
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
透射光谱的水体亚硝酸盐含量模拟估算
[王彩玲1  , 王波
, 王波2 , 纪童3 , 徐君4 , 剧锋5 , 王洪伟6, * ]
, 王波]
|
|


作者简介: 王彩玲, 女, 1984年生, 西安石油大学计算机学院副教授 e-mail: azering@163.com
亚硝酸盐是水体中重要的必测指标之一, 对于水体质量的评估有着重要意义。 但传统的检测方法操作复杂、 受干扰因素多、 测定时间长、 不能及时反映水质变化、 无法及时有效地预警突发水污染事件。 鉴于此, 探索准确、 实时、 环保的环境水体和饮用水中的亚硝酸盐含量检测办法具有重要意义。 采用优级纯试剂配制10种浓度的亚硝酸盐氮标准溶液(0.02, 0.04, 0.06, 0.08, 0.10, 0.12, 0.14, 0.16, 0.18和0.20 mg·L-1), 采用OCEAN-HDX-XR微型光纤光谱仪扫描10次各浓度亚硝酸盐溶液在181.1~1 023.1 nm范围内的透射光谱, 取平均值作为各浓度亚硝酸盐溶液原始透射光谱, 之后以亚硝酸盐含量作为因变量, 全波段原始透射光谱作为自变量, 采用随机森林回归中特征变量重要性方法, 筛选特征变量, 再此基础上利用交叉验证法, 挑选最为稳定的模型变量个数, 建立亚硝酸盐优化随机森林反演模型。 结果如下: (1)利用全波段建立的随机森林模变量解释率(var explained)=76.49%, 均方残差(mean of squared residuals)=0.000 688; (2)随机森林变量重要性方法筛选对亚硝酸盐反演的敏感波段, 其中195.1 nm重要性值最高, 并利用留一交叉法发现, 当利用19个光谱特征变量时随机森林模型的均方根误差最低, 以筛选光谱特征变量建立的优化随机森林变量解释率(var explained)=83.45%, 均方残差(mean of squared residuals)=0.000 552。 变量筛选有效减少了光谱数据量, 对优化模型的建立提供了基础; (3)对建立模型进行模型检验, 其中全波段随机森林模型测试集 R2=0.820 3, RMSE=0.03, 检验集 R2=0.979 3, RMSE=0.01, 优化随机森林模型测试集 R2=0.873 4, RMSE=0.022, 检验集 R2=0.979 8, RMSE=0.008, 对比全波段随机森林模型与优化后随机森林模型后发现, 优化随机森林模型测试集与检验集模型解释度、 模型精度均要高于全波段随机森林模型, 说明优化方法不仅可有效降低光谱维度, 对于寻找亚硝酸盐光谱敏感波段, 建立精度较高的亚硝酸盐反演模型有着积极意义。 基于以上试验结果, 提出了一种优化随机森林模型高光谱水质亚硝酸盐参数的反演方法, 为水质亚硝酸盐参数动态检测提供了新方法。
NO2-N is an important parameter in water bodies and can quickly detect organic pollution parameters. It is of great significance to the assessment of water quality. However, traditional methods are complicated in operation, subject to many interference factors, long measurement time, cannot reflect water quality changes in time, and cannot provide timely and effective early warning. For sudden water pollution incidents, because of the shortcomings of traditional methods, it is of great significance to explore accurate, real-time, and environmentally friendly detection methods for the NO2-N content in environmental water bodies