
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Wasserstein散度的t-SNE相似性度量方法研究
[刘鑫鹏1  , 孙祥洪
, 孙祥洪2 , 秦玉华1, * , 张敏1 , 宫会丽3 ]
, 孙祥洪, 张敏|
|


作者简介: 刘鑫鹏, 1998年生, 青岛科技大学信息科学技术学院硕士研究生 e-mail: lxp702179@163.com
近红外光谱具有高维、 高冗余、 非线性的特性, 严重影响了样本之间的相似性度量的精准, 故而提出了一种基于Wasserstein散度的t分布随机近邻嵌入算法(Wt-SNE)。 基于流形学习算法思想, 利用高斯分布将高维数据的距离转换为概率分布, 使用更加偏重长尾分布的方式t分布表示低维空间中对应数据点的概率分布。 将高维数据的概率分布嵌入映射至低维度空间, 重构低维流形结构, 引入Wasserstein散度度量两个空间内概率分布的差异, 通过降低散度值来提高两个分布的相似度, 以此来实现高维数据降维处理。 为验证Wt-SNE算法的有效性, 首先对烟叶近红外光谱数据进行降维投影, 并与PCA、 LPP、 t-SNE算法比较, 结果表明Wt-SNE算法降维后的数据, 在低维空间内样本类别边界更加明显。 其次, 采用KNN、 SVM和PLS-DA分类器对降维后的数据进行烟叶产地预测, 准确率分别为93.8%、 91.5%、 92.7%, 表明降维后的数据不仅重构了原始光谱的空间结构而且保留了样本间的相似度关系。 最后, 选取某一卷烟叶组配方中的烟叶进行单料目标烟叶的替换, 根据备选样本与目标样本之间的马氏距离选取替换样本。 实验表明, Wt-SNE选取的替换烟叶与目标烟叶相似度最高, 烟碱、 总糖等化学成分含量与目标烟叶差异较小, 香气、 烟气、 口感得分表现出较高的一致性。 该方法能够有效度量烟叶近红外光谱之间的相似性, 为卷烟叶组配方的维护提供有力的依据。
Near-infrared spectroscopy has the characteristics of high dimension, high redundancy, and nonlinearity, which seriously affects the similarity measurement results between samples. This paper proposes a t-distributed stochastic nearest neighbor embedding algorithm (Wt-SNE) based on Wasserstein divergence. Based on the idea of manifold learning algorithm, Gaussian distribution is used to convert the distance of high-dimensional data into a probability distribution, and t-distribution is used to represent the probability distribution of corresponding data points in low-dimensional space, which is more inclined to long-tailed distribution. The probability distribution embedding of high-dimensional data is mapped to the low-dimensional space. The low-dimensional manifold structure is reconstructed, the Wasserstein divergence is introduced to measure the difference between the probability distributions in the two spaces, and the similarity of the two distributions is improved by reducing the divergence value. In this way, the dimensionality reduction processing of high-dimensional data is realized. In order to verify the effectiveness of the Wt-SNE algorithm, this paper first performs dimensionality reduction projection on tobacco NIR spectral data and compares it with PCA, LPP, and t-SNE algorithms. The results show that the sample category boundaries in the low-dimensional space are more obvious after the dimensionality reduction of the Wt-SNE algorithm. Secondly, the KNN, SVM, and PLS-DA classifiers were used to predict the tobacco origin of the reduced-dimensional data, and the accuracy rates were 93.8%, 91.5%, and 92.7% respectively, indicating that the reduced-dimensional data not only reconstructed the spatial structure of the original spectrum but also retained the similarity relationship between samples. Finally, tobacco from a particular cigarette formula was selected for single material target tobacco replacement, and the replacement samples were selected based on the Marginal distance between the candidate samples and the target samples. The experiments showed that the replacement tobacco selected by Wt-SNE had the highest similarity to the target tobacco, the chemical composition contents such as nicotine and total sugar were less different from those of the target tobacco, and the aroma, smoke, and taste scores showed high consistency. The method can effectively measure the similarity between the NIR spectra of the tobacco and provide a strong basis for the maintenance of the cigarette formula.
