


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于红外光谱的城市生活垃圾高值化利用深度分选
[胡斌1, 2  , 付浩
, 付浩1 , 王文斌1 , 张兵1, 2 , 唐帆3, * , 马善为1, 2 , 陆强1, 2, * ]
, 付浩, 马善为]
|
|


作者简介: 胡 斌, 1992年生, 华北电力大学新能源学院讲师 e-mail: binhu92@126.com
红外光谱分析具有快速、 精确度高等优点, 在分类鉴别领域中发挥着重要作用。 红外光谱在生活垃圾分类领域的应用主要集中在塑料等可回收垃圾而忽略了对不可回收垃圾的深度分选。 现行生活垃圾的四分法分类中, 源头分类得到的其他垃圾中含有多种具有高值化利用潜力的组分, 可分为纤维素类、 烯类聚合物、 木竹类等。 这些垃圾的成分和结构不同, 因此具有不同的红外谱图, 基于其红外谱图特征波段利用机器学习建立相应的分类模型可以将上述几类垃圾从其他垃圾中分选出来。 本研究收集了纤维素类、 烯类聚合物、 木竹类及低值类垃圾, 并采集红外光谱数据共72组, 对比分析了预处理方式、 降维程度和建模算法对模型分类准确率的影响。 利用标准正态变量变换(SNV)、 多元散射校正(MSC)、 求导(DC)和平滑滤波(Smooth)方法对数据进行预处理, 然后利用主成分分析法(PCA)对预处理后的数据进行降维, 获得72×8和72×5的数据集。 分别利用概率神经网络(PNN)、 广义回归神经网络(GRNN)、 支持向量机(SVM)和随机森林(RDF)算法进行建模。 分析结果表明, 经PCA降维后的数据用于后续建模时, 5维数据比8维数据得到的分类效果更好, 平均准确率上升2.4%~4.4%。 基于5维降维数据, DC/Smooth预处理方法比SNV和MSC预处理得到的平均准确率更高, 达到了96.5%; PNN模型比其他三类模型的平均准确率高4.2%~6.5%, 可达98.1%; 针对四类垃圾, 除烯类聚合物的平均判别率只有93.8%外, 纤维素类及木竹类的平均判别率均在95%以上, 低值类最高可以到达100%。 验证了红外光谱结合机器学习实现其他垃圾深度分选的可能性及科学性, 为未来开发快捷深度分选设备提供参考。
Due to the advantages of high speed and high accuracy, infrared spectra play a vital role in classification and identification. For municipal solid wastes, the application of infrared spectra mainly focuses on recyclable garbage such as plastics, neglecting the deep separation of the non-recyclable wastes. Based on the current “Quartering Method” of municipal solid wastes, the residual wastes contain various high-value potential ingredients that can be sorted into cellulose, vinyl-polymers, and woods. These ingredients have different constituents and structures, so they have different infrared spectra. Therefore, the useful constituents can be further separated from the residual wastes by combing their infrared spectra and the machine learning classification models. This study collected cellulose, vinyl-polymers, woods, and low-value residual wastes, and 72 groups of infrared spectra data were obtained. The influence of data preprocessing, dimension reduction and algorithms on the sorting models' accuracy was investigated. Infrared spectra data were preprocessed by standard normal variate (SNV), multiplicative scatter correction (MSC), derivative correction (DC), and smooth. Principal component analysis (PCA) was used to reduce the dimension of the preprocessed data, and 72×8 and 72×5 datasets were obtained. Sorting models were built using probabilistic neural network (PNN), generalized regression neural network (GRNN), support vector machine (SVM), and random forest (RDF) algorithms. As a result, the classification accuracy of 5-Dimensional data was superior to that of 8-Dimensional data, with the average accuracy increasing 2.4%~4.4%. Based on 5-Dimensional data, DC/Smooth preprocessing achieved the highest average accuracy of 96.5% among the three preprocessing methods. The average accuracy of the PNN model was 4.2%~6.5% higher than the other three sorting models, up to 98.1%. As for the four types of residual wastes, the sorting accuracy for vinyl polymers was 93.8%, it was over 95% for cellulose and woods, and it could be up to 100% for the low-value wastes. This study examined the possibility and scientific potentiality of the combination of infrared spectroscopy and machine learning to achieve the deep sorting of residual wastes, providing a theoretical basis for the future development of fast and accurate deep separation equipment of municipal solid wastes.
