
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
激光诱导击穿光谱结合XGBSFS特征优选的废钢分类识别方法
[孙永长1, 2  , 刘艳丽
, 刘艳丽4 , 黄晓红1, 2 , 宋超1, 2, * , 程朋飞3 ]
, 刘艳丽, 程朋飞|
|


作者简介: 孙永长, 1997年生,华北理工大学人工智能学院硕士研究生 e-mail: 13582703841@163.com
我国每年的钢铁生产与出口量位居世界前列, 而在钢铁生产过程中产生的废钢是一种重要的资源。 废钢的精准分类是电炉炼钢的关键环节, 对于环境能源的可持续发展也具有重要意义。 为了提高废钢回收利用的效率, 提出了一种利用激光诱导击穿光谱结合XGBSFS特征优选的废钢牌号智能识别方法, 与 k最邻近算法(kNN)、 支持向量机(SVM)分类算法联合建立了XGBSFS-SVM、 XGBSFS-kNN两种优化模型。 首先通过Lapa-80型固体脉冲激光器采集3类共18种不同的废钢样品在170~400 nm范围内的激光诱导击穿光谱数据, 通过 k值校验剔除光谱数据中的粗大误差, 并对剔除后剩余的数据进行平均, 每个样品28组共得到504组平均光谱数据; 然后对光谱数据进行基线校正、 归一化等预处理, 降低基体波动影响; 最后将处理后的光谱数据从每类钢种中提取一个样品的数据作为模型的测试集, 剩余数据作为模型的训练集, 并提取光谱数据中Si, Cu和C等元素的16条特征谱线作为分类特征, 用于模型的输入, 经过基于XGBoost的XGBSFS特征选择算法对变量进行优化后, 应用kNN、 SVM建立废钢智能识别模型。 XGBSFS-SVM、 XGBSFS-kNN算法模型在测试集上的准确率分别为100%和98.8%, 输入维数也均由16维降至2维, 且两种模型的建模时间分别由3.1下降至2.79 s, 3.26 s下降至1.64 s, 相较于单独使用SVM和kNN的算法模型, 提出的优化模型预测精度和建模效率较高, 且泛化能力较好。 经过对比建模时间和准确率综合效果, 选取XGBSFS-SVM模型用于不同废钢的智能快速识别。 实验结果表明, 该研究提出的LIBS与XGBSFS特征优选方法能够有效的对特征变量进行优化建模, 为工业生产中废钢种类的快速智能识别和钢铁的回收提供了一种新技术。
As an important metal material, steel is widely used in manufacturing and construction due to its good plasticity, toughness, and low price. China's annual steel production and export volume ranks among the top in the world, and the scrap produced in the steel production process is an important resource. Accurate classification of steel scrap is a key link in electric furnace steelmaking, and it is also of great significance to the sustainable development of an environmental and energy. In order to improve the efficiency of scrap steel recycling, a method for intelligently identifying scrap steel grades using laser-induced breakdown spectroscopy (LIBS) combined with XGBSFS is proposed. Firstly, the LIBS data in the range of 170~400 nm were collected by Lapa-80 solid-state pulsed laser for 3 types of 18 different scrap steel samples. The gross error in the spectral data is eliminated by k-value verification, and the remaining data after the elimination is averaged. 28 groups for each sample, a total of 504 groups of average spectral data were obtained. Then, the spectral data is subjected to baseline correction, normalization and other preprocessing to reduce the influence of matrix fluctuations. Finally, the processed spectral data is divided into the training set and test set, and 16 characteristic spectral lines of Si, Cu, C and other elements in the spectral data are extracted as classification features for the model's input. After the variables are optimized by the XGBSFS feature selection algorithm based on XGBoost, kNN and SVM are used to establish an intelligent identification model of scrap steel. The accuracy rates of the XGBSFS-SVM and XGBSFS-kNN algorithm models established in this study are 100% and 98.8% respectively, on the test set, and the input dimensions are also reduced from 16 dimensions to 2 dimensions, and the modeling times of the two models are respectively From 3.1 to 2.79 s, 3.26 s to 1.64 s. Compared with the algorithm model using SVM and kNN alone, the optimized model proposed in this paper has higher prediction accuracy, modeling efficiency, and better generalization ability. After comparing the comprehensive effects of modeling time and accuracy, the XGBSFS-SVM model was selected for the intelligent and rapid identification of different scraps. The experimental results show that the LIBS and XGBSFS feature optimization methods proposed in this study can effectively optimize the modeling of feature variables and provide a new technology for the rapid and intelligent identification of scrap steel types in industrial production and the recovery of steel.