近年来, 近红外光谱分析技术(NIR)快速发展, 因其具有高效、 便捷、 无损、 重现性好等优点, 非常适合大批样品的快速分析, 被广泛应用于石油、 食品、 医药、 烟草等领域[1]。 近红外光谱的相似性度量能够实现产品之间质量的相似性评价, 针对目标样本进行有效的替换, 缓解稀缺原料使用的紧张程度, 在食品加工、 卷烟生产领域具有重要意义[2]。 而高维、 高冗余、 非线性的近红外光谱使得样本间的距离度量效果不佳, 严重影响了相似性样本替换的准确率。 因此, 建立一种适用于高维近红外光谱数据的特征提取、 数据降维的方法[3], 来满足样本之间的相似性度量显得尤为重要[4]。
臧卓[5]等为探讨主成分分析法(PCA)在乔木树种高光谱数据降维分类中的效果, 分别对滤波后的高光谱反射率数据及3种预处理数据进行降维处理, 树种分类时选择前15~20个主成分, 分类精度达到一个较高的水平。 但PCA作为一种线性降维方法, 无法对光谱中非线性特征进行有效提取, 使得某些波段的特征信息在降维过程中丢失。 徐宝鼎[6]等将高维光谱数据划分为多个网格子空间, 通过改进的LLE算法将高维子空间数据映射至低维空间, 计算每个子空间的相似度矩阵, 并将每个空间中归一化后的相似度矩阵进行加和, 以此实现光谱的相似性度量。 改进后的LLE算法虽然避免了因样本分布稀疏导致的不确定性, 但近邻数的选择仍会对降维结果产生较大影响。 姜斌[7]等利用t-SNE算法对恒星光谱进行降维, 利用流形学习方法从高维采样数据中恢复低维流形结构, 并求出相应的嵌入映射, 降维后的恒星光谱在机器学习分类器中具有较高的分类准确率。 但t-SNE算法使用KL散度表示高维空间和低维空间中数据点概率分布的差异, 当分布相距较远或完全没有重叠时, 将会出现梯度消失的现象。 马雁军[8]等应用PPF(projection of basing on principal component and fisher criterion)建立国产白肋烟近红外光谱的投影分析模型, 并度量其产地、 部位间相似性, 将相似性判定结果用于指导烟叶替换和复烤配方的微调。 基于主成分分析及Fisher准则的PPF方法能够克服数据高维距离度量无效性带来的困扰, 但维度越高, 带来的后续计算越困难。 由此可见, 对高维光谱数据降维是分析样本间关系的必要环节, 消除光谱中堆叠的冗余信息, 实现高维数据的降维能够提高近红外光谱样本间相似性度量的精准度。
