{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于XGBoost的糖尿病血液拉曼光谱定量分析法
[王铭萱 , 王巧云
, 王巧云* , 骈斐斐, 单鹏, 李志刚, 马振鹤]
, 王巧云, 骈斐斐, 单鹏, 李志刚, 马振鹤]
|
|


作者简介: 王铭萱, 1997年生,东北大学信息科学与工程学院硕士研究生 e-mail: 1163886570@qq.com
血液中包含着大量的生物信息, 如激素、 酶、 血糖等成分, 而血糖偏高将引发糖尿病。 糖尿病有很多并发症, 比如脑梗塞, 脑出血, 肾脏损害, 眼底损害, 周围神经病变等一系列疾病。 目前, 血液常规成分检测分析周期较长, 结果反馈较慢, 难以实现快速连续检测。 光学检测技术能够根据待测物质的光谱鉴别物质化学成分和相对含量, 因其灵敏度高、 适用性强、 分析速度快等优势, 在血液无创检测领域逐渐发挥其优势。 随着激光技术的不断进步, 拉曼光谱技术作为一种非线性散射光谱技术, 在血液检测技术中得到了广泛应用。 为提高拉曼光谱的预测精度, 首次将XGBoost算法应用到拉曼光谱血液血糖浓度中进行预测精度的提升。 实验中106组血液样本及试验标准值为河北省秦皇岛市第一医院提供, 选用布鲁克的MultiRAM光谱仪进行血液的拉曼光谱数据测量, 实验中1 064 nm激发光源功率为400 mW, 光谱分辨率为6 cm-1, 扫描速率为10 kHz, 扫描范围为400~4 000 cm-1, 对每个样本重复采集10次并计算平均值作为原始光谱数据, 以保证实验的准确性和可重复性。 该方法无需对数据进行预处理, 首先将光谱数据随机划分为训练集和测试集, 比例为7:3, 训练集用于训练模型并确定模型参数, 测试集用于测试模型的稳定性和预测精度。 建立XGBoost模型后, 用网格搜索法和k折交叉验证优化模型参数; 引入模型评估指标和克拉克网格误差分析图对XGBoost模型血糖浓度的预测进行分析; 最后将XGBoost模型与决策树(DT)、 随机森林(RF)和支持向量机回归(SVR)模型进行对比。 实验结果表明通过XGBoost建立的定量回归模型效果最佳, 模型的决定系数为0.999 99, 校正集均方误差为0.007 49, 预测集均方误差为0.007 17, 相对分析误差为331.973 18, 预测点均落在克拉克网格误差分析图的A区。 结果证明, 将XGBoost算法应用到拉曼光谱血液成分定量分析中具有较高的预测精度, 并且数据未经过预处理, 可以有效缩短程序运行时间, 其在拉曼光谱以及近红外光谱定量分析领域具有广阔的发展前景。
The blood contains many biological information, such as hormones, enzymes, blood sugar and other components. High blood sugar will cause diabetes, which has many complications, such as cerebral infarction, cerebral hemorrhage, kidney damage, fundus damage, peripheral neuropathy and a series of diseases.At present, the routine blood component detection and analysis cycle are too long, the resulting feedback is