
{kind=link}
{kind=link}
{kind=link}
{kind=link}
X射线荧光光谱结合CARS变量筛选选择方法用于土壤中铅砷含量的测定
[江晓宇1, 2  , 李福生
, 李福生2, * , 王清亚1, 2 , 罗杰3 , 郝军1, 2 , 徐木强1, 2 ]
, 李福生, 王清亚|
|


作者简介: 江晓宇, 1988年生, 东华理工大学核技术应用教育部工程研究中心博士研究生 e-mail: jjxxyy1988@126.com
X射线荧光光谱分析作为一种以化学计量学为基础的定量分析技术, 所建立模型优劣对结果的预测准确性显得十分重要。 竞争性自适应重加权算法(CARS)采用自适应重加权采样技术, 利用交互验证选出互验证均方根误差(RMSECV)值最低原则, 寻出最优变量组合。 为了进一步提高PLS模型的解释和预测能力, 将竞争性自适应重加权算法(CARS)与X射线荧光光谱分析技术相结合, 对土壤中重金属元素铅和砷进行特征波长变量筛选后建立偏最小二乘(PLS)模型。 首先, 利用CARS算法对铅含量密切相关的波长变量进行筛选, 当采样次数为26次时, 筛选出60个有效波长点; 对砷含量密切相关的波长变量进行筛选, 当采样次数为34次时, 筛选出19个有效波长点; 然后对优选出的波长点利用PLS方法分别建立土壤中铅和砷含量定量分析模型, 并与经连续投影算法(SPA)及蒙特卡罗无信息变量消除(MC-UVE)方法波长变量筛选后所建立的PLS模型进行比较。 结果显示: 铅的CARS-PLS模型的预测集决定系数( R2)、 交互验证均方根误差(RMSECV)、 预测均方根误差(RMSEP)和相对预测误差(RPD)分别为0.995 5, 2.598 6, 3.228和9.401 1, 砷的CARS-PLS模型的预测集 R2, RMSECV, RMSEP和RPD分别为0.989 9, 3.013 2, 2.737 1和8.211 6; 两元素的CARS-PLS模型性能均优于全波段PLS, SPA-PLS和MC-UVE-PLS模型。 基于CARS-PLS的算法可以有效筛选出X射线荧光光谱特征波长点, 在简化了建模复杂程度的同时, 提高了模型的准确性和稳健性。
As a quantitative analysis technique based on stoichiometry, X-ray fluorescence spectroscopy is very important to the prediction accuracy of the results. The competitive adaptive reweighted algorithm (CARS) adopted adaptive reweighted sampling technology and used interactive verification to select the lowest value square error (RMSECV) by interactive verification to find out the optimal combination of variables. To further improving the interpretation and prediction ability of PLS models, the competitive adaptive reweighted algorithm (CARS) was combined with X-ray fluorescence spectroscopy. A partial least square (PLS) model was established after screening the characteristic wavelength variables of lead and arsenic in the soil. Firstly, the CARS algorithm screened the wavelength variables closely related to lead content. When the sampling times were 26 times, 60 effective wavelength points were selected, and the wavelength variables closely related to arsenic content were screened. When the sampling times were 34 times, 19 effective wavelength points were selected. Then used the PLS method to establish the quantitative analysis model of lead and arsenic content in soil and compared it with the PLS model established by continuous projection algorithm (SPA) and Monte Carlo method. The results showed that the prediction sets Determination Coefficient ( R2), Root Mean Square Error of Cross-Validation (RMSECV), Root Mean Square Error of Prediction (RMSEP) and Relative Prediction Deviation (RPD) of the lead CARS-PLS model were 0.995 5, 2.598 6, 3.228 and 9.401 1, respectively. Moreover, the prediction sets R2, RMSECV, RMSEP and RPD of arsenic CARS-PLS models were 0.999, 3.013 2, 2.737 1 and 8.211 6, respectively. The CARS-PLS model performance of the two elements is better than that of full-band PLS, SPA-PLS and MC-UVE-PLS model. The CARS-PLS algorithm based on the X fluorescence spectrum can effectively screen the characteristic wavelength, simplify the complexity of modeling, and improve the accuracy and robustness of the model.
