
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于光谱结构特性的马铃薯干腐和疮痂病识别方法研究
[李鸿强1  , 孙红
, 孙红2 , 李民赞2, * ]
, 孙红]
|
|


作者简介: 李鸿强, 1979年生,河北建筑工程学院理学院副教授 e-mail: hqlgood@cau.edu.cn
马铃薯干腐病和疮痂病的检测通过人工目测, 结果存在主观性, 该工作研究正常、 干腐和疮痂病马铃薯的光谱分类识别方法。 试验获取116个样本, 光谱采集范围860~1 745 nm。 经过一阶导数(first derivative, FD)处理后的光谱数据, 主成分(PCA)分类识别效果较好, FD作为光谱预处理方法。 光谱曲线上的极值点、 极值点间的中点和极值点间连线的斜率决定光谱曲线的形状和变化, 是曲线上的关键点, 光谱曲线形状变化代表着内部物质的变化, 具有指纹特性, 利用极值点和中点对应的光谱或极值点间连线的斜率组成模式特征向量。 分别用3种样本关键点的平均光谱形成标准模式特征向量, 通过计算待测样本关键点组成的特征向量和标准模式特征向量之间的马氏距离, 以最小马氏距离判定样本的归属, 通过错误识别率检验模型识别性能。 正常、 干腐、 疮痂样本分别有13, 12, 15个关键点, 由各自关键点对应的反射率组成的模式特征向量, 3类样本的错误识别率为0。 去掉冗余关键点整合成一个标准模式特征向量, 正常和疮痂样本的错误识别率为0, 干腐样本的错误识别率为14.3%, 全部错误识别为疮痂样本, 特征向量数据点的增多, 增加了病害样本之间的贴合度, 降低了两类病害样本之间的区分度。 利用波长911, 1 269和1 455 nm处两点间的斜率形成模式特征向量, 正常和疮痂样本的错误识别率为0, 干腐样本的错误识别率为2.4%。 利用前2个主成分得分作为参数, 采用线性判别分析(LDA)和贝叶斯分类器(BC)建模, 提供不同角度的分类模型, 对比检验基于模式特征向量建立的分类模型的有效性, 2种识别方法的错误识别率均为0。 实验结果表明, 可以利用表征光谱曲线结构特征的模式特征向量作为分类参数, 结合距离法建模, 与常见识别方法具有同等识别精度。
At present, the detection of dry rot and potato scab was completed by manual visual inspection, and the detection results were subjective. This experiment studied the spectral detection method for classification and recognition of normal, dry rot and scab of potato. 116 potato samples were collected in the experiment, and the spectrum collection range was 860~1 745 nm. After the first derivative (FD) processing, the principal component analysis (PCA) classification recognition effect was better, and FD was used as the spectral preprocessing method. The shape of the spectral curve was determined by the extreme points on the spectral curve, the midpoint between the extreme points and the slope line between the extreme points. The shape change of the spectral curve represented the change of the internal substance and had fingerprint characteristics. The mode eigenvector was composed of the spectrum corresponding to the key points or the line slope between the extreme points. The average spectra of the key points of the three samples were used to form the standard pattern feature vectors. By calculating the Mahalanobis distance between the feature vectors composed of the key points of the tested samples and the standard pattern feature vectors, the minimum Mahalanobis distance was used to determine the attribution of the samples, and the error recognition rate tested the recognition performance of the model. There were 13, 12 and 15 key points in normal, dry rot and scab samples, respectively. The pattern feature vector was composed of the reflectance corresponding to each key point, and the error recognition rate of the three types of samples was zero. By removing redundant key points and integrating them into a standard pattern feature vector, the error recognition rate of normal and scab samples was zero, that of dry rot samples was 14.3%, and all were scab samples. The feature vector data points increase the fit degree between disease samples and reduces the discrimination between two types of disease samples. Using the slope between two points at the wavelength of 911, 1 269 and 1 455 nm to form the pattern feature vector, the error recognition rate of normal and scab samples was zero, and the error recognition rate of dry rot samples was 2.4%. Linear discriminant analysis (LDA) and Bayesian classifier (BC) were used to build the classification model by using the scores of the first two principal components as the parameters. Different classification models were provided. The effectiveness of the classification model based on the pattern feature vector was compared and verified. The error recognition rate of the two recognition methods was zero. The experimental results show that the pattern feature vectors representing the structural features of spectral curves could be used as the classification parameters, and the distance method could be used for modeling, which had the same recognition accuracy as the standard recognition methods.
