




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
优化FCOS网络复杂果园环境下绿色苹果检测模型
[张中华1  , 贾伟宽
, 贾伟宽1, 2, * , 邵文静1 , 侯素娟1 , Ji Ze3 , 郑元杰1 ]
, 贾伟宽, 邵文静|
|


作者简介: 张中华, 1997年生, 山东师范大学信息科学与工程学院硕士研究生 e-mail: zzhs9714@163.com
目标果实的精准识别是实现果园测产和机器自动采摘的基本保障。 然而受复杂的非结构化果园环境、 绿色苹果与枝叶背景颜色接近等因素的影响, 制约着可见光谱范围下目标果实的检测精度, 给机器视觉识别带来极大挑战。 针对复杂果园环境下的不同光照环境和果实姿态, 提出一种优化的一阶全卷积(FCOS)神经网络绿色苹果识别模型。 首先, 新模型在FCOS的基础上融合了卷积神经网络(CNN)的特征提取能力, 消除了对锚框的依赖, 以单阶段、 全卷积、 无锚框的方式预测果实置信度与边框偏移, 在保证检测精度的前提下提升了模型的识别速度; 其次, 增加了自底向上的特征融合架构, 为模型提供了更加准确的定位信息, 进一步优化绿色苹果的检测效果; 最后根据FCOS末端三个输出分支设计整体损失函数, 完成模型训练。 为尽可能模拟真实果园环境, 分别采集不同光照环境、 光照角度、 遮挡类型、 摄像距离的绿色苹果图像, 制作数据集并用以模型训练。 挑选最优训练模型在包含不同场景的验证集上进行评估, 结果为: 在检测效果方面, 平均精度为85.6%, 与目前最先进的检测模型Faster R-CNN, SSD, RetinaNet, FSAF相比, 分别高出0.9, 10.5, 2.5, 1.9个百分点; 在模型设计方面, FCOS的模型参数量与整个检测流程所需的计算量分别为32.0 M和47.5 GFLOPs (10亿次浮点运算), 与Faster R-CNN相比, 分别降低了9.5 M和12.5 GFLOPs。 对比表明, 在可见光谱范围下, 对复杂果园环境中绿色苹果, 提出的新模型具有更高的检测精度和识别效率, 为苹果果园测产和自动化采摘提供理论和技术支撑; 也可为其他果蔬的球形绿色目标果实识别提供借鉴。
In the visible spectrum range, the accurate recognition of target fruit is the fundamental guarantee for achieving orchard yield measurement and machine automatic picking. However, this task is susceptible to many interferences, such as the complex unstructured orchard environment, the close color between green apples and background leaves, etc., which significantly restrict the detection accuracy of target fruits and bring great challenges to recognition of machine vision. It targeted the different illumination environments and fruit postures under the complex orchard environment. An optimized convolution and one-stage (FCOS) fully neural network model for green apple recognition is proposed in this study. Firstly, the new model combines the feature extraction ability of convolutional neural network (CNN) based on FCOS, eliminates the dependence of previous detectors on anchor boxes, and switches to a novel manner of one-stage, full convolution and anchor-free for predicting the fruit confidence and boxes offsets, which greatly improves the recognition speed of the model while ensuring the detection accuracy simultaneously. Secondly, the bottom-up feature fusion architecture is embedded after the feature pyramid to provide more accurate positioning information for high -levels and thus further optimize the detection effect of green apple. Finally, the overall loss function is designed to complete the iterative training given three output branches of FCOS. To simulate the real orchard environment as possible, we collected green apple images in various environments with different lighting environments, illumination angle, occlusion type, camera distance for data sets generation and model training, and then evaluated the optimal model on validation set containing different scenes. The experimental results show that our proposed model's average precision (AP) is 85.6%, which is 0.9, 10.5, 2.5 and 1.9 percentage points higher than the state-of-the-art detection models Faster- R-CNN, SSD, RetinaNet and FSAF, respectively. In the aspect of model design, the model parameters of FCOS and the calculation of the whole detection process are 32.0 M and 47.5 GFLOPs (billion floating-point operations), respectively, which are 9.5 M and 12.5 GFLOPs lower than those of Faster R-CNN. Comparisons of experimental results show that the new model has higher detection accuracy and recognition efficiency in the visible spectrum, which can provide theoretical and technical support for orchard yield measurement and automatic picking. In addition, the new model can also provide theoretical references for other kinds of fruits and vegetables.