红外光谱是分析物质成分的有力工具, 广泛应用于食品、 化工、 现代医学等领域, 具有所需样本量小、 不破坏样本、 快速、 简便、 精确度高等优点[1, 2]。 随着计算机科学的发展, 红外光谱与机器学习的联合使用在分类鉴别领域得到了广泛应用[3, 4, 5]。 在垃圾分类研究中, 基于红外光谱检测与机器学习建模的分类鉴别方法主要用于可回收垃圾的精细分选。 不同类别塑料垃圾的近红外光谱特征波段具有显著差异, 利用机器学习方法可以有效地识别不同种类的塑料, 进行精细分选, 且目前已有多种近红外光谱塑料分选设备问世[6]。 然而, 近红外光谱对于深色垃圾的分选仍存在一定的局限性。 近期, 赵冬娥等[7]利用高光谱成像和光谱角填图法、 Fisher判别方法提出了纸质、 塑料和木质三类可回收垃圾的分类方法, 准确率超过97%, 为城市可回收类垃圾的高效分选打下了基础。
随着我国城市垃圾源头分类“ 四分法” 的稳步推进, 有害垃圾、 厨余垃圾和可回收垃圾得到了有效分离, 剩余的其他垃圾组分十分复杂, 资源化利用难度较大, 其主流处理方法仍为较为粗犷的焚烧发电和卫生填埋。 事实上, 其他垃圾的总量十分可观, 通常占生活垃圾总量的30%[8], 其中含有废纸张、 废塑料、 废橡胶、 织物、 木竹等多种有机组分, 这些组分可以进一步高值化利用。 举例来说, 废纸张中主要成分为纤维素, 利用固体酸催化热解纤维素可以高选择性地制备左旋葡聚糖[9]; 塑料和化纤织物等烯类聚合物可以经催化热解联产碳纳米管和富氢气体[10]; 木竹类是典型的生物质资源, 恰当的预处理后可以热解生产高品质的生物油或生物炭[11]。 这些组分的红外光谱特征波段差异显著, 彼此之间具有较大的区分度[6, 12, 13], 可以基于红外光谱数据利用机器学习方法建立其他垃圾深度分选模型, 然而, 相关的分类模型还少有报道。
现阶段, 基于红外光谱和机器学习方法从源头分类获得的其他垃圾中深度分选出高值组分的研究还有相当大的发展空间, 特别是高效机器学习模型仍有待建立。 依据其他垃圾的主要成分和利用手段, 可以将其分为: 纤维素类、 烯类聚合物、 木竹类、 低值类。 本研究将依靠红外谱图和机器学习, 建立其他垃圾高值化利用的深度分选模型, 为未来城市生活垃圾的自动化分选以及高值化利用提供科学依据。
采集纤维素类、 烯类聚合物、 木竹类及低值类四类其他垃圾样本共18件。 样本选取上尽可能接近实际生产生活中其他垃圾受污染程度, 具体实验材料如表1所示。 四类样本的特征如下: (1)纤维素类, 主要成分是纤维素及其衍生物, 收集的样本包括打印纸、 草纸、 一次性纸杯、 棉布、 烟头等; (2)烯类聚合物, 多数为受污染的塑料或人造织物, 具有耐腐蚀且难降解的特点, 收集的样本包括方便面包装盒、 食品包装袋、 快餐包装纸、 奶茶杯、 腈纶标签等; (3)木竹类, 以自然界植物枝干叶子为主, 主要成分为纤维素、 半纤维素、 木质素等, 与纤维素类的主要区别是含有较高比例的木质素, 并非仅含有单一的纤维素组分, 收集的样本包括竹扇、 落叶、 干树枝、 木质铅笔、 一次性筷子等; (4)低值类, 无机物含量相较其他类别较高, 深度分选后无更多高值化利用方式, 主要以卫生填埋或者焚烧处理, 收集的样本包括棒骨、 陶瓷、 贝壳等。
