
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于TSFS结合高阶张量特征提取方法的海水半潜油种类鉴别研究
[孔德明1  , 崔耀耀
, 崔耀耀2, 3 , 仲美玉2 , 马勤勇2 , 孔令富2 ]
, 崔耀耀|
|


作者简介: 孔德明, 1983年生,燕山大学电气工程学院副教授 e-mail: demingkong@ysu.edu.cn
半潜油是一种隐藏于海面之下并呈现悬浮状态的溢油, 其长期毒害并侵蚀着海洋生态环境。 然而, 针对半潜油污染到目前还未形成有效地监测手段和处理方式, 致使其污染的突发性和危害性更甚于海面溢油。 因此, 研究有效地半潜油鉴别方法对保护海洋生态环境具有重要意义。 三维荧光光谱技术中的总同步荧光光谱(TSFS)在油类污染物检测与鉴别中具有不存在瑞利散射干扰以及冗余数据少的优势, 但由于TSFS数据本身不具备三线性结构, 使得多维校正分析方法在其应用上受到了一定的限制。 基于此, 开展基于TSFS结合高阶张量特征提取方法的海水半潜油种类鉴别研究。 首先, 利用有机分散剂和六种不同种类的油品配制了90个半潜油实验样本; 然后, 利用FS920荧光光谱仪采集实验样本的TSFS数据, 并对该数据进行标准化预处理; 最后, 通过高阶张量特征提取方法二维线性判别分析(2D-LDA)以及二维主成分分析(2D-PCA)分别建立了半潜油样本的鉴别模型; 并将所建模型与常规方法多元曲线分辨率交替最小二乘法(MCR-ALS)结合线性判别分析(LDA)以及多维偏最小二乘判别分析(NPLS-DA)进行了对比。 分析结果表明, 2D-LDA和2D-PCA所建立的半潜油样本鉴别模型具有可靠的性能, 鉴别模型的精确率、 灵敏度及特异性分别为100%, 100%和100%。 并且, 2D-LDA和2D-PCA能够直接提取TSFS光谱图像矩阵在空间、 统计学以及图形学上的精细光谱特征, 为区分半潜油样本带来更为精准的鉴别依据。 因此, 相较于常规的基于展开或分解数据的方法, 高阶张量特征提取方法所建立鉴别模型所得到的预测结果更加精确。 该研究为半潜油种类鉴别提供了一种参考。
Submersible oil is a kind of oil spill hidden under the sea surface in a suspended state. It has poisoned and eroded the marine ecological environment for a long time. However, effective monitoring means and treatment methods have not been formed for submersible oil pollution, which makes its pollution more sudden and harmful than a sea oil spill. Therefore, it is of great significance to studying effective submersible oil identification methods to protect the marine ecological environment. The TSFS in three-dimensional fluorescence spectroscopy has the advantages of no Rayleigh scattering interference and less redundant data in detecting and identifying oil pollutants. The application of the multidimensional correction analysis method to TSFS data is limited because it does not have a trilinear structure. Thus, a new identification method for seawater submersible oil samples was proposed by combining TSFS with a high-order tensor feature extraction algorithm. First, 90 submersible samples were prepared by using organic dispersants and six different kinds of oil products. Then, the TSFS data of samples were collected using an FS920 fluorescence spectrometer, and the data were preprocessed by standardized. Finally, the identification models of submersible oil samples were established by 2D-LDA and 2D-PCA in the high-order tensor feature extraction method. The established model was compared with the identification model established by conventional MCR-ALS-LDA and NPLS-DA. The results show that the submersible oil sample identification models established by 2D-LDA and 2D-PCA have robust and reliable performance, and the accuracy, sensitivity and specificity of the identification models were 100%, 100% and 100%, respectively. In addition, the fine spectral features of the TSFS spectral image matrix in space, statistics, and graphics can be directly extracted by 2D-LDA and 2D-PCA, which brings a more accurate identification basis for distinguishing submersible oil samples. Therefore, compared with the conventional methods based on expansion or decomposition of data, the more accurate prediction results were obtained by the discrimination model established by the high-order tensor feature extraction method. This study provides a reference for submersible oil identification.
