



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
二尺度分解和显著性提取的红外与可见光图像融合
[冯鑫1, 2  , 方超
, 方超1, * , 龚海峰2 , 娄熙承1 , 彭烨1 ]
, 方超, 龚海峰|
|


作者简介: 冯 鑫, 1982年生,重庆工商大学机械工程学院副教授 e-mail: 149495263@qq.com
为增强红外与可见光图像融合可视性, 克服红外与可见光图像融合结果中细节丢失、 目标不显著和对比度低等问题, 提出一种基于二尺度分解和显著性提取的红外与可见光图像融合方法。 首先, 以人类视觉感知理论为基础, 针对人眼对图像不同区域敏感性不同特性, 在跨模态融合任务中需要对源图像进行不同层次分解, 避免高频分量和低频分量混合减少光晕效应, 采用二尺度分解方法对源红外与可见光图像进行分解, 分别获取各自的基本层和细节层, 该分解方法能够很好的表达图像并具有很好的实时性; 然后, 针对基本层的融合提出一种基于视觉显著图(VSM)的加权平均融合规则, VSM方法能够很好提取源图像中的显著结构和目标。 采用基于VSM的加权平均融合规则对基本层融合, 能够有效避免直接使用加权平均策略而导致对比度损失, 使融合图像可视性更好; 针对细节层的融合, 采用Kirsch算子对源图像分别提取得到显著图, 然后通过VGG-19网络对显著图进行特征提取获取权值图, 并与细节层进行融合, 得到融合的细节层; Kirsch算子能在八个方向上快速提取图像边缘, 显著图中将包含更多边缘信息和更少噪声, 且VGG-19网络能够提取到图像更深层特征信息, 获取的权值图中将包含更多有用信息; 最后, 将融合后的基本层和细节层图像进行叠加, 获取最终融合结果。 在实验部分, 选取了四组典型的红外与可见光图像来进行测试, 并与其他六种目前主流方法进行对比。 结果表明, 该方法在主观质量上具有高对比度、 目标突出、 细节信息丰富和图像边缘特征保持较好等优势。 在信息熵、 互信息、 标准差、 多尺度结构相似度测量和差异相关和等客观指标上也展现出比较好的结果。
To enhance the visibility of infrared and visible image fusion and overcome the problems of detail loss, insignificant target, and low contrast in infrared and visible image fusion results, a novel infrared and visible image fusion method based on two-scale decomposition and saliency extraction is proposed. Firstly, based on the theory of human visual perception, the source image is decomposed at different levels to avoid mixing high-frequency and low-frequency components to reduce the halo effect. In this paper, we use a two-scale decomposition method to decompose the source infrared and visible images and obtain the basic layer and detail layer, respectively, representing the image well and having good real-time performance. Then, a weighted average fusion rule based on a visual saliency map (VSM) is proposed to fuse basic layers, and the VSM method can extract the salient structures and targets in the source images. The VSM-based weighted average fusion rule is used to fuse the base layer, effectively avoiding the contrast loss caused by the direct use of the weighted average strategy and making the fused image perform better. The Kirsch operator is used to extract the source images separately to obtain the salient maps for the fusion of the detail layer. Then the VGG-19 network is applied to get the weight maps by extracting features from the salient maps and fusing them with the detail layer to obtain the fused detail layer. The Kirsch operator can quickly extract the image edges in eight directions, and the significant map will contain more edge information and less noise. The VGG-19 network can extract deeper feature information from the image, and the obtained weight map will have more helpful information. Finally, the fused basic and detail layer images are superimposed to get the final fusion result. Four sets of typical infrared and visible images are selected for testing and compared with six other current mainstream methods in the experimental part. The experimental results show that the method in this paper has the advantages of high contrast, prominent target, rich detail information and better retention of image edge features in terms of subjective quality. The objective metrics such as information entropy, mutual information, standard deviation, multiscale structural similarity measure and difference correlation sum also show relatively good results.