slow, and it is not easy to achieve rapid and continuous detection. Optical detection technology can identify the chemical composition and relative content of the substance according to the spectrum of the substance to be tested. Because of its advantages, such as high sensitivity, strong applicability, and fast analysis speed, it gradually exerts its advantages in blood non-invasive detection. With the continuous advancement of laser technology, Raman spectroscopy technology, as a nonlinear scattering spectroscopy technology, has been widely used in blood detection technology. In order to improve the prediction accuracy of Raman spectroscopy in this paper, the XGBoost algorithm was firstly applied to the blood glucose concentration of Raman spectroscopy to improve the prediction accuracy. 106 sets of experimental blood samples and real concentrations were provided by the First Hospital of Qinhuangdao City, Hebei Province. Bruker's Multi RAM spectrometer was used to measure blood Raman spectroscopy data. In the experiment, the power of the 1 064 nm excitation light source was 400 mW, the spectral resolution was 6 cm-1, the scanning rate was 10 kHz, and the scanning range was 400~4 000 cm-1. Each sample is collected 10 times, and the average value is calculated as the original spectrum to ensure the accuracy and repeatability of the experiment. In this paper, the method does not require preprocessing of the data. Firstly, the spectral data were randomly divided into a training and test sets with a ratio of 7:3. The training