




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
深度神经网络和高光谱显微图像的二维材料纳米片识别
[彭仁苗1, 2  , 徐鹏鹏
, 徐鹏鹏2 , 赵一默2 , 包立君1 , 李成2, * ]
, 徐鹏鹏]
|
|


作者简介: 彭仁苗, 1996年生,厦门大学电子科学与技术学院硕士研究生 e-mail: prm649286898@126.com
近年来, 二维材料由于其独特的性质而受到了广泛关注。 在制备二维层状晶体的各种方法中, 机械剥离法获得的薄层二维材料晶体质量高, 适用于基础研究及性能演示。 然而用机械剥离法从衬底上获得的材料具有一定的随机性, 可能包含了少许相对较厚的部分。 实现对这些二维薄层材料有效、 快速且智能化的表征有利于促进二维材料性能的进一步研究。 提出了一种基于深度学习的表征方法, 通过搭建的编解码结构的卷积神经网络语义分割算法, 可以根据光学显微镜图像进行分割和快速识别二维材料纳米片。 卷积神经网络作为深度学习在图像处理领域中的典型算法, 能够对光学显微镜图像中的复杂信息进行特征提取。 首先采用机械剥离制备MoS2纳米片样本, 通过光学显微镜采集高光谱图像并对样本进行标记, 根据样本的厚度范围标记出不同的区域, 对标记后的图像进一步处理, 包括图像的颜色校准和剪切操作, 得到用于网络训练和测试的数据集。 针对光学图像中二维纳米薄片存在的低对比度、 碎裂等特点, 编码时加入残差结构和金字塔池化模型, 有助于特征信息的提取; 解码时融合编码路径中提取的浅层特征信息, 以提高网络分割精度。 实验中采用带权重的交叉熵损失函数解决类别数量不平衡问题和采用数据增强扩大数据集。 对训练后的网络测试结果表明, 模型像素精度为97.38%, 平均像素精度为90.38%, 均交并比为75.86%。 之后通过迁移学习成功地对剥离的单层和双层石墨烯纳米片样本进行了识别, 均交并比达到了81.63%, 表明该方法具有普适性。 通过MoS2和石墨烯纳米片的识别演示, 实现了深度学习在二维材料的光学显微镜图像中的成功应用。 该方法有望在更多的二维材料上得到扩展并突破自动动态处理光学显微镜图像的问题, 同时为其他纳米材料的高光谱图像处理提供参考。
In recent years, two-dimensional materials have received widespread attention due to their unique properties. Among the various methods for preparing two-dimensional layered crystals, the thin-layer two-dimensional material crystals obtained by mechanical exfoliation are of high quality, suitable for basic research and performance demonstration. However, mechanically exfoliated crystals on substrates exhibit a certain degree of randomness, including a few layers and relatively thick flakes. The effective, rapid and intelligent characterization method of these two-dimensional nanostructures is beneficial to further research on the properties of two-dimensional materials. This paper proposes a method based on deep learning, which can segment and quickly identify two-dimensional material nanosheets based on optical microscope images through a convolutional neural network semantic segmentation algorithm built with an encoding-decoding structure. As a typical algorithm for deep learning in the field of image processing, Convolutional neural networks can be applied to the feature extraction in optical microscope images. Firstly, MoS2 nanosheet samples were prepared by mechanical exfoliation, and high spectroscopic images were acquired by optical microscopy. The nanosheet samples were labeled, and the marked images were further processed, including color calibration and sliding shear operation, to obtain datasets for network training and testing. A semantic segmentation algorithm based on encoding-decoding network structure was designed to rapidly identify nanosheets. Aiming at some flakes in images showing the characteristic of low contrast and fragmentation, residual convolution and pyramid pooling models were added to strengthen the extraction of features during encoding. The shallow feature information extracted from the encoding stage was reused during decoding to improve the network segmentation results. In the experiment, the weighted cross-entropy loss function was used to solve the problem of unbalanced classes, and the dataset was enlarged with data augmentation. Testing on the trained network show that the pixel accuracy was 97.38%, the mean pixel accuracy was 90.38%, and the mean intersection over union was 75.86%. Then, the exfoliated monolayer and bilayer graphenes were identified by transfer learning, and the mean intersection over union reached 81.63%, showing that this technique is universal for the identification of two-dimensional nanosheets. The identification of MoS2 and graphene nanosheets realizes the application of deep learning in optical microscopy images of two-dimensional materials. This method is expected to apply to more two-dimensional materials and break through the problem of automatic dynamic processing of optical images. Moreover, it provides a reference for hyperspectral images processing of other nanomaterials.