我国是钢铁生产和消费大国。 冶金过程中产生的废钢作为钢铁工业重要的可持续发展资源, 主要用于长流程转炉的炼钢添加料或短流程电炉的添加料, 是高炉炼钢的不可或缺的原料之一, 不仅比矿石炼钢耗能低, 节省钢企成本, 还能减轻环境污染, 对环境友好。 世界范围内每年产生的废钢量约3~4亿吨, 但回收率不高。 如何对废钢进行合理配置不仅是冶金行业需要考虑的重要方面, 对于中国发展全废钢电炉炼钢也具有重要的战略意义[1]。 对废钢进行有效分类, 是电炉炼钢的关键环节, 能有效加快钢厂炼钢流程, 助力冶金行业的可持续发展进程。
目前利用废钢外观、 尺寸作为分类标准的方式较为繁琐, 需要检测人员具有大量经验且学习成本较高, 而利用传统检测方式如火花直读、 红外光谱法[2]和X荧光检测[3]在实验环境要求, 样品制备过程等方面较为严苛和复杂, 对样品表面伤害也较大, 很难达到快速精准分类的要求。 激光诱导击穿光谱(laser-induced breakdown spectroscopy, LIBS)是一种快速且高效的光谱分析技术, 可以通过采集等离子体光谱对被测物质进行分析, 样品需求量少、 破坏性小、 无需复杂的样品制备且快速高效, 近年来在冶金工程、 环境资源检测、 生物医学分析、 地质分析、 农业和军事[4, 5, 6, 7, 8, 9, 10, 11]等多种领域都有广泛应用。
机器学习算法结合LIBS进行材料的分类识别在近年来有广泛的研究。 Zhang等[12]以全谱数据、 全谱标准化数据和前四条强谱线分别建立偏最小二乘判别分析(partial least squares discriminant analysis, PLS-DA)模型, 并通过五折交叉验证确定最优潜变量数对两种不同的钢渣进行分类识别, 经对比, 前四条谱线作为输入建立的定性模型识别率达到96.67%, 证明该定性模型能够应用于生产中, 有助于鉴别钢渣质量。 后来的研究中[13], 通过独立分量分析(independent component analysis, ICA)提取光谱有效特征, 将其作为输入小波神经网络(wavelet neural network, WNN)模型, 建立的ICA-WNN模型用来对3类煤灰样品进行分类, 最终准确率为98.89%, 验证了LIBS与WNN相结合对煤炭工业在线分析的合理性和有效性; Liu等[14]为了对三类航空用铝进行快速准确分类, 首先使用基于连续图像定位技术实现对数据的准确采集, 再以Cu, Zn等元素的高斯归一化谱线强度值作为输入建立多维高斯概率密度分布模型, 平均识别率为99.15%, 表明此方法有助于对金属进行高性能分类; Dong等[15]利用机器学习结合LIBS对东北5个产地的人参进行产地分类识别, 利用主成分分析(principal component analysis, PCA)提取有效成分并减少维度, 