


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于块稀疏学习的光谱基线校正方法
[陈苏怡 , 李浩然, 戴继生
, 李浩然, 戴继生* ]
, 李浩然, 戴继生]
|
|


作者简介: 陈苏怡, 1996年生, 江苏大学电气信息工程学院硕士研究生 e-mail: 2221907057@stmail.ujs.edu.cn
光谱数据在采集过程中易发生基线偏移现象, 导致后续的鉴别和分析结果偏离真实值。 因此, 在光谱数据分析前, 需利用基线校正技术获取更为准确的光谱数据。 基于稀疏贝叶斯学习(SBL)的基线校正方法无需人工选择参数, 基线校正结果在贝叶斯框架下具有最优性。 然而, 现有的稀疏贝叶斯建模较为简单, 无法适用于复杂的稀疏结构。 在实际应用中, 当纯谱的某些谱峰较宽时, 对应的稀疏向量将具有一定的块稀疏特性。 利用额外的块稀疏结构, 有助于进一步提升SBL方法的性能。 为了建模稀疏向量的块稀疏结构特性, 在原有的贝叶斯模型框架中引入模式耦合分层模型。 得益于稀疏贝叶斯框架固有的学习能力, 引入的模式耦合分层模型可自适应地学习稀疏向量的块稀疏结构, 从而大幅提升了基于SBL的基线校正方法的性能。 为验证本文方法的基线校正性能, 首先利用模拟数据集进行仿真实验, 并将该方法与SSFBCSP方法和SBL-BC方法在不同噪声方差条件下进行对比。 仿真实验结果表明, 该方法恢复谱峰较宽纯谱的效果提升明显, 特别是当噪声方差较大时, 其他方法的性能均有不同程度的下降, 但该方法依然具有较好的稳定性。 蒙特卡罗仿真实验结果也显示该方法纯谱拟合的标准化均方根误差明显优于其他对比方法。 最后, 利用色谱数据集与三种矿物的拉曼光谱数据集进行实测数据的基线校正性能验证, 结果表明该方法能产生比其他方法更为平滑的纯谱拟合结果, 且去噪效果更优。
Baseline deviation often occurs with the spectrum data acquisition, making the subsequent identification and analysis results deviate from the true values. Therefore, it is necessary to utilize the baseline correction technology to obtain more accurate spectrum data before the spectrum data analysis. The sparse Bayesian learning (SBL)-based baseline correction method can provide the optimal baseline correction results within the Bayesian framework, and it does not need to select parameters manually. However, the SBL framework is too simple to apply to complex sparsity structures. In practical implementations, if the peak of the pure spectrum is wide, the corresponding sparse representation vector would exhibit a block-sparsity property. The performance of the SBL method will be further improved if the additional block-sparse structure can be exploited appropriately. To this end, we introduce a coupling pattern model into the SBL framework to adaptively learn the block-sparse structure. Due to the inherent learning capability of the SBL framework, the proposed method can significantly improve the baseline correction performance. We conducted several simulations to evaluate the performance improvement, where the proposed method is compared to SSFBCSP and SBL-BC with different noise variances. The simulation results verify the superiority of the proposed method for wide peak recovery. Specifically, it has good stability when the noise level is high, but the performance of other methods degrades substantially. Monte Carlo simulation results further demonstrate that our method can significantly improve the pure spectrum fitting’s normalized mean square error (NMSE) performance. Finally, one real chromatogram dataset and three Raman datasets are used to validate the performance of the proposed method. The experimental results indicate that our method can produce smoother pure spectrum fitting and better denoising effects than others.