近年来, 随着陆上石油储量的不断减少, 海洋石油勘探与开发的步伐明显加快[1, 2]。 与此同时, 海上石油生产及其运输也随之增长, 导致各类溢油事故频繁发生[3]。 当事故发生后, 溢油不仅会在海面上漂浮, 还可能会在海中或海底等更深的水域中发生悬浮或者沉底。 其中, 悬浮状态的溢油称之为半潜油, 而沉底状态的溢油则称之为沉底油。 对于这些悬浮或沉底状态的溢油, 到目前为止还没有形成有效地监测手段和处理方式, 致使其污染的突发性和危害性更甚于海面溢油[4]。 相对于沉底油, 半潜油是一种更加广泛存在的状态, 且更容易随洋流在海中飘荡, 其对海洋生态环境造成的危害通常十分显著。 因此, 开展有效地半潜油探测与鉴别方法研究对于海事部门进行应急处理以及保护海洋生态环境具有重要的实用价值。
目前, 荧光光谱技术是检测与鉴别复杂环境背景中石油类污染物最有效地手段之一, 国内外研究人员主要通过激发-发射矩阵荧光光谱(excitation-emission matrix spectroscopy, EEMS)、 总同步荧光光谱(total synchronous fluorescence spectroscopy, TSFS)以及时间分辨荧光光谱(time-resolved fluorescence spectroscopy, TRFS)等三维光谱技术对石油类污染物进行信息采集与表征[5, 6]。 通常, 利用化学计量学中的多维校正方法可实现对三维荧光光谱数据特别是其中的EEMS数据矩阵的精确解析, 这种创新型的分析策略已经在溢油污染物组分定性及定量研究中得到了广泛的应用[7, 8]。 但是由于TSFS数据不具备三线性结构, 使得多维校正分析的策略在其应用上受到了一定的限制。
然而, TSFS能够以更少的数据量获取与EEMS相同的荧光信息, 还能避免瑞利散射的影响。 相较于EEMS, 在复杂多荧光团混合物表征中能够充分减少光谱重叠现象, 从而有效提高对复杂混合物的分析能力, 使其在溢油污染物的分析与鉴别中具备一定的优势[9]。 用于TSFS张量数据鉴别的常用方法是基于数据分解或展开的方法提取其光谱特征, 并结合模式识别中的分类方法以获得最终鉴别结果。 Kumar利用TSFS结合多元曲线分辨率交替最小二乘法(multivariate curve resolution-alternating least squares, MCR-ALS)对具有石油产品复杂荧光背景中的三种多环芳烃进行了分析, 获得了与实际情况较为一致的分析结果[10]。 Steiner-Browne等使用TSFS结合平行因子分析(parallel factor, PARAFAC)成功监测到了蛋白质结构变化过程中更多的组分[11]。 然而, 数据分解或展开的方法往往会破坏张量数据的原始空间结构及其相关性, 同时还会增加计算的复杂度[12]。 最近, 图像识别领域已经提出了用于高阶张量特征提取的方法[13, 14]。 此类方法能够在保留张量数据原始空间结构的前提下, 直接在矩阵的空间、 统计学以及图形学上提取相关特征向量, 进而有效降低其计算复杂度并显著提升特征向量的鉴别性能。 基于此, 本文采集了六种油类使用有机分散剂配制的90个半潜油样本的TSFS数据, 并基于高阶张量特征提取方法中的二维线性判别分析(2-dimensional linear discriminant analysis, 2D-LDA)以及二维主成分分析(2-dimensional principal component analysis, 2D-PCA)分别建立了样本的鉴别模型, 从而为半潜油种类鉴别提供了一种新的思路。
半潜油主要以分散油、 溶解油以及被颗粒物吸附后形成的油-悬浮物凝聚体等形态存在[4]。 化学分散剂能够加速海面溢油的降解进程, 是使海面溢油发生半潜的重要因素。 其中, 十二烷基硫酸钠(sodium dodecyl sulfate, SDS)是一种具有良好的乳化及分散功能的有机分散剂, 其能够有效降低溢油的粘度及其表面张力, 使溢油快速转化为不同粒径的油滴。
