


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
尿液SERS分析快速评估人体能量摄入量
[韩晓龙1  , 林嘉盛
, 林嘉盛2 , 李剑锋2, * ]
, 林嘉盛, 李剑锋]
|
|


作者简介: 韩晓龙, 1980年生,中国航天员科研训练中心助理研究员 e-mail: iandsteoro@163.com;林嘉盛, 1994年生,厦门大学固体表面物理化学国家重点实验室博士研究生 e-mail: jackson_js17@163.com;
韩晓龙,林嘉盛:并列第一作者
人体能量摄入量与能量消耗量平衡是评估健康的标准之一。 不平衡的能量摄入量可能造成生物体组织细胞损伤、 机体过度肥胖等后果。 评估能量摄入量对人的身体健康管理具有重大意义。 目前评估能量摄入量的主要方法是膳食回顾法, 该方法不仅耗时长, 还会增加待评估人员的负担, 所以亟需开发一种简单快速的能量摄入量评估方法。 能量摄入后经过体内的消化代谢, 会产生代谢产物作为废弃物排出体外。 废弃物如尿液等, 含有大量的化学物种, 可以系统性反映生物体的饮食代谢状况和疾病进程。 基于高灵敏、 可无损检测两个组“指纹式”分子光谱特征的表面增强拉曼光谱(SERS), 采用谱峰统计、 无监督和有监督聚类算法分别对尿液的SERS信号开展分析, 最终实现对不同能量摄入量的聚类分析。 首先尝试对能量摄入量分组分别为1 500, 2 030和2 700千卡·日-1两个组的志愿者尿液SERS谱图进行谱峰分析, 发现很多有机分子的拉曼谱峰存在一定程度的重叠, 所以直接对谱峰进行解析及归属存在较大难度, 需要采用化学计量学的方法建立分类模型, 以实现良好区分和预测效果。 对比无监督的主成分分析(PCA)和有监督的正交偏最小二乘判别分析(OPLS-DA)两种算法的区分效果。 首先对原始光谱数据直接进行主成分分析, 发现模型中不同类别的散点分布存在较大程度的重叠, 这使得组别归类效果很差, 而经过一阶导数差分校正基线后, 模型呈现出可分类的趋势。 OPLS-DA算法通过预先设定 Y的标签及正交信号矫正处理, 能将 X矩阵信息分解成与 Y相关和不相关的两个组分, 集中表达相关的信息, 实现良好的分类效果。 结果表明, OPLS-DA算法可以对三种不同能量摄入量水平进行很好的归类, 而且每两组间也可以实现很好区分。 ROC分析结果表明敏感性和特异性均达到100%。 200次迭代的置换检验结果也说明了模型良好的可靠性和预测性。 表明通过采集尿液的拉曼信号, 经过一定的数据处理即可评估人体能量摄入量水平。 该方法可以实现尿液的快速分析, 测试分析时间小于2 min, 操作简单, 判别结果准确, 在医疗健康领域具有很大应用前景。
Author: HAN Xiao-long and LIN Jia-sheng: joint first authors
The balance of human energy intake and energy consumption is one of the standards for maintaining health. Unbalanced intake may cause consequences such as cell damage and obesity. The estimation of energy intake is of great significance to human health management. The current method of assessing energy intake is mainly through dietary review, but it is time-consuming because of increasing the burden of the person to be evaluated. Therefore, developing a simple and fast way to estimate energy intake is urgent. After energy intake, metabolites generated by digestion and metabolism are excreted as waste. Wastes such as urine, etc., contain many chemical species, which can systematically reflect the dietary status and disease processes. This research aims to establish a classification model based on SERS techniques, which is highly sensitive, non-destructive, and identifiable molecular fingerpring. Peak statistics, and unsupervised and supervised clustering algorithms are utilized to analyze SERS data collected from volunteer groups of energy intake with 1 500, 2 030, 2 700 kcal·day-1. Since there is a certain amount of overlapping of Raman peaks in many organic molecules, it is difficult to analyze and assign SERS peaks. This study adopts a comparative analysis of an unsupervised PCA and a supervised OPLS-DA algorithm for classification and prediction. It was found that the scattering distribution of different categories in PCA has a large extent, so the model shows poor categorization. After correcting the background by first-order derivative difference, the scatter map presents the classified trend. The OPLS-DA algorithm can decompose the X matrix information into the Y-related and unrelated two components by presetting the Y's label to achieve good classification after orthogonal signal correction processing. The results show that the OPLS-DA algorithm can be well-classified for three or each two different energy intake levels. Both the specificity and accuracy of the ROC analysis have reached 100%. The permutation test of 200 times also illustrates the model with good accuracy and predictability. The results indicate that the levels of human energy intake can be directly estimated by analyzing the SERS signal of the urine. This method can rapidly analyse urine in 2 minutes with simple manipulation and accurate discriminant results, which shows great potential in medical health applications.
