

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于IFSR异常样本剔除的落叶松木材密度近红外优化模型的研究
[张哲宇 , 李耀翔
, 李耀翔* , 王志远, 李春旭]
, 李耀翔, 王志远, 李春旭]
|
|


作者简介: 张哲宇, 1997年生, 东北林业大学工程技术学院博士研究生 e-mail: 1453029789@qq.com
木材密度可以反映木材的干缩性、 抗压抗拉强度等多种物理性质, 是重要的木材物理特性。 采用近红外光谱技术能够实现木材密度的快速预测, 可克服传统检测方法耗费人力、 物力、 时间的弊端, 但建模结果往往受异常样本的影响。 为准确识别并剔除样本集中的异常样本, 提出一种孤立森林结合学生化残差方法(IFSR), 在利用孤立森林集成特征的优点基础上考虑样本对模型的影响度, 可同时检测异常样本与强影响样本。 该研究对181个落叶松木材样本的近红外光谱及其在常温下的气干密度进行了测定。 通过对比多种方法预处理和特征选择方法, 确定采用标准正态变量变化(SNV)+去趋势处理(DT)+均值中心化(MC)+标准化(Auto)方法进行预处理, 采用竞争性自适应重加权算法(CARS)进行特征波段选择, 消除噪声及无关信息对算法的影响, 简化数据集, 提高算法剔除异常样本的准确性。 为验证IFSR方法剔除异常样本的能力, 将其与蒙特卡洛交互验证(MCCV)、 马氏距离(MD)等其他六种异常检测方法对比分析, 建立偏最小二乘(PLS)模型对其进行异常检测性能评价。 同时在上述基础上采用粒子群寻优-支持向量机回归(PSO-SVR), BP神经网络(BPNN)与PLS分别建立落叶松木材密度近红外预测模型。 结果表明, IFSR结合PSO-SVR方法得到的优化模型预测能力最强, IFSR可有效剔除奇异样本, 提高模型精度。
Wood density is an important physical property of wood which can reflect a variety of physical properties such as wood shrinkage, compressive and tensile strength. Using near-infrared spectroscopy technology can rapidly predict wood density, which can overcome the disadvantages of traditional detection methods that consume workforce, material resources and time. However, the modeling results are often affected by abnormal samples. In order to accurately identify and eliminate abnormal samples in the sample set, an isolation forest combined with the studentized residual method (IFSR) was proposed. Based on the advantages of integrated features of isolated forests, the influence of samples on the model is considered, and abnormal samples and strong influence samples can be detected simultaneously. This study measured the near-infrared spectra of 181 larch wood samples and their air-dry density at room temperature. By comparing a variety of preprocessing and feature selection methods, the preprocessing method was determined to adopt the standard normal variable change (SNV) + detrending processing (DT) + mean centralization (MC) + standardization (Auto) method and the feature wavelength selection was determined to adopt competitive adaptive reweighted sampling (CARS) method. Eliminated the influence of noise and irrelevant information on the algorithm, simplified the dataset, and improved the algorithm's accuracy in removing abnormal samples. In order to verify the ability of the IFSR method to eliminate abnormal samples, it was compared with the other six anomaly detection methods such as Monte Carlo Interactive Verification (MCCV), Mahalanobis Distance (MD), etc. The partial least squares (PLS) model was established to evaluate its anomaly detection performance. At the same time, the particle swarm optimization-support vector machine regression (PSO-SVR), BP neural network (BPNN) and PLS were used to establish the near-infrared prediction model of larch wood density. The results show that the optimized model obtained by IFSR combined with PSO-SVR has the strongest predictive ability, and IFSR can effectively eliminate singular samples and improve the model's accuracy.
