
{kind=link}
{kind=link}
高光谱反射率的滨海地区土壤全磷含量反演
[魏丹萍 , 郑光辉
, 郑光辉* ]
, 郑光辉]
|
|


作者简介: 魏丹萍, 女, 1997年生, 南京信息工程大学地理科学学院硕士研究生 e-mail: wdpnuist@163.com
反射光谱在近年来广泛应用于土壤属性的估算。 作为一种有效估算土壤全磷含量的手段, 反射光谱技术可以很大程度上减少传统化学测量方法所损耗的人力物力。 以江苏滨海土壤为研究对象, 在30个采样点采集了共147个土样, 测量土壤样品光谱反射率及全磷含量。 利用原始光谱反射率数据及6种不同的光谱变换结果, 通过随机抽样(RS)、 KS、 SPXY三种样本集划分方法, 基于偏最小二乘回归(PLSR)和支持向量机(SVM)方法分别建立土壤全磷含量的估算模型, 对比分析了三种样本集划分方法对估算结果精度的影响。 结果表明: (1)以原始光谱反射率为数据, PLSR模型, RS方法在多数情况下可以获得较为稳定的模型精度, 明显优于KS和SPXY方法; 在SVM模型中, 采用SPXY方法获得的模型结果最优, KS次之, RS结果最差。 (2)不同的样本集划分方法所合适的光谱变换方法不同, 对于三种划分样本集方法, PLSR和SVM对应的最优光谱变换分别是对数的倒数和一阶导数(KS方法), 原始光谱和一阶导数(RS方法), 一阶导数和多元散射校正(SPXY方法)。 其中采用KS方法划分样本集, PLSR和SVM均能获得最佳的预测结果。 并非所有光谱变换方法都可以提高模型精度, 部分光谱变换后PLSR模型预测精度显著降低; (3)在所有的样本集划分方法中, SVM的建模效果优于PLSR, 采用RS方法划分样本集, PLSR的预测精度高于SVM, 而采用KS和SPXY方法划分样本集, SVM的预测精度整体高于PLSR。 综上所述, 本研究区域估算土壤全磷含量的最佳模型是基于KS样本集划分方法和一阶导数光谱变换建立的SVM模型, 此时拟合优度($R_{p}^{2}$)为0.82。 结果表明反射光谱可以对滨海地区的土壤全磷含量进行有效预测, 对土壤磷元素的高效快速反演具有一定的指导意义。
In recent decades, reflectance spectroscopy technology has developed rapidly and has been widely used in soil science, especially soil property estimation. It can greatly reduce the manpower and material resources consumed by traditional chemical measurement methods as an effective method to estimate total phosphorus content in soil. In this paper, 147 soil samples were collected from 30 sampling sites in coastal soil of Jiangsu Province, China. The spectral data and total phosphorus content of the soil were measured, respectively. Three different sample set partitioning methods were performed on the original spectral data and six different spectral transformation results, including Random Sampling (RS), Kennard-Stone (KS) and Sample Set Partitioning Based on Joint X-Y Distance Algorithm (SPXY). In order to compare and analyze the influence of three sample set partitioning methods on the accuracy of estimation results, partial least square regression(PLSR) and support vector machine(SVM) methods were used to establish the estimation models of total phosphorus content in the soil. The results are as follows: (1) Under the condition of original spectral data, the RS method can obtain better results and more stable model accuracy in most cases for PLSR, which is superior to KS and SPXY. In the SVM model, the result obtained by SPXY method is the best, KS is the second, RS is the worst. (2) The appropriate spectral transformation methods for different sample set partitioning methods are also different. Among the three sample set partitioning methods, the optimal spectral transformations of PLSR and SVM are respectively the reciprocal of logarithm and the first derivative (KS method), the original spectrum and the first derivative (RS method), the first derivative and multiple scattering correction (SPXY method). Using the KS method to divide the sample set, PLSR and SVM model can obtain the optimal prediction results. Not all spectral transformation methods can improve the model accuracy. The prediction accuracy of the PLSR model is significantly reduced after partial spectral transformation. (3)Among all sample set partitioning methods, SVM has a better modeling effect than PLSR. Using the RS method to divide the sample set, the prediction accuracy of PLSR is higher than that of SVM. The results were reversed when KS and SPXY were used. According to the comprehensive results, the best estimation model for the study area was obtained using the KS sample set partitioning method, and the first derivative transformation method, combined with the SVM method, the R2 of the prediction result was 0.82. This study shows that reflectance spectroscopy can effectively predict the total phosphorus content of the soil in coastal areas and have a certain guiding significance for the efficient and rapid inversion of soil phosphorus.
