





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于随机蛙跳波段选择算法的土壤铅含量高光谱估测
[安柏耸1, 2  , 王雪梅
, 王雪梅1, 2, * , 黄晓宇1, 2 , 卡吾恰提·白山1, 2 ]
, 王雪梅, 黄晓宇|
|


作者简介: 安柏耸, 女, 1997年生, 新疆师范大学地理科学与旅游学院硕士研究生 e-mail: aaanbs@163.com
高光谱数据中存在的大量冗余信息对高光谱估测精度产生较大影响。 旨在寻求特征波段筛选的最佳算法, 以实现土壤重金属铅含量的准确监测, 为土壤污染防治提供参考。 以新疆渭干河-库车河三角洲绿洲土壤重金属铅含量与光谱数据为数据源, 利用蒙特卡洛交叉验证(MCCV)算法确定92个有效土壤样品, 通过相关分析选取倒数对数一阶微分变换处理的光谱数据, 采用随机蛙跳(RF)算法, 并结合竞争性自适应重加权(CARS)算法、 迭代保留有效信息变量(IRIV)算法及连续投影算法(SPA), 构建RF-CARS、 RF-IRIV及RF-SPA三种算法对波段进行筛选。 以倒数对数一阶微分变换处理下的特征波段反射率为自变量, 土壤重金属铅含量为因变量, 采用极端梯度提升(XGBoost)和地理加权回归(GWR)方法构建土壤重金属铅含量估测模型。 结果表明: (1)光谱变换处理可有效增强光谱与土壤铅含量的敏感性, 其中倒数对数一阶微分变换后的土壤光谱特征更为明显, 相关系数可达到0.620( p<0.001)。 (2)RF-CARS、 RF-IRIV及RF-SPA算法分别从高光谱数据中筛选出6、 9和7个特征波段, 全部位于近红外光谱区域, 3种算法具有较强的特征提取能力, 极大减少光谱数据中的冗余信息。 (3)基于RF-IRIV算法构建的土壤铅含量估测模型的精度和稳定性高于RF-CARS和RF-SPA算法构建的模型, 说明RF-IRIV算法能更为准确的保留与土壤铅含量相关的波段。 此外, GWR模型的性能优于XGBoost模型, 构建的RF-IRIV-GWR模型具有较好的预测能力, 可作为研究区土壤铅含量的最优估测模型, 其验证集的决定系数( R2)为0.892, 均方根误差(RMSE)为0.825 mg·kg-1, 相对分析误差(RPD)为3.09。 基于随机蛙跳(RF)与迭代保留有效信息变量(IRIV)算法, 结合地理加权回归(GWR)建模方法在快速准确估测土壤铅含量方面具有一定优势, 可进行土壤重金属污染的动态监测。
Due to the large amount of redundant information in hyperspectral data, it greatly impacts the accuracy of hyperspectral estimation. The purpose of this study is to find the best algorithm for the screening of feature bands to realize the accurate monitoring of the lead content of heavy metals in soil and to provide a reference for soil pollution prevention and control. The lead contents and spectral data in the oasis soils of the Weigan-Kuqa river delta in Xinjiang were used as data sources, and 92 valid soil samples were identified using the Monte Carlo cross-validation algorithm (MCCV), and the spectral data processed by the first-order differential transformation of the reciprocal logarithm are selected through correlation analysis. The random frog (RF) algorithm is combined with the competitive adaptive reweighted sampling (CARS) algorithm. The iteratively retains informative variables (IRIV) algorithm and the successive projections algorithm (SPA). The RF-CARS, RF-IRIV and RF-SPA algorithms are constructed to screen the bands. Taking the reflectivity of feature bands as the independent variable and the content of heavy metal lead in the soil as the dependent variable, the extreme gradient boosting (XG Boost) and geographically weighted regression (GWR) methods were used to construct the estimation model of the lead content in the soil. The results show that: (1) The spectral transformation treatment can effectively enhance the sensitivity of the spectrum and lead content. The spectral characteristics after the first-order differential transformation of the reciprocal logarithm are obvious, and the correlation coefficient can reach 0.620 ( p<0.001). (2) RF-CARS, RF-IRIV and RF-SPA algorithms extract 6, 9 and 7 feature bands from hyperspectral data, all located in the near-infrared spectral region. The three algorithms have strong feature extraction ability, greatly reducing redundant information in spectral data. (3) The accuracy and stability of the soil lead content estimation model constructed based on that the RF-IRIV algorithm are higher than those constructed by RF-CARS and RF-SPA, showing the RF-IRIV algorithm can more accurately retain the bands related to soil lead content. In addition, the performance of the GWR model is better than that of the XGBoost model, and the constructed RF-IRIV-GWR model has the good predictive ability, which can be used as the optimal estimation model for soil lead content in the study area. The R2, RMSE and RPD of the validation set of the RF-IRIV-GWR model are 0.892, 0.825 mg·kg-1 and 3.09 respectively. Based on the random frog (RF) and iteratively retains informative variables (IRIV) algorithm combined with geographically weighted regression (GWR) modeling method, it has certain advantages in quickly and accurately estimating soil lead content, which can be used for dynamic monitoring of soil heavy metal pollution.