木材密度可以很好地表征木材的干缩性、 抗压抗拉强度等物理性质, 同时还是确定加工价值与工艺需求的重要因素, 是提高木材利用率中应重点研究的木材材性之一[1, 2], 准确、 实时地估算木材密度对木材材性预测及合理造材具有重要意义。 近红外光谱技术是一种快速、 无损的检测技术[3, 4], 在近红外定量预测过程中, 所采集的样本数据可能存在因人为因素或仪器因素出现的奇异样本或偏离整体的强影响样本, 这些异常样本会带偏模型预测的方向, 使模型预测结果变得不可靠[5]。 因此有必要在近红外建模过程中剔除上述异常现象, 以提高模型的精度。 目前常用的剔除光谱异常样本的方法包括: 蒙特卡洛交互验证[6], 马氏距离[7], 杠杆值检验[8]及光谱残差检验[9]等。 近年来新方法也层出不穷, 尹宝全等提出一种联合光谱数据X与组分信息Y的ODXY异常样本剔除算法, 通过对羊肉近红外样本的异常剔除, 证明该算法能很好地提高模型的泛化能力[10]。 Brownfield等将排序差异和算法(sum of ranking differences, SRD)与Procrustes分析相结合, 通过同时跨窗口评估光谱与组分的异常值, 调整参数值来提高异常检测的效率和准确率[11]。 以上方法虽然可以有效识别异常样本, 但大多受经验阈值或建模偏差的影响, 容易在建模前的剔除过程中出现误判, 且对复杂样品的异常样本剔除能力相对较差, 从而降低了模型的泛化能力及准确性。
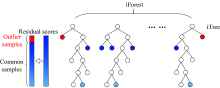
孤立森林算法(isolation forest, iForest)在统计学领域被广泛应用于识别高维复杂数据的异常值, 其认为特征空间中异常样本是孤立的, 可以选取子样本, 使用随机超平面构建孤立树iTree, 递归地连续分割数据集, 其中正常样本需要分割到孤立树较深层的叶子节点, 需要较长的分割路径, 而异常样本靠近孤立树根节点, 只需较短的分割路径就能孤立出来。 孤立森林算法不假设样本与背景空间的概率分布, 是一种采用特征集成方法的无监督异常检测方法。 目前孤立森林算法已开始应用于高光谱影像的异常识别[12, 13]等方面。
近红外光谱数据的高维性及复杂性, 在一定程度上限制了其建模精度及普及性, 将孤立森林算法应用于近红外光谱数据将会大大提高数据分析的有效性, 但是在实际应用中也遇到两个主要问题, 其一近红外光谱谱峰重叠严重, 且各个波段共线性强, 采用孤立森林划分时不易有效地区分无效波段与特征波段; 其二光谱数据全谱波段信息量较大, 可能会出现建完孤立树后遗漏有效特征。 针对以上两点, 在使用孤立森林算法检测近红外光谱异常值前应对光谱数据进行预处理及特征波段选择, 以减少噪声等对背景的干扰, 同时简化光谱数据, 增强光谱特征对比度。
为利用iForest高效检测异常目标的优点, 同时克服将其直接应用于近红外光谱分析的困难, 本研究提出一种孤立森林结合学生化残差方法(isolation forest-studentized residual, IFSR)。 首先通过对光谱数据预处理降低噪声、 基线漂移等的影响, 提高光谱分辨率。 再通过选择特征波段, 简化光谱数据, 突出强相关波长, 降低特征峰重叠给iForest带来的不确定性, 利用iForest计算的异常得分, 代入计算学生化残差, 考虑每个样本对模型的影响程度, 若异常得分过大或残差值过大, 则可认定该样本为异常样本。