针对上述问题, 本文提出了一种基于Wasserstein散度[9]的t分布随机近邻嵌入算法(Wt-SNE)。 该方法能够有效地把高维的数据映射到低维的空间, 采用Wasserstein散度衡量两个空间的概率分布, 有效避免了近红外光谱在高维空间内由于样本分布稀疏导致的梯度消失的现象, 并且保持了数据在高维空间的局部结构。 实验表明, 该方法降维后的近红外光谱类别边界更明显, 低维空间的距离度量能够表示样本间的相似度, 在烟叶近红外光谱相似性度量中表现出良好的效果。
随机近邻嵌入SNE(stochastic neighbor embedding)是一种非线性流形降维算法[10], 通过仿射变换将数据点映射到概率分布上, 在高维空间和低维空间构建概率分布, 优化两个概率分布之间的距离即KL散度, 使其分布尽可能地相似, 以此实现数据从高维空间到低维空间的降维。
采用SNE在高维空间构建近红外光谱的概率分布的过程如下。 假设在高维欧氏空间RD中有n个D维数据集X={x1, x2, x3, …, xn}, xi∈ RD, (i=1, 2, 3, …, n), 利用式(1)计算数据点xi与xj之间的概率分布pij, 以高斯概率分布表示样本的位置信息[11]。
式(1)中,
为了让高维空间的点映射到低维空间后, 尽可能保持一样的分布, SNE采用梯度下降的方法, 不断更新低维空间内点的分布, 使得两个概率空间的KL散度逐渐降低, 使得降维之后的特征空间与高维空间局部邻域信息具有较高的相似度。
Wasserstein散度是一种度量两个概率分布之间距离的方法[13], 能够保持两个概率分布的几何特性。 目前, Wasserstein散度在概率理论和数理统计方面已有成熟的理论研究, 并且随着深度学习神经网络的发展, Wasserstein散度在算法研究领域具有较为广泛的应用[14]。 值得一提的是在生成对抗网络中, Wasserstein散度优化了JS散度距离衡量不合理性, 拉近生成数据和真实数据的数据分布, 有效的解决了生成对抗网络训练不稳定的问题, 提高了样本数据生成、 图像生成、 文本生成的准确率[15]。 Wasserstein散度表示两个概率分布之间的距离定义如式(3)
