

{kind=link}
{kind=link}
{kind=link}
激光诱导击穿光谱结合人工神经网络鉴别不同产地的丹参药材
[孙成玉1  , 焦龙
, 焦龙1, * , 闫娜莹1 , 闫春华1 , 屈乐2 , 张晟瑞3 , 马羚1 ]
, 焦龙, 闫娜莹|
|


作者简介: 孙成玉, 1998年生, 西安石油大学化学化工学院硕士研究生 e-mail: 710835609@qq.com
不同产地丹参药材的质量差异显著, 亟需建立准确、 快速的分析鉴别方法, 对丹参药材的产地进行识别。 激光诱导击穿光谱(LIBS)具有快速、 实时、 高效、 等特点, 克服了传统分析方法时间长、 程序复杂等问题。 人工神经网络(ANN)方法则具有强大的学习和泛化能力, 是一种快速、 准确的分析方法。 采用LIBS技术结合ANN方法构建了对不同产地丹参药材的鉴别方法。 实验首先收集来自安徽、 甘肃等六个不同产地的丹参样品, 并通过LIBS光谱仪对丹参样品进行光谱采集; 之后对丹参LIBS光谱的元素特征峰进行比对, 发现不同产地丹参样品的元素发射谱线强度存在着差异, 如Fe元素(238.20, 373.71 nm)和Ca元素(315.89, 317.93 nm)等; 采用最大最小归一化(MMN)、 标准正态变换(SNV)、 均值中心化(MC)、 Savitzky-Golay平滑滤波(SG)以及多元散射校正(MSC)五种预处理方法对LIBS光谱数据进行预处理优化, 减少光谱噪声以及其他干扰信息的影响; 最后分别搭建ANN分类模型, 从测试集分类准确率、 每类产地的敏感性、 精确率和特异性等方面进行比较, 选择最优模型。 基于原谱的ANN模型测试集分类准确率为94.24%; SNV、 MC两种方法并没有提升ANN模型的分类能力; MMN、 SG及MSC三种预处理方法均提升了ANN的分类效果。 SG-ANN模型取得了最佳鉴别效果, 外部测试集分类准确率为98.15%, 同时具有更高的敏感性、 精确率和特异性, 其中, 安徽、 河南两地丹参样品的判别结果最好, 敏感性、 精确率及特异性均达到100.00%, 其余四种产地丹参样品的敏感性、 精确率及特异性也在95.00%以上。 该结果表明, 选择合适的光谱预处理方法, 能显著提升ANN模型对于丹参产地的预测分类能力, 构建一种相关性更强的定性分析模型。 研究结果表明LIBS技术结合人工神经网络方法是一种很有前景的丹参药材分析鉴别方法, 为中药材质量监督体系提供一种新思路。
The quality of Salvia miltiorrhiza in different origins varies greatly, and it is urgent to establish an accurate and rapid analytical method for discrimination. Laser-induced breakdown spectroscopy (LIBS) has the advantages of fast, real-time, high efficiency, which overcomes many problems of traditional analysis methods. Artificial neural network (ANN) has strong learning and generalization abilities, a fast and accurate analysis method. Therefore, a method for discriminating Salvia miltiorrhiza from different geographical origins was developed by using LIBS combined with ANN. In the experiment, the samples of Salvia miltiorrhiza from six different origins, such as Anhui and Gansu provinces were collected, and the spectra of Salvia miltiorrhiza samples were collected by LIBS spectrometer. Then, comparing the element characteristic peaks of LIBS, it was found that there are differences in the element emission intensity of Salvia miltiorrhiza from different origins, such as Fe (238.20, 373.71 nm) and Ca (315.89, 317.93 nm). A supervised classification model was established by the ANN method combined with 5 different spectral preprocessing methods: maximum and minimum normalization (MMN), mean centralization (MC), standard normal transformation (SNV), Savitzky-Golay smooth filtering (SG) and multiple scattering correction (MSC). The RAW-ANN model has achieved a test set classification accuracy of 94.54%; SNV and MC methods did not improve the classification ability of the ANN model; And the three preprocessing methods of MMN, SG, and MSC all have improved the classification performance of the ANN model. The SG-ANN model achieved the best classification effect, with a test set classification accuracy of 98.15%. At the same time, it has higher sensitivity, precision and specificity, of which Anhui and Henan provinces have the best discrimination results, with sensitivity, precision and specificity reaching 100.00%. The other four orgins’ sensitivity, precision and specificity are also above 95.00%. The results showed that selecting an appropriate spectral preprocessing method could significantly improve the classification ability of the ANN method and build a more relevant qualitative analysis model. The above results show that LIBS combined with ANN is a promising method for analysing and identifying Salvia miltiorrhiza, which provides a new idea for the quality supervision system of Chinese medicinal materials.