and drinking water. This experiment is to study the use of superior grade pure reagents to prepare 10 concentrations of NO2-N nitrogen standard solutions (0.02, 0.04, 0.06, 0.08, 0.1, 0.12, 0.14, 0.16, 0.18 and 0.2 mg·L-1), using the OCEAN-HDX-XR micro-fiber spectrometer to scan 10 times the transmission spectrum of the NO2-N solution of each concentration in the range of 181.1~1 023.1 nm. Take the average value as the original transmission spectrum of the NO2-N solution of each concentration, and then take the NO2-N content of the solution as the dependent variable and the original transmission spectrum as the independent variable. Use the method of variable feature importance in random forest regression to screen the feature variables. Based on the cross-validation method, the number of the most stable model variables is selected, and the NO2-N optimization random forest inversion model is established. The results of the study are as follows: (1) The variable explained rate (Var Explained) of the random forest model established by the whole band (Var Explained)=76.49%, and the mean squared residuals (Mean of squared residuals)=0.000 688; In the sensitive band of salt inversion, 195.1 nm has the highest importance value, and the leave-one-out crossover method is used to find that the random forest model has the lowest root mean square error when 19 spectral characteristic variables are used to screen the optimized random forest established by spectral characteristic variables Variable Explained rate (Var Explained)=83.45%, Mean of squared residuals (Mean of squared residuals)=0.000 552. Variable screening effectively reduces the amount of spectral data and provides a basis for the establishment of the optimization model; (3) Model verification of the established model, including the full-band random forest model test set R2=0.820 3, RMSE=0.03, test set