分别建立PCA-SVM和PCA-BP-ANN分类模型, 得到的平均精度为99.5%和99.08%, 证明了BP-ANN训练速度更快, 结果稳定且分类精度高, 可实现对人参产地的快速识别; Zhang等[16]利用随机森林算法(random forest, RF)与LIBS相结合对9种不同的钢样进行分类, 采用袋外误差与交叉验证优化模型参数, 并与PLS-DA等算法进行对比分析, 结果表明, 利用随机森林算法对钢样分类的效果优于其他模型, 所建立的模型能够有效快速且精准实时的预测钢种类别; Pan等[17]利用PCA结合极限学习机(extreme learning machine, ELM)对不同种类铝合金进行识别, 选取主要差异元素共21条谱线进行主成分分析, 将21维特征减少至8维, 建立PCA-ELM模型, 使得分类准确率达98.01%, 且通过多次分类过程验证了模型的良好效率和稳定性。
上述研究表明, 机器学习算法结合LIBS在材料分类领域具有可行性。 本研究利用基于XGBoost算法的XGBSFS特征选择算法对输入的光谱特征进行筛选, 减少输入矩阵的维度, 最大程度降低了模型复杂度, 建立优化的机器学习分类模型, 实现了对不同种类的废钢样品精准快速分类, 并验证了模型的准确性和有效性。
XGBSFS算法[18]是一种基于XGBoost算法和改进的序列浮动向前选择策略的特征选择算法, 其利用XGBoost的树模型的独特优势, 以XGBoost算法的重要性度量指标作为特征选择的重要依据, 即基于XGBoost算法中的FScore、 AverageGain和AverageCover作为特征选择指标。 设有生成的叶子节点上的所求特征集合X, 重要性指标可以表示为
其中, Gain为X中每个叶子结点分割后的增益值, FScore为特征分裂次数, AverageGain为特征的平均增益, AverageCover为特征的平均覆盖率。 将其中两个重要性指标参与到改进的序列浮动向前策略中, 根据指标对特征进行添加和删除, 确定最终特征。 这种双向特征搜索算法优于一般的单向选择算法, 能够有效避免模型陷入局部最优的情况。
支持向量机(support vector machine, SVM)是通过在高维输入特征空间寻找最大间隔超平面, 即最优解, 从而实现对样本分类。 SVM通过非线性变换转化为某维特征空间ϕ中的线性分类问题来解决现实生活中的非线性分类问题, 这种非线性变换即核函数
式(4)中, x和z为输入空间中的值, ϕ(x)和ϕ(z)为映射到特征空间ϕ中的值。
即非线性支持向量机算法过程为在训练数据集T={(xi, yi)}, i=1, 2, …, N中, 选取合适的核函数和惩罚系数C(C>0), 与线性问题类似, 构造求解凸二次规划问题。
得到最优解α*, 在通过满足条件的分量