Novoselov等[1]于2004年通过对石墨烯的机械剥离成功获取了单层石墨烯; 随后的十几年间, 人们发现了越来越多的二维材料, 例如过渡金属二硫族化合物(transition metal dichalcogenides, TMDs)[2]、 黑磷(black phosphorus, BP)[3]、 六方氮化硼(hexagonal boron nitride, h-BN)[4]等, 这些材料在原子层厚度情况下具有独特的光学和电学性质, 在多个领域具有广泛的应用前景。 时至今日, 机械剥离依然是获得高质量单层和少层二维材料晶体的最常用的方法之一。 该技术不仅能产生单层和少层纳米片, 还能产生大量的较厚的薄片。 通过光学显微镜获取光学图像, 然后直接利用光学图像识别纳米片厚度的过程很大程度上依赖于研究者的经验, 既困难又耗时。 原子力显微镜(AFM)通常用于测量二维材料纳米片的厚度, 但它很耗时, 不适合大面积快速测量[5], 因此需要找到更加快速有效的方法识别二维材料纳米薄片。 为了解决这一问题, 提出了基于光学对比度的识别方法[5], 通过衬底和不同层数的二维材料纳米片之间的光学对比度差异进行区分, 但是该方法通常会受到衬底(如二氧化硅)厚度和光照强度等的影响。
光学显微镜在纳米材料的科学研究中发挥着不可或缺的作用, 因为它提供了重要的物理和化学性质的丰富信息。 近年来, 深度学习得到了快速的发展, 被广泛运用到了图像识别、 材料缺陷检测和医学图像病变分割等各个方面, 尤其以卷积神经网络(convolutional neural networks, CNNs)[6, 7]为代表的算法在图像领域取得了良好的结果。 卷积神经网络不仅避免了传统算法特征提取的复杂过程, 而且在高级抽象特征提取方面拥有更加突出的能力, 特别是对细粒度图像识别具有极大的优势和潜力。 因此, 可以利用卷积神经网络对二维纳米材料的光学显微图像进行特征提取。 以二维材料MoS2的光学图像识别为例, 基于卷积神经网络算法演示了一种简单, 快速且可靠的二维纳米片材料厚度识别方法, 并通过迁移学习成功应用到石墨烯纳米材料的识别, 表明基于人工智能的材料表征方法是一个强大的工具, 为材料科学方面的基础研究提供了新的途径, 有望促进纳米材料科学技术的发展。
为了使采集的光学图像具有广泛代表性, 机械剥离制备的MoS2纳米片转移到不同衬底(90或300 nm SiO2/Si)上, 同时在采集图像的过程中使用不同的光照强度。 利用CCD摄像机在100倍物镜下采集了196张1 024×768像素大小的MoS2薄膜光学图像, 每张图像包含有不同厚度的薄片, 并利用原子力显微镜(AFM)测量了样品的形貌和厚度。 图1中, (a)和(d)为MoS2纳米片光学显微图像, (b)和(e)为对应的AFM测量图, (c)和(f)表示测得的MoS2纳米片厚度, 其值分别为2.3和4.8 nm。 2.3和4.8 nm厚的MoS2膜, 对应的层数分别为3层和7层。
 | 图1 MoS2样品表征 (a), (d): MoS2光学显微图像; (b), (e): 对应的AFM测量图; (c), (f): 测得的厚度值Fig.1 Characterization of MoS2 sample (a), (d): MoS2 optical images; (b), (e): AFM images; (c), (f): Thicknesses obtained by AFM analysis |
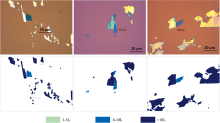