R2=0.979 3, RMSE=0.01, optimized random forest model test set R2=0.873 4, RMSE=0.022, test set R2=0.979 8, RMSE=0.008, after comparing the full-band random forest model with the optimized random forest model, it is found that the optimized random forest model test set and test The interpretation and accuracy of the set model are higher than the full-band random forest model, indicating that the optimization method can not only effectively reduce the spectral dimension, but also has positive significance for finding the sensitive band of NO2-N spectrum and establishing a high-precision NO2-N inversion model. . Based on the above test results, an inversion method for optimizing the hyperspectral water quality NO2-N parameters of the random forest model is proposed, which provides a new method for the dynamic detection of water quality NO2-N parameters.
随着人类物质生活水平的提高和工业化的发展, 水污染已经成为当今社会普遍存在的问题, 其监测与治理也备受关注。 在pH< 6.5时亚硝酸盐会与仲氨反映生成具有强致癌性的亚硝胺基, 是水质监测的必测指标之一[1]。 “ 分光光度计法” 、 紫外-分光光度法为现下普遍接受的测定亚硝酸盐指标的方法, 但测定时间长、 不能及时反映水质变化, 不适合现场监测[2]。
原始光谱反射数据有着数据量大, 指标彼此高度相关的特性, 原始指标高度相关的特性经常会导致多重共线性问题的产生, 从而导致模型失真[3]; 因此如何对大量光谱数据进行处理和挑选一直是光谱反演的重点。 随机森林(random forest, RF)作为常用机器学习算法在分类、 指标反演、 筛选指标上应用广泛[4], 国内许多学者将随机森林等机器学习新方法作为典型计量模型的代表广泛应用到水质预测领域, 促进水质分析向多参数测试趋势发展。 张颖等[5]利用随机森林分类算法对巢湖区域水质进行类别判定, 监测断面水质分类准确率可达96.15%; 吴志明等[6]基于随机森林对太湖湖泊水体有色可溶性有机物(CDOM)浓度进行遥感估算, 根据随机森林算法的特征重要性参数提供的各自变量影响力结果, 发现709和560 nm波段贡献率最大, 是反演CDOM的敏感波段, 并建立了精度较高的随机森林反演模型;
现有文献报道中, 利用透射光谱估测水质参数亚硝酸盐指标的报道较少; 基于此, 试验利用光谱数据进行水体指标亚硝酸盐的反演, 测定水体样本的光谱数据, 将采集到的光谱数据与标液亚硝酸盐含量建立亚硝酸盐随机森林反演模型, 由于光谱指标之间的高度相关, 为避免模型失真, 在建立反演模型之前, 利用随机森林变量重要性法挑选敏感光谱指标, 并将筛选指标利用留一交叉法进一步筛选, 最终利用筛选的变量组合建立亚硝酸盐随机森林反演模型, 比较全波段(未筛选)与优化(筛选变量)随机森林模型精度, 选出更加适合反演亚硝酸盐指标的建模方法。 探索利用高光谱估测水体亚硝酸盐含量的可行性与最优方法, 为实时诊断水体状况提供关键技术与可行的途径。
称取在105~110 ℃下烘干约4 h的亚硝酸钠(NaNO2)0.492 8 g溶于水, 准确定容至1 000 mL, 此溶液含NO2-N 100 mg· L-1。 实验前, 用移液管吸取此溶液20.00 mL用水稀释至1 000 mL, 此溶液含NO2-N 0.2 mg· L-1。 用此方法配制0.02, 0.04, 0.06, 0.08, 0.10, 0.12, 0.14, 0.16, 0.18和0.20 mg· L-1的亚硝酸盐标液[7]。