丹参是目前治疗心血管疾病的常用药物, 具有多种显著的医学作用[1, 2, 3], 如抗氧化、 抗动脉粥样硬化、 抗肿瘤、 预防脑卒中、 降低血糖等。 不同地区丹参因生长环境、 栽培措施、 采收时间、 加工方法等各不相同, 导致药材质量差异较大。 传统上对丹参来源的鉴定主要根据其形状、 颜色和活性成分含量进行, 但当丹参的形态或活性成分含量相似时, 这些方法的鉴定结果常常不够准确。 因此, 需要构建一种可靠、 准确、 能够对不同地区种植的丹参进行鉴别的标准化方法。
不同产地丹参的分类可以通过其化学成分(如活性成分、 毒性元素和营养元素)的差异来完成。 丹参的常规分析技术主要有高效液相色谱(high performance liquid chromatography, HPLC)[4]、 电感耦合等离子体发射光谱(inductively coupled plasma-atomic emission spectrometry, ICP-OES)[5]和电感耦合等离子体质谱(inductively coupled plasma mass spectrometry, ICP-MS)[6]等。 虽然可以实现丹参有效成分或微量元素的准确分析, 然而通常需要经过复杂的样品预处理和较长的分析时间, 致使分析效率下降; 此外, 上述分析技术在检测过程中通常需要有机溶剂, 且具有毒性及致癌性, 进而对操作人员的身心健康产生一定的影响。 因此, 建立一种快速有效的分析方法是对丹参产地进行鉴别和分类的必要条件。 激光诱导击穿光谱(laser induced breakdown spectroscopy, LIBS)[7, 8]具有快速、 实时、 原位、 微破坏分析、 远程检测和多元素同时分析等优点[9], 已被应用于地质勘查[10]、 工业过程分析[11, 12]、 科学考古[13]、 医学诊断[14]、 环境监测[15]等领域。 在中药研究方面, LIBS技术已被应用于中药(如三七、 葛根、 当归、 川芎)的产地划分、 营养元素和毒性元素的检测[16, 17, 18], 然而, 关于LIBS技术应用于丹参分析的报道却鲜有报道。
人工神经网络(artificial neural network, ANN)方法源自生物学, 结合数学和物理方法从信息处理的角度对人脑神经网络进行抽象, 建立自适应非线性动态系统, 具有强大的输入输出非线性映射能力、 自我适应能力和学习能力[19]。 采用LIBS技术结合ANN方法对物质进行定性分类, 具有良好的可行性, 并被应用于多种研究领域。 宋海声[20]等利用LIBS技术结合人工神经网络法对常见的9种塑料进行分类识别, 识别准确率为99.72%; 在中医药方面, Wang[21]等采用激光诱导击穿光谱、 主成分分析(PCA)和人工神经网络相结合的方法, 对两种不同产地或不同部位的中草药——党参和川芎进行了分析和鉴定, 识别准确率分别为95.83%和99.85%。 由此推测, 可以使用人工神经网络结合LIBS技术对丹参产地进行分类鉴别。
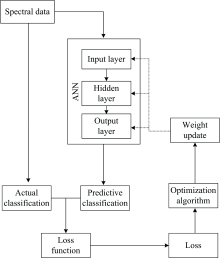
将反向传播-人工神经网络(BP-ANN)方法与LIBS光谱技术相结合。 首先, 采集六个产地的丹参LIBS光谱, 通过NIST数据库对LIBS光谱中元素特征峰进行比对, 对光谱进行初步的分析; 其次, 从最大最小归一化(MMN)、 标准正态变换(SNV)、 均值中心化(MC)、 Savitzky-Golay平滑滤波(SG)以及多元散射校正(MSC)五种方法中选择出最佳的光谱预处理方法, 基于BP-ANN方法搭建分类模型。 实验流程如Scheme 1所示。
 | Scheme 1 研究流程图Scheme 1 LIBS coupled with ANN for identification of Salvia miltiorrhiza |
