一特点可以用于食品保鲜领域, 满足健康绿色的发展理念[1]。 绿茶加工产生的黄酮醇和多糖等副产品可以阻止轻微细胞的脂质肠吸收和积累[2]; 普洱茶里的碳水化合物通过抑制葡糖糖苷酶有降低血糖的功效。 随着茶叶市场的不断扩大, 出现了鱼龙混杂的现象。 此外, 目前鉴别茶叶主要是感官鉴别和化学分析法。 感官鉴别的评价者是根据自己的经验和判断来辨别茶叶的质量, 然而感觉器官容易受到外界的干扰, 主观性较强, 鉴别准确率有一定的局限性。 化学分析方法会对检测样本造成破坏且费时费力。 因此为了维护消费者的利益, 找到一种简单快速的鉴别方法尤为重要。
目前, 国内外诸多学者在茶叶检测方面取得了一定的研究成果。 Lin等提出利用多通道发光二极管诱导荧光系统, 并结合卷积神经网络的方法对茶叶品种进行分类[3]; 通过电子鼻和电子舌收集的信息可以直接拼接融合进行定性和定量分析茶叶质量等级[4]; 利用高效液相色谱-二极管阵列检测方法快速定量分析西湖龙井样本的十个主要成分[5]; 王丽等利用高效液相色谱法建立不同种类的茶叶的指纹图谱, 采用指纹图谱的相似度软件对数据进行分析, 结果表明不同品种的茶叶样本能够有效的区分[6]; Li等采用荧光高光谱成像技术, 结合优化的支持向量机(support vector machines, SVM)模型进行快速无损的茶叶鉴别[7]; 武小红等采用模糊非相关鉴别C均值聚类算法, 并结合近红外光谱技术实现快速有效的茶叶品种鉴别[8]。 Mishara等利用高光谱成像数据中的空间信息实现茶叶品种分类[9]; Bakhshipour等基于模糊决策树的计算机视觉系统, 将多种茶叶的图像信息引入到分类器中用于实现茶叶分类, 准确率高达95.0%[10]。
近些年来, 红外光谱技术因具有快速无损、 安全高效等特点, 在食品检测应用较为广泛[11, 12]。 大多数化合物的基频吸收带出现在中红外区, 因此可以通过中红外光谱的吸收强度、 吸收峰值信息进行食品鉴别。 结合多种分类方法, 例如: K近邻、 SVM、 人工神经网络、 决策树等进行食品的产地溯源、 真伪鉴定、 品种鉴定、 品质检测等。 Adenan等利用中红外衰减全反射结合数据处理有效地筛选出食用燕窝的结构掺杂物[13]。 Wei等提出氧化石墨烯的中红外光谱与化学计量学相结合的分类方法, 对12种普洱茶的品种进行鉴别, 可实现100%的品种分类准确率[14]。 本文提出了一种模糊协方差学习矢量量化, 采用基于模糊协方差矩阵的自适应距离测度, 对三类茶叶的中红外光谱数据进行分类, 并与模糊C均值聚类算法(fuzzy C-means clustering, FCM)[15], GK聚类[16], 模糊Kohonen聚类网络(fuzzy Kohonen clustering, FKCN)[17]算法的分类结果进行对比。
1.1.1 材料
试验样本均在四川省乐山市当地茶叶市场上购买, 包括峨眉山茶叶、 优质竹叶青茶叶、 劣质竹叶青茶叶, 每类样本各32份, 共96份。
1.1.2 光谱仪器与分析软件
