




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
比较用可见/短波近红外光谱结合机器学习算法测量土壤性质的不同多元校准方法分析
[黄招娣1  , 陈再良
, 陈再良2 , 王琛3 , 田彭2 , 章海亮2 , 谢潮勇2, * , 刘雪梅4, * ]
, 陈再良, 刘雪梅]
|
|


作者简介: 黄招娣, 女, 1980年生, 华东交通大学基础实验与工程实践中心实验师 e-mail: 14136092@qq.com
土壤肥力通常由有机质、 总氮、 速效磷、 速效钾等含量决定。 这些物质的含量通常采用可见/长波近红外光谱(visible/near-infrared spectroscopy, Vis/NIRS: 350~2 500 nm)进行研究, 可见/短波近红外区域(visible/shortwave near-infrared spectroscopy, Vis/NIRS: 325~1 075 nm)的研究却非常罕见, 将可见/短波近红外光谱结合机器学习算法来测量土壤养分具有巨大潜力。 选取了南昌市新建区和吉安市安福县的四个村庄作为样品获取地点, 通过2×2网格法选取对角区的10~30 cm深度的土壤样本, 其中水稻土120份(水稻土1和水稻土2), 棕壤60份、 红壤60份。 样品经过研磨、 风干等处理后用四分法均匀划分为两份, 用于测定样品光谱信息和理化信息。 将获取的光谱数据去除325~349和1 073~1 075 nm的噪声波段, 然后采用S-G卷积平滑结合一阶导数进行预处理。 将预处理后的光谱数据进行主成分分析(PCA), 根据主成分分析得到的得分图(PC1: 98.44%, PC2: 3.5%, PC3: 0.14%)显示出样品存在明显聚类现象且在二维空间内相互可分, 样品存在明显聚类现象, PCA可以在一定程度上合理解释不同土壤样品的光谱特征差异。 将预处理后的光谱数据建立全波段主成分回归(PCR)和偏最小二乘回归(PLSR)模型, 通过PCA和PLSR对光谱数据降维, 提取出3个主成分因子(PCs)和9个潜在变量(LVs), 建立非线性反向传播神经网络(BPNN)和最小二乘支持向量机(LS-SVM)模型。 通过比较PCR、 PLSR、 BPNN和LS-SVM方法对Vis/SW-NIRS及对OM、 TN、 P、 K的预测精度, 得出以下结论: (1)LS-SVM-LVs模型在所有土壤性能方面都优于PCR、 PLSR、 BPNN-PCs、 BPNN-LVs和LS-SVM-PCs模型; (2)LS-SVM-LVs模型对OM和N的预测精度最高, 这是在NIR区域具有光谱响应的特性; (3)采用Vis/SW-NIRS测定土壤矿质养分P和钾, 具有不同的准确性, 这是由于光谱活性成分的共变。 根据本研究取得的结果, 建议采用LS-SVM-LVs分析作为预测土壤性质(OM、 TN、 P和K)的最佳模型方法。 然而, 还需要进一步的研究来深入解释在近红外区域不具有直接光谱响应的土壤特性的测量。 该研究成果可以为当地的精细农业的发展提供理论与技术参考。
, CHEN Zai-liang, LIU Xue-mei
Soil fertility is usually determined by the content of organic matter, total nitrogen, available phosphorus, and available potassium. The content of these substances is usually studied by visible/long-wave near-infrared spectroscopy (Visible/near-infrared spectroscopy, Vis/NIRS: 350~2 500 nm), and visible/shortwave near-infrared spectroscopy (Vis/NIRS: 325~1 075 nm) research is scarce, and