能量色散X射线荧光(EDXRF)光谱仪因其在多元素检测中具有无损、 快速的特点, 相比传统检测方法, 在土壤重金属分析中具有先天的优势。 另外, EDXRF因其较小的体积、 较轻的重量、 更快的分析速度以及较高的准确度, 广泛应用于野外现场分析。 近几年来, EDXRF越来越受环保领域的欢迎, 成为土壤修复行业和环境监管部门的首选仪器。 然而, X射线荧光光谱易受噪声、 变量维度高和多重共线性等问题的干扰, 特别是在测土壤样品时, 因其样品来源广泛, 基体成分复杂, 采用偏最小二乘(PLS)直接建模的话会导致模型复杂, 并且降低了模型的预测能力和鲁棒性。 因此, 如何选择合适的变量显得尤为重要。 近年来, 科学技术的飞速发展, IT和计算机技术快速应用, 特征变量筛选方法被大量提出, 如基于统计学方面的变量选择方法[1]、 基于单一指标的变量选择方法[2, 3]以及群体智能优化算法[4, 5]等。
竞争性自适应重加权算法(competitive adaptive reweighted algorithm, CARS)是利用蒙特卡罗(MC)的优势进行采样和PLS回归系数为指标的一种特征波长变量选择方法[6]。 其核心是利用自适应重加权采样(ARS)技术, 然后在构建的模型中只保留权重显著(回归系数绝对值大)的波长点, 最后按照均方根误差值最小的原则选择最优组合子集变量。 此外, 在对大多文献调研过程中发现, 很少有对土壤样品X射线荧光光谱波长变量进行筛选。 但X射线荧光光谱往往也存在维度过高, 变量数大于建模样本数问题, 建立的模型容易过拟合, 模型稳定性变差。
先利用能量色散X射线荧光光谱仪对土壤中的铅和砷进行分析获取原始光谱信息, 然后利用CARS算法先对所获取的原始光谱进行波长变量选择, 最后利用PLS分别建立土壤中铅、 砷的定量分析模型。 为了评估建模的有效性, 一般采用预测集决定系数(determination coefficient, R2)、 模型交互验证均方根误差(root mean square error of cross validation, RMSECV)、 模型预测均方根误差(root mean square error of prediction, RMSEP)和模型相对预测误差(relative prediction deviation, RPD)等为模型评价指标, 并与全波段、 SPA和MC-UVE等变量选择算法所建立的定量分析模型进行比较。
主要仪器: TS-XH4000型便携式X射线荧光光谱仪, 浙江泰克松德能源科技有限公司; SDD探测器, 能量分辨率为125 eV, 美国Amptek公司; 球磨仪, 江苏宜兴丁蜀浩强机械设备有限公司; 样品杯(聚乙烯), 尺寸为Φ 3 cm× 1 cm, 单开口, 带固定麦拉膜的颈圈; 麦拉膜, 厚度为3.6 μ m, 宽7.6 cm, 美国Chemplex公司。
本试验中, 共计样品139个, 其中野外采集土壤样品80个(江西鄱阳湖地区), 另外59个为国家土壤标准样品(GSD和GSS系列)。 样品采集和制备方法必须严格按照《土壤环境质量标准》(GB15618— 2018)的技术规范执行。 将采集到的所有土样铺开自然风干, 去除土样中明显的沙子、 草屑等杂物, 使用四分法取其2份, 1份用于实验分析, 1份留作备用。 将国家土壤标准样品和实验分析的土壤样品均匀填入玛瑙钵体中, 用球磨机研磨5 min, 然后过200目筛子。 将处理后的土壤样品使用TS-XH4000便携式XRF分析仪在管压35 keV、 电流40 μ A和时间90 s下, 采集土壤X射线荧光光谱原始数据, 每个样本测量3次, 移动不同位置3次, 最后取平均值作为光谱数据, 共获取样品在0~45 keV范围内共2 048个通道数的光谱信息。
