


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于冠层高光谱特征的油茶叶片碳氮比估算模型构建
[傅根深1  , 吕海燕
, 吕海燕1 , 燕李鹏1 , 黄庆丰1 , 程海峰2 , 王新文3 , 钱文祺1 , 高祥4 , 唐雪海1, * ]
, 吕海燕]
|
|


作者简介: 傅根深, 1997年生, 安徽农业大学林学与园林学院硕士研究生 e-mail: fugenshen2021@163.com
叶片碳氮比是反映油茶个体养分利用效率的重要指标, 基于冠层高光谱特征估算碳氮比可为油茶养分监测及精准施肥提供重要的科学依据。 当前, 利用高光谱开展经济林理化性质的研究较少, 特别是面向具有花果同期生物学特性的油茶, 其高光谱数据除面临共线性问题外, 复杂的理化性质也对敏感光谱特征的响应及估算模型构建带来极大挑战。 以安徽黄山区域的油茶长林系列品种为研究对象, 在野外环境下采集了120株油茶的冠层光谱, 选取可见光与近红外谱区400~1 000 nm波长范围的高光谱特征进行分析。 利用多元散射校正(MSC)和一阶导数(FD)变换对原始高光谱进行处理, 并各自构建三种两波段指数(差值指数-DI、 比值指数-RI和归一化指数-NDI)。 采用相关分析观察不同处理方法下光谱响应特征区域的变化, 使用变量组合集群分析(VCPA)提取响应变量并去除共线性得到最优特征变量子集, 进一步构建三种机器学习模型(随机森林-RF、 支持向量机-SVM和BP神经网络-BPNN)。 最后, 比较不同处理下光谱参数对模型估算精度的影响, 根据模型评价指标得到最优油茶叶片碳氮比估算模型。 研究结果表明: (1)经过MSC或FD特征变换的原始光谱协同VCPA能够挖掘更多潜在变量。 (2)两波段光谱指数组合扩展了敏感波段的响应区域, 进一步增强了VCPA筛选特征变量的能力, FD-RI与FD-NDI处理效果最好。 (3)三种机器学习模型整体精度由大到小排序为BPNN>RF>SVM。 所有模型中, 经过FD-NDI处理的光谱参数构建的BPNN模型预测能力表现最好, 训练集和测试集的决定系数( R2)分别为0.71和0.66, 其相对分析误差(RPD)达到1.74。 该研究建立了一种收获期油茶叶片碳氮比的最优BPNN估算模型, 拓展了油茶高光谱应用的范围。
, LÜ Hai-yan
Leaf C/N ratio is an important indicator reflecting the individual nutrient utilization efficiency of Camellia oleifera. Estimating C/N ratio based on canopy hyperspectral characteristics can provide important theoretical basis for nutrient monitoring and precise fertilization of Camellia oleifera. There are very limited studies on non-timber product forests’ physical and chemical properties -using hyperspectral data, especially for Camellia oleifera with the synchronous biological characteristics of flowers and fruits. In addition to the collinearity problem, its complex physical and chemical properties pose great challenges to the response of sensitive spectral characteristics and the construction of estimation models. In this study, the Changlin series of Camellia oleifera in the Huanagshan area of Anhui Province was taken as the research objects. The canopy spectra of 120 Camellia oleifera plants were collected in the field, and the hyperspectral characteristics of the 400~1 000 nm wavelength range in the visible and near-infrared spectral regions were selected for analysis. Original hyperspectral data were processed by using multiplicative scatter corrections (MSC) and first derivative (FD) transformations, and three types of two-band indices (i.e., difference index-DI, ratio index-RI, and normalized difference index-NDI) were constructed respectively. Correlation analysis was used to observe the changes inspectral response feature regions under different processing methods. Response variables were extracted by variable combination population analysis (VCPA), and an optimal feature variable subset was obtained by removing collinearity to construct three machine learning models (i.e., random forest-RF, support vector machine-SVM and BP neural network-BPNN). Finally, the effects of spectral parameters on model estimation accuracy under different treatments were compared, and the optimal estimation model of the C/N ratio of Camellia oleifera leaves was identified according to model evaluation indices. Results showed that: (1) The original spectrum after MSC or FD feature transformation combined with VCPA can mine more potential variables. (2) The combination of a two-band spectral index expands the response region of sensitive bands and further enhances the ability of VCPA to select characteristic variables. FD-RI and FD-NDI are with the best treatment effect. (3) The overall accuracy of the three machine learning models ranked indescending order were BPNN>RF>SVM. Among all models, the BPNN model constructed by FD-NDI spectral parameters has the best prediction ability performance. The determination coefficient ( R2) of the training and test sets are 0.71 and 0.66, respectively, and the relative percent difference (RPD) is 1.74. This study established an optimal BPNN estimation model for the C/N ratio of Camellia oleifera leaves in the harvest period, which expands the application range of hyperspectral of Camellia oleifera leaves.