随着生活水平的日益改善, 超重和肥胖的人群在世界范围内已呈现急剧增加的趋势, 引起了公众对健康的担忧[1]。 超重和肥胖主要由能量摄入与能量消耗不平衡引起的, 合理的能量摄入量对拥有健康的身体有着举足轻重的作用, 例如对于青少年群体, 一天的能量摄入集中在晚餐, 而晚餐能量摄入后缺乏足够的能量消耗, 导致能量积累, 进而引起超重和肥胖[2]。 另有研究表明, 能量摄入量与寿命存在关联, 过高的能量摄入会在体内产生过量的活性氧物种, 引起DNA、 磷脂和蛋白质的损伤, 加速了生物体的衰老, 而持续性的低热量摄入同时保持必要的营养摄入对机体的健康及抗衰老将会产生有益的影响[3]。 因此, 能量摄入量分析对饮食管理、 抗衰老、 生命健康有重大指导意义。
目前, 能量摄入量的评估主要通过膳食回顾法来实现。 食物中可提供能量的物质为碳水化合物、 脂肪和蛋白质, 每克碳水化合物、 脂肪和蛋白质的生理能值分别为3.99, 9.01和3.99 千卡, 通过计算饮食中摄入的碳水化合物、 脂肪和蛋白质的质量就可以大致评估个体的能量摄入量。 膳食回顾法虽然可以对个体的能量摄入量进行一个大致的评估, 但它操作繁琐耗时, 容易增加受试者的负担, 而且有可能出现错误回顾的情况, 因而亟需开发一种可以快速简便的能量摄入量分析方法。
表面增强拉曼光谱(surface enhanced Raman spectroscopy, SERS)作为一种高灵敏的指纹识别光谱学技术, 凭借其对样品无损, 无水干扰等优势已在生命健康[4]、 卫生安全[5]、 环境检测[6]等诸多领域得到了广泛的应用。 为实现能量摄入量的快速评估, 以不同能量摄入量志愿者的尿液作为研究对象, 通过溶胶团聚法采集待测人员的尿液SERS信号, 并结合机器学习算法建立尿液的增强拉曼信号与能量摄入量之间的联系。 选取能量摄入量分别为1 500, 2 030和2 700千卡·日-1的志愿者的尿液作为研究对象, 分别代表低、 中、 高三种能量摄入水平。 测试时选择银纳米溶胶作为SERS增强纳米粒子, 利用尿液中含有的盐离子, 诱导银纳米粒子的团聚, 进而获得尿液的SERS信号。 通过对尿液的SERS数据进行无监督的主成分分析(principal component analysis, PCA)和有监督的正交偏最小二乘判别分析(orthogonal partial least-squares discriminant analysis, OPLS-DA), 发现后者可以对不同能量摄入量的尿液的SERS信号进行良好的聚类。 建立尿液的SERS信号与能量摄入量的关系, 通过直接分析尿液的SERS信号实现能量摄入量的归类分析, 可以为合理安排膳食提供指导性意见。