set was used to train the model and determine the model parameters. The test set was used to verify the stability and prediction accuracy of the model. Then, the XGBoost model was established, and grid search and k-fold cross-validation were used to optimize the model parameters. We adopted model evaluation indicators and a Clark grid error analysis chart to analyze the prediction of blood glucose concentration of the XGBoost model. Finally, the XGBoost model was compared with Decision Tree (DT), Random Forest (RF) and Support Vector Machine Regression (SVR) models.The experimental results showed that the quantitative regression model established by XGBoost had the best effect. The model's coefficient of determination was 0.999 99, the mean square error of the calibration set was 0.007 49, the mean square error of the prediction set was 0.007 17, and the relative analysis error was 331.973 18. The prediction points fell in area A of the Clark grid error analysis chart. The results prove that the application of the XGBoost algorithm to the quantitative analysis of blood components in Raman spectroscopy has high prediction accuracy, and the data is not pre-processed, which can effectively shorten the program's running time. It has broad development prospects in Raman spectroscopy and near-infrared spectroscopy quantitative analysis.
近年来, 糖尿病、 心脑血管疾病等作为危害人体健康的重要杀手, 发病率日益攀升, 给家庭和社会都带来重大负担, 人们迫切需要寻求实现此类疾病前期预防、 临床诊断和及时治疗的有效手段[1]。 血液蕴藏着生命体宝贵的信息, 参与各组织器官功能调节和正常的新陈代谢, 以维持人体的生理平衡。 当人体任何部位发生病理性变化时, 血液中的成分也随之改变, 因而血液成分检测对疾病的诊断及预防有着重要意义。 对于血糖的测量, 光谱检测技术能够根据待测物所呈现的光谱来鉴别物质化学成分和相对含量, 具有对样本无损、 灵敏度高、 适用性强、 操作性好、 分析速度快等优势[2]。 拉曼光谱是一种由分子振动和转动产生的散射光谱, 其波峰位置、 强度和线宽等可提供分子振动、 转动等信息, 因此可实现分子官能团和化学键的鉴别分析, 适用于化合物分子结构测定、 混合物成分分析及样本浓度检测, 且具有对水分子散射效应小的突出特点。 机器学习中很多算法在光谱定量回归中得到了广泛的应用, 常用的拉曼光谱定量回归方法有支持向量机(SVM)、 偏最小二乘(PLS)、 极限学习机(ELM)、 卷积神经网络(CNNs)和主成分分析回归(PCA)等算法。 近年来, 不少学者将以决策树(DT)为基础的随机森林(RF)、 梯度提升决策树(GBDT)、 自适应提升(AdaBoost)、 XGBoost[3, 4, 5, 6]等算法应用到定量回归中, 并取得了良好的效果。 2018年, 李盛芳[7]等利用随机森林对不同类型的水果糖分进行近红外光谱预测, 预测精度R2达到0.999, RMSEC达到0.015, 且RF模型效果好于PLS模型。 2021年, 蒋薇薇等利用集成学习算法对药片和柴油进行近红外光谱预测, 其中采用了GBDT算法[见本刊2021, 41(4): 1119]。
XGBoost算法是陈天奇等开发的一个开源机器学习项目, 高效地实现了GBDT算法并进行了算法和工程上的许多改进, 被广泛应用在回归和分类当中。 2018年, Zhong[8]等将XGBoost框架用于蛋白质预测。 2019年, Shi[9]等将XGBoost用于驾驶评估和风险预测。 XGBoost在Kaggle竞赛及其他许多机器学习竞赛取得了不错的成绩。 该算法具有并行处理、 灵活性高、 正则化等特点。
首次将XGBoost应用到拉曼光谱血液定量回归中, 以提升预测精确度和模型稳健性, 且取得了不错的效果。
实验所用的血液样本收集于河北省秦皇岛市第一医院, 实验样本均已征求并取得医生和病人的同意, 符合临床试验的伦理原则。 本实验血液样本取自临床已确诊糖尿病的患者和健康志愿者, 共106组血液样本。 被试者取血条件均为: 当天下午18:30— 19:30开始禁食12 h, 于次日晨6:30— 7:30采集静脉血5 mL。 取得血液样本后加入乙二胺四乙酸二钠抗凝剂抗凝, 将血液置于4 ℃环境下备用。 在提取过程中, 为避免样本间的交叉感染, 均使用一次性胶头滴管。 为保证实验的连续性和可重复性, 采集时确保样本采集的背景大致相同, 降低外环境差异等原因对实验数据的干扰, 并在两日内完成全部样本的采集, 为后期数据处理的真实性和准确性提供保障。
在实验前, 将样本均分为两份, 一份样本按照临床标准方法进行检测并作为标准浓度, 另一份样本置于洁净石英透明杯中, 用拉曼光谱仪在室温环境下检测, 设置激发光源功率为400 mW, 光谱分辨率为6 cm-1, 扫描范围为400~4 000 cm-1, 由于血液样本稀缺导致样本数目过少, 为避免偶然因素干扰, 本实验对每个样本进行10次拉曼光谱数据采集后对数据进行加和平均处理。 实验进行样本溶液测量使用德国布鲁克(Bruker)公司生产的MultiRAM傅里叶变换拉曼光谱仪, 且相应配备高性能液氮冷却的Ge检测器、 标准Nd:YAG(1 064 nm)激光器和OPUS7.0光谱分析软件程序。
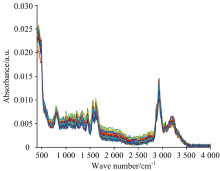
使用拉曼光谱仪扫描测得106组实验血液样本的光谱数据, 原始拉曼光谱如图1所示。