| 表1 其他垃圾实验材料 Table 1 Residual waste materials |
使用美国PerkinElmer公司生产的Spectrum 100N FT-IR傅里叶变换红外光谱仪, 选用衰减全反射红外光谱技术采集光谱数据。 每个样本分别选取四个不同特征点, 每个特征点采集6次光谱信息, 取平均值为该点的光谱反射率数据。 红外光谱实验背景为空气, 光谱范围是650~4 000 cm-1波段, 分辨率为4 cm-1。 最终, 18件样本共得到72组光谱数据, 每组光谱数据为1× 3 351的一维线性矩阵, 整体构成72× 3 351的光谱反射率数据矩阵, 如式(1)所示, 其中m=72, 为实验样本总数, n=3 351, 为每个样本对应650~4 000 cm-1波段的红外光谱反射率数据。
为消除实验室光源及仪器发热等干扰因素带来的噪音, 分别采用标准正态变量变换(standard normal variate, SNV)、 多元散射校正(multiplicative scatter correction, MSC)、 导数处理联合平滑滤波(derivative correction/smooth, DC/Smooth)对原始光谱数据进行预处理。 其中, SNV、 MSC主要用于消除在光谱数据采集过程中固体颗粒大小、 表面散射及光程变化而产生的影响; DC/Smooth联合预处理可以有效处理红外光谱数据中的高频噪音和基线平移, 提高光谱数据的灵敏度与分辨率[14]。
对预处理后的光谱数据以主成分分析法[15](principal composition analysis, PCA)进行降维处理。 以预处理光谱反射率数据72× 3 351矩阵作为输入参数, 计算数据矩阵的协方差矩阵, 求解其特征值及特征向量, 选择其中k个特征值所对应的特征向量, 构成矩阵Wn× k。 以式(2)计算得到降维后的数据Zm× k, 其中k为PCA处理后的数据维度。 以式(3)和式(4)计算降维后数据贡献度, 其中Zi为第i个主成分, a1为对应样本集标准化矩阵特征值λ i的特征向量。 使k个主成分的累计贡献度α i超过90%, 第k+1及以后的累计主成分贡献率小于10%。