以落叶松木材密度为研究对象, 分别采用多种预处理方法与特征波长选择方法对光谱数据进行处理, 对比IFSR方法与不同异常样本剔除方法处理样本集后的建模效果, 验证IFSR的异常识别能力。 再基于常用的近红外定量分析建模方法: 偏最小二乘交叉验证[14](partial least squares, PLS)、 BP神经网络[15](back propagation neural network, BPNN)以及支持向量机回归[16](support vector regression, SVR)建立预测模型, 通过对比来得到最优的近红外模型。
孤立森林结合学生化残差的异常样本剔除算法(IFSR), 其运行共分三步。 其原理如图1所示。
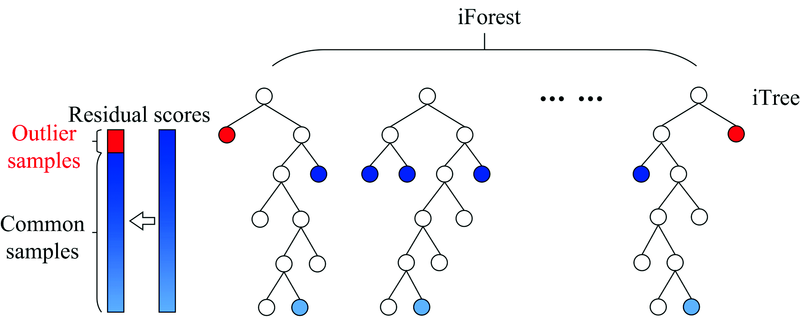 | 图1 IFSR算法原理图Fig.1 IFSR algorithm schematic diagram |
第一步是对光谱数据进行预处理和特征波段选择, 即先简化光谱数据, 去除噪音及无关特征对异常样本识别及建模的干扰, 提高IFSR算法的准确性和对异常样本的敏感性。 第二步是训练, 即在样本集吸光度矩阵x中随机选取一个特征, 并在x的范围内构建iTree进行二叉划分, 构建一棵iTree时, 从n个样本中均匀抽样Ψ 个样本, 作为这棵树的训练样本, 将大于和小于该值的样本归于左右叶子节点, 继续在左右叶子节点重复上述过程, 直到达到终止条件: 数据不可再分且达到树的最大高度l=log2(Ψ )。 第三步是预测, 即记录测试样本从iTree的根节点到外部叶子节点所走过的边数, 记为路径长度h(x)。 为标准化样本集吸光度矩阵x的路径长度h(x), 需要计算树的平均路径长度c(n)
式(1)中, H(i)为调和数(i=1, 2, …, n-1), 该值可以被估计为H(i)+0.577 215 664 9[17]。 最后将h(x)代入, 计算样本集x的异常得分S
式(2)中, E[h(x)]为样本x在孤立森林的路径长度的期望。 当S接近1时样本被识别为异常样本, 当S接近0时, 样本被识别为正常样本, 当S在0.5附近时, 无法明确区分样本是否异常。 此时利用学生化残差将异常得分考虑在内, 计算校正集均方根误差, 见式(3)
$\text{RMSE=}\sqrt{\frac{\sum\limits_{i=1}^{n}{{{({{y}_{i}}-{{{\hat{y}}}_{i}})}^{2}}}}{n-1}}$(3)
则学生化残差Ri为式(4)
${{R}_{i}}=\frac{{{y}_{i}}-{{{\hat{y}}}_{i}}}{\sqrt{\text{RMSE(1}-{{S}_{i}}\text{)}}}$(4)
很明显Ri在考虑特征空间异常样本的同时考虑了每个样本对模型的影响度, 可以更好地检测异常样本。
实验采用美国ASD公司制造的LabSpec® Pro FR/A114260便携式物质成分分析光谱仪测量近红外光谱。 该仪器可选择的光谱范围为: 350~2 500, 1 000~2 500, 1 000~1 800, 1 800~2 500, 350~1 800和350~1 050 nm。 光谱分辨率为: 3 nm@700 nm, 10 nm@1 400 nm, 10 nm@2 100 nm。 光谱采样间隔为: 1.4 nm@350~1 050 nm, 2 nm@1 000~2 500 nm。 本工作采用的所有算法均在MATLAB R2017a软件上操作。
