




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于可见光谱和卷积神经网络的贝类识别方法
[张洋1, 2  , 岳峻
, 岳峻1, * , 贾世祥1 , 李振波2 , 盛国瑞1 ]
, 岳峻, 贾世祥|
|


作者简介: 张 洋, 1996年生, 鲁东大学信息与电气工程学院硕士研究生 e-mail: zy_09_20@163.com
目前卷积神经网络(CNN)在物体种类识别方面取得突破性进展。 贝类作为农业经济的重要组成部分, 种类繁多, 特点复杂, 大多贝类存在着相似度高, 各类样本分布不均衡情况, 以致CNN对贝类分类的准确率偏低。 针对这一情况, 提出了基于可见光谱和CNN的贝类识别方法, 旨在提取更有效的贝类特征, 从而提高贝类分类的准确率。 首先, 提出了一种包含输出熵度量和正交性度量的滤波器信息度量与特征选择方法, 重新初始化修剪掉的滤波器并使其正交, 捕获网络激活空间中的不同方向, 使神经网络模型学习到更多有用的贝类特征信息, 提升模型分类准确率; 其次, 提出了一种包含正则化项和焦点损失项的贝类分类目标函数, 通过控制各类别样本对总损失的共享权重, 来减少易分类样本的权重, 以使模型注意力向预测不准的样本倾斜, 均衡样本分布和样本分类难度, 进一步提高贝类分类的准确率。 贝类图像数据集由74类贝类组成, 共11 803张图像。 获取原始数据集后, 对数据集图像进行水平翻转、 垂直翻转、 随机旋转、 在[0, 30°]范围内旋转、 在[0, 20%]范围内缩放和移动等数据增强操作, 将图像数量从11 803张增加到119 964张。 整个图像数据集按8:1:1的比例随机分为训练集95 947张图片、 验证集11 996张图片和测试集12 021张图片。 在建立贝类图像数据集的基础上进行了实验验证, 达到了93.38%的分类准确率, 将基准网络(Resnest)的准确率提高了1.18%, 相较网络SN_Net和MutualNet, 准确率分别提升了4.34%和0.85% , 并且训练时长为22 320 s, 将基准网络(Resnest)的训练时长缩短了960 s, 训练时长分别比SN_Net和MutualNet短3 180和2 460 s。 实验结果证明了该方法的有效性。
At present, Convolutional Neural Network (CNN) has made a breakthrough in species recognition. As an important part of the agricultural economy, shellfish has a wide variety of species with complex characteristics. Some of the shellfish are highly similar and the distribution of various samples is unbalanced, which causes a low accuracy of CNN classification. In view of this situation, a shellfish recognition method based on visible spectrum and CNN is proposed in this paper, which aims to extract more effective shellfish features to improve the classification accuracy of shellfish. Firstly, a filter information measurement and feature selection method including output entropy measurement and orthogonality measurement is proposed, which reinitializes the pruned filter and makes it orthogonality, captures different directions in the network activation space, so that the neural network model can learn more useful shellfish feature information and improve the classification accuracy of the model; secondly, a shellfish classification objective function including regularization term and focal loss term is proposed, which reduces the weight of easily classified samples by controlling the shared weight of each sample to the total loss, it tilts the attention of the model to the samples with inaccurate prediction, so as to balance the distribution of samples and the difficulty of sample classification, and improve the accuracy of shellfish classification. The shellfish image dataset in this paper consists of 74 shellfish species with 11 803 pictures in total. After obtaining the original dataset, data augmentation which consists of horizontal flipping, vertical flipping, random rotation, rotation within the range of [0, 30°], scaling and moving within the range of [0, 20%] and moving is performed on the images of the dataset, increasing the number of images from 11 803 to 119 964. The whole image dataset is randomly divided into training set with 95 947 pictures, validation set with 11 996 pictures and test set with 12 021 pictures in an 8:1:1 ratio. In this paper, based on the establishment of the shellfish image dataset, the experimental verification has reached the classification accuracy of 93.38%, which increases the accuracy of the benchmark network (Resnest) by 1.18%. Compared with SN_Net, and MutualNet, the accuracy of the proposed method is increased by 4.34% and 0.85%, respectively. And the training time is 22 320 seconds, which shortens the training time of the benchmark network (Resnest) by 960 seconds, the training time of the proposed method is 3 180 seconds and 2 460 seconds shorter than SN_Net and MutualNet, respectively. The experiments results demonstrate the effectiveness of the proposed method.