碳、 氮是构成植物细胞内基本物质的关键元素, 发挥着驱动与调控植物体代谢活动的重要作用。 生态化学计量学中通常使用碳氮比(简称C/N)揭示碳氮元素间相互制约与平衡的作用规律, 对实现资源可持续利用具有现实意义[1]。 叶片C/N通过调节冠层光合作用可以显著影响树体的生长发育及果实成熟, 因此, 作为一项重要的指示性理化参数, C/N也成为植物个体参与生物地球化学循环的研究热点[2]。
油茶(Camellia oleifera Abel.)是世界四大木本油料树种之一, 是中国特有的经济林, 栽培利用历史悠久[3]。 长久以来, 油茶因其显著的经济效益和生态价值广受市场欢迎。 由于油茶天然具有花果同期的生物学特性, 仅靠树体自身很难均衡养分元素, 因此油茶结实会出现大小年交替现象。 随着中国树立茶油“ 高端国油” 形象的提出, 油茶种植规模将继续扩大, 种植户也必将追求持续稳定的高产。 传统的营林措施已难以满足生产层面追求稳定高产的需求, 人们越发期望实现精准作业来大幅度减少开支与增产增效。 传统方法采用取样通过化学试剂测定元素含量来定性判断局部区域生长情况, 此法存在时空局限性并对树体造成破坏, 难以支撑精准作业的发展需求[4]。 高光谱遥感具有无损、 快速和准确的特点, 这种技术将为油茶C/N监测提供极大便利, 同时也为产量提高和良种选育提供新的途径。
国内外学者利用高光谱特征测定植物体C/N已有深入研究。 Xu等[5]通过提取高光谱曲线斜率特征并用分支定界算法(branch-and-bound, BB)构建了精度R2超过0.81的大麦和小麦叶片C/N估算模型。 Gao等[6]揭示了利用重要条带(important bands, IBS)和已知碳、 氮化合物吸收条带(known absorption bands, KBS)相结合的谱段信息来估算高山草原系统中草料C/N的潜力。 原始高光谱特征蕴含众多微观物质信息, 但在野外复杂样本环境下, 除了光谱本身存在着严重共线性和物质谱峰重叠因素外, 基线漂移、 背景噪音和散射影响等干扰因素也会进一步削弱模型估算精度。 一些学者通过对原始高光谱特征进行多种数学变换来有效降低干扰, 如张子鹏等[7]使用连续统去除和一阶导数变换对可见光-近红外的漫反射光谱进行处理, 进而组合成三波段光谱指数来估算土壤有机质含量, 显著弱化了噪声干扰并提高了定量模型估测精度。 Huang等[8]分别使用标准正态变量变换、 导数变换、 多元散射校正和连续统去除方法增强光谱曲线特征差异, 结果显示, 一阶导数变换后的建模精度R2可达到0.986。 此外, 高光谱全波段信息量大会造成数据冗余, 而选用适当的变量筛选方法挖掘潜在响应特征可以有效避免陷入“ 维数灾难” , 同时也能提升估算模型的鲁棒性和泛化能力。 Yun等[9]针对近红外光谱特征, 在比对多种静态与动态变量筛选方法后提出了一种混合变量选择策略来连续收缩可变空间并得到最优变量组合, 为模型提供更好的解释性。
高光谱技术在经济林领域具有广泛的应用前景, 但实际应用中对冠层光谱特征信息的解译依然充满挑战。 目前, 高光谱C/N监测技术主要运用在农业作物领域, 而对具有显著效益的经济林领域在应用广度和深度方面的研究均滞后于前者, 且多聚焦在叶片尺度, 而上升到冠层尺度直接监测叶片C/N的报道仍然较少[10]。 鉴于此, 通过挖掘油茶叶片C/N与冠层可见光与近红外谱区高光谱的响应特征, 使用机器学习算法构建最优估算模型, 旨在推广高光谱技术在油茶养分含量分析中的应用, 并为油茶叶片C/N监测提供科学支撑。