实验选用SDS分散剂配制半潜油样本, 海水取自渤海秦皇岛海域, 选择92#汽油、 95#汽油、 0#柴油、 润滑油、 航空煤油以及工业级白油六种油品作为实验样品。 半潜油样本的具体配制流程如下: 首先, 利用精密电子天平(FA1004, 精度: 0.000 1 g, 天津天马衡基仪器有限公司)称取适量的SDS并将其溶解在海水中, 配制浓度为0.1 mol· L-1的SDS溶剂; 然后, 称取适量的六种油品, 其实际重量如表1所示, 分别将其溶解在SDS溶剂中并使用100 mL容量瓶定容, 再置于往复式振荡器上震荡以模拟海洋环境中的风浪条件, 振荡频率选择120 r· min-1, 振荡时间为2 h, 以使油品能够充分地分散和溶解在海水中; 最后, 通过SDS溶剂进一步稀释已经充分溶解的油样, 分别配制浓度范围在0.2~3.0 mg· mL-1的15样本, 最终得到90个(6× 15)半潜油实验样本。
| 表1 六种油品的实际重量(单位/g) Table 1 Actual weight obtained of six oils (unit/g) |
使用FS920稳态荧光光谱仪(英国Edinburgh Instruments公司)采集实验样本的TSFS数据矩阵。 激发波长扫描范围设置为260~400 nm, 步长为2 nm; 偏移波长Δ λ 设置为10~110 nm, 激发和发射端的狭缝宽度设置为1.15 mm, 扫描的积分时间为0.1 s。
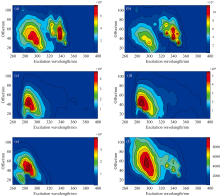
实验样本所获得的原始荧光光谱如图1所示, 其中, (a)是0#柴油, (b)是工业级白油, (c)是92#汽油, (d)是95#汽油, (e)是航空煤油, (f)是润滑油。 由图可知, 柴油和工业白油的荧光峰集中在激发波长为270~315和320~350 nm以及偏移波长为20~80和30~80 nm区域; 航空煤油的荧光峰集中在激发波长为265~300 nm以及偏移波长为10~70 nm区域; 92#汽油和95#汽油和的荧光峰集中在激发波长为275~320 nm以及偏移波长为20~80 nm区域; 润滑油的荧光峰集中在激发波长为270~320 nm以及偏移波长为20~90 nm区域, 这些区域的光谱主要归属于油类中所含的萘、 芴、 菲、 二苯并噻吩、䓛系列等多环芳烃组分。 另外, 还可以看出, 0#柴油与工业级白油的荧光峰的位置及其形状极为相似, 92#汽油与95#汽油的荧光峰的位置及其形状同样极为相似, 这种情况使得常规的鉴别方法面临极大的挑战, 仅仅依靠几种简单光谱特征通常很难取得理想的鉴别效果。 而张量特征提取方法能够直接提取光谱图像矩阵在空间、 统计学以及图形学上的精细光谱特征, 可以为区分样本带来更为精准的鉴别依据。
 | 图1 实验样本的原始荧光光谱图Fig.1 Original fluorescence spectrum of experimental samples |
在荧光光谱图中的相对荧光强度主要与样本浓度相关, 即在一定浓度范围内, 样本的浓度与其相对荧光强度呈线性关系, 而油类样本的类别主要与TSFS的光谱形状、 峰位等特征相关。 因此, 需要对TSFS数据进行标准化处理以消除高浓度样本所带来的杠杆效应, 即数据标准化的作用是指消除相对荧光强度(即样本浓度因素)带来的影响, 使不同样本之间具有可比性, 这对模型的构建至关重要。 另外, 为了合理评估所建模型的鉴别能力, 本文使用Kennard-Stone采样选择算法[15]将所有样本划分为训练集(共60个)与测试集(共30个)。 其中, 训练集样本用于构建训练模型, 而测试集样本则用于测试和验证所建模型的性能。
1.3.1 二维线性判别分析
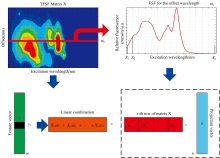
对于m× n的TSFS数据矩阵X, 行数(m)和列数(n)分别对应于激发和偏移波长的数量。 2D-LDA通过将X乘以投影矢量a(n× 1)来获得特征向量y(m× 1)
式(1)中, 特征向量y的第i分量yi由TSFS数据矩阵X的第i行mi与投影矢量a之间的标量积给出, 如图2所示。
 | 图2 从TSFS数据中计算2D-LDA特征向量的每个元素Fig.2 Calculation of each element of a 2D-LDA feature vector from TSFS data |
