




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
矿石拉曼光谱模型拟合分类方法
[夏桐 , 刘一伟, 高远, 程杰
, 刘一伟, 高远, 程杰* , 殷建]
, 刘一伟, 高远, 程杰, 殷建]
|
|


作者简介: 夏 桐, 1998年生,山东大学(威海)机电与信息工程学院硕士研究生 e-mail: tongxia@mail.sdu.edu.cn
拉曼光谱因具有简单、 快速及无损等特点, 非常适合矿石的分类与鉴别。 拉曼光谱模型拟合分类方法无需构建参考光谱库且避免了复杂的逐项光谱匹配, 具有明显的优势。 然而, 已有的基于机器学习及深度学习的矿石拉曼光谱分类研究所采用的学习模型比较单一, 缺乏具有参考意义的综合比较。 对基于机器学习及深度学习的矿石拉曼光谱模型拟合分类方法进行综合评估验证, 对比了KNN, XGBoost, SVM, RF四种传统机器学习方法和CNN, DNN, RNN三种深度学习模型在RRUFF矿物拉曼光谱数据集上的分类效果, 验证了4种数据预处理方法和样本量对模型分类效果的影响。 为提升机器学习模型的分类性能, 本文还提出了一种拉曼光谱强度曲率的数据预处理方法, 对经基线矫正后的拉曼光谱序列强度计算曲率作为构造特征, 使模型更有效的提取出拉曼光谱的特征峰位置。 实验结论: 数据预处理对提升机器学习模型的分类性能效果明显, 而对深度学习模型不敏感; 样本量为影响模型分类效果的关键因素, 当样本量较大时, 深度学习模型的分类效果优于传统的机器学习模型; 对于微小样本, 深度学习模型难以发挥其优势, 而辅以预处理的机器学习具有更优的分类性能。
Due to simplicity, rapidity and non-destructiveness, Raman spectroscopy is very suitable for mineral classification and identification. A Raman spectral model-fitting method does not need to build a reference spectral database and complex spectral matching, which is advantageous in mineral classification. However, there is a lack of comprehensive comparison of the existing model-fitting methods based on machine learning and deep learning since they use relatively single-learning models. To this end, this paper comprehensively evaluates the model-fitting classification methods of mineral Raman spectral using the RRUFF mineral Raman spectrum dataset. It compares the classification performance of four traditional machine learning methods of KNN, XGBoost, SVM, and RF, and three deep learning models of CNN, DNN, and RNN, as well as four data preprocessing methods and sample size on the classification effect. To improve the classification performance, we also propose a data preprocessing method of Raman spectral intensity curvature, which calculates the curvature of the baseline-corrected Raman spectral sequence intensity as a construction feature so that the model can extract the position of the spectra peaks more effectively. The experimental results showed that data preprocessing greatly improved the classification performance of machine learning models but had little effect on deep learning models. Additionally, the size of the sample is a key factor of the model performance. When the size is large, the deep learning models outperform the traditional machine learning models, whereas when the size is small, it is difficult for the deep learning models to exert their advantages, while the traditional machine learning models combined with data preprocessing work better.
