






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于波段注意力卷积网络的近红外奶粉皮革水解蛋白掺假检测
[陈国喜1, 2  , 周松斌
, 周松斌2, * , 陈颀1 , 刘忆森2 , 赵路路2 , 韩威2 ]
, 周松斌, 陈颀|
|


作者简介: 陈国喜, 1997年生, 昆明理工大学信息工程与自动化学院硕士研究生 e-mail: yonhang@163.com
近年来, 深度学习技术在近红外光谱、 拉曼光谱、 荧光光谱等的光谱学数据建模上取得一系列突破。 由于深度学习方法对于样本数量的需求高, 而在分析化学领域获得大量有标签样本较为困难, 因此过拟合问题一直是深度神经网络在化学计量学中应用时研究者高度关注的问题。 该工作提出基于波段注意力卷积网络(WA-CNN)的近红外数据建模方法, 并应用于婴儿配方奶粉皮革水解蛋白(HLP)掺假定量分析。 WA-CNN在传统卷积网络的基础上加入波段注意力模块, 该模块采用卷积操作自训练波段注意力权值, 并以乘法加权形式对有效波段进行激活, 从而有效缓解深度神经网络在近红外数据建模中的波段信息冗余问题, 达到抑制过拟合, 提升预测精度的目的。 研究中共测试100个皮革水解蛋白掺假婴儿配方奶粉样本的近红外光谱数据, 其中皮革水解蛋白的掺假比例范围是0%~20%。 采用60%的样本训练, 剩余40%样本测试, 随机采样10次, 通过测试集均方根误差(RMSEP)、 决定系数(R2)以及相对分析误差(RPD)的均值来进行模型评价。 并建立偏最小二乘回归(PLS)、 支持向量机回归(SVR)和常规的一维卷积神经网络(CNN)三种传统模型用于对比。 与上述对比方法相比, WA-CNN取得最优的模型预测结果, 最终获得了RMSEP=1.32%±0.12%, R2=0.96±0.01, RPD=4.92±0.41的掺假定量预测结果。 此外, 实验结果还表明, 相比于传统CNN, WA-CNN在训练过程中对于训练集及测试集损失函数都具有更快更稳定的收敛速度。 在20%~80%的不同训练样本数量情况下, WA-CNN相比于三种对比方法均取得最优的模型预测结果。
In recent years, deep learning has made a series of breakthroughs in processing near-infrared spectroscopy, Raman spectroscopy, fluorescence spectroscopy and other spectroscopy data. However, due to the high demand for deep learning methods for the size of the training set, and it is difficult to obtain a large number of labeled samples in the field of analytical chemistry, the overfitting issue has always been highly-concerned by researchers in the application of deep neural network in chemometrics. In response to this problem, this paper proposed a near-infrared spectra modeling method based on the wavelength attention-convolutional neural networks (WA-CNN) and applied it to the quantitative analysis of hydrolyzed leather protein (HPL) adulteration in infant formula. WA-CNN adds a wavelength attention module based on the traditional convolutional network. This module uses convolution operation to learn the attention weights and activates the effective bands in the form of multiplication, thereby effectively alleviating the redundancy and over-fitting problem in NIR modeling based on deep learning. A total of 100 HLP adulterated infant formula samples were tested, and the adulteration ratio was in the range of 0% to 20%. Random sampling was performed 10 times for modeling, in which 60% of the samples were used for training, while the remaining 40% of samples were adopted for testing. The model was evaluated by the mean of root mean square error (RMSEP), coefficient of determination (R2) and relative analysis error (RPD). Three traditional models, namely partial least squares regression (PLS), support vector machine regression (SVR) and conventional one-dimensional convolutional neural network (CNN), were also established for comparison. Compared with the above comparison methods, WA-CNN achieved the best model prediction results and obtained RMSEP=1.32%±0.12%, R2=0.96±0.01, RPD=4.92±0.41. In addition, the results also show that the WA-CNN has a faster and more stable convergence process than the traditional CNN for both the training set and the test set during the training process. Moreover, in the case of different training sample sizes (ranging from 20% to 80%), WA-CNN also achieves the best accuracies among all the examined models.