the combination of visible/short-wave NIR spectroscopy with machine learning algorithms to measure soil nutrients has great potential. In this paper, four villages in Xinjian District, Nanchang City and Anfu County, Ji’an City, were selected as sample acquisition sites, and soil samples with a depth of 10~30 cm in the diagonal area were selected by the 2×2 grid method, including 120 paddy soils (paddy soil 1 and paddy soil 2), 60 parts of brown soil, and 60 parts of red soil. After grinding and air-drying, the samples were evenly divided into two parts by the quartering method, which was used to determine the samples’ spectral and physicochemical information. The acquired spectral data were removed from the noise bands of 325~349 and 1 073~1 075 nm and then preprocessed by S-G convolution smoothing combined with the first derivative. Principal component analysis (PCA) was performed on the preprocessed spectral data, and the score map (PC1: 98.44%, PC2: 3.5%, PC3: 0.14%) obtained according to the principal component analysis showed that the samples had obvious clustering and were in two The samples can be separated from each other in the dimensional space, and the samples have obvious clustering phenomenon. PCA can reasonably explain the differences in the spectral characteristics of different soil samples to a certain extent. In addition, full-band principal component regression (PCR) and partial least squares regression (PLSR) models were established on the preprocessed spectral data, and PCA and PLSR dimensionally reduced the spectral data to extract three principal component factors (PCs) and 9 latent variables (LVs), build nonlinear back-propagation neural network (BPNN) and least squares support vector machine (LS-SVM) models. By comparing the prediction accuracy of Vis/SW-NIRS for OM, TN, P, K by PCR, PLSR, BPNN and LS-SVM methods, the following conclusions can be drawn: (1) The LS-SVM-LVs model has good performance in all soil properties All are better than PCR, PLSR, BPNN-PCs, BPNN-LVs and LS-SVM-PCs models; (2) LS-SVM-LVs model has the highest prediction accuracy for OM and N, which is characteristic of spectral response in the NIR region (3) Determination of soil mineral nutrients P and K by Vis/SW-NIRS has different accuracy, which is due to the co-variation of spectral active components. Based on the results obtained in this study, LS-SVM-LVs analysis is recommended as the best model approach for predicting soil properties (OM, TN, P, and K). However, further research is needed to deeply interpret measurements of soil properties that do not have direct spectral responses in the near-infrared region. The research results of this paper can provide theoretical and technical references for the development of local precision agriculture.
土壤肥力通常由有机质、 总氮、 速效磷、 速效钾等含量决定。 土壤中有机质由不同分解阶段的动植物残余物组成, 能够增加土壤肥力与缓冲性, 还能够有效减少农药和重金属污染[1]。 土壤氮养分能够促进植物的根、 茎、 叶的生长和发育, 是决定作物品质的首要元素[2]。 土壤中磷和钾可以增加作物抗寒、 抗旱、 抗病及抗倒伏能力。 对不同地区和类型的土壤的养分含量的检测与调控, 有利于挖掘土壤潜质, 提升作物品质和产量, 研究土壤肥力状况对我国农业发展具有重要意义。 我国自古就讲究精耕细作, 快速获取土壤养分含量信息是研究土壤肥力状况的关键, 传统的土壤分析方法步骤繁琐、 耗时费力, 不利于精细农业的发展[3]。
近红外光谱技术凭借着快速、 便携等突出优势在土壤肥力检测方面展开了大量研究: Marta等[4]采用四种范围光谱(350~700、 701~1 000、 1 001~2 500和350~2 500 nm)分析了葡萄园土壤的氮、 有机质和粘土含量; Said等[5]比较了采用350~2 500 nm范围的可见/近红外光谱结合偏最小二乘回归(PLSR)、 支持向量回归(SVR)、 多元自适应回归(MARS)三种模型对有机质和粘土含量的评估的最佳方法; Xiao等[6]分析了在不同土壤粒径下的光谱反射率规律, 研究了不同粒径时光谱检测氮精度的影响等。 经过研究发现, 研究学者更专注于可见/长波近红外区域的光谱对土壤性质的研究, 对于可见/短波近红外光谱区域(325~1 075 nm)是否对土壤性质也具有较好的响应机制的研究却非常罕见。 不仅如此, 采用主成分分析(PCA)和偏最小二乘回归(PLSR)对光谱数据降维后, 建立机器学习中典型的非线性模型的反向传播神经网络(BPNN)[7]和最小二乘支持向量机(LS-SVM)[8]模型的相关研究存在研究精度不高等问题。 近红外光谱结合数据融合的机器学习算法被验证在光谱领域, 特别是土壤研究方面具有较大潜力。