光谱分析主要包括红外光谱分析、 拉曼光谱分析、 原子光谱分析等技术, 它能快速测定样品的化学成分含量, 实现无损伤的定性和定量分析, 因此已被广泛应用于农业、 食品、 医学及化工等领域[1, 2, 3]。 然而光谱数据采集过程易受温度、 湿度等环境因素影响, 发生基线偏移现象, 从而对样品定性和定量分析的准确性产生较大影响[4]。 因此, 在光谱数据分析前, 需对光谱数据进行适当的基线校正[5]。
与纯谱相比, 基线的变化较为缓慢[6]。 利用该特性, 国内外研究人员提出了大量光谱基线校正方法。 基于惩罚最小二乘(penalized least squares, PLS)算法, 很多文献陆续报道了扩展PLS方法, 例如非对称加权惩罚最小二乘(asymmetrically reweighted penalized least squares, asPLS)[7], 双重加权惩罚最小二乘基线校正算法(doubly reweighted penalized least squares, drPLS)[8]以及改进的非对称最小二乘法(improved asymmetric least squares, IAsLS)[9]。 这些基于PLS的方法能够自动更新不对称权重, 但在低信噪比的情况下无法获得较好的基线校正精度性。 近年来, 随着压缩感知理论的快速发展, 基于稀疏表示的信号恢复技术在特征选择[10]、 人脸识别[11]、 信道估计[12]和光谱信号的基线校正[13]等方面取得长足发展。 Han等最早提出了一种基于稀疏表示的光谱基线校正方法[14], 其主要思想是通过引入光谱线型冗余字典将纯谱稀疏表示, 然后利用l1范数最小准则, 同时实现稀疏信号恢复和基线校正。 由于采用了l1范数近似, 上述方法不可避免地存在性能损失。 此外, l1范数相关的正则项难以选择, 且Voigt-like线型冗余字典不足以提供完备的基来准确地实现稀疏表达。 随后, Li等提出了一种基于稀疏贝叶斯学习(sparse Bayesian learning, SBL)的基线校正方法(SBL-BC)[15], 有效解决了l1范数近似方法性能下降的问题, 所有参数由最大后验概率确定, 避免人工选择正则项, 并引入网格细化技术解决了字典矩阵的偏离网格间隙问题, 获得了较好的基线校正性能。