1.3.1 CARS算法原理
CARS算法是模拟生物进化论中的“ 适者生存” 的法则, 每次通过ARS技术和PLS回归系数的绝对值对变量进行筛选, 保留PLS回归系数中的绝对值大的点, 去掉绝对值较小的点, 得到一系列最优子集[7]。 然后使用交叉验证(CV)方法选择模型RMSECV最小值的子集, 并最终将子集确定为与测量元素相关的最佳波长组合。
1.3.2 CARS算法步骤
假设Y表示为m× 1样本目标属性矩阵, X为m× n样本光谱矩阵, 其中m为样本数, n为变量数, α 表示组合系数; T为X与α 的线性组合, 是X的分矩阵; θ 是Y和T所建PLS模型的回归系数向量; 其中, β 和ε 分别表示为n维的回归系数向量和样本预测残差。 假设式(1)和式(2)成立。
式(2)中, 回归系数向量β =α θ =[β 1, β 2, ..., β n], 第i个波长变量对Y贡献, 那么所有波长对Y的总贡献用第i个元素绝对值
式(3)中, 每计算一次wi的过程实际上就是波长变量重要性评估的过程。 将每次计算的|β i|值较大波长变量保留, 然后采用ARS技术从中重新组合新的变量, 在此基础上利用PLS建模, 计算其RMSECV值。 其中, 采样次数设为N, 重复N次, 直到采样结束, 我们将得到最优变量子集集合, 即一系列RMSECV值最小的变量子集。
最后, CARS, PLS, SPA和MC-UVE的算法编写通过Matlab R2016b实现, 而图表绘制由Origin9.0软件完成。
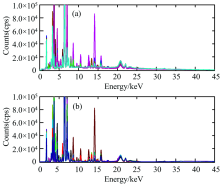
X射线荧光光谱为特征谱, 其中铅元素的Lα 和Lβ 特征峰分别在10.549和12.61 keV附近; 砷元素的Kα 和Kβ 特征峰在10.532和11.729 keV附近。 X射线荧光光谱采集会产生大量的高频随机噪声、 基线漂移和散射等噪声信息干扰, 使X射线荧光光谱与元素含量之间的相关性变差, 导致所建模型的准确性和稳定性会受到影响。 为消除噪声和基线的影响, 尽可能完整保留土壤样品中原始X射线荧光光谱的特征峰, 去噪选用小波变换(sym4小波基), 而校正基线采用适应迭代重加权惩罚最小二乘(airPLS)法[8], 处理结果如图1所示。 最后, 选择处理后的X射线荧光光谱数据进行特征变量选择。
 | 图1 土壤样品光谱的噪声和基线校正结果 (a): 139个土壤样品的原始光谱; (b): 139个土壤样品的去噪声和基线校正光谱Fig.1 Noise and baseline correction results for the spectra of soil samples (a): Raw spectra of 139 soil samples; (b): Denoising and baseline corrected spectra of 139 soil samples |
