{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于仿生优化算法的水稻叶绿素含量反演模型
[李晓凯 , 于海业, 于跃, 王洪健, 张蕾, 张昕, 隋媛媛
, 于海业, 于跃, 王洪健, 张蕾, 张昕, 隋媛媛* ]
, 于海业, 于跃, 王洪健, 张蕾, 张昕, 隋媛媛]
|
|


作者简介: 李晓凯, 1998年生,吉林大学生物与农业工程学院硕士研究生 e-mail: lixk20@mails.jlu.edu.cn
用光谱信息精准、 高效地检测水稻叶片叶绿素含量, 对诊断和优化水稻叶片氮素营养、 开发和优化稻田氮素追肥系统、 监测和评价水稻病虫害具有重要的实际意义。 针对单纯采用机器学习模型反演水稻叶片叶绿素含量模型精确性和稳定性差的问题, 以粳稻吉粳88为研究对象, 通过网格试验获得分蘖期等关键生育期的叶片表型高光谱数据和相对叶绿素含量。 选取核极限学习机(KELM)为基础建模模型, 提出了一种先依据基础KELM建模效果选择预处理方法后, 再利用仿生优化算法对所选预处理组合所对应的KELM模型的训练过程进行优化的新思路, 以提高模型预测精度。 首先, 对光谱数据的各类预处理方法展开研究, 通过对4类预处理方法进行全排列组合共得到72种预处理组合。 利用连续投影算法(SPA)选择特征波段输入KELM模型以筛选较优预处理组合。 依据建模效果, 预处理组合CWT+MMS, CWT+MSC+SG+SS和CWT+SS所对应KELM的测试集决定系数(Rp2)较高, 分别为0.850, 0.835和0.828。 其次, 为使KELM模型在保证稳定性和泛化性的前提下性能达到最优, 引入哈里斯鹰优化算法(HHO), 通过模拟鹰群在捕食时的合作行为和追逐策略, 自动最优调节上述三种KELM模型参数, 使得HHO-KELM模型Rp2分别为0.957, 0.867和0.858, 模型精度得到有效提升, 最高提升10.7%。 通过研究, 证明了HHO算法优化机器学习模型反演水稻叶片叶绿素含量的可行性, 为东北粳稻叶绿素含量的测定和评估提供了有力的参考和借鉴。
The accurate, efficient and nondestructive detection of chlorophyll content in rice leaves using spectral information is of practical importance for diagnosing and optimizing nitrogen nutrition in rice leaves, developing and optimizing nitrogen fertilization systems in rice fields, and monitoring and evaluating rice pests and diseases. This paper addresses the problem of poor model accuracy and stability when machine learning models are used solely to invert the chlorophyll content of rice leaves. Moreover, takes Northeast japonica rice Jijing88 as the research object, obtains leaf phenotypic hyperspectral data and relative chlorophyll content at key fertility stages such as tillering through grid tests, select the kernel limit learning machine (Kernel function extreme learning machine, KELM) in machine learning as the base modeling model, and proposes a new idea of selecting preprocessing methods based on the base KELM modeling effect first, and then optimizing the KELM training process corresponding to the selected preprocessing combination using a bionic optimization algorithm to improve the model prediction accuracy. First, this paper investigates the preprocessing methods of spectral data, and a total of 72 preprocessing combinations are obtained by combining all four types of preprocessing methods. The sequential projection algorithm (Successive Projections Algorithm, SPA) is used to select the characteristic bands for input into the KELM model to filter the better preprocessing combinations. Based on the modeling effect, the test set's coefficient of determination (Rp2) corresponding to KELM for the pretreatment combinations CWT+MMS, CWT+MSC+SG+SS, and CWT+SS was higher, 0.850, 0.835, and 0.828, respectively. Secondly, to make the KELM model perform optimally while ensuring stability and generalization. In this paper, the Harris Hawk Optimization Algorithm (Harris Hawks Optimizer, HHO) is introduced to automatically and optimally adjust the parameters of the above three KELM models by simulating the cooperative behavior and chasing strategy of the hawks during predation, resulting in the HHO-KELM models with Rp2 of 0.957, 0.867 and 0.858, respectively, and a maximum of 10.7% effectively improves the model accuracy. The feasibility of the HHO algorithm to optimize the machine learning model to invert the chlorophyll content of rice leaves was demonstrated, which provides a strong reference and reference for the determination and assessment of chlorophyll content in northeastern japonica rice.