掺假奶粉不仅降低了乳制品的营养质量, 而且给消费者带来了重大的健康风险[1, 2]。 在三聚氰胺之后, 又涌现出例如皮革水解蛋白(HLP)等一些新类型的乳制品掺假物, 令检测的难度加大, 对乳制品掺假检测手段研究需求日益迫切。 近红外光谱(NIR)是一种具有实时响应、 检测简单、 仪器成本相对低廉、 无损检测和环境友好分析等优点的分析技术[3], 在乳制品掺假检测领域具有良好的应用前景。
为了实现高精度、 高鲁棒性的乳制品掺假识别与定量分析, 不少研究者探索了各类模型近红外建模方法在乳制品掺假识别中的应用。 例如庞佳烽等采用线性判别分析方法和非相关线性判别分析方法, 成功地实现了含三聚氰胺掺伪奶粉的鉴别[4], 有研究使用偏最小二乘法对掺入牛奶的羊奶进行鉴别和定量, 测定其脂肪和蛋白质含量[5]。 近年来, 深度神经网络在近红外光谱、 拉曼光谱、 荧光光谱等的光谱数据处理中的应用受到研究者的广泛关注。 然而, 近红外光谱数据存在谱信息的冗余与共线性, 且大量有标签的样本制备和收集较为困难[6]。 因此, 深度神经网络在近红外光谱建模中的过拟合问题, 一直是该研究面临的一大挑战。 针对近红外光谱的信息冗余与共线性问题, 曾有研究者提出了各种类型的有效波段选择方法, 例如Shan等针对咖啡水溶液中绿原酸浓度测试开发了基于GA和SPA方法选择有效波长的校准模型, 并取得了更好的性能[7], Vaddi等提出使用最优相邻重建(ONR)方法选择的高光谱数据的非相关频带可以在目标分类任务上有更好的表现[8]。 近几年, 也有研究提出了基于了神经网络的特征波段选择方法[9, 10], 但往往涉及到特征的重排列与多次重复训练, 计算效率有待提升。
本工作提出了一种基于波段注意力的近红外光谱建模方法(wavelength attention-convolutional neural networks, WA-CNN), 应用于奶粉的皮革水解蛋白掺假定量分析。 本方法采用卷积层结构自训练波段重要性权值, 并以乘法加权方式进行波段激活, 从而实现基于注意力的定量分析。 研究中还采用了三种经典回归方法(PLS, SVM和CNN)进行比较。 将PLS模型得到的回归系数用于概率波长选择[11], 并与提出的WA-CNN模型得到的权重进行了比较。
1.1.1 样品制备
实验中共测试了100个HLP掺假的婴儿配方奶粉样本。 HLP浓度按照0.5%梯度配置了掺假比例0%~20%的样品。 为保证模型具有更好的泛化能力, 婴儿配方奶粉样品包含三个品牌的婴儿配方奶粉: 惠氏、 美智臣和贝因美, 及三种品牌奶粉的随机比例混合。 HLP粉购自三家生产商(北京开泰; 德国嘉吉; 无锡AccoBio), 掺假物为三个生产商HLP的随机比例混合粉体。 将HLP掺入婴儿配方奶粉, 并充分搅拌均匀, 形成掺假样品。
1.1.2 近红外光谱
采集通过手持近红外分析仪(DLP NIRscan Nano: Texas Instruments, Dallas, TX, USA)获得样品的近红外光谱数据。 分析仪光谱范围为900~1 700 nm (11 000~5 880 cm-1), 扫描分辨率为2.8 nm。 每个样品重复16次扫描并取平均值。