矿石材料包含了复杂的物质信息[1], 发现和识别这些信息在众多应用领域, 如行星探测、 矿物勘探、 以及文化遗产研究等中具有重要意义[2]。 然而, 由于矿物的结构多样性和复杂性, 矿物种类的鉴定过程通常非常复杂且具有破坏性, 而拉曼光谱因其简单、 快速以及无损[3]等特点, 在矿石的分类与鉴别上具有突出的优势。 因而, 基于拉曼光谱的矿物分类与鉴别成为近年来的热点研究与应用。
基于拉曼光谱的物质分类方法大致可分为两类: 光谱匹配方法和模型拟合方法。 光谱匹配方法其主要思想是构建一个参考光谱库, 每次分类需将待检物的光谱与库中参考光谱进行逐一匹配, 根据匹配度确定待检物的类别。 此方法通常需要依赖人工或匹配软件, 如CrystalSleuth(https://rruff.info/about/about_software.php)来实现大规模的光谱匹配; 同时, 由于同种物质的光谱也存在差异性, 仅通过与单一光谱的匹配度难以将矿物进行准确分类[2]。
与光谱匹配方法不同, 模型拟合方法无需构建参考光谱库以及进行逐项光谱匹配, 而是根据已知矿物的拉曼特征峰拟合拉曼谱线模型。 用户使用时, 只需将待检物的拉曼光谱数据输入拉曼谱线模型, 即可输出最符合待检物拉曼特征的矿物类别。 同时, 该方法关注一类矿物的光谱特征而非单一物质的拉曼光谱, 可获得更为准确的分类效果。
近年来, 机器学习被广泛应用于拟合模型的构建, 如: Ishikawa等[4]基于人工神经网络方法实现了火山岩矿石的关键矿物准确分类, 平均分类准确率达到了83%; Zhang等[5]基于Bio-Rad的数据库, 采用迁移学习方法开发了一种矿石分类模型, 分类准确率达到了96.4%; Sattlecker等[6]也证明了SVM模型在拉曼光谱分类问题上的优良性能。 然而, 上述研究所采用的机器学习模型比较单一, 缺乏具有参考意义的不同模型的综合比较。
为提供更为全面的模型研究, Jahoda等[7]比较了KNN, SVM, Trees, WN和CNN方法在RRUFF[8]数据集上的分类性能, 但是缺少对RNN、 DNN等深度学习方法的验证。 Liu等[9]提出一种基于卷积神经网络的拉曼光谱分类方法, 涉及到众多模型, 但其研究以深度学习模型为主, 缺少对机器学习方法以及预处理方法的研究。 该研究认为, 在RRUFF光谱数据集上, 基于卷积神经网络的模型分类精度优于传统机器学习方法, 且无需数据预处理过程, 因而使用门槛更低[9]。 但是, 深度学习模型依赖大量训练样本, 而实际应用中, 同类物质的拉曼光谱数据样本通常难以达到足够的规模, 小样本数据集将极大限制基于深度学习的模型分类精度。 而传统机器学习模型可使用少量实验样本达到与大量样本相近的分类性能[4], 若结合正确的数据预处理可达到更为理想的分类效果, 即机器学习对于小样本拉曼光谱数据分类具有更好的性价比。 所以, 深度学习与传统的机器学习方法对基于模型拟合的矿石拉曼光谱分类是各具优势的。
本文旨在为基于机器学习和深度学习的矿石拉曼光谱模型拟合分类方法提供较为全面和综合的验证和对比, 所对比的模型涵盖K近邻(KNN)、 XGBoost、 支持向量机(SVM)、 随机森林(RF)等常用的机器学习算法, 和深度神经网络(DNN)、 卷积神经网络(CNN)、 循环神经网络(RNN)等深度学习算法, 是目前比较全面的矿物拉曼光谱模型拟合分类研究。
为探究适用于矿石拉曼光谱分类问题的数据预处理方法, 提高机器学习模型的分类精度, 本文还提出一种新的数据预处理方法, 即: 经基线矫正后, 计算拉曼光谱曲线的多点曲率, 目的是更有效地提取出拉曼光谱的特征峰的位置, 使算法更加关注特征峰。 本文还基于RRUFF数据集测试了强度曲率以及其他预处理方法, 如PCA特征降维[10]、 数据增强、 归一化等对各模型分类效果的影响。
