


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于机器学习的水体化学需氧量高光谱反演模型对比研究
[王春玲1, 2  , 史锴源
, 史锴源1, 2 , 明星3, * , 丛茂勤3 , 刘昕悦3 , 郭文记3 ]
, 史锴源, 丛茂勤|
|


作者简介: 王春玲,女, 1975年生,北京林业大学信息学院副教授 e-mail: wangchl@bjfu.edu.cn
化学需氧量(COD)是水体有机污染的一项重要指标, 如何快速准确检测水体的COD含量尤为重要。 机器学习在水质反演领域应用日益增多, 并取得了较多的研究成果, 高光谱遥感具有光谱空间分辨率高、 成像通道多等优势, 使其在水体COD反演方面有着极大的潜力。 利用不同的高光谱预处理方法对原始高光谱数据进行处理, 并利用处理前后的高光谱数据对比研究了不同机器学习模型、 不同高光谱预处理方法对水体COD的反演性能。 首先利用ZK-UVIR-I型原位光谱水质在线监测仪在扬州宝带河实地收集了1 548组COD和对应的高光谱数据(400~1 000 nm)样本, 为降低光谱噪音干扰以及消除光谱散射影响, 分别使用Savitzky-Golay(SG)平滑、 多元散射校正数据(MSC)以及SG平滑结合MSC对原始光谱进行预处理。 其次, 将样本集随机划分为训练集和测试集, 其中训练集占比80%, 测试集占比20%。 对预处理后的训练集全波段光谱基于线性回归、 随机森林(random forest)、 AdaBoost、 XGBoost四种机器学习方法建立COD高光谱反演模型, 并选取了决定系数(R2)、 均方根误差(RMSE)、 相对分析误差(RPD)三种指标在测试集数据中评估高光谱反演模型的精度。 结果表明, 随机森林、 AdaBoost、 XGBoost均优于线性回归, 无论光谱处理与否, 通过XGBoost建立的反演模型预测能力均为最佳, 其中使用XGBoost对经过SG平滑和MSC处理后的光谱数据进行建模的反演模型精度最高, 其R2达到0.92, RMSE为7.1 mg·L-1, RPD为3.4。 考虑到原始光谱可能存在冗余, 通过主成分分析法(PCA)对经过SG平滑和MSC处理后的光谱进行降维, 并选取累计贡献率达到95%的前十个主成分作为模型的输入变量。 通过XGBoost建立反演模型, 结果表明经过PCA后的反演模型不仅精度有所上升, RPD达到3.8, 而且模型的训练时间也由72 s缩短到2.9 s。 以上研究可为该水域及类似水域的高光谱水质反演模型的建立提供新的方法及思路。
Chemical oxygen demand (COD) is an important indicator of organic pollution in water. How to quickly and accurately test the COD content of water is particularly important. The application of machine learning in the field of water quality inversion is increasing, and more research results have been obtained. Hyperspectral remote sensing has the advantages of high spectral-spatial resolution and multiple imaging channels, so it has great potential in retrieving water’s COD. This study uses different hyperspectral pre-processing methods to process the original hyperspectral data. It uses the hyperspectral data before and after processing to compare the inversion performance of different machine learning models and different hyperspectral pre-processing methods on the COD content of water. Firstly, 1 548 groups of COD content and corresponding hyperspectral data (400~1 000 nm) samples were collected by ZK-UVIR-I in-situ spectral water quality on-line monitor in Baodai River. In order to reduce the interference of spectral noise and eliminate the influence of spectral scattering, Savitzky-Golay (SG) smoothing, Multiplicative scatter correction (MSC) and SG smoothing combined with MSC methods were used to pre-process the original spectra. Secondly, the sample set is randomly divided into training set and test set, where the training set accounts for 80% and the test set accounts for 20%. A COD hyperspectral inversion model based on the four machine learning methods of linear regression, random forest (random forest), AdaBoost, and XGBoost was established for the pre-processed training set full-band spectrum. Moreover, three indexes of determination coefficient (R2), root mean square error (RMSE) and relative analysis error (RPD) were selected to evaluate the accuracy of the hyperspectral inversion model. The results show that random forest, AdaBoost and XGboost are all the better than linear regression. The prediction ability of the inversion model established by XGboost is the best whether the spectral data is processed or not, withR2 of 0.92, RMSE of 7.1 mg·L-1, and RPD of 3.4. Considering that the original spectrum may be redundant, the dimensionality reduction of the spectrum after SG smoothing and MSC processing is performed by principal component analysis (PCA), and the top ten principal components with a cumulative contribution rate of 95% are selected as the input variables of the model. XGBoost established the inversion model, and the results show that after PCA, the accuracy of the inversion model is improved, the RPD is 3.8, and the training time of the model is shortened from 72 seconds to 2.9 seconds. The above research can provide new methods and ideas for establishing hyperspectral inversion models of this water area and similar water areas.