水稻为我国主要粮食作物, 其农业生产面积在全国耕地面积中占比高, 约为25%, 居世界第2位。 随着人口规模的增长和生活质量的日益改善, 对粮食需求量也越来越高, 水稻产业得到了快速发展。 据国家统计局2020年度数据显示, 水稻产量在我国三大农作物中占比约为34%, 基本能保证60%的人民对粮食的需要, 所以确保水稻的质量和产量, 直接关系到我国粮食安全问题。 叶绿素是植物进行光合作用的主要色素, 在作物体内许多重要物质和蛋白质的合成中起着重要作用, 其含量与植被的光合能力、 生长发育以及营养状况密切相关。 当植物受外界环境胁迫时, 叶绿素含量会降低, 从而间接反映植物胁迫、 生长和衰老等状况[1, 2]。 有研究证明其含量可用于水稻叶片氮素营养诊断及优化、 稻田氮素追肥系统开发与优化、 监测与评估水稻病虫害等多方面研究[3], 具有重要的意义。 叶绿素含量直接影响水稻的光谱反射率, 尤其是可见光与近红外波段[4, 5], 因此基于光谱反射率反演叶绿素含量具有夯实的理论基础。
目前基于光谱信息预测水稻叶片叶绿素含量多以单波段、 多波段或全光谱信息为主。 单波段光谱常结合与叶绿素含量有较好相关性的植被指数或改进后的植被指数进行建模, 如比值指数、 归一化指数、 三角植被指数等, 但常会导致光谱有效信息无法充分利用, 模型精度偏低且适用性差[6, 7]。 选取全波段光谱信息建模时, 又由于存有复杂的冗余信息, 同样会使模型精度受到一定的影响。 此外, 光谱数据易受光、 噪音和基线漂移等因素的干扰, 影响后续分析处理和建模效果, 因此需在建模进行预处理。 常采用预处理手段是根据光谱信号的特征依照经验选择预处理方法, 虽无需建立模型, 但要求选择者有敏锐的判断力和丰富的经验; 为克服上述缺点, 增强模型准确性, 可采用依据预处理目的将预处理方法分类, 通过全排列组合后的实际建模效果选择最佳预处理方法, 但目前预处理方法较多, 耗时较长。 极限学习机(extreme learning machine, ELM)与核极限学习机(kernel function extreme learning machine, KELM)在风电功率预测[8]、 作物蒸散量预测[9]、 利用光谱对水源类型识别[10]等领域均取得较高精度, 但存有计算繁琐且易陷入局部最优解等问题, 并且在反演预测植物相关生理信息方面尚缺乏应用。
随着人工智能技术的发展, 最优算法在各个研究领域被广泛应用。 然而在求解多峰值、 多变量或目标函数不可微分等复杂优化问题时, 传统优化方法常导致求解过程计算繁琐或难寻得全局最优解等问题。 仿生群智能算法凭借对目标函数与约束条件的限制较少, 能高效地寻求最优解, 且与其他模型结合性好, 使得诸多复杂的问题得以更好地解决。为解决单纯采用机器学习模型反演叶绿素含量时精确性和稳定性差且易陷入局部最小值等的问题, 引入由Heidari, Mirjalili等在2019年提出的一种基于群体优化的仿生群智能算法— — 哈里斯鹰算法(Harris Hawks optimizer, HHO)[11]。 