式(3)中,
为了在近红外光谱中, 找到与目标样本相似度匹配最近的样本, 提出了基于Wasserstein散度的t分布随机近邻嵌入算法(Wt-SNE)。 先将近红外光谱数据利用概率分布在高维空间表示, 重构低维度空间的概率分布, 同时引入Wasserstein散度替换KL散度, 通过迭代调整低维空间内样本点的位置信息, 降低两个空间样本分布差异性, 增强低维空间中相似性度量结果的准确度, 基于Wasserstein散度的t分布随机近邻嵌入算法的相似性度量方法步骤如下:
Step 1: 根据式(1), 将近红外光谱数据集X中每个样本在高维空间内的分布用高斯概率分布表示, 获取高维空间中两个样本的条件概率pj|i。
Step 2: 在低维空间中, 对于低维特征矩阵Y={y1, y2, y3, …, yn}使用更重长尾分布的t分布来避免crowding问题[16], 以此来替代高斯分布, 表达低维空间内两点之间的相似度, 在t分布下第i个样本分布在样本j周围的概率qij计算如式(4)
Step 3: 引入Wasserstein散度计算高维空间和低维空间两个概率分布之间的距离W(p, q), 通过梯度下降算法, 迭代更新低维度空间的特征矩阵Y, 计算概率分布, 优化Wasserstein散度。 低维度空间的特征矩阵Y更新如式(5)
式(5)中, Y(t)表示t轮迭代后的特征矩阵, η 为梯度更新的学习率, α 为动量因子。 相比KL散度, 即使两个分布的支撑集没有重叠或者重叠非常少, Wasserstein散度仍然能反映近红外光谱在两个空间内概率分布的相似情况, 而KL散度变得无意义。
Step 4: 低维特征矩阵Y, 保留了原始数据的多种有效特征结构, 通过计算低维特征矩阵样本点之间的马氏距离, 得到目标样本与其他样本之间的差异程度[17]。 此距离越大, 样本间的差距越大, 反之样本间的相似度越高, 距离度量标准如式(6)
式(6)中, yi、 yj分别为降维后第i个和第j个样本的特征向量, V为类协方差矩阵。
选取某烟草企业提供的近3年广西、 山东、 四川、 云南四个产区具有代表性的280个烟叶样品, 其主要化学成分含量已知。 将样本置于60 ℃烘箱内烘2 h, 磨碎过40目筛, 常温避光密封保存24 h后采集样本光谱。