为了提高定标精度, 删除了光谱起始和末端波段, 以避免为这些区域存在较为明显的仪器噪声。 使用1 000~1 600 nm(波段数量为180个)的光谱进行分析。 对所有的近红外光谱数据进行一阶Savitzky-Golay导数预处理[12](平滑点为9, 多项式阶数为2), 以达到基线校正和平滑的目的。
研究中提出了一种基于波段注意机制与卷积神经网络(WA-CNN)的近红外光谱分析算法, 该算法通过自训练注意力方式对各波段特征进行加权, 从而使有效波段贡献度更高, 实现减低冗余、 抑制过拟合、 提升算法精度的目的。 WA-CNN分为两部分: 注意力模块和回归模块。 注意力模块中包含两个一维卷积层, 整个模块不改变输入输出的特征大小, 可以很方便地嵌入到回归模型中。
WA-CNN模型具体结构与数据流程如下:
(1)原始光谱特征输入注意力模块, 经过两层卷积操作和非线性激励, 注意力模块输出波段权值
式(1)中, Fo为原始光谱特征, φ (x)为注意力模块中的卷积操作, wA为输出的波段权值。
(2)波段权值与原始光谱以乘法形式进行加权, 在此过程中, 有效波段将被激活, 对与后续回归计算的贡献量更大。 加权处理流程可表示为式(2)
(3)加权后的光谱特征作为回归模块的输入, 回归模块采用典型的卷积神经网络结构, 最终的预测输出为
式(3)中, P为归一化的预测输出, wj和b为回归模块输出层的权值与偏置。
最终构建整个模型前, 对WA-CNN网络结构采用训练集内部交叉验证方法进行优化。 其中, 回归模块卷积层数在1~5范围内进行优化, 卷积层滤波器数量在(8, 16, 32, 64)范围内进行优化。 最终得到优化的卷积层数和每个卷积层的滤波器数量分别为3和16。 并且在研究中发现, 加入池化层会降低模型精度, 因此回归网络结构中并未加入任何池化层。 优化后模型的结构参数如图1。 网络的学习率和迭代次数分别为0.000 1和2 000。
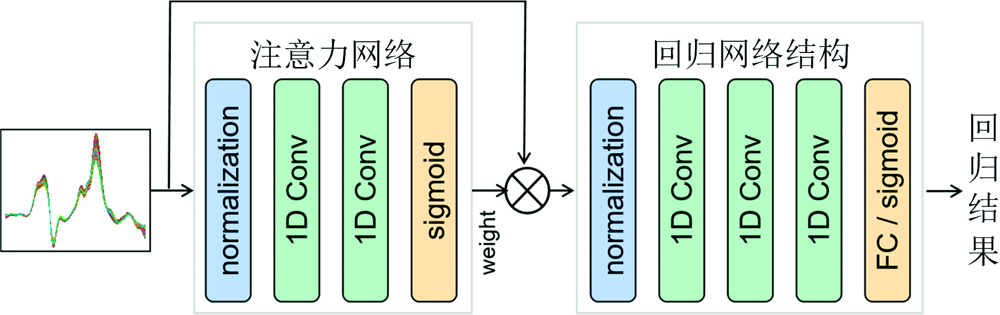 | 图1 WA-CNN网络结构Fig.1 Architecture of the proposed WA-CNN |
1.4.1 偏最小二乘回归
偏最小二乘法(partial least squares, PLS)回归是一种经典的化学计量学线性回归分析方法[13]。 在PLS模型建立之前, 采用训练集内10折交叉验证方法优化主成分数, 优化范围为5~25。
1.4.2 支持向量机回归
支持向量回归(support vector regression, SVR)是一种常用的非线性回归分析方法[14]。 本工作选用径向基函数(radial basis function, RBF)作为核函数, 使用网格搜索(grid search, GS)算法及训练集内的5-折交叉验证方法, 优化SVR的惩罚参数C与核函数的参数γ 。
1.4.3 一维卷积网络
