
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于紫外拉曼光谱的转基因大豆油快速识别方法研究
[郭宗昱 , 郭一新, 金伟其
, 郭一新, 金伟其* , 何玉青, 裘溯]
, 郭一新, 金伟其, 何玉青, 裘溯]
|
|


作者简介: 郭宗昱, 女, 1996年生, 北京理工大学光电学院硕士研究生 e-mail: phoebe_gzy@163.com
转基因技术对实现作物增产增质, 降低农药使用量, 降低生产成本等具有重要作用, 但对生态环境也存在一定的潜在威胁。 为了防止转基因大豆在食品化中的滥用, 对转基因产品快速鉴别技术的研究尤为迫切。 紫外拉曼光谱检测技术具备外场远距离无损遥测检测, 简单高效, 快速准确等优点, 可有效用于物质遥测鉴别领域。 基于紫外拉曼光谱的转基因/非转基因大豆油以及与其他类别食用油鉴别方法, 采集了五种不同食用油(两种品牌转基因/非转基因大豆油各500组样本和一种稻米油100组样本, 共2 100组样本)在3 500~400 cm-1(268~293 nm)范围内的日盲紫外拉曼光谱信息, 为提高光谱数据的信噪比并保证分类识别的准确性, 对上述光谱数据采用Savitzky-Golay滤波降噪、 基于自适应迭代加权惩罚最小二乘法(airPLS)的基线校正以及多元散射校正(MSC)的光谱数据修正等预处理。 根据大豆油的紫外拉曼指纹图谱, 分析出主要化学成分包含脂肪类、 蛋白质类、 酰胺类。 将每种大豆油样本按1:1划分为训练集和测试集, 输入训练集数据至支持向量机(SVM)进行训练, 采用10折交叉验证建立最佳模型, 识别准确率达99.81%, 对转基因大豆油的判别效果显著; 采用主成分分析法(PCA)进行数据降维处理, 提取出8个主成分, 累计贡献率为74.84%, 可代表大部分原始数据特征。 在此基础上, 将预处理后的光谱数据按4:1划分为训练集和测试集, 采用偏最小二乘回归判别分析方法(PLS-DA), 结合10折交叉验证法建立全谱的最佳PLS-DA模型(判别阈值设置为0.5), 判别准确率达到70.95%。 研究表明, 紫外拉曼光谱分析方法可较为准确地鉴别非转基因/转基因大豆油, 同时可鉴别大豆油与稻米油, 实现对转基因大豆食品的快速无损鉴别, 可望成为转基因大豆油及其食品的现场检测新的技术途径, 对推动转基因产品遥测鉴别技术的发展具有进步意义。
Transgenic technology plays an important role in increasing crop yield and quality, and reducing pesticide use and production cost, but it also has a certain potential threat to the ecological environment. In order to prevent the abuse of genetically modified soybean in food, the research on rapid identification technology of genetically modified products is particularly urgent. UV Raman spectroscopy detection technology can be effectively used in material telemetry and identification with many advantages, such as long-distance non-destructive telemetry detection, simplicity, efficiency, rapidity and accuracy. Based on UV Raman spectroscopy, the feasibility of identifying transgenic/non-transgenic soybean oil and other types of edible oil was studied. The UV Raman spectra of five different edible oils (500 samples of each brand of GM/non-GM soybean oil and 100 samples of one kind of rice oil, 2 100 samples in total) in the wavelength range of 3 500~400 cm-1(268~293 nm) were collected. In order to improve the signal-to-noise ratio of spectral data and ensure the accuracy of classification, we used Savitzky-Golay filtering to denoise, adaptive iterative weighted penalty least squares (airPLS) to correct baseline and multiple scattering correction (MSC) to standardize spectrum. According to the UV Raman fingerprint of soybean oil, the main chemical components were analyzed, including fats, proteins and amides. We divided each kind of soybean oil into the training set and test set according to 1:1, input the training set data into a support vector machine (SVM) for training, and established the best model by 10-fold cross-validation. The recognition accuracy was 99.81%, which had a significant effect on detecting the transgenic soybean. Principal component analysis (PCA) is used for data dimensionality reduction, and 8 principal components were extracted, with a cumulative contribution rate of 74.84%, which can represent most of the characteristics of the original data. On this basis, the preprocessed spectral data were divided into the training set and test set according to 4:1. The partial least squares regression discriminant analysis (PLS-DA) and 10-fold cross validation method were used to establish the best PLS-DA model of the whole spectrum (the discrimination threshold was set to 0.5) with the accuracy of 70.95%. It is shown that UV Raman spectroscopy can accurately and rapidly identify GM/non-GM soybean oil and rice oil. The study provides an important practical and theoretical basis for the on-site detection of transgenic soybean oil and its food and is of great significance in promoting the development of telemetry identification technology for transgenic products.