在实际苹果园环境下, 目标果实的精准识别是实现果园测产和自动采摘的基础, 果园的自动化和智能化作业是苹果产业的发展以及缓解农业劳动力缺乏的重要保障。 受非结构化的复杂环境制约, 当前机器视觉系统难以应对各种干扰, 如果实受枝叶遮挡、 果实间相互重叠、 光照角度和强度、 天气等因素; 特别是绿色苹果由于与实景颜色极为接近, 进一步加大了识别难度, 容易出现漏检或果实与叶片之间的混检。 绿色苹果的高效识别和精准定位是实现果园智能作业的关键。
在可见光谱范围, 利用传统的机器学习在水果检测等方面积累了一定的研究基础[1, 2, 3], 然而这些方法大多基于目标果实的颜色、 纹理、 形状等其他表征的组合进行目标果实的检测, 当果实由于光照强度、 角度或自然环境变化等因素出现纹理特征不明显, 枝干、 树叶遮挡或果实间相互重叠等因素出现形状缺失, 目标果实与同色系叶片背景相似出现颜色干扰等问题时, 该类方法的识别精度明显下降, 难以满足果实采摘机器人部署到实际应用时对精度和速度的要求。 近年来, 随着深度学习技术的发展, 在目标识别过程中, 能够自行深度提取图像特征, 实现端到端的检测, 大幅提升了模型识别的精度与鲁棒性等多个方面的优势。 在此基础上, 衍生出的众多目标检测和图像分割算法开始被广泛应用到目标果实的识别[4, 5]。 Bargoti首先利用多尺度多层感知器和卷积神经网络将苹果图像分割, 提取出图像中的苹果目标, 然后用分水岭分割和圆形Hough变换法对苹果目标进行识别和计数[6]。 Jia通过改进实例分割模型Mask R-CNN以适应苹果目标的检测, 结合ResNet与DenseNet作为原模型的特征提取网络, 大幅提高了重叠及枝叶遮挡环境下苹果目标的检测精度[7]。 熊俊涛借助ResNet与DenseNet, 设计了Des-YOLOv3算法实现了网络多层特征的复用与融合, 加强了小目标和重叠遮挡果实的鲁棒性, 为夜间成熟柑橘的识别与检测提供了技术支持[8]。 以上基于卷积神经网络(convolutional neural networks, CNN)的果实识别算法在多个维度的表现均优于传统机器视觉方法。
当前以Faster R-CNN, Mask R-CNN为代表的双阶段检测分割算法, 以及以SSD, YOLO为代表的单阶段检测算法, 都沿用了先在原图上设置预定义锚框, 再通过网络进行调整得到边界框的方式进行预测。 该类方法对计算与存储资源的需求较高, 识别速度慢, 实时性差, 正常作业时的稳定与功耗得不到保证, 尚不适合将其迁移部署至移动采摘设备。 针对上述问题, 本研究提出一种基于无锚框检测器的一阶全卷积(fully convolutional one-stage, FCOS)高效绿色苹果检测优化模型, 首先借助CNN的特征提取能力, 消除对锚框的依赖, 在保证检测精度的前提下提升了模型的识别速度及识别不同外形果实的适应能力, 兼顾准确率与效率。 在多尺度FCOS的基础上添加了自底向上的特征融合架构, 为模型提供更加准确的定位信息, 提升模型的检测效果。
图像采集地点为山东省烟台市福山区, 如图1所示, 挑选不同光照强度(清晨、 中午、 夜间)、 不同光照角度(顺光、 逆光、 测光)、 不同遮挡类型(枝干遮挡、 叶片遮挡、 果实间相互重叠)的拍摄场景, 并按照不同的拍摄距离采集图像, 尽可能模拟苹果采摘机器人真实作业环境, 最终共采集绿色苹果图像256张。
 | 图1 果园环境下的绿色苹果图像Fig.1 Green apple images in orchard environment |