随着工农业的快速发展, 矿井排水、 石油开采、 化学农药使用等多种人类活动将重金属带入土壤, 致使土壤中重金属含量明显高于原有水平, 从而造成土壤重金属污染[1]。 铅(Pb)作为一种毒性强、 难降解、 易积累的重金属元素, 在土壤中不断富集, 对环境以及人类健康构成严重威胁。 因此, 快速、 准确估测土壤铅含量对土壤污染防治具有重要意义。 相较于传统的土壤重金属监测方法, 高光谱遥感监测技术具有效率高、 成本低等优点, 为实现大规模快速监测土壤重金属含量提供了新途径[2]。
由于高光谱波段中存在大量无用和干扰信息, 对模型的稳定性和预测能力产生严重影响。 因此, 通过波段选择算法从高光谱数据中筛选出最具代表性的特征波段, 对提高土壤铅含量估测模型的性能至关重要。 Tan等[3]利用竞争性自适应重加权(competitive adaptive reweighted sampling, CARS)算法筛选的特征波段构建土壤重金属含量估测模型, 发现该模型在所有模型中精度和稳定性最好。 Jiang等[4]分别通过连续投影算法(successive projections algorithm, SPA)、 CARS等方法筛选特征波段, 对重金属含量进行估测, 最优模型R2可达0.734。 通常广泛采用一种算法来筛选特征波段, 但随着研究的深入, 发现对波段进行二次筛选在降低数据冗余性、 提取特征信息方面具有更好的效果, 能进一步提高模型精度[5]。 Wei等[2]将迭代保留有效信息变量(iteratively retains informative variables, IRIV)算法与斯皮尔曼秩相关分析(Spearman's rank correlation analysis, SCA)结合, 发现结合两种方法能更好的筛选出与土壤重金属相关的重要波段。 Wei等[6]先采用稳定竞争自适应重加权采样(stbility CARS, sCARS)算法, 再利用连续投影算法(SPA)进行特征波段选择, 解决了光谱数据的冗余和共线问题, 与单纯使用sCARS算法相比, 所建模型具有更高的预测精度。
前人在研究高光谱波段选择算法时, 多采用CARS、 IRIV等构建结合算法, 却很少将具有竞争选择机制的随机蛙跳算法(random frog, RF)运用到结合中, 对RF构建的结合算法相对缺少研究。 为了对高光谱数据进行有效降维, 有必要全面研究不同算法的结合, 深入探索更加适用的波段选择结合算法。 鉴于此, 本研究通过相关分析选取倒数对数一阶微分变换后的光谱数据, 采用随机蛙跳算法(RF), 并结合竞争性自适应重加权(CARS)算法、 迭代保留有效信息变量(IRIV)算法及连续投影算法(SPA), 构建RF-CARS、 RF-IRIV及RF-SPA三种算法进行特征波段的筛选, 并采用极端梯度提升(extreme gradient boosting, XGBoost)和地理加权回归(geographically weighted regression, GWR)方法建立渭干河-库车河三角洲绿洲耕层土壤重金属铅含量估测模型, 旨在确定土壤重金属铅含量的最佳波段选择算法和特征波段, 从而提高估测模型的精度, 为土壤重金属污染监测提供理论及技术支持。