对于支持向量机而言, 选择合适的核函数、 惩罚系数等参数, 是废钢分类问题的快速精准实现环节中重要的一环。
k最邻近分类算法(k-Nearest Neighbor, kNN)的基本步骤为利用训练样本数据找出与待分类样本距离最近的k个样本并判断样本的类别, 以k个样本中出现最多的类别作为未知样本的预测类别。
算法中判断待分类点与其他点的距离的计算方式可以分为欧式距离, 汉明距离等。 一般采用欧氏距离作为依据, 欧氏距离表示为
式(9)中,
需要对kNN中的重要参数k进行优化。 若k很小, 容易受到噪声的影响, 发生过拟合; 若k很大, 则会增大计算量, 发生欠拟合, 都会影响分类效果。 选择合适的参数能够提升废钢分类的准确性和实用性。
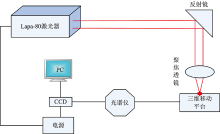
图1为用于废钢分类识别的激光诱导击穿光谱实验系统结构示意图。 系统采用自主研发的具有独立自主产权的便携LIBS废钢成分检测仪, 内置独立自主知识产权的基于瑞芯微RK3399 pro的嵌入式LIBS高精度定标分析软件系统, Lapa-80型固体脉冲激光器(脉冲能量80 mJ可调, 频率0~20 Hz可调), AvaSpec-Mini4096CL小型光纤光谱仪2块(波长范围: 170~300 nm, 290~400 nm), 独立自主知识产权的高精度光路探头, 不共轴光路, 最优激光焦点到样品表面距离LTSD为2 mm, 保证了检测精度。
 | 图1 实验系统结构Fig.1 Experimental system structure |
实验样品均为国家标准样品, 成分见表1。 编号1—6样品为编号为GSB A68072-92的1—6号碳素结构钢; 7—12为GSB-03-2615的1—6号低合金钢; 13—18是编号为YSBS23207-97的A1—A6号中低合金钢。
| 表1 钢样组成元素含量(Wt%) Table 1 The concentrations of steel components (Wt%) |
实验在标准大气压和室内温度25 ℃下进行。 便携LIBS废钢成分检测仪设置最优实验条件及参数, 激光器电压130 V, 脉冲频率2 Hz, 积分时间1.05 ms, 延迟时间1.28 μs。 采集数据时, 每个样品表面均匀选取28个不同检测位置, 每个位置用脉冲激发30次, 前5次激发用于清洗样品表面污渍, 取第6~30次为有效数据; 然后进行k值校验去除粗大误差光谱, k值设置为2.5, 将剩余光谱数据取平均值, 降低脉冲能量抖动和不同位置的光谱波动对废钢LIBS光谱数据造成的不稳定性; 最后得到18个样品(3类钢种)共504组数据; 从每类钢种中抽取一个样品, 即选择1#, 10#和17#号样品作为测试集, 用于验证模型性能, 将除1#, 10#和17#以外的样品作为训练集用于模型的训练。
3.1.1 基线校正及谱线筛选