为筛选合适的其他垃圾深度分选模型, 采用4种具有代表性的分类判别方法进行对比: 概率神经网络(probabilistic neural network, PNN)、 广义回归神经网络(general regression neural network, RNN)、 支持向量机(support vector machine, SVM)及随机森林(random decision forests, RDF)。 PNN与GRNN鉴别模型具有优秀的非线性映射能力及学习速度, 在处理少量样本数时, 判别效果很好, 处理不稳定数据集时也有较好效果; SVM模型具有较为良好的泛用性, 在面对分类条件复杂时, 具有突出的判别能力; RDF是使用多棵决策树对样本训练并判别的一种分类器, 该算法参数选择较少, 不需要担心过度拟合, 并拥有较强的抗噪声本领。
为弥补样本量少的缺点和提高最终测试结果的可信度, 采用留一法交叉验证用于模型的建立。 每个模型以准确率(Accuracy)、 均值及标准误差作为判评标准, 准确率计算方法如式(5)所示, 其中TP和FP分别代表测试样本中被正确分类的样本个数与被错误分类的样本个数。
采集的原始红外光谱如图1所示, 对比文献[6, 12, 13]可知, 采集的四类垃圾样本的红外数据在各类垃圾中具有典型性, 能够较好地涵盖上述四类垃圾的特征红外波段。 图1(a)中, 纤维素类样本在2 800~2 900 cm-1附近存在两个较强的吸收峰, 是甲基、 亚甲基中碳氢键的振动吸收峰, 1 100~1 200 cm-1附近存在的强吸收峰, 是醚键、 羟基中碳氧键的吸收峰; 图1(b)所示的烯类聚合物样本在800和1 300 cm-1处是不饱和C=C键的吸收峰; 图1(c)中, 木竹类样本与纤维素类样本的明显区别在1 600 cm-1附近的吸收峰, 是其所含木质素组分苯环的吸收峰、 3 300 cm-1附近是羟基及其形成的氢键所对应吸收峰; 而图1(d)所示的低值类样本由于无机物含量较高, 除1 000 cm-1附近碳氢吸收峰以外, 其他吸收峰均相对平缓。 由此可见, 四类样本具有不同的红外光谱特征, 这是分类模型建立的重要前提; 此外, 机器学习方法还能够基于人为难以鉴别的特征建立精细的分类模型。
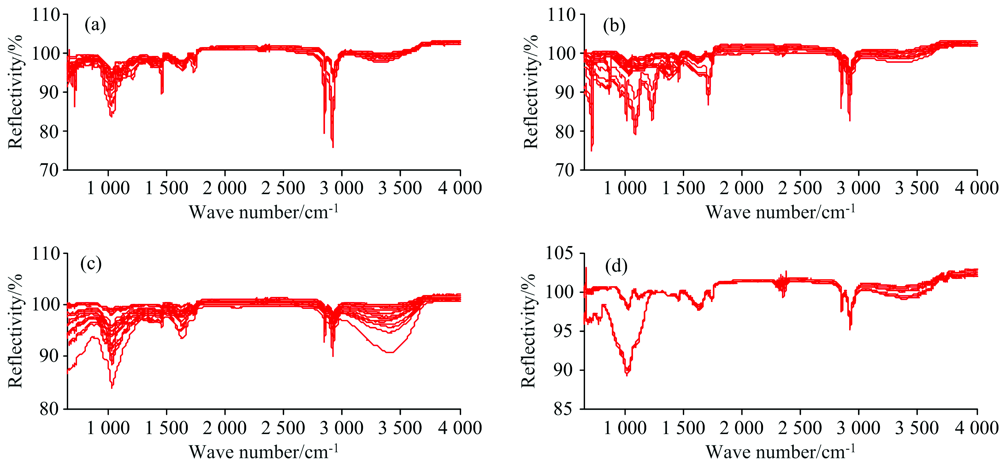 | 图1 纤维素类(a)、 烯类聚合物(b)、 木竹类(c)和低值类(d)的原始红外光谱Fig.1 Original infrared spectra of cellulose (a), vinyl polymers (b), woods (c) and low-value wastes (d) |
分别采用SNV, MSC及DC/Smooth对原始红外光谱进行预处理。 如图2和图3所示, 经SNV和MSC预处理后规避掉了很多不必要的杂乱数据, 使光谱数据整齐有序。 此外, 两种预处理方法的效果很接近, 因此最终分类模型的预测结果应当也较为接近, 这将在后续进一步讨论。 如图4所示, 经DC/Smooth联用预处理后, 红外光谱谱图具有明显变化, 低值类垃圾的谱图区分度更加明显。 对比上述预处理后的光谱数据, 可以发现四类垃圾的光谱数据在特征波段仍然具有显著的区别。