渭干河-库车河三角洲绿洲(39° 29'51″—42° 38'01″N, 81° 28'30″—84° 05'06″ E)位于中国新疆维吾尔自治区南部的塔里木盆地北缘, 地势北高南低, 为中国西北干旱区典型的扇形冲积平原绿洲。 研究区属温暖带大陆性干旱气候, 年均气温10.5~11.4 ℃, 降水稀少(年均降水量50.0~66.5 mm), 蒸发强烈(年均蒸发量1 990~2 865 mm)。 该绿洲主要发展农业, 农作物有玉米(Zea mays)、 棉花(Gossypium spp.)等, 经济作物有核桃(Juglans regia L.)、 苹果(Malus pumila)、 红枣(Ziziphus jujuba Mill.)等。 土地利用类型主要包括耕地、 林地、 草地、 建设用地、 裸地等。 主要的土壤类型为潮土、 灌淤土和棕漠土。 近年来, 随着新疆油气资源的开发及化工产业的发展, 砷、 铅、 镉等重金属元素在土壤环境中逐渐积累, 土壤重金属污染问题日益突出。
于2019年7月采用GPS定位方法在渭干河-库车河三角洲绿洲采集98个土壤样品(图1), 采集土层深度为0~20 cm。 采样过程中, 对样点周围环境进行拍照, 并详细记录样点信息, 如经纬度坐标、 植被类型、 土壤质地等。 每个样点采集土壤样品约500 g放入已编号的自封袋内密封, 带回实验室自然风干后进行研磨过筛处理。 每个土壤样品分成两份, 一份测定高光谱数据, 另一份通过石墨炉原子吸收分光光度法测定土壤重金属铅含量。
 | 图1 采样点分布图Fig.1 Distribution of sampling points |
采用ASD FieldSpec3地物光谱仪, 选择光照稳定、 天气晴朗的中午, 在室外空旷场地测定土壤高光谱数据。 光谱采集范围为350~2 500 mm, 采样间隔为1 nm。 远离可能干扰土壤光谱的物体, 对地物光谱仪进行白板校正, 然后按编号顺序把土壤样品均匀平铺在50 cm× 50 cm的牛皮纸上, 将探头放置在距土壤样品表面15 cm的垂直距离处, 对每个样品重复采集10次光谱数据, 并取其平均值作为土壤样品的原始光谱反射率。 由于环境因素存在不可控性, 统一去除土壤原始光谱数据中受水分影响的1 341~1 400和1 811~1 950 mm波段及噪声较大的2 451~2 500 mm波段。 采用Savitzky-Golay法对土壤原始光谱数据进行平滑处理, 减少噪声影响。 为了增强土壤样品的代表性, 保证模型的有效性, 利用蒙特卡洛交叉验证(Monte Carlo cross-validation, MCCV)算法剔除异常样本, 通过计算各样本预测误差的标准差和均值, 将标准差和均值的平均值的2.5倍作为阈值, 大于阈值的判定为异常样本并剔除, 最终从98个土壤样品中确定92个有效土壤样品。 通过联合X-Y距离(sample set partitioning based on joint x-y distance, SPXY)方法对土壤样品进行划分, 以光谱数据为X变量, 土壤重金属铅含量为Y变量, 利用两种变量计算样品间欧式距离, 获得具有代表性的训练集(70%)和验证集(30%)。