黄山市黄山区仙源弦歌油茶专业合作社种植地(30° 19'N, 118° 9'E, 见图1)研究区地处皖南山区中部, 境内地形地貌多样, 以中、 低山和丘陵为主。 其气候带处于北亚热带和中亚热带过渡区, 属亚热带季风湿润气候。 夏季持续时间长、 温度高, 冬季较冷。 全年雨水充沛。 试验于2021年10月28日至11月2日期间开展, 正值油茶果实成熟收获期, 除了进行锄草, 调查时间的前7个月内无其他经营措施, 林中病虫侵害情况较轻。 研究区内油茶样本具有明显的大小年交替现象, 采集时正处在大年丰产阶段。
 | 图1 研究区位置图Fig.1 Location of the study area |
1.2.1 油茶叶片碳氮数据获取
供试油茶为2012年栽植的长林系列, 样地内随机布点取样120株, 包含三个长林品种(长林27号、 长林40号和长林53号)。 每株油茶采摘冠层中上部的东南西北四个方位, 每个方位2片, 共16片叶子, 带回实验室于105 ℃下杀青30 min, 后在60 ℃下烘干至恒重。 烘干后研磨并过60目筛, 再用锡囊包取2~3 mg样, 最后使用碳氢氮元素分析仪(EURO EA3000, EuroVector Inc., Italy)测定得全碳(total carbon, TC)和全氮(total nitrogen, TN), 单位统一换算成g· kg-1。
1.2.2 冠层高光谱数据采集与处理
选择晴朗无风或微风的天气, 使用便携式野外地物光谱仪(ASD FieldSpec4 Wide-Res, Analytical Spectral Devices, Boulder, Co., USA), 在北京时间10:00— 14:00间(太阳高度角大于45° )获取油茶冠层高光谱。 仪器先预热20 min, 每株单次测定10条光谱, 除去异常光谱曲线求均值得到最终光谱曲线。 由于油茶植株高度普遍较高, 受限于光纤25° 的前视场角, 需将探头连接光纤跳线再使用伸缩杆抬至冠层正上方2 m位置处。 该设备光谱测定的全波段范围覆盖350~2 500 nm, 其中, 间隔在350~1 000 nm波段范围(visibleand near-infrared, Vis-NIR)的光谱分辨率是3 nm、 1 000~2 500 nm波段范围(short-wave infrared, SWIR)是30 nm, 全波段重采样间隔为1 nm。 除去少量信噪比低的波段(350~400 nm), 采用在400~1 000 nm范围的Vis-NIR光谱特征。 首先, 按照5 nm的重采样间隔设置原始光谱, 形成121个波段总数; 其次, 使用2阶9窗口点数的Savitzky-Golay滤波对每条高光谱曲线因设备暗电流引发的随机高频噪声进行平滑, 同时考虑云层、 地形和冠层结构等众多因素对光谱的影响, 采用平均归一化法[见式(1)]以增加光谱数据内部的可比性; 最后, 将经过上述处理的光谱重新定义为原始光谱(R)。
${{R}_{Ni}}={{R}_{i}}/\left( \frac{1}{n}\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{R}_{i}} \right)$(1)
式(1)中, RN是归一化后的光谱反射率, Ri是归一化前不同波长处的光谱反射率, n是波段总数。
1.3.1 原始光谱特征变换