所用样本采自黑龙江省方正县高楞镇星火林场 (N45° 43'5.73″, E129° 13'34.37″), 在落叶松天然次生林区, 分别在向阳与背阴面共设立4块样地, 每块样地大小为20 m× 20 m, 在每块样地中选取3棵标准木; 各标准木经伐倒后, 用便携油锯在标准木胸径(胸高1.3 m处)附近自下而上连续锯截多个木圆盘, 带回实验室经手工剥皮后, 在木圆盘上过树芯截取木条, 共得到181个2 cm× 2 cm× 4 cm的落叶松木材样本, 并对每个样本标号记录。 在通风干燥的室温(20 ℃)环境中将样本放置4周, 测得样本的平衡含水率约为10%, 参照《木材密度测定方法(GB/T 1933— 2009)》测定木材气干密度。
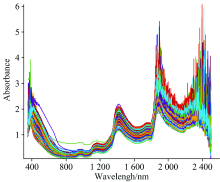
用80目的砂纸打磨木材样本各个面各5次, 使其表面粗糙度参数Ra接近12.5 μ m。 在样本横切面的两个不同位置用光纤探头扫描各1次, 每次扫描时间约为1.5 s, 设定扫描期间对样本连续扫描30次。 取两次测量的平均值为原始光谱数据。 得到原始光谱的吸光度如图2所示。 由图可知在1 440, 1 894和2 395 nm附近处存在明显的吸收峰, 且此三处波段对应的吸收峰在水分子H— O键的二倍频吸收带附近, 但1 840~2 500 nm的光谱存在较大的噪声, 因此需要对光谱数据进行降噪及预处理。
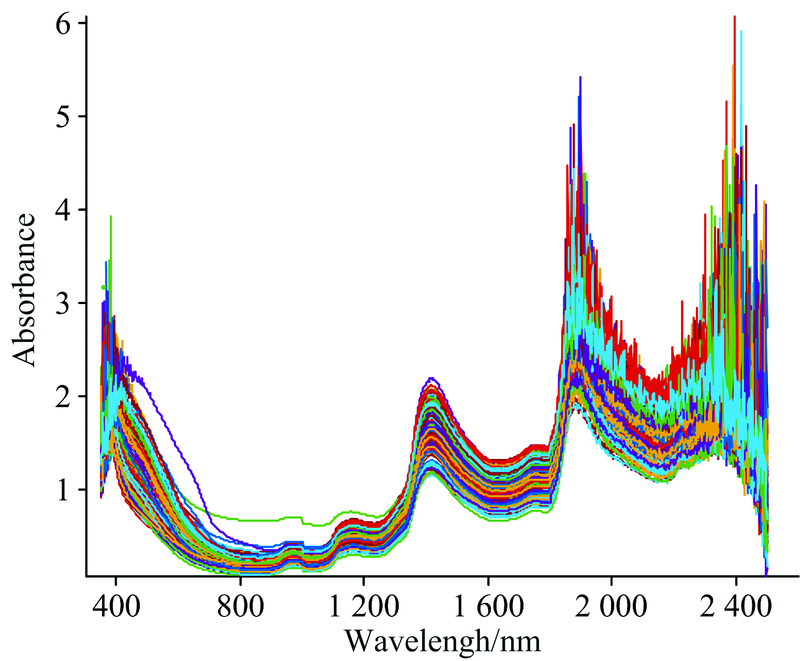 | 图2 落叶松木材样本近红外原始光谱图Fig.2 Original near-infrared spectra of larch wood samples |
采用光谱-理化值共生距离法SPXY(sample set partitioning based on joint X-Y distance)方法[18]划分样本集, 选取样本集的1/3作为预测集, 2/3作为校正集, 共得到校正集样本121个, 预测集样本60个。 SPXY方法考虑了样本集光谱所含理化值的权重以及与木材密度的关系, 以光谱和木材密度为基本参数通过计算样本空间距离来进行样本集划分, 所划分的数据集更具有代表性。 如表1所示, 校正集与预测集的木材气干密度均值与标准差均相差不大, 样本分散较为均匀。
| 表1 校正集与预测集样本统计分析(g· cm-3) Table 1 Statistical analysis of correction set and prediction set results (g· cm-3) |
由于近红外光谱在扫描过程中主要靠漫反射来获取物质信息, 其光谱通常不仅只包含实验所需要的信息, 还包括了很多诸如各种噪音、 散射光、 以及来自样本本身内部的杂质信息等等, 这些噪音及无关信息会干扰预测模型的精度, 同时增加识别异常样本的难度。 直接分析含有较多干扰信息的光谱数据容易出现误判, 可能错误地删除非异常样本, 因此本研究在进行异常样本的识别及剔除之前采用光谱预处理方法排除上述杂质信息, 从而提高识别的准确度及后续建模的质量和精度。