该算法具有较强的全局收敛性及鲁棒性, 能够很好地解决非线性规划、 组合优化等问题, 同时可根据不同情况选择合适的控制变量以获得更高的寻优精度, 因此备受研究人员的重视并迅速应用在各种领域。 Hossein等[12]将其应用于土木工程领域, 通过HHO算法优化了土质边坡稳定条件因子计算权重, 提高了预测准确度, 有效地解决了土木工程中边坡稳定性计算的难题; Du等[13]将HHO算法应用于空气质量检测领域, 利用改进后的HHO算法对极限学习机参数进行优化, 提出了一种预测精度较高的PM2.5和PM10极限学习机混合模型。 HHO算法还在水火电调度优化、 电力预测、 图像分割、 物联网领域、 新冠病毒感染人数预测等多领域取得进展[14, 15, 16]。 然而, 基于HHO算法在植物生理信息预测方面的应用还有待深入研究。
为进一步提高水稻叶绿素含量预测精度与稳定性, 以东北粳稻吉粳88为研究对象, 采用光谱检测技术, 首先依据多波段建模对水稻叶片光谱数据的预处理方法展开研究。 基于4类预处理方法全排列组合的优势, 在HHO模型基础上, 结合连续投影法将各预处理组合所筛选的特征波段输入模型中, 依据实际建模效果选择最佳预处理方法。 其次, 利用HHO仿生优化算法对KELM训练过程进行优化, 提出一种HHO-KELM融合模型, 进一步提高水稻叶片叶绿素含量反演模型的准确性与泛化性。 旨在探究光谱预处理的必要性及寻求最优的预处理方法, 拓宽群智能算法在植物生理信息预测方向的研究, 建立了更精准稳定的水稻叶片叶绿素含量诊断模型, 为作物叶片叶绿素含量诊断提供新的思路与理论依据。
实验于吉林大学农业实验基地内进行, 水稻品种选用吉粳88。 于2021年5月20日移栽, 实验共设5个氮肥梯度, 分别为N0(0), N1(120), N2(160), N3(200), N4(240), 单位为kg· hm-2, 氮肥梯度采用网格种植, 各网格面积为10 m× 10 m, 各水平设置3次重复。 每小区选取20株长势旺盛、 健康无病虫害的水稻叶片作为实验待测样本。
实验选定在阳光明媚、 无风的情况下进行, 实验时间为2021年7月10日(分蘖盛期)10:00— 14:00, 对300株样本进行数据采集, 每株测量倒二、 三完全展开叶, 采集叶片的高光谱和叶绿素含量数据, 样本量共为600个。 高光谱数据采用美国Analytical Spectral Devices公司生产的手持式地物光谱仪FieldSpec HandHeld 2测定, 测量范围325~1 075 nm, 采样间隔1.4 nm, 分辨率3 nm, 采用叶夹式对每片叶取避开叶脉的1/3, 1/2和2/3处进行测量。 叶绿素含量采用SPAD-502叶绿素仪测定(日本柯尼卡美能达), 同上述位置3次重复测量。 SPAD-502读数与叶绿素含量密切相关[17], 因此以其值表示叶绿素含量。 以上2种数据均取平均值作为该叶片高光谱与叶绿素含量数据。 数据处理与分析软件为ViewSpecPro, Matlab R2018b和 Origin 2018。
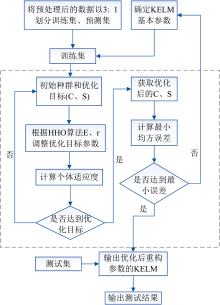