常规的一维卷积神经网络(CNN)也用于模型比较。 为了和所提出算法进行合理、 公正的比较, CNN的网络超参数, 包括卷积层数量、 卷积层厚度、 卷积核尺寸、 非线性激励函数等, 均与WA-CNN中的回归模块保持一致。
定量分析模型主要采用训练集均方根误差(RMSEC)、 测试集均方根误差(RMSEP)、 测试集的决定系数(coefficient of determination, R2)以及相对分析误差(RPD)进行评价。 其中, RPD的计算公式为
式(4)中, SD是测试集样本标签的标准差。
训练集与验证集的比例为60%(60个样本)和40%(40个样本)。 为了准确评价模型的性能, 进行10次随机取样与建模, 用10次训练与测试得到的测试集均方根误差(RMSEP)、 决定系数R2和相对分析误差(RPD)的平均值和标准差评价各定量分析模型的预测能力。
为确保所提方法及所有对比方法都得到充分优化, 采用在训练集内部交叉验证的形式, 优化各模型的超参数。 在本研究中, 所有基于CNN的方法都在开源平台TensorFlow上进行, PLS和SVR模型采用sklearn机器学习库实现。
图2为五个不同HLP含量样本的原始光谱曲线及预处理后光谱曲线。 由图2(a, b)可见, 不同HLP含量样本红外光谱反射率整体趋势相似, 经过一阶导数处理后差异仍不明显。 在近红外光谱范围内, 蛋白质的氨基酸中含有的含氢基团(比如C— H, N— H, O— H)会形成较为明显的吸收峰。 图2(a, b)中在1 150~1 200 nm间有一个吸收峰, 主要由C— H键的二级倍频产生, 在1 400~1 540 nm间有一个较强的吸收峰, 分析认为由游离的N— H和O— H基团产生的一级倍频以及C— H基团的组合频。
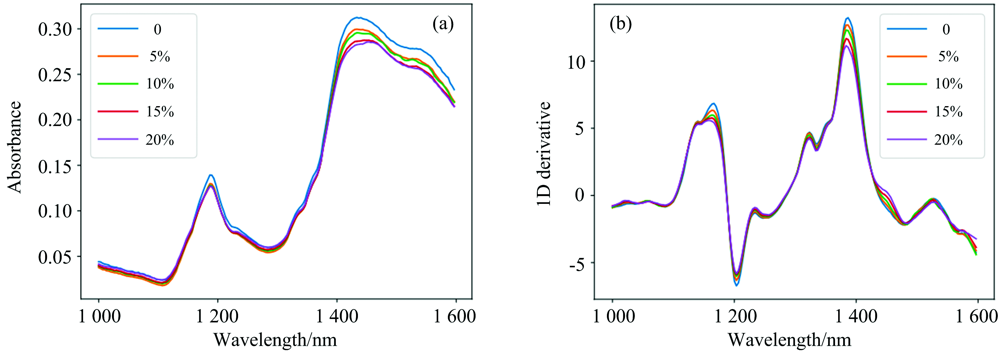 | 图2 不同HLP浓度样本的近红外光谱吸收图 (a): 原始光谱; (b): 一阶导数光谱Fig.2 NIR spectra of samples with different HLP concentrations (a): Raw spectra; (b): Spectra ofter 1D derivative preprocessiong |
采用经典流形学习方法T分布随机邻域嵌入(tSNE)对预处理后的近红外光谱数据进行降维可视化分析[15](见图3), 评价其定量分析的潜力。 从图3可见, 掺假含量与主成分之间难以观察到明显的变化规律, 显示出在婴儿配方奶粉中进行皮革水解蛋白掺假定量分析具有一定的难度。 其主要原因是皮革水解蛋白为复杂混合物, 其近红外光谱特性较为复杂, 且皮革水解蛋白主要成分为动物性水解蛋白, 与奶粉中的蛋白质有一定的相似性。
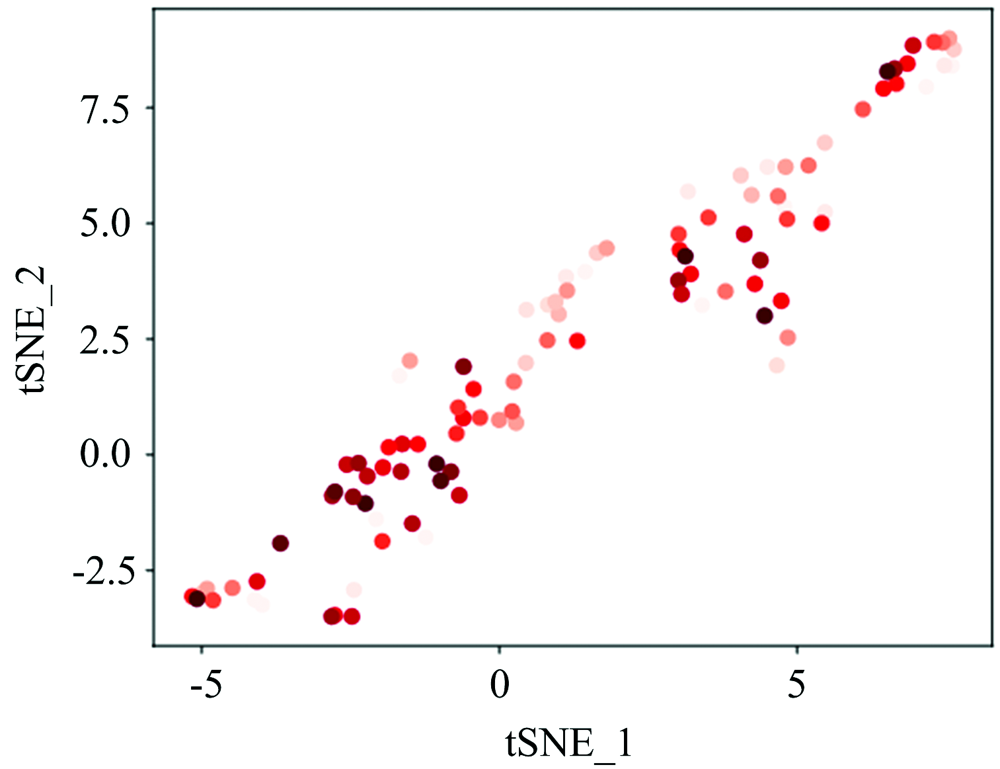 | 图3 tSNE分析可视化效果图Fig.3 Visualization by tSNE |