首先采用随机蛙跳(RF)算法初步筛选波段, 再分别利用竞争性自适应重加权(CARS)算法、 迭代保留有效信息变量(IRIV)算法及连续投影算法(SPA)对波段进行二次筛选, 构建RF-CARS、 RF-IRIV及RF-SPA算法。 RF是一种模拟稳态分布的马尔可夫链的变量选择方法, 通过计算变量在每次迭代过程中被选择的概率, 根据概率衡量变量的重要性, 概率越高则变量越重要。 CARS模拟达尔文进化论中“ 适者生存” 的原则对变量进行选择, 采用蒙特卡洛采样法随机选取样本建立偏最小二乘回归模型并计算各波段权重, 利用自适应重采样加权采样技术和指数衰减函数去除权重较小的波段, 通过迭代确定变量的最佳组合。 IRIV基于二进制矩阵重排过滤器选择变量, 通过多次迭代消除无信息变量和干扰信息变量, 保留强信息变量和弱信息变量, 最后进行反向消除确定最优变量集。 SPA是一种前向变量选择算法, 在向量空间中采用投影分析, 获得共线性小的变量集合。 以上4种特征波段筛选方法均在MATLAB R2019b软件中实现。
选取极端梯度提升(XGBoost)和地理加权回归(GWR)构建土壤重金属铅含量估测模型, 并对比分析2种模型的效果。 XGBoost通过损失函数引入二阶导数信息, 并使用正则项防止模型过度拟合, 是梯度增强算法的优化实现。 设置该模型的关键参数学习率为0.3, 树的最大深度为6。 GWR是局部回归模型, 将数据的空间坐标代入回归参数, 可利用局部加权最小二乘法实现样点估测。 该模型的参数选择如下: 模型类型为Gaussian, 核函数为Adaptive bi-square, 带宽选择Golden section search(定义范围1~27), 准则为AICc。 XGBoost模型通过R 4.1.2平台实现, GWR模型使用GWR 4.0软件构建。 为评估模型的稳定性和预测能力, 采用决定系数(coefficient of determination, R2)、 均方根误差(root mean square error, RMSE)和相对分析误差(relative percent deviation, RPD)对结果进行检验。
通过对研究区土壤重金属铅含量进行基本统计分析(表1), 可以看出总体样品的土壤铅含量在9.2~22.3 mg· kg-1范围, 变异系数为18.27%, 属于中等空间变异, 说明土壤铅的空间异质性较显著, 训练集和验证集的平均值分别为15.262和15.922 mg· kg-1, 标准差分别为2.925和2.552 mg· kg-1, 平均值和标准差较为接近, 表明训练集和验证集中存在偏差的可能性减小, 确保了样本的代表性。 总体样品的平均值为15.455 mg· kg-1, 是新疆灌耕土铅元素背景值(13.50 mg· kg-1)的1.14倍, 说明人类活动对土壤造成一定程度的铅污染[7]。