在光谱预数据处理前, 首先去除噪声, 保留401~1 000 nm波段, 采用蒙特卡洛交叉验证法(MCCV)在筛选光谱值与化学值的同时进行异常样本剔除, 保留样本561个。 然后应用不同预处理方法结合连续投影算法(successive projections algorithm, SPA)进行特征波段选择, 降低光谱数据维度。 样本采用3:1随机划分训练集(420个)和测试集(141个), 分别建立KELM模型以及优化后的HHO-KELM模型。
现有的光谱预处理方法大致可分为基线校正、 散射校正、 平滑处理和尺度缩放四类, 本研究所采用的预处理方法如表1所示。 按表1中由上至下的顺序, 依次从每类中选取一种方法(0代表无预处理), 全排列组合可以得到108种预处理组合方法。 由预实验可知, 采用MA与任何方法组合均不理想, 其相关系数不足0.1, 后续不再讨论。 其余全排列组合可得72种组合方法, 编号为1— 72。 将72种预处理组合方法结合SPA法进行KELM建模, 采用测试集决定系数(
| 表1 预处理方法种类 Table 1 Various pretreatment methods |
1.4.1 核极限学习机
极限学习机(ELM)是由南洋理工大学的Huang等[18]于2004年提出的基于单隐藏层前馈神经网络的算法, 最初是为改进反向传播算法(BP)以提升学习效率和简化学习参数的设定。 相较于传统前馈神经网络训练速度慢、 易陷入局部极小值点、 训练过程不稳定等缺点, ELM算法可以在输入层与隐含层之间随机产生连接权值(w)和隐藏层神经元的阈值(b), 且后续训练过程中无需调整, 只需要设置隐含层神经元的个数即可获得最优解。
为进一步增强ELM的泛化能力以及模型稳定性, Huang等[19]通过深度分析ELM与支持向量机(SVM)的原理, 提出将ELM与SVM中的核函数结合的改进算法KELM, 能够在保留ELM优点的基础上提高模型的适应性与稳定性, 使模型的预测性能得到有效提升。 其最终表达式为
式(1)中: x为输入向量, (x1, x2, …, xn)为训练样本输入向量, K()为核函数, n为样本数量, I为单位矩阵, C为正则化系数, Ω ELM为核矩阵, L为期望输出。
1.5.1 算法仿生原理
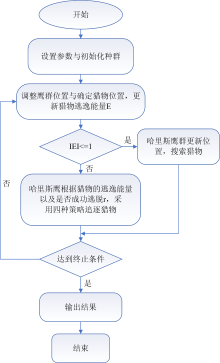
HHO算法是依据美国亚利桑那州南部猛禽哈里斯鹰在捕食时的合作行为和追逐策略。 根据场景动态性和猎物逃跑模式, 对哈里斯鹰群进行了数学模拟, 并结合莱维飞行(Levy-Flight)实现对复杂多维问题优化求解。 在合作行为中, 群鹰各自分工不同, 寻找目标、 驱赶、 狩猎各有所司。 在追逐策略中, 主要为“ 突袭围捕” , 突袭指群鹰从不同方向合作突袭猎物, 同时向猎物周围汇聚, 一次性捕获; 围捕指初次失败致使猎物外逃时, 在靠近猎物的地方进行多次快速短距离的突袭, 并根据猎物的反应和躲避方向做出不同的追逐策略。 这两种追逐方式可看作一种动态博弈过程。 由此建立了新的数学模型来处理各种优化问题[8]。 在HHO中, 哈里斯鹰是候选解, 猎物是随迭代逼近的最优解, 分为全局探索阶段、 探索与开发转换阶段和局部开发阶段, 局部开发阶段又分为软包围、 硬包围、 渐进式快速俯冲的软包围以及渐进式快速俯冲的硬包围四种策略。