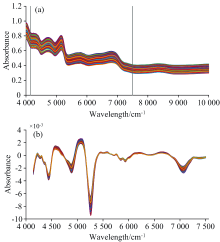
选用尼高力公司的Antaris Ⅱ 近红外光谱仪, 光谱扫描范围为4 000~10 000 cm-1, 分辨率为8 cm-1。 每个实验样品称重15 g, 置于样本杯中用压样器压实, 压实用200 g压力。 保持室温在18~22 ℃、 湿度< 60%。 重复扫描3次取平均值作为该样品的最终光谱, 如图1(a)所示。 化学物质的含量是度量样本烟叶之间相似性的关键指标, 烟叶中总糖、 烟碱、 还原糖等物质的特征波段主要分布在4 140~7 500 cm-1范围内, 不同样本在此波段吸收峰的变化存在差异, 因此选取4 140~7 500 cm-1波段作为样本相似性度量的波长区间。 将光谱数据进行Savitzky Golay(9, 2)一阶导数预处理, 以消除环境、 仪器和人为等因素的噪声干扰, 预处理后的光谱如图1(b)所示。
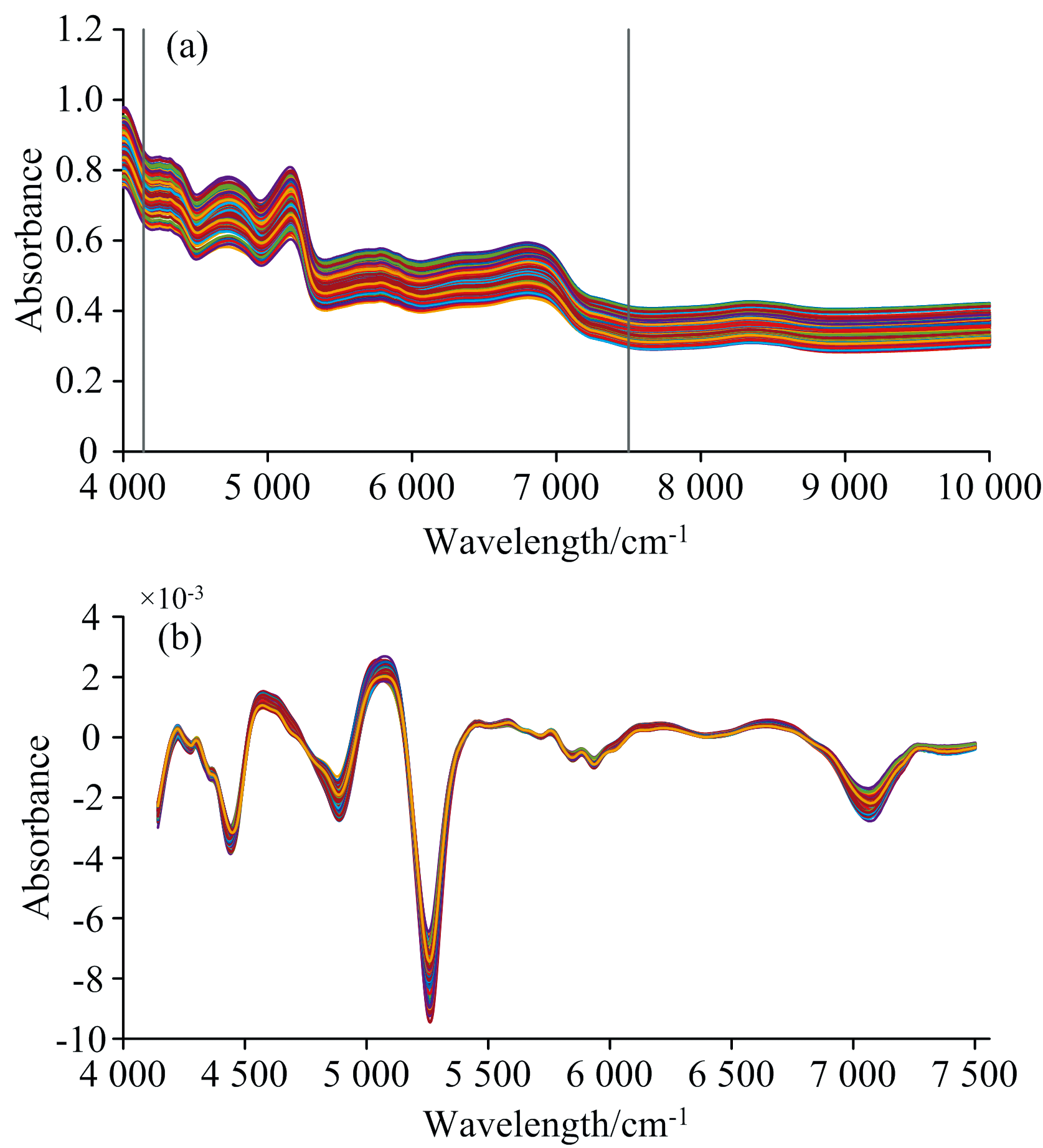 | 图1 原始光谱图和预处理结果 (a): 原始光谱; (b): Savitzky Golay(9, 2)一阶导数预处理Fig.1 The original and pretreated spectra (a): Original spectra; (b): Savitzky Golay(9, 2) first derivative |
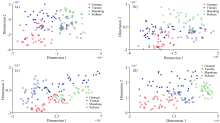
领域专家认为相同产地的烟叶相似度高, 将高维烟叶光谱数据进行降维, 重构的低维数据尽可能的表达原数据的特征信息。 好的降维方法应使相同产地的烟叶尽可能靠近, 不同产地的烟叶尽可能分开。 随机选取140个样本, 分别采用PCA、 LPP、 t-SNE、 Wt-SNE方法对不同产区烟叶光谱数据进行降维的投影效果对比如图2所示。
 | 图2 降维投影图 (a): PCA; (b): LPP; (c): t-SNE; (d): Wt-SNEFig.2 Dimension reduction projection diagram (a): PCA; (b): LPP; (c): t-SNE; (d): Wt-SNE |