 | 图1 血液样本原始拉曼光谱Fig.1 Original Raman spectra of blood samples |
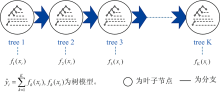
XGBoost算法本质是一个梯度下降树(GBDT), 因其引入分布式和对损失函数进行二阶泰勒展开等改造, 把速度和效率发挥到极致, 因此叫作X(Extreme)GBoosted。 XGBoost的基学习机可以是树(Cart)模型也可以是线性模型, 本文选取树模型。 XGBoost算法原理如下: 给出一个有n个样本, m个特征的数据集, 假设有K课树, 第i个样本的输出
式(1)中
2.1.1 构造目标函数
式(2)中:
式(3)中: T为叶子节点个数, wj为叶子节点j的输出, λ和γ 分别为叶子节点数目和输出的正则化参数。
2.1.2 构造树模型
设待训练的第t棵树有T个叶子节点, wj为叶子节点j的输出, 对式(1)进行追加法训练, 其核心思想为已经训练的树不再进行调整, 则第t棵树进行训练, 目标函数为
对式(4)进行二阶泰勒展开, 并略去常数项, 目标函数简化为
式(5)中,
式(6)为叶子节点j的最优输出, 式(7)为最优的目标值。
2.1.3 寻找最佳分裂节点
目标函数代表树的得分, 其值越小越好, 由于不能枚举所有的树结构, 本文XGBoost算法对于节点采取贪心算法对子树进行划分, 枚举合适的分裂点, 选择目标函数值最小, 增益函数最高的划分, 增益函数如式(8)
Gain值越大, 说明分裂后能使目标函数值减小越多。
在XGBoost系统中, 最佳节点的选择方法, 用户可以根据需求自由选择, 算法均可通过参数进行配置, 可提供的算法有: 精确贪心算法、 近似算法全局策略、 近似算法本地策略。 分裂到树的最大深度后停止分裂, 并开始构建下一棵树的残差。 最后将所有生成的树进行集合, 得到完整的XGBoost模型。
| 表1 贪心算法示意图 Table 1 Schematic diagram of greedy algorithm |
预测结果评估结果采用决定系数R2、 校正集均方根误差RMSEC、 预测集均方根误差RMSEP、 相对分析误差RPD来评价定量回归模型的性能, 判断所建模型的优劣。
 | 图2 XGBoost算法示意图Fig.2 Schematic diagram of XGBoost algorithm |
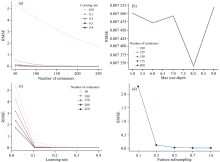
本次实验血液数据共106组, 光谱数据未经过预处理, 将数据集随机分为训练集和测试集, 比例为7:3。 后进行调参工作, XGBoost的参数分为三种, 即通用参数、 任务参数和命令行参数。 任务参数用来控制结果的度量方法和理想的优化目标, 通用参数是本文调参的核心。 本文选用决策树为弱学习器, 并行线程为最大, 以保证运行速度, verbosity为静默, 后调节弱学习器的参数。 引入网格搜索法和k折交叉验证进行参数优化, 图3为调参过程的超参数调整和相应的性能比较。 超参数调整顺序和具体数值设定见表2。
| 表2 超参数 Table 2 Hyper-parameters |
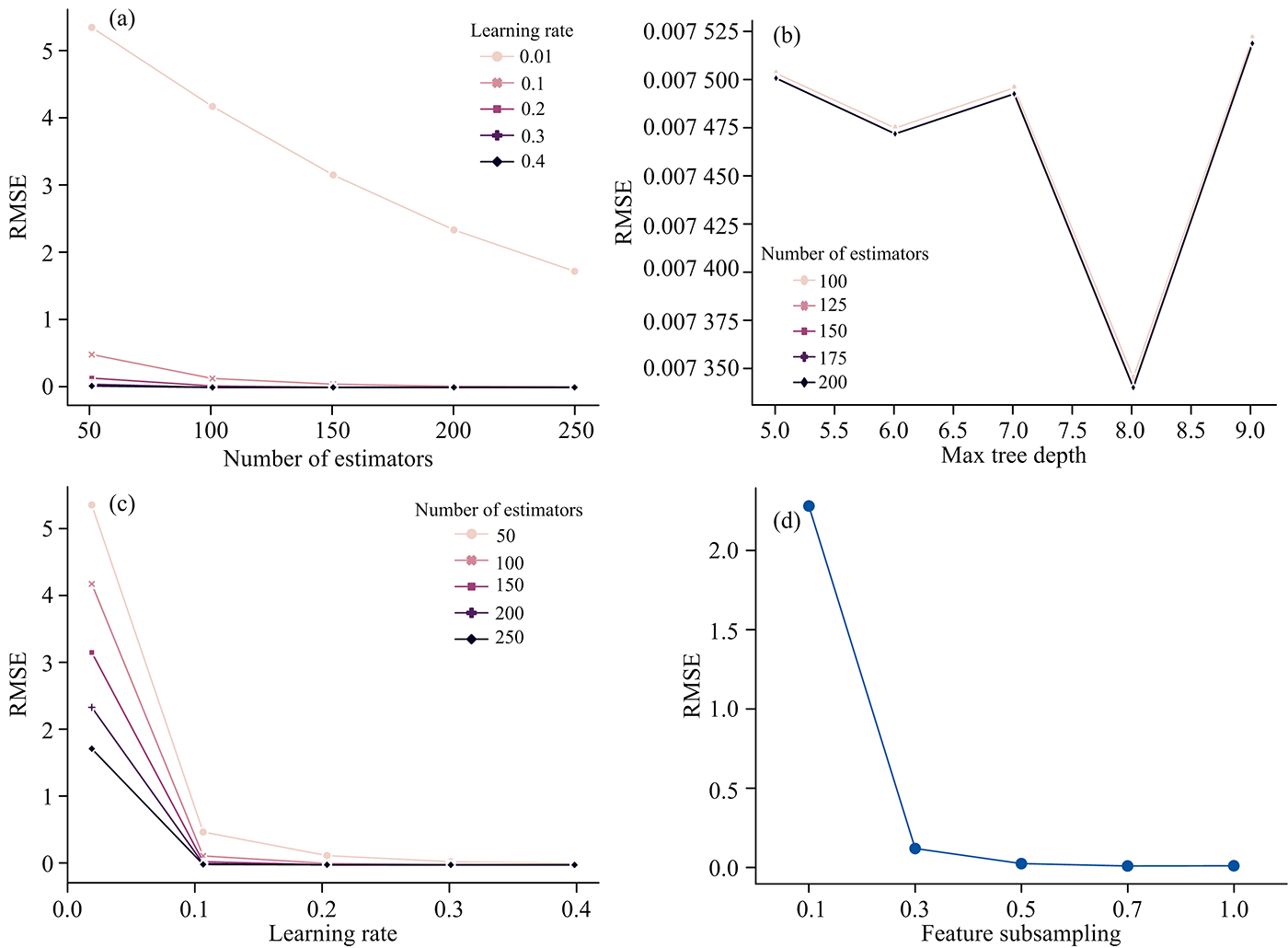 | 图3 XGBoost超参数调整Fig.3 XGBoost Hyper-parameters tuning |
为了更好地评估模型的性能, 引入支持决策树(DT)、 向量机(SVR)和随机森林(RF)定量回归模型作为对比, 评估结果如表3所示。