1.5.2 具体算法与流程
(1)探索阶段
哈里斯鹰群体分散度很高, 其个体随机潜伏在某些位置, 利用敏锐的双眼侦查环境、 追踪猎物, 并根据两种策略等待并发现猎物: 当q< 0.5时, 哈里斯鹰会根据其他成员和猎物的位置进行栖息; 当q≥ 0.5时, 哈里斯鹰会在种群活动范围内随机栖息在某棵树上。
式(2)中, X(t)和X(t+1)分别为当前和下一次迭代时个体的位置, t为迭代次数, Xrand(t)和Xrabbit(t)分别为随机选出和具有最优适应度的个体位置, r1, r2, r3, r4和q都是[0, 1]区间的随机数, ub和lb为搜索空间变量的上下界。 根据q来随机选择所采用的策略, Xm(t)为个体平均位置, 其表达式为
式(3)中, N为种群规模, Xi(t)为种群中第i个个体的位置。
(2)探索与开发阶段的转换
根据猎物的逃逸跑量在探索和开发行为之间转换, 猎物逃逸能量(E)定义为
式(4)中, E0是猎物的初始能量, 为[-1, 1]之间的随机数, 随迭代自动更新; t为迭代次数; T为最大迭代次数。 当|E|≥ 1时进入全局探索阶段, |E|< 1当时进入局部开发阶段。
(3)局部开发阶段
在此阶段中, 哈里斯鹰开始对猎物进行突袭追捕。 根据逃逸能量E及区间(0, 1)的随机数r的取值大小来选择四种攻击策略捕获猎物, 具体体现为:
①软包围
当0.5≤ |E|< 1且r≥ 0.5时, 猎物有足够的体力去逃跑, 而鹰群通过环绕追逐猎物, 使其疲劳。 此阶段数学模型为式(6)
式(5)中, J=2(1-r5)为猎物的随机跳跃强度, r5为区间(0, 1)上的随机数。
②硬包围
当|E|< 0.5且r≥ 0.5时, 猎物筋疲力尽已不足以逃脱追捕, 此阶段的模型为
③渐进式快速俯冲式软包围
当r< 0.5, |E|≥ 0.5时, 猎物仍有能量去逃跑, 而鹰群将会产生一个环绕软包围来追捕猎物。 为了模拟猎物的逃跑模式和跳跃动作, 将Lé vy函数LF集成在HHO算法中, 此阶段模型为
式(7)中, F(· )表示最小化问题的适应度值, Y和Z分别为
式(8)和式(9)中, S为大小为D× 1的(0, 1)上的随机向量, D为目标函数涉及的维度, LF(· )为服从Levy-Flight 分布的向量, 其一维计算方法为式(10)
式(11)中, μ 和ν 为(0, 1)上的随机数, β 设置为1.5。
④渐进式快速俯冲式硬包围
当r< 0.5, |E|< 0.5时, 猎物没有足够的能量去逃跑, 鹰群构建了一个环绕硬包围来捕获猎物, 此阶段的数学模型为
式(12)中, Y和Z分别为式(13)和式(14)
算法流程如图1所示。
 | 图1 HHO算法流程示意图Fig.1 Schematic diagram of HHO algorithm flow |