然而, 现有的稀疏贝叶斯建模方法只适用于简单的稀疏信号恢复, 当纯谱的某些谱峰较宽时, 需多个相邻的高斯线型拟合该谱峰, 则对应的稀疏向量将具有一定的块稀疏特性。 SBL-BC尚无法适用于这种复杂的块稀疏结构。 利用额外的块稀疏结构, 有助于进一步提升SBL方法的性能。 为了建模稀疏向量的块稀疏结构特性, 我们在原有的贝叶斯模型框架中引入模式耦合分层模型[16], 使得稀疏向量中每个元素不仅受其对应的超参数影响, 还受相邻两个元素的超参数影响。 借助于稀疏贝叶斯框架具有固有的学习能力, 引入的模式耦合分层模型可自适应地学习稀疏向量的块稀疏结构, 大幅提升基于SBL的基线校正方法的性能。
假设采集到的数据维度为N的光谱x∈ RN由纯谱s∈ RN、 基线b∈ RN和随机噪声n∈ RN组成, 即
构造一个高斯线型矩阵A∈ RN× N, 其第(i, j)个元素为:
式(2)中,
式(3)中, w∈ RN表示一个稀疏向量, 其非零元素对应s的谱峰。 将式(3)代入式(1), 可得
若假设噪声n服从均值为零, 方差为σ 2的高斯分布, 则有
式(5)中, α =σ -2表示噪声精度。 与s相比, b变化非常平缓, 其二阶差分的结果Db大部分趋于零, 其中D∈ R(N-2)× N表示二阶差分矩阵[14]。 因此, 我们将Db建模为均值为零, 精度为β 的独立分布高斯过程, 即[15]
由于α 和β 未知, 在传统稀疏贝叶斯框架中, 一般假设它们服从伽马分布[15]
式(7)和式(8)中, c和d分别为一个较小的正实数。 为了构建w的稀疏先验特性, 假设w服从一个精度向量为γ =
且γ 服从独立伽马分布
根据上述稀疏贝叶斯模型, 联合分布p(x, Θ )可分解为
式(11)中, Θ ={w, α , γ , β , b}表示隐藏变量。