对原始光谱特征进行数学变换将有效消除噪声和突出响应细节, 以便更好地解译光谱信息。 选择用于消除散射水平差异的多元散射校正法(multiplicative scatter correction, MSC)和削弱土壤背景干扰、 基线漂移及分辨重叠峰的一阶导数法(first derivative, FD)进行处理。 相对于单波段参数, 通过两波段线性组合成光谱指数可以放大光谱波段内部相互作用信息、 削弱外部因素的影响, 进而有效提高光谱特征估算理化参数的度量精度。 常见两波段光谱指数组合有差值指数(difference index, DI)、 比值指数(ratio index, RI)和归一化指数(normalized difference index, NDI)三种形式[式(2)-式(4)]。
式中, Ri、 Rj分别代表在400~1 000 nm范围内第i、 j波长处的光谱反射率。
1.3.2 敏感特征提取和筛选
先利用Pearson相关分析得到光谱原始及变换特征与油茶叶片C/N的响应关系, 再将其中达到极显著水平的波长(p-value≤ 0.01)初筛为敏感波段。 为进一步细化模型输入变量, 使用变量组合集群分析(variable combination population analysis, VCPA)获取光谱特征变量子集。 VCPA[11]是基于指数递减函数(exponentially decreasing function, EDF)、 二进制矩阵采样(binary matrix sampling, BMS)和模型集群分析(model population analysis, MPA)进行不断迭代筛选的最佳变量子集。 其中, EDF基于达尔文进化理论中“ 适合生存” 的简单有效原则使可变空间连续缩小至小而优化的空间; BMS通过生成二进制矩阵确保以采样几率相等的方式对所有变量随机组合; MPA用于统计BMS产生的大量随机可变组合模型。 为最大程度减少变量组合内部的多重共线性, 对VCPA结果还需要计算两两变量间的相关系数, 设定阈值0.9, 所有超过阈值的各对变量仅保留其中与叶片C/N相关程度最高的, 以得到最优变量组合子集。
1.4.1 数据集划分
首先, 利用留出法按照7∶ 3比例随机将样本数据划分为训练集(Training set)和测试集(Test set); 其次, 利用5折交叉验证对训练集按照平均交叉验证均方误差最小进行调参; 然后, 选取最优超参数组合重新在训练集上训练模型; 最后, 在测试集上评估模型泛化能力。
1.4.2 机器学习模型
选择随机森林、 支持向量机和BP神经网络三种机器学习算法进行油茶叶片C/N估算模型构建。
随机森林(random forest, RF)[12]是集成算法中Bagging架构的具体实现, 并行构造多个CART决策树, 用多个决策树学习结果的算术平均作为回归结果进行最终的模型输出。 由于每棵树选取特征的随机性, 因此, RF整体模型具有较好的泛化能力和抗过拟合性能。 通常来说, RF训练前需要配置的超参数较多, 其中的决策树个数和深度对模型拟合能力具有较大影响, 所以, 主要对决策树数目M和最大决策分割数N两项参数进行调优。