转基因作物是指利用重组DNA技术将克隆的外源基因导入作物组织并表达, 从而获得的具有特定目标性状的作物[1]。 据国际农业生物技术应用服务组织(International Service for the Acquisition of Agri-biotech Applications, ISAAA)统计报告, 1996年— 2018年全球转基因作物种植面积攀升至1.917亿公顷, 发展中国家与发达国家分别占1.031亿公顷和0.886亿公顷, 其中, 转基因大豆在全球的应用率最高, 占全球转基因作物面积的50%。 虽然转基因技术可增加作物产量、 改善作物品质、 提高抗旱抗寒能力和其他特性, 但转基因作物也可能对生态环境造成潜在的威胁(如土壤生态系统和生物地球化学循环等), 甚至可能对生物种群造成严重影响[2], 因此, 转基因作物的环境安全性评价一直是人们关注的问题。 我国是世界上主要的大豆消费国和进口国, 截至2019年进口的大豆量达8.34亿吨, 消费量约为10亿吨, 其中绝大多数均为转基因大豆[3]。 2020年农业农村部下发了三款耐除草剂转基因大豆的农业转基因生物安全证书批准清单[4]。 为了防止转基因大豆在食品化中的滥用, 解决食品标识不清甚至鱼龙混杂的问题, 食品转基因大豆成分检测形势非常迫切。
常见的转基因大豆检测技术主要有外源核酸检测和外源蛋白检测两类。 前者主要有定性聚合酶链式反应(polymerase chain reaction, PCR)、 定量聚合酶链式反应、 环介导等温扩增(loop-media isothermal ampli-fication, LAMP)等技术; 后者主要有酶联免疫吸附(enzyme linked immune-sorbent assay, ELISA)、 试纸条和Western blot等检测技术[5, 6]。 这些检测方法大多特异性强、 检测准确度高, 但对样品提取的质量要求高, 预处理复杂, 采样检测耗时较长且均为破坏性检验, 不仅对检测人员的专业素质要求较高, 而且难以适应在某些实际场合样品量大且需要快速检测的应用需求。
拉曼光谱是一种无损的非接触性光散射分析方法, 谱峰位置、 强弱及形状可精确反映出有关物质或混合物的结构信息, 因此常用来鉴别物质和组分分析。 拉曼光谱检测无需预处理, 不产生化学污染物, 具有快速准确、 简单高效、 可重复性高等优点。 然而, 由于大豆油组分中包含大量碳-碳双键(线性或环状不饱和分子, 具有大量的p键偶联)[7], 会产生强荧光背景[8], 对拉曼光谱的检测产生较大干扰。 相对于常见的可见光和近红外拉曼光谱, 紫外拉曼光谱的特点: ①与荧光光谱大致分离[9]; ②由于臭氧层对紫外线的隔离, 紫外拉曼光谱受环境光干扰较小, 适用现场遥测, 应用场景更广泛; ③拉曼散射强度与波长的四次方成反比[10], 在同等条件下紫外拉曼光谱对弱散射信号的探测更具优势, 更适合实际现场的检测。 本文研究紫外拉曼光谱对转基因大豆油的鉴别方法, 分析转基因与非转基因大豆油的分类可行性, 为转基因大豆油及其食品的现场检测探索新的技术途径。