物体识别是计算机视觉的重要组成部分, 在人机交互中具有重要意义。 目前卷积神经网络(convolutional neural network, CNN)在物体识别方面取得突破性进展, 逐渐应用于计算机视觉[1]和语言处理[2]等领域, 但在海洋领域的研究还很少见。 海洋贝类作为农业经济的重要组成部分, 种类繁多, 特点复杂, 甚至某些贝类形态高度相似。 故将CNN运用到海洋贝类图像识别领域, 开展对形态相似的海洋贝类图像识别研究, 让机器视觉代替人眼了解贝类不同类别的差异。
贝类分类方法方面。 国内的研究技术较为落后, 传统贝类分类方法是基于分子生物技术从基因角度进行区分[3], 识别的贝类种类少且操作复杂。 国外逐渐将复杂神经网络应用到贝类检测中, Li等[4]在MobileNet-v2-SSD框架的基础上, 提出一种使用残差注意机制的贝类物体检测模型。 当前, 国内外并没有完整的贝类识别系统, 虽然上述实验对基于机器视觉的贝类分类研究具有一定促进作用, 但大多数适用于平滑贝壳且识别的贝类种类少。 由于某些贝类形状的相似性或颜色的相似性, 以及各类样本分布不均衡, 对贝类的分类识别造成一定的难度。
CNN具有无效的滤波器, 即对输出结果精度影响很小的滤波器。 所以裁剪某些无效滤波器可以加快CNN的学习速度, 而不会影响识别性能。 因此许多学者开始研究如何确定不重要的滤波器[5], 或者如何有效地去除性能不可容忍的滤波器[6]。 不少学者通过设计有效的卷积块[7]或修剪不重要的网络连接[8]来减少CNN的特征冗余。 但是, 这些工作主要关注减小网络规模, 并不能实现最佳的识别精度和速度权衡。 因此, 在裁剪一些网络连接信息时, 应考虑找回误删的信息, 综合考虑网络识别的精度与速度。 为了满足网络识别精度与速度的动态约束, 2019年, Yu等[9]将不同的复杂性整合到一个网络中, 提出了可切换的批量标准化以进行神经网络的瘦身训练; Yu等[10]又提出调整运行网络的宽度, 以实现识别精度与速度的折衷。 2020年, Cai等[11]提出了一种从训练过的大型网络中微调子网络的方法; Yang等[12]强调同时考虑网络宽度和输入分辨率对有效网络设计的重要性; Zhang等[13]提出了Resnest网络模型, 模型采用跨通道的注意力机制, 以提取所要识别图像的有用特征, 有利于提高模型的识别准确率, 与本文要解决的图像特征相似的贝类识别问题不谋而合, 因此选择Resnest网络作为本工作的基线网络。
很多贝类图片特征具有高相似度且各类样本不均衡的特点, 使得CNN直接应用于贝类识别上效果不佳, 识别准确率较低, 且计算量大。 为了提升贝类分类准确率并适当减小分类模型复杂度, 本工作创新提出了一种滤波器信息度量与特征选择方法, 抑制贝类特征之间的相关性, 更关注正交特征, 捕获网络激活空间中的不同方向; 提出一种包含正则化项和可变损失项的新贝类分类目标函数, 控制各类别样本之间对总损失的共享权重, 平衡样本分类难度。
通过衡量滤波器的信息重要性和层中滤波器间的正交性判断滤波器是否有效, 进而进行特征选择。 因此针对高相似度贝类分类问题, 提出输出熵度量方法和正交性度量方法分别度量滤波器的信息重要性和层中滤波器间的正交性。