马铃薯是世界第四粮食作物。 商品马铃薯贮藏期间, 易发生干腐病和疮痂病。 在国标《马铃薯商品薯分级与检测规程》[1]中, 干腐病和疮痂病是规定检测项目, 是商品薯重要定级依据。 目前, 干腐病和疮痂病的检测通过目测完成, 仿照人的检测过程, 机器视觉技术和光谱分析技术广泛用于马铃薯病害检测[2, 3]。
王鑫野[4]等基于特征波段反射率和主成分图像灰度值建立K最近邻分类算法、 BP神经网络、 决策树算法3种识别模型对不同时期马铃薯晚疫病进行识别, 基于二次主成分图像的灰度值结合BP神经网络建立的模型, 识别率达96.6%。 赵明富等[5]将主成分图像的平滑度、 三阶矩、 均值、 标准差、 一致性、 熵作为输入值, 建立了改进的贝叶斯分类器, 判别发芽、 腐烂、 表面碰伤、 机械损伤、 黑心以及合格马铃薯, 预测集的识别率为95%以上。
Liang等[6]试验表明近红外光谱是一种快速检测马铃薯斑纹病的方法, 分类准确率为96.7%。 Zhou等[7]研究了利用513~850nm可见光-近红外透射光谱技术结合偏最小二乘线性判别分析方法对黑心病马铃薯进行分类的可行性, 校准集的分类准确率可以达到96.82%, 验证集的分类准确率可以达到96.53%。 王丽艳等[8]选出7个特征波段, 建立全波段、 特征波段的SVM和BP人工神经网络模型, 紫色、 红色、 黄色马铃薯鉴别准确率达到100%。
实验证明, 机器视觉和光谱分析技术都是有效无损检测方法, 机器视觉技术相较光谱分析技术更加直观, 但是在面对同源(马铃薯)但不同种类疾病(干腐病, 疮痂病)的同时检测问题, 干腐病和疮痂病外观颜色相似, 病变区的物质成分不一样, 利用机器视觉技术, 难以确定缺陷的性质, 光谱分析技术的分析基础是物质成分或浓度的差异, 在无损检测马铃薯中更具优势。
利用近红外高光谱技术获取860~1 745 nm正常、 干腐和疮痂马铃薯样本光谱, 对正常、 干腐病和疮痂病马铃薯分类检测进行研究, 为高光谱分析技术用于马铃薯特定外部缺陷检测提供参考。
实验样本购于本地超市(正常46个, 干腐病42个, 疮痂病28个), 随机挑选样本的2/3构成建模集, 1/3构成验证集。 3类样本的样例分别如图1(a, b, c)所示。