采用配有高灵敏度DLATGS检测器和多层镀膜溴化钾分束器的FTIR-7600型傅里叶红外光谱分析仪。 开机预热1 h, 扫描32次, 扫描波数4 001~401 cm-1, 扫描间隔为1.928 cm-1, 分辨率为4 cm-1。 将购买的茶叶经研磨粉碎, 再用40目筛进行过滤后, 各取0.5 g分别与溴化钾1∶ 100均匀混合; 每个样本取混合物1 g进行压膜, 然后用光谱仪扫描3次, 为减小误差, 取3次的平均值作为样本光谱数据。 采集光谱时环境温度和相对湿度保持相对稳定, 最终得到三类茶叶样本, 每类含32个傅里叶中红外光谱数据, 共96个样本。
1.1.3 光谱数据处理
由于样本颗粒不均匀以及样本大小、 仪器的噪声等都会对采集到的光谱数据产生一定的影响, 因此利用多元散射校正(multiplicative scattering correction, MSC)对采集到的数据进行相应处理。 茶叶数据维数较高, 包含大量的冗余信息, 通过主成分分析(principal component analysis, PCA)提取其大量有效信息, 从而减小建模的难度。 在PCA处理之后, 为了提高数据之间的区分度, 使不同种类的数据投影点尽可能远离, 故采用线性判别分析(linear discriminant analysis, LDA)对数据进一步处理。
在GK聚类和学习向量量化(learning vector quantization, LVQ)的基础上设计了一种模糊协方差学习矢量量化, 该算法步骤描述如下:
(1) 初始化参数: 设置品种数c=3; 初始权重指数m0=2; 最大迭代数rmax=100; 误差上限值ε =0.005 ; 测试样本数n2=66; 初始类中心设置为FCM算法运行后的聚类中心VFCM, 并将样本与该聚类中心的欧式距离进行式(1)运算, 求得初始模糊隶属度矩阵U0
式(1)中,式(1)中,$u_{ik,0}$表示算法开始运行时第k{k=1,2,...,c}类的模糊隶属度,类的模糊隶属度,$D_{ik,0}$表示样本$x_{k}$到第i类聚类中心的初始欧氏距离。类聚类中心的初始欧氏距离。
(2) 计算第i类数据的模糊协方差矩阵Sfi, r
式(2)中, r为迭代次数; mr-1为第r-1次迭代的权重指数, uik, r-1表示算法第r-1次迭代时样本xk对第i类的模糊隶属度, vi, r-1表示第r-1次迭代时第i类的类中心。
(3) 计算第i个聚类中心的范数矩阵Ai, r
式(3)中, d为测试样本的维数。
(4) 计算第r次迭代时的距离范数Dik, r
(5) 给定权重指数的变化量
(6) 更新第r次迭代时的权重指数mr
(7) 更新模糊隶属度值uik, r
(8) 计算学习速率αik, r
(9) 更新聚类中心vi, r
(10) 定义迭代误差限Er
(11) 当Er< ε 或r>rmax时, 停止迭代, 并记录最终模糊聚类中心Vf与模糊隶属度矩阵Uf; 否则令Vr-1=Vr, Ur-1=Ur, 返回步骤(2)继续迭代运算。 当迭代停止后, 根据最终的模糊隶属度uik, r, 若uik为uk中最大值, 则判定样本xk属于第i类。