本研究目的是分析土壤在可见/短波近红外光谱区域是否具有良好的光谱响应机理, 同时建立Vis/SW-NIRs区域不同种类土壤有机质、 总氮、 速效磷和速效钾的预测模型。 比较了主成分回归(PCR)、 偏最小二乘回归(PLSR)、 反向传播神经网络(BPNN)和最小二乘支持向量机(LS-SVM)对土壤性质的测量精度。
研究区位于南纬24° 29'— 30° 04', 东经113° 34'— 118° 28'的中国江西省, 该地降雨量充沛, 环境污染少, 土壤资源富饶, 是我国农业和林业大省, 十分适合研究土壤性质。 通过调查, 该地的水稻土、 红壤和棕壤是具有代表性的几种土壤类型, 其中红壤和水稻土是当地最具特色的土壤类型。 红壤因缺乏碱金属而富含铁、 铝氧化物而呈现酸性红色, 水稻土受人为因素及自然成土的双重影响形成具有剖面特征的土壤, 棕壤通常具备较为丰富的有机物, 是肥沃的林业用土。 实验选取了南昌市新建区和吉安市安福县的四个村庄作为样品获取地点, 如图1(a)所示。
 | 图1 样品采集示意图 (a): 采集地; (b): 采样网格; (c): 采样深度Fig.1 Schematic diagram of sample collection (a): Collection places; (b): The net of collection; (c): The deep of collection |
通过2× 2网格法确定如图1(b)所示的两个对角区作为采样点, 采集10~30 cm深度的土壤用于研究[图1(c)]。 采集过程中将采样点的石子、 草根等杂质剔除, 从两个采样点采集100 g土壤充分混合均匀装袋, 并做好标记。 实验采集了水稻土120份, 红壤60份, 棕壤60份, 共240份样品。
由于土壤粒径大小、 含水量等会影响测量的光谱反射率, 因此将样品充分研磨、 过筛, 然后放置在实验室环境下自然烘干48 h, 风干后的样品再经过2 mm筛子过筛后均匀放置在容器内。
测定土壤养分含量的理化值时, 采取化学方法。 测量土壤有机质、 总氮、 速效磷和速效钾的含量分别采取重铬酸钾氧化法、 杜马斯干烧法、 比色法和醋酸铵浸提— — 火焰光度法。 测出样品中含量如表1所示。
| 表1 土壤样品中有机质和总氮、 磷和钾的含量 Table 1 Statistics of OM, TN, P and K and TN in soil samples |
光谱测量仪为美国ASD手持式地物光谱仪, 覆盖325~1 075 nm的波长范围, 采样间隔1 nm。 每个样品均采集10次, 取平均值作为样品光谱。
由于数据的采集会受到仪器、 环境和人为的影响, 所采集的光谱数据存在大量噪声。 在数据处理过程中去除边缘噪声较大的波段(325~349和1 074~1 075 nm), 保留350~1 073 nm波段的光谱数据进行样品建模分析。 为进一步提高光谱信噪比, 将每5个连续波长作一次平均, 采用卷积平滑结合一阶导数处理。 采用S-G平滑对数据进行预处理, 可以明显降低高频噪声、 基线偏移等噪声干扰的影响, 提高光谱数据的平滑性。 通过导数预处理可以有效消除背景影响和基线漂移影响, 分辨重叠峰, 提高灵敏度。
主成分回归(principal component regression, PCR)[9]和偏最小二乘回归(partial least squares regression, PLSR)[10, 11]是多元线性回归中最为常用的两种校正模型。 主成分分析的中心目的是将原变量降维, 使得新产生的变量尽可能表征原变量的数据特征。 采用偏最小二乘回归提取的特征变量不仅能很好地概括原始变量的信息, 而且对因变量具有很强的解释能力。
1.5.1 反向传播神经网络