二水合柠檬酸三钠, 硝酸银均购自国药集团化学试剂有限公司, 试剂均为分析纯; 电阻率18.2 MΩ 的超纯水从Milli-Q Plus水净化系统(Millipore Corporation)获得。 紫外可见分光光度计(SHIMADZU UVmini-1280)用于分析银纳米溶胶的消光光谱; 便携式拉曼光谱仪(厦门赛纳斯科技有限公司, SHINS-P785X)用于采集待测尿液的拉曼信号。
银纳米粒子的合成采用柠檬酸钠还原法, 将100 mL 1.5 mmol·L-1硝酸银溶液加热煮沸, 再一次性快速加入5 mL 1 Wt%的柠檬酸钠溶液, 继续煮沸冷凝回流3 h, 待银溶胶冷却到室温后, 置于4 ℃冰箱中保存待用。 银溶胶的紫外可见吸收光谱通过紫外-可见分光光度计测试。
志愿者状态: 选择志愿者7名, 均为中国男性公民, 年龄29~45岁, 身高165~180 cm, 体重指数(BMI)18.5~24, 高中及以上文化程度, 无政治性问题, 身体健康, 不嗜烟酒, 有一定锻炼习惯, 无药物依赖, 无心理疾病、 精神、 遗传病和传染病病史, 无器质性疾病(特别关注骨骼和心血管系统疾病)和地域性疾病, 无严重过敏史, 体内无金属植入物, 无营养不良。 受试者事先接受实验背景和意义的培训和教育, 以提高受试者的依从性。
志愿者分组尿液样品收集: 为了降低个体代谢差异对实验结果的影响, 7名志愿者均参与三组能量摄入量的实验, 即依次参与1 500组, 2 030组, 2 700组实验。 具体能量摄入量及营养摄入比例见表1。 每组实验为期3天, 每天收集受试者晨尿, 每份3 mL。 每组实验间隔一周洗脱期, 避免组间相互干扰。 洗脱期膳食条件为2 030 千卡·日-1标准摄入量。 整个实验总共收集63份尿液样品, 所有样品收集后立即保存于-20 ℃, 测试前恢复到室温, 避免多次冻融。 尿液无需任何前处理, 可直接用于后续的检测。