采用Kennard-Stone(K-S)算法[9]对139个土壤样本进行校正集与验证集的划分。 K-S算法的原理: (1)计算样本两两之间的距离, 选择样本间距离最大的两个作为选中的集合样本, 其余为未选中的集合样本; (2) 对于剩余样本, 分别计算其与选中的两个样本之间的距离; (3)然后选择最短距离与所选样本之间相对最长的距离对应的样本, 作为所选样本集; (4)重复步骤(3), 直到所选样本数等于之前确定的数量, 例如10个或20个。 本实验选取的样本集为校正集, 约70%的铅和砷样品转入校正集, 共97个样品, 剩余42个样本归为预测集。 表1列出了被测土壤中铅和砷实测值的变化范围和平均值(Mean)等统计量。 K-S算法也是通过Matlab R2016b软件完成。
| 表1 土壤铅和砷含量实测值的统计结果 Table 1 Descriptive statistics of measured soil Lead and Arsenic content |
2.3.1 土壤中铅特征波长选择
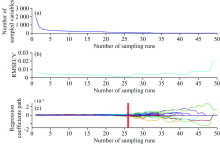
先以铅X射线荧光光谱全部的2 048个波数点作为选择对象, 采用CARS算法筛选样本光谱中与铅相关的光谱波长变量, 筛选结果如图2所示。 从图2(a)中, 我们看到选择的波长变量的数量随着采样次数的增加而减少, 趋势是先快后缓, 说明波长变量先经历了一个粗略的选择过程后再进行精选过程; 图2(b)中, 随着采样次数的增加, RMSECV值先减后增, 即所选波长变量的个数逐渐减少, RMSECV值也在减小, 说明与铅无关的冗余波长变量在CARS变量筛选时优选剔除掉, 而后RMSECV值上升, 说明是剔除了与铅相关的波长变量引起的; 图2(c)中红色“ * ” 处的MC采样次数为26, 此时RMSECV值最小, 经过CARS筛选后, 共选择了60个波长变量, 且所选择的波长变量组合最优。
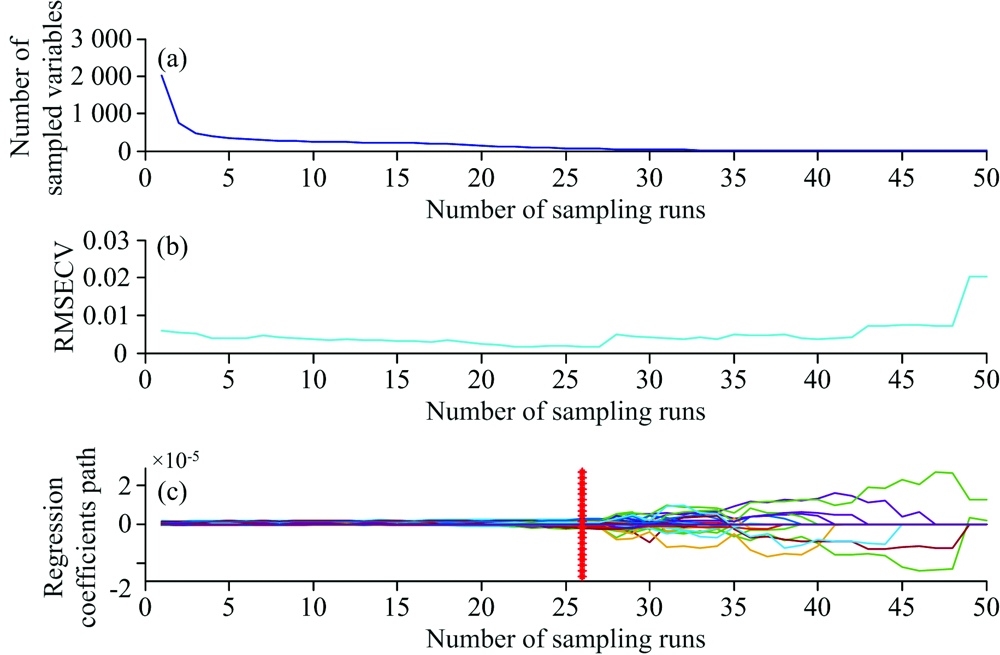 | 图2 土壤中铅的CARS变量筛选结果Fig.2 Plots of CARS variable selection for Lead in soil |
2.3.2 土壤中砷特征波长选择
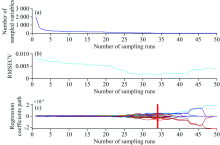
以砷的X射线荧光光谱全部的2 048个波数点作为选择对象, 采用CARS算法筛选样本光谱中与砷相关的光谱波长变量, 筛选结果如图3所示。 类似于上述铅的情况, 从图3(a)中我们可以看到随着采样数增加, 被优选波长变量的数量迅速减少。 在图3(b)中, 在1~34次采样期间, RMSECV值不断减小, 表明变量筛选时去除了与砷含量相关的变量, 但在34个样品后, RMSECV值再次开始上升, 这表明与砷含量相关的重要变量被去除。 在采样为34次时, 即图3(c)中“ * ” 的位置, 出现RMSECV值最小, 共选择了19个波长变量, 所对应的光谱变量子集最优。
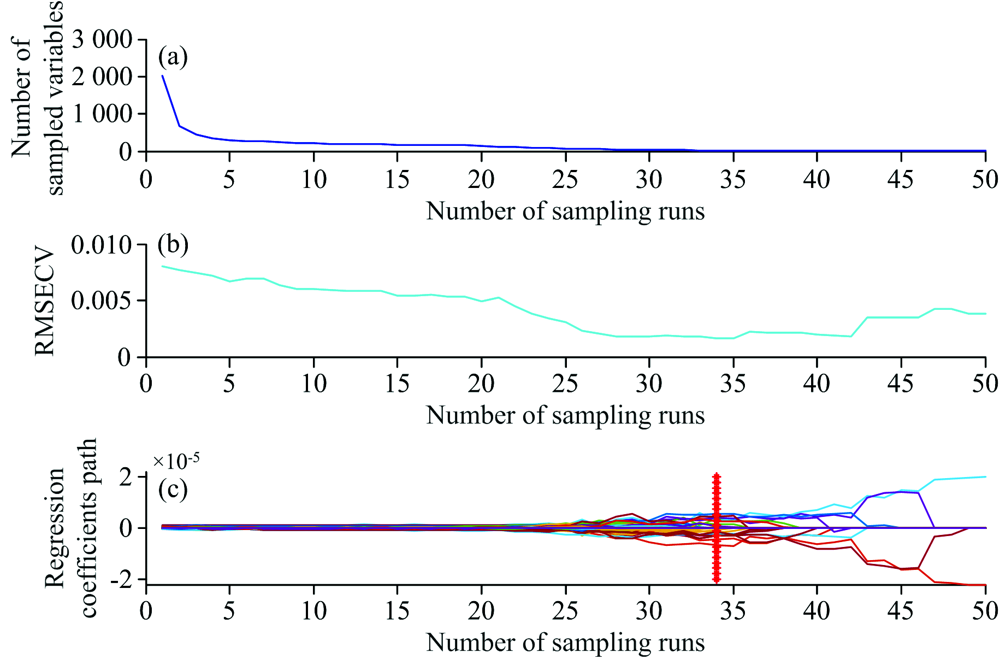 | 图3 土壤中砷的CARS变量筛选结果Fig.3 Plots of CARS variable selection for Arsenic in soil |