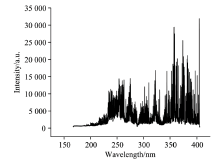
图2为7#样品的一个光谱图。 由于钢铁材料自身的基体效应以及实验条件的波动, 会产生连续背景干扰, 为了减弱这种干扰, 需要对全光谱进行基线校正, 使光谱基线平整。 而对于实验中获得的激光诱导击穿光谱而言, 光谱数据中夹杂着无关的噪声, 且数据的维数庞大, 若利用全光谱数据作为输入训练模型, 会因数据中存在的无关因素对模型造成干扰, 影响实验结果, 不利于模型的建立。 废钢中各种元素在不同含量的情况下, 对应的元素谱线的强度值也不同, 两者之间存在较为明显的相关性, 对于不同牌号的废钢, 可以利用有代表性的元素谱线作为分析线训练模型, 以提高分类的准确性和效率。
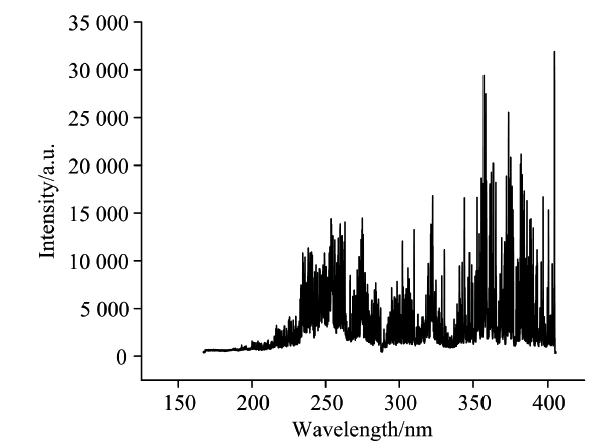 | 图2 钢样光谱图Fig.2 Spectrum of steel sample |
查询美国国家标准与技术研究院(National Institute of Standards and Technology, NIST)发射谱线数据库结合实验所得的光谱数据, 对元素谱线进行分析和选取。 以自吸收效应小、 谱峰完整的原则对特征谱线进行选择, 共筛选出具有代表性的Cu, Si, C, Mn和Cr等元素共16条谱线, 具体的元素谱线波长在表2中列出。
| 表2 实验所用各元素及对应的特征谱线 Table 2 Characteristic lines of selected elements |
3.1.2 归一化处理
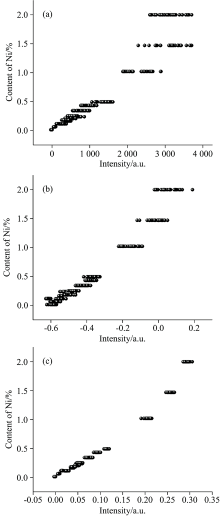
归一化对光谱数据前期处理尤为重要, 将筛选出的16条各元素谱线进行归一化处理, 可以减少谱线波动, 增强谱线强度与不同牌号钢种之间的相关性, 提升分类准确率。 为了得到更好的分类效果, 对未进行归一化、 标准正态变量变换(standard normal variate, SNV)和内标法归一化等三种方法进行对比以选择最优的归一化方法。 图3(a), (b)和(c)分别为Ni元素在231.58 nm处的谱线强度在未归一化、 SNV处理和内标法处理下的强度与浓度之间的相关图, 可以看出, 由于在原谱线中本身相关性不高, 导致使用SNV方法处理后没有产生良好的校正效果, 而经过内标法处理, 针对的选择了内标线进行归一化, 相关性明显提高。 因此, 在对筛选出的内标线进行不同归一化处理对比后, 选择内标法作为归一化方法更能体现各元素浓度与其谱线强度间的相关性, 依据更精确的线性关系能够对不同种类的钢种进行更好的区分。 归一化所用的内标谱线选取强度在各个样品中较为稳定的Fe元素在波长为271.44 nm处的强度值, 对16条谱线强度做同样的归一处理, 将最后得到的504×16维的特征数据矩阵, 用于后续的特征选择、 模型建立和验证。