 | 图1 正常(a)、 干腐(b)、 疮痂病(c)马铃薯样本Fig.1 Normal (a), dry rot (b) and scab (c) potatoes samples |
常温下, 将马铃薯清理干净并静置24 h。 使用“ 盖亚(Gaia Sorter)” 高光谱分选仪采集光谱数据, 光谱范围890~1 650 nm。
通过ENVI5.1软件提取感兴趣区域(region of interest, ROI), ROI大小为10× 10像素, 同区域获取5~6个ROI, 计算平均光谱作为原始反射光谱数据。
在反射光谱曲线上, 极大值点反映了该处光谱对物质的强反射, 极小限值点反映了该处光谱对物质的深度吸收, 相邻两个极值点间的中点限定了光谱曲线的变化趋势, 相邻极值点间连线的斜率反映了光谱对物质反射(吸收)的变化率。 极值点、 相邻极值点间的中点和斜率, 是反射光谱的“ 指纹” 特征。
利用极值点和中点对应的反射率, 相邻极值点间光谱的斜率可以组成模式特征向量。 3类样本极值点和中点处的平均光谱形成标准模式特征向量, 通过计算待测样本的模式特征向量与各标准模式特征向量的马氏距离, 以最小马氏距离判定待测样本的类别。
对去噪后的光谱数据进行主成分分析(principal component analysis, PCA), 利用主成分得分作为输入变量, 采用贝叶斯分类器[5](Bayesian classifier, BC)和线性判别识别分析[9, 10](linear discriminant analysis, LDA)方法进行分类识别。
使用错误识别率评判模型识别性能差异, 数值越小表示模型性能越好, 计算方法见式(1)。
所用距离为马氏距离, 计算方法见式(2)。
式(2)中, x为待测样本, G为样本总体, μ为样本均值, Σ 为样本集协方差矩阵, d为马氏距离。
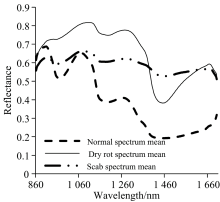
疮痂病, 干腐病和正常马铃薯样本的平均光谱如图2所示。
 | 图2 三类样本平均光谱Fig.2 Average spectra of normal, dry rot and scab potatoes |