作为土壤中仅次于氮的营养成分, 磷在很大程度上影响着土壤肥力的高低, 土壤磷的流失也是导致湖泊富营养化的主要因素, 因此快速准确获取土壤全磷含量对于农业生产和环境保护具有重要意义。 传统的化学测量方法需要耗费大量人力物力, 且不能大面积的推广, 给土壤全磷含量的估算带来了一定的困难。 近年来, 土壤反射光谱被广泛的应用于土壤属性估算, 由于其获取方式容易, 价格低廉等特点, 已成为估算土壤属性的重要手段。 利用反射光谱可以预测不同土壤类型的全磷含量, 张佳佳等[1]发现使用反射光谱可以较好预测南方丘陵红壤的土壤全磷含量; 薛利红等[2]同样利用反射光谱成功反演了太湖流域水稻土的全磷含量。 不同土壤光谱数据的最佳光谱变换方法和预测模型也可能不同, Xiong等[3]将倒数光谱变换结合多元逐步回归方法预测巢湖地区土壤磷含量; 王莉雯等[4]将原始数据结合偏最小二乘回归方法建立湿地土壤的全磷含量模型; Sarathjith等[5]将一阶导数变换结合支持向量机方法估算土壤全磷含量。 此外, 不同的样本集划分方式会对建模结果产生影响, 陈奕云等[6]采用Kennard-Stone(KS)和Sample Set Partitioning Based on Joint X-Y Distance Algorithm(SPXY)方法划分样本集研究江汉平原洪湖地区水稻土中土壤有机质含量; 于慧春等[7]利用SPXY方法划分样本建立霉变玉米中两种毒素含量的预测模型; 毛博慧[8]等比较了随机抽样(random sampling, RS)和SPXY样本集划分方法对于冬小麦叶绿素浓度的估算精度影响。 全磷含量的估算也可能受其他因素的影响, 如章文龙等[9]发现闽江河口湿地土壤全磷与有机质诊断指数高度相关。
目前我国对于土壤中全磷含量的光谱特征研究仍处于初级阶段, 不同土壤类型之间的属性估算模型存在明显差异。 滨海滩涂土壤作为我国重要的后备土地资源和空间资源, 面积广且分布集中, 具有较大的开发潜力。 因此, 对滨海土壤的光谱特征及属性反演研究具有重要的科学与实践意义。 为了提高模型精度, 很多学者采用不同的光谱变换方法来处理光谱数据, 但较少将不同的样本集划分方法应用于土壤全磷含量的估算研究中, 或将不同的光谱变换结合数据集划分方法来建立模型并分析其对估算精度的影响。 因此, 为了探索不同样本集划分方法以及不同光谱变换结合数据集划分方法对模型精度的影响, 我们利用光谱反射率数据结合偏最小二乘回归和支持向量机两种建模方法开展以下研究: (1)对比分析三种样本集划分方法对土壤全磷含量估算结果的影响; (2)评价不同的光谱变换方法结合不同样本数据集划分方法对于滨海土壤全磷含量模型精度的影响; (3)评估利用反射光谱估算滨海地区土壤全磷含量的可靠性。
东台市位于江苏省沿海地区, 长江三角洲北翼, 境内地势平坦, 河流众多。 该地区属于亚热带季风海洋性气候, 年平均气温为15.0 ℃, 年降水量为1 061.2 mm。 东台地区的土壤类型以水稻土和潮盐土为主, 两者大致以范公堤为界, 境内的滩涂资源十分丰富。 本研究在东台地区采集13个0~5 cm的表土样点和17个0~100 cm的剖面样点, 共计30个采样点(图1)。 剖面采样深度分别为0~5, 5~10, 10~20, 20~30, 30~40, 40~60, 60~80和80~100 cm, 由于两个剖面分别缺失一个0~5和80~100 cm的样本, 最终获得147个有效样品。 将土样风干并研磨, 过100目筛, 分成两份分别用于光谱测量和化学分析, 采用硫酸-高氯酸消化-钼锑抗比色法测量土壤全磷含量, 利用重铬酸钾氧化-外加热法测量土壤有机质含量。