支持向量机(support vector machine, SVM)[13]是一种基于Vapnik-Chervonenkis维理论和结构风险最小化原则的监督式学习算法, 能够利用有限的训练样本信息寻求模型复杂度与学习能力之间的最佳平衡。 SVM理论的关键在于核技巧, 即通过构造核函数避免特征从低维空间映射到高维空间的复杂运算。 本工作选取鲁棒性较好的径向基函数(radial basis function, RBF)作为核函数, 并用网格搜索法对惩罚系数C和核参数γ 两个超参数加以调优。
BP神经网络(back propagation neural network, BPNN)[14]是一种基于Widrow-Hoff学习规则广泛应用的多层前馈神经网络, 能够模拟多种非线性关系。 BPNN的拓扑结构包括输入层、 隐含层和输出层, 通过设定网络运行参数(迭代数、 学习率等)计算各层权重和偏置, 使用梯度下降法通过误差逆反馈对权重和偏置进行不断修正, 最终使网络的误差平方和达到最小。 BPNN通常包括隐藏层个数和各隐藏层节点数这两个重要的超参数, 配置网络时需要指定这两个参数的值, 层数和节点数的最优配置仍然是目前具有挑战的未知问题。 为了获取泛化能力更好、 预测精度更高的神经网络模型, 将隐藏层数设定为3层, 依据式(5)并采用网格搜索法配置各层的最佳节点数。
$n=\sqrt{I+O}+\alpha $(5)
式(5)中, n是隐藏层节点数, I和O分别是输入层和输出层的变量维数, α 是1~10之间的调节常数。
1.4.3 模型评价与比较
选取决定系数R2(coefficient of determination)、 均方根误差RMSE(root mean square error)和相对分析误差RPD(relative percent deviation)作为模型评估指标, 计算公式见式(6)— 式(8)。
${{R}^{2}}=\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{({{{\hat{y}}}_{i}}-{\bar{y}})}^{2}}/\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{({{y}_{i}}-{\bar{y}})}^{2}}$ (6)
$\text{RMSE}=\sqrt{\overset{n}{\mathop{\underset{i=1}{\mathop \sum }\, }}\, {{({{{{\hat{y}}}}_{i}}-{{y}_{i}})}^{2}}/n}$ (7)
式中, yi、${{{\hat{y}}}_{i}}$、${\bar{y}}$分别表示油茶叶片C/N的观测值、 预测值和平均值, SDy表示观测值的标准差, n为样本容量。 通常来说, R2越大且RMSE越小, 模型效果越好; RPD越大, 精度越好, RPD≥ 1.4时表示模型具有较好的估算能力[15]。 所有相关操作均在Matlab(Version R2020b, MathWorks.Inc)编译环境中完成。
通过计算每株油茶叶片TC与TN的比值可以得到一个无量纲参数叶片C/N, 三者的统计描述如表1所示。 由表1可知, 叶片TC含量为弱变异, 变异系数仅有1.71%, 说明TC总体稳定离散分布在511.92 g· kg-1附近, 而叶片TN和叶片C/N均为中等变异且十分接近, 体现出收获期油茶氮元素含量在不同单株间存在较大差异。 叶片TC偏度值为负值, 呈现左偏态分布; 而TN和C/N偏度值为正值, 均为右偏态分布。