| 表1 土壤重金属铅的基本统计分析 Table 1 Basic statistical analysis of soil lead content |
由于原始光谱反射率与土壤重金属铅含量的相关性较低, 故采用MATLAB R2019b软件对原始光谱反射率做倒数对数、 一阶微分、 二阶微分等多种数学变换, 其中土壤原始光谱反射率R及其3种变换lg(1/R)、 [lg(1/R)]'、 [lg(1/R)]″与土壤铅含量的相关系数曲线如图2所示。 经分析, 发现倒数对数一阶微分[lg(1/R)]'变换后的光谱反射率与土壤铅含量之间的相关性有明显提高, 相关系数可达到0.620(p< 0.001), 能有效增强波谱信息, 因此选取倒数对数一阶微分变换处理的光谱数据进行特征波段的筛选。
 | 图2 土壤重金属铅含量与光谱反射率的相关分析Fig.2 Correlation analysis of soil lead content and spectral reflectance |
2.2.1 RF算法的初步筛选
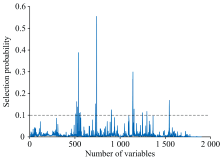
由于高光谱波段众多, 数据冗余严重, 为提高模型估测精度, 采用波段选择算法对光谱数据进行特征波段提取。 首先, 采用随机蛙跳(RF)算法进行初步筛选, 去除无用信息波段和干扰信息波段。 设定RF算法的最大潜在变量数为10, 初始变量数为2, 迭代次数为10 000, 但RF算法基于蒙特卡洛思想, 每次的筛选结果略有差异, 具有随机性, 因此运行100次, 取选择概率的平均值作为特征波段的筛选依据, 结果如图3所示。 从图中可以看出, 只有少数变量的选择概率较高, 选择概率在第740个变量处(光谱波段1 089 nm)达到最高。 设置阈值为0.1, 用黑色水平虚线表示, 选取概率超过阈值的22个变量作为特征波段, 结果见表2。 由于RF算法每次筛选出的特征波段存在一定差异, 导致22个波段中可能存在冗余信息, 并且经SPSS软件分析, 发现波段间存在共线性, 因此分别采用竞争性自适应重加权(CARS)算法、 迭代保留有效信息变量(IRIV)算法和连续投影算法(SPA)进一步对波段进行筛选。
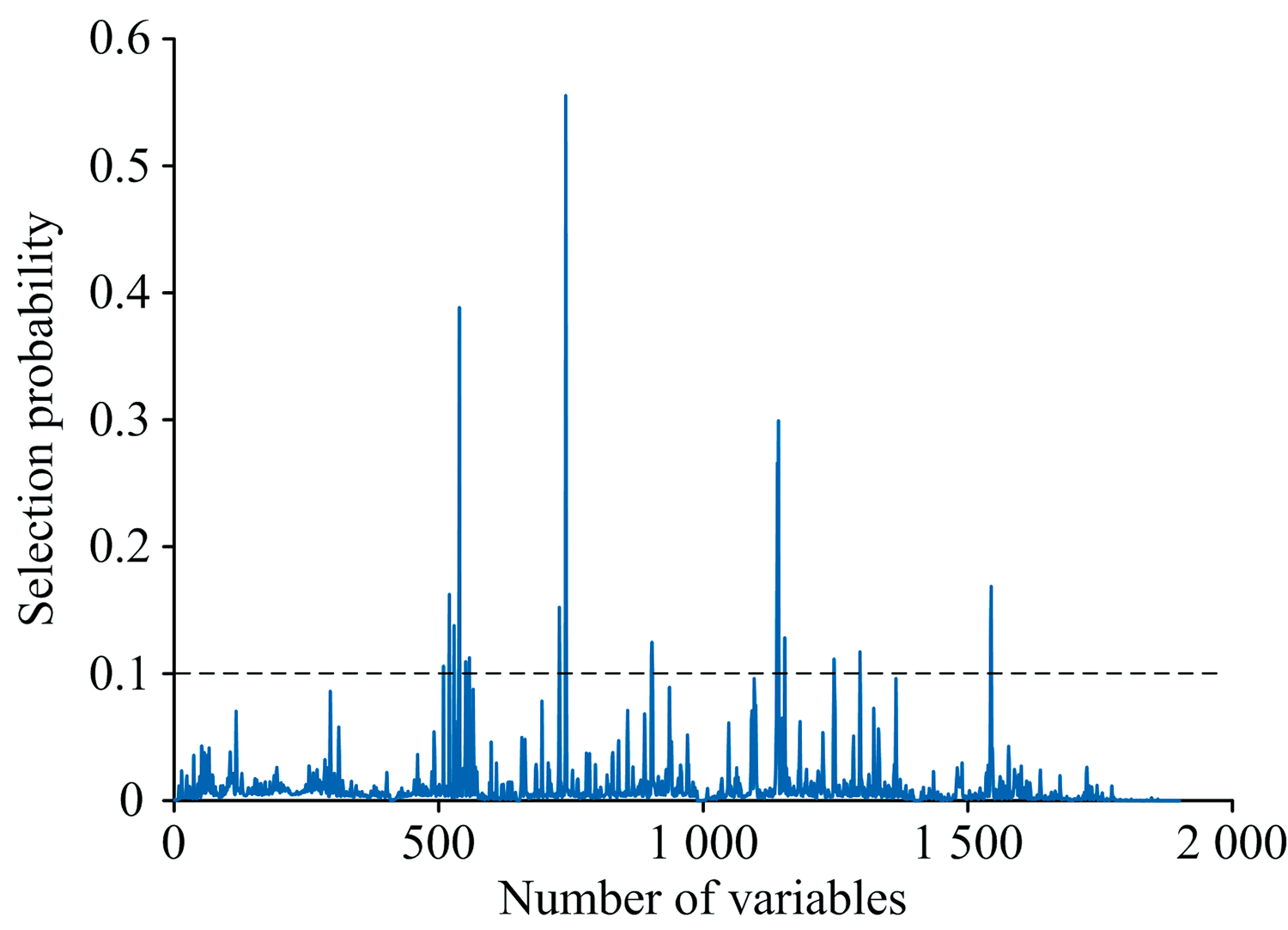 | 图3 RF算法确定的变量选择概率Fig.3 Selection probability determined by RF |
| 表2 不同算法筛选的特征波段 Table 2 Characteristic bands extracted by different algorithms |
2.2.2 基于RF-CARS、 RF-IRIV和RF-SPA算法的波段筛选