在建模之前需对KELM的正则化系数C和核函数参数S进行预处理, 预处理方法中SG平滑的窗口参数、 CWT的小波函数和分解尺度参数, 均需结合SPA进行优化。 SG平滑优化选取窗口数从3~15进行筛选, 间隔为2, 以模型的RMSE值为评价标准, RMSE最小值对应的窗口即为最佳窗口数。 CWT优化方法为选取Daubechies(db2, db3, …, db15), Coiflets(coif1, coif2, …, coif5), Symmlets(sym2, sym3, …, sym7)共25个小波函数, 分解尺度从1~10, 同样以模型的RMSE值为评价标准, 最小值为最佳小波函数和分解尺度。 最终寻优结果如表2所示。
| 表2 预处理方法及KELM参数优化结果 Table 2 Optimization results of pretreatment methods and KELM parameters |
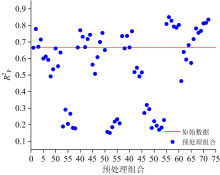
通过对预处理方法优化后, 对样本集进行KELM建模, 其结果如图2所示。 由图可知, 采用基线校正与尺度缩放以及两类方法结合可显著提高建模效果, 当引入CWT时, 发现在大部分情况下可显著提高预测精度, 但当加入散射校正后, 除结合CWT外的其余任意种类预处理效果反而下降, 尤其是引入MSC后显著下降。 最终选取较优预处理组合为CWT+MMS, CWT+MSC+SG+SS和CWT+SS。
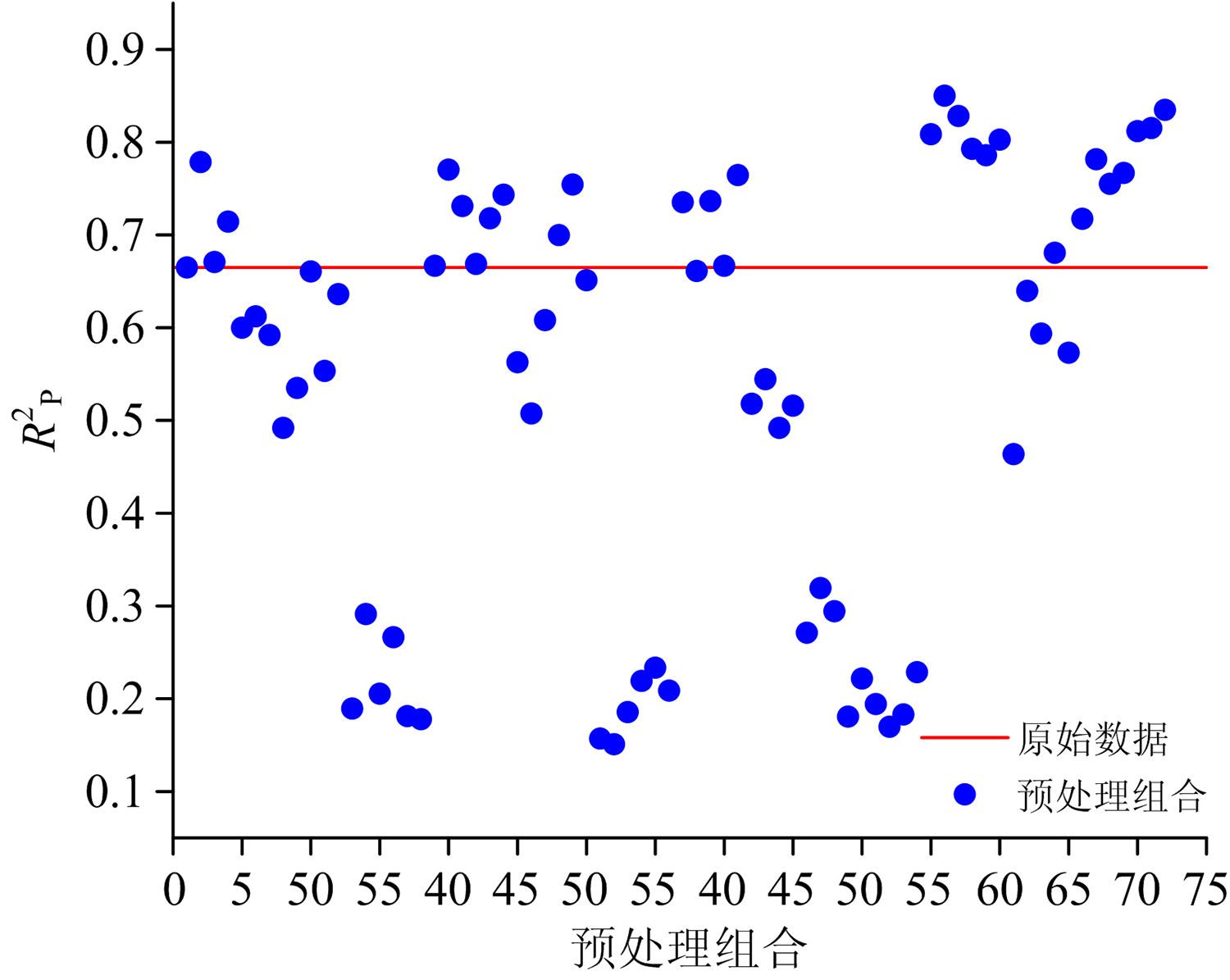 | 图2 预处理方法的KELM模型测试集决定系数 |
基础KELM中C和S取寻优后的固定值, 选取高斯核函数(RBF)为核函数。 利用HHO算法优化时, 依据其寻优特性对KELM的C和S选取进行优化, 同样选取核函数为RBF, 进而形成对比以验证模型预测精度的变化情况。 HHO中的适应度函数选择训练集误差的均方误差(MSE), 其值越小表明预测的数据与实际叶绿素数据拟合性越好。 适应度值定义如式(15)
HHO-KELM算法流程如图3所示。
 | 图3 HHO算法优化KELM算法流程示意图 注: 点画线框内为HHO优化KELMFig.3 Schematic diagram of the HHO algorithm to optimize the KELM algorithm |
为增加模型的对比性, 将预处理组合CWT+MMS, CWT+MSC+SG+SS和CWT+SS结合SPA所筛选的特征波段分别带入KELM和HHO-KELM模型中, 均选取高斯核函数(RBF)为核函数, 并通过调整种群规模(N)、 搜索空间变量的上下界(ub, lb)和最大迭代次数(T)使HHO-KELM模型达到最优效果。 本实验SPAD数值范围为[28.7, 48.9]且精确到0.1, SPAD-502量程为[0, 50], 因此为保证模型精度, ub设为[25, 50], lb为[0.1, 0.1]。 经反复实验后, 在模型达到最高精度时CWT+MMS, CWT+MSC+SG+SS和CWT+SS所对应的N和T分别为70, 30, 60和30, 40, 30。 3种预处理组合所对应的最优KELM和HHO-KELM模型的训练集均方误差(MSEC)、 决定系数(
| 表3 三种预处理组合所对应的KELM和HHO-KELM模型结果 Table 3 Individual parameters of the KELM and HHO-KELM models corresponding to the three pretreatment combinations |