由于采用有监督的学习方法, 需要预先对样本进行标注, 所用的标注工具是MATLAB中的Image Labeler。 通常二维材料的性能研究多集中在少于10层的薄层, 因此将图像中剥离下来的MoS2按层数标记为三类, 即1—5层(1—5 L), 6—10层(6—10 L), 和大于10层(>10 L)。 总共被标记的光学图像数量为196张, 标注后的部分代表性图像如图2所示, 上排为MoS2光学显微图像, 下排为对应的标签图。
 | 图2 按不同厚度范围标注的MoS2纳米片部分标签图Fig.2 Partial labels of MoS2 nanosheets marked by different thickness ranges |
采集图像过程中, 由于使用了不同的衬底和不同的光照强度, 因此首先必须对每一幅光学原图进行颜色校准。 颜色校准的步骤为: 首先将RGB图像转化为Lab图像(L表示图像亮度通道, a和b分别表示图像两个颜色通道), 然后进行如式(1)—式(3)处理
其中, Ls, as和bs分别代表图像中衬底的相应值, L', a' 和b'分别代表图像处理之后的值。 由于衬底在图像中所占的像素数量超过50%, 因此取图像像素点的中位数作为相应的Ls, as和bs的值, 之后将Lab图像转为RGB图。 选取其中的80%作为训练数据集, 剩余的20%作为测试数据集。 校准后的图像和相应的标记图经过同样的裁剪形成192×192大小的图像, 训练集675张, 测试集239张。 图3为经处理后的部分光学显微图像和对应的标签图。
 | 图3 处理后的光学图像和对应的标签图Fig.3 Processed optical images and corresponding label images |
Long等[8]于2014年首次提出了全卷积神经网络FCN, 提高了分割效率。 2015年, U-Net[9]和SegNet[10]的诞生, 标志着编码和解码结构成为语义分割网络的主流, 之后被广泛应用到了生物医学图像的分析中[11, 12], 它们可以在较少的数据集上得到良好的分割效果。
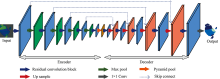
设计的对称式编解码网络结构如图4所示, 将其记为2D-Net。 输入为192×192×3的可见光谱图像, 网络结构由编码部分和对称的解码部分组成。 网络中使用了跳跃连接来融合不同层次的特征。 利用1×1的卷积层对特征图的通道尺度进行压缩, 输出大小为192×192×4的分割图像, 通过softmax分类器按像素进行分类。
 | 图4 网络结构示意图Fig.4 Diagram of Network structure |
1.3.1 编码结构
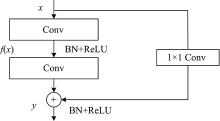
编码部分由5个残差卷积块构成主干网络, 将其分别记为B1, B2, B3, B4和B5, 残差卷积[13]有助于细节特征的提取。 图5为网络中使用的残差卷积块, 由两部分构成, 一是由1×1的卷积层完成输入到输出的映射, 另一个是由卷积层、 激活层(ReLU)和批量标准化层(BN)组成的残差部分, 最后将两部分的特征进行求和。 前4次下采样为最大池化(Max pool), 最后一次下采样为金字塔池化[14](Pyramid pool)。
 | 图5 残差卷积块结构Fig.5 Structure of residual convolution network |
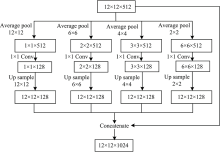