实验采用RRUFF数据集(https://rruff.info/)。 RRUFF是由亚利桑那大学建立的一个开源的矿物拉曼光谱数据库, 其目标是创建一个涵盖地球上所有已知矿物的拉曼光谱数据库, 为基于拉曼设备的矿物种类鉴定提供数据基础。 RRUFF数据库中的每个矿石种类的光谱数据均在相同的环境下采集得到, 即采集同一种矿石的数据时所使用的矿石样本相同、 采集仪器相同、 采集方式相同, 光谱数据所受采集环境因素影响相对较小, 因而具有较高的参考价值[11]。
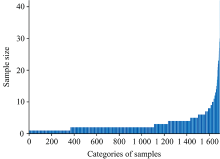
RRUFF数据集根据是否定向和是否经过预处理将数据整理为四个数据集[5], 实验选用了经过预处理且包含不同波长的非定向标准拉曼光谱数据集Excellent_Unoriented, 此数据集包含1684种矿石物质由不同波长的激光激发出的共5244组光谱数据, 数据集中的每条光谱数据都通过Razor库(http://www.spectrumsquare.com)进行了基线矫正处理, 基线矫正的内容包含消除宇宙射线和边缘对齐, 每种矿石的数据有1到42条不等, 其中大多数类别的光谱样本量小于10, 极少数类别的样本量能达到40条以上, 图1为实验数据集各类别的样本量分布情况[9], 横坐标为矿物类别, 包括1 684种矿物, 纵坐标为每种矿物类别所包含的数据样本数量。
 | 图1 数据集中各类矿物的光谱样本量[9]Fig.1 The number of spectral samples of each mineral in the whole dataset |
本文实验环境采用Inter Core i7-9700K CPU, NVIDIA GeForece GTX 1070 GPU, 32GB 2133MHz计算机内存。 系统环境使用Python 3.7, Numpy, Scipy, Sckit-learn等运算库[12]; 深度学习模型基于TensorFlow 2.2.0后端, Keras 2.4.3框架[13]。
原始数据集中每一条光谱数据对应一个矿物样本及其拉曼光谱曲线, 其中拉曼光谱曲线为拉曼谱线上的二维离散数据点的集合。 为方便理解, 将离散点数据对应为二维坐标, 其中, 纵横坐标分别表示光谱强度和拉曼位移。 对拉曼光谱源数据的预处理包括4个步骤: 数据增强、 插值处理、 强度曲率和归一化。
1.2.1 数据增强
由图1可以看出, 各类矿石光谱数据分布极不均衡, 各类别的样本数量差异较大, 这种差异将使机器学习算法可能会偏向于大样本类别而忽略小样本类别, 造成预测误差[14], 为此需进行数据增强。
采用Liu[9]等提出的随机增加小距离位移和叠加高斯噪声的数据增强方法, 即: 对于需要增强的光谱数据, 随机进行不大于1 cm-1距离的左右位移, 在新生成的光谱上叠加均值为0、 方差为0.5的高斯噪声。 由此, 使原本数据样本低于42条的类别增强到42条。
1.2.2 插值处理
本文将矿物样本的拉曼光谱曲线作为模型的输入, 对应的矿物种类作为输出。 为统一输入格式, 需对拉曼曲线进行插值处理, 目的是获得每个拉曼曲线在一组固定拉曼位移上的强度序列, 即统一光谱曲线的输入维度。
由于拉曼曲线离散点分布密集, 本文采用了简单的线性插值方法。 对任意拉曼光谱样本, 设其拉曼位移集合为X={x1, x2, …, xn}, n为数据点数量, 对应的拉曼强度集合为Y={y1, y2, …, yn}, 插值后的拉曼位移数据点m个, 拉曼位移集合为X*={
1.2.3 强度曲率