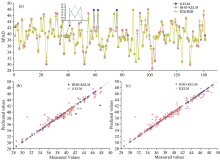
两模型所对应的测试集训练结果和预测误差如图4所示。 由图4(a)可看出HHO-KELM比KELM模型预测准确度更高, 观察图4(b)和(c)得KELM在训练集和测试集中预测存在较大偏差且稳定性差, 说明基础KELM有时无法充分利用数据信息, 所建模型预测性能较差。 而利用HHO算法优化后可以较好地解决, 表明利用HHO算法可以对KELM训练过程进行优化, 自动最优调节KELM模型参数, 使统计分析结果更准确且更有说服力。 图4(a)中测试集第59, 62和76个样本点的模型偏差显著, 经反复实验发现此3点为MCCV未筛选出的异常样本。 由此证明了利用HHO算法优化数学模型用于反演植物生理信息的可行性, 为今后寻求更优群智能算法用于研究精准、 无损和稳定的植物生理信息检测技术提供了理论依据。
 | 图4 CWT+MMS所对应的测试集预测结果对比图与散点图 (a): 训练集预测结果; (b): 训练集预测结果散点; (c): 预测集预测结果散点Fig.4 Comparison of prediction results and scatter plots for the training and test sets corresponding to CWT+MMS (a): Graph of prediction results of training set; (b): Graph of prediction results of training set; (c): Scatter plot of prediction results of the prediction set |
基于HHO-KELM模型建立植被生理参数反演模型的研究中仍有一些问题有待解决, 如本研究中以水稻的某一生育期为研究对象, 将其研究结果应用于其他植物或不同生育期的可靠性有待进一步考察。 是否可尝试结合多波段植被指数以减弱误差影响, 再提升模型的准确性与适用性。 其次是否所有的群智能算法都可应用于机器学习模型, 从而提升植物生理参数的预测性能, 还需更多验证。 最后在反复实验中发现, 因样本数量的关系, HHO算法易出现过拟合现象。 对于植物生理参数反演模型的可靠性和普适性仍需更深入的研究与实践。
通过对水稻叶片表型高光谱数据进行72种预处理组合后建模, 发现并非所有预处理方法都是有效的, 根据经验及信号特点进行预处理可能会对模型精度造成一定偏差, 可按数据处理目的对已有预处理方法进行分类再排列组合, 结合特征波段提取方法进行建模分析是选择最佳预处理方法的安全有效途径。 本研究依据建模效果, 预处理组合CWT+MMS, CWT+MSC+SG+SS和CWT+SS所对应KELM的测试集决定系数(
引入HHO算法自动最优调节三种KELM模型参数, 使得HHO-KELM模型
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|