所用丹参样品均以干根的形式从中国西安医药超市购买。 选取陕西、 山西、 山东、 河南、 甘肃、 安徽6个产地共18种丹参样品, 每个产地分别有3种不同丹参样品, 其中1—3号样品来自安徽省、 4—6号来自甘肃省、 7—9号来自河南省、 10—12号来自山东省、 13—15号来自山西省、 16—18号来自陕西省。 将所有样品首先进行烘干和粉碎处理, 使用球磨机对粉碎后的样品进行研磨, 粉末通过200目不锈钢筛子, 最后使用压片机(PC-24, Pinchuang Technology, China)对丹参粉末进行压片处理, 压力为40 MPa, 时间为5 min, 压制成直径为20 mm, 厚度为3 mm的薄片。
采用Q-switched Nd:YAG激光器(Dawa 300, Beijing Beamtech, China), 波长为1 064 nm, 本实验脉冲能量经过优化设置为150 mJ, 持续时间约为8 ns, 重复频率为5 Hz。 将丹参粉末样品薄片直接放置在X-Y-Z手动测微台上。 利用焦距为100 mm的平凸透镜将激光束垂直聚焦到样品表面, 对样品进行烧蚀, 形成直径为100 μ m的光斑。 为了提高发射强度的再现性, 将焦点放置在目标表面以下2 mm处。 等离子体辐射利用7 mm聚焦熔融二氧化硅准直透镜耦合到光纤上, 然后传输到三通道光纤光谱仪(MX2500+, Ocean Optics, USA, 波长范围: 200~500 nm, 分辨率: 0.07 nm)。 光谱仪的门宽设置为1 ms。 探测器的延迟时间设置为3 μ s, 避免了脉冲激光轫致辐射的探测, 提高了信噪比。 在进行LIBS实验之前, 利用Hg-Ar灯对LIBS光谱的波长进行了标定。 光谱采集时, 对每个产地丹参薄片样品随机采集120次光谱, 为了减少激光波动的影响, 每条光谱是通过10个激光脉冲累积得到的, 六个产地丹参样品光谱总数为720。
BP-ANN是单向传播的多层前向网络, 由输入层、 隐含层和输出层组成, 采用该网络可以实现输入-输出的非线性映射。 网络的隐含层数量决定了网络的性能和效率, 当隐含层数较多时, 虽然可以提高学习精度, 但是会增加神经网络的复杂程度, 延长训练时间; 当隐含层数和节点数较少时, 学习效率较高, 精度较好。 选择单隐含层的三层BP网络。
BP-ANN模型的学习过程由正向传播和反向传播组成, 正向传播计算如式(1)、 式(2)所示
其中, i, j, k分别代表输入层、 隐含层、 输出层的神经元个数; yh为隐含层的输出; f1表示输入层到隐含层的Sigmoid传递函数; wij表示输入层与隐含层间的权值; li为输入层的数值, 即为丹参LIBS光谱; Cj表示输出层的输出值, 即为丹参产地; f2为隐含层到输出层的线性传递函数; wjk为隐含层与输出层的权值。
反向传播公式为
式(3)中, Ep表示输出值的误差, tpj为期望输出值, ypj为实际输出值。 输入数据li通过隐含层Sigmoid函数f1的非线性变换处理, 再经过线性变换传入输出层, 如果输出层没有达到期望值, 则把Ep反向传播回去, 以此对各层神经元之间的权值进行迭代调整, 直至Ep减小到设定的范围内, 然后即可按照新的权值来完成神经网络的测定。
BP-ANN建模采用Matlab(2019b)中的Neural Network Pattern Recognition工具箱。 全部计算在配置为Intel(R) Core(TM) i7-6500U CPU的计算机中进行。
表1为分类任务的混淆矩阵, 其中TP(true positive)表示真实正例样本被正确分类为正例样本的数目, TN(true negatives)表示真实负例样本被正确分类为负例样本的数目, FP(false positives)表示真实负例样本被错误分类为正例样本的数目, FN(false negatives)表示真实正例样本被错误分类为负例样本的数目。