拉曼光谱特征峰的位置在拉曼光谱的分类识别中起到了至关重要的作用[15]。 基于此, 提出一种数据预处理方法: 将拉曼光谱强度曲线的曲率作为新的输入特征纳入模型训练。
对任意包含n个点数据的拉曼光谱样本集, 其拉曼位移集合为X={x1, x2, …, xn}, 拉曼强度集合为Y={y1, y2, …, yn}, 处理后得到的拉曼强度曲线的曲率为Y'={y'1, y'2, …, y'n}, 对于每一个离散点(x'i, y'i), 有与其左右相邻的原始拉曼数据点(xj, yj)和(xk, yk), 按照如式(2)关系构造曲率。
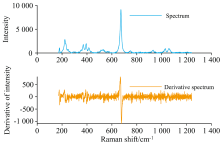
由于拉曼光谱中特征峰位置对应的强度曲率绝对值较大, 因而此方法可以更有效地提取出拉曼光谱的特征峰的位置。 图2展示出同一光谱的原始光谱曲线与强度曲率的对比, 可以看到拉曼光谱曲线求曲率后特征峰强度变化被放大的效果。
 | 图2 拉曼光谱强度和拉曼强度曲率Fig.2 Raman spectrum and curvature of Raman spectrum |
1.2.4 归一化
为了尽可能减小由拉曼光谱强度差引起的模型预测误差, 将每条光谱数据的拉曼强度进行归一化处理。 对任意拉曼光谱样本, 设其光谱强度的最大值为max, 最小值为min, 将样本中任意强度为y的拉曼强度归一化为数值范围为[0, 1]的强度y*, 归一化公式如式(3)
归一化使模型训练更关注拉曼强度的强度变化而非强度值的大小, 更有助于模型识别特征峰。
为实现拉曼光谱智能分类, 本文选用了目前较为常用的K近邻(KNN)、 XGBoost、 支持向量机(SVM)、 随机森林(RF)四种机器学习模型和卷积神经网络(CNN)、 深度神经网络(DNN)、 循环神经网络(RNN)三种深度学习模型。
1.3.1 机器学习模型
对于四种机器学习模型SVM, XGBoost, KNN和RF, 模型参数均取多次测试的最优值。 在调参实验中, 采用网格参数辅助函数得到全部参数的可选值的所有组合, 对于每一种组合使用3折交叉验证方法, 每次随机选取2条数据用于测试, 最终评选出预测准确率最高的参数组合进行后续实验。 各模型调参结果如下:
(1) XGBoost: 学习率learning_rate值取为0.2, 决策树的个数n_estimatores=80, 树的深度max_depth=2, 孩子节点的样本权重和最小值min_child_weight=2。
(2) KNN算法: 邻居的数量K是唯一影响模型效果的参数, 在当前数据集上K的最佳取值为1。
(3) 在SVM的多种核函数中, 线性核函数对矿石拉曼光谱分类具有最好的预测效果。
(4) RF模型: n_estimators参数控制模型训练过程中生成多少棵树, max_ depth参数控制每棵树的最大深度。 实验得到的最优参数组合为: n_estimators=35、 max_depth=65。
1.3.2 深度学习模型
为探究深度学习对拉曼光谱的分类效果, 本文比较了三种不同的深度学习模型, 分别是深度神经网络(DNN)、 卷积神经网络(CNN)和循环神经网络(RNN)。 三类模型均使用“类别交叉熵”作为损失函数, 选择Adam作为优化算法, 输入特征维度为M, 矿石物质类别数为N。
(1)DNN
借鉴了Zhang等[5]的DNN模型, 共三层全连接神经网络, 结构如图3所示。 三层全连接神经网络神经元数分别为M, 2M和N, 第二层后接系数为0.5的Dropout层, 激活函数为Tanh, 最后一层激活函数为Softmax。 学习率为0.000 01, 训练100次。