其中, 最佳投影矢量aopt可通过式(2)获得
式(2)中, SB和SW分别是类间与类内散度矩阵, 计算如式(3)和式(4)
式(3)和式(4)中,
$X_p=\frac{1}{N_p}\sum_{k∈I_p}X_k$(5)
$X=\frac{1}{N}\sum_{k=1}^{N}X_k$(6)
如果SW是非奇异矩阵, 则aopt需满足式(7)条件
式(7)中, λ 是
通常, 通过选择一组正交约束的投影向量{a1, a2, …, ar}作为投影矩阵A, 并以此计算TSFS数据矩阵X的特征矩阵Y(m× r)
1.3.2 二维主成分分析
与2D-LDA类似, 2D-PCA也是直接对TSFS数据矩阵X进行特征提取, 同样通过将X乘以投影矢量b(n× 1)来获得特征向量y(m× 1)
其中, 最佳投影矢量由式(10)标准确定
式(10)中, Sb是训练样本投影矢量的协方差矩阵, tr(Sb)表示Sb的迹, Sb计算如下
那么, tr(Sb)可表示为
图像的协方差矩阵(即散度矩阵)Gt定义如式(13)
那么, 式(10)可以转化为
式(14)中, b是一个酉向量, 这个标准又称为广义最大散度准则, 使该准则最大化的酉向量b称为最优投影轴。 通常, 需要选择一组正交约束且最大化准则J(b)的投影轴, 即
将该组投影轴排列为投影矩阵B, 然后通过投影矩阵B来计算TSFS数据矩阵X的特征矩阵Y(m× d)
1.3.3 鉴别方法
基于2D-LDA和2D-PCA可以获得USFS数据的特征矩阵Y, 根据测试集样本和训练集样本之间的相似性对其进行鉴别。 本文对文献[16]中的七种相似性度量测试后, 选用欧氏距离d(Ytest, Ytrain)评估样本之间的相似性
最后, 将测试样本分配给对应于最小距离的训练样本所属的类Cp, 即
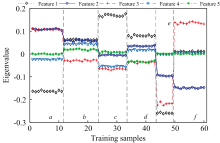
利用2D-LDA提取的不同类别的训练集样本平均特征如图3所示。 其中, 图3(a— f)分别是0#柴油、 工业级白油、 92#汽油、 95#汽油、 航空煤油以及润滑油的平均特征图。 图中横坐标代表在相应激发波长处的特征值, 纵坐标代表所提取的特征向量数量, 强度值则代表了特征值的大小。 由图可以看出, 不同类别样本的光谱特征主要集中在前5个特征向量中。 并且与其原始图像中的情况相同, 即本身光谱相似的图像其特征图中的主要特征依然相似, 但在特征图的细节特征以及强度值上则存在明显差异。
 | 图3 训练样本提取的2D-LDA特征Fig.3 2D-LDA features extracted from training samples |
利用2D-PCA提取不同类别训练集样本的前5个特征值如图4所示。 其中, 图4(a— f)分别是0#柴油、 航空煤油、 92#汽油、 95#汽油、 润滑油以及工业级白油的前5个特征值。 图中横坐标代表所有的训练集样本, 纵坐标代表所提取的特征值大小。 由图可以看出, 相同类别的训练集样本其5个特征值均稳定存在, 不同类别的训练集样本其5个特征值则差异较大, 这为样本分类鉴别提供了良好的特征基础。
 | 图4 训练样本提取的2D-PCA特征Fig.4 2D-PCA features extracted from training samples |
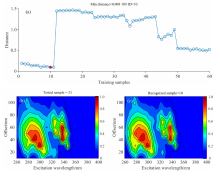
利用2D-LDA和2D-PCA分别提取测试集样本的相应特征。 然后, 根据测试集与训练集样本之间的相似性即欧氏距离来确定测试样本所属的类别, 基于2D-LDA特征的测试集中第21个样本的鉴定结果如图5所示。 其中, 图5(a)是测试中第21个样本与所有训练集样本之间的欧式距离, 可以看出该测试样本与训练集中前11个样本之间的距离均较小, 而在这些训练集样本中, 与第10个样本(ID=10)具有最小的欧式距离, 即Min Distance=0.098 189, 在图5(a)中用红色实心圆点标记。 其表示测试集中的第21个样本与训练集中的第10个样本之间的相似度最高, 属于同一类油品。 训练集中的第10个样本属于柴油如图5(c)所示, 所以测试集中的第21个样本被鉴定为柴油如图5(b)所示。 另外, 在图5(a)中1— 11为测试集中的0#柴油; 12— 23为测试集中的航空煤油; 24— 33为测试集中的92#汽油; 34— 43为测试集中的95#汽油; 44— 49为测试集中的润滑油以及50— 60为测试集中的工业级白油。 可以看出, 基于2D-LDA特征的测试集样本与同类训练集样本之间距离均较近, 即样本之间具有极高的相似度。 而与其他异类样本之间的距离均较远, 且与每一类样本之间的距离值较为稳定, 具有明显分界, 实验结果表明2D-LDA特征对TSFS光谱具有优异的表征能力。