化学需氧量(chemical oxygen demand, COD)是以化学方法测量水样中需要被氧化的还原性物质的量。 水样在一定条件下的COD以氧化1升水样中还原性物质缩小化的氧化剂的量为指标, 折算成每升水样全部被氧化后, 需要的氧的毫克数, 以mg· L-1来表示。 COD测试可以很容易地量化水中有机物的含量。 COD最常见的应用是量化地表水(如湖泊和河流)或废水中可氧化污染物的量, 在水质监测中起到了巨大的作用。
传统的化学需氧量的检测方法有重铬酸盐滴定法和分光光度法等方法, 电化学方法和流动注射分析法也用于COD的检测, 但这些检测方法都存在检测周期较长、 消耗试剂等缺点, 对水体的批量检测也难以实现。 而利用高光谱技术和机器学习手段对水质参数进行反演近期已成为国内外热点研究问题。 高光谱技术能够获得物体连续的光谱信息, 近年来逐步应用于水农产品检测、 生物医学诊断和指导、 植被和水资源调控等领域并取得了一定成果[1, 2, 3, 4, 5]。 在水质参数高光谱反演建模中, 国内外学者采取机器学习方法对不同水质参数进行建模, 如总氮、 总磷、 水质浊度、 一般悬浮物、 化学需氧量等, 并取得了一定成果[6, 7, 8, 9, 10, 11, 12]。 尽管利用高光谱和机器学习手段对化学需氧量反演的研究逐步增多, 但是仍存在一定问题: 例如对高光谱数据的预处理手段不够完善, 导致数据集存在较多的噪音或者丢失波段信息, 所采用的机器学习方法拟合效果较差或机器学习模型过于复杂, 导致模型精度低或建模成本过大。
基于高光谱和机器学习技术对扬州宝带河水体COD进行反演建模。 分别使用Savitzky-Golay(SG)平滑、 多元散射校正数据(multiplicative scatter correction, MSC)以及SG平滑和MSC相结合的方法对原始光谱进行预处理。 对预处理后的全波段光谱基于多元线性回归、 随机森林、 AdaBoost、 XGBoost机器学习方法建立COD反演模型。 结合主成分分析法(principal component analysis, PCA)对全波段光谱提取特征波段, 再基于特征波段建立COD反演模型, 并对模型的精度和训练时间进行对比。
研究区位于江苏省扬州市宝带河水域(119° 25'27″E, 32° 24'13″N)。 研究采用ZK-UVIR-I型原位光谱水质在线监测仪(北京智科远达数据技术有限公司), 该监测仪能够实时检测水体化学需氧量信息, 并能够采集样本在400~1 000 nm之间的高光谱数据, 采集高度为3 m, 采集位置位于河岸边, 采集时间选在晴朗的白天。 由于光谱在810~1 000 nm范围内受噪声影响较大, 最终选用400~810 nm波段对光谱数据进行处理分析。 该设备共获取1 548组高光谱。 使用随机抽样的方法对采样样本进行划分, 80%用作模型训练, 20%用作模型测试。
数据处理使用windows10(64位操作系统), Intel(R)Core(TM) i5-7200U CPU @2.50GHZ处理器, python3.6。
1.2.1 光谱数据预处理
高光谱数据通常包含由相机或仪器产生的随机噪声和光谱变化。 光谱预处理可以减少或消除数据中与自身性质无关的信息, 降低模型的复杂性, 提高数据和模型的可解释性(鲁棒性和准确性)。 光谱数据的预处理在进行多变量分析之前是必不可少的。 SG平滑能够使光谱曲线平滑, MSC方法能够消除基线漂移和平移现象。 采用SG平滑、 MSC以及SG平滑结合MSC光谱预处理手段对原始光谱进行预处理并进行比较。
1.2.2 特征波段提取
高光谱波段由大量的波段组成, 有些波段的相关性较高而且存在冗余以及噪声等。 对特征波段的提取在一定程度上可以规避这两种情况。 PCA是一种分析、 简化数据集的方法[13], 能够最大程度提取原始数据的有效信息, 同时能够大大降低数据集维数。 选用主成分分析法对特征波段进行提取, 并对所建模型的精度、 模型训练速度进行分析比较。
1.2.3 反演模型