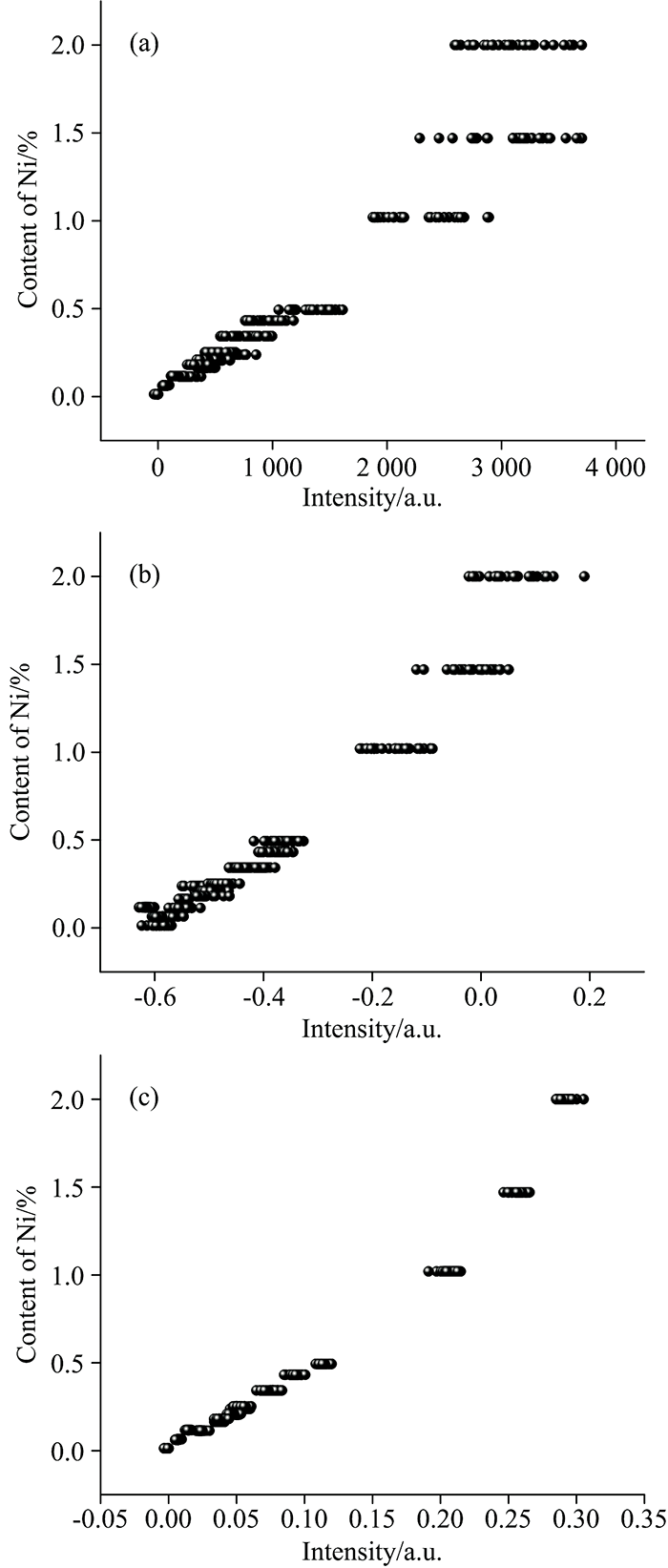 | 图3 Ni元素经不同方法处理后含量与强度相关图 (a): 无归一; (b): SNV; (c): 内标法Fig.3 Correlation diagram of content and intensity of Ni element treated by different methods (a): Untreated; (b): SNV; (c) Internal standard |
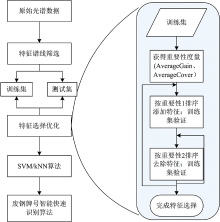
本文所提出的废钢牌号智能快速识别算法流程如图4所示。 具体流程为: 首先将获取到的原始数据进行光谱数据预处理, 如基线校正、 归一化等, 以此减少波动的影响, 增强谱线强度与不同牌号废钢的相关程度; 接着在高维度的光谱谱线中选择多条特征元素谱线作为模型输入, 通过XGBSFS算法去除对识别结果决定性较小的谱线, 优化模型输入; 最后与高效的SVM和kNN模型相结合进行训练, 得到变量优化的预测模型, 完成对不同牌号的快速智能识别。
 | 图4 废钢牌号智能识别算法流程图Fig.4 Flow chart of intelligent recognition algorithm for scrap steel grade |
建立废钢识别模型前需要利用XGBSFS算法进行特征选择。 首先对筛选出的16条特征谱线进行重要程度排序, 以便于后续的特征选择过程。 利用XGBoost算法实现计算特征重要性排序, 通过网格搜索法确定算法相关参数。 确定学习率、 树最大深度和叶子结点最小样本数分别为0.1, 4和1。 实验获取到的训练集(Train)数据共420组, 即训练集数据矩阵为420×16维, 测试集(Test)数据为84组, 即测试集数据矩阵为84×16维。 利用训练集数据进行训练, 建立XGBoost集成学习树模型, 其测试集的准确率为95.2%。 说明利用筛选得到的16条特征谱线作为模型输入所生成的XGBoost模型针对不同种类的钢种的特征变量进行有效划分和学习, 特征划分较好, 可以得到可信的特征重要性度量值。
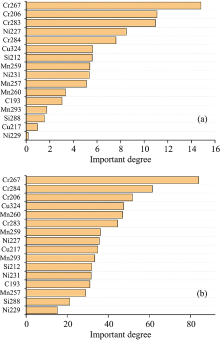
经过XGBoost进行特征节点分割并建立出有效的分类树后, 得到AverageGain和AverageCover特征重要性度量结果, 将其作为作为特征选择指标。 将特征按AverageGain重要性度量进行由大到小排序, 标记为特征集1; 按AverageCover重要性度量进行由小到大排序, 标记为特征集2, 作为后续特征选择的候选特征子集。 图5(a)和(b)分别为16条谱线特征在两个重要性度量下的指标值。