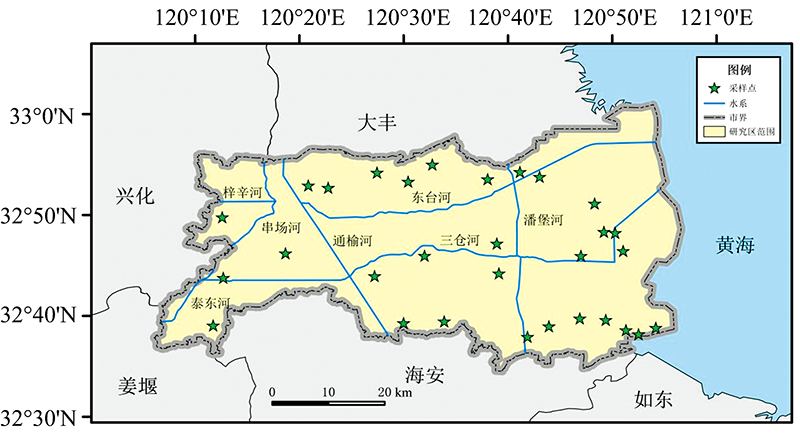 | 图1 采样点位置分布图Fig.1 Sampleing location |
土壤的光谱测量在暗室中进行, 采用美国分析光谱仪器公司(ASD)的FieldSpec3便携式光谱分析仪, 该设备的探测波段在350~2 500 nm之间。 实验室的环境条件设置如下: 将一盏50 W的卤素灯作为光源, 调整光照角度为15° , 距离样品30 cm; 采用5° 视场探头角, 探头在距土样15 cm处进行光谱采集, 探测半径为0.655 cm。 在测量光谱之前, 先去除暗电流, 利用空白标准参照板获取相对反射率, 取适量土样放入器皿内并将表面刮平, 土样放入平台匀速转动, 同时可获得20条光谱曲线, 算数平均后得到最终的反射光谱数据。
光谱数据在1 000和1 800 nm处产生明显的断点, 利用仪器自带的软件ViewSpecPro对断点进行校正, 获得较为连续的光谱曲线。 利用Savitzky-Golay(SG)方法将光谱曲线作平滑处理, 去除前后10 nm波段的光谱数据, 保留360~2 490 nm波段范围的光谱曲线作为原始光谱反射率(reflectivity, R)。 对R分别进行标准正态变量变换(standard normal variable, SNV)、 多元散射校正(multiple scatter correction, MSC)、 一阶微分(first derivative, FD)、 二阶微分(second derivative, SD)、 对数的倒数(reciprocal of logarithm, RL)和连续统去除(continuum removal, CR)等共6种不同的光谱变换。 SNV方法主要是用来消除固体颗粒大小、 表面散射以及光程变化对近红外漫反射光谱的影响。 MSC方法可以有效地消除散射影响, 增强成分含量相关的光谱吸收信息, 提高信噪比。 光谱数据经过FD处理后特征差异明显增大, 线性背景和噪声等干扰降低。 SD光谱变换可以很大程度上消除原始光谱的背景干扰, 提高分析精度[10]。 RL方法可以增强光谱的差异, 并减少光照条件变化对于光谱的影响。 CR方法主要将反射率归一化为0~1, 从而提取特征波段以便识别[11]。
除了最常用的随机抽样(RS)方法, 还采用了KS和SPXY样本集划分方法。 为减小随机划分样本集对模型结果的影响, 进行1 000次随机抽样、 建模及预测, 综合分析其1 000次的计算结果。 KS[12]方法是根据样本自变量之间的欧氏距离来选择建模集和预测集。 SPXY方法的基本思路与KS方法相似, 最大改变在于它还考虑了因变量Y之间的欧氏距离, 将自变量X和因变量Y之间的欧氏距离分别进行最大值标准化后求和, 以此“ 和” 的值作为样本之间的距离, 再按照KS方法的迭代思路建立建模集。 建模集样本数量占80%(118个), 预测集样本数量占20%(29个)。
偏最小二乘回归[13]是一种集主成分分析、 典型相关分析和多元线性分析方法优点于一体的新型多变量回归分析方法, 能够简化数据结构, 并解决自变量的多重相关性问题。 支持向量机[14]在解决小样本、 非线性及高维模式识别问题中表现出许多特有的优势, 并能推广应用到函数拟合等其他问题中。