采用多元散射校正(multiplicative scatter correction, MSC), 标准正态变量变换(standard normal variate transformation, SNV), 去趋势(detrending, DT), 移动平均平滑(moving average smoothing, MAS), Savitzky-Golay卷积平滑(Savitzky-Golay smoothing, SGS), 与均值中心化(mean centering, MC), 标准化(autoscaling, Auto)相结合对原始光谱进行预处理, 结果如表2所示。 由表2可以看出经预处理后的光谱数据的预测集决定系数R2及均方根误差(root mean squared error of prediction, RMSEP)相较原始光谱均有较大改善, 均可以很好地校正光谱的基线漂移及去噪, 其中采用SNV+DT+MC+Auto联合光谱预处理方法, 主因子个数为5, 预测集R2为0.721 1, RMSEP相较原始光谱从0.042 2降为0.034 7, 是不同预处理方法预测结果中的最小值。 综合考虑, 确定采用SNV+DT+MC+Auto作为异常样本剔除及建模前的预处理方法。
| 表2 基于不同预处理方法的落叶松木材密度预测结果 Table 2 Prediction results of larch wood density based on different pretreatment methods |
对预处理后的光谱数据, 尽管对其进行了降噪, 基本消除了基线漂移等对光谱数据的影响, 但光谱中还存在大量冗余信息, 其共线性对异常样本识别以及后续建模仍有较大影响, 因此需要进一步分析光谱数据, 提取特征信息。 工作中采用竞争性自适应重加权算法(competitive adaptive reweighted sampling method, CARS) 提取特征波段。 采用CARS方法时, 设定蒙特卡洛采样次数为50, 以10折交叉验证构建最大潜变量因子数为15的偏最小二乘模型。
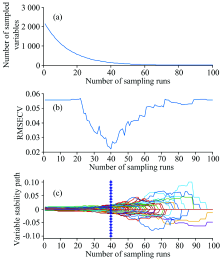
模型整体预测效果相比无特征选择提升明显, 其中R2从0.437 7提高到0.894 2, RMSEP从0.045 2降低为0.019 6。 CARS方法的特征波段选择结果如图3所示, 图3(a)表示选取的特征变量数随波长变量子集数的增加的变化趋势图, 整体呈逐渐减小趋势, 且减小速度逐渐变缓。 对比图3(b)中的交叉验证均方根误差(root mean squared error of cross validation, RMSECV)结果, 曲线呈先减小后增加的趋势, 随着无关信息的剔除RMSECV逐渐减小, 模型效果渐优, 但当部分有用信息被剔除时, RMSECV则趋于增加, 模型出现过拟合现象, 可以确定在波长变量子集数为40时得到最优的特征波段集。 图3(c)表示各波段的稳定度随波长变量子集的变化轨迹, 其中星号线表示最小RMSECV对应的子集数, 稳定度为选择特征波段的主要依据, 当有用信息的稳定度变为0则RMSECV对应也会增加。
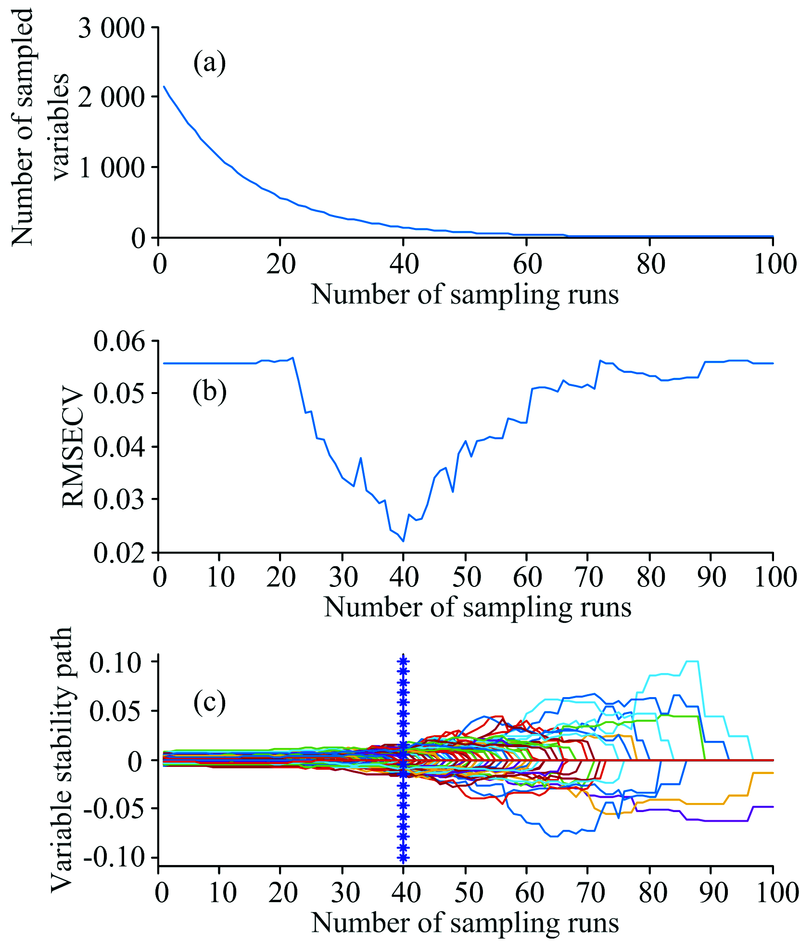 | 图3 CARS波段选择变化趋势图 (a): 选取变量数; (b): RMSECV; (c): 变量稳定度轨迹Fig.3 CARS band selection trend chart (a): Number of sampled variables; (b) RMSECV; (c) Variable stability path |