采用检测任务标注软件labelme, 挑选256张图像中的230张进行标注, 统一将分辨率缩小至600× 400像素, 图像中每个果实的最小外接矩阵作为真实框并生成对应的json文件。 标注完成后对230幅图像进行数据增强, 增强类型包括亮度增强、 对比度下降、 雾化、 高斯噪声、 脉冲噪声、 泊松噪声等, 如图2所示, 每种增强类型又分为不同增强程度, 最终共生成图像5 290张。 由原始图像生成的增强图像共享同一json文件中标注信息, 在每一种干扰类型的每一种干扰程度中以7∶ 3的比例划分训练集与验证集, 最终得到训练集共3703张图片, 验证集共1587张图片, 并分别生成MS COCO数据集[9]格式的标注文件。
 | 图2 不同类型的图像增强示例Fig.2 Examples of different types of image enhancement |
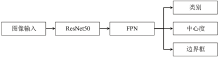
FCOS不同于以往的单阶段或双检测检测框架[10], FCOS摆脱了模型对锚框的依赖, 在保证检测精度的前提下缩减模型容量与算法复杂度, 减少采摘机器人正常作业时的功耗并提升稳定性。 FCOS在整体架构上以全卷积、 单阶段的方式进行预测, 模型结构与RetinaNet基本类似, 但正负样本的判定方式、 预测目标的生成及模型的训练却大相径庭。 如图3所示, 基础FCOS主要分为以下几个部分: 图像输入、 ResNet50、 特征金字塔网络(feature pyramid networks, FPN)和图像输出(类别、 中心度、 边界框)。
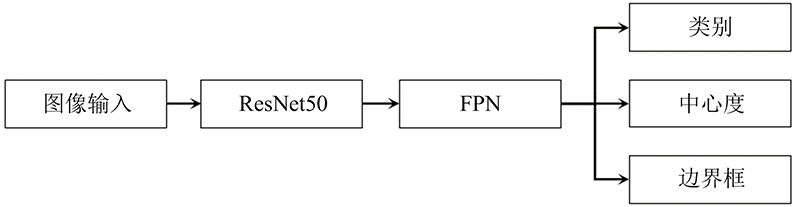 | 图3 FCOS网络结构简图Fig.3 FCOS network structure diagram |
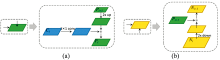
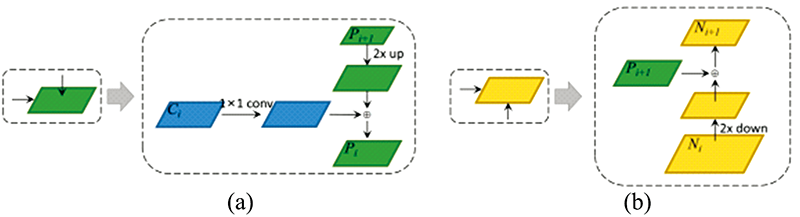 | 图4 (a)自顶向下融合方式; (b)自底向上融合方式Fig.4 (a) Top-down pathway; (b) bottom-up pathway |
2.1.1 ResNet骨干框架
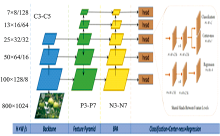
ResNet是FCOS网络中的骨干部分, 主要负责提取图像特征。 其通过残差学习的方式, 在网络中加入残差模块来帮助网络实现恒等映射, 解决了CNN由于层数过深而导致的梯度爆炸/消散、 退化问题。 其基本思想为在网络前向过程中, 当浅层的输出已经足够成熟, 让深层网络后面的层能够实现恒等映射的作用; 在反向过程中帮助传导梯度, 让更深的模型能够成功训练。 在ResNet中输出相同尺度的网络部分称为一级, 每经过一级会通过卷积等降采样操作逐渐丰富深层网络的语义信息和表达能力, 得到尺寸为原图尺寸1/2l的特征图(feature map), l为层级索引, 每一级最后一个残差块的输出分别记为{C1, C2, C3, C4, C5}, 如图5中左侧Backbone部分所示。
 | 图5 优化后的FCOS网络Fig.5 Optimized FCOS nerwork |
2.1.2 FPN特征提取网络
