

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
中红外光谱结合机器学习对不同产地平菇鉴别
[杨承恩1  , 苏玲
, 苏玲2 , 冯伟志1 , 周建宇1 , 武海巍1, * , 袁月明1 , 王琦2, * ]
, 苏玲, 袁月明]
|
|


作者简介: 杨承恩, 1996年生,吉林农业大学工程技术学院硕士研究生 e-mail: 928618077@qq.com
平菇味道鲜美、 营养丰富, 深受消费者喜爱。 平菇在我国的栽培范围较广, 产地分散, 每个产地的气候条件、 栽培基质、 栽培方式的差异, 使不同产地生产的平菇在口感、 营养价值方面会有不同。 为规范平菇产品的市场管理, 更为打造区域内特色平菇品牌, 借助中红外光谱技术无污染、 高效、 低成本等特点, 突破目前化学分析、 生物学鉴别方法的限制, 提出一种中红外光谱结合机器学习鉴别不同产地平菇的方法。 对10个不同产地的平菇子实体进行红外光谱数据采集, 每个地区各60份共600份样本。 光谱数据经分析表明, 在波段530~1 660 cm-1范围内红外光谱的相关性表现出较明显的差异。 同时, 基于K-S法按照训练集和测试集比例为7∶3对样品划分, 得训练集为420份, 测试集为180份。 采用多元散射校正(MSC), 标准正态变量变换(SNV), 平滑(SG), 一阶导数(FD), 二阶导数(SD)等预处理方法进行光谱优化, 去除噪声, 并结合支持向量机(SVM)进行初步建模对比, 得出MSC预处理后光谱数据差异性最大, 预测集识别效果最好为84.44%。 将MSC光谱数据进行0~1区间的归一化处理, 并采用主成分分析(PCA)对其进行降维, 选择满足训练集中主成分个数累积贡献率≥85%, 且主成分方差百分比≥1%的前7个主成分作为输入变量与支持向量机(SVM)、 随机森林(RF)、 极限学习机(ELM)进行建模识别比较。 实验结果表明, 在识别不同产地平菇模型中, SVM模型识别效果最佳, 训练集和测试集识别率均为100%; RF模型训练集识别率为100%, 测试集识别率略低, 为98.89%; ELM模型对比其他模型识别率较差, 训练集识别率为99.28%, 测试集识别率为98.33%。 3种模型的识别率均高于98%, 说明采用红外光谱结合机器学习的方法可以简单、 快速、 低成本的实现对不同产地平菇的鉴别, 不仅为平菇产品产地识别提供方法依据, 也为其他种类食用菌产品的产地鉴别提供参考。
Pleurotus ostreatus is popular with consumers because of its delicious taste and rich nutrition. Pleurotus ostreatus is widely cultivated in China, and its producing areas are scattered. The differences in climate conditions, cultivation matrix and cultivation mode of each producing area make the Pleurotus ostreatus produced in different producing areas different in taste and nutritional value. In order to standardize the market management of Pleurotus ostreatus products and create regional characteristics of Pleurotus ostreatus brands, with the help of the characteristics of non-pollution, high efficiency and low cost of mid-infrared spectroscopy, this paper broke through the limitations of chemical analysis and biological identification methods at present, and put forward a method of identifying Pleurotus ostreatus from different producing areas by mid-infrared spectroscopy combined with machine learning. The infrared spectrum data of fruiting bodies of Pleurotus ostreatus from 10 different producing areas were collected, and 60 samples were collected from each area. The analysis of the spectral data showed that the correlation of the infrared spectra showed significant differences in the band 530~1 660 cm-1. At the same time, based on the K-S method, the samples were divided according to the ratio of the training set to test set of 7∶3, 420 training sets and 180 test sets were obtained. Multiplicative scatters correction (MSC), standard normal variable transformation (SNV), Smoothing(SG), first derivative (FD), second derivative (SD) and other preprocessing methods were used to optimize the spectrum and remove the noise. In addition, it combined with a support vector machine (SVM) for preliminary modeling comparison. It was concluded that the difference in spectral data after MSC pretreatment was the largest, and the recognition performance of the prediction set was the best at 84.44%. The MSC spectral data is normalized in 0-1, and principal component analysis (PCA) was used to reduce the dimension. The first seven principal components, which satisfy the cumulative contribution rate of principal components in the training set ≥85% and the variance percentage of principal components ≥1%, were selected as input variables for modeling identification comparison with support vector machine (SVM), random forest (RF) and extreme learning machine (ELM). The experimental results showed that the SVM model had the best recognition effect in identifying Pleurotus ostreatus models from different producing areas, and the recognition rate of the training set and test set was 100%. The recognition rate of the RF model training set was 100%, and the recognition rate of the test set was slightly lower, 98.89%. Compared with other models, the recognition rate of the ELM model was poor, the recognition rate of the training set was 99.28%, and that of the test set was 98.33%. The recognition rates of the three models were all higher than 98%, indicating that the identification of Pleurotus ostreatus from different producing areas can be realized, quickly and at low cost using infrared spectroscopy combined with machine learning. This provided a method basis for the producing areas identification of Pleurotus ostreatus products and a reference for the identification of other kinds of edible fungi products’ producing areas.