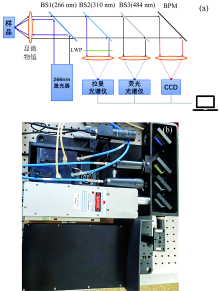
紫外拉曼光谱检测系统如图1所示, 主要由紫外激光器、 拉曼光谱仪、 荧光光谱仪和可见光相机组成。 激光脉冲经BS1(266 nm, Semrock, Bright Line)双向色镜反射, 垂直穿过工作距离为15 mm的10倍紫外聚焦物镜, 到达样品表面; 样品被激发出的光谱首先入射到BS1, 滤去266 nm激光, 透过大于266 nm的拉曼光谱、 荧光谱及可见光等; BS2(310 nm, Semrock, Bright Line)处266~310 nm的光谱由采集头收集, 并通过光纤传送至拉曼光谱仪; BS3(484 nm, Semrock, Bright Line)处310~484 nm光谱由光纤传送至荧光光谱仪; 最终的可见光(波长大于484 nm)由带通反射镜BPM反射至CCD相机成像, 实现对不可见紫外采样点场景的搜索与瞄准, 同时荧光通道可结合门控技术计算荧光衰减时间, 实现对物质的快速筛选。 其中, 266 nm长通滤光片LWP可抑制激光反射和瑞利散射; 反绿光带通滤光片BPM可避免荧光过强导致的过曝问题, 同时反射绿光为CCD提供照明。 光谱仪通过USB连接至电脑, 由PyCharm(Python 3.8)平台进行数据处理。
 | 图1 本实验紫外拉曼光谱系统 (a): 光路设计; (b): 装置实物Fig.1 Ultraviolet Raman spectrometer (a): Optical path design; (b): Experimental device |
系统采用长春光机所四倍频Nd:YAG脉冲激光器MPL-N-266, 波长266 nm, 平均功率为30 mW, 脉宽5 ns, 重频3~5 kHz; 拉曼通道采用海洋光学QE-pro光谱仪, 光学分辨率0.14~7.7 nm (FWHM), 光谱检测范围265~300 nm; 荧光通道采用海洋光学Maya 2000光谱仪, 光学分辨率0.035 nm (FWHM)。
首先采用Savitzky-Golay滤波器[11]对原始光谱进行降噪, 提高光谱平滑性, 再使用自适应迭代加权惩罚最小二乘法(adaptive iteratively reweighted penalized least squares, airPLS)进行基线校正。 由于散射水平差异, 同一样品在不同时刻测得的光谱曲线有一定的偏移, 对后续光谱分类的准确性造成影响, 采用多元散射校正(multiple-scattering corrections, MSC)[12]改善基线的偏移和平移。
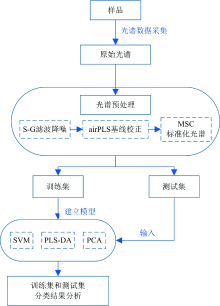