由于无法直接获得后验概率分布p(Θ |x)的闭式解, Li等采用变分贝叶斯推理(VBI)求得p(Θ |x)的最优近似解, 同时引入步进梯度算法迭代更新高斯线型函数方差的网格取值, 解决了离网间隙问题[15]。 SBL-BC的显著优势在于: (1)所有参数由最大后验概率确定, 无需人工参与; (2)基线校正结果在贝叶斯框架具有最优性, 能显著提升光谱基线校正性能。 然而, SBL-BC的贝叶斯建模较为简单, 无法适用于复杂的稀疏结构。 若s的某些谱峰较宽, 需多个相邻的高斯线型拟合, 这时w具有一定的块稀疏特性。 若能充分利用额外的稀疏结构特性, 将有助于进一步提升基于SBL的基线校正方法性能。
为了建模w的块稀疏结构特性, 本节我们将在贝叶斯框架下引入模式耦合分层模型[16], 自适应地学习w的块稀疏结构, 大幅提升基于SBL的基线校正方法的性能。
为处理随机块状稀疏信号, 我们拟采用文献[16]中提出了模式耦合模型, 其主要思想是: 假设w的每个元素(例如wn)不仅受其对应的精度影响(即γ n), 还受相邻元素的精度(即γ n-1和γ n+1)影响。 因此, 若定义zn=
而zn建模为均匀类别分布
进一步, 将式(9)替换为式(12)和式(13), 则联合分布p(x, Θ )可重写为
其中隐藏变量重写定义为Θ ={w, α , γ , β , b, Z}。 由于依然无法获得后验分布p(Θ |x)的闭式解, 我们将采用变分贝叶斯推断寻找一个最优的近似解。
依据文献[17], 我们首先将p(x, Θ )分解为
上述分解形式并不唯一, 最优分解形式应最小化p(Θ |x)和q(Θ )的Kullback-Leibler(KL)离散距, 即
KL离散距小, 其相似程度越高。 根据变分贝叶斯推导[17], 式(16)的解为
式(17)中, θ g表示Θ 第g个元素,
由于q* (θ g)取决于q* (θ i), i≠ g, 需通过迭代更新获得稳态解。 下面我们将依次讨论如何更新各个q(θ g)。
在更新q(w)时, 有
式(18)中, Ψ l=diag{φ 1, l, …, φ N, l}, φ n, l=q(zn=el), Λ =diag{
式(19)中
在更新q(α )时, 有
由此可知, q(α )服从伽马分布
在更新q(γ )时, 有
式(26)中:
γ n的期望为
q(β )与q(b)的更新过程与上面相似, 类比可得
其中
q(Z)的更新过程可由文献[16]的推导获得, 但在实际应用中, 为了避免过拟合, 我们可简单地采用均匀分布