平菇(Pleurotus ostreatus)也称糙皮侧耳, 中国台湾又称秀珍菇, 分类学上将其划分为担子菌门、 伞菌目、 侧耳科、 侧耳属[1]。 因其价格便宜, 味道鲜美非常受大众喜爱。 近年来, 我国平菇产业发展迅猛, 目前是我国产量前三位的食用菌大宗品种, 在全国大部分省、 市、 地区均有栽培。 实际生产中全国各地的平菇因为成本问题, 往往采用当地农作物废料作为培养平菇的基质, 不同的基质和当地独有的农业特点往往导致不同地区平菇营养价值各具特色[2, 3]。 龙瑞等经过对不同地区平菇分析得出不同主栽地区平菇各有自己的营养价值优势[4]。 不同地区气候、 栽培方式差异也影响着平菇的口感、 营养成分含量。 消费者很难从外观进行其产地的判别, 为有序进行平菇产品的规范管理, 打造区域特色平菇品牌, 开发可实现简单、 快速、 低成本的平菇产地鉴别方法迫在眉睫。
傅里叶变换红外光谱(Fourier translation infrared spectroscopy, FTIR)技术具有绿色、 高效、 低成本的特点和优势[5, 6], 在检测和识别农作物种类、 地区方面已有许多研究报道。 陈林杰等[7]通过中红外光谱指纹区对不同产地桑黄进行分析; 李超等[8]通过红外光谱的图谱解析对不同产地苍术进行快速判别; 安淑静等[9]基于中红外光谱结合化学计量学对7种产地山茱萸鉴定与分析等等。 目前, 尚未见傅里叶中红外光谱鉴别平菇产地的研究报道, 本研究基于傅里叶中红外光谱技术的特点与机器学习建模, 开发一种简单、 快速、 低成本的平菇产地判别方法, 以解决平菇由“量产”升级转型向“优产”的产业需求。
选取由国家食用菌产业技术体系各综合试验站, 提供并鉴定的平菇样品, 共600份。 样品分布情况见表1。
| 表1 平菇样品采集信息 Table 1 Antler cap sample collection information |
主要设备: 美国Nicolet iS10傅里叶变换红外光谱仪, 便携式HY-12型压片机(天津天光光学仪器有限公司), 超帅高速多功能粉碎机型号CS-700(武义海纳电器有限公司), 200目不锈钢筛(江苏国业机械设备有限公司)等。
数据采用Omnic v8.2光谱采集软件、 The Unscrambler X 10.4、 Matlab2014b、 Origin2019b等数据处理软件进行处理。
首先用蒸馏水洗净平菇样品上的杂质, 置于干燥箱9~10 h脱水至恒重, 使用多功能粉碎机粉碎, 过200目筛, 同时将溴化钾放入75 ℃恒温干燥箱内烘6小时左右。