可以看出, PCA算法降维后的烟叶样本, 投影混合现象严重, LPP算法无法有效区分不同产区的烟叶, 存在部分样本的重叠, 线性降维方法PCA、 LPP对于近红外光谱数据的相似性和样本分布特征提取较差。 t-SNE算法对四个产地的烟叶区分度优于PCA和LPP算法, 但分类边界效果较差。 本文提出的Wt-SNE算法对于烟叶产地的区分度明显高于其他三种算法, 产区分类边界明显, 降维效果较优。
近红外光谱数据能够反映不同产地烟叶的成分、 质量的差异性, 将其降至低维后进行分类, 通过产地识别的准确率反映降维方法对近红外光谱数据的特征提取能力。 将280个具有代表性的样本数据按照3∶ 1的比例随机划分数据集, 210个样本作为训练集, 剩余样本为测试集。 分别利用PCA、 LPP、 t-SNE、 Wt-SNE将光谱数据降维至1~7维, 再通过KNN分类器对低维光谱数据建立烟叶产地分类模型, 分类准确率随光谱特征维度的变化如图3所示。
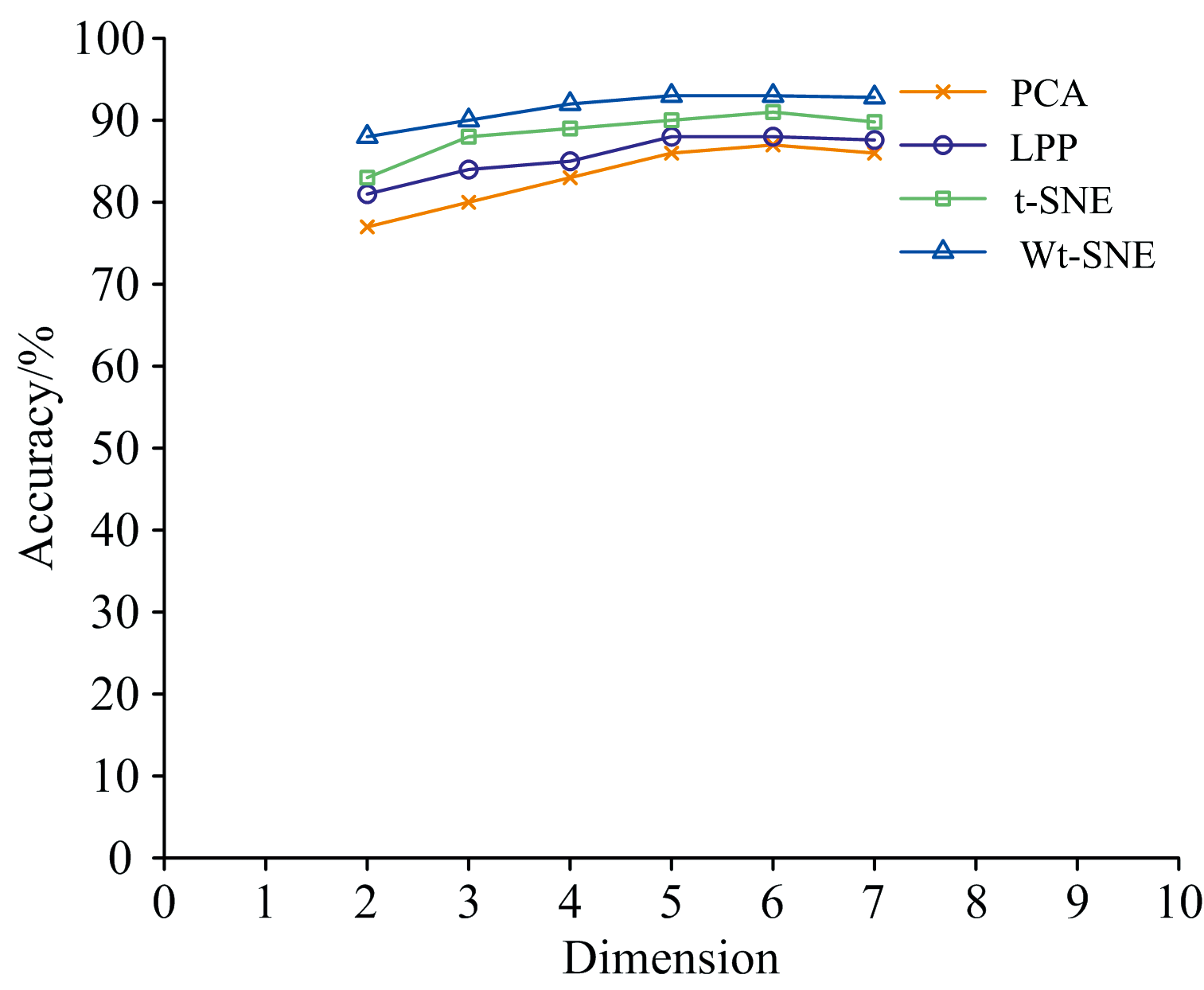 | 图3 不同维度下产地识别准确率Fig.3 Accuracy of origin recognition in different dimensions |
通过图3可以看出, 四种降维方法得到的特征数据在不同维度下产地识别准确率各不相同, 总体上随着维度的增加分类准确率先上升后趋于平缓, 在6维特征空间之后呈现下降趋势。 因此实验将光谱数据降至6维特征, 以确保四种降维方法能够从近红外光谱中提取到烟叶的关键信息, 从而保证烟叶样本相似性度量的可靠性。
为进一步验证降维结果的有效性, 分别使用PCA、 LPP、 t-SNE、 Wt-SNE算法对烟叶光谱数据降至6维特征, 之后除KNN分类器外, 另外再选用SVM和PLS-DA分类器利用训练集光谱建立烟叶产地分类模型, 对测试集70个样本进行产地预测, 表1为不同算法在测试集中的产地分类准确率对比。
| 表1 烟叶产地分类准确率对比 Table 1 Comparison of accuracy of tobacco origin classification |