我们采用了一种不同监督模式下拉曼光谱特征分类和识别方法, 处理流程如图2所示, 其中各环节的作用大致为:
(1) 基于支持向量机的光谱全局分类
支持向量机(support vector machine, SVM)是一种二分类监督学习方法, 基本模型定义为特征空间上间隔最大的线性分类器, 通过核函数将向量投影至高维特征空间, 建立最优超平面以实现模式识别, 利于解决小样本、 非线性、 高维度数据[11]。
(2) 基于主成分分析
对于大样本数量情况, 可优先使用主成分分析(principal component analysis, PCA)进行数据降维再使用其他分类识别方法。 其作为目前光谱分析中常用的无监督统计方法, 可记录原始变量的方差, 降低数据维度并减小测量误差[13]。
(3) 基于PLS-DA的全局分析
偏最小二乘判别分析(partial least squares-discriminant analysis, PLS-DA)是一种常用的有监督多元因子回归方法, 在PCA的基础上进行最小二乘回归, 可用于多变量数据的分类和判别[13]。 本实验建立多类别分类模型, 设定判定阈值在0.5, 当模型标签的预测值与实际值差的绝对值大于0.5时, 表明判别错误; 反之则判别正确。
SVM在The Unscrambler X软件上实现, PCA、 PLS-DA算法在PyCharm(Python 3.8)上实现。
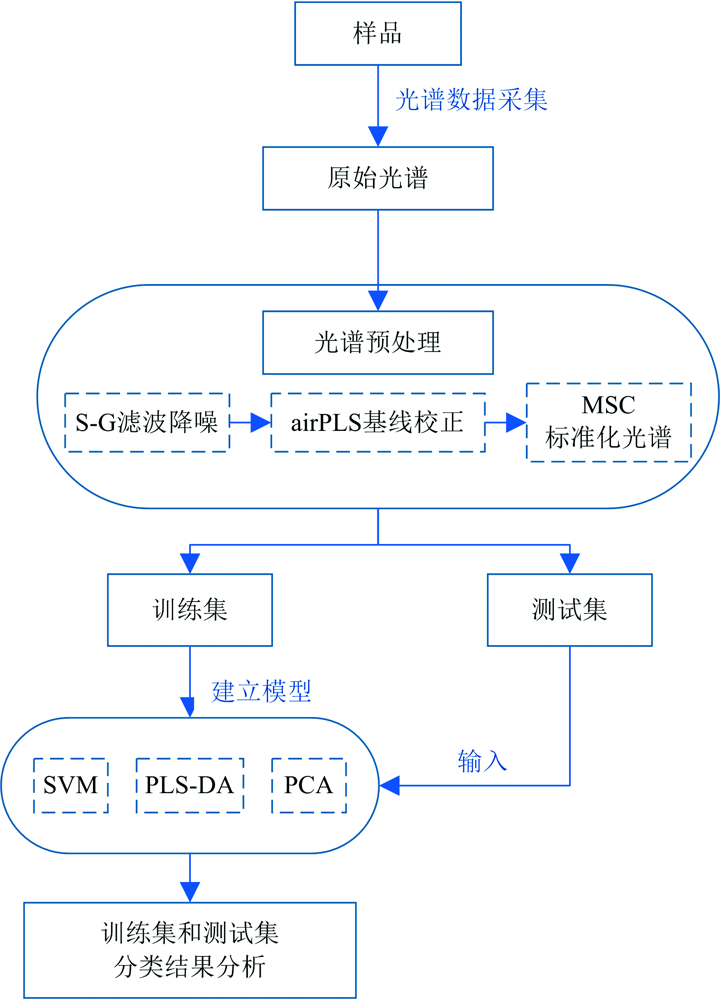 | 图2 拉曼光谱特征分类和识别方法流程图Fig.2 Flow chart of Raman spectrum feature classification and recognition method |
实验样本共有5种食用油(见表1), 其中两种转基因/非转基因大豆油(记为A和B类)和一种稻米油(记为C类), 外观上无明显差异。 A、 B类样品作为转基因/非转基因大豆油的鉴别依据, C类样品作为对照研究大豆油和其他油类鉴别的可行性。
| 表1 实验样品信息 Table 1 Information of experimental samples |
实验中样品温度维持在室温, 每种样品取2 mL, 装入尺寸12.5 mm× 12.5 mm× 40 mm, 容量为3.5 mL的石英(可透日盲紫外)比色皿中, 水平放置于样品采集区检测。 使用OceanView软件采集样本光谱, 光谱仪采用扫描次数10次的平均值作为一个样本采集光谱。 A类及B类样本一次采集100组, 共采集5次; C类样本一次采集20组, 共采集5次, 共计2 100组数据。 为了增加样本的鲁棒性, 同类数据的采集均会间隔另一种不同类数据的采集, 即不连续采集同一类样本。
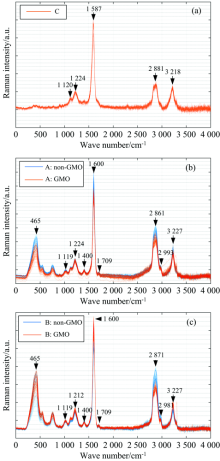