 | 图5 (a)AverageGain重要度量; (b)AverageCover重要度量Fig.5 (a) AverageGain importance measure; (b) AverageCover importance measure |
利用排序好的特征, 建立XGBSFS-kNN与XGBSFS-SVM牌号识别模型并选择准确性和稳定性较好的识别模型作为最终的智能识别算法模型。
得到两组特征候选子集后, 以特征集1开始, 依照重要程度向最终备选特征集中添加一个特征, 若添加新特征后能提高模型准确率, 则保留新特征, 否则不进行添加。 每添加一个新特征后, 对当前备选特征集根据特征集2进行特征去除, 去除的原则与添加新特征原则相同, 以提高模型准确率为前提, 直到没有满足条件的特征去除为止, 记此过程为一轮。 经过多轮的特征的添加与删除操作后, 得到最终的备选特征集即为本次模型特征选择的最后结果。
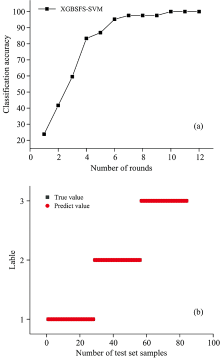
对kNN模型进行特征选择。 在每一轮的特征选择过程中, 均采用5折交叉验证法对kNN中的参数k进行寻优, 以模型在训练集上的分类准确率作为特征添加和去除的标准。 图6(a)为以kNN作为基分类器的特征选择过程, 随着选择轮次的迭代, 模型准确率逐渐升高, 在第8轮后达到最优, 此时得到最优特征集为Ni元素波长231.58 nm, Cr元素波长284.99 nm共2条特征谱线。 以420×2的特征矩阵作为输入, 模型通过交叉验证的准确率为99.76%, 获得最优参数k=40, 图6(b)为kNN模型在测试集上的废钢分类预测情况。 模型在测试集上的分类准确率为98.80%, 建模时间1.64 s, 具有较高的识别精度。
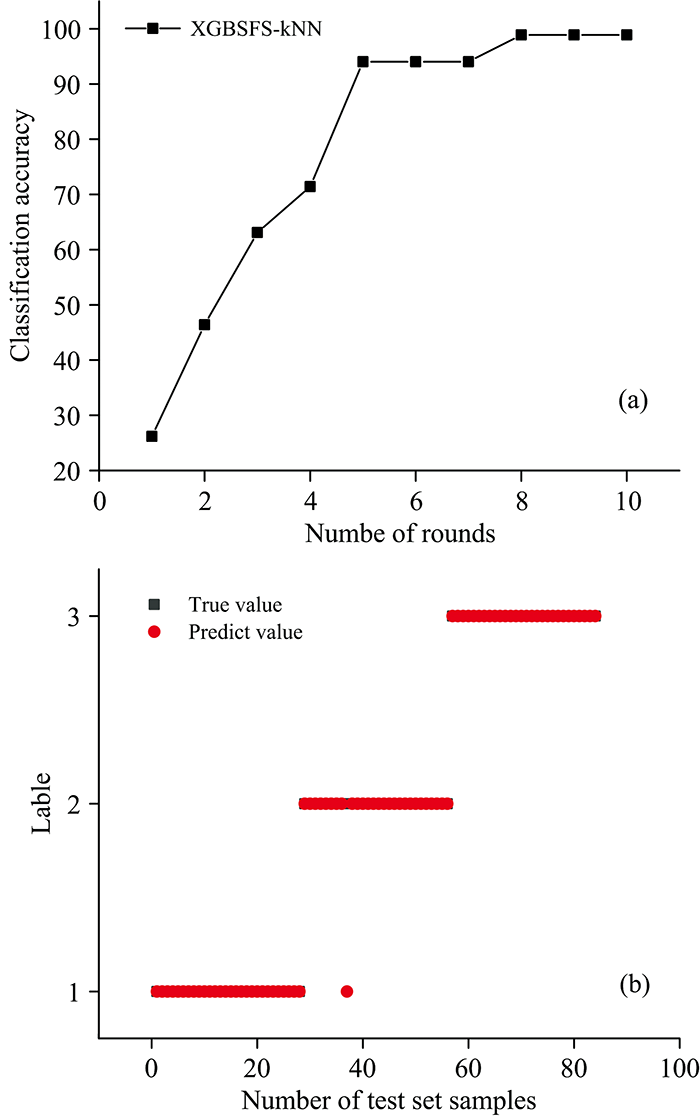 | 图6 (a)kNN特征选择过程; (b)分类识别效果图Fig.6 (a) Feature selection process of kNN; (b) Classification recognition result graph |
以SVM模型作为基分类器进行特征选择。 图7(a)为SVM模型在特征选择过程中分类准确率随迭代轮次的变化图, 可以得出当轮次达到10时, SVM模型效果最优, 且后续效果不再变化。 此时SVM模型在16个特征中选择出2条特征谱线, 分别为Ni元素波长227.01 nm, Cr元素波长284.99 nm。 使用与kNN模型相同的训练集, 以5折交叉验证的方法确定参数, 得到模型的最优惩罚系数C为18, g为3.9, 此时交叉验证的准确率为99.35%。 通过训练, XGBSFS-SVM模型在测试集上的分类准确率为100%, 建模运行时间为2.79s, 如图7(b)为该模型在测试集上的分类效果图, 证明模型预测效果的良好和稳定性。