图6为网络中使用的金字塔池化结构, 4个窗口为12×12, 6×6, 4×4和2×2的平均池化层对特征图进行下采样, 利用1×1的卷积层分别进行通道维度压缩, 变为原来的1/4, 之后通过上采样恢复到原输入特征图的尺寸大小。 将输入特征图和这4个不同尺度上的特征图在通道维度上进行级联, 形成一个在尺寸上同输入特征图相同但通道维度上为其2倍的特征图。 B1到B5输出特征图依次记为[F1, F2, F3, F4, F5]。 F2到F5特征图的大小分别为原始输入图像的1/2, 1/4, 1/8, 1/16。
 | 图6 金字塔池化模型结构Fig.6 Structure of pyramid pooling model |
1.3.2 解码结构
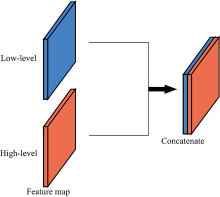
解码部分由跳跃连接、 上采样层和残差卷积块构成, 通过横向连接依次融合F4, F3, F2和F1的特征信息。 解码部分的残差卷积块与编码中的相同。 上采样层用于恢复特征图的尺寸大小。 通常浅层网络提取的特征主要包含了颜色信息和轮廓信息, 这些信息对于图像的识别效果起着重要的作用, 因此在解码时二次使用了编码时提取的浅层语义特征信息。 将解码时上采样后的特征图与编码中的浅层特征图在通道维度上进行级联组合, 如图7所示。 编解码过程中各阶段参数如表1所示。
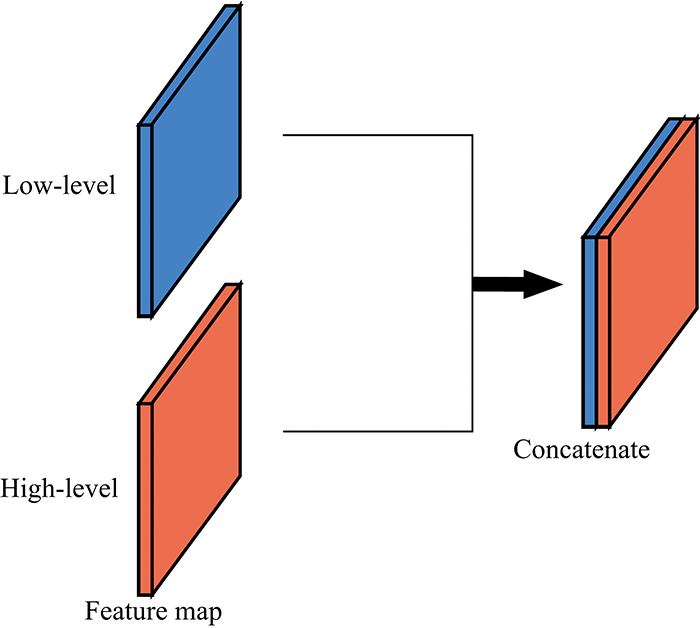 | 图7 浅层特征图重用示意图Fig.7 Schematic diagram of low-level feature map reuse |
| 表1 编解码阶段网络参数 Table 1 Network parameters in the encoding and decoding stages |
1.3.3 带权重的损失函数
由于采集的数据集中类别数量不平衡, 其中超过70%的像素点为背景类别, 所以需要利用加权的交叉熵损失函数以提高数量少的类别的分割精度。 带权重的交叉熵损失函数表达式如式(4)
式(4)中, xi为输入像素点i经过softmax函数后得到的输出值, yik为像素点i处的标签yi经过独热码编码后在第k个类别处的标签值。 经过独热码编码后只有在真实标签位置处为1, 其余位置处为0。 K为标签种类数, N为像素点总数, wk表示训练数据中第k类的权重, 其值为第k类样本在训练数据集中的比率的倒数, 即意味着样本数量少的类别会获得更大的权重。
采用如下三种标准对搭建的网络进行评估: 像素精度(pixel accuracy, PA)、 平均像素精度(mean pixel accuracy, MPA)、 均交并比(mean intersection over union, MIoU)[15]:
PA表示分类正确的像素数量与像素总数之间的比率
MPA表示对所有类别的像素精度求平均值
MIoU表示对所有类别的交并比求平均值
式(5)—式(7)中, nij表示实际为i类但是被预测为j类的像素数量, nc表示类别总数。
深度学习的网络中通常含有大量的参数, 训练的样本越多, 得到的网络模型鲁棒性越好。 为此, 对前面裁剪后得到的小尺寸训练集图像和标签图同时逆时针旋转(90° , 180° 和270° )和翻折(水平、 竖直)进行数据增强。