| 表1 能量摄入量分组情况及营养摄入比例 Table 1 Energy intake and nutrient intake rations of three groups |
采用便携式拉曼光谱仪对尿液样品进行信号采集。 具体步骤如下: 用移液枪吸取80 μL尿液与210 μL银纳米溶胶混匀, 利用尿液中含有的盐离子诱导银纳米溶胶的团聚。 使用便携式拉曼光谱仪采集团聚后的银溶胶拉曼信号, 即可获得尿液的表面增强拉曼光谱。 测试参数为: 激发光波长为785 nm、 激光功率100 mW、 采集的波数范围为300~2 000 cm-1、 积分时间3~8 s、 累积次数2次。 每分样品平行测试3次, 总共采集189条光谱。
谱峰分析: 求每组光谱特征谱峰波段的峰面积。 将求得的峰面积值数据集采用箱线图分析, 分别计算其数据的最小值, 第一四分位数(25百分位数), 中位数, 第三四分位数(75百分位数)和最大值。
主成分分析(PCA): 对收集到的尿液SERS谱图进行主成分分析, 建立分类模型。 为了避免采集过程的信号波动带来偏差, 需要对所有光谱数据进行归一化, 即将光谱强度值除以采集时间、 除以采集功率。 计算得到的光谱数据集可进行主成分分析。 下面是具体的计算过程:
(1)对所有的光谱计算一阶导差分谱, 以消除荧光背景干扰;
(2)利用MATLAB R2017a软件中的统计和机器学习工具包对上述的一阶导差分谱(1 500组、 2 030组和2 700组)进行主成分分析;
(3)绘制主成分1(PC1)和主成分3(PC3)的散点图, 计算两个主成分的贡献率;
正交偏最小二乘判别分析(OPLS-DA): 将采集的尿液SERS光谱进行归一化处理, 然后合并成为一个数据集并对每个样本做好归类标签。 将得到的样本数据矩阵导入到SIMCA-P(版本14.1)软件中进行OPLS-DA分析。 在建立模型过程中, 不断增加引入主成分的个数, 直到模型的解释方差(R2)或者模型的预测方差(Q2)增长率不超过2%, 建立模型的有效性通过置换检验(200次迭代)来确认, 特异性和敏感性通过ROC分析进行检验。
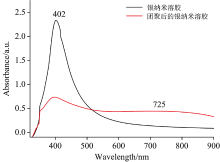