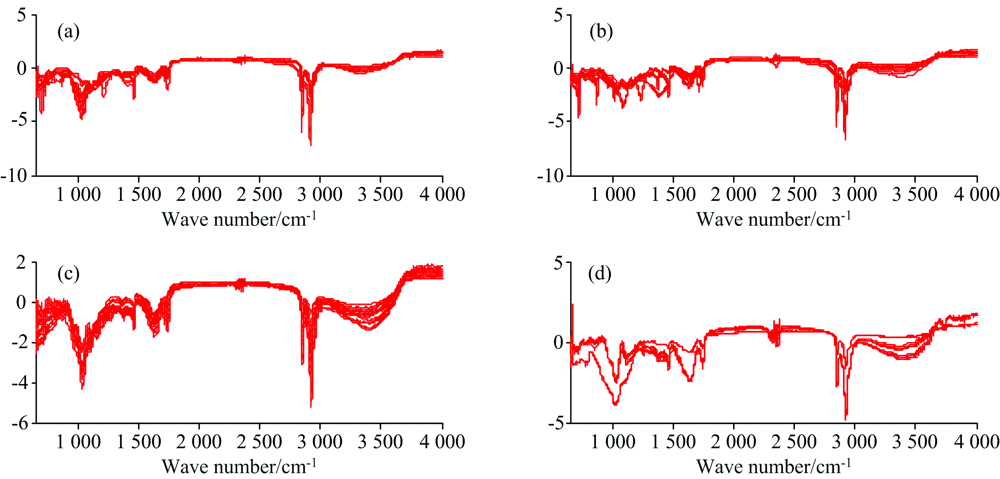 | 图2 SNV预处理后的纤维素类(a)、 烯类聚合物(b)、 木竹类(c)和低值类(d)红外光谱Fig.2 SNV pretreated infrared spectra of cellulose (a), vinyl polymers (b), woods (c) and low-value wastes (d) |
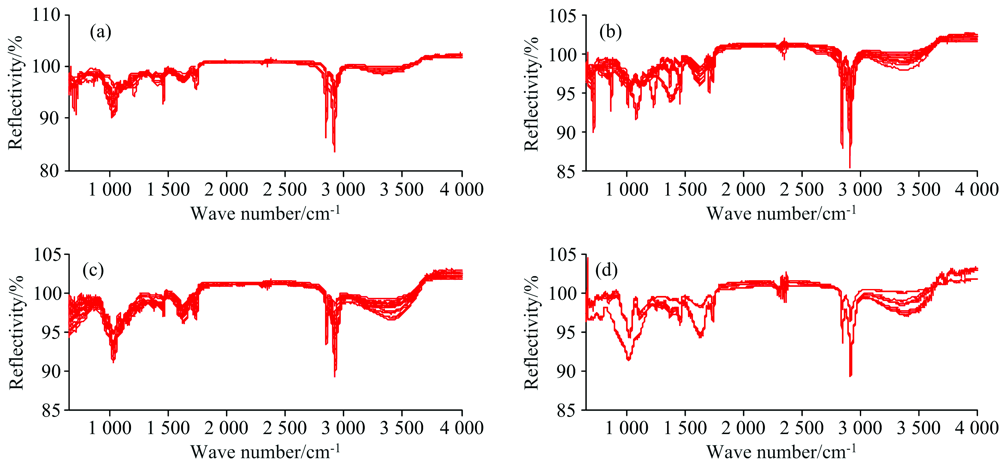 | 图3 MCS预处理后的纤维素类(a)、 烯类聚合物(b)、 木竹类(c)和低值类(d)红外光谱Fig.3 MCS pretreated infrared spectra of cellulose (a), vinyl polymers (b), woods (c) and low-value wastes (d) |
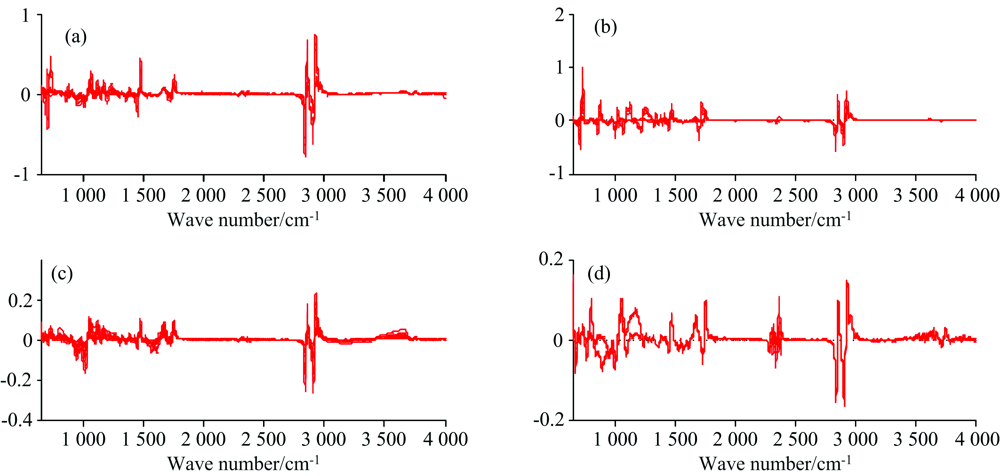 | 图4 DC/Smooth预处理后的纤维素类(a)、 烯类聚合物(b)、 木竹类(c)和低值类(d)红外光谱Fig.4 DC/Smooth pretreated infrared spectra of cellulose (a), vinyl polymers (b), woods (c) and low-value wastes (d) |
SNV, MSC及DC/Smooth预处理数据经PCA降维后得到主成分特征值和方差贡献率, 前8维主成分数据列于表2。
| 表2 SNV, MSC及DC/Smooth预处理数据集经PCA处理后主成分的特征值和方差贡献率 Table 2 The principal component eigenvalues and variance contribution of SNV, MSC and DC/smooth datasets |
由表2可知, 预处理后的数据经过降维后的前5维主成分累计贡献率均达到90%以上, 第8维及以后主成分的贡献率低于1%。 其中, SNV预处理后的红外光谱数据经PCA降维后得到的8维和5维数据, 对原始红外光谱数据的贡献率分别达到了96.5%和91.0%。 类似地, MSC预处理后的数据经PCA降维得到73× 8和72× 5的数据集, 贡献率分别为97.1%和91.5%; DC/Smooth预处理后的数据经PCA降维得到72× 8和72× 5的数据集, 贡献率分别为97.1%和93.3%。 对比5维和8维数据, 5维数据更加简练并可以反映原始数据的大部分信息, 而8维数据相比于5维数据对原始数据的累计贡献率更高(3.8%~5.6%), 后续将分别以5维和8维数据用于模型建立, 进一步探讨数据降维程度对模型的影响。