不同种类大豆油及稻米油标准化的全谱图如图3所示, 大豆油的拉曼谱图曲线相似度较高, 仅在强度和部分波数范围内有部分差异, 无法直接从视觉上根据原始光谱进行转基因和非转基因样本的区分。
 | 图3 不同种类大豆油及稻米油标准化的全谱图 (a): 稻米油; (b): A类大豆油; (c): B类大豆油Fig.3 Full spectrum of standardized soybean and rice oils (a): Rice; (b): Soybeanclass A; (c): Soybeanclass B |
所有大豆油样品(品牌A、 B的转基因和非转基因大豆油)的谱图中, 拉曼特征峰相似。 1 507~1 701 cm-1的光谱区域为蛋白质, 1 705~1 782及2 827~2 877 cm-1为脂肪[14]。 1 000~1 200 cm-1的特征峰对应蛋白质中的磷酸基团 O=P— O。通常1 400 cm-1附近的拉曼峰与甲基CH3有关, 1 290, 1 531.5和1 689 cm-1附近的拉曼特征峰分别对应酰胺Ⅲ 、 Ⅱ 和Ⅰ 带[15], 图3光谱中1 600 cm-1附近的特征峰对应酰胺带[16]。 2 850~2 980 cm-1特征峰与脂类的CH2相关。 此外, 465 cm-1附近为石英容器的拉曼特征峰。 具体的样品拉曼特征峰归属见表2。
| 表2 样品拉曼光谱特征峰的归属 Table 2 Raman spectrum characteristic peak attributions |
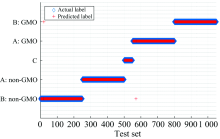
从实验角度出发, 基于SVM分析方法对不同的数据集划分比例(4:1, 3:1, 1:1等)进行了多次测试, 最终选择判别准确度最高的1: 1划分方法。 将预处理后的数据按类打乱, 分别在各类中以1:1随机划分为训练集和测试集, 并为训练集中五类样本设置不同标签(如表1): A类(-1/1), B类(-2/2), C类(0); 测试集不设置标签。 将训练集的1 050组光谱数据及其标签值作为输入, 训练SVM模型; 余下1 050组数据用于评估分类器的性能, 输入至训练完成的模型后得到分类的准确率。 基于样本数据分布特征, 本文选择建模效果较好的线性核函数, 模型采用C-SVC。 采用10折交叉验证, 结合网格搜索算法(grid search, GS)选择最佳惩罚因子C=1进行模型训练。 模型训练完成后, 输入测试集中的1 050组数据, 获得预测标签, 与实际标签对比后最终得到分类的平均准确率。 分类结果如图4所示, 蓝色为实际标签, 红色为预测标签, 仅有两个样本标签预测错误, 分类准确率达到99.81%。 表明紫外拉曼光谱结合支持向量机分析(SVM), 不仅对转基因/非转基因大豆油的鉴别具有可行性, 而且可区分大豆油和稻米油。