红外与可见光图像融合是一项重要且应用很广泛的图像增强技术。 图像融合的关键问题是如何从源图像中提取突出的特征, 以及如何结合这些特征来生成融合后的图像。 可见光图像的空间分辨率较高并且细节明暗对比鲜明, 但比较容易受到周围环境和气候等因素的影响; 红外图像通过热辐射来描绘物体, 能够抵抗环境和气候等因素干扰, 但红外图像分辨率较低和纹理信息比较差。 红外与可见光图像共享互补特性, 从而可以产生稳健且信息丰富的融合图像[1, 2]。 近年来, 人们提出了许多图像融合方法, 将源图像中的特征结合到单一图像中[3]。 这些方法被广泛应用于视频监督, 目标识别和图像增强[4, 5]。 最典型的图像融合方法是基于多尺度变换和基于表示学习的方法。
在多尺度变换领域, 比较常见的有双树复小波变换(dual-tree complex wavelet transform, DTCWT)[6]、 曲波变换(curvelet transform, CVT)[7]、 Tetrolet变换[8]、 脉冲耦合神经网络(pulse coupled neural network, PCNN)[9]和四阶偏微分方程(fourth order partial differential equations, FPDE)[10]等。 这些方法将源图像投影到频率域, 增加了计算的复杂性; 并且通过预先定义好的基函数来处理图像, 源图像中的细节纹理信息不能够得到很好的提取。 因此, 研究者在变换域方法的基础上, 提出基于表示学习的图像融合方法。
在表示学习领域, 最常见的红外与可见光图像融合方法是基于字典学习和稀疏表示。 比如基于压缩感知(compressive sensing, CS)[11]、 潜在低秩分解(latent low-rank representation, LatLRR)[12]、 稀疏表示(sparse representation, SR)[13]等方法。 其中, LatLRR方法可以将源图像进行分解, 得到噪音分量、 低秩分量和显著分量三部分。 在融合的时候可以分离出噪音分量, 达到减噪效果。 SR方法通过滑动窗口将源图像进行分块, 从而减少伪影和提高误配准鲁棒性。 尽管基于表示学习的方法在红外与可见光图像融合质量方面已具有较好表现, 但是该类方法相对比较复杂且字典学习过程需要耗费大量时间。 这些因素促进了图像融合中深度学习方法的发展, 以机器学习取代了稀疏表示的字典学习。
基于深度学习的图像融合方法利用源图像中的深层特征来产生融合图像。 比如预训练网络VGG-19[14]和Resnet50[15]来提取源图像中的深层特征, 使得融合图像中包含更多源图像的细节信息和结构信息。 随着网络层加深, 信息损失减少, 但参数选择会愈加复杂。
基于以上分析, 提出一种基于二尺度分解和显著性提取的红外与可见光图像融合方法。 首先, 为避免高频分量和低频分量混合减少光晕效应, 采用二尺度分解对源红外与可见光图像进行分解, 分别获得源图像相应的基本层和细节层; 然后对基本层融合采用基于视觉显著图(visual saliency map, VSM)的加权平均融合规则, 该规则能很好提取图像中显著结构和目标; 针对细节层融合采用Kirsch算子对源图像分别提取得到显著图, Kirsch算子能在八个方向上快速提取图像边缘特征, 使显著图包含更多特征信息且减少噪声; 然后通过VGG-19网络对显著图进行特征提取, 获取权值图, 并与细节层融合; 最后将融合的基本层和细节层进行融合, 得到最终融合结果。
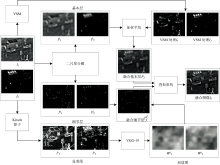
融合方法结构图如图1所示。 在此以两张待融合源图像的情况为例, 多张源图像的融合策略类似。 融合方法步骤如下:
 | 图1 本融合方法结构图Fig.1 Schematic diagram of the fusion method in this paper |
(1)用二尺度分解将源红外图像I1和可见光图像I2分解, 分别获得源红外图像基本层