为了提升高光谱估算模型的精度, 分别采用RF-CARS、 RF-IRIV和RF-SPA三种算法进行了最佳特征波段的筛选。 图4为利用竞争性自适应重加权(CARS)算法对RF算法提取的22个波段进行再次筛选的过程, 抽样运行次数为50次。 图4(a)说明抽样运行次数与所选变量数量之间的关系, 随着运行次数的增加, 所选变量的数量以指数衰减函数的态势逐渐减少。 图4(b)为交叉验证均方根误差(root mean square error of cross validation, RMSECV)的变化趋势图。 当运行次数为1~26时, RMSECV总体为下降趋势, 说明在运行过程中去除了波段中的冗余信息; 当运行次数超过26后, RMSECV值逐渐增大, 表示关于土壤重金属铅含量的重要变量开始被去除。 因此, 在第26次运行时, RMSECV值最小, 此时可以确定最佳变量组合, 对应的变量数为6个, 结果见表2。 虽然RF-CARS算法的筛选结果仍存在少量共线性, 但与RF算法的初步筛选结果相比, 已较好地降低了波段间的共线性。
 | 图4 RF-CARS筛选变量Fig.4 Variables extracted by RF-CARS |
通过对RF算法初筛结果进行多次实验, 确定迭代保留有效信息变量(IRIV)算法的最大主因子数为10, 交叉验证次数为5, 对22个波段共进行3轮筛选, 结果如图5所示。 在第1轮迭代, 保留的变量数量迅速减少, 由22个减少到18个, 经过第2轮迭代, 减少1个变量后, 保留17个变量, 之后进入反向消除的第3轮迭代, 最终得到9个变量, 筛选完成。 IRIV算法将RF筛选出的波段进一步分为强信息波段、 弱信息波段、 无信息波段和干扰信息波段, 减小RF筛选结果的随机性, 增加与土壤重金属铅含量相关的有效信息波段被选中的概率, 有利于增强估测模型的精度。 通过RF-IRIV算法筛选出9个特征波段, 结果见表2。
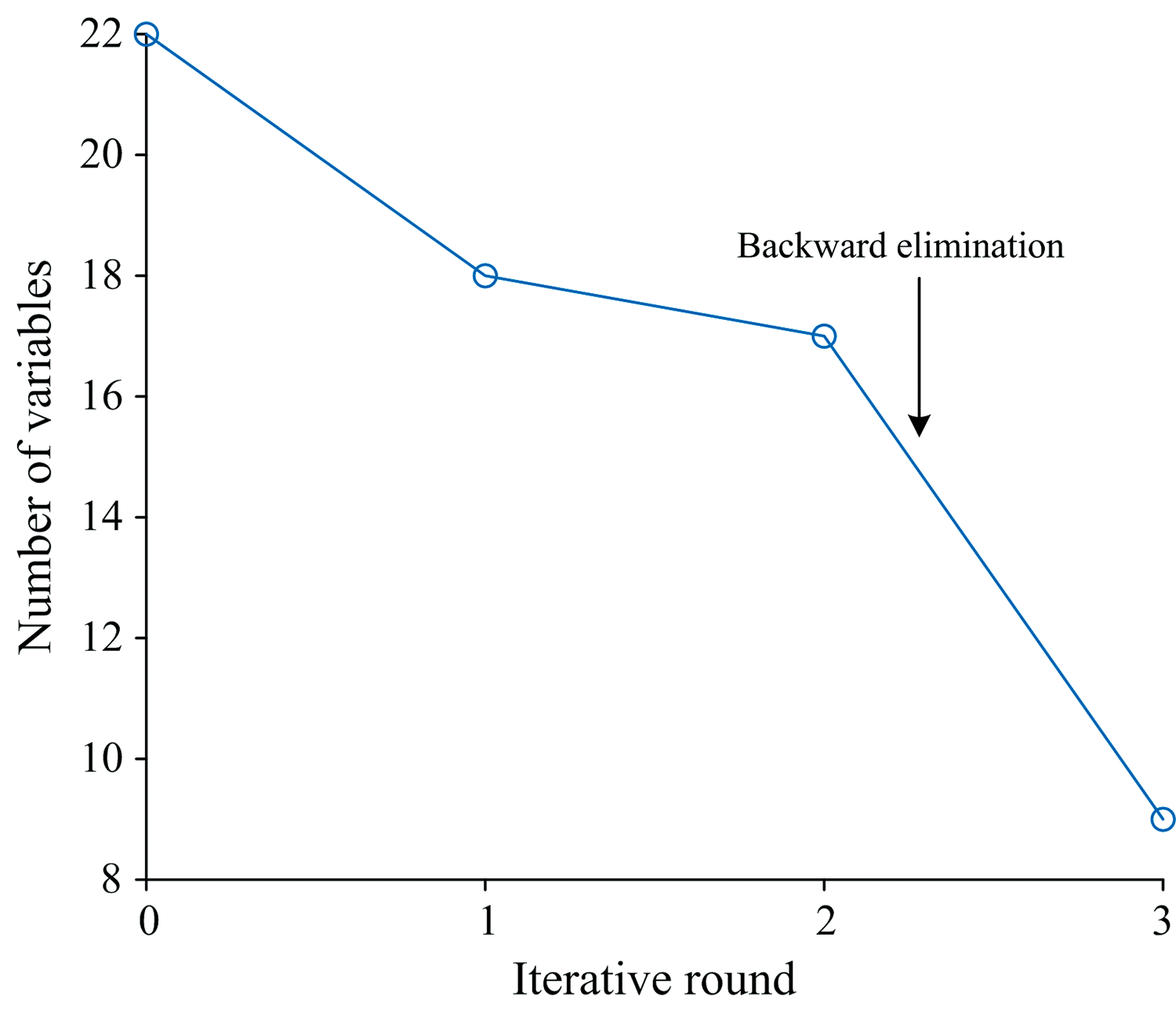 | 图5 RF-IRIV筛选变量Fig.5 Variables extracted by RF-IRIV |
在RF算法初选后, 再采用连续投影算法(SPA)进一步筛选变量, 结果如图6所示。 由图6(a)可知, 随着筛选变量数量增加, RMSE曲线先迅速下降后趋于平缓, RMSE最小值(RMSE=1.765 6 mg· kg-1)对应的变量数为最优变量个数(7个)。 图6(b)为RF-SPA算法筛选出的7个最优变量, 结果见表2。 该波段选择算法重点解决变量间的共线性问题, 提高了对特征波段的选择能力。
 | 图6 RF-SPA筛选变量Fig.6 Variables extracted by RF-SPA |
表2为不同算法筛选的特征波段, 从中可以看出RF算法初选的特征波段主要位于近红外光谱区域, 这与土壤组分中的有机质、 铁氧化物和黏土矿物有关。 成永生等[8]认为土壤铅的特征波段主要分布在350~418、 838、 1 400~1 600及1 930~2 400 nm; 刘彦平等[9]认为铅元素的特征波段主要在350~600、 900~1 200、 1 300~1 800及2 000~2 500 nm范围。 本研究初选的特征波段基本在前人认可的范围内, 二次筛选提供了较为可靠的光谱数据。 在RF算法的基础上, 采用CARS、 IRIV及SPA算法进一步筛选, 分别得到6、 9和7个特征波段, 其中888、 1 550和1 563 nm波段被3种算法同时选中, 说明这3个波段中的信息可能与土壤铅含量有重要关联。