 | 图3 用于光谱识别的DNN模型结构示意图Fig.3 Diagram of the DNN model for spectrum recognition |
(2)CNN
借鉴了Lecun等[16]提出的LeNets模型, 如图4所示, 共五层神经网络。 由于数据样本量较小, 模型中未使用池化层。 第1层为一维卷积层, 共16个滤波器, 卷积核大小为9。 第2层为一维卷积层, 有8个滤波器, 卷积核大小为16。 第3层为一维卷积层, 有4个滤波器, 卷积核大小为25。 后两层为全连接层, 神经元个数分别为2M和N。 第4层后接系数为0.5的Dropout层。 激活函数为Relu, 最后一层激活函数为Softmax。 学习率为0.000 01, 训练200次。
 | 图4 用于光谱识别的CNN模型结构示意图Fig.4 Diagram of the CNN model for spectrum recognition |
(3)RNN
借鉴了Hochreiter等[17]提出的LSTM模型, 共三层神经网络, 结构如图5所示, 其中前两层为LSTM层, 后接系数为0.5的Dropout层。 最后一层为全连接层, 神经元个数为N, 激活函数为Softmax。 学习率为0.000 01, 训练200次。
 | 图5 用于光谱识别的RNN模型结构示意图Fig.5 Diagram of the RNN model for spectrum recognition |
本节实验用来评估特征降维、 数据增强、 强度曲率以及归一化4种数据预处理方法的必要性, 将上述方法预处理前后的各模型分类准确率作为评估标准。
为避免实验的偶然性, 所有实验的测试集与训练集均采用随机划分方式, 且所有的实验结果都经过5次重复实验验证。 为保证参与实验的每个类别都包含两条测试集并且至少有两条训练集, 实验删除了数据集含量少于4条的微小样本类别。 具体的测试集划分方式为: 遍历所有类别, 每个类别随机抽取两条数据加入测试集, 剩余数据纳入训练集。
2.1.1 机器学习模型性能
由于拉曼光谱数据作为输入时维数较高, 所以实验前本文结合主成分分析(PCA)对数据进行特征降维, 目的是过滤掉原始的高维特征中冗余部分, 提高预测效果减少训练时间[10]。 特征降维前数据集的维度是1131, 保留99.9%的方差对数据集进行特征降维后, 数据集的维度减少到180左右。 其余三种预处理均按照第一章所述方法, 4种预处理方法使用前后对比实验效果如图6所示, 纵坐标表示每次实验的测试集准确率, 其中, 图6(a)为PCA处理前后四种机器学习模型的分类准确率对比, 图6(b)为采用原始强度和强度曲率机器学习模型的分类准确率对比; 图6(c)与(d)分别为数据增强和归一化处理前后分类准确率的对比。
 | 图6 数据预处理前(蓝)后(粉)的分类准确率对比Fig.6 Comparison of classification accuracy before (blue) and after (pink) data preprocessing |
由图6(a)可知, XGBoost和RF模型在结合PCA特征降维后, 分类效果都有显著提升; 但PCA特征降维对KNN和SVM影响不大; 然而, 由于特征降维操作缩短了四种方法的训练时间, 所以本文认为KNN, XGBoost, RF和SVM四种方法均适合采用PCA特征降维。
根据图6(b), 强度曲率相对原始强度对四种机器学习模型的分类准确率均有提升, 且XGBoost和KNN提升幅度较大。 此实验验证了强度求曲率对基于机器学习的拉曼光谱分类的有效性。
如图6(c)所示, 数据增强对XGBoost, SVM和RF三种模型的分类准确度有大幅度提升, 但是对KNN方法的预测效果影响不大。