选取线性回归、 随机森林、 AdaBoost、 XGBoost四种机器学习建模方法。 线性回归是一种确定两个或多个变量间相互依赖定量关系的机器学习方法; 随机森林算法是决策树的集成, 通过平均决策树可以大大降低过拟合的风险, 是比单一决策树性能更优的模型[14]; Adaboost是将弱学习器结合创造一个强学习器的机器学习方法[15], 本研究将决策树作为Adaboost的弱学习器; XGBoost是一种改进的梯度提升迭代决策树(gradient boosting decision tree, GBDT)算法, 基于损失函数2阶泰勒展开进行优化并引入正则项, 同时支持多线程运算。
1.2.4 模型评估
采取RMSE, R2和RPD三个指标对反演模型进行对比和评价。
式(1)中, n为样本量,
式(2)中, yi为真实值,
式(3)中, SD为标准差,
图1为样本水体的原始光谱曲线, 水体在550~600 nm的反射率较高, 在700~750 nm的反射率较低。 从图中可以看出每个水体样本曲线的变化趋势类似, 没有呈现较大的差异, 而且难以直接通过光谱曲线对其COD含量进行判断。 水体样本的COD值统计结果如表1所示, 模型的训练集与测试集都涵盖了较大的范围, 各标准差与总样本的标准差也基本一致, 满足训练以及检验的需求。
 | 图1 水体样本原始光谱反射率曲线Fig.1 The original spectral reflectance curve of water samples |
| 表1 COD含量描述统计分析 Table 1 Results of chemical oxgen demand (COD) statictical value of samples |
使用三种光谱预处理方法对原始光谱进行预处理, 预处理后的光谱分布如图2(a, b, c)所示。
 | 图2 水体样本预处理后的光谱分布 (a): SG smoothing; (b): MSC; (c): SG smoothing结合MSCFig.2 Spectral profiles of water samples after preprocess (a): SG smoothing; (b): MSC; (c): SG smoothing and MSC |
经过光谱预处理后, 高光谱的数据质量得到了一定改善, 但还是无法直观的从光谱曲线上判断水体的COD含量, 因此还需要通过机器学习方法对其建模进行分析。
2.3.1 机器学习模型超参数调整
在机器学习中, 超参数是在开始学习过程之前设置值的参数。 决策树的数量直接决定了随机森林、 Adaboost、 XGBoost模型的性能, 以5作为步长设定决策树的数量并对上述三个模型进行训练, 通过观察训练集均方误差(mean-square error, MSE)随决策树的数量变化调整模型的决策树数量, 最终结果如图3(a, b, c)所示。 由于随机森林模型具有随机性, 所以决策树增加时, 模型的预测性能会出现波动, 在考虑模型性能以及模型运行时间因素后, 将随机森林的决策树的数量设为175, AdaBoost的决策树数量设为200, XGBoost决策树数量设为350。
 | 图3 机器学习模型中决策树数量与模型在训练集上的MSE的关系 (a): 随机森林模型; (b): Adaboost模型; (c): XGBoost模型Fig.3 Relationship between the number of decision trees and model MSE on training sample (a): Random forest; (b): Adaboost; (c): XGBoost |
2.3.2 反演模型精度及对比
对原始光谱数据和三种不同的预处理方法分别使用四种机器学习模型建模。 模型的反演精度与建模的训练时间如表2— 表5所示。
| 表2 基于原始数据机器学习模型结果 Table 2 The results of machine learning model based on orginal data |
| 表3 基于SG平滑预处理机器学习模型结果 Table 3 The results of machine learning model based on data processed by SG smoothing |
| 表4 基于MSC预处理机器学习模型结果 Table 4 The results of machine learning model based on data processed by MSC |