(2)针对基本层融合采用基于VSM的加权平均融合规则。 用VSM方法分别处理源红外图像与可见光图像, 然后使用加权平均策略, 获得融合基本层
(3)针对细节层融合采用基于Kirsch算子和VGG-19的融合规则。 首先用Kirsch算子分别处理源红外图像和可见光图像得到显著图
(4)将融合后的基本层和细节层叠加重构, 获得最终融合结果If。
假设有两张已经预配准源红外和可见光图像, 其表示为Ik, k∈{1, 2}。 二尺度分解方法通过均值滤波器或中值滤波器将图像分解为基本层和细节层; 与其他多尺度分解方法相比, 该分解方法能够很好的表达图像并具有很好的实时性。 本工作引入该方法将源红外与可见光图像分别分解为基本层和细节层。 对于每一张源图像Ik, 基本层
式(1)中, Ik为源图像,
源图像减基本层图像获取最终细节层图像
式(2)中,
二尺度分解方法处理源图像结果如图2所示。
 | 图2 二尺度分解结果 (a): 源红外图像; (b): 红外图像基本层; (c): 红外图像细节层; (d): 源可见光图像; (e): 可见光图像基本层; (f): 可见光图像细节层Fig.2 Two scale decomposition results (a): Source infrared image; (b): Infrared image base layer; (c): Infrared image detail layer; (d): Source visible image; (e): Visible image base layer; (f): Visible image detail layer |
可以看出, 基本层中主要包括红外与可见光图像的亮度和轮廓信息; 而细节层中主要包括红外与可见光图像的细节显著特征信息以及边缘信息。
基于二尺度分解的方法能有效分离高频信息和低频信息, 其中高频信息对应二尺度分解的细节层, 而低频信息对应二尺度分解的基本层。 基本层中包含的低频信息控制着融合图像的整体轮廓和对比度, 如果仅仅采用加权平均的方法, 将无法充分整合这些低频信息, 甚至还会导致融合图像对比度损失。
本工作提出基于VSM的加权平均融合规则来融合基本层图像。 VSM能够清楚感知到图片中显著的视觉结构、 区域和突出目标。 将VSM方法引入基本层融合, 能够有效避免对比度损失。
VSM将一个像素与其他像素进行对比来定义像素级显著性。 像素点p的显著值S(p)定义如式(3)[17]
式(3)中, Ip为在源图像I中某个像素点p的像素值, M为源图像I中总像素数。 如果在源图像中两个像素有相同的像素值, 那它们的显著值也是相同的。 则式(3)可表示为
式(4)中, i为像素强度, Ni为强度值与i相同的像素值, L为灰度值, 设置为256。 然后, 将S(p)归一化到[0, 1]。 VSM方法对源图像的处理结果如图3所示。
 | 图3 VSM方法处理的结果 (a): 红外图像; (b): VSM处理(a); (c): 可见光图像; (d): VSM处理(c)Fig.3 The result of VSM method processing (a): Infrared image; (b): VSM of image (a); (c): Visible image; (d): VSM of image (c) |
经VSM处理后的红外与可见光图像分别表示为S1和S2。 可以通过如式(5)加权平均策略获得融合的基本层
式(5)中, 权值Wb定义为
如果处理结果S1和S2位置相同, 则权重Wb取平均权值。 如果处理结果S1大于S2, 则权值Wb将大于0.5, 融合图像
3.2.1 Kirsch算子构建显著图
采用Kirsch算子来生成显著图, 该方法能在八个方向上快速提取图像的边缘特征, 在保留细节边缘和抵制噪声方面表现更优。
Kirsch算子获取源图像显著图可表示为
式(7)中, K(·)为Kirsch算子函数,