图6(d)表明, 经过归一化处理后, 四种机器学习模型的预测准确率均有大幅度提高。 此实验也证明了对于拉曼光谱分类问题, 归一化处理可以显著提升机器学习模型对特征峰的提取效果。
表1为以上实验的数据结果, 经过数据预处理后, 四种机器学习模型的预测精度均有18.3%~44.5%的提升, 其中准确率最高的SVM(linear)达到了85.8%, 比Liu[9]等的实验结果提升了约3.9%。
| 表1 数据预处理前后不同模型的分类精度 Table 1 Classification accuracy on different models when applying data preprocess versus not applying data preprocess |
2.1.2 深度学习模型性能
深度学习模型对样本数据量和训练次数均有较大依赖, 数据量不足将难以保证深度学习模型得到好的训练效果[14]。 为避免微小样本类别干扰深度学习模型的分类效果, 实验依次删除了数据集中样本量过少的类型数据, 并将经过增强后的数据纳入模型训练。
图7为不同样本数量下的数据增强前后三种深度学习模型分类准确率对比, 对于小样本数据集, 各类深度学习模型经过数据增强后其分类精度均有显著提升; 随着样本量的差距缩小, 该提升幅度也逐渐减小。 由于拉曼光谱数据集中大部分类别的样本量比较少, 若不经过数据增强, 深度学习模型难以充分学习到样本特征, 经过数据增强后有更多的样本可用于模型的训练, 因而分类效果更好。
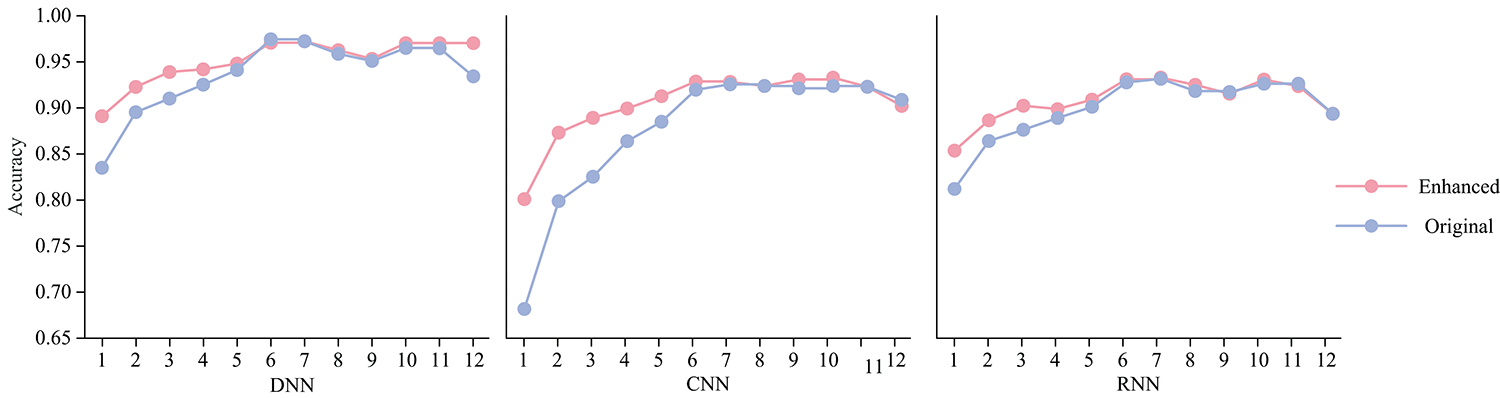 | 图7 数据增强前后三种模型的分类精度Fig.7 Classification accuracy of the three models before and after applying data enhancement |
本文同样探究了不同预处理方法对深度学习模型分类效果的影响, 分别将未经过处理、 归一化处理、 曲率、 和曲率& 归一化处理后的数据集纳入构建的DNN, CNN和RNN模型进行训练, 实验数据结果如表2, 表3和表4所示, 可以看出, 强度曲率和归一化处理模型的分类准确率变化不大, 说明深度学习模型对预处理不敏感, 这与Liu等[9]的研究结论一致。
| 表2 样本数量、 数据预处理方法对DNN模型分类准确率的影响 Table 2 The influence of data preprocessing and sample size on the classification accuracy of DNN model |
| 表3 样本数量、 数据预处理方法对CNN模型分类准确率的影响 Table 3 The influence of data preprocessing and sample size on the classification accuracy of CNN model |
| 表4 样本数量、 数据预处理方法对RNN模型分类准确率的影响 Table 4 The influence of data preprocessing and sample size on the classification accuracy of RNN model |
实验所采用的数据集中, 存在部分微小样本类别数据, 其样本量仅为1~2条, 对于这部分类别, 显然无法进行有效的模型训练。 为此, 本文依次删除了数据量过少的类别。 为探究每个类别至少需要多少条数据才能达到预期的分类效果, 本文设置了以下实验: 从保留拥有4条数据的类别开始, 依次删除数据量最少的类别, 每个类别随机选取两条数据加入预测集, 其余作为训练集并数据增强处理, 将训练集输入模型进行训练, 以模型在测试集上的预测准确率作为评估标准进行分析。