CARS模型RMSECV值最小时, 铅和砷对应的最优采样次数和最优变量子集中包含的变量个数如表2所示。
| 表2 土样中铅和砷在RMSECV值最小时对应的采样次数及最优变量子集包含的变量个数 Table 2 Sampling frequency and variable number in optimal variables subset of Pb and As when RMSECV value is lowest in soil samples |
提出采用CARS算法对原始光谱进行波长信息变量筛选, 并与蒙特卡罗无信息变量消除(MC-UVE)和经连续投影算法(SPA)方法进行比较, 然后分别采用偏最小二乘(PLS)方法建立土壤中铅和砷含量的定量检测模型, 评价所建模型的建模效果。 CARS变量筛选方法, 基于蒙特卡罗(MC)交叉验证确定成样次数设置为50次, 可满足其可用的最大因子数。 针对SPA变量选择方法, 其利用向量投影分析原理, 能有效地消除波长之间共线性问题, 分别设置好最小最大波长数, 其最佳波长组合通过交叉验证建模实现, 然后找到具有最小冗余信息的变量组, 最终提高模型精度。 MC-UVE变量选择方法是基于PLS回归系数b的算法, 重复N次, 得到N个回归系数组成的矩阵, 大大减少了最终PLS模型中所包含的变量数量, 模型的复杂度和稳定性得到改善。 其中SPA和MC-UVE变量选择方法的具体原理和步骤见文献[10, 11, 12]。
采用决定系数(R2)、 交互验证均方根误差(RMSECV)、 预测均方根误差(RMSEP)和模型相对预测误差(RPD)等4个参数来评价PLS模型性能。 其中, R2值越接近于1, 模型的拟合度和稳定性越好; RMSECV和RMSEP值越小, 模型预测能力越强; RPD值等于样本标准偏差与均方根误差的比值。 如果RPD≥ 3, 认为所建立的模型预测效果良好, 具有良好应用价值; 如果2.25≤ RPD< 3, 则认为所建立的模型预测效果较好, 具有较好实际应用价值; 如果1.75≤ RPD< 2.25, 则认为模型可用, 模型对样本能进行粗略评估; 如果RPD< 1.75, 模型预测效果差, 无法预测样本。
2.4.1 土壤中铅的PLS模型的建立与验证
经CARS, SPA及MC-UVE变量筛选后, 采用PLS方法建立土壤中铅含量的定量检测模型, 建模结果见表3。 从表3可以看出, 经过CARS筛选后, CARS-PLS模型铅的波长变量数从2 048减少到60个, 模型最优, 所得建模集的R2, RMSECV, RMSEP和RPD分别为0.997 3, 2.610 1, 3.322 1和9.351 8, 预测集的R2, RMSECV, RMSEP和RPD分别为0.995 5, 2.598 6, 3.228和9.401 1; 与CARS-PLS模型相比, 虽然SPA-PLS和MC-UVE-PLS模型建模的波长变量更少, 但建模集和预测集的R2, RMSECV, RMSEP和RPD均劣于CARS-PLS模型。 另外, 从表3还发现, 与全波段PLS模型相比, SPA-PLS模型的预测集R2, RMSECV, RMSEP和RPD分别0.980 5, 3.549 5, 5.344 5和8.611 4, 劣于全波段PLS模型, 模型的稳定性不如PLS, MC-UVE-PLS和CARS-PLS模型。