将每个样本以平菇1.8 mg和溴化钾190 mg放入玛瑙研钵中研磨, 再经红外压片模具压片测定, 采用Omnic v8.2软件采集中红外光谱数据。 波数范围400~4 000 cm-1, 分辨率为4 cm-1, 扫描次数为16, 每个样本重复扫描3次, 取平均光谱。 实验数据采集过程中, 保持室内温度为25 ℃, 相对湿度为38%RH。 实验采集10个不同地区平菇各60份样品, 共600份样品。
1.4.1 光谱预处理
在采集光谱信息时, 会因为样品本身、 光散射与基线漂移等因素产生随机的偏差。 光谱预处理技术不仅对原始光谱的噪声进行优化处理, 且可以提高对光谱数据处理的效率。 在与原始光谱对比的基础上, 采用The Unscrambler X 10.4软件对采集的原始光谱进行多元散射校正(multiplicative scatter correction, MSC), 标准正态变量变换(standard normal variable transformation, SNV), 平滑(smoothing, SG), 一阶导数(first derivative, FD), 二阶导数(second derivative, SD)等数据处理。
1.4.2 K-S检验样品划分
K-S检验(kolmogorov-stone, K-S)是一种能够选出充分符合样本分布规律且具有代表性数据的样本划分方法[10]。 按照训练集和测试集样品数为7∶ 3的比例, 用K-S法划分600份样品, 得训练集420份(不同地区平菇各42份), 测试集180份(不同地区平菇各18份)。
1.4.3 主成分分析
主成分分析(principal component analysis, PCA)是一种常见的无监督降维方法[11]。 针对中红外光谱数据量大, 冗余信息多的特点, 使用PCA降维分析可以减少无效数据的堆积并尽可能提取主要特征信息。
1.4.4 支持向量机
支持向量机(support vector machine, SVM)是一种非常有效的分类与预测算法[12]。 通过核函数将低维度中不可分的数据映射到一个高维度的n维欧式空间中, 就此寻找一个超平面求解分类问题。
1.4.5 随机森林
随机森林(random forest, RF)是一种具有集成思想的分类与预测算法[13]。 它将每一个单独的决策树汇集成决策森林, 从而产生“好而不同”的个体学习器, 并在保持准确性和多样性方面做出最优的分类与预测选择。
1.4.6 极限学习机