在970和1 450 nm波段, 3类样本反射光谱均表现深吸收特性, 反射光谱出现极小值, 正常样本相较两类病变样本吸收强度更大, 970和1 450 nm波段是水O— H键第2倍频和水O— H键第1倍频吸收, 干腐和疮痂病的病变区域均表现为缺水变黑、 变干, 病变性质和反射光谱特征一致。 970 nm处, 疮痂病样本的反射光谱低于疮痂病样本, 1 450 nm处, 疮痂病样本的反射光谱高于干腐病样本, 两种病变存在区别。
疮痂病, 干腐病和正常马铃薯的反射光谱曲线, 起及转折走向相似, 可以理解为3类样本种源相似。 在相同波长处吸收程度不同, 由样本内在物质差异引起。
分别利用1阶导数[11], 多元散射[12]和标准正态变量变换[13]进行光谱预处理[14]。
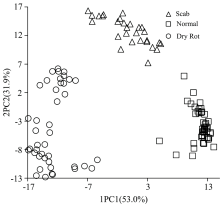
经过1阶导数处理的光谱, 经主成分分析后, 前两个主成分的累积贡献率为84.9%。 基于前2个主成分得分的样本散点图如图3所示, 3类样本可以通过第1, 2主成分得分线性分开, 1阶导数去噪处理效果优于多元散射和标准正态变量变换。
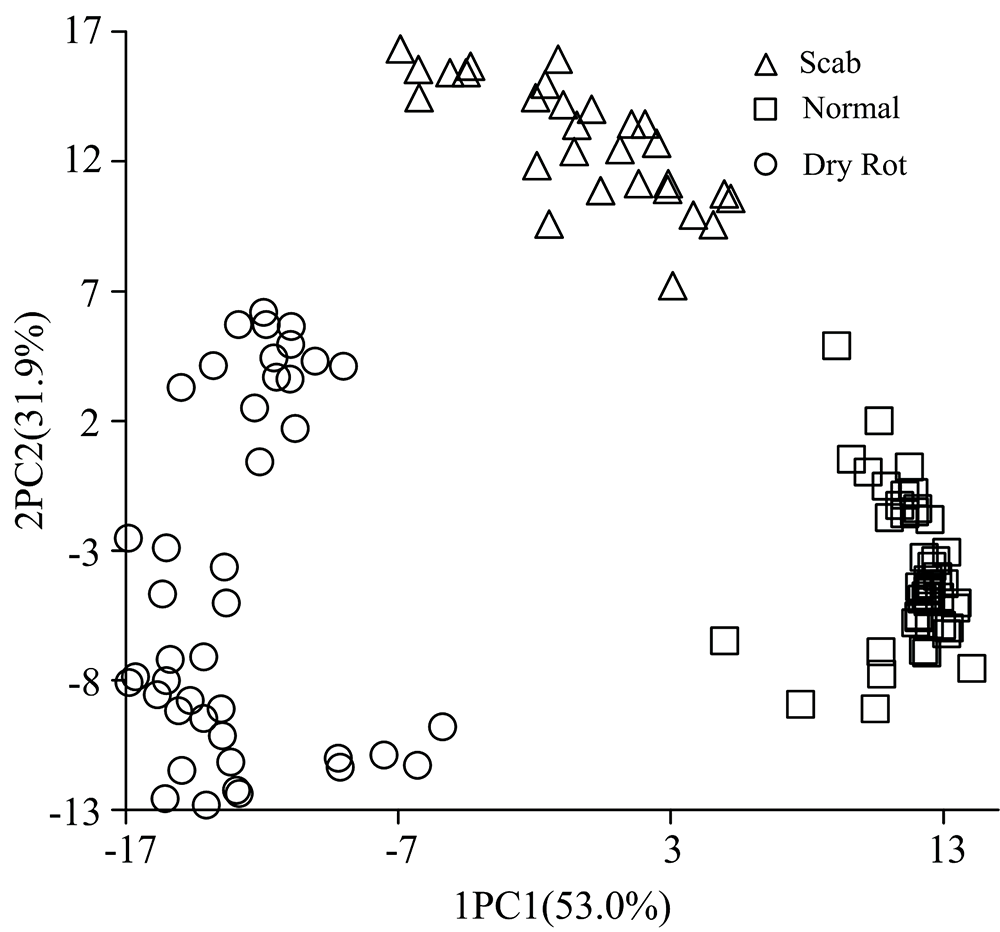 | 图3 前2个主成分样本散点图Fig.3 Top two principal component score map |
2.3.1 基于光谱曲线结构特征的识别分析
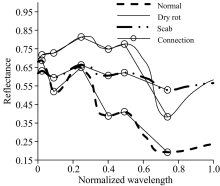
图4光谱曲线上圆圈标出的是三类样本的极值点, 3类样本的极值点波长位置相同, 只是物质浓度不同引起的反射(吸收)程度不一样。 同时, 极值点间, 3类样本的光谱变化趋势一致, 但是起伏程度不一样, 表现为极值点间的连线斜率不同, 从图上看到: 类似一条曲线, 沿着反射率坐标轴上下平移旋转得到另外2条曲线, 图中显示出一簇曲线中的3条。 “ 一簇曲线” 说明3类样本同种同源, “ 平移旋转” 是病变引起的物质含量变化。 极值点, 中点处的反射率, 极值点间连线的斜率是物质反射谱典型“ 指纹” 特征, 符合同物同谱规律。 干腐病, 疮痂病, 正常马铃薯光谱曲线上的极值点, 中点统计结果见表1。