| 表1 混淆矩阵 Table 1 Confusion matrix |
表1中获得的TP, TN, FP和FN, 分类任务的准确率(Accuracy)、 敏感性(Sensitivity)、 精确率(Precision)和特异性(Specificity)可分别表示为式(4)—式(7)
图1(a—d)分别显示了不同产地丹参药材的LIBS光谱, 光谱特征谱线主要集中在波长为220~390 nm的范围内, 因此根据波长范围将原始光谱图分为3段(b: 220~270 nm; c: 270~330 nm; d: 330~390 nm), 根据美国国家标准与技术研究院(NIST)数据库[22]确定丹参光谱中具有代表性物质元素的发射谱线, 并在图1中标出。
 | 图1 不同产地丹参的代表性LIBS光谱 (a): 全谱; (b): 220~270 nm; (c): 270~330 nm; (d): 330~390 nmFig.1 Representative LIBS spectra of the Salvia miltiorrhiza samples from different regions (a): Full sqectrum; (b): 220~270 nm; (c): 270~330 nm; (d): 330~390 nm |
图1中识别了丹参LIBS中Fe、 Co、 B、 C、 Al、 Ti、 Mn、 Mg、 Pb、 Si、 Ca、 和Sc元素的特征发射谱线, 通过比对可以看出, 不同产地丹参样品的元素的发射谱线强度存在着差异, 如Fe元素(238.20, 373.71 nm), B元素(239.50 nm), Al元素(308.22, 309.27 nm), Ca元素(315.89, 317.93 nm)和Ti元素(334.94, 336.12, 337.28 nm)等。 这可能是由于不同产地丹参药材的种植环境因素(如气候、 土壤、 水和光照等), 以及人为因素(如植栽培技术、 采收方法及时间、 加工及炮制技术等)的影响, 导致不同产地的丹参药材样品中各种元素含量存在一些差异, 同时, 丹参中各种元素含量的差异也导致了丹参药材不同产地的质量存在差异。 通过以上分析可以看出, 不同产地丹参的LIBS光谱确实存在差异, 但是仅凭人眼很难区分差异, 同时对于光谱中各个元素特征谱线的标注工作量繁重, 可以采用人工神经网络方法结合LIBS光谱来对丹参药材产地进行鉴别。
对于LIBS光谱, 除了丹参样品的特征信息外, 还有激光诱导过程中产生的背景噪声辐射, 光纤探头采集到的噪声, 模拟/数字、 数字/模拟转换等过程产生的附加噪声[23]。 因此, 通常需要使用光谱预处理方法来消除不相关信息, 改善光谱数据之间的差异, 从而提高ANN模型的训练效果。 本工作选择最大最小归一化(MMN)、 标准正态变换(SNV)、 均值中心化(MC)、 Savitzky-Golay平滑滤波(SG)以及多元散射校正(MSC)五种方法对LIBS光谱进行预处理。 五种预处理方法结合ANN建立分类模型, 通过对比1.5节中的各项评价指标, 选择最佳模型。
以丹参样品的LIBS光谱作为ANN模型的输入层, 隐含层为神经网络模型的神经元, 输出层为丹参产地标签。 采用随机划分的方法, 将LIBS光谱按70%:15%:15%的比例划分训练集、 验证集及测试集。 训练集用于训练模型; 验证集用于参数调优, 得出最佳模型; 测试集用于评价模型。
使用Matlab(2019b)中自带的Scaled conjugate gradient backpropagation(trainscg)算法对BP-ANN模型进行学习训练。 Trainscg算法根据缩放共轭梯度法更新权重和偏差值, 同时占用更少的内存, 适用于LIBS光谱数据等一维数据, trainscg算法中迭代次数(epoch)阈值为1 000, 交叉熵损失值(performance)范围为0.000~0.410, 梯度(gradient)范围为1~2.50, 验证检查(validation check)的范围为0~6。 BP-ANN模型的训练流程如图2所示。