 | 图4 Kirsch算子处理结果 (a): 红外图像; (b): 红外显著图; (c): 可见光图像; (d): 可见光显著图Fig.4 Kirsch operator processing results (a): Infrared image; (b): Saliency map of infrared iamge; (c): Visible image; (d): Saliency map of visible image |
3.2.2 基于VGG-19网络的细节层融合
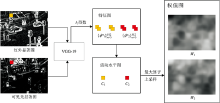
VGG-19网络共有19层, 包含16个卷积层和3个全连接层。 其结构相对较简单, 使用3×3的卷积层和2×2的池化层, 网络表现随着网络结构层数增加而提升[14]。 在VGG网络中, 使用多个3×3卷积核来代替较大卷积核(11×11, 7×7, 5×5), 这样在具有相同感知野的条件下, 提升了网络深度和网络的效果。 VGG-19网络结构如图5所示。
 | 图5 VGG-19网络结构图Fig.5 VGG-19 network structure diagram |
为了让融合的细节层包含更多目标信息, 采用五层VGG-19网络来提取显著层的特征图, {
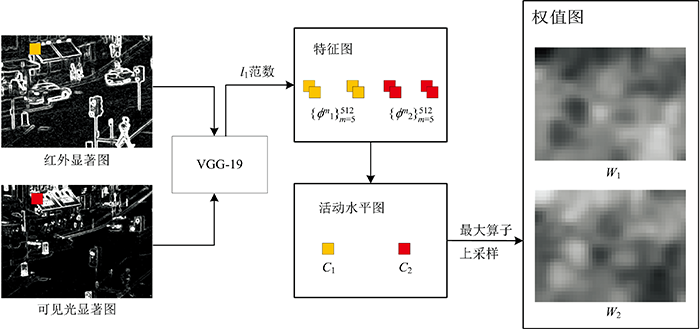 | 图6 VGG-19网络处理过程图Fig.6 Diagram of the VGG-19 network processing procedure |
多层融合策略的详细步骤如下。
首先, 基于VGG-19网络提取深层特征图, 可表示为
式(8)中,
然后, 将VGG-19网络提取深层特征图转变成活动水平图, 可表示为
式(9)中, Ck(x, y)分别表示对应特征图{
将活动水平图Ck用软最大算子处理, 得到初始权值图
式(10)中, j为初始权值图的数量, 设置为2。
池化算子在VGG网络中是一种下采样方法, 用五层VGG网络提取的初始权值图只有源图像
将提取的权值图Wk与细节层
3.2.3 最终融合结果重构
将融合的基本层和细节层重构, 得到最终融合图像为
方法的实验平台为: AMD(R) Ryzen(R)5 3500X 6核6线程CPU、 Geforce RTX 2070 SUPER 8G显卡、 16G 3200MHz内存, 仿真平台软件为Matlab2020a, 在win10专业版的64位操作系统上实验。 实验测试数据选择四组典型的红外与可见光图像Kaptein_1123、 Lake、 Jeep_in_front_of_house和Man_in_doorway。 实验对比方法为DTCWT方法[6]、 CVT方法[7]、 FPDE方法[10]、 LatLRR方法[12]、 VGG-19方法[14]和Resnet50方法[15]。 其中, DTCWT、 CVT和LatLRR是基于多尺度分解的方法; FPDE是基于子空间的方法; VGG-19和Resnet50是基于深度学习的方法, 主要通过深度学习网络获得相应图像权值图, 然后将图像与权值图进行融合。 对比方法代表了目前红外与可见光图像融合的主流方法, 用它们与本方法对比能很好验证其有效性。
为了对实验结果进行定量评价, 采用信息熵(Entropy, EN)、 互信息(mutual information, MI)、 多尺度结构相似度测量(multiscale structural similarity measure, MS-SSIM)、 差异相关和(sum of correlations of differences, SCD) 和标准差(standard deviation, SD)等典型融合指标对结果分析。 其中, EN是基于信息论来衡量融合图像中包含源图像的信息量, EN越大, 则表明包含源图像的信息越多, 但它会受到噪声的影响, 噪声越多, 信息熵也会越大; MI表示融合图像与源图像之间的相关程度, 用于衡量从源图像传输到目标图像的信息量, MI越大, 目标图像包含源图像信息量越多, 其融合效果越好; MS-SSIM用来衡量结构信息, 其值越大, 表明融合图像结构与源图像更接近; SCD根据融合图像与源图像差异相关性之和来评价融合效果, 其值越大, 融合效果越好; SD是基于融合图像的分布和对比度来衡量融合效果, 其值越大, 表明融合图像视觉效果比较好。