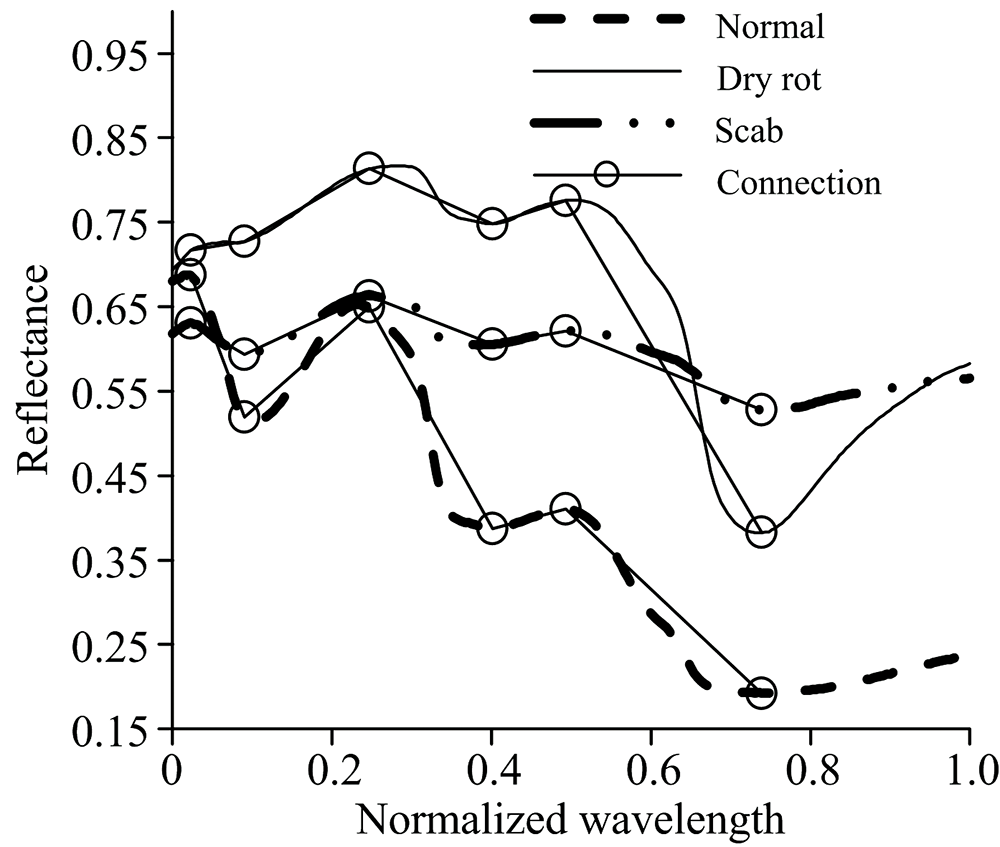 | 图4 光谱曲线上的极值点Fig.4 Extreme points of spectra |
| 表1 极值点、 中点对应波长统计结果 Table 1 The statistical results of wavelengths corresponding to extreme point and midpoint |
2.3.1.1 基于关键点光谱形成模式特征向量的识别方法
利用3种样本平均光谱关键点处的反射率, 形成3类样品的标准模式特征向量, 正常样本的向量长度为13, 干腐样本的向量长度为12, 疮痂样本的向量长度为15。 获取待测样本相应波长处的反射率, 计算待测样本与各模式向量之间的马氏距离, 以距离最小识别待测样本的所属类别。 3类样本的错误识别率均为0。 从识别正确率来看, 关键点处的反射率可以代表不同样本的特征。
将3种样本的平均光谱关键点处的反射率, 组合形成1个标准模式向量, 向量长度为31。 获取待测样本相应波长处的反射率, 计算待测样本与该标准模式向量之间的马氏距离, 以距离最小识别待测样本的所属类别。 正常样本的错误识别率均为0, 干腐样本的错误识别率是14.3%, 均被错误识别为疮痂样本, 疮痂样本的错误识别率为0。 向量长度为31的模式, 存在冗余数据, 由于数据点的增多, 增加了异类样本之间的贴合度, 缩小了两类病害样本之间的距离, 降低了两类病害样本之间的区分度。
设置从向量长度为31的模式中, 选定1到30个波长形成组合, 作为新模式向量, 统计结果见表2。 当向量长度小于5时, 没有相关组合能使3类样本的错误识别率达到0。 5个波长的组合中, 有2 269种组合使3类样本的错误识别率达到0。 5个波长组合, 各波长的被选情况见表2。 波长组合(911, 955, 962, 973), 以上波段包含有蛋白质C— H键第3倍频伸缩振动吸收、 水O— H键第2倍频伸缩振动吸收, 被选中百分比占到32.9%。 波长组合(1 068, 1 081, 1 108, 1 185, 1 199, 1 275, 1 282), 以上波长包含有机物质C— H键第2倍频伸缩振动吸收, 被选中百分比占到43.0%。 波长(1 452, 1 455, 1 500, 1 647)包含有淀粉、 水O— H键第1倍频伸缩振动吸收, 蛋白质N— H键第1倍频伸缩振动吸收, 被选中百分比占到24.1%, 曲线起始波段等其他16个波段没有被选择, 被选建模波长与样本蛋白质、 淀粉物质成分直接相关。