此外, 为了快速计算式(34)和式(35), 采用与SBL-BC相似的方法, 设
3.1节和3.2节中分别采用模拟数据集和真实数据集评估所提方法的性能。 在所有仿真实验中, 本文方法初始化参数设置如下:
在仿真1中, 针对指数基线构造的模拟数据集, 将本文方法与SSFBCSP[14]和SBL-BC[15]进行比较。 假设模拟数据集中纯谱为
式(37)中, 均值$\{\bar{μ}_{l}\}_{l=1}^{8}=\{75, 125, 150, 250, 275, 400, 550, 750\}$, 方差$\{\bar{σ}_{l}\}_{l=1}^{8}=\{50, 30, 80, 60, 50, 100, 80, 30\}$峰值{pl
式(38)中, bn表示b的第n个元素。 针对该模拟数据集, 将噪声方差分别设为σ 2={10-4, 10-2, 10-1}。 图1为不同基线校正方法估计出的纯谱, 红色实线为估计出的纯谱, 黑色虚线为真实光谱。 由图可知, 当噪声方差较小(即σ 2=10-4)时, SSFBCSP方法估计出的纯谱性能较差, SBL-BC和本文方法性能均可获得较好的纯谱拟合性能。 当噪声方差增大(例如σ 2=10-1)时, SSFBCSP方法性能下降明显, SBL-BC方法和本文方法的纯谱拟合性能均略有下降。 无论噪声方差如何变化, 本文方法都能表现出最优的估计性能。
 | 图1 模拟指数基线下不同基线校正方法估计的纯谱对比图 (a): 原始光谱; (b): SSFBCSP; (c): SBL-BC; (d): 本文方法Fig.1 Estimated spectrum comparison among different baseline correction strategies for simulated exponential baseline (a): Original spectrum; (b): SSFBCSP; (c): SBL-BC; (d): Our method |
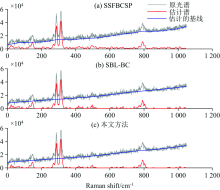