偏最小二乘回归(partial least square regression, PLSR)和支持向量机(support vector machine, SVM)的模型精度取决于拟合优度(R2)、 均方根误差(root mean square error, RMSE)、 相对分析误差(relative percent deviation, RPD)三个评价指标[15]。 RMSE(建模集RMSEc、 预测集RMSEp)趋近于0、 R2(建模
使用标准差、 变异系数、 峰度和偏度等描述土壤属性特征。 变异系数(variable coefficient, CV)是指数据的离散程度; 峰度(kurtosis, K)可以描述数据分布形态的陡缓程度, 3代表正态分布, 1.8代表均匀分布; 偏度(skewness, S)可以衡量数据分布的偏斜程度, 0代表正态分布。 由表1可见, 东台地区滩涂土壤有机质(soil organic matter, SOM)含量较低(平均值为9.18 g· kg-1), 具有很强的空间异质性(最小值为1.39 g· kg-1, 最大值为52.56 g· kg-1, CV为95.21%)。 全磷(total phosphorus, TP)含量在0.22~1.30 g· kg-1之间, 其变化幅度低于SOM含量变化, CV仅为28.02%。 SOM的K> 3(K=6.72), 表明数据分布中具有过高的峰值。 TP的K< 3(K=1.01)则代表数据分布中具有过低的峰值, 由此可以看出TP相对于SOM分布比较平坦。 TP和SOM的偏度均为正值, 呈正偏态分布, 数据的平均值大于中位数和众数, 表示样本中存在部分TP和SOM含量过高的点。 而TP的偏度绝对值高于SOM, 代表其数据的偏倚程度较大。 在本研究区中TP与SOM之间相关性弱(相关系数为0.17), 标准差、 变异系数、 峰度和偏度相差较大, 因此无法利用SOM来研究TP对土壤光谱的影响。
| 表1 土壤TP与SOM含量 Table 1 Statistics of soil TP and SOM contents |
KS和SPXY算法在样本集的划分中应用广泛, 可以在一定情况下提高模型的预测精度。 利用KS和SPXY算法对样品集进行划分, 将土壤全磷样本划分成为118个建模集和29个预测集, KS和SPXY样本划分的结果见表2和表3。 从两个表中可以看出, 建模集样本的TP含量涵盖了预测集样本的TP含量范围, 变异系数小于31%, 样本集划分较合理。 KS划分样本的建模集变异系数略低于SPXY方法, 而其预测集的变异系数始终高于SPXY方法。 利用同一种方法划分样本, 不同的光谱变换获取的建模和预测样本集也略有不同, 因此得到的建模结果可能有所差异。
| 表2 KS样本集划分 Table 2 Sample set partitioning based on KS |
| 表3 SPXY样本划分 Table 3 Sample set partitioning based on SPXP |
表4和表5分别是利用原始光谱数据建立的基于三种数据集划分方法的PLSR和SVM预测模型。 从PLSR的结果可知, RS方法的1000次运算结果差异较大, 除去预测
| 表4 偏最小二乘回归结果 Table 4 Statistics of partial least square regression |
| 表5 支持向量机的结果 Table 5 Statistics of support vector machine |
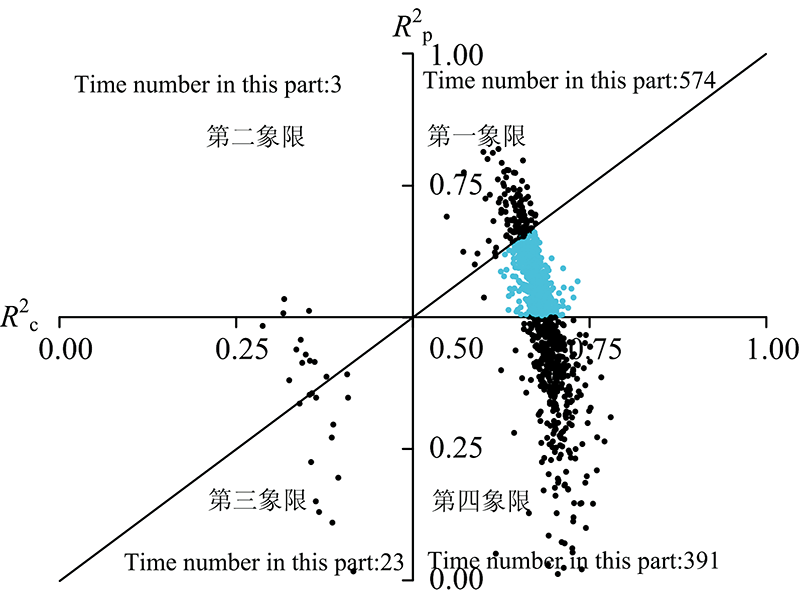 | 图2 PLSR建模及预测验证R2散点分布图Fig.2 Scatter plot of determination coefficients for partial least square regression calibration and prediction |