采用上述波段选择后的光谱数据样本集, 剔除其中可能存在的对模型产生强影响的极端样本或异常样本。 奇异样本可能存在于光谱数据或组分指标的真值, 其可能是由于测量时的人为误差或仪器误差造成的, 剔除这些奇异样本是确保预测精度和模型准确性的必要步骤。 为验证IFSR算法对经预处理及特征选择后的光谱数据的异常筛选能力, 分别应用蒙特卡洛交互验证(Monte Carlo cross validation, MCCV)、 马氏距离(Mahalanobis distance, MD)、 高杠杆值检验(high leverage, HL)、 杠杆值与学生化残差t检验(high leverage-studentized residual, HLSR)、 光谱残差检验(spectral residual, SR)以及基于XY变量联合的ODXY算法共六种算法与孤立森林算作对比, 对上述数据进行异常样本剔除, 并在异常样本剔除后建立偏最小二乘交叉验证模型, 根据模型的预测能力进行评估。
对于MCCV方法, 设定蒙特卡洛循环次数为1 000次, 假设各样本的预测残差均满足正态分布, 引入设定参数q, 分别计算预测残差均值m(i)与预测残差标准差s(i)的阈值Tm和Ts, 超出阈值的样本即为异常样本。 设定参数q根据3σ 准则设为3, Tm, Ts的计算公式如式(5)和式(6)
${{T}_{m}}=\frac{\sum\limits_{i=1}^{n}{m(i)}}{n}+q\sqrt{\frac{\sum\limits_{i=1}^{n}{{{(m(i)-\bar{m})}^{2}}}}{n}}$(5)
${{T}_{s}}=\frac{\sum\limits_{i=1}^{n}{s(i)}}{n}+q\sqrt{\frac{\sum\limits_{i=1}^{n}{{{(s(i)-\bar{s})}^{2}}}}{n}}$(6)
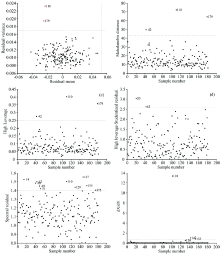
对于IFSR方法, 设定iTree数量为100, iTree训练子样本容量为256, iTree的最大特征容量为经特征波长选择方法简化后的光谱波长数, 最大迭代次数为50次, 学生化残差检验的t值查阅t分布临界值表确定, 本研究中t临界值为2.601, 其余参数均为默认值。 基于IFSR方法剔除结果如图4所示, 共剔除了样本编号为33, 39, 107, 146, 150, 172, 175的7个异常样本。
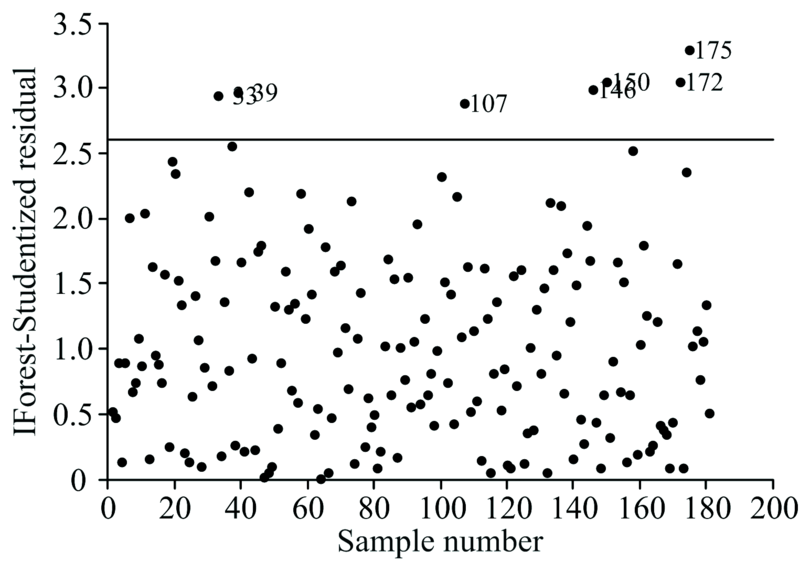 | 图4 基于IFSR方法的异常样本剔除结果Fig.4 Results of abnormal sample elimination based on IFSR method |
对其他异常样本剔除方法的阈值采用逐一放回法进行确定, 规定每种方法先预选出20个异常值, 再按照次序从最后一个剔除的样本开始放回, 若模型性能没有变差则保留放回, 否则剔除, 得到最佳模型性能的异常样本数对应的阈值即为最佳阈值。 基于六种异常样本剔除方法的样本剔除结果分别如图5(a— f)所示。
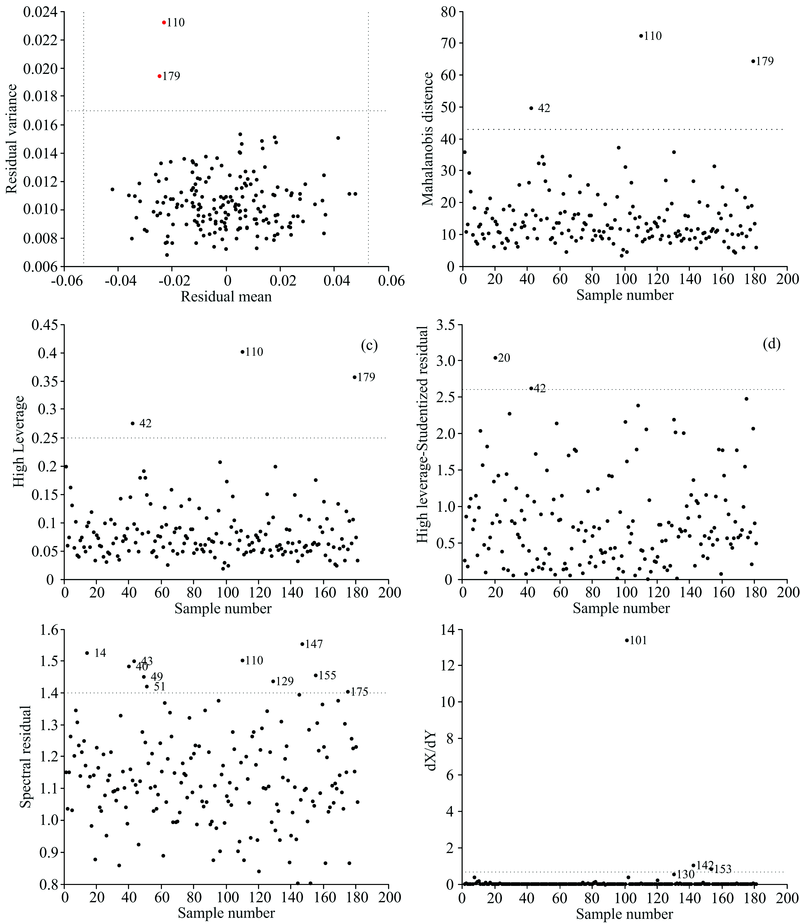 | 图5 基于六种异常样本剔除方法的样本剔除结果 (a): MCCV; (b): MD; (c): HL; (d): HLSR; (e): SR; (f): ODXYFig.5 Sample removal results based on six abnormal sample removal methods (a): MCCV; (b): MD; (c): HL; (d): HLSR; (e): SR; (f): ODXY |