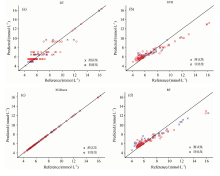
从表3和图4可以看出, 对于血液血糖拉曼光谱数据浓度的回归预测, XGBoost模型的评估指标要远优于DT、 RF和SVR模型。 XGBoost模型的决定系数R2和相对分析误差RPD相对于其他模型来说最高, 且R2=99.999%十分接近1、 RPD=331.973 18远远大于2, 数据结果表明XGBoost模型回归预测效果最好、 最为可靠。 同时, 校正集均方根误差RMSEC、 预测集均方根误差RMSEP在四种模型中最小且最接近, 二者相差0.000 32, 表明XGBoost模型没有过拟合, 模型的精确度高, 预测可靠性是四种模型中最高的。 由表3可以看出, 以DT模型为基础的RF模型和XGBoost模型在数据没有经过预处理的情况下的预测精度要高于SVR模型。
| 表3 模型评估 Table 3 Model evaluation |
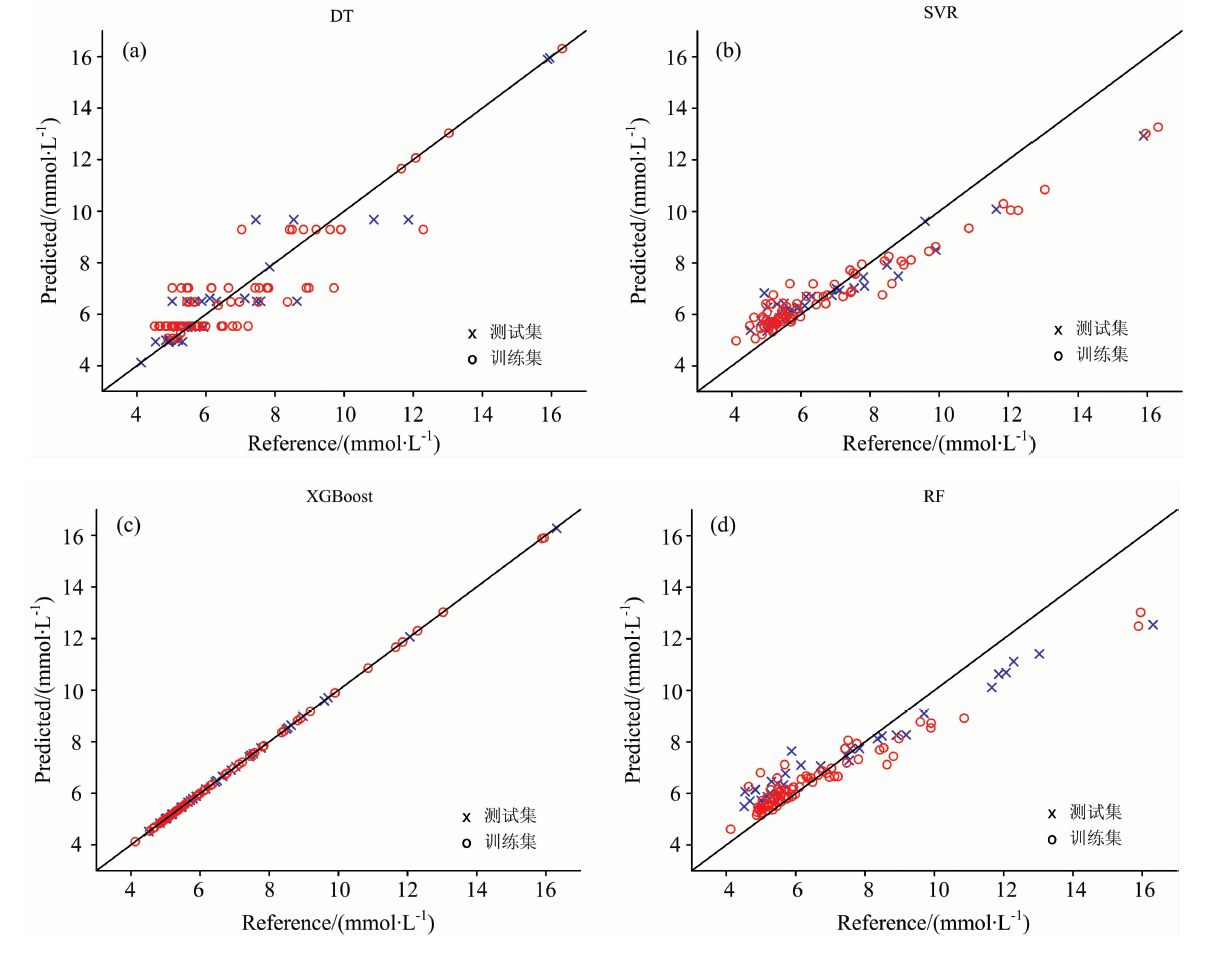 | 图4 模型血糖预测回归图 (a): DT; (b): SVR; (c): XGBoost; (d): RFFig.4 Model prediction regression diagram (a): DT model; (b): SVR model; (c): XGBoost model; (d): RF model |
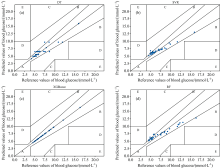
采用克拉克网格误差分析将预测结果可视化, 可以更直观的看出各种算法在拉曼光谱上应用的效果。 克拉克误差网格分析法是为了评估病人的测量血糖值和参考血糖的临床精确度而于1987年开发的分析方法, 它根据血糖预测值落在A, B, C, D和E五个区域的概率来评估血糖预测方法的准确性。 图5使用上述方法预测变化的克拉克误差网格分析结果, 落在A区域的值具有较高的预测精度, 表明预测值偏离实际值不超过20%。 由图5可知所有的预测点都在A和B区域内, 使用XGBoost进行预测时, 所有的点都在A区域内, 可见其预测能力明显高于另三种算法。
 | 图5 克拉克网格误差分析图 (a): DT; (b): SVR; (c): XGBoost; (d): RFFig.5 Clarke grid error analysis diagram (a): DT Clark grid error analysis; (b): SVR Clark grid error analysis; (c): XGBoost Clark grid error analysis; (d): RF Clark grid error analysis |
XGBoost在各大机器学习、 数据挖掘比赛中广受好评, 但却没有被应用在拉曼光谱定量分析研究中。 本文首次将XGBoost算法应用到拉曼光谱血液定量分析中, 并构建了决策树(DT)、 随机森林(RF)和支持向量机回归(SVR)三个定量回归模型与本文模型进行对比, 实验结果表明, XGBoost模型的预测效果最好, 其预测精度为99.999%。 并且, 本文抛弃了光谱数据传统的预处理方法, 如平滑、 求导、 多元散射校正、 标准正态变换等, 应用XGBoost模型且未对数据进行预处理, 减少程序运行时间, 并达到较高的预测精度。 证明XGBoost模型应用到拉曼光谱血液定量分析中具有较强的适用性、 较高的预测精度和泛化能力, 在拉曼光谱定量分析领域中有着重要的研究价值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|