为了直观的观察到波段注意力模块的波段选择效果, 将波段注意力模块得到的波段权值绘制曲线展示于图4(a)。 PLS建模得到的每个波段的相关系数绝对值同样可用于表征波段的重要性, 因此绘制相关系数曲线于图4(b)中用于对比。 由图4(a)可见, 波段注意力权值曲线具有非常明显的峰值, 表明各个波段在掺假奶粉定量分析任务中重要性有明显区别。 权值曲线突出的波长集中在三个区域: 1 090~1 120, 1 280~1 320和1 400~1 550 nm。 对比PLS模型得到的相关系数曲线, 其相关性高的区域与波段注意力方法基本吻合, 但是相关系数曲线更加平缓, 相关系数区分度不显著。
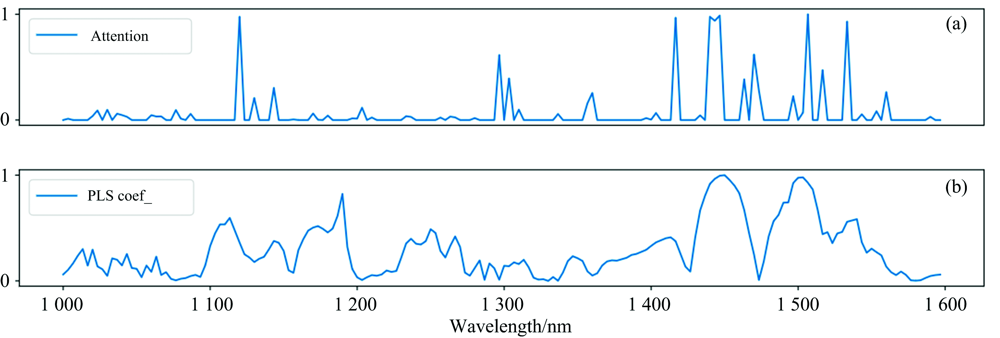 | 图4 (a)波段注意力权值曲线; (b)PLS相关系数曲线Fig.4 (a) Attention weight curve; (b) PLS correlation coefficient |
工作中将研究不同的注意力模块结构超参数对于WA-CNN网络性能的影响, 具体研究的结构超参数包括注意力卷积层的层数和注意力卷积层的非线性激活函数。 采用训练集内五折交叉验证的验证集均方根误差(RMSECV)、 验证集决定系数来
保持注意力卷积层数量为2, 对注意力模块中每层卷积的激活函数寻优。 采用Relu、 PRelu、 tanh等典型激活函数的组合, 在其他参数不变的情况下, 改变注意力模块中两个卷积层的激活函数, 分别采用验证集测试网络性能, 结果如表1所示。 最终两个注意力卷积层的激活函数为Prelu和Relu时, 取得最佳的验证集预测效果。
| 表1 注意力模块中不同激活函数组合得到的交叉验证结果 Table 1 Cross validation result obtained by attention module corresponds to different activation function |
在优化后的模型超参数基础上, 对WA-CNN网络进行训练及最终的模型表现评估。 为了展示加入波段注意力模块对于模型训练过程的影响, 将CNN和WA-CNN在训练过程中训练集和测试集损失函数变化图及决定系数变化图列于图5。 由图5(a)可见, 对比CNN, 无论训练集还是测试集, 图5(b)中CNN和WA-CNN在训练过程中测试集上R2变化也反映了此规律。 WA-CNN的损失函数早期变化更加陡峭, 更快进入平台期, 说明网络收敛速度更快。 并且可观察到WA-CNN网络的训练集与测试集损失函数差距更小, 有效缓解了过拟合。
 | 图5 CNN和WA-CNN训练过程中的损失函数和决定系数曲线 (a): 测试集和训练集的loss曲线; (b): 测试集R2曲线Fig.5 Loss and R2 curves of CNN and WA-CNN over training epochs (a): Loss curves of the training and test sets; (b): R2 curve of the test sets |