ResNet网络最后输出的特征图C5虽然包含了丰富的语义信息, 但经过不断的降采样之后, 其分辨率很低, 边界等细节信息基本丢失, 因此只适合预测大尺度目标。 FPN主要解决了目标检测中的多尺度预测问题, 其通过融合深层特征图的语义信息和浅层特征图的细节信息来构建特征金字塔, 将不同尺度的待检测目标分发给金字塔中不同层级的特征图负责预测。 该网络能有效提升模型对于不同尺度, 尤其是小尺度目标果实的检测效果, 从而能够更好的指导苹果采摘机器人的识别采摘与路径规划。 在FCOS中, 采用了ResNet中后三个层级输出的特征图C3, C4, C5来构建特征金字塔, C3, C4, C5通过1× 1卷积的横向连接与2倍上采样的自顶向下连接进行融合, 得到P3, P4, P5, 如图4(a)所示, 再由P5经过两次下采样得到P6和P7, 得到构建好的特征金字塔{P3, P4, P5, P6, P7}, 如图5中Feature Pyramid部分所示。
2.1.3 结果输出
基础FCOS采用特征金字塔{P3, P4, P5, P6, P7}中的每一层特征图分别预测。 如图5中最右侧所示, 每一层特征图分别接以分类、 中心度、 回归三个分支, 分别负责预测特征图上每一个空间位置属于苹果的置信度、 距离苹果中心的偏移程度及对应在原图坐标到真实框四条边的距离。 其中分类与回归分支分别使用两条不同的全卷积通道解耦预测, 使其更专注于各自的训练任务, 中心度的预测相对简单, 因此和分类分支共享同一部分全卷积网络, 最后分别通过1个1× 1卷积核和C个1× 1卷积核得到中心度与分类输出。 通过比较RetinaNet与FCOS在网络设计上的差别, 不同之处在于FCOS添加了一个中心度分支。 FCOS虽然消除了模型对锚框的依赖, 但其与基于锚框的检测器之间仍然存在着一定的距离, 原因在于距离目标中心较远的位置产生了很多低质量的预测边框。 因此, FCOS提出了一种简单而有效的策略来抑制这些低质量的预测边框, 而且不涉及任何超参数。 这种策略即引入中心度分支, 预测特征点与目标中心的偏移程度。 测试时, 将预测的中心度与相应的分类分数相乘, 得到边界框的最终得分, 因此, 中心度可以降低远离对象中心的边界框的权重, 从而通过非极大值抑制等后处理过程将其过滤掉。
本工作主要针对FCOS中的特征融合方式进行改进。 对目标检测而言, 深层的语义信息与浅层的细节信息都很重要, 特征融合通过FPN实现, 其虽然通过横向连接与自顶向下的架构方式逐渐丰富了浅层特征图的语义容量, 但深层特征图的细节信息仍是由ResNet通过几十甚至一百多个网络层传递得到, 即浅层到深层的传递路径过长, 导致浅层信息丢失严重, 增加了定位信息流动的难度。 因此, 借鉴PANet中的自底向上的路径增强(bottom-up path augmentation, BPA)模块并将其融合至FCOS网络中。 如图5中BPA部分所示, 对通过FPN得到的特征金字塔{P3, P4, P5, P6, P7}再连接一个自底向上的特征融合路径, 生成一个新的特征金字塔{N3, N4, N5, N6, N7}, 更好的保留浅层特征信息, 具体融合方式如图4(b)所示。
2.2.1 正负样本判定及训练目标生成
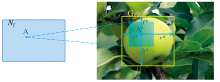
设特征图Nl上的某一空间位置为A: (x, y), 按照当前层级的下采样数sl可得其在输入图片上对应感受野区域的中心坐标为A': 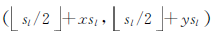
 | 图6 坐标映射图Fig.6 Coordinate mapping |
正样本在分类分支的训练目标为苹果标签, 因为本工作的目的是检测图像中的绿色苹果, 是一个二分类问题, 因此, 分别设正负样本的训练目标P* 取值为1, 0。 正样本在回归分支的训练目标为一个四维向量d* =(l* , t* , r* , b* ), 如图6所示, l* , t* , r* , b* 分别为映射坐标到与其相关联真实框的四条边的距离。 最后, 对于中心度分支的训练目标, 其计算方式如式(1)所示