试验用仪器为Ocean Optics公司出品的OCEAN-HDX-XR微型光纤光谱仪, 该光谱仪采用高清晰度光学系统, 具有高通量、 低杂散光和高热稳定性的特点, 适用于精确测量溶液中的分析物, 具有体积小, 容易集成到许多工业应用的生产过程环境的优势。 仪器参数见表1。
| 表1 光谱仪参数 Table 1 Spectrometer parameters |
样品为0.02, 0.04, 0.06, 0.08, 0.10, 0.12, 0.14, 0.16, 0.18和0.20 mg· L-1的亚硝酸盐标液, 光谱仪狭缝为10 μ m, 相同时间间隔重复采集十次上述标液181.1~1 030.1 nm范围内的高光谱透射率数据, 共计得到100条光谱数据。
采用白板校正分别得到所采集的高光谱数据的光谱透射率值[8], 如式(1)所示
式(1)中: TC为光谱透射率, TO为原始光谱数据, TW为白板数据。
随机森林(RF)算法[9]结构清晰、 易于解释、 运行效率高, 对于数据要求低, 且具有很好的抗噪声能力, 能够处理高维度数据, 训练速度快, 泛化能力强, 比较容易实现并行计算, 不易出现过拟合问题。 随机森林模型的建立通过调用R语言中“ randomForest” 程序包[10]来实现。 该方法首先完成两个随机采样过程, 即通过自助法重采样技术有放回的在100组训练数据中重复随机抽取67个训练样本(总样本容量的三分之二), 未被抽取到的数据被称为“ 袋外” (outofbag)数据。
随机森林模型建立时有两个重要参量[11], 分别为随机森林决策树数目(mtry)与指定节点中用于二叉树的变量个数(ntree), 其中mtry一般取值为变量的二次方根, ntree的取值需要逐一尝试, 当模型内误差稳定时, 即为ntree数值。
模型评价方面, 通过计算解释方差百分比(%Var explained)与模型拟合精度(R2)来评定模型稳定能力与预测能力。
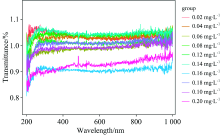
图1为10种浓度亚硝酸盐原始透射光谱, 从图中可以看出不同浓度溶液的亚硝酸盐光谱曲线的趋势类似, 在紫外波段180.1~400 nm亚硝酸盐光谱曲线呈先下降后上升的趋势, 光谱曲线波谷分布于185~197 nm范围内, 且谱线均在在紫外短波段有强吸收, 图中在210 nm波长周围处有极大的吸收峰, 浓度不同峰的高度也有所不同, 主要表现为随着亚硝酸盐含量的增加, 亚硝酸盐在各波段的光谱透射率逐渐降低。
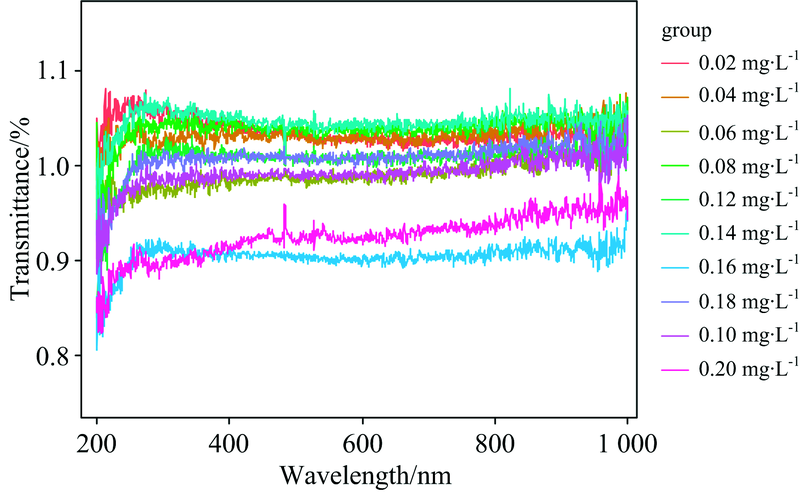 | 图1 原始透射光谱图Fig.1 Original transmission spectra |
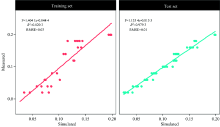
原始光谱共有2 049个变量, 对所有光谱变量进行随机森林建模, 其中参数ntree设定为500, mytry设定为40, 随机森林反演模型参数见表2, 其中残差平方均值为0.000 69, 变量解释率为76.49%。 拟合结果见图2训练集(train), 其中拟合精度(R2)为0.820 3, 均方根误差为0.03, 说明随机森林模型对于水体亚硝酸盐含量能够做出很好的预测。
| 表2 随机森林模型参数 Table 2 Spectrometer parameters |
 | 图2 全波段随机森林模型在测试集与训练集的预测结果Fig.2 The prediction results of the test set and training set using the full-band random forest model |
利用测试集test, 对建立的随机森林模型进行模型检验, 检验结果见图2, 通过对预测值与真实值进行线性拟合, 进行模型检验, R2=0.979 3, RMSE=0.01, 说明建立的随机森林模型有着很强的预测能力。
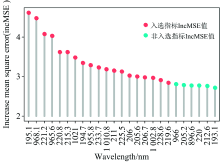