| 表1 TC、 TN和叶片C/N的描述统计 Table 1 Descriptive statistics of TC, TN, and leaf C/N |
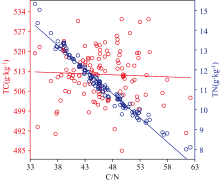
图2为油茶叶片C/N分别与叶片TC、 TN的响应关系, 由图2可知, 油茶叶片C/N幅度变化与TN的关联程度明显大于TC, 且呈极显著的负线性相关(r=-0.98, p=0.00< 0.01), 而TC累积量的振荡现象揭示, 主要是氮元素在碳氮代谢协调中充当限制因子。 油茶收获期的叶片C/N差异在一定程度上也反映出树体营养器官与生殖器官之间对同化产物的争夺和转化情况。
 | 图2 叶片C/N与TC、 TN响应关系的双Y轴图Fig.2 Double Y-axis diagram of the response relationship between leaf C/N and TC, TN |
两种特征变换引起原始光谱曲线(R)的变化情况(图3)表明, MSC光谱[图3(b)]总体波峰走势基本与R光谱[图3(a)]保持一致, 仅对绿光波段500 nm处至近红外波段900 nm处之间的反射率标准差(standard deviation, S.D.)有明显减弱, 而对其余波段特征改变不明显。 和R与MSC光谱相比较, FD光谱[图3(c)]出现了较多的凹凸区域, 在可见光范围内由峰谷特征构成的光谱曲线起伏均有不同程度的放大, 尤其体现在近红外波段过渡区域的红边增强效应最直观。 三种光谱曲线反射率在近红外波段900nm处均有较大的波动, 这与植物叶片的内部构造差异有关。
 | 图3 不同特征变换的光谱反射率曲线 (a): R光谱; (b): MSC光谱; (c): FD光谱Fig.3 Spectral reflectance curves of different feature transformations (a): R spectra; (b): MSC spectra; (c): FD spectra |
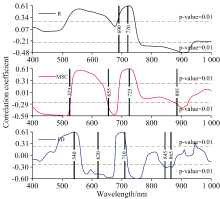
进一步用油茶叶片C/N与R、 MSC和FD光谱反射率分别构造相关系数曲线, 由图4可知, 油茶叶片C/N与R光谱反射率在400~745 nm之间呈正相关, 而在其他波段呈负相关, 最高相关性的波长位置在725 nm(r=0.61), 其中敏感波段(p≤ 0.01)范围主要位于515~660、 690~740和760~940 nm。 MSC光谱反射率明显增加了在400~520 nm范围内与叶片C/N的关联程度, 在该区域维持较高的负线性相关; 同时, 相对于R相关曲线, MSC凸显了在650~680 nm的负相关, 但是, 在750 nm之后光谱特征响应的敏感程度则明显下降, 其最高相关性的位置与R保持一致, 均在725 nm处(r=0.61)。 FD光谱反射率与叶片C/N的敏感特征响应区间主要在可见光范围(400~780 nm), 其中, 在485~555和680~710 nm呈现极显著的正相关, 而在570~675和720~775 nm为极显著的负相关, 且仅在近红外区域的840~870和945~950 nm有极显著的线性相关。 使用VCPA方法对R、 MSC和FD光谱反射率的敏感特征进一步遴选并去除共线性, 得到如图4所示最优特征变量子集位置分布, 其中, R光谱的变量组合集中在红边范围, 而MSC和FD光谱的变量组合子集在多个敏感特征响应区域均有分布。 这些结果表明, MSC和FD特征变换处理可以有效提高VCPA挖掘潜在信息的能力。