式(1)中, centerness* 的取值范围为[0, 1], 当映射坐标位于真实框正中心时, centerness* 取值为1, 随着映射坐标朝着真实框四周偏移而逐渐衰减, 如图7所示, 红色、 蓝色和其他颜色分别表示1, 0和[0, 1]之间的渐变值。 模型测试阶段, 将中心度的预测值与分类分支对应位置的预测值相乘作为最后预测框的置信度, 从而有效抑制远离苹果果实中心的正样本点预测的边界框。
 | 图7 centerness* 取值变化Fig.7 Centerness* value change |
2.2.2 损失函数
模型实现检测绿色果实能力的方式, 是通过迭代训练计算预测边框与真实框之间的损失, 并按照损失值反向传播梯度来更新模型参数, 直至损失减少并收敛至一个取值区间。 对应FCOS网络末端的三个输出分支, 其损失函数由Lcls, Lreg, Lcenter三部分组成, 分别采用Focal Loss, IoU (intersection of union) Loss和BCE Loss计算, 模型整体损失函数如式(2)所示。
式(2)中, px, y, dx, y, centerx, y分别为分类分支, 回归分支, 中心度分支在空间位置(x, y)处的预测值,
关于式(2)中的分类损失Lcls, 如式(3)和式(4)所示
式(3)和式(4)中, α 负责平衡正负样本之间的重要性, γ 负责调节简单样本权重降低的速率。
关于式(2)中的回归损失Lreg, 如式(5)所示
式(5)中, Intersection(dx, y,
为验证优化FCOS模型对绿色苹果检测的有效性, 进行以下试验。 首先介绍试验运行平台及模型在训练与测试阶段的相关实施细节; 然后挑选最优训练模型, 在验证集上进行评估并分析试验数据; 接着分别对基础FCOS与优化FCOS进行训练, 分析BPA模块的绿色苹果检测的有效性; 最后, 选取目前最先进的各类型目标检测, 测试并对比模型在检测绿色苹果时在精度与速度两方面性能上的差异。
服务器的主要配置环境为Ubuntu 16.04操作系统、 32 GB的Tesla V100显卡和10.0的CUDA环境。 所有模型均使用Python语言及Pytorch 1.4深度学习库, 并借助MMDetection框架相关模块进行搭建。
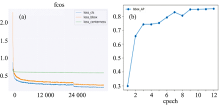
训练阶段: 正式训练之前, 抽取COCO数据集中包含苹果图像的1 586张图像并使用这些图像进行预训练, 将预训练完成之后参数迁移至FCOS网络作为初始化参数以更好的提升模型精度和鲁棒性。 正式训练时, 采用mini-batch的方式迭代训练12个epoch, 每次迭代使用2个样本作为一个batch, 共迭代31 740次, 训练过程中的三个分支产生的损失变化如图8(a)所示, 横轴为迭代次数, 纵轴为损失值。 每训练完一个epoch后在验证集上进行评估, 得到AP变化曲线图如图8(b)所示。 每次更新权值时使用BN进行正则化, 使用SGD(stochastic gradient descent)更新模型参数, 学习率、 权重衰减、 动量分别设为0.002 5, 0.000 1和0.9。 网络训练之前统一尺寸至(1 200, 800), 并依次经过随机翻转、 正则化、 填充等预处理操作。