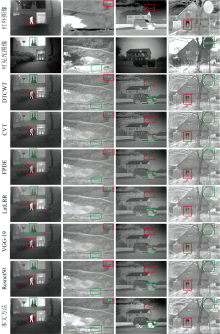
图7为已经预配准的四组典型的红外与可见光图像融合结果对比图。 图7第一列为Kaptein_1123红外与可见光图像融合结果。 第一行和第二行表示待融合源图像, 第三行到第九行分别为DTCWT方法、 CVT方法、 FPDE方法、 LatLRR方法、 VGG-19方法、 Resnet50方法以及本方法融合结果。 可以看出, DTCWT方法和CVT方法融合结果红框内的目标对比度较差, 绿框内的树出现了伪影现象。 FPDE方法引入较多噪声。 LatLRR方法融合结果绿框中树的细节显示非常模糊。 VGG-19方法、 Resnet50方法以及本方法的融合结果, 目标信息保留较为完整, 引入噪声和伪影较少, 但本方法在对比度、 突出目标方面优于其他两种方法。 所以, 本方法在突出目标信息、 边缘保持和对比度方面具有很好的优势。
 | 图7 四组典型的红外与可见光图像融合结果Fig.7 Four sets of typical infrared and visible image fusion results |
图7第二列为Lake红外与可见光图像融合结果。 可以看出, FPDE方法在红色框内的目标受可见光图像的影响, 没有很好的突出目标信息。 DTCWT方法CVT方法融合结果在绿框内草中引入了噪声。 LatLRR融合结果在绿框内的植物难以辨认, 只保留了轮廓特征。 VGG-19方法、 Resnet50方法以及本方法的融合结果相对较好, 但本方法更好的保持了源图像目标信息, 地面上的草地清晰度较高, 更好的保留目标的边缘信息, 视觉效果好。
图7第三列和第四列分别表示Jeep_in_front_of_house和Man_in_doorway红外与可见光图像融合结果。 可以看出, 上述融合方法均取得较好融合结果, 但相比较而言, 本方法融合结果具有很高的辨识度, 保留较多源图像中的细节信息, 目标比较突出边缘特征信息完整和对比度较高。
表1为最典型一组实验(第三列图像)的五个客观评价指标值。 表2为四组实验图像的五个客观评价指标平均值。 从表中可以看出, 与其他六种方法相比, 本方法在评价指标EN, MI, MS-SSIM, SCD和SD上都有不同程度的领先。 从方法运行时间上看, 本方法耗时虽然相对较高, 但是低于基于LatLRR的复杂多尺度方法, 略高于基于深度学习的VGG-19与Resnet50方法。
| 表1 典型图像的客观评价结果(第三列图像) Table 1 Objective evaluation results of typical images (Third column images) |
| 表2 图像评价结果的指标平均值 Table 2 Average value of indicators for image evaluation results |
提出一种基于二尺度分解和显著性提取的红外与可见光图像融合方法。 用二尺度分解方法将源图像分解为基本层和细节层, 针对基本层融合采用基于VSM的加权平均融合规则, 该规则有效克服直接使用加权平均策略的对比度损失问题; 针对细节层融合采用Kirsch算子获取显著图, 很好保留了源图像细节边缘信息和抵制噪声, 引入VGG-19网络获取权值图, 使融合图像中包含更多显著细节信息。 与目前主流的红外与可见光融合方法对比, 本融合方法结果具有高对比度、 目标突出、 细节信息丰富和图像边缘特征保持较好等优势。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|