和PLSR的结果不同, 采用SVM方法建模, RS划分样本集的1 000次运算结果差异相对较小, 建模
将360~2 490 nm波段的原始光谱数据, 分别经过6种光谱变换方法, 3种数据集划分方法, 结合偏最小二乘回归方法和支持向量机方法分别建立模型, 并通过精度比较确定最优估算模型。 从表6的PLSR分析结果可得: (1)采用RS数据集划分方法, SD光谱变换方法的建模精度最高,
| 表6 不同光谱变换方法和样本集划分方法的PLSR建模和估算结果 Table 6 PLSR calibration and prediction results of different spectral transformation methods and sample-set partitioning methods |
从表7的SVM分析结果可得: (1)采用RS样本集划分方法, FD光谱变换方法的建模精度最高,
| 表7 不同光谱变换方法和样本集划分方法的SVM建模和估算结果 Table 7 SVM calibration and prediction results of different spectral transformation methods and sample-set partitioning methods |
综合两种方法的建模预测结果可以发现, 并非所有光谱变换方法都可以提高模型精度, 不同的样本集划分方法所适合的光谱变换方法也不一样, 尤其在PLSR模型中表现明显。 采用RS方法划分样本集时PLSR的预测精度高于SVM, 而采用KS和SPXY方法划分样本集, SVM的预测精度整体高于PLSR。 采用KS方法划分样本集, PLSR和SVM均能获得最优的预测结果, 但对应的光谱变换方法分别是RL和FD。 不同的样本集划分方法和光谱变换均能对建模预测结果产生较大的影响, 不同模型所适合的方法不同, 综合来看, 本研究区KS样本集划分方法结合FD光谱变换方法建立的土壤全磷含量SVM模型结果最优。
利用土壤反射光谱数据探讨了不同光谱变换结合不同样本集划分方法及预测模型在滨海土壤全磷含量估算中的可用性。 本研究区土壤有机质与全磷相关性较小, 因此无法利用土壤有机质来获取全磷含量。 从两种建模方法的结果来看, 在PLSR方法中, 1 000次随机抽样结果表明有45.70%的可能性能得到合理且精度较高的土壤全磷含量模型, 利用RS方法划分样本集的结果在大部分情况下都优于KS和SPXY方法。 而在SVM模型中, 1 000次运算结果中只有0.12%的预测结果较好, 综合来说采用SPXY方法获得的结果最优, KS次之, RS结果最差。 不同的样本集划分方法会对建模预测结果产生较大的影响, 不同的建模方法适合的样本集划分方法也有所差异, 在原始光谱数据的条件下, PLSR模型适合RS方法划分样本集, SVM模型适合采用SPXY方法划分样本。
经不同的光谱变换后, PLSR和SVM模型采用KS方法划分样本集分别结合RL和FD变换的预测精度最高,
综上所述, 在实际应用中, 土壤样本采用不同样本集划分方法, 结合不同的光谱变换及建模方法会对土壤全磷含量的估算精度有较大影响, 考虑到区域性的差异, 普适性的建模方法及策略应该是下一步的研究方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|