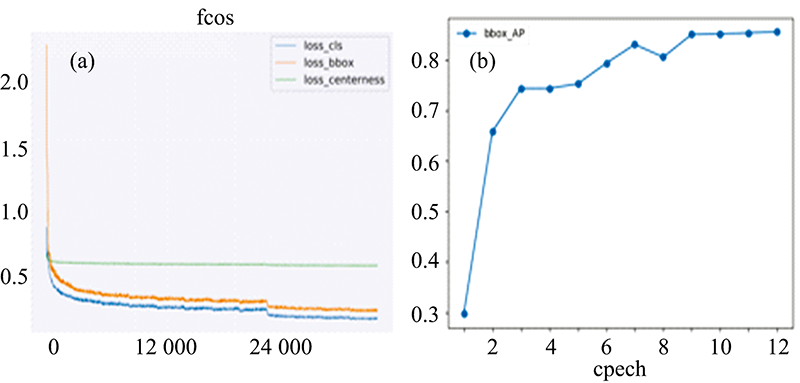 | 图8 损失变化曲线(a)与AP变化曲线图(b)Fig.8 Loss value curve (a) and AP value curve (b) |
测试阶段: 图像输入网络之前同样经过剪裁、 随机翻转、 正则化、 填充等预处理操作; 网络推断结束后, 首先剔除置信度小于0.05的低质量预测框, 再使用非极大值抑制(non maximum suppression, NMS)筛选重叠度过高的预测框, 筛选时使用IoU等于0.5作为阈值, 筛选完成后按照置信度排序, 每张图片至多保留前100置信度的预测框。
由于需要对模型的检测结果作出综合评价, 所以评价指标需要同时考虑准确率和召回率, 因此本工作主要选择AP作为评估指标, 首先, 在特定IoU阈值下准确率P与召回率R定义如式(7)所示
式(7)中, TPs为实际为苹果且被模型预测为苹果的个数, 即真实的正样本数量; FPs为实际为背景却被模型预测为苹果的个数, 即虚假的正样本数量; FNs为实际为苹果但没有被网络识别为苹果的个数, 即虚假的负样本个数。 进一步可得特定IoU阈值下平均精度APIoU=i定义如式(8)所示
如式(8)所示, 特定IoU阈值下的AP值是通过取101个召回率R: [0, 0.01, …, 1]下对应的准确率并取平均得到的。 求得特定IoU阈值下的, 最终的评估指标AP定义如式(9)所示
其中, I为IoU阈值数组: [0.5, 0.55, …, 0.95], 即AP值为分别计算IoU阈值从0.5开始, 每间隔0.05~0.95结束的10个APIoU=i值并取平均。 本工作还使用以下评估指标, 具体定义细节请参照MS COCO。
APsamll: 评估模型对小尺度目标果实的检测效果(真实框面积小于322); APmedium: 评估模型对中等尺度目标果实的检测效果(真实框面积介于322~962); APlarge: 评估模型对大尺度目标果实的检测效果(真实框面积大于962); AR: 每个图像中检测到固定数量100时的最大召回, 同样平均10个IoU阈值下的结果; ARsamll, ARmedium, ARlarge: 模型对不同尺度的平均召回; Params: 模型包含的参数量, 用来衡量模型的简洁程度; FLOPs: 模型推断时所需的浮点运算次数, 用来衡量模型的计算复杂度。
如图8(b)所示, 模型在训练完最后一个epoch后AP值最高, 为85.6%, 因此挑选该模型作为最优模型来评估网络整体性能, 模型在验证集上的详细评估结果如表1所示。
| 表1 FCOS网络评估结果 Table 1 Evaluation results of FCOS network |
此外, 我们选取多幅包含了重叠、 枝叶遮挡、 夜间、 远景及逆光等混合干扰情况下的图像进行检测, 并对检测效果进行研究分析, 如图9所示, 每对图片中的左列为人工标注图, 右列为FCOS模型检测的效果图。 可以看出, 由于各种干扰及混合干扰导致苹果的形状、 颜色和纹理发生缺失时, FCOS均能取得很好的检测效果, 且在人工标注的目标果实检测图中, 存在一些果实由于面积遮挡严重或拍摄距离过远等原因而没有标注, FCOS也能准确的将其检测出来, 说明模型不仅具有较好的检测效果与抗干扰能力之外, 而且具有较强的泛化能力。 综上所述, 优化FCOS网络能够胜任不同复杂场景下的绿色苹果检测任务。
 | 图9 模型在不同干扰场景下的检测效果Fig.9 Detection effect of the model in different interference scenes |