| 表3 土样中铅定量检测的PLS建模结果 Table 3 PLS modeling results of quantitative determination of Lead in soil samples |
2.4.2 土壤中砷的PLS模型的建立与验证
经CARS, SPA及MC-UVE变量筛选后, 采用PLS方法建立土壤中砷含量的定量检测模型, 建模结果见表4。 从表4可以看出, 砷CARS-PLS模型的波长变量数由2 048个减少到19个, 与全波段PLS, SPA-PLS和MC-UVE-PLS模型相比, 砷的CARS-PLS模型建模集和预测集的R2, RMSECV, RMSEP和RPD值均最优, 所建模型效果最好。 与其他三个模型相比, 虽然SPA-PLS模型的波长变量最少, 但建模集和预测集的R2, RMSECV, RMSEP和RPD均劣于CARS-PLS和MC-UVE-PLS模型, 仅优于全波段PLS模型。
| 表4 土样中砷定量检测的PLS建模结果 Table 4 PLS modeling results of quantitative determination of Arsenic in soil samples |
从以上结果可以看出, CARS-PLS模型定量检测土壤中的铅和砷要优于全波段PLS, SPA-PLS及MC-UVE-PLS 模型, 表明CARS方法在X射线荧光光谱的波长变量选择方面具有较明显优势, 可以筛选出有用的波长信息变量并去除多余的波长变量, 来提高模型的准确性和稳定性。
图4显示了四种模型的预测值与传统化学方法测定值之间的相关关系。 CARS-PLS模型铅砷预测值与其实验室分析值或标准值最为接近, 线性最好。 这进一步说明CARS算法可以有效筛选波长变量, 且用更少的变量建立更好的铅砷定量分析模型。
 | 图4 各模型铅、 砷校正集真实值与预测值对比Fig.4 Comparison of measured values and predicted values of Lead and Arsenic corrected Set of each model |
采用CARS波长变量筛选算法, 建立了土壤中X射线荧光光谱定量分析重金属铅和砷含量检测模型(CARS-PLS ), 筛选出具有较高适用性的波长变量子集组合, 实现了铅和砷含量的准确预测。 具体结论如下:
(1)通过对土壤中铅和砷的X射线荧光光谱进行建模, 结果表明CARS方法是一种有效的波长变量选择方法, 在降低模型的维数同时还剔除了多余的干扰信息, 使模型的计算效率和稳健性得到提升。
(2)采用CARS方法对土壤中铅和砷的波长信息变量进行筛选, 分别筛选得到60和19个波长变量作为预测铅和砷的优选变量集。
(3)与全波段PLS, SPA-PLS和MC-UVE-PLS模型相比, 采用CARS-PLS所建模型具有最优的预测精度和预测能力, 同时有效减少了波长变量。
由于此次试验采用的土壤样品经过晾干、 筛分等物理前处理过程, 消除了土壤含水率、 粒径等因素对检测结果的影响, 所建立的铅砷的定量分析模型在现场的准确性如何是下一步研究的重点。 另外, 在应对极低浓度元素时会受到一定噪声影响, 在做波长变量筛选时, 会影响建模的结果, 这也是我们下一步需要优化的地方。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|