2.2.1 机器学习模型
表5为四种机器学习模型在保留不同样本量的数据集上的预测效果, 表中列出数据集所保留的各类别样本量最小值, 例: “4”表示数据集中保留了所有样本量不少于4条的类别。 为避免实验的偶然性, 实验的测试集与训练集都采用随机划分的方式, 表中数据为五次重复实验的平均值。
| 表5 不同样本数量下的KNN, XGBoost, SVM, RF模型分类准确率 Table 5 Classification accuracy of KNN, XGBoost, SVM, RF in different sample sizes |
由实验结果可知, 四种机器学习模型KNN, XGBoost, SVM和RF分别在保留类别最小样本量为9, 7, 5和6条时预测准确率达到90%以上。
对于样本量为4条的微小样本集, SVM结合PCA特征降维的预测效果最好, 达到85.51%, 其次为RF结合PCA特征降维, 能够达到83.15%。 实验表明, 删除微小样本类别可以提升机器学习方法的预测效果, 对基于机器学习模型的矿石拉曼光谱分类方法, 删除数据量较少的类别是有必要的。
2.2.2 深度学习模型
对于深度学习模型, 本文在只经过插值处理的矿石拉曼光谱数据集中每个类别随机选择两条数据加入预测集, 其余作为训练集, 从保留含有两条数据的类别开始, 依次删除最少数据集的类别, 对构建的深度学习模型进行测试, 实验结果如表6所示。
| 表6 不同样本数量下的三种深度学习模型分类准确率 Table 6 Classification accuracy of DNN, CNN and RNN in different sample sizes |
实验结果表明, 删除小样本类别数据后, 深度学习模型精度有较大提升, 尤其是当删除样本数为9条以下的类别后, DNN, CNN和RNN的识别精度分别为97.34%, 95.69%和96.83%, 此三种模型中, DNN模型略有优势。
针对机器学习方法的矿石拉曼光谱智能分类算法进行了较为全面的综合比对, 比对的算法包括SVM, XGBoost, RF和KNN传统机器学习模型和CNN, DNN和RNN深度学习模型, 并且测试了数据预处理与PCA特征降维对各种分类算法的影响。 实验结果表明, 对传统机器学习模型, 有效的数据预处理是必要的, 归一化、 强度曲率等预处理方法能有效提升模型的分类效果。 深度学习算法无需数据预处理提取特征, 但是对于微小样本数据集, 数据增强是必要的。
经过对几种方案的分类准确度测试, 目前在RRUFF矿物拉曼光谱数据集上分类效果最好的传统机器学习模型是SVM(linear)模型, 效果最好的深度学习模型是DNN。 无论是机器学习还是深度学习模型, 样本量均为影响模型分类效果的关键因素, 当样本量较大时, 深度学习模型的分类效果优于传统的机器学习模型; 对于微小样本, 深度学习模型难以发挥其优势, 对于此类样本数据, 结合预处理的机器学习具有更好的容忍性。
采用去尾方式来降低其对模型分类效果的负面影响, 但是微小样本数据有助于模型识别更多的矿物种类, 接下来将考虑采用迁移学习等方法充分利用这些微小样本数据以提升模型的分类效果。 此外, 矿石成分与结构是矿石分类的重要依据, 结合矿石成分结构信息进行针对性的特征筛选是提升模型分类效果和特征降维的有效途径, 所以将矿石成分结构信息融入分类模型是本文后续研究的另一个改进方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|