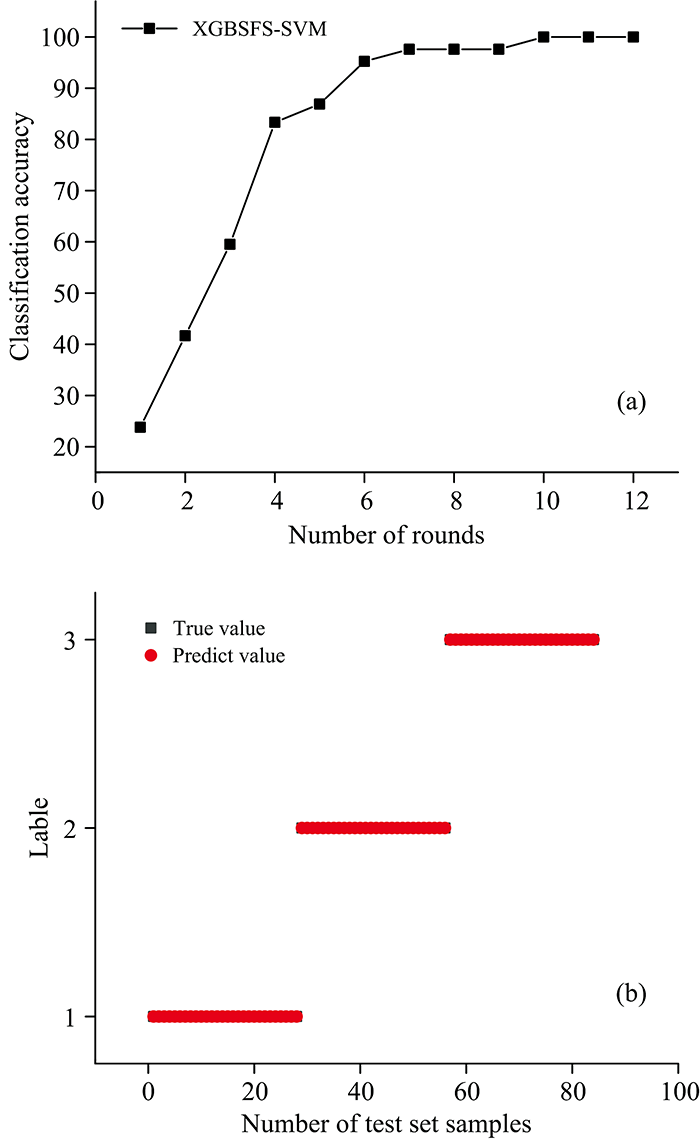 | 图7 (a)SVM特征选择过程; (b)分类识别效果图Fig.7 (a) Feature selection process of SVM; (b) Classification recognition result |
为了对比在特征选择前后模型的整体效果, 分别建立特征选择前的kNN与SVM模型, 以420×16维的训练集作为输入, 利用交叉检验确定模型参数, 最后得到的模型在测试集上的准确度分别为95.23%和96.42%。 表3为特征选择前后两种模型的分类效果对比。
| 表3 建模结果对比 Table 3 Comparison of modeling results |
从表3中可以看出, 实验建立的XGBSFS-kNN模型准确率保持在98%以上, XGBSFS-SVM模型则提升到100%, 表明经XGBSFS算法选择出的特征具有更强的代表性, 与不同种类的废钢相关性更强, 能够对不同牌号的废钢进行有效识别。 在建模时间方面, 由于特征维度的变化, 两种建模时间均有所减少, kNN模型由3.26 s提升到1.64 s, SVM模型由3.10 s提升到2.79 s。 由于XGBSFS-kNN在分类策略上的逻辑较XGBSFS-SVM简单但快速, 所以精度略低于SVM模型, 而速度高于SVM模型。 经过对比, 选用精度较高、 速度良好的XGBSFS-SVM模型作为废钢牌号的快速智能识别模型。 在经过特征筛选后, 保留了在光谱中较为稳定且不易受干扰的谱线, 且去除对模型影响较小的谱线后没有对分类效果造成干扰。 总体来说, 两种算法模型经过特征选择后在分类精度与建模时间上都有所提升, 充分说明经过XGBSFS算法筛选特征后, 能够将对分类效果影响较小的特征剔除, 保留更重要的特征, 简化模型, 提升模型效果, 建立的优化模型能够对工业中不同种类的废钢分类问题提供一种快速可行的方案。
将LIBS与XGBSFS特征选择算法相结合, 建立XGBSFS-kNN与XGBSFS-SVM两种机器学习模型对3类不同种类的废钢进行分类识别。 经过XGBSFS算法进行特征筛选后, 16个输入特征均减少至2个; XGBSFS-kNN与XGBSFS-SVM模型在测试集的84组数据中的识别准确率为98.8%和100%, 建模运行时间均有所提升, 最终选用XGBSFS-SVM模型作为废钢牌号快速智能识别模型。 实验结果证明XGBSFS算法结合SVM算法不仅能够筛选出有效特征, 简化模型, 且性能优于未进行特征选择的模型。 将优化模型与LIBS结合能够对不同类别的废钢进行有效分类识别, 为加快电炉炼钢进程提供了一种满足快速和精准要求的检测识别方法。 在后续的研究中, 将逐步增加各类钢样的数量, 以使模型学习到更多信息, 提升分类性能与泛化能力。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|