极限学习机(extreme learning machine, ELM)是一种基于经典神经网络改进后的快速学习算法[14]。 在训练阶段采用随机的输入层权值和偏差, 能够以极快的速度进行较好泛化, 具有选择参数少、 学习效果好、 适用性强的特点。
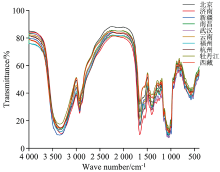
不同产地平菇中红外光谱图, 见图1。 在红外光谱中, 分析特征吸收峰是判断光谱差异的主要方式。 由图1可知, 在基因频率区中, 3 350 cm-1附近为O—H振动伸缩; 2 929 cm-1附近为—CH3和—CH2振动伸缩; 1 655和1 651 cm-1附近为CN3
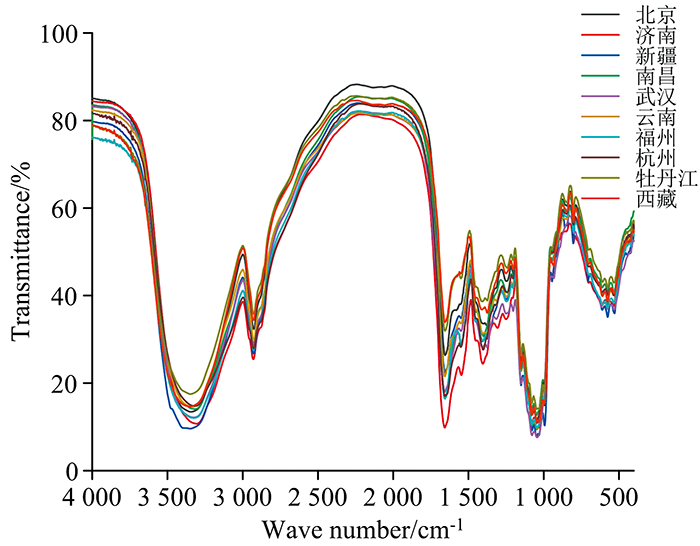 | 图1 不同产区的平菇平均光谱图Fig.1 Average spectra of pleurotus ostreatus in different producing areas |
经多种预处理后的光谱结合支持向量机进行建模对比如表2, 可知MSC预处理后的光谱数据建模识别效果最佳, 训练集识别率为86.67%, 测试集识别率为84.44%。
| 表2 光谱预处理方法对比 Table 2 Comparison of spectral pretreatment methods |
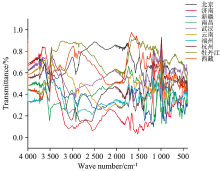
将MSC平菇光谱数据进行归一化处理, 设置数据映射范围为0~1(见图2)。 在python3.7平台上, 采用pandas库中的PCA函数对归一化后的训练集MSC平菇光谱数据进行主成分分析。 此处仅展示MSC全段光谱的前10个主成分方差百分比和累积贡献率如表3所示。 可知PCA1的方差百分比最大为53.9%, PCA2的方差百分比为13.85%, 前3个PCA的累积贡献率为79.09%, 直到前7个PCA的累积贡献率为97.51%, 之后的各PCA方差百分比都小于1%且累积贡献率提高速度逐步变小。
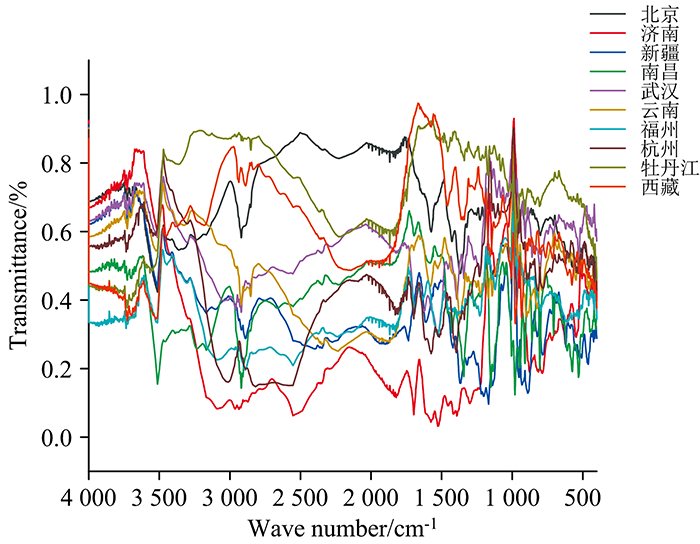 | 图2 归一化后的不同产地平菇数据Fig.2 Normalized data of pleurotus ostreatus from different habitats |
| 表3 前10个主成分的方差百分比和累积贡献率 Table 3 Variance percentage and cumulative contribution rate of the top 10 principal components |