分别以RF-CARS、 RF-IRIV和RF-SPA算法筛选出的特征波段为自变量, 土壤重金属铅含量为因变量, 构建基于XGBoost和GWR的土壤铅含量估测模型, 建模效果如表3所示。 对比2种模型下3种算法的表现, 发现通过RF-CARS算法构建的模型精度低于RF-IRIV和RF-SPA算法。 可能因为采用 CARS 算法对波段进一步筛选时, 指数衰减函数误将部分有用的弱信息波段进行了强制剔除, 导致模型的估测能力降低[10]。 RF-IRIV算法的建模效果明显优于其他算法, 说明该算法能筛选出代表性较好的特征波段, 这与IRIV筛选波段时具有软收缩的特点有关。 在IRIV的多次迭代中, 减小了偶然因素造成的误差, 更充分的对波段中的有效信息进行挖掘。 SPA在筛选波段时, 通常会选择具有较低共线性的波段, 而非有效波段, 因此采用RF-SPA算法选取的特征波段不太稳定。
| 表3 土壤铅含量估测模型的训练集与验证集结果 Table 3 Training set and validation set results of heavy metal content estimation model |
通过对模型的整体估测效果进行对比, 发现基于特征波段构建的GWR模型(R2> 0.75, RMSE< 1.3 mg· kg-1, RPD> 2)明显优于XGBoost模型, 这可能与其在建模过程中不仅考虑光谱特征, 并且应用采样点空间位置信息进行局部回归有关。 结合RF-IRIV算法构建的GWR模型预测效果最佳, 训练集与验证集的R2分别为0.917和0.892, RMSE分别为0.837和0.825 mg· kg-1, RPD分别为3.49和3.09, 相较于RF-IRIV-XGBoost, 验证集R2提升了0.161, RMSE降低了0.527 mg· kg-1, RPD提高了1.20, 可对土壤样品进行有效估测。
为进一步对比模型估测效果, 选取2种建模方法下的最优模型, 以土壤铅含量的实测值为横坐标、 预测值为纵坐标绘制散点图(图7)。 从图中可以看出, RF-IRIV-GWR模型的样点比RF-IRIV-XGBoost模型更接近1:1线, 证明该模型具有更好的精度和预测能力。 综合分析表3和图7, 认为基于RF-IRIV算法筛选出的特征波段构建的GWR模型可作为土壤重金属铅含量的最优估测模型。
 | 图7 不同铅含量估测模型预测值与实测值的比较Fig.7 Comparison between predicted and measured values of different lead content estimation models |