由表1可以得出, 三种分类器对原始数据进行产地识别的准确率最低, 说明原始数据中存在较多的噪声和冗余信息的干扰。 运用四种降维方法后的样本产地识别准确率均有所提高, 其中, Wt-SNE算法降维后的数据在三种分类器下的产地识别准确率分别为93.8%、 91.5%、 92.7%, 相比t-SNE算法识别错误的样本有所减少, 这是因为在t-SNE算法中, KL散度虽然能够确保低维空间生成的t分布正确匹配高维空间高斯分布的峰值部分, 但尾部样本的概率分布将无法有效匹配。 而Wt-SNE算法采用Wasserstein散度衡量两个概率分布的距离, 更加重视全局性的概率分布特征, 且两概率分布的尾部同样会受到关注, 有效拉近了低维空间生成的概率分布与高维空间真实的概率分布之间的相关性。 相比其他算法, 该方法降维后保留了更多烟叶的特征信息, 因此识别率最高, 这与投影分析结果一致。
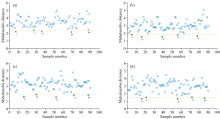
单料烟叶的替换是配方维护和保持卷烟叶组配方质量稳定性的关键环节, 在某一需要维护的卷烟叶组配方中, 选取一个单料烟作为替换的目标烟叶, 从90个用于维护的烟叶样品中查找相似烟叶。 图4为采用PCA、 LPP、 t-SN、 Wt-SNE方法降维后的维护烟叶样本与目标样本之间的马氏距离以及通过马氏距离选出5个距离最近的替换样本。 替换样本与目标样本在空间中的马氏距离反映了样本间的相似度, 距离越近相似度越高。
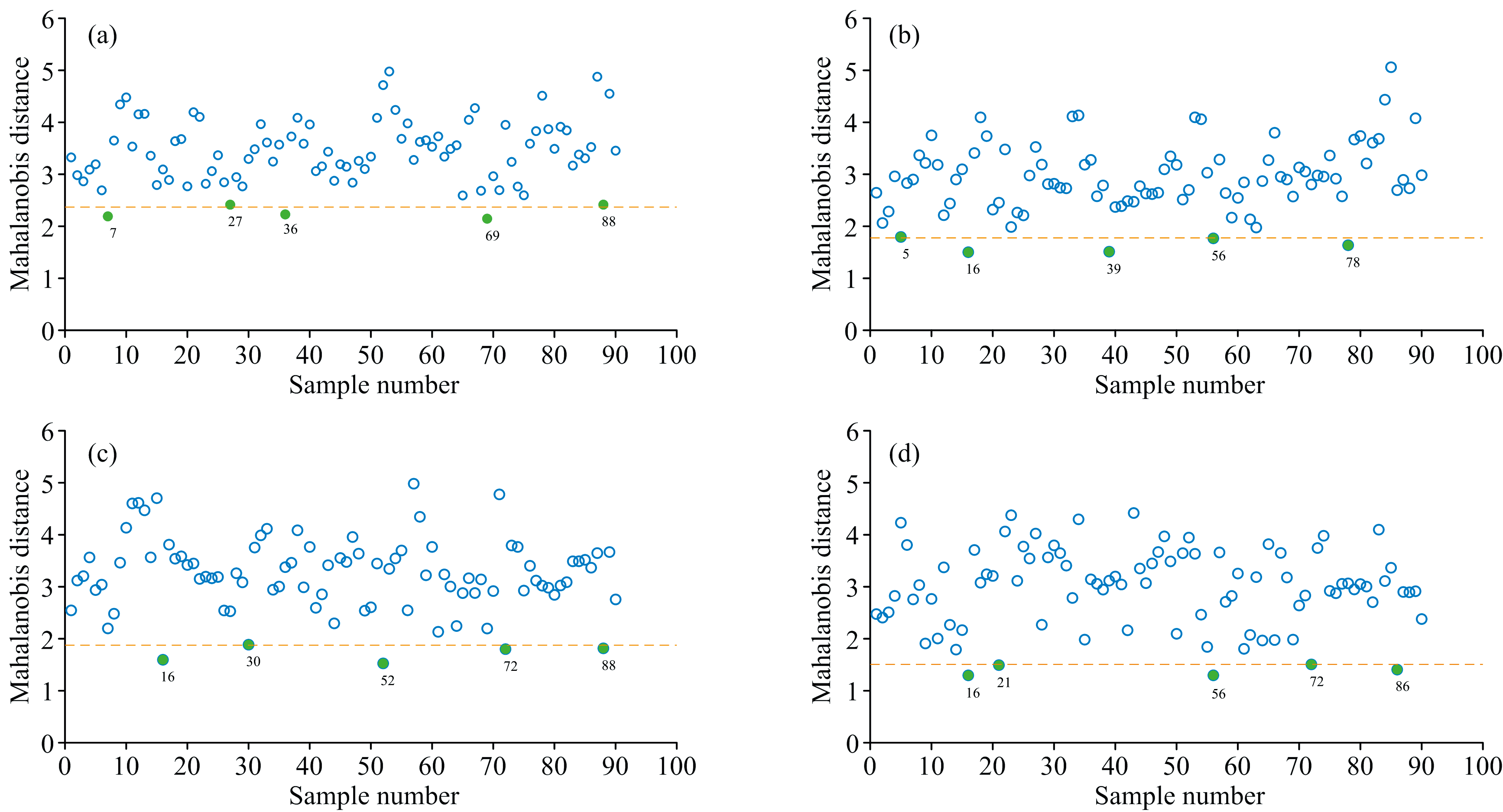 | 图4 备选样本与目标样本之间的马氏距离度量结果 (a): PCA; (b): LPP; (c): t-SNE; (d): Wt-SNEFig.4 The Mahalanobis distance measurement results between the candidate sample and the target sample (a): PCA; (b): LPP; (c): t-SNE; (d): Wt-SNE |
从图4可以看出, 四种降维方法选取的替换烟叶存在部分重复的情况, 样本16、 56、 72、 88均被两种以上方法选为较优先的替换样本, 其中样本16被LPP、 t-SNE和Wt-SNE三种方法选为与目标样本最为接近的替换样本, 表明通过马氏距离的度量在不同的低维空间内选取的替换结果具有相似性。