在PCA降维过程中, 选择主成分的个数会直接影响机器学习建模后的分析结果。 采用主成分个数累积贡献率≥ 85%原则结合主成分方差百分比≥ 1%原则[15], 选择经PCA降维后的前7个主成分。
将经PCA降维后的前7个主成分光谱数据作为输入变量, 建立SVM, RF和ELM不同产地平菇识别模型。
2.3.1 SVM模型
支持向量机需要确定最佳惩罚因子(c)、 核函数参数(g), 及最优核函数。 此处采用粒子群优化算法(particle swarm optimization, PSO), 将变量C1初始值设为1.5来增加PSO参数局部搜索能力, C2初始值设为1.7增加PSO参数全局搜索能力, 最大进化数量初始值为200, 种类最大数量初始值为20, 种族更新弹性系数为1, 以此来寻找最佳c和g, 使用径向基核函数(radial basis function, RBF)作为最优核函数。
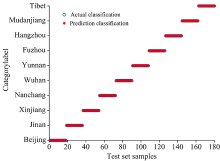
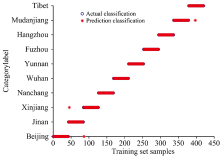
基于MSC-PCA平菇光谱数据建立SVM识别模型见图3(a, b), 可知SVM模型在训练集和测试集的识别率均为100%。 由此可得SVM对不同产地的平菇分类识别有着极好的效果。
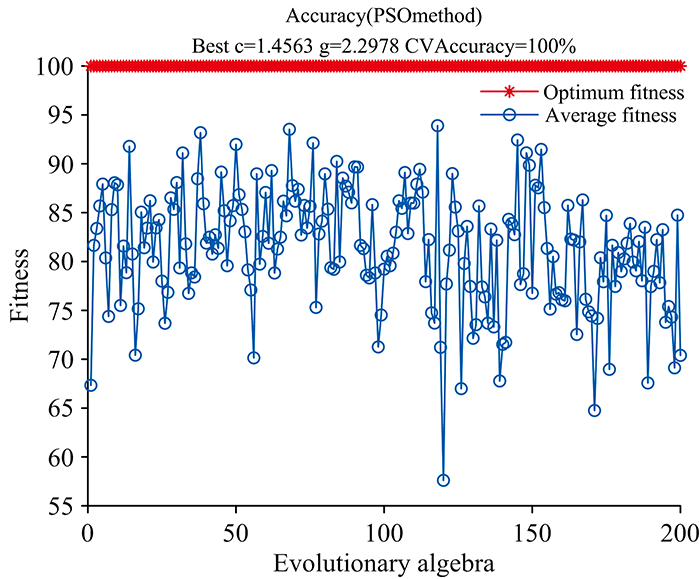 | 图3(a) 粒子群优化参数寻优适应度曲线Fig.3(a) Particle swarm optimization parameter optimization fitness curve |
 | 图3(b) SVM的测试集识别结果Fig.3(b) Test set recognition results of SVM |
2.3.2 RF模型
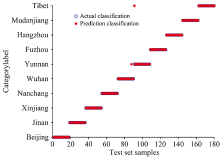
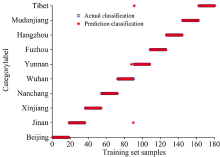
在RF模型中, 初始分类器的个数影响着最终建模分类的好坏, 本研究采用遗传算法寻找最优参数, 将遗传算法中待优化的变量个数设置为2, 个体数目设置为20, 最大遗传代数设置为200, 变量的二进制位数设置为10。 建立RF模型, 当决策树数量为540时模型识别效果最佳, 建模识别结果如图4(a, b)。
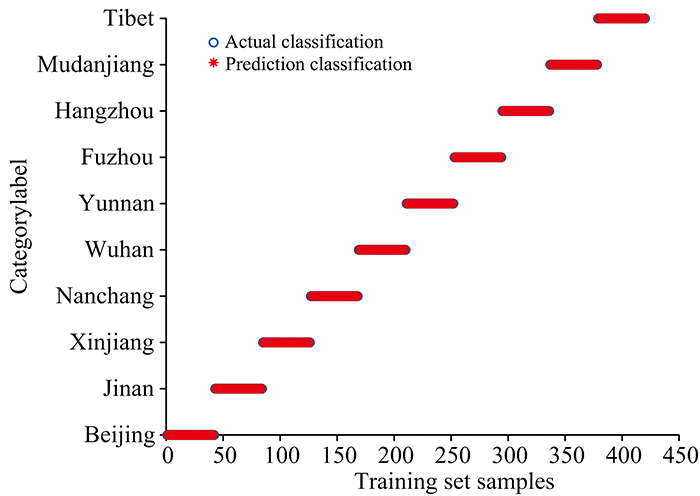 | 图4(a) RF的训练集识别结果Fig.4(a) Training set recognition results of RF |