图1为银溶胶的紫外可见吸收光谱图。 从图中可以看到, 未团聚的银纳米溶胶在402 nm处有吸收峰, 该峰为银纳米粒子的偶极吸收峰。 银纳米粒子团聚后在725 nm处新增一峰, 该峰是银纳米团聚体的共振峰, 峰很宽主要是由非均匀加宽效应引起的, 团聚后的银纳米溶胶在402 nm处仍然有微弱的吸收峰, 该峰可能是由于团聚过程仍然有部分银纳米粒子没有团聚所引起的。 700~800 nm的宽吸收峰可以与785 nm激发光匹配, 有利于实现最大化的拉曼信号增强。
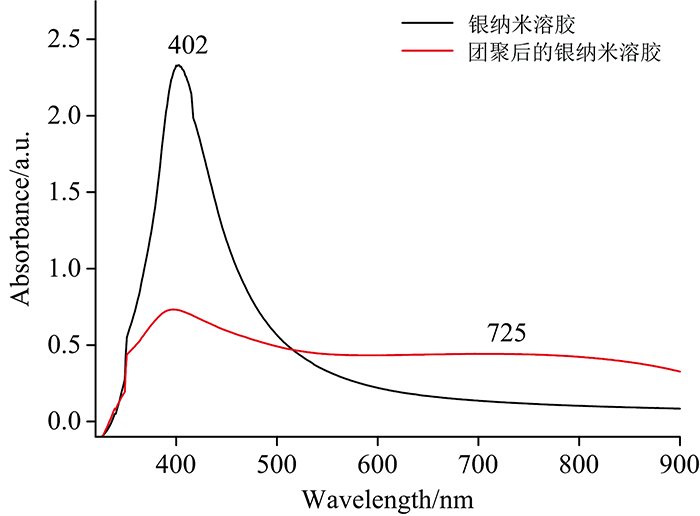 | 图1 银溶胶的团聚前后的紫外可见吸收光谱图Fig.1 UV-Vis absorption spectra before and after agglomeration of silver sol |
用便携式拉曼光谱仪采集三个分组的SERS光谱, 原始谱图中带有部分荧光背景。 为了观察组间差异, 对每个分组内所有光谱取平均后采用B样条插值拟合法校正基线, 三组平均谱图对比展示于图2。
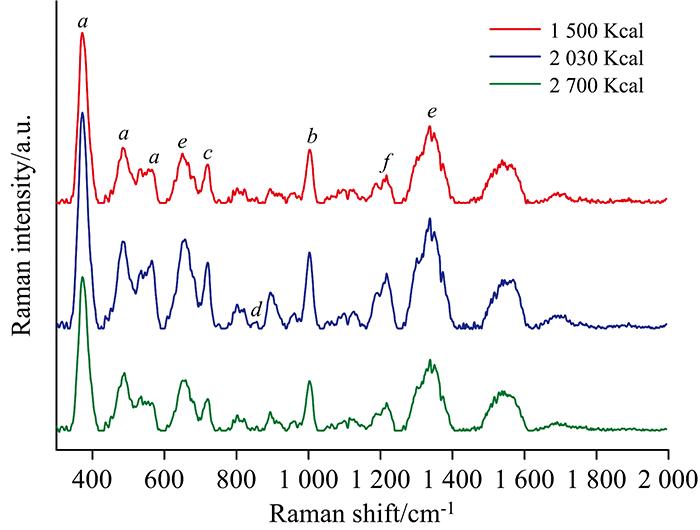 | 图2 三组SERS数据的平均光谱(基线校正)Fig.2 Average spectra of three groups of SERS data (baseline-corrected) |
尿液中含有大量的盐离子, 可以破坏银溶胶的介稳性, 使其发生团聚。 在银纳米粒子团聚的过程中受到激光辐照时, 粒子与粒子间隙处可以形成等离激元热点。 间隙处的分子的拉曼信号被急剧放大。 因此从光谱图上, 可以观察到很多谱峰特征。 如图2所示, a所指的谱峰, 如375, 485和567 cm-1等峰归属于乳糖分子[7]。 b所指的谱峰1 003和1 560 cm-1等峰归属于尿素[8]。 c所指的谱峰718 cm-1归属于次黄嘌呤[8]; d所指的谱峰855 cm-1归属于肌酐[11]; e所指的谱峰650和1 350 cm-1归属于黄嘌呤[9]; f所指的谱峰1 218 cm-1归属于黄蝶呤[9]。 据报道不同膳食条件下, 志愿者群体的尿液表现出不同的代谢物比例[12]。 但是由于SERS 光谱是在复杂的尿液基质中获得的, 通过候选分子的拉曼光谱与尿液样本的SERS光谱比对可以进行初步成分分析。 虽然可以分析候选的成分, 但很难清楚地解析出具体的物质比例, 因为具有相似化学结构的分子可以在相似的光谱范围内产生谱峰, 从而掩盖了精确的成分比例。