为了测试2D-Net网络结构的分割性能, 设置了四组对比实验, 将2D-Net网络同FCN8、 SegNet、 U-Net等分割网络进行了比较。 训练时迭代周期为50个, 前25个周期学习率为0.001, 后25个周期学习率为0.000 1。 优化方法采用SGD, 批大小为5, 初始化方式为随机初始化。 采用64位window 10操作系统, CPU型号为: Intel(R) Core(TM) i9-9900K CPU @3.60 GHz, 64.0 GB RAM; GPU型号为: NVIDIA Quadro RTX 4000 , 8 GB GDDR6。 网络的搭建、 训练和测试都基于keras框架, 详细配置情况如下: Anaconda3+tensorflow-gpu2.2.0+Cuda10.1+Cudnn7.6
图8为设计的2D-Net网络在50个训练周期过程中的损失曲线和准确率曲线图, 从图中可以看出, 经过训练后的网络基本收敛。
 | 图8 2D-Net网络训练过程中的损失曲线和准确率曲线图Fig.8 Loss curve and accuracy curve during 2D-Net network training |
对四种网络单独训练结束后进行测试, 其结果如表2所示。 可以看出, 2D-Net网络同其他网络相比, 在各项评价指标上均有提升, 分割效果更好。
| 表2 四种网络结构的测试结果 Table 2 Test results of four network structures |
图9为2D-Net网络的测试结果的混淆矩阵。 在混淆矩阵中, 横轴代表每个像素的真实类别, 纵轴代表预测类别, 对角线代表预测正确的像素比率, 非对角线代表预测错误的像素比率。
 | 图9 测试结果的混淆矩阵Fig.9 Confusion matrix of test results |
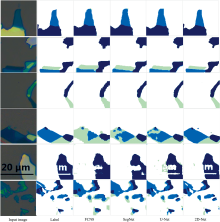
图10展示了四种网络结构的部分预测结果。 从左到右, 每一列依次为输入图像、 标签图像、 FCN8预测图像、 SegNet预测图像、 U-Net预测图像和本工作设计的2D-Net预测图像。 和标签图比较后发现, 对于大块剥离的材料薄膜或者对比度较明显时, 四种网络均可以提取到对比度、 颜色及分布情况等特征信息, 预测较为准确。 其中FCN8分割的轮廓线条较其他网络显得稍粗糙。 分类错误的情况主要发生在薄膜层数相近的一些低对比度区域, 薄膜尺度小、 破碎的部分以及文本标记处或其他残留物等区域。
 | 图10 四种网络结构的预测结果图Fig.10 The prediction results of the four network structures |
对于低对比度区域, FCN8网络的分割效果最差, 同?.嘟饴虢峁沟腟egNet和U-Net的分割效果有所提升, 相比之下2D-Net网络的识别效果最好。 对于薄片破碎的部分, FCN8和SegNet未能分割出破碎轮廓线, U-Net和2D-Net有所改进, 但仍有区域粘连, 对比之下可以观察到2D-Net分割出的地方多于U-Net。 在实际标注过程中, 文本标记或其他残留物这些非薄膜材料和衬底一起被标记为背景类, 但由于其数量较少且又同衬底之间有明显的颜色差异, 用于对比的其他三种网络均未能很好地分辨出来, 而2D-Net网络对于这些部分的分割效果最佳。 由此可以看出, 2D-Net具有更好的抗干扰能力和较高的准确性。