由表2可以看出, 第1、 2维主成分对于原始数据的贡献率最高, 提取以上三种预处理数据降维后第1、 2主成分的载荷因子, 取平均值绘制载荷因子图谱, 如图5所示。 由图可知, 在680, 1 000, 1 200, 1 300, 1 500, 1 650, 2 300, 2 800~2 900及3 300 cm-1等处具有明显振动, 说明这些波段在数据中发挥更高的作用。
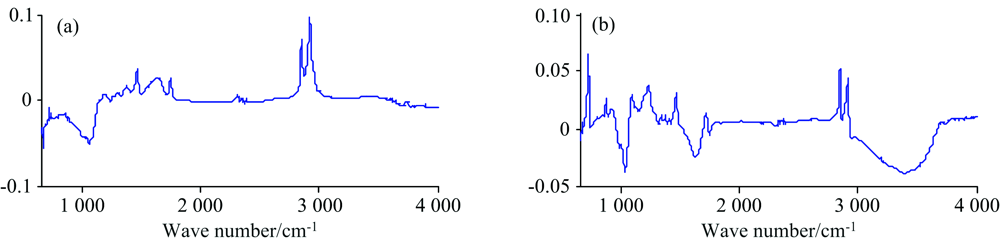 | 图5 经PCA降维后的第1(a)和2(b)主成分载荷分析谱图Fig.5 The first (a) and second (b) principal component load analysis spectra |
以PCA降维后得到的72× 8和72× 5数据集作为输入参数, 分别建立PNN, GRNN, RDF及SVM判别模型, 结果分别列于表3和表4。
| 表3 分类模型的准确率对比(基于72× 8数据集) Table 3 Comparison of classification model accuracies (based on 72× 8 dataset) |
| 表4 分类模型准确率对比(基于72× 5数据集) Table 4 Comparison of classification model accuracies (based on 72× 5 dataset) |
由表3可知, 红外光谱数据预处理后所建立的高值化深度分选模型平均准确率接近甚至超过90%, 相较未经预处理的模型平均准确率上升5.5%~11.2%, 其中SNV, MCS及DC/Smooth三种预处理方式的平均准确率为89.4%, 88.4%及94.1%。 如图2和图3所示, SNV和MCS预处理后得到的光谱特征波段相近, 导致基于两种预处理方式所建分类模型的鉴别能力相当。 DC/Smooth联合预处理获得的预测平均准确率最高, 这是由于导数处理(DC)可有效消除其他背景的干扰, 分辨重叠峰, 提高分辨率和灵敏度; Smooth可以防止导数处理的信噪比降低、 部分噪声放大。 对比表3和表4中数据发现, 不同数据降维程度下, 三类预处理方式对应的分类准确率相对关系是一致的。 相比之下, 72× 5数据集得到的预测准确率整体有所提高, SNV, MCS及DC/Smooth三种预处理方式对应的平均准确率分别为93.8%, 92.4%及96.5%, 准确率提高了2.4%~4.4%。 表3中, DC/Smooth联合预处理的准确率均方根误差较未处理有所上升, 而SNV和MSC预处理后的均方根误差明显降低; 对于5维数据, SNV和MSC预处理的均方根误差较未预处理有所升高, 而DC/Smooth联合预处理有所下降。 由表2可知, 三种预处理方式得到的数据经过降维后的前5维主成分累计贡献率即达到90%, 而第6~8维数据对于原始数据的贡献很低(0.9%~3.1%), 这表明8维数据相比于5维数据增加了无效数据, 尽管对原始数据的贡献率更高, 但是预测效果反而不如5维数据。 针对同一预处理方法所得数据集, 对比四类分类模型预测准确率的均方根误差, 8维数据得到的分类模型整体稳定性更高, 这是因为5维数据去掉了更多的次要信息, 从而使得不同建模算法更具区分度, 更利于筛选合适的建模算法。