在仿真2中, 本文通过蒙特卡罗实验研究了信噪比与纯谱拟合的标准化均方根误差(normalized mean square error, NMSE)的关系, 其中NMSE的定义为
式(39)中, 蒙特卡罗实验次数M=200,
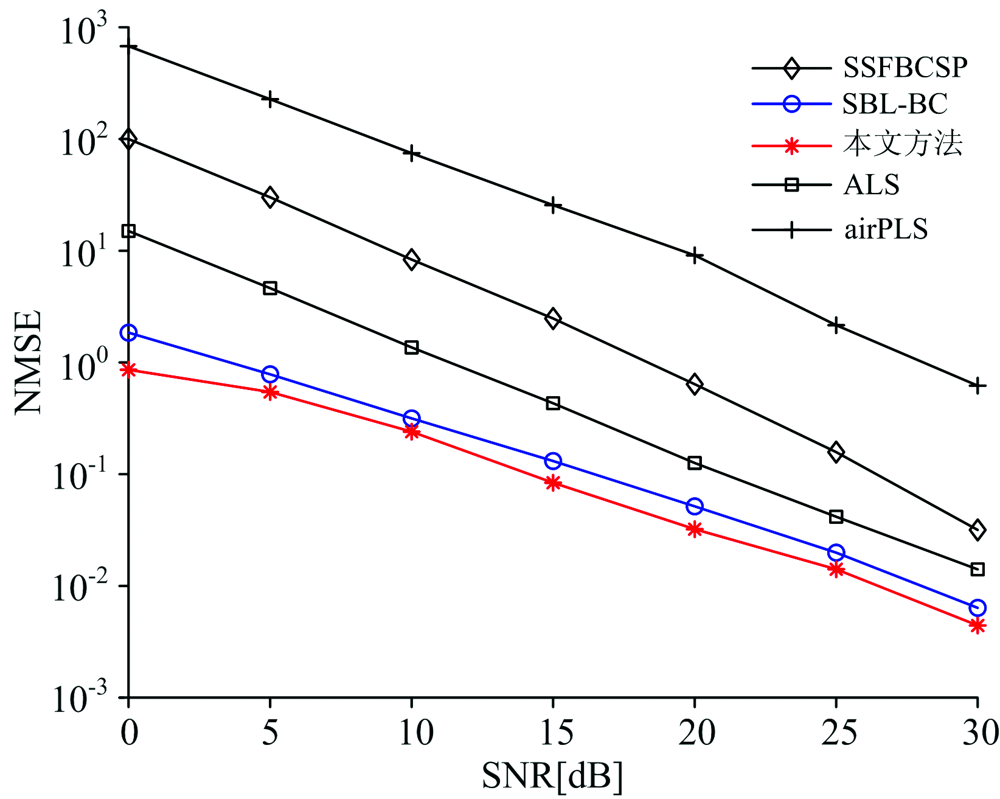 | 图2 模拟指数基线下随信噪比变化的纯谱拟合NMSE性能对比图Fig.2 NMSE performance comparison of spectrum fitting versus SNR for simulated exponential baseline |
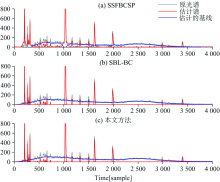
在实测数据实验中, 本文分别使用色谱数据集和三种不同矿物的拉曼光谱数据集(微斜晶石(R040154.3), 准蒙脱石(R050391), 马来石(R040043))进行仿真实验[15]。 将本文方法与SSFBCSP[14]和SBL-BC[15]进行比较, 灰色实线为原光谱, 红色实线为估计出的纯谱, 蓝色实线为估计出的基线。
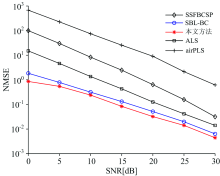
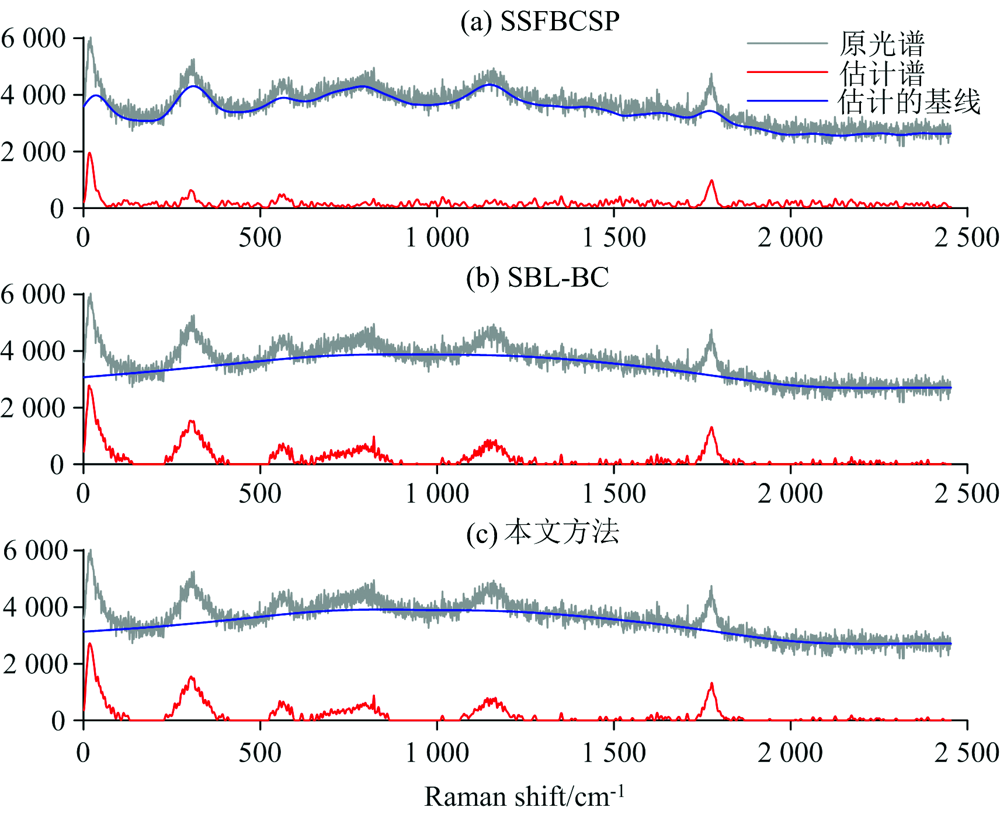
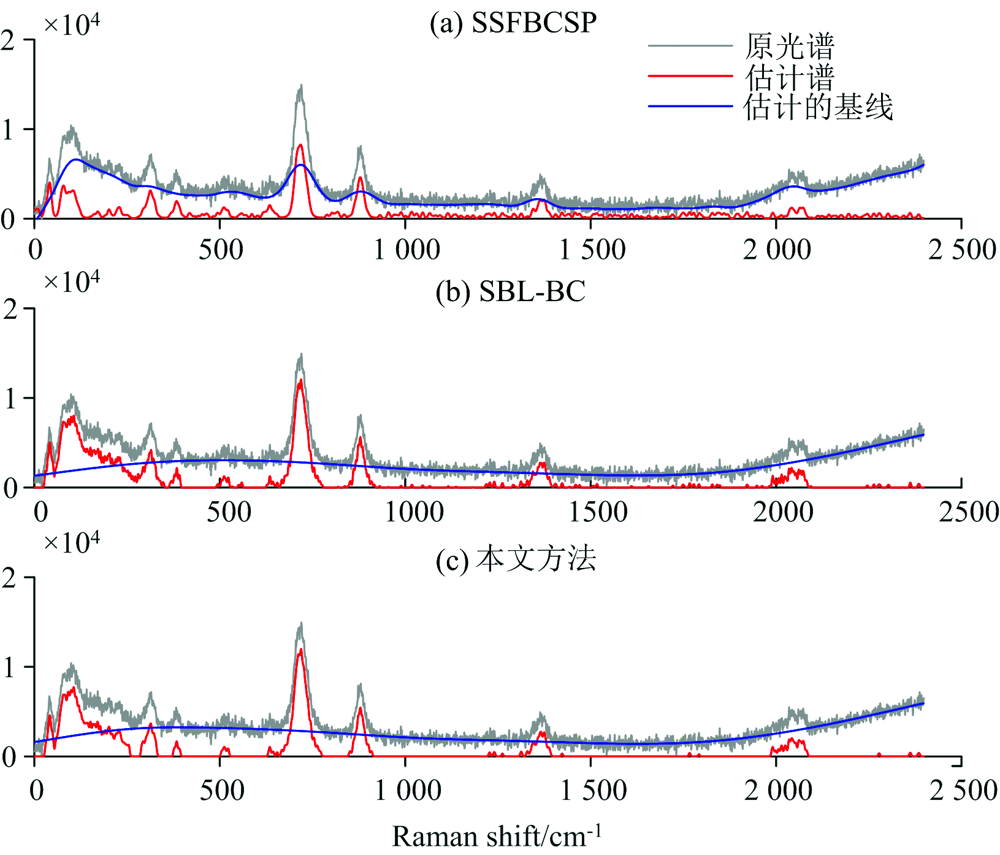
图3为基于色谱数据集估计出的纯谱与基线, 横坐标为时间, 噪声方差设为σ 2=10-4。 图4、 图5和图6分别表示基于三种不同矿物的拉曼光谱数据集估计出的纯谱与基线, 横坐标为拉曼位移, 噪声方差均设为σ 2=10-3。 可以看出, 在色谱数据集中, SSFBCSP表现出去噪效果, 但没有对第1 000次样本附近的基线进行校正, SBL-BC方法与本文方法估计出的基线非常相似, 但本文方法获得了更好的光谱信号重构性能, 具有较好的基线校正效果; 微斜晶石数据集中, 本文方法表现出较好的抑制基线偏移的性能; 准蒙脱石和马来石数据集中, 本文方法估计出的纯谱信号更平滑, 可过滤较多的噪声; 对比三种矿物的拉曼光谱数据集, 本文方法表现出了最优的基线校正准确性。