 | 图2 BP-ANN训练流程图Fig.2 The flow chart of BP-ANN training |
以10~20作为隐含层节点数变量选择范围, 以原始光谱ANN模型为例, 探究不同隐含层节点数对ANN模型分类准确率影响, 验证集分类准确率如表2所示。 从表2可以看出, 当隐含层节点数设置为15时, ANN模型的性能达到最优, 验证集分类准确率为93.76%, 且具有较少的迭代次数, 即训练时间较短, 因此后续实验选择15为ANN模型的隐含层节点数。
| 表2 不同隐含层节点数对ANN模型的影响 Table 2 Influence of different number of hidden layer nodes on ANN model |
基于原始光谱数据和五种预处理后的光谱数据建立了六个ANN鉴别模型, 探究不同预处理方法对ANN模型分类准确率影响, 隐含层节点数设置为15, 测试集分类准确率如表3所示。 表3可以看出, 基于LIBS原谱的ANN模型已经取得了不错的分类效果, 测试集分类准确率为94.24%; 较原谱相比, SNV、 MC两种预处理方法并没有提升ANN模型的分类效果, 准确率分别为93.34%和92.46%; MMN、 SG及MSC三种预处理方法提升了ANN模型的分类能力, 其中, SG-ANN模型效果最佳, 测试集分类准确率为98.15%。
| 表3 不同产地丹参样品的鉴别结果(敏感性、 精确率和特异性) Table 3 The discriminant results of Salvia miltiorrhiza samples from different production areas obtained by different preprocessing methods (Sensitivity, Precision and Specificity) |
每个产地的敏感性(Sensitivity)、 精确率(Precision)和特异性(Specificity)也在表3中标出。 敏感性表示模型预测正确的产地占真实丹参产地的比例; 精确率表示模型预测正确的产地占模型预测产地的比例; 特异性表示模型预测正确的其他产地占模型预测的其他产地比例。 三者均是ANN模型分类效果的判别指标, 数值越高, 表示模型的分类效果越好。 从表3可以看出, 与其他五种判别模型相比, SG-ANN模型对每个产地的丹参样品都取得了较好的判别结果, 其中, 安徽和河南两地丹参样品的判别结果最好, 敏感性、 精确率及特异性均达到100.00%, 其余四种产地丹参样品的敏感性、 精确率及特异性也在95.00%以上。 结果表明, SG-ANN模型对不同产地丹参样品具有良好的鉴别性能, 且对于各个产地均具有不错的分类效果。
提出了一种基于人工神经网络的丹参LIBS光谱产地分类模型, 实现了对中药材丹参产地的定性鉴别。 采用LIBS光谱仪对丹参进行光谱采集, 并通过NIST数据库对LIBS光谱中元素特征峰进行识别, 发现仅凭人眼分辨难以识别产地, 同时元素特征谱线的标注工作量繁重; 通过五种不同的光谱预处理方法对比, 选择Savitzky-Golay平滑滤波方法为最佳预处理方法, 并基于ANN方法搭建分类模型, 优化网络参数权重, 完成模型训练; SG-ANN模型对于丹参产地鉴别效果显著, 外部测试集分类准确率为98.15%, 同时具有较高的敏感性、 精确率和特异性。 由此可见, LIBS技术结合人工神经网络方法应用于丹参药材的产地判别具有良好的可行性, 同时更加简便、 准确、 高效, 为中药材定性分类研究提供了一种新的方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|