| 表2 5个波长选择统计结果 Table 2 Five wavelengths selection statistical results |
2.3.1.2 基于关键点间斜率组成模式特征向量的识别方法
3类样本的平均光谱, 其相同极值点对应波长为: 911, 962, 1 081, 1 199, 1 269和1 455 nm, 共计6处。 如图4中极值点连线(图中黑色细线)所示, 各类样本极值点间曲线的走向基本一致, 但是起伏程度不同。 计算相邻两点间连线的斜率(计算时将波长进行归一化, 消除量纲影响), 由斜率组成模式向量, 获取待测样本相应的斜率, 计算待测样本与各标准模式向量之间的马氏距离, 以距离最小识别待测样本的所属类别。 从6个波长中可以分别选择其中2, 3, 4, 5, 6个点组合, 分别有15, 20, 15, 6, 1种组合方式, 共有57种组合。
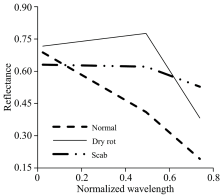
经统计, 3个波长的组合: 911, 1 269和1 455 nm, 是所有组合情况中识别错误率最低的组合, 正常样本的错误识别率为0, 干腐样本的错误识别率为2.4%, 有1个样本被识别为正常样本, 原因可能是病区较小或者病情较轻, 在选取感兴趣区域时, 圈入正常区域面积所占比例较大, 使得平均光谱更接近正常样本, 疮痂样本的错误识别率为0。 波长911 nm附近包含蛋白质C— H键的第3倍频伸缩振动吸收, 波长1 269 nm附近包含C— H键的第2倍频伸缩振动吸收, 波长1 455 nm附近包含淀粉和水的O— H键的第1倍频伸缩振动吸收。 如图5所示, 各类样本波形起伏程度不同, 反映的是内部物质的差异, 以上3点之间连线的斜率正好能反映出正常样本和病害样本, 以及两种病害样本之间的成分区别。