反向传播神经网络(back propagation neural network, BPNN)[9]模型用到了一个标准的前馈网络, 由一个输入层, 一个隐含层和一个输出层组成。 其中隐含层采用非线性Sigmoid函数作为激活函数, 输出层引用的是线性函数。 图2是BP神经网络结构图。
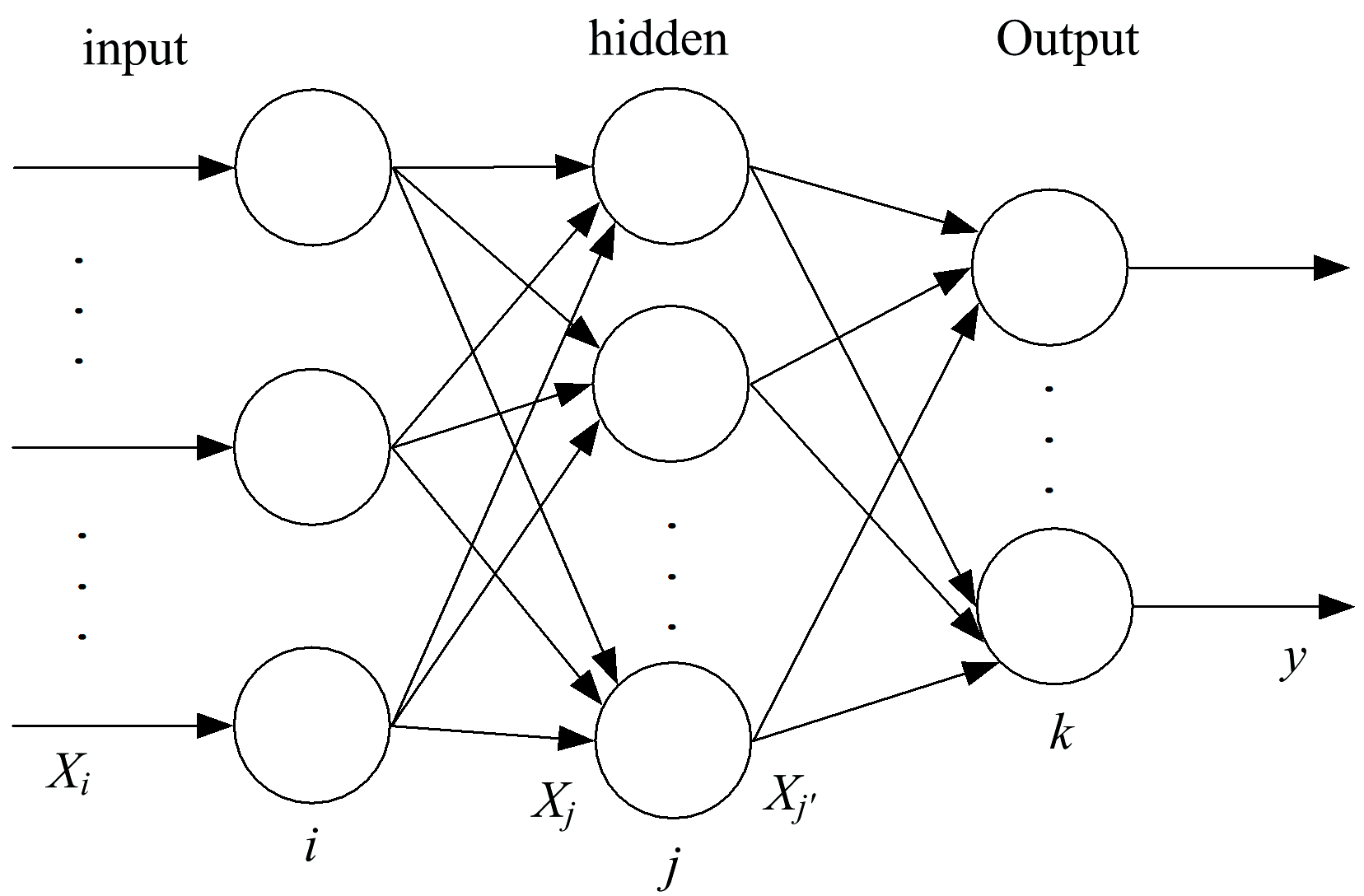 | 图2 BP神经网络结构Fig.2 BP neural network structure |
1.5.2 最小二乘支持向量机
最小二乘支持向量机(least squares-support vector machine, LS-SVM)[11, 12]是回归计算与模式识别中一种强大的机器学习方法, 采用如式(1)所示的非线性径向基核函数, 可以有效处理多元校准中的线性和非线性问题。
1.5.3 模型评价指标
模型的评价指标包括决定系数(coefficient of determination, R2)、 预测均方根误差(root mean square error, RMSE)和相对分析误差(relative percent deviation, RPD)。 通常RMSE越小, R2越接近真值1, 模型性能越好、 精度越高。 RPD常被用于描述模型稳定性, RPD计算公式如式(2)所示
$RPD=\sqrt{\frac{\overset{n}{\mathop{\mathop{\sum }_{i=1}}}\, {{({{{{\hat{y}}}}_{i}}-{{{{\bar{y}}}}_{i}})}^{2}}}{\overset{n}{\mathop{\mathop{\sum }_{i=1}}}\, {{({{{{\hat{y}}}}_{i}}-{{y}_{i}})}^{2}}}}$ (2)
式(2)中, yi是样品的真实值, $\bar{y}$和${{{\hat{y}}}_{i}}$分别是样品的平均值和模型预测值。
当RPD< 1.4时, 认为模型不可靠; 1.4< RPD< 2.0时, 模型较为可靠; 2.0< RPD< 2.5时, 模型具有较高的可靠性, 可用于建模分析; RPD> 2.5时, 模型非常可靠, 模型性能好。
采集到的土壤样品光谱原始反射曲线如图3(a)所示。 从图像可以看出, 整体光谱反射率随着波长点增大而上升, 并在460、 740和900 nm等处存在较为明显的光谱吸收特征。 这些特征与土壤颜色、 有机成分和粘土矿物之间存在联系。 据报道, 460和680 nm左右可见光的吸收特征与460 nm的蓝色区域和680 nm左右的红色区域相关。 750~1 073 nm的近红外区域已有大量实验表明与有机分子中含氢基团的吸收区一致, 900 nm处的反射特征与C— H+C— H、 C— H+N— H的组合相关联。 图3(b)是经过预处理后的光谱反射曲线。
 | 图3 光谱(a)原始反射曲线和通过(b)SG+1ST预处理反射曲线Fig.3 Spectral (a) rawreflectance curve and pre-processed spectra by SG+1ST |
PCA通常被称为一种数据压缩技术, 通过PCA得到的少量PC变量可以解释大部分原始信息。 为了更加清晰地看出不同样品的光谱差异, 用PCA得到的前三个PCs(累计贡献度99.67%)进行了聚类分析, 如图4(a, b, c)所示。 根据得分图可知, 四种土壤样品的光谱特征存在一定可区分度。 得分图显示不同样品存在聚类叠加现象, 可以明显看出样品在二维空间内相互可分。 PCA可以在一定程度上合理解释不同土壤样品的光谱特征差异。
 | 图4 前三个主成分得分的散点图 (a): PC-1— PC-2; (b): PC-1— PC-3; (c): PC-2— PC-3Fig.4 Scatter plots of the first three principal components scores (a): PC-1— PC-2; (b): PC-1— PC-3; (c): PC-2— PC-3 |