 | 图5 测试集中第21个样本的鉴定结果Fig.5 Identification result of the 21st sample in the test set |
表2列出了基于2D-LDA与2D-PCA特征的测试集样本具体鉴定结果, 以混淆矩阵的形式表示。 被鉴定正确的测试集样本在表中绿色底纹标注, 从表中可以看出, 无论是基于2D-LDA特征还是基于2D-PCA特征均获得了理想的结果, 所有测试集样本都被鉴定为正确的类别所属。 实验结果表明基于高阶张量特征提取的方法不仅能够有效表征具有明显差异特征的样本, 而且在图像形状极为相似的样本中同样具有优异的性能。
| 表2 测试集样本获得的混淆矩阵 Table 2 Confusion matrix obtained for test set |
为了进一步比较高阶张量特征提取方法的性能, 本文分别使用了基于数据分解的方法— — MCR-ALS-LDA以及基于数据展开的方法— — 多维偏最小二乘判别分析(multi-way partial least square discriminant analysis, NPLS-DA)对TSFS数据中的训练集和测试集样本进行了分析。 其中, 使用奇异值分解确定MCR-ALS[10]的组分数为3, 并使用进化因子分析获得其初始估计值, 利用MCR-ALS解析结果中的得分矩阵作为LDA的鉴别依据, 最终获得的鉴别模型评价结果如表3所示。 通过交叉验证的方式确定NPLS-DA[17]的潜在变量数为9, 然后利用训练集样本计算NPLS-DA模型, 最后使用测试集样本评价模型的性能, 其评价结果列于表3。
| 表3 不同鉴别模型的评价结果 Table 3 Evaluation results of different identification models |
由表3可以看出, 本文所述的2D-LDA和2D-PCA模型均以100%的正确率获得了完美的性能表现, MCR-ALS-LDA模型以93.3%的正确率获得了良好的性能表现, 而NPLS-DA模型的正确率为66.7%, 其性能表现较差。 另外, 由精确率、 灵敏度和特异性三个评价指标可以看出, MCR-ALS-LDA模型在92#汽油、 95#汽油以及航空煤油三种油类鉴别中出现错误预测, 而NPLS-DA模型则在所有油类鉴别中均出现错误预测。 在MCR-ALS-LDA模型仅利用了MCR-ALS中的得分矩阵对油类进行鉴别, 而具有定性意义的载荷矩阵并没有被利用, 这可能是造成其性能不如2D-LDA和2D-PCA模型的原因。 而NPLS-DA模型同样仅利用了NPLS的主成分数进行分类, 且其解析结果并没有实际的化学意义, 这可能是造成其分类性能最差的原因。 这些评价结果表明了相较于2D-LDA和2D-PCA的特征提取方法以及基于MCR-ALS-LDA的分解方法, 基于NPLS-DA的展开类方法使用全部数据进行油种鉴别时的计算复杂度高且预测精度低。 基于特征提取或数据分解结果的油种鉴别获得更为精确的预测结果, 一方面表明了这些方法性能的优异, 另一方面也表明TSFS在半潜油检测中本身就具备一定的优势。
有效鉴别半潜油污染物对保护海洋生态环境具有重要意义。 本文采用了2D-LDA、 2D-PCA、 MCR-ALS-LDA及NPLS-DA四种方法分别建立了半潜油样本TSFS数据的鉴别模型。 实验结果表明, 2D-LDA 和 2D-PCA 可以有效提取TSFS数据的高阶张量特征, 所建立的鉴别模型能够对六种不同的油类进行准确鉴别, 其准确率均为100%。 本文为半潜油污染鉴别提供了一种新的思路。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|