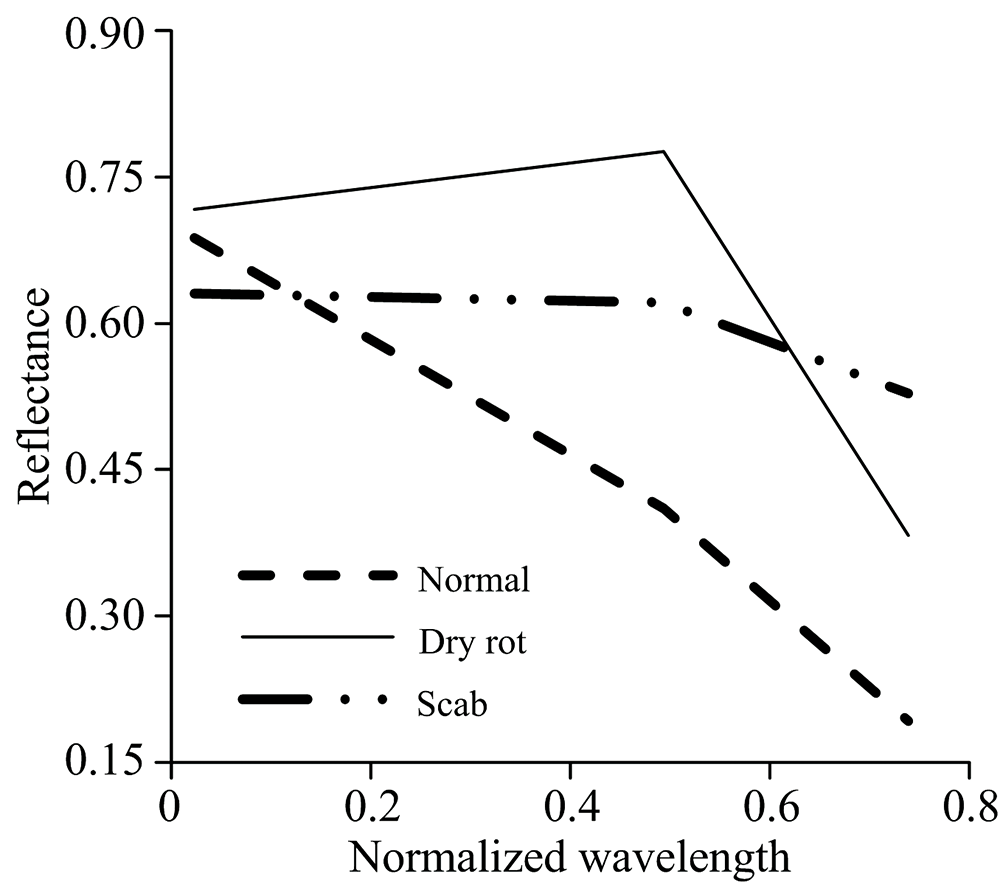 | 图5 波段911, 1 269和1 455 nm间光谱连线变化趋势Fig.5 The changing trend of interconnect between bands 911, 1 269 and 1 455 nm |
2.3.2 基于主成分的识别结果
利用前2个主成分作为输入变量, 识别结果如表3所示, 用LDA和BC识别方式错误识别率均为0%。
| 表3 基于主成分识别结果 Table 3 Results of discriminant based on PC1& PC2 |
通过采集正常、 干腐、 疮痂马铃薯高光谱, 利用光谱前两个主成分得分, 进行线性判别分析, 贝叶斯分类器进行分类识别。 利用表征光谱曲线形状的模式特征向量作为参数, 采用马氏距离对3种马铃薯识别建模。 获得以下主要结论:
(1)光谱曲线上的极值点和极值点间的中点, 这些关键点最能体现反射光谱的“ 指纹” 效应。 寻找3类样本平均光谱的关键点, 以平均光谱关键点对映的反射率形成标准模式向量, 通过计算待测样本对应向量与3个标准向量的马氏距离, 以最小距离判定待测样本的归属, 3类样本的错误识别率均为0。 统一3个标准向量的对应波长, 以最小马氏距离判定待测样本的归属, 由于数据整合, 不利于两类病害样本的识别, 干腐样本的错误识别率14.3%, 均被错误识别为疮痂样本。 对统一标准向量所含波段, 进行重新组合, 可以利用其中5个波段形成的模式向量, 对样本进行分类识别, 3类样本的错误识别率均能达到0。
(2)三类样本光谱曲线共有6个相同极值点, 极值点间曲线的走向基本一致, 但是不同样本起伏程度不同, 波形的起伏反映的是内部物质的变化, 相邻两点间连线的斜率可以体现这种变化。 可以利用波长(911, 1 269, 1 455 nm)处两点间的斜率形成的模式特征向量, 同样以最小马氏距离判定待测样本的归属, 正常和疮痂样本的错误识别率为0, 干腐样本的错误识别率为2.4%。
(3)利用表征光谱结构的模式特征进行识别, 使用较少数据, 即能降低识别模型的复杂度, 同时识别精度也有保障。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|