 | 图4 R、 MSC和FD与叶片C/N的相关系数Fig.4 Correlation coefficients of R, MSC, and FD with leaf C/N |
按照两波段差值(DI)、 比值(RI)和归一化(NDI)组合方式, 进一步使用R、 MSC和FD光谱反射率计算光谱指数与油茶叶片C/N的相关系数矩阵(图5)。 结果显示, R光谱在三种光谱指数中的敏感区域基本一致, 其中, 波长在550和720 nm附近的反射率分别与可见光、 近红外波段组合呈现一正一负两种响应关系, 而在920 nm附近由波长反射率自身的组合表现出显著的正线性相关, 同时其RI和NDI的处理效果非常相似。 MSC光谱在三种光谱指数中的敏感区域相较于R光谱均有所拓展, 图5(e)和(f)表明, MSC处理可提高可见光与近红外波段组合的响应程度。 由图5(g— i)中可知, FD的光谱指数从DI、 RI到NDI逐步细化敏感特征的响应区域, 其中FD-NDI光谱形成大量的敏感细碎斑块。 总体来看, 两波段组合相对于单波段变换能够提高光谱特征与油茶叶片C/N最大的响应程度, 但效果不明显。
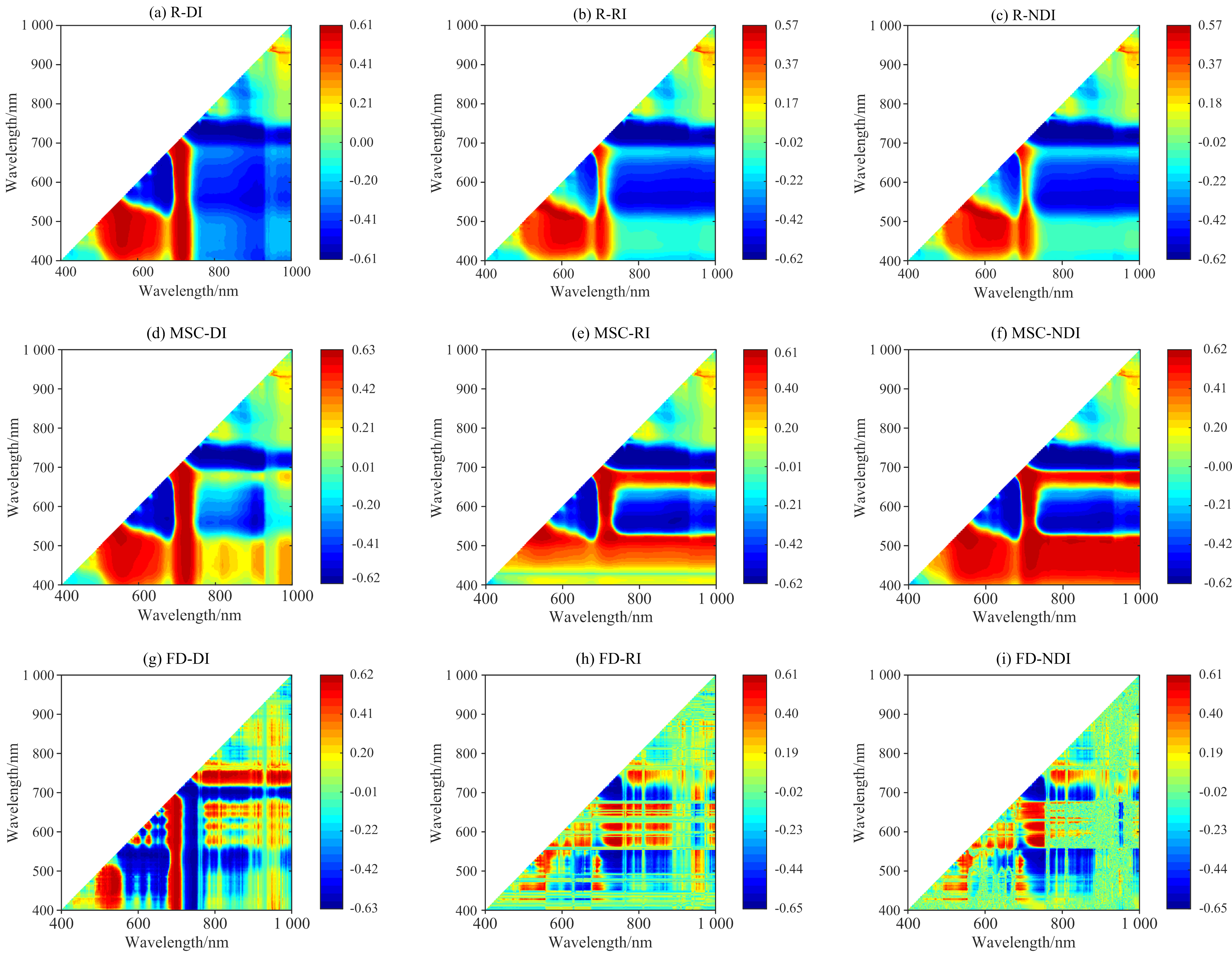 | 图5 不同单波段变换的DI、 RI和NDI与叶片C/N的相关系数矩阵Fig.5 The correlation coefficients matrix of DI, RI and NDI with leaf C/N in different single band transformations |
使用VCPA方法面向三种单波段变换的DI、 RI和NDI光谱指数, 从对应处理的敏感区域反射率组合值中遴选出变量子集并去除共线性得到如表2所示的最优组合分布情况。 由表2可知, FD-RI与FD-NDI处理能够保留较多可见光与近红外波段组合的响应信息。
| 表2 两波段最优光谱特征变量组合子集 Table 2 Optimal spectral characteristic variable combination subset of two bands |
用R、 MSC和FD及对应两波段组合指数分别构建三种机器学习模型(RF、 SVM与BPNN)的效果见表3— 表5, 各表中均相应列出经过交叉验证调参的参数配置。 由表3可知, RF模型在训练集中的R2范围为0.33~0.69, RMSE为2.85~4.20; 在测试集中的R2为0.36~0.60, RMSE为3.85~4.91。 结果显示, 经过MSC处理的RF模型表现最佳, 其测试集R2为0.60且RPD达到1.61, 可以说明该RF模型具有较好的叶片C/N估算能力。
| 表3 不同处理下RF模型的评价指标汇总 Table 3 Summary of evaluation indexes of RF models under different treatments |
| 表4 不同处理下SVM模型的评价指标汇总 Table 4 Summary of evaluation indexes of SVM model under different treatments |
| 表5 不同处理下BPNN模型的评价指标汇总 Table 5 Summary of evaluation indexes of BPNN model with different treatments |