 | 图4 SVM算法对测试集样品分类(1 050个样品)Fig.4 Classification results of test set samples by SVM algorithm (1 050 samples) |
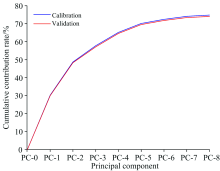
每种大豆油的光谱数据均有12个明显的拉曼特征峰, 采用主成分分析法(模型为NIPALS, 最大迭代次数为100)对2 100组数据进行降维处理, 提取出8个主成分, 从第9个主成分开始不收敛。 前8个主成分的贡献率见表3, 累计贡献率达74.84%, 可以代表大部分原始数据的特征。 验证集和校准集的累计贡献率见图5, 可见校准后的数据整体贡献率有略微提升。
| 表3 全局数据主成分分析得分情况 Table 3 Principal component analysis score of global data |
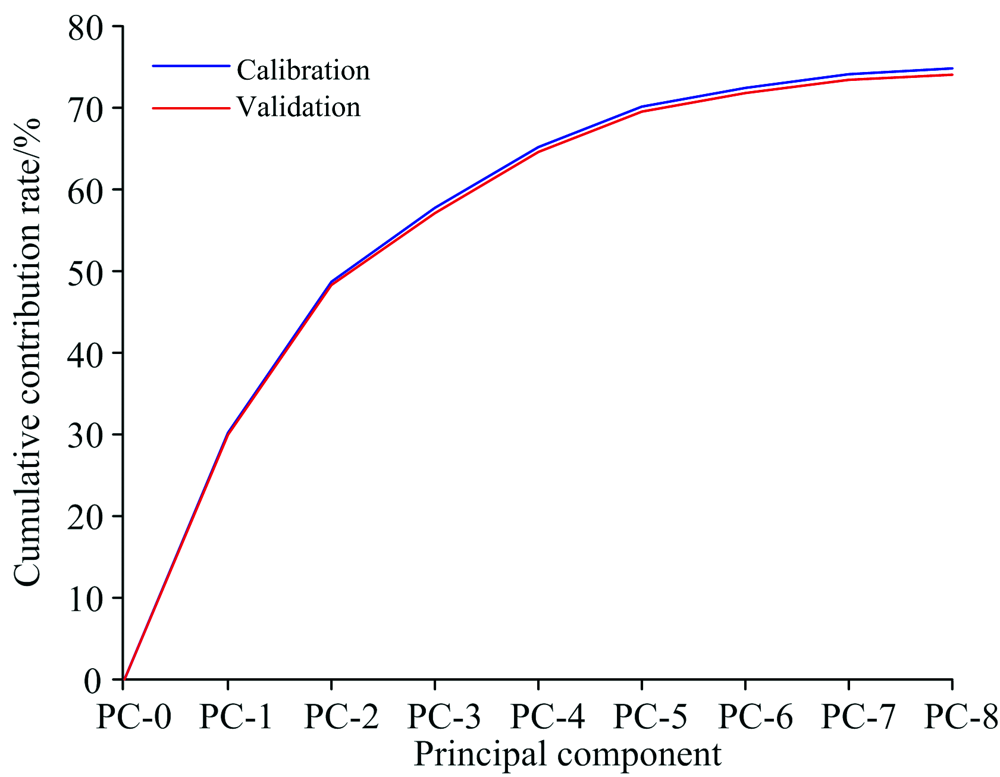 | 图5 验证集和校准集中前8个主成分累计贡献率Fig.5 The cumulative contribution rate of the first 8 principal components in the validation set and calibration set |
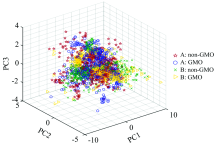
为了直观表现不同样本的相关程度, 使用聚类图展示前三个主成分的分布特征, 见图6。 前三个主成分间交叠程度较大, 区分度不够明显, 说明使用三个主成分无法较好实现分类, 需要进一步分析。
 | 图6 四种大豆油光谱数据前3个主成分散点图Fig.6 Scatter of first 3 principal components from spectral data of 4 kinds of soybean oil |
相较于无监督式的PCA分析方法, 偏最小二乘回归(PLS-DA)是一种有监督的判别分析统计方法, 结合了主成分分析和相关分析思想, 利用PLS降维获得的特征变量不仅可以代表原始变量信息, 而且对因变量有较强的解释能力。 本文将建立光谱特征与样本类别标签之间的关系模型, 以实现对样品种类的预测。 从实验角度出发, 我们基于PLS-DA分析方法对不同的数据集划分比例(4:1, 3:1, 1:1等)进行了多次测试, 最终选择判别准确率最高的4:1划分方法。 将数据集以4:1划分为训练集和测试集, 将训练集中的1 680组样本数据作为输入, 采用10折交叉验证, 根据本实验样本数据特征(大量样本及较少变量的数据), 使用更加合适的Kernel PLS模型进行训练。 建模完成后, 对得到的主成分进行绘制, 并对不同类样本进行标识。 图7给出PLS-DA模型对样品训练集的预测值, 可以看出: 四种大豆油(☆, A类非转基因; ○, A类转基因; × , B类非转基因; ▷, B类转基因)与稻米油(❋, C类)有显著差异, 无交叠部分, 区分度达100%; 四种大豆油集中分布在同一区域(以原点为中心的四个象限内), 分布上存在差异, 但有部分交叠, 这是因为不同类大豆油的拉曼光谱具有相似线型, 同时特征峰位置基本一致, 仅存在强度方面的差异。