对比表3中四类分类模型可以看出, SVM模型平均准确率最高, 达到了92.0%; PNN模型与RDF模型的平均准确率较SVM模型低, 但整体准确度在生产生活实践接受范围内; GRNN的平均准确率最低, 但均方根误差明显低于其他模型, 因此该模型最为稳定, 而其他三类模型的稳定性几乎相同。 预测准确率最高的是通过DC/Smooth联合预处理的SVM模型, 正确率达到了97.2%。 对比表3和表4数据可以发现, 数据降维对四种分类模型的平均准确率和均方根误差的影响并不相同。 对于5维数据, PNN和GRNN模型的分类准确率较8维数据有明显提升(7.5%和5.2%), 其中通过DC/Smooth联合预处理的PNN模型及SNV预处理的GRNN模型的准确率都达到了100%。 此外, 5维数据的GRNN模型的稳定最差, 均方根误差为5.6%, 和8维数据得到的结果完全相反, 这是由于GRNN模型对数据维度的敏感性, 维度降低导致数据失真程度变高, 进而导致稳定性的下降。 综合来看, 以上四种鉴别模型均具备快速、 准确深度分选四类垃圾的潜力, 其中, SVM和PNN模型分别基于DC/Smooth预处理的8维和5维数据获得最高的分类准确率最大值和平均值, 且稳定性相对较好。
由于DC/Smooth联合预处理数据得到的预测准确率更高, 进一步基于DC/Smooth预处理比较了四类模型的对四类垃圾分类的准确性, 预测结果如表5和表6所示。 由表5可知, 依据72× 8的降维数据, 对烯类聚合物垃圾的预测准确率最低, 80个样本中正确预测数只有72, 平均准确率只有90.0%, 这是因为烯类聚合物种类多, 具有不同的红外光谱特征波段; 同时, 这也导致了烯类聚合物预测的均方根误差最高, 稳定性较差。 对于纤维素类与木竹类来说, 四种模型共80个样本, 正确预测数均为75, 平均准确率为95.0%, 均方根误差均为4.1%, 表明这两类垃圾红外光谱有很多区分度相近的特征波段数据, 分类模型对其分类能力基本相同。 四种分类模型对低值类垃圾的分类判别结果最优, 48个样本只有一个误判, 平均准确率达到97.9%, 相对其他类别准确率上升2.9%~7.9%, 而其均方根误差与纤维素类及木竹类相近, 模型稳定性较强, 这是因为低值类垃圾组分中无机物含量较多, 红外光谱特征波段与其他类别分辨率大。 对比表5与表6可知, 四种分类模型对四类垃圾分选的平均准确率由高到低依次是: 低值类, 纤维素类、 木竹类及烯类聚合物; 5维数据相比于8数据, 平均分类准确率上升1.3%~2.5%, 其中, 基于5维数据低值类分类平均准确率可以达到100%; 5维数据对应分类模型的均方根误差相较8维数据下降1.2%~4.2%, 对四类其他垃圾分类判别稳定性有所上升。