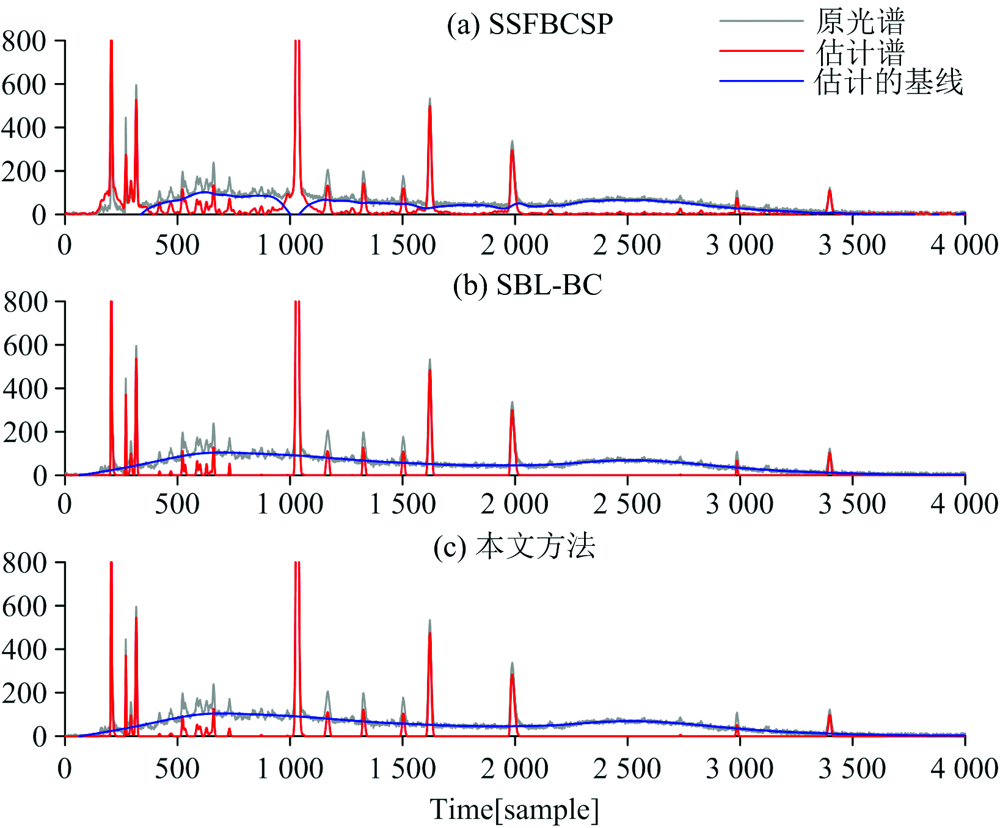 | 图3 色谱数据集的基线校正对比图Fig.3 Comparison of baseline correction for chromatograms dataset |
 | 图4 微斜晶石数据集的基线校正对比图Fig.4 Comparison of baseline correction for microcline dataset |
 | 图5 准蒙脱石数据集的基线校正对比图Fig.5 Comparison of baseline correction for paramontroseite dataset |
 | 图6 马来石数据集的基线校正对比图Fig.6 Comparison of baseline correction for marialite dataset |
最后, 表1列出了每个数据集的程序运行时间。 可以看出, 对于维度为4 000的数据集, 本文方法的程序运行时间不到5 s, 维度在2 500左右的数据集, 运行时间约为3 s。 本文方法执行时间略多于SBL-BC, 但明显少于SSFBCSP, 且本文方法的纯谱拟合与去噪效果明显优于SBL-BC和SSFBCSP方法。
| 表1 不同基线校正方法的运行时间对比 Table 1 Comparison of the running time of different baseline correction methods |
在原本的稀疏贝叶斯框架中引入模式耦合模型, 使得稀疏向量中每个元素不仅受其对应的超参数影响, 还受相邻两个元素的超参数影响。 为充分利用稀疏向量中的结构特征性, 提出一种基于块稀疏的方法进行基线校正, 解决了稀疏贝叶斯模型由于难以适用于复杂稀疏结构进而导致性能下降的问题。 利用指数基线构造的模拟数据集进行实验仿真, 在不同信噪比下将本文方法与SBL-BC等其他方法相对比, 本文方法获得了更精确的纯谱拟合结果。 真实数据集的实验对比结果表明, 本文方法较SBL-BC方法获得更精确的光谱信号重构性能, 同时表明了本文方法在实际应用中的普适性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|