为验证选取的替换样本与目标样本的相似度情况, 选取四种降维方法中与目标样本马氏距离最为接近的2个样本作为替换烟叶, 分别从化学成分和感官评吸方面对选取的替换烟叶进行评价。 感官评吸组织10位专家依据YC/T 497— 2014《卷烟中式卷烟感官评价方法》从香气、 烟气、 口感特性方面进行打分评价。 此外, 为直观评价烟叶总体质量差异, 以0.5分为梯度对烟叶品质进行打分, 烟叶品质偏差感官评价标准见表2。 表3为采用四种降维方法选取与目标样本马氏距离最为接近的2个样本评价结果。
| 表2 烟叶品质偏差感官评价标准 Table 2 Sensory evaluation standard of tobacco quality deviation |
| 表3 目标烟叶和替换烟叶评价结果对比 Table 3 Evaluation comparison of target tobacco and replacement tobacco |
由表3可以看出, LPP、 t-SNE和Wt-SNE选取的最为接近的替换烟叶(16号样本)与目标烟叶的相似度较高, 烟叶总糖和烟碱的含量与目标烟叶最为相近, 香气、 烟气、 口感评析得分表现出较高的一致性, 烟叶总体品质无偏差。 但LPP和t-SNE选取的次优替换烟叶39号和52号样本与目标烟叶存在一定差异, 相比之下Wt-SNE选取的替换烟叶56号烟叶与目标烟叶的相似度较为接近, 表明Wt-SNE降维后的数据在替换样本选择上具有一定的稳定性, 能够准确地度量烟叶近红外光谱之间样本的相似度, 是一种有效的单料烟叶的替换方法。
基于Wasserstein散度的t分布随机近邻嵌入算法(Wt-SNE)能够有效提取近红外光谱高维空间稀疏矩阵的特征信息, 实现高维数据降维的同时, 保留了高维数据的特征结构, 利用Wasserstein散度改进了t-SNE算法两个空间中概率分布的差异表示, 保证降维后数据的信息映射更加准确。 实验表明, 该方法可视化投影类别区分明显, 降维后的数据保留了烟叶样本的有效特征。 进一步对单料烟替换前后的相似性结果进行了对比, Wt-SNE选取的替换烟叶在化学成分和感官评析方面与目标烟叶相似性最高, 满足企业原料烟叶替换标准, 该方法可在产品相似性度量的其他领域得到进一步的推广。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|