为了观察网络如何从图像中提取相关特征, 在将MoS2光学图像作为输入的情况下选取了编码结构中各个残差卷积块阶段的特征图进行可视化观察, 以F2和F5的部分特征图可视化结果进行说明, 如图11所示。 图11(a)给出三组MoS2纳米片输入图像和F2特征图。 由于F2是较浅层的特征图, 所以可以方便观察网络提取的相关特征。 从图中可以看出网络除了能对颜色特征进行提取外, 还能检测到更多的边界特征, 对MoS2薄片的轮廓、 边缘及线条进行了特征提取。 随着深度的增加, 由于网络中的池化层作用, 每个特征图变得更小, 每个卷积核的接受场(当前层中每个神经元可以响应的区域)变得相对较大, 且ReLU激活函数对特征进行了非线性提取, 这导致了对全局图形特征的更高层次的抽象表示, 如图11(b)F5特征图所示。
 | 图11 特征图可视化输出结果 (a): 输入图像和F2特征图; (b): 输入图像和F5特征图Fig.11 Output results of feature map visualization (a): MoS2 optical images and F2 feature maps; (b): MoS2 optical images and F5 feature maps |
为了检验2D-Net网络对其他二维材料的普适性, 通过迁移学习的方式将采用MoS2纳米片训练的参数模型运用到石墨烯纳米片识别。 提供了剥离法制备的石墨烯光学图片44张; 首先对图片进行标注, 这里为了更加细致地区分层数, 标注了单层和双层石墨烯, 然后选30张作为训练集, 14张作为测试集。 之后进行同样的预处理和数据增强操作, 形成900张训练集图片和180张测试集图片。 迭代周期为100, 前50个周期学习率为0.001, 后50个周期学习率为0.000 1。
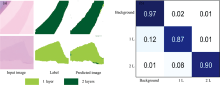
图12为利用迁移学习方式得到的石墨烯图片的部分预测结果和混淆矩阵, 从光学图像中可以看出单层和双层石墨烯同衬底颜色相差不大, 但是网络也能对其进行有效识别, 在测试数据集上平均像素精度为91.37%, 平均交并比为81.63%。 通过对MoS2和石墨烯纳米片层数识别的演示, 表明了深度学习技术结合光学显微镜可实现对二维材料薄片厚度的有效表征, 具有较高的精准度且不受光学设置变化的影响, 能够满足不同的用户需求, 可以进一步促进其相关性能的研究。
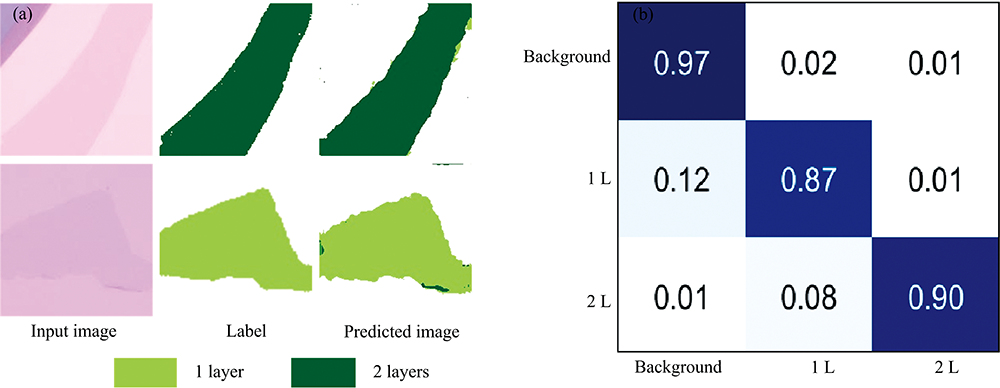 | 图12 剥离石墨烯的迁移学习 (a): 预测结果; (b): 测试的混淆矩阵Fig.12 Transfer learning for exfoliated grapheme (a): Predicted results; (b): Confusion matrix of testing |
利用卷积神经网络, 设计了一种编解码结构的深度神经网络实现对二维材料光学显微图像的特征提取与分割。 实验结果表明, 该网络模型能够通过光学显微图像有效识别二维材料薄片, 具有较好的抗干扰能力和较高的准确率。 首先对于剥离的MoS2薄片的识别, 模型像素精度为97.38%, 平均像素精度为90.38%, 均交并比为75.86%。 其次, 通过迁移学习的模型能够很好地区分出单层和双层石墨烯纳米片, 均交并比达到了81.63%, 说明了该方法具有良好的可扩展性。 在后续的工作中将加入其他类型的二维材料和不同方式制备的薄膜样本以及制作更加丰富的厚度类别数据集, 使其广泛地适用于二维材料领域的研究, 同时利用深度学习的速度优势有望实现对二维材料薄片的光学原位图像数据实时处理, 将为研究二维材料的人员节省大量时间。 本工作演示了深度学习在纳米材料的光学显微镜图像处理中拥有的广阔应用前景。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|