表4为经过不同处理构建的SVM模型评价效果, SVM模型在训练集中的R2范围为0.32~0.50, RMSE为3.65~4.24; 在测试集中的R2为0.29~0.54, RMSE为4.15~5.16。 结果显示, MSC-DI和FD处理的SVM模型具有较好的估算能力, 其测试集的R2均为0.54, RPD均达到1.49。
表5为光谱经过不同处理构建的BPNN模型评价效果, BPNN模型在训练集中的R2范围为0.51~0.71, RMSE为2.76~3.62; 在测试集中的R2为0.47~0.66, RMSE为3.56~4.47。 其中, 经过FD-NDI处理的BPNN模型在测试集的R2为0.66, RPD达到1.74, 说明该BPNN模型相对来说具有更高的准确性和泛化能力, 可以用此模型进行收获期油茶叶片C/N的估算。
上述结果分析可知, 由不同处理产生的变量组合子集内部差异会对模型估算精度有较大影响, 而三种机器学习模型整体效果最好的是BPNN, 其次是RF和SVM。 从计算机对算法运行的效率来看, 网络结构更加复杂的BPNN需要的运行时间更长。 为了更好地解释模型的估算特征, 选取RPD评价效果最好的三种模型进行展示, 即FD-NDI-BPNN[图6(a)]、 MSC-BPNN[图6(b)]和MSC-RF[图6(c)]。 由图6可知, 这三个模型在测试集中的回归线斜率均低于1∶ 1线, 因此, 模型倾向于过高估计低C/N和过低估计高C/N。 同时, 数据回归分布的95%置信区间(confidence interval, C.I.)特点表明, 即使在同一生长时期C/N水平相近的油茶个体, 其模型估算精度也会有较为明显的差异, 这可能与选取范围内光谱携带信息的上限有关, 需要考虑其他影响油茶生长状态的生理生化指标来综合提升模型估算精度。
 | 图6 选取模型的叶片C/N观测值与预测值比较Fig.6 Comparison of the observed and predicted values of leaf C/N with different models |
通过使用MSC、 FD及DI、 RI和NDI波段组合对研究区120株油茶冠层高光谱进行处理, 分析敏感波段变化差异, 利用VCPA方法筛选变量并去除共线性, 分别构建每种处理的三种机器学习模型(RF、 SVM和BPNN)进行叶片C/N估算, 并验证与评价模型精度。 结论如下:
(1)在单波段变换中, 先对R光谱进行MSC或FD处理, 再利用VCPA筛选出更多响应变量, 说明采用特征变换方法协同变量筛选策略能够挖掘更多潜在变量。
(2)在两波段光谱指数组合中, 可见光与近红外组合进一步拓展了敏感波段的响应区域, FD-RI与FD-NDI处理最大程度地增强了VCPA筛选特征变量的能力。
(3)三种机器学习模型中, BPNN整体效果最好, 其次是RF和SVM。 所有模型中FD-NDI-BPNN模型预测能力最优, 其测试集的R2=0.66, RMSE=3.56, RPD=1.74。 本研究建立了一种能够较好估算收获期油茶叶片C/N的BPNN模型, 拓展了高光谱手段在经济林方面的应用范围, 为油茶养分监测提供了理论依据和数据支持, 也对开展基于精准施肥的油茶林经营研究提供一定的实验基础。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|