原始光谱数据量繁杂, 变量间存在多重共线性问题, 研究亚硝酸盐光谱敏感波段, 对于分析水体亚硝酸盐光谱特征, 降低光谱冗余, 以及提升模型精度有着重要意义。 随机森林算法中变量重要性算法, 可以分析各个自变量对因变量的影响程度, 以方差增量(IncMSE)指标来定性表征[12]。 方差增量指将某一变量替换成随机变量后对预测结果造成的影响, 若用于替换的随机变量显著改变了方差, 则认为原变量重要性很高。 在建立全波段随机森林模型过程中得出的随机森林变量重要性结果如图3所示; 25个光谱变量(IncMSE≥ 3)中195.1 nm变量重要性最高, IncMSE值为4.6, 说明195.1 nm波段对反演水体亚硝酸盐含量有着重要作用。
 | 图3 随机森林变量重要性(IncMSE)图Fig.3 Random forest variable importance (IncMSE) graph |
按照变量重要性大小, 将指标由大到小依次输入随机森林模型, 并采用交叉验证方法比较输入不同变量时模型均方误差的大小, 结果如图4所示, 发现模型输入变量为19个时, 模型均方误差值最低(RMSE=0.02), 且随变量数增多, 模型均方误差趋于稳定, 故选用筛选出的19个光谱变量作为优化随机森林模型的初始变量。
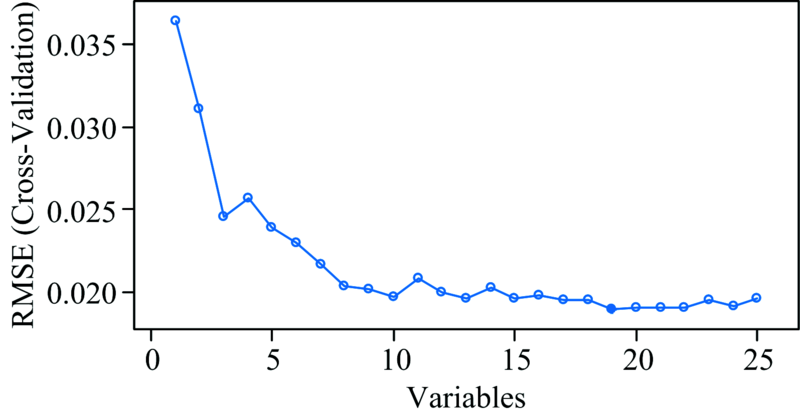 | 图4 交叉验证Fig.4 Cross-validation |
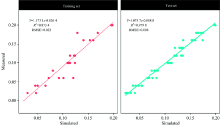
利用筛选出的19个光谱变量进行随机森林建模, 其中参数ntree设定为500, 因参与建模的光谱变量仅有19个, 因此mytry设定为4, 随机森林反演模型参数见表3, 其中残差平方均值为0.000 55, 变量解释率为83.45%, 拟合结果见图5训练集(training set), 其中拟合精度(R2)为0.873 4, 均方根误差(RMSE)为0.022, 说明优化随机森林模型对于水体亚硝酸盐含量能够做出很好的预测。
| 表3 优化随机森林模型参数 Table 3 Optimize random forest model parameters |
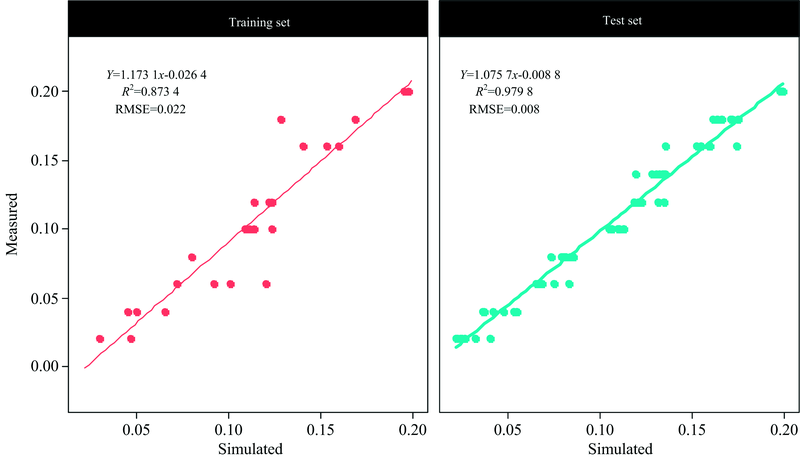 | 图5 优化随机森林模型在测试集与训练集的预测结果Fig.5 The prediction results of the test set and training set of the random forest model |
利用袋测试集test, 对建立的随机森林模型进行模型检验, 检验结果见图5, 通过对预测值与真实值进行线性拟合, 进行模型检验, R2=0.9798, RMSE=0.008, 说明建立的随机森林模型有着很强的预测能力。
物质的光谱强度与物质的组成成分和性质之间存在一定的联系, 从而可以建立光谱强度与样品含量之间的关系模型。 基于透射光谱研究水体亚硝酸盐含量的研究较少, 多在紫外吸收光谱中研究, 其中硝酸盐氮(NO3-N)的紫外吸收峰在202.0 nm左右, 而亚硝酸盐氮(NO2-N)的紫外吸收峰在210 nm左右[7]。 在建立全波段随机森林模型时, 利用随机森林变量重要性得出191.5, 968.1和221.2 nm等19个重要性较高变量, 得出的波段与亚硝酸盐氮(NO2-N)的紫外吸收峰210nm结果相近。
利用一种优化后的随机森林模型方法进行水体亚硝酸盐指标的反演, 通过随机森林变量重要性法筛选的光谱指标, 并利用交叉验证法进一步缩小了变量个数, 建立了优化随机森林模型, 优化后随机森林模型具有以下优点: (1)通过波长或波长区间选择, 可以有效减少参与建模的自变量数量, 从而简化模型, 降低建模预测时的计算量; (2)对待测组分具有光谱特征的波段处的信息进行提取强化, 同时弱化待测组分吸收不明显或干扰物质影响显著的波段, 以此提升模型的预测精度; (3)消除或减弱由于仪器和环境带来的噪声以及谱线中存在的冗余信息对回归建模的影响。
优化随机森林模型不仅模型精度, 稳定性、 预测能力显著高于全波段随机森林模型, 而且有效降低了光谱数据维度, 综合了有效波段的光谱特性。 结果表明本优化方法, 模型精度较高, 可适用于反演水体亚硝酸盐含量反演。
以上试验结果为水质亚硝酸盐指标的快速估算提供了理论基础, 为水体质量评估提供更便利的方案。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|