在平均光谱图的比较中, 组别之间差异较大的谱峰波段位于538~588和835~869 cm-1。 我们对这两个波段展开统计分析(如图3所示)。 分别计算每组样本光谱在此两波段的谱峰面积, 并采用T检验计算组间的p值。 从538~588 cm-1波段统计分析中看出, 1 500组与2 030组、 2 030组与2 700组的p值小于0.05, 存在显著统计学差异。 1 500组与2 700组的p值过大, 统计学上无显著差异。 在835~869 cm-1波段, 仅仅2 030组与2 700组之间存在统计学上差异。 然而从箱线框分析, 组与组存在许多重叠分布, 很难找到可以清楚区分三组的阈值。
 | 图3 不同波段不同分组的峰面积统计分析Fig.3 Statistical analysis of peak areas of different bands and groups |
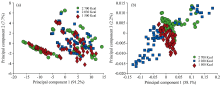
对于SERS光谱的多变量分析, 采用在波长范围为300~2 000 cm-1的光谱数据集进行无监督的PCA和有监督的OPLS-DA建模。 在进行PCA分析之前, 对所有光谱数据求一阶差分谱, 以排除背景信号的干扰。 对数据集开展主成分分析后, 绘制散点分布图(如图4所示)。 图4(b)展示了基于第一主成分(PC 1)和第三主成分(PC 3)的散点分布图, 低、 中、 高能量摄入量的三组之间具有一定分类趋势。 三组的PCA结果表明, 所有变量的60.3%可以通过PC 1和PC 3解释, 其中PC 1占总数的58.1%, PC 3占2.2%。 三个不同能量摄入量的分组主体能进行区分, 但是存在部分的散点交叠, 比如1 500组与2 700组。 另外2 030组的散点分布范围较宽, 与1 500组、 2 700组存在较大重叠。 从直观上看散点分布, 三组的区分效果一般。 为了获得>80%的原始数据集的主变量, 对于此三组的比较需要使用前33个主成分(数据未展示)。 为了比较, 原始SERS光谱也进行了PCA分析[如图4(a)所示], 三组的PCA散点分布图彼此存在大量重叠。 因此, 基线校正的SERS光谱比原始SERS光谱进行PCA更有效。
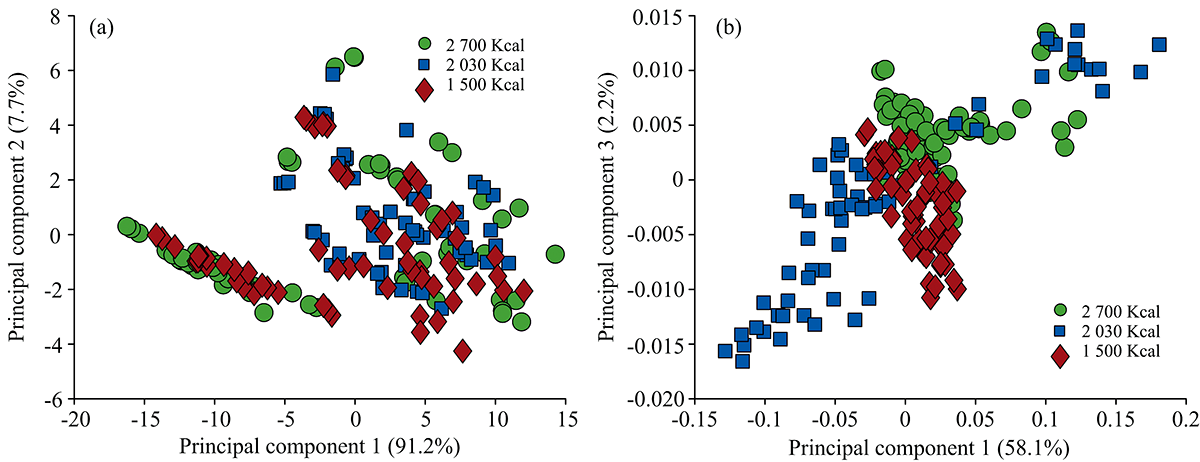 | 图4 三组数据的主成分分析得分散点图Fig.4 Score scatter plotsof the three groupsgenerated by PCA |