为进一步确认IFSR方法的异常样本识别能力, 将上述几种异常样本剔除方法剔除后的样本集重新用SPXY方法按照3∶ 1划分校正集与预测集, 分别建立偏最小二乘交叉验证模型, 并对各模型对比评价, 得到未经异常样本剔除(Full)与经IFSR方法及六种对照方法所建交叉模型的预测结果如表3所示。
| 表3 基于不同异常值剔除方法的落叶松木材 密度建模及预测结果 Table 3 Modeling and prediction results of larch wood density based on different outliers elimination methods |
从表3可以看出经异常剔除后的结果均比未剔除更优, 且IFSR方法的剔除效果均为最优。 对比剔除样本编号, IFSR相较MD、 HL方法在剔除空间距离异常点的同时还剔除了残差过大所造成的强影响点; 而IFSR相较传统SR方法多考虑了空间距离的影响因素; MCCV方法虽然结合了X与Y变量间的关系进行分析, 但也会由于异常导致模型过拟合造成误判; ODXY方法也联合XY两变量进行分析, 但其以平均光谱为参考进行关联分析也会由于异常样本导致偏差从而造成误判。 IFSR方法虽然并未结合XY两变量综合考虑, 但其以二叉树对光谱数据进行切割, 对不同空间维度均可进行切割, 且该方法具有随机性并结合了集成学习的优点, 能在循环中快速找到异常样本, 同时切割过程无需建模, 大大提高了搜索速度。
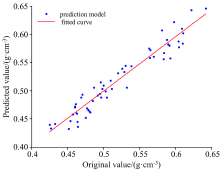
为得到最优的落叶松木材密度近红外预测模型, 对经IFSR剔除异常样本后重新划分好的样本集分别采用PSO-SVR, PLS和BPNN三种建模方法建模并确定最优方法。 所采用的PSO-SVR算法基于LIBSVM工具箱, 确定核函数为径向基核函数, 惩罚因子c与核参数g通过粒子群算法(particle swarm optimization, PSO)确定, PSO算法中设定种群规模大小为200, 个体学习因子c1=1.5, 社会学习因子c2=1.7, 最大迭代次数为200, 交叉验证折数为10折, 主成分因子数为上述交叉验证偏最小二乘测试IFSR方法时所确定的主因子数。 其中PSO参数寻优适应度曲线及校正集与预测集的拟合曲线可视化结果如图6所示。 由图6(a)可知, 在惩罚因子c=30.029 1, 核参数g=0.01时的预测效果最优, 此时预测集R2为0.932 1, RMSEP为0.015 4。 PSO-SVR模型的预测效果很好。
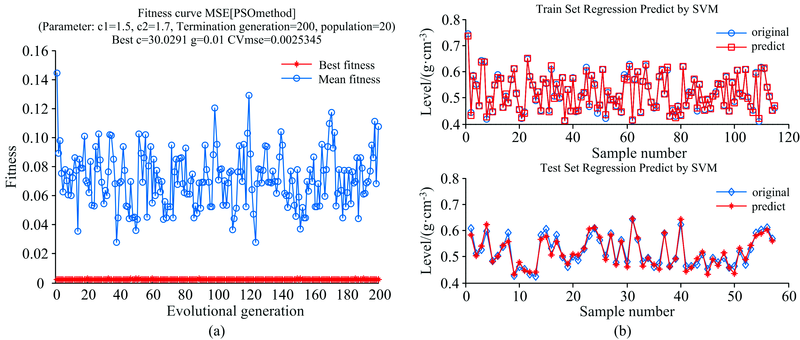 | 图6 PSO-SVR预测结果 (a): PSO参数寻优适应度曲线; (b): 校正集与预测集的拟合曲线Fig.6 PSO-SVR prediction results (a): PSO parameter optimization fitness curve; (b): Fitting curve of correction set and prediction set |