采用RF-CARS算法提取特征波段, 与Wei等[11]采用CARS-SCA算法提取与土壤砷含量相关的光谱信息的效果相似。 RF-IRIV算法减少了波段中的不相关信息, 与冯帅等[12]利用该算法筛选波段的效果一致。 Wu等[13]利用CARS-SPA算法优选的7个特征波段构建土壤含水量估测模型, 极大降低模型的复杂度, 而本研究的RF-SPA算法也具有相同研究效果。 研究结果表明, 采用RF-CARS、 RF-IRIV及RF-SPA 3种算法对高光谱波段进行筛选可去除波段中的大量冗余信息, 提取出与土壤重金属铅含量相关的重要波段, 并提高估测模型的稳定性和预测能力, 这与前人在估测土壤重金属含量方面对波段进行两次筛选的效果一致, 表明本研究筛选特征波段的方法具有一定可行性[6]。 基于RF-CARS和RF-SPA算法筛选特征波段虽能简化模型, 但所选波段的稳定性不足, 提取的波段不总能反映土壤铅含量信息。 RF-IRIV算法能较为稳妥的提取高光谱数据中的有效波段, 并且在RF算法的基础上使用IRIV算法能克服单纯使用IRIV算法筛选波段时计算量大、 耗时长的缺点。 此外, 3种算法筛选的特征波段全部位于近红外光谱区域, 说明土壤铅元素的光谱敏感区域主要位于近红外波段。 利用XGBoost和GWR方法构建估测模型, 综合考虑了全局与局部回归算法。 GWR模型在土壤含盐量反演方面具有较好的效果, 但在土壤重金属含量估测方面的研究较少, 作为一种局部建模方法, 本研究中GWR土壤重金属铅含量估测模型的性能也较好[14]。 在光谱处理过程中, 采用传统数学变换增强了光谱与土壤铅含量的敏感性, 但通过相关研究发现, 连续小波变换等处理方法在挖掘土壤有效信息方面具有更好的效果, 所建模型具有更高的预测能力[15]。 为进一步提升土壤重金属含量的高光谱反演精度, 采用多源化数据、 线性与非线性方法结合已成为高光谱遥感技术的重要发展趋势[7]。
以渭干河-库车河三角洲绿洲为研究区, 采用RF-CARS、 RF-IRIV及RF-SPA算法对高光谱数据进行特征波段的筛选, 并分别构建XGBoost和GWR模型, 比较不同算法的估测精度。 研究表明:
(1)倒数对数一阶微分变换后光谱与土壤铅含量的相关性显著提高, 相关系数最高可达到0.620(p< 0.001), 说明一阶微分变换处理可有效放大细小的光谱特征, 增强波谱信息。
(2)通过RF-CARS、 RF-IRIV及RF-SPA算法分别提取6、 9和7个特征波段, 占全波段的0.32%、 0.47%和0.37%, 表明3种算法可在很大程度上减少高光谱波段中的冗余信息。
(3)对比3种算法, 发现基于RF-IRIV算法建立的2种模型精度最高, 说明RF-IRIV算法能有效克服RF-CARS和RF-SPA的不足, 更为准确的筛选出包含有效信息的波段。 相较于XGBoost, 利用GWR方法构建的模型的稳定性和预测能力更好, 更适于研究区土壤铅含量的估测, 其中RF-IRIV-GWR模型的性能最好, 训练集与验证集的R2均大于0.8, RMSE均小于0.9 mg· kg-1, RPD均大于3, 在本研究区土壤铅含量估测方面具有一定适用性, 为同类地区反演土壤重金属含量提供参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|