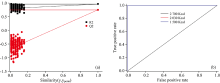
为了进一步有效地区分, 我们采用了有监督的分类算法——正交偏最小二乘判别分析(OPLS-DA)。 PCA仅使用独立变量(X)计算获得新的主成分, 而OPLS-DA通过建立新的变量阐释独立变量和依赖变量(Y)之间的相关性, 用于阐释光谱的之间的关联性。 我们采用原始SERS光谱进行OPLS-DA建模, 三组的散点分布图如图5(a)所示, 可视化的分类结果非常好。 所有的189份SERS光谱均能被正确分类。 为了检验分类模型的准确性, 对模型进行ROC(receiver operating characteristic)分析, 从图6(b)中可以看出, 三个分类的AUC(area under curve)均为1, 说明模型具有100%的敏感性, 100%特异性, 100%准确性。 在OPLS-DA分析模型中, R2=1表示模型的完美拟合, Q2=1表示完美的可预测性, 通常Q2接近R2Y较佳, Q2值≥ 0.4的生物模型通常被认为是可靠且可接受。 此三分类的模型中R2Y(拟合性能)和Q2(预测性能)分别为0.961, 0.691。 两者差值为0.27, 小于0.3。 说明此模型拟合效果很好, 预测效果良好并且模型是可靠的。 为了进一步区分, 对每两个实验组都进行OPLS-DA分析, 得到的散点分布图如图5(b, c, d)所示, 其R2Y和Q2分别为0.938, 0.792; 0.995, 0.853和0.956, 0.764。 从数据中可以看出二分类的拟合效果都非常好, 预测能力较三分类的有所提升。 说明采用OPLS-DA模型, 二分类的效果较佳。 此外, 为了检验三分类模型的有效性, 我们开展了置换检验。 置换检验图[图6(a)]可以检查OPLS-DA模型的有效性, 评估标准是左侧R2和Q2的值低于右侧原始点的值。 其中, R2表示由Y预测解释的训练集中的变化百分比, Q2表示基于交叉验证模型预测的训练集中的变化百分比。 经过200次置换试验后, 三组的初始R2和Q2均低于原始R2和Q2值, 表明模型是可靠有效的。 因此, 本研究中的OPLS-DA模型表现出对不同能量摄入量尿液SERS谱图的高预测性和高可靠性。