为进一步说明优化FCOS网络在速度与精度上的高效性, 选取目前最先进且同样基于深度学习的目标检测算法, 在验证集上进行评估并分析对比试验指标, 以说明模型在复杂自然环境下检测绿色苹果的表现。 分别选择基于锚框的双阶段算法Faster R-CNN[11]、 基于锚框的单阶段算法SSD[12]和RetinaNet[13]、 无锚框的单阶段算法FSAF(feature selective anchor-free)[14]四种方法。 试验运行在同一设备的相同环境下, 且使用相同的图像预处理流程, 模型检测完成后, 统一使用NMS和相同的IoU阈值筛选, 具体试验对比结果如表2所示。
| 表2 各模型对绿色苹果的检测结果 Table 2 Detection results of different models |
如2表所示, 优化FCOS在检测精度上, 其综合评估指标AP与AR值最高, 分别为85.6%和87.6%, 均高于其他四种不同类型的目标检测算法。 其中Faster R-CNN与FCOS的检测精度相差较小, 仅相差0.9个百分点, 这得益于其先通过区域候选网络(region proposal network, RPN)得到候选框再进行校准的双阶段检测流程, 但代价也同样明显, 如表2所示, Faster R-CNN的参数量和计算量分别为41.5 M和60 .0 GFLOPs, 远超FCOS 12.0 M和12.5 GFOLPs。 SSD512模型的参数量仅为24.4 M, 这是因为其提取特征时使用的卷积神经网络为VGG16, 相比FCOS模型使用的ResNet50更加简洁, 因此参数量更少, 但由于其是一种基于锚框的检测器, 因此所需的计算量同样很高。 为更直观比较以上五种模型对绿色苹果的检测效果, 我们挑选了三幅具有代表性且检测难度较大的图像并可视化预测结果如图10所示。 可以看出, 相较于其他四种算法, FCOS几乎没有漏检、 叶片与果实之间混检、 多个相邻果实识别为一个的现像。
 | 图10 五种不同类型的检测器在不同复杂场景下的检测效果图Fig.10 Detection effect images of 5 detectors in different complex scenes |
基于无锚框、 单阶段的目标检测模型FCOS, 并结合复杂自然场景下绿色苹果检测的实际要求进行优化。 实验结果表明, 该方法的检测精度高, 在各种干扰条件下的鲁棒性强。 相较于Faster R-CNN等不同类型的检测算法, 模型的计算及存储消耗更少, 架构设计更为简洁。 另外, 在整个检测过程中, 我们借助了FCOS高效的检测能力, 其舍弃了以往深度视觉模型对锚框的依赖, 使得FCOS能直接被泛化应用到其他果实的识别中。 在本文实验中采用的是绿色苹果果实, 形状为类球形, 若采用基于锚框的检测分割算法识别其他果实时, 例如黄瓜、 辣椒等, 又需要改变锚框大小等超参数以提升识别准确率, 同时还需要考虑锚框放置的密集程度以提升召回率。 而FCOS不需要进行这些操作, 避免了超参数设置对果实识别效果的影响与众多锚框对计算资源的消耗。 最后, 对最先进的基于深度学习的视觉识别算法, 选择并对比基于锚框的双阶段算法Faster R-CNN、 基于锚框的单阶段算法SSD, RetinaNet、 无锚框的单阶段算法FSAF在复杂自然条件下对绿色果实识别上的性能差异, 其各项评估指标更好, 优势显著。 改进FCOS能够以更简洁的模型结构和更少的计算量达到更高的检测精度, 能够同时实现速度与精度上的高效性且适应复杂的果园环境。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|