为了验证训练集样本数量对于各模型表现的影响, 改变训练集比例(20%~80%), 并在每种比例下随机取样10次, 观察WA-CNN及对比方法的模型表现[见图6(a— d)]。 总体来说, 在小样本情况下, 由于过拟合问题, CNN的表现差于PLS和SVR, 而WA-CNN在各个不同的训练集比例下都取得优于其他三种对比方法的结果, 尤其是在训练样本非常小的情况下, WA-CNN相比于对比方法的预测精度提升更加明显, 验证了本工作所提算法在小样本情况下的优越性。 WA-CNN训练基于卷积层的波段权值, 以乘法加权形式激活有效波段, 从而有效缓解近红外光谱建模中波段信息冗余问题, 从而能够在小样本建模情况下取得更好的表现。
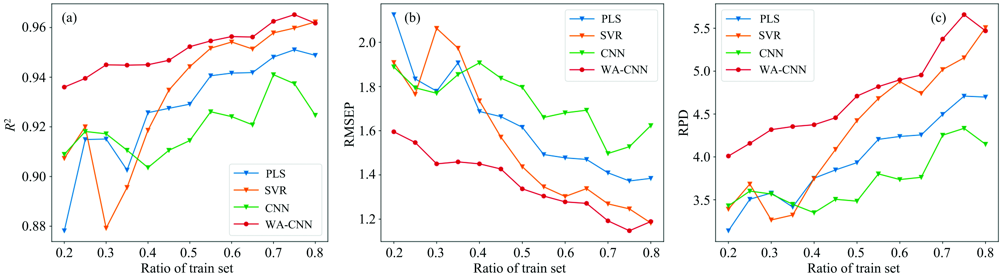 | 图6 不同大小训练集下的模型预测结果 (a): 测试集均方根误差; (b): 决定系数; (c): 相对分析误差Fig.6 The prediction effect under different training set size (a): RMSEP; (b): R2; (c): RPD |
将本方法及对比方法对皮革水解蛋白掺假含量预测结果总结于表2。 由表中数据对比可见, 相比于PLS, SVR和CNN方法, WA-CNN在RMSEP, R2和RPD指标上均取得最优结果, 尤其对比常规CNN有较大的提升。 WA-CNN模型在RMSEP上较PLS, SVR和常规CNN分别提高了18.5%, 9.5%, 29.4%, 体现了该方法的优越性。
| 表2 采用WA-CNN和对比方法得到的HLP奶粉掺假定量分析结果 Table 2 Regression WA-CNN and contrast method regression analysis results of HLP data |
分别取四种方法十次随机取样中预测精度最接近平均值的一次结果绘制回归散点图于图7。 从图中可以看出, CNN回归发生了较为明显的过拟合, 而WA-CNN则未产生明显的过拟合现象, 在所有对比方法中取得了最好的回归预测效果。
 | 图7 不同模型得到的回归散点图 (a): PLS; (b): SVR; (c): CNN; (d): WA-CNNFig.7 Regression plots obtained by different models (a): PLS; (b): SVR; (c): CNN; (d): WA-CNN |
提出了一种基于注意机制的近红外数据定量分析方法WA-CNN, 并在婴儿配方奶粉皮革蛋白掺假数据集上对其进行了验证。 在该算法中, 将基于卷积运算的注意力模块学习到的权值作为自训练注意掩模进行波段激活, 进而实现进一步的回归建模。 预测结果表明, 与PLS, SVR和CNN等传统建模方法相比, 对于婴儿配方奶粉皮革蛋白掺假数据集, WA-CNN具有更好的回归预测能力, 最终获得了RMSEP=1.32± 0.12, R2=0.96± 0.01, RPD=4.92± 0.41的模型预测结果。 所述近红外定量分析方法在乳制品掺假等基于近红外光谱的食品安全检测领域具有广泛的应用前景。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|