采用的BPNN算法基于MATLAB神经网络工具箱, 经过多次调试确定BPNN的训练参数: 学习速率为0.01, 训练要求精度为0.000 1, 最大训练次数为2 000次。 BPNN预测集拟合曲线如图7所示。 从图中7可知, 预测集的R2为0.913 1, RMSEP为0.017 7, BPNN也可以很好地预测木材密度。
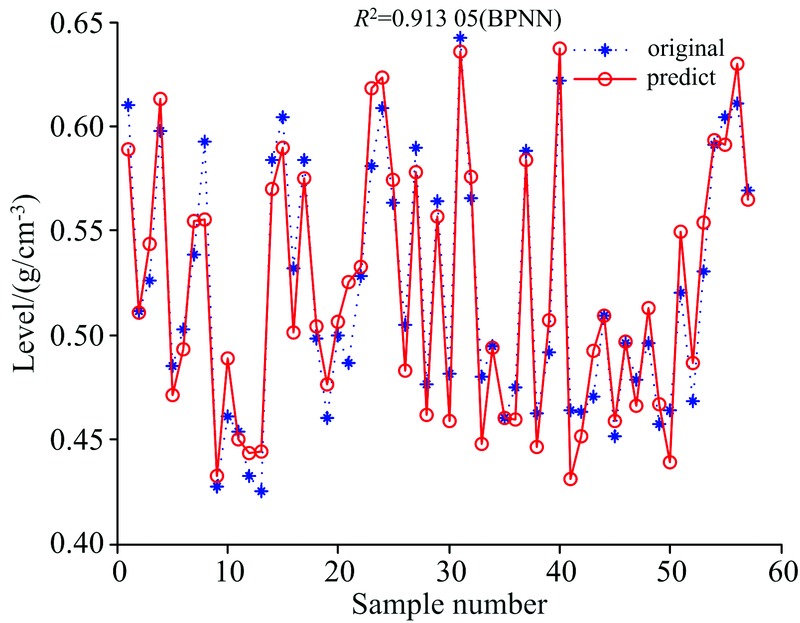 | 图7 BPNN预测集拟合曲线Fig.7 BPNN prediction set fitting curve |
分别对IFSR剔除异常样本后的落叶松木材密度近红外样本集进行PSO-SVR, BPNN及PLS建模, 得到的预测结果如表4所示, 从表4可以看出, PSO-SVR与PLS方法的建模效果优于BPNN, 而PSO-SVR方法的建模效果最优, R2为0.932 1, RMSEP为0.015 4, 由此证明对于小样本数据, 支持向量回归要优于神经网络, 且SVR考虑了非线性因素, 所建模型的预测能力优于线性的PLS。 PSO-SVR所建落叶松木材密度近红外模型的预测结果如图8所示。
| 表4 基于PSO-SVR, BPNN, PLS方法的落叶松木材密度建模及预测结果 Table 4 Modeling and prediction results of larch wood density based on PSO-SVR, BPNN and PLS methods |
 | 图8 PSO-SVR模型预测结果Fig.8 Prediction results of PSO-SVR model |
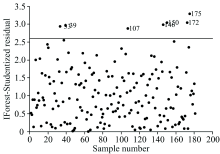
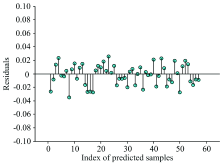
通过对预测结果与真实值进行残差分析(图9), 残差值均匀分布在横轴两端, 证明预测值是等方差分布的, 且在± 0.04范围内预测值具有很强的解释性, 进而证明预测模型具有较强的可靠性。 预测结果表明, 基于IFSR的异常样本剔除方法能在建模前准确地识别样本集中的异常样本, 尤其针对高维且多变量的数据集具有明显效果, 由于结合了学生化残差检验, 只需查表即可确定阈值, 避免了根据经验或多次实验确定阈值的复杂过程。 相对传统异常样本剔除方法更加准确简便。
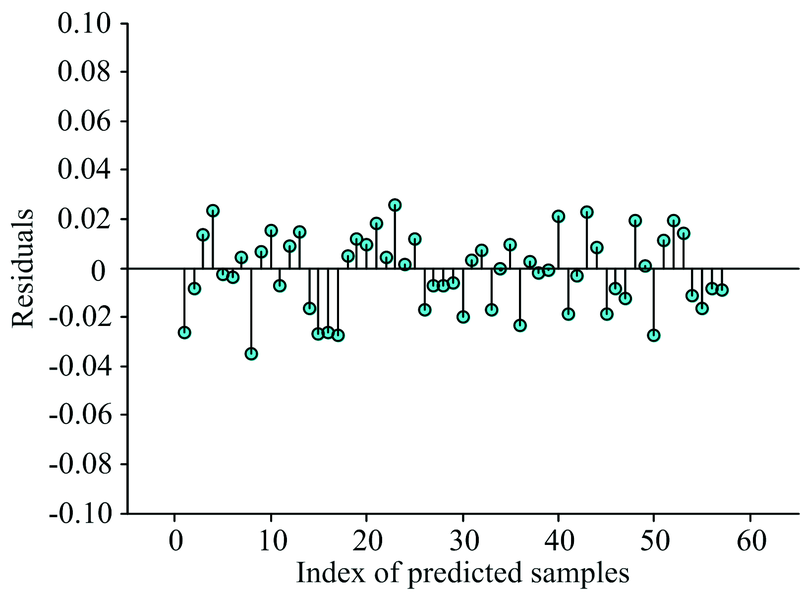 | 图9 预测结果残差分析Fig.9 Residual analysis of calibration prediction results |
基于统计学方法孤立森林算法, 提出了一种孤立森林结合学生化残差方法(IFSR), 并通过预处理及特征变量选择消除数据中的噪音及无效信息, 使其可用于识别并剔除高维、 高共线性的近红外光谱数据中的异常样本值, 且在识别过程中只需查阅t分布临界值表即可确定阈值, 避免了设定阈值的问题。
为验证IFSR的可靠性, 将该算法用于剔除落叶松木材密度样本中的异常值, 并建立近红外预测模型, 经与多种传统异常样本剔除方法对比, 证明用IFSR可以有效剔除近红外光谱中的异常样本值, 所得预测模型稳健性好, 预测精度高。 但IFSR方法也有一定的局限性, 如未将光谱数据X与真实值Y联合考虑来分析样本中的异常值, 下一步可从此方向, 结合阔叶材、 竹材等多种样本进一步优化算法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|