| 表5 四类其他垃圾分类准确率对比(基于72× 8 DC/Smooth预处理数据) Table 5 Comparison of classification accuracies for the four kinds of residual wastes (based on 72× 8 DC/Smooth dataset) |
| 表6 四类其他垃圾分类准确率对比(基于72× 5 DC/Smooth预处理数据) Table 6 Comparison of classification accuracies for the four kinds of residual wastes (based on 72× 5 DC/Smooth dataset) |
上述结果表明, 基于红外光谱检测和机器学习建立垃圾深度分选模型具有可行性。 需要说明的是, 对于预测中出现的误差, 可能是由于实验样本量少, 导致同一类别中红外光谱数据偏差大, 特别是烯类聚合物的种类较多, 所以上述模型对烯类聚合物的鉴别准确率最低。 此外, 由于源头分类结果不一、 垃圾受污染程度参差不齐, 导致红外光谱信息波动, 因此在实际应用中还存在较大的不确定性, 这将在后续的模型优化研究中考虑。
基于城市生活垃圾“ 四分法” 源头分类, 针对其他垃圾中不同组分的高值化潜力, 将其他垃圾分为纤维素类、 烯类聚合物、 木竹类及低值类, 利用红外光谱和典型分类器建立了其他垃圾深度分选模型, 对比分析了预处理方式、 降维程度和建模算法对分类准确率的影响, 主要结论如下:
SNV, MSC和DC/Smooth联合预处理三类预处理方法中, DC/Smooth联合预处理的数据用于后续建模得到的分类准确率最高、 稳定性最强; 经PCA降维后的数据用于后续建模时, 5维数据比8维数据得到的分类性能更强, 整体准确率上升2.4%~4.4%; 基于5维降维数据, DC/Smooth预处理方法比SNV和MSC预处理得到的平均准确率更高(96.5%), PNN模型比其他三类模型的平均准确率更高(98.1%), 其中, DC/Smooth预处理的PNN模型及SNV预处理的GRNN模型的分类准确率都达到了100%, 用来建立其他垃圾深度分选模型效果最为优异。 针对四类其他垃圾, 除烯类聚合物的平均判别率只有93.8%以外, 纤维素类、 木竹类及低值类的平均分类准确率均在95%以上, 最高可以达到100.0%。
通过红外光谱及机器学习实现了其他垃圾高值化利用的深度分选模型的建立。 未来开发快捷准确的其他垃圾深度分选技术, 还需要在考虑源头分类结果均一程度和垃圾受污染程度的基础上, 扩大模型学习样本, 同时优化分类算法, 进一步提升模型的分类准确率、 稳定性和对实际垃圾样本的适应性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|