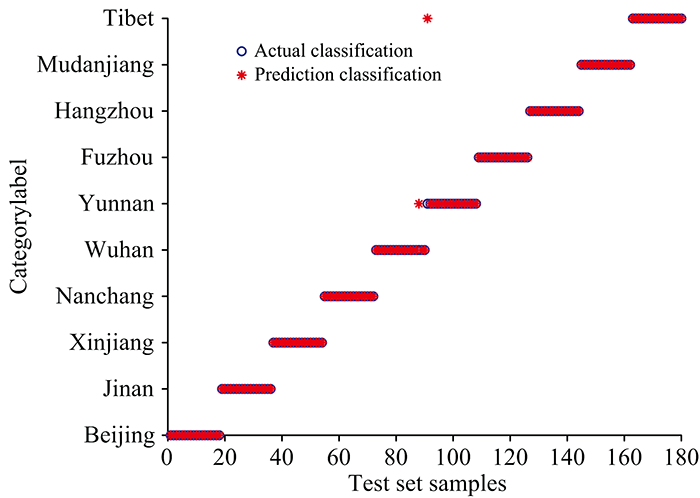 | 图4(b) RF的测试集识别结果Fig.4(b) Test set recognition results of RF |
由图4(a, b)可知, RF模型对不同产地的平菇识别效果较好, 训练集识别率为100%, 测试集识别率为98.89%, 仅有1份武汉地区平菇样品和1份云南地区平菇样品识别错误。
2.3.3 ELM模型
在ELM模型中, 随机输入的隐藏权值和隐藏偏差阈值会极大地影响ELM模型的识别准确率, 同时过多的隐层神经元个数又会增加模型识别的耗时时间。 选择sigmoidal函数作为激活函数, 设置隐层神经元个数为1~5 000, 步长为1进行对比寻找最优参数, 见图5(a, b)。
经计算对比, 当最优隐层神经元个数为1 252, ELM模型寻优速度快, 识别效果最好。 由图5(a, b)可知, 训练集识别率为99.28%, 有1份济南地区平菇样品和1份新疆地区平菇样品, 1份西藏地区平菇样品识别错误; 测试集识别率为98.33%, 有2份武汉地区平菇样品和1份云南地区平菇样品识别错误。 ELM模型识别率尚可。
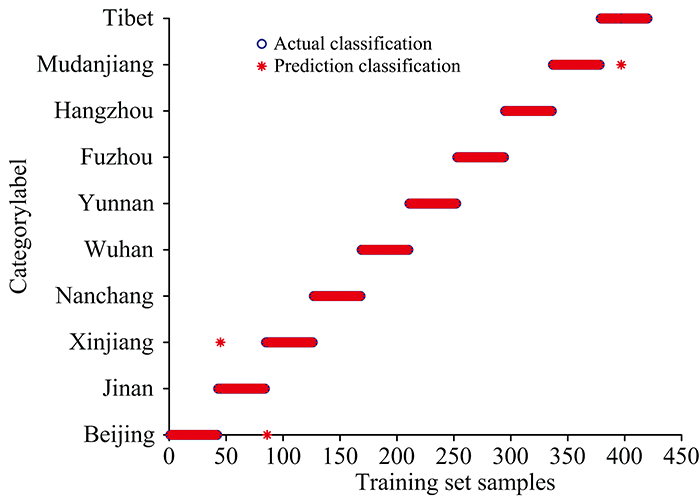 | 图5(a) ELM的训练集识别结果Fig.5(a) Training set recognition results of ELM |
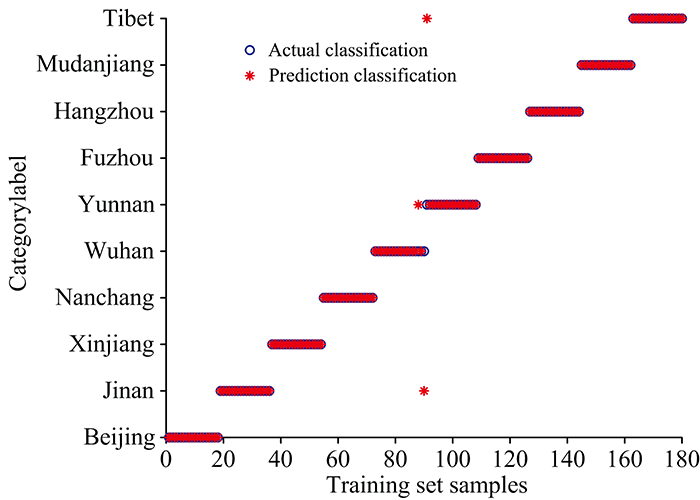 | 图5(b) ELM的测试集识别结果Fig.5(b) Test set recognition results of ELM |
基于中红外光谱结合机器学习, 提出一种对不同产地平菇快速鉴别的方法。
(1)受产地差异的影响, 来源于不同产地平菇在中红外光谱的530~1 660 cm-1波段内的相关性表现出明显差异。
(2)MSC-PCA平菇光谱数据结合SVM, RF, ELM都有不错的识别效果, 其中SVM模型训练集、 测试集识别率均为100%; RF模型训练集识别率为100%, 但测试集识别率稍低为98.89%; ELM模型相比其他模型识别率较差, 训练集识别率为99.28%, 测试集识别率为98.33%。 3种模型的识别率均高于98%, 说明采用红外光谱技术结合机器学习可以有效识别不同产地的平菇。
(3)中红外光谱结合机器学习, 特别是SVM模型能够更准确地鉴别不同产地平菇, 此方法的开发也可为其他种类的食用菌产品来源鉴别提供参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|