将96个样本分为训练集与测试集。 训练集共3类, 每类10个样本; 测试集共3类, 每类22个样本。 在采集茶叶样本的光谱数据时, 散射水平的差异以及周围的环境因素将产生光谱噪声、 基线漂移等。 为了有效地消除噪声影响, 增强与组分含量相关的光谱吸收信息, 利用MSC对得到的初始中红外光谱数据进行预处理。 由于不同类别光谱数据特征信息的区分度直接体现在光谱的吸收率上, 最终发现不同类别的茶叶光谱吸收率上存在明显差异, 故有效利用该差异提取茶叶光谱数据的特征鉴别信息对于茶叶分类有重要意义。
2.1.1 中红外光谱的主成分分析
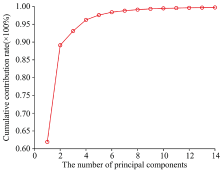
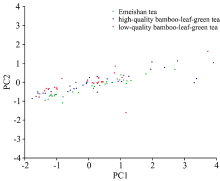
由于中红外光谱数据维数为1 868, 包含大量的冗余信息和噪声, 大大增加了建模的难度, 因此采用主成分分析对数据进行降维, 降维后数据的主成分得分图如图2。 根据主成分个数不同, 计算出其累计贡献率大小, 图1指出当数据维数降至14维时, 14个主成分的贡献率达到了99.74%。
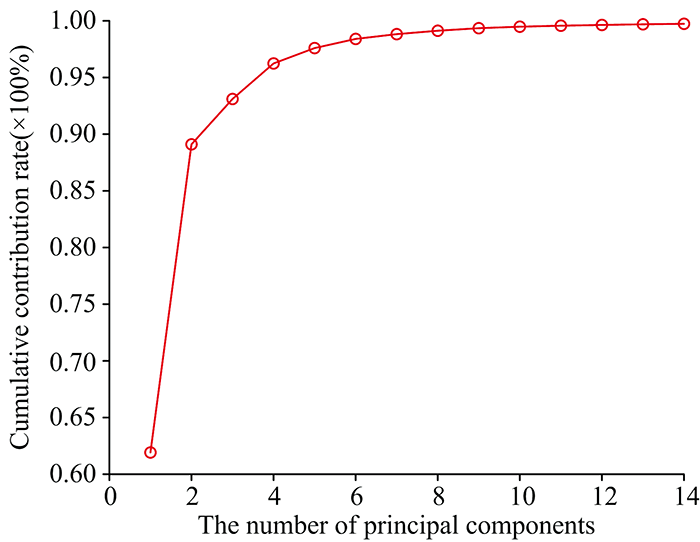 | 图1 主成分的累计贡献率Fig.1 Cumulative contribution rate of principal components |
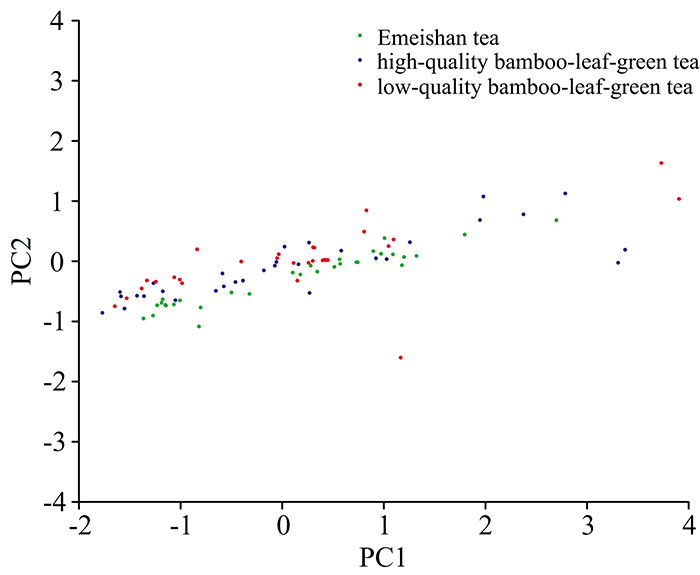 | 图2 主成分得分图Fig.2 Principal component score plot |
由主成分得分图可以看出三种茶叶重叠度较高, 难以仅根据图像进行分类, 因此采用线性判别分析对数据提取特征鉴别信息。
2.1.2 中红外光谱的线性判别分析
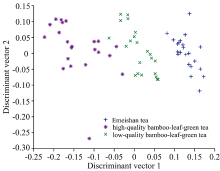
由于测试集数据用于最终准确率的计算, 故此处对训练集数据进行LDA算法提取鉴别信息。 在使用LDA提取特征的过程中, 选取两个特征鉴别向量, 使得各类样本在特征空间中的投影满足类间距离最大, 类内距离最小, 以提高数据分类的准确率。 将测试集数据投影到二维特征空间后样本分布如图3所示。 三类茶叶区分度较高, 为后续茶叶品种的识别奠定了良好的基础。
 | 图3 线性判别分析后的数据Fig.3 Data processed by LDA |
2.2.1 模糊聚类相关参数的初始化
通过主成分分析和线性判别分析对数据处理后, 分别采用FCM, GK, FKCN和FCLVQ算法对66个测试样本进行聚类, 比较其准确率。 由于四种聚类算法均为迭代运算, 故对参数进行初始化: 设置类别数c=3; 初始权重指数m0=2; 最大迭代次数rmax=100; 误差上限值ε =0.005。 首先运行FCM算法得到其最优聚类中心VFCM与模糊隶属度矩阵UFCM, 将VFCM作为FKCN与FCLVQ的初始聚类中心, 同时将VFCM代入式(1)求得矩阵U0作为GK, FCLVQ算法的初始模糊隶属度矩阵。
2.2.2 模糊隶属度值的计算与分类结果
分别运行FCM, GK, FKCN和FCLVQ算法, 在满足迭代停止条件后终止计算, 得到模糊隶属度矩阵UFCM, UGK, UFKCN, UFCLVQ。 根据模糊隶属度判断样本所属类别, 例如: 若uik, FCLVQ为uk, FCLVQ中最大值, 则FCLVQ算法将样本xk归属于第i类。 FCM, GK与FKCN算法的分类准确率分别为90.91%, 90.91%, 92.42%; 而FCLVQ算法的分类准确率达到了95.45%。 模糊隶属度值如图4所示, 其中(a), (b), (c), (d)分别表示FKCN, GK, FCM和FCLVQ算法。