通过PCA和PLSR获得的主成分变量(PCs)和潜在因子(LVs)作为校正模型的输入是减少模型运行时间、 提高校准模型鲁棒性的有效办法。 表2是通过PLSR模型的前9个LVs对土壤性质的解释方差, 这9个LVs几乎能100%解释原始数据。 将这9个LVs和PCA得到的前3个PCs作为后续校正模型输入。 把采集的180个样品按照2∶ 1(120∶ 60)划分为建模集与预测集建立PCR和PLSR模型, 以及主成分变量(PCs)和潜在因子(LVs)作为校正模型输入的BPNN和LS-SVM模型。
| 表2 通过PLSR模型解释前9个LVs对土壤性质的方差 Table 2 The explained variance of the first nine LVs for soil properties by the PLSR models |
图5(a, b, c)和图6是通过不同多元回归模型得到有机质、 总氮、 速效磷和速效钾的R2、 RMSE和RPD。 所用到的模型评价指标中, RMSE被认为比R2和RPD更为重要, 这是由于RMSE直接关系模型预测误差。 从高R2、 RPD和低RMSE可知LS-SVM-LVs是最优模型。 此外, OM在四种理化值的预测效果中最为理想(R2=0.873 4, RMSE=2.92和RPD=2.56), N(R2=0.831 0, RMSE=16.499和RPD=2.43)、 P(R2=0.780 1, RMSE=4.977和RPD=2.13)和K(R2=0.735 4, RMSE=13.42和RPD=1.94)也有着较为不错的预测效果。 Liu等[8]采用可见/短波近红外在土壤肥力检测中也做了相应的研究, 其研究结果表明: EWs-LS-SVM模型是最优模型, OM的R2和RMSE是0.863 1和3.61, N的R2和RMSE是0.820 3和17.20, P的R2和RMSE是0.766 5和5.50, 以及K的R2和RMSE是0.727 3和15.08。 本次研究均提高了其R2, 降低了RMSE, 获得了更好的模型预测效果。
 | 图5 (a)有机质、 (b)总氮、 (c)速效磷和(d)速效钾的R2和RMSEFig.5 R2 and RMSE for: (a) organic matter, (b) available N, (c) available phosphorous and (d) available potassium |
 | 图6 有机质、 总氮、 速效磷和速效钾的相对分析误差(RPD)Fig.6 Relative percent deviation (RPD) for: organic matter, available TN, available phosphorous and available potassium |
尽管P和K在短波可见/近红外区域不具有直接的光谱响应, 但是通过实验证明了短波可见/近红外光谱能够用于测量P和K, 可能是由于P和K与C— H— O— N键之间存在间接联系。
通过PCA得到的PCs和PLSR得到的LVs作为模型输入均使模型性能得到了优化, 但BPNN模型的预测精度同LS-SVM模型相比不是最优的模型, 但也得到了较好的预测结果。
通过比较PCR、 PLSR、 BPNN和LS-SVM方法对Vis/SW-NIRS对OM、 TN、 P、 K的预测精度, 可以得出以下结论:
(1)LS-SVM-LVs模型在所有土壤性能方面都优于PCR、 PLSR、 BPNN-PCs、 BPNN-LVs和LS-SVM-PCs模型。
(2)LS-SVM-LVs模型对OM和N的预测精度最高, 这是在NIR区域具有光谱响应的特性。
(3)采用Vis/SW-NIRS测定土壤矿质养分P和钾, 具有不同的准确性, 这是由于光谱活性成分的共变。
根据本研究取得的结果, 建议采用LS-SVM-LVs分析作为预测土壤性质(OM、 TN、 P和K)的最佳模型方法。 然而, 还需要进一步的研究来深入解释在近红外区域不具有直接光谱响应的土壤特性的测量。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|