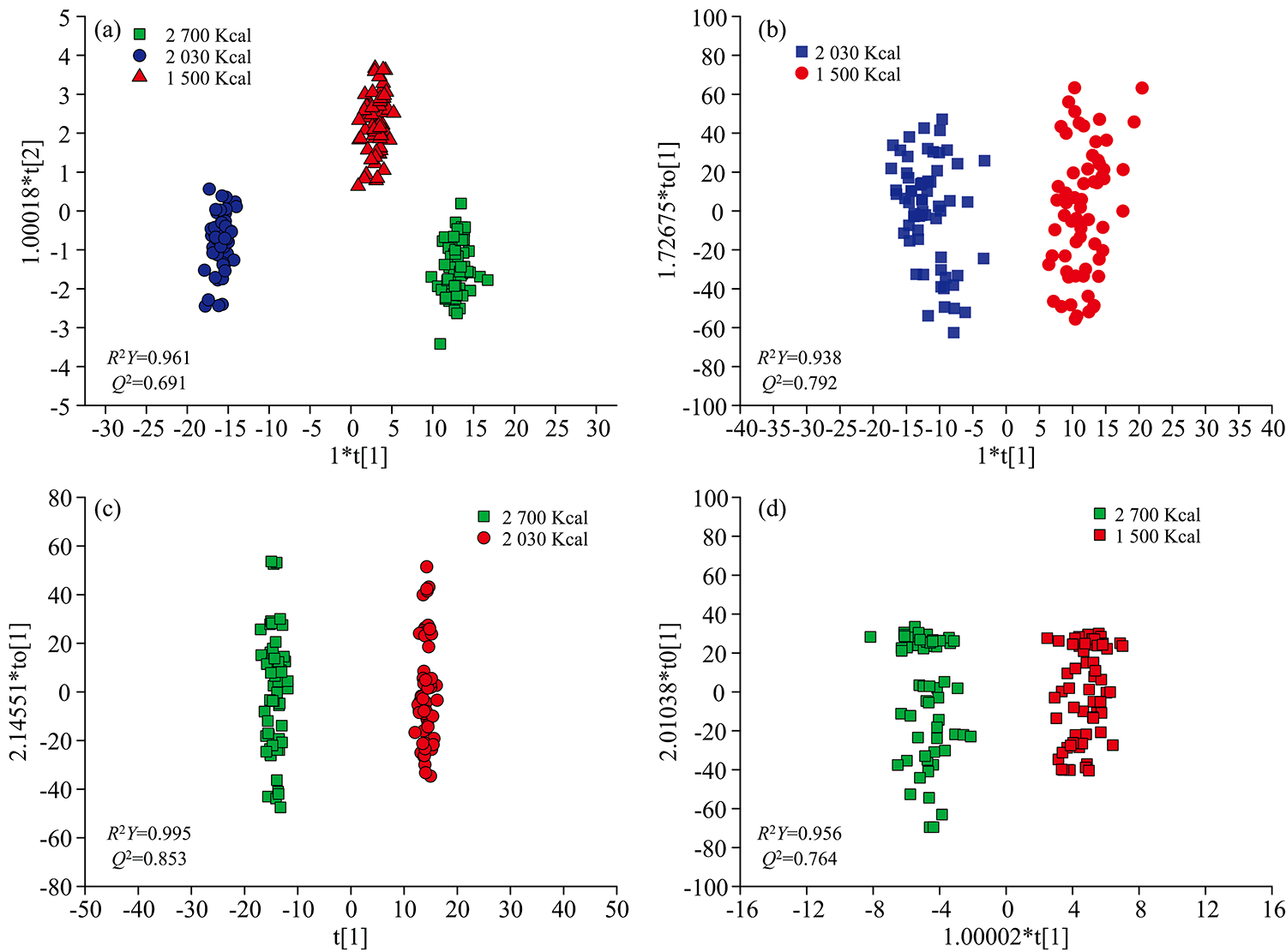 | 图5 OPLS-DA分析三组与每对分组的散点分布图Fig.5 Scatter plots of three groups and each pair of groups generated by OPLS-DA |
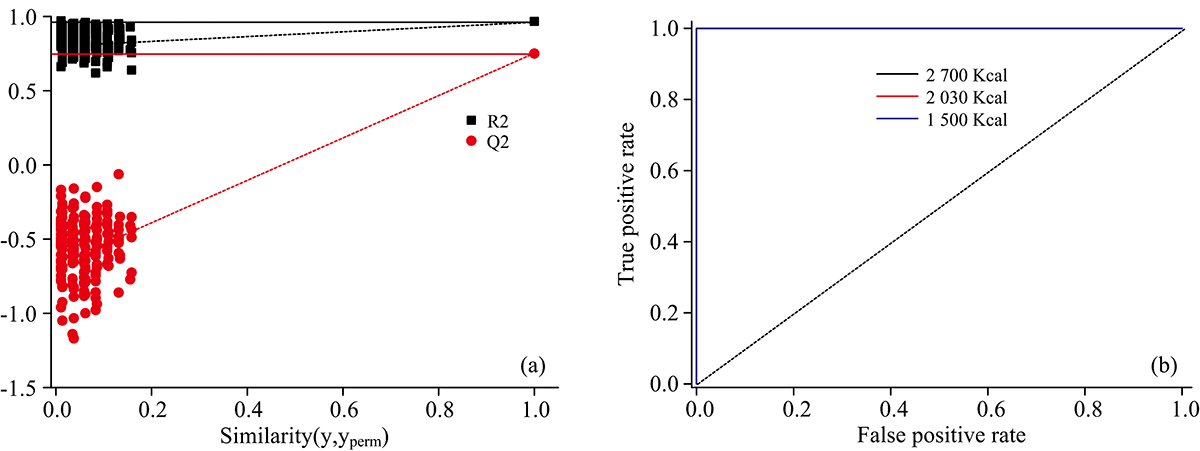 | 图6 (a)三组分类模型的置换检验散点图; (b)三组分类模型的ROC分析曲线Fig.6 (a) Permutation test of three-group classification model; (b) ROC analysis curve of three-group classification model |
分析结果表明, 使用银溶胶进行非侵入性的能量摄入量尿液SERS分析是可行的。 虽然在本研究中只分析了小规模的样本数据, 但这些结果很有指导意义, 今后需要拓展更大数量的样品研究。 与传统的膳食回顾法相比, 使用银溶胶的SERS能量摄入量分析具有成本低, 简单快速准确的优点。 该方法如果与手持式拉曼光谱仪结合使用, 可以在家中实现每日能量摄入量的分析, 为合理安排膳食提供指导性意见。
发展了一种针对不同能量摄入量的人体尿液SERS快速分析方法, 并结合无监督的算法PCA和有监督的算法OPLS-DA分别建立尿液数据的分类模型。 实现对低能量摄入组、 中能量摄入组、 高能量摄入组的良好分类。 在本研究中, OPLS-DA比PCA更有效, 在OPLS-DA中显示高中低能量摄入量分组的100%敏感性和100%特异性。 尽管从光谱图很难清楚地解释SERS谱峰对应尿液中的分子, 但结合算法分析, 可以完美鉴别不同能量摄入量的人群。 此方法整体分析时间小于2 min, 无需样品前处理, 具有简单便捷快速的特点, 可以作为一种能量摄入量的判断手段, 将有利于人体的饮食管理和健康管理。 OPLS-DA模型对三类营养摄取量能进行有效区分, 意味着模型的良好性, 并有望实现更小能量差异的区分。 未来将进一步拓展不同能量摄入量、 不同营养摄入比例的精细区分, 以实现精准指导。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|