| 表5 基于SG平滑和MSC预处理机器学习模型结果 Table 5 The results of machine learning model based on data processed by SG smoothing and MSC |
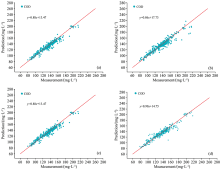
由表2— 表5中数据可以看到, XGBoost在原始光谱以及三种经过预处理数据上的建模精度均优于其他模型, 且训练时间小于随机森林模型以及Adaboost模型。 线性回归所建的反演模型表现较差, 说明COD与光谱数据并没有直接的线性关系。 在所有的模型中, 通过XGBooost对经过SG平滑和MSC处理的数据所建的反演模型精度最高, 其中R2为0.92, RMSE为7.1 mg· L-1, RPD为3.4。 通过不同预处理方式所得的XGBoost反演模型散点图如图4(a— d)所示。
 | 图4 不同预处理方法下XGBoost反演模型COD预测值与实测值关系散点图 (a): 原始数据; (b): MSC处理; (c): SG平滑处理; (d): SG平滑结合MSCFig.4 Sccetterplots of XGBoost inversion model based on different preprocessing methods (a): Original data; (b): MSC; (c): SG smoothing; (d): SG smoothing and MSC |
2.4.1 PCA提取特征波段
利用主成分分析法(PCA)对经过SG平滑以及MSC处理的高光谱数据进行特征提取。 图5为前10个主成分的方差贡献率, 其中前五个主成分的累计方差贡献率已经达到95%以上, 包含了原始波段的大多数信息。 最终, 为保证尽可能多地保留原始高光谱信息, 选取了前十个主成分作为特征变量用于后续的建模及预测。
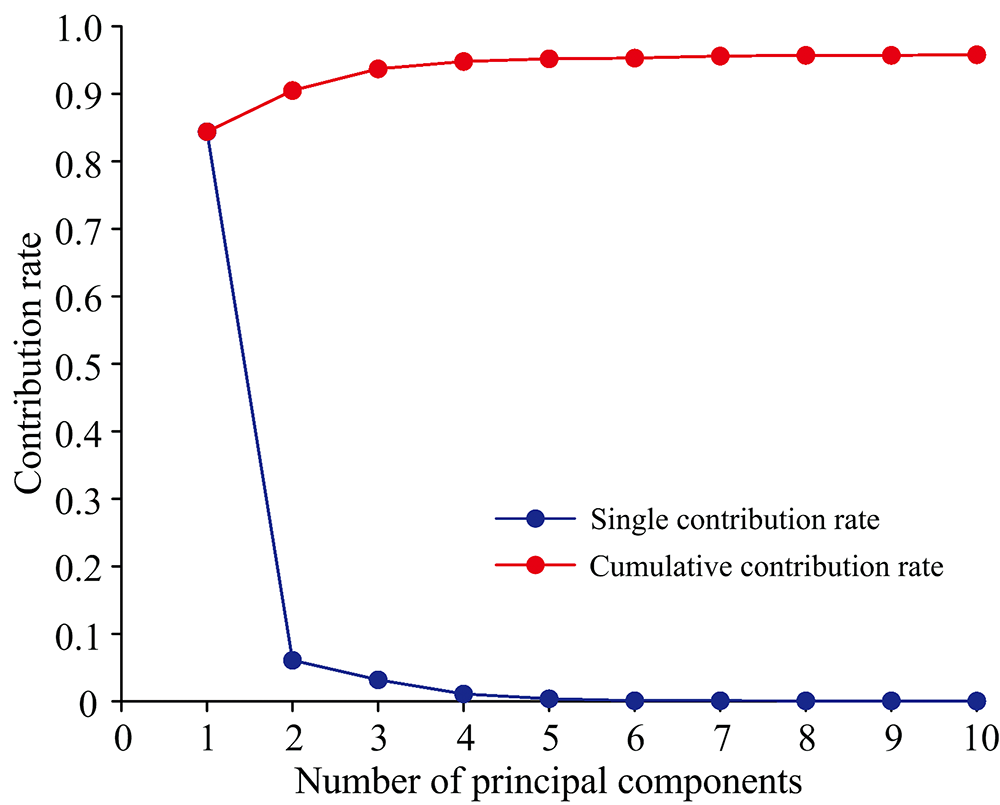 | 图5 利用PCA方法得到的前十个主成分的方差贡献率Fig.5 The variancecontribution rate of the first ten principal components about PCA |
2.4.2 基于特征波段的建模分析
基于XGBoost机器学习方法对特征波段建立COD反演模型, 并在测试集进行验证, 模型的精度以及模型训练时间见表6。
| 表6 基于PCA方法XGBoost模型的结果 Table 6 The result of the XGBoost model built based on the PCA method |
由表6中可以看出, 在XGBoost模型中经过PCA进行特征波段提取所建的反演模型精度高于全波段所建的反演模型, 且大大缩短了训练时间, 说明经过PCA进行波段特征提取能够一定程度上降低数据冗余。
以扬州宝带河COD为研究对象, 利用ZK-UVIR-I型原位光谱水质在线监测仪获取COD的高光谱数据及对应浓度数值, 分别采用SG平滑、 MSC以及SG平滑和MSC组合的方式对原始高光谱数据进行预处理, 并使用四种机器学习算法(线性回归模型、 随机森林模型、 AdaBoost模型、 XGBoost)建立COD反演模型。 比较了不同预处理方法和机器学习模型COD反演模型精度的影响。 基于R2, RMSE和RPD比较了这几种模型的精度, 此外还比较了各个模型的训练时间。 结果显示, 线性回归模型训练时间最短但是精度也最低。 XGBoost方法所建的反演模型精度, 最高RPD达到3.4。 XGBoost训练时间也少于随机森林和Adaboost模型。 通过PCA方式对经过SG平滑和MSC预处理后的全波段数据进行特征提取, 所提取的特征波段数为10, 最后对这10个特征波段使用XGBoost进行建模并取得了较好的效果, 而且特征波段训练时间远远低于全波段训练时间。 在实际生产过程中也可根据实际需求, 综合考虑模型精度、 模型训练时间等因素进行模型的选择。
研究结果表明, 基于机器学习的高光谱COD反演模型精度可以达到较高水平, 为机器学习在高光谱水质监测领域的应用提供了参考。 此外, 机器学习模型可解释性需要进一步研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|