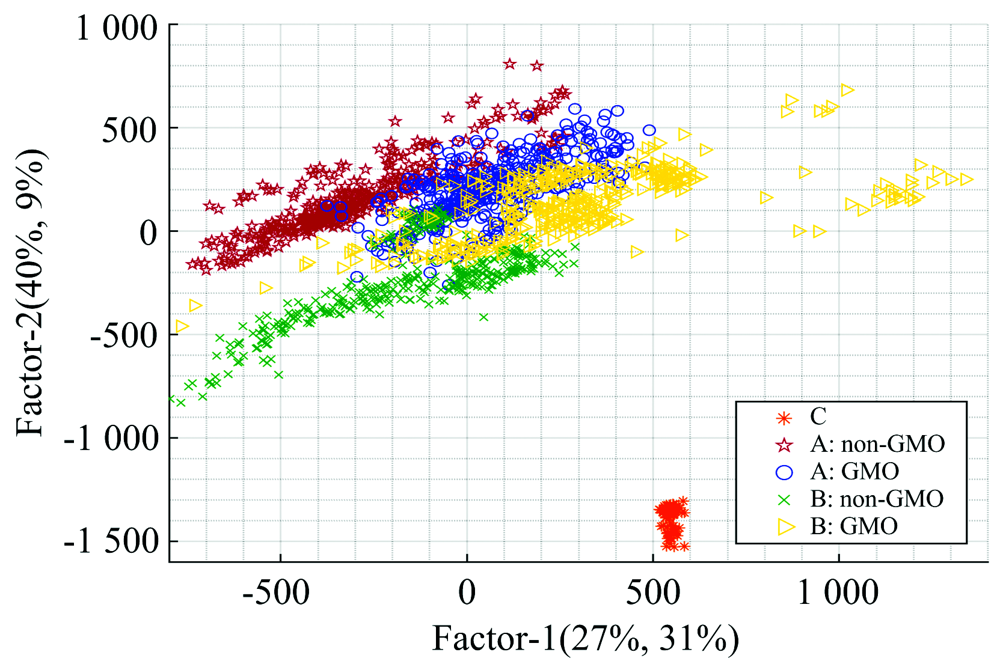 | 图7 PLS-DA模型中五类样品的分布情况Fig.7 Distribution of the 5 types of samples in the PLS-DA model |
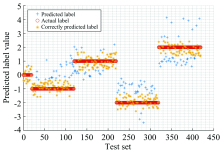
模型建立后, 输入测试集的420组样品, 得到预测的标签值, 将其与实际标签值对比, 判别阈值设置为0.5, PLS-DA模型对样品测试集的预测情况如图8。 结合图7及图8的数据分布得到, 稻米油(C类)与其他样品的差异较大, 模型建立效果较好, 仅有一个样本标签预测错误; 由于不同类大豆油拉曼谱线相似, 数据分布存在重叠, 会对预测准确率产生一定的误差, 但不影响大部分数据的预测。 根据计算最终得到模型的判别准确率达70.95%, 这表明紫外拉曼光谱结合PLS-DA分析方法对转基因大豆油的鉴别具有可行性。
 | 图8 PLS-DA模型对样品测试集的预测情况 +: 预测标签; ○: 实际标签; ❋: 正确的预测标签Fig.8 The prediction of the PLS-DA model for the sample test set +: Prediction label; ○: Actual label; ❋: Correctly predicted label |
采用紫外拉曼光谱技术, 结合支持向量机, 主成分分析以及偏最小二乘回归分析法, 对稻米油、 转基因/非转基因大豆油进行鉴别研究, 并取得较好的鉴别效果。 论文实验训练集和测试集分别为1 680组和420组, 使用支持向量机对油品进行建模时的识别准确率可达99.81%; 采用无监督式的主成分分析法对样品建模时, 可提取出8个特征峰, 主成分累计贡献率为74.84%, 可以代表大部分原始数据特征, 但无法提升到80%以上, 存在局限性; 使用有监督式偏最小二乘回归分析法PLS-DA时, 模型中样本可分, 但存在部分重叠, 经过对验证集样品标签的预测, 准确率为70.95%, 说明PLS-DA可成功预测大部分转基因大豆油类型。 综上所述, 针对紫外拉曼光谱鉴别转基因大豆油, 采用有监督分类法的效果优于无监督分类法。
由于紫外拉曼光谱检测仪可以在自然环境下进行一定距离的遥测, 不仅可对毒品、 爆炸物等危险品进行有效检测, 也可望为市场上各类转基因、 添加剂或过期食品的检测提供一种高效率的有效方法, 具有广泛的应用前景。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|