 | 图4 四种模糊聚类算法的模糊隶属度值Fig.4 Fuzzy membership values of four fuzzy clustering algorithms |
2.2.3 权重指数m对算法准确率的影响
当权重指数m发生变化时模糊聚类的准确率也会发生变化。 对权重指数m进行从2变到8时的变化, 从表1中可以发现当m由2变为3时, FCM、 GK聚类、 FKCN三种算法准确率均得到了改善; 当m由3变化到6时, 四种聚类算法的准确率均没有发生变化, FCM和FKCN两种算法的准确率均保持92.42%, GK聚类和FCLVQ两种算法准确率保持在95.45%; 当m继续增大至8时, 除了FKCN之外的三种算法的准确率均有所下降。 特别地, 当m从7增大到8时, FCM和FCLVQ两种算法的准确率发生骤然下降, 说明当m值增大到一定值时, 算法的误差就会增大, 所以m的取值对于样本种类的识别起着重要的作用。 当m在2~7之间变化时, 四种算法的准确率均基本高于90%, 模糊协方差学习矢量量化的准确率高达95.45%, 说明主成分分析与线性判别分析结合四种聚类算法是一种比较好的鉴别茶叶种类的方法, 可以有效地实现茶叶品种的分类。
| 表1 不同m时各算法分类准确率 Table 1 Classification accuracy of each algorithm at different m-values |
2.2.4 ε 值对算法准确率的影响
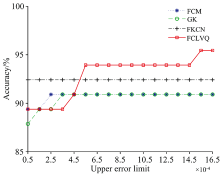
在程序运行的过程当中, 随着误差上限ε 约束的松弛程度不同, 算法的迭代次数也会相应发生变化, 从而导致模糊隶属度的变化。 研究了ε 介于0.000 05~0.001 65之间, 步长为0.000 1情况下FCM, GK, FKCN, FCLVQ算法的分类准确率的变化, 其结果参见图5。
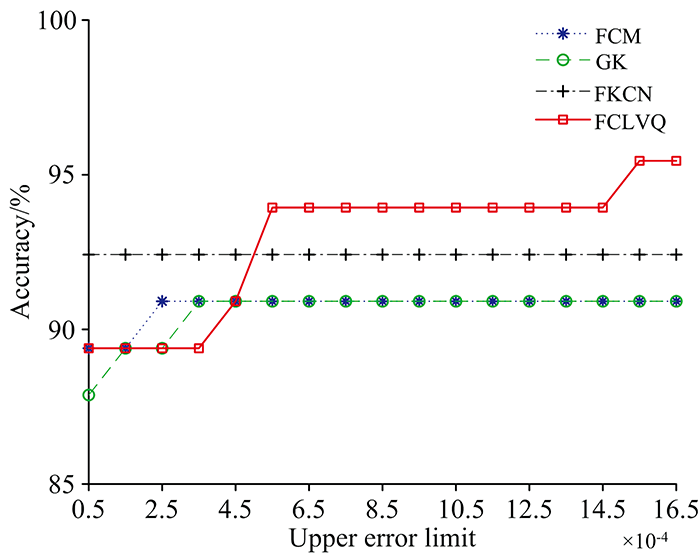 | 图5 不同ε 时各算法分类准确率Fig.5 Classification accuracy of each algorithm at different ε -values |
获取三类不同品种茶叶的光谱数据后, 先后使用MSC, PCA, LDA对数据进行预处理, 较好地对数据进行了降噪, 降维与特征鉴别信息提取。 最后选择了合适的初始化参数后, 利用提出的FCLVQ聚类算法对数据进行聚类分析, 并与FCM聚类, GK聚类, FKCN聚类算法的分类效果进行对比。 结果表明: MSC, PCA, LDA结合FCLVQ算法有着更好的分类效果。 例如: 在权重指数m=2, ε =0.005的情况下对茶叶中红外光谱数据的分类准确率为95.45%, 故FCLVQ算法可以被用来进行茶叶的品种鉴别。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|