输出熵度量方法方面, 提出了一种输出熵的度量方法衡量滤波器的信息重要性。 相比于滤波器范数和参数稀疏度等方法, 本文提出的输出熵的度量方法更为精准, 且得到的度量参数更有区分性。 首先将权重连续分布转换为离散分布, 具体来说, 将权重值的范围划分为C个不同的区间, 并计算每个区间的概率。 最后滤波器的熵可以计算为
式(1)中, Wl, j∈
在式(1)的基础上, 计算第l层具有的总信息为
式(2)中, H(Wl, j)表示第l层卷积层中第j个滤波器包含的信息。 Jl是第l层中滤波器的数量, 且j∈ Jl。
根据式(1)和式(2)分别计算H(Wl, j)和H(Wl), H(Wl, j)和H(Wl)数值越小, 滤波器的信息越少, 即信息重要度越低。
关于正交性度量方法, 提出了一种滤波器间的正交性度量方法, 以捕获贝类图片正交特征, 抑制贝类图片相似特征。 卷积核大小为k× k的滤波器是k× k× c的3D向量, 其中c是通道数。 将滤波器向量展开为k× k× c的1D向量, 并用f表示。 归一化权重为
式(3)中, Wl是行数为Jl的矩阵, 一行为一个滤波器展开的向量。 Jl是第l层中滤波器的数量, 且l∈ L。
根据
式(4)中, Pl矩阵第i行数据表示同一层其他滤波器对第i个滤波器的相关性。 对第i行数据求和所得值越小, 表示第i个滤波器与其他滤波器相关性越小。 当其他滤波器与给定第i个滤波器正交时, 第i行的总和达到最小值。
根据相关性矩阵计算滤波器间的正交性度量
式(5)中, f是滤波器对应向量, 根据式(5)可知, f所对应行的求和越小, 表示正交性越大。
为防止误删有效的特征信息, 选择更多有用的贝类特征, 通过基于滤波器信息度量方法的特征选择方法, 进行特征的移除与更新, 从而选择有用的特征信息, 具体流程如图1所示。 经过两步移除实现特征移除, 首先移除无效滤波器, 然后移除相似滤波器中相对无效的滤波器, 第二步是在第一步的基础上进行。 特征更新通过激活滤波器使其具有正交性(相似性越低正交性越高)。
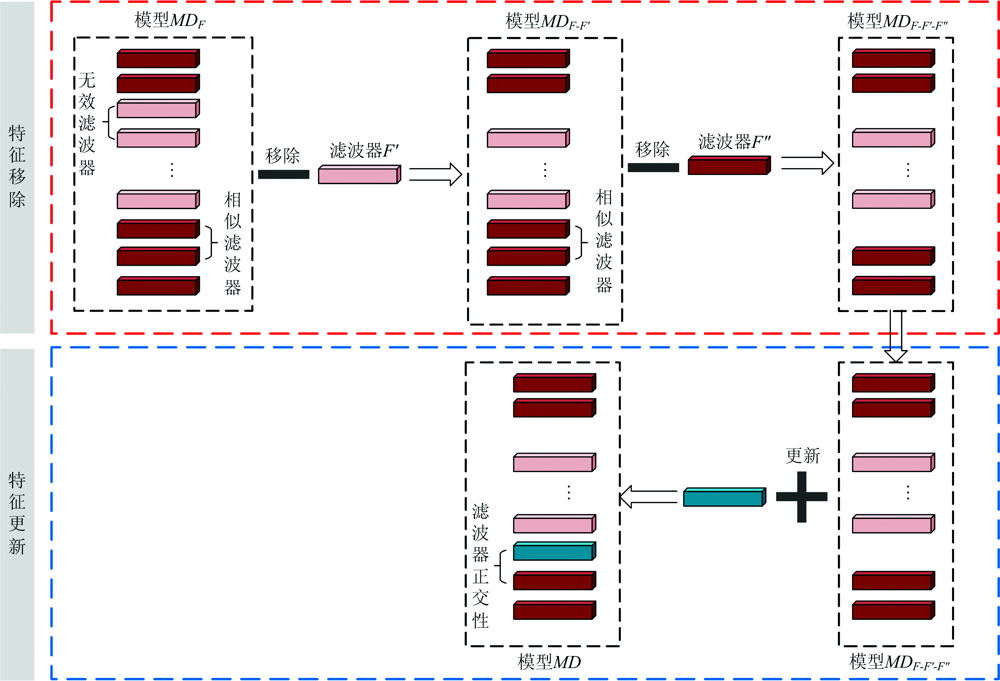 | 图1 特征选择Fig.1 Feature selection |
综上所述, 为解决具有高相似度特征的贝类分类难的问题, 首先对滤波器按信息量从大到小排序, 移除掉信息量较低的s %的滤波器, 然后根据正交性度量方法移除其中信息量相似的滤波器, 最后重新初始化移除掉的滤波器, 也就是特征更新。 本文所提出的度量方法能够抑制特征之间的相关性, 更关注模型的正交特征, 并通过特征更新, 重新捕获激活空间中的不同方向, 提升模型泛化能力。
在滤波器信息度量方法(1.1节)的基础上, 针对样本不均衡以致贝类分类难的问题, 提出一种新的贝类分类目标函数。
首先, 依据滤波器正交性度量, 让模型学习到相互正交的特征, 提出一种包含正则化项的损失函数L1
式(6)中,
其次, 贝类样本分布是不均衡的, 导致不同样本分类难度存在巨大差异, 采用原始交叉熵损失函数无法刻画这种分布特征, 分类效果不理想。 为了解决这一问题, 控制各类样本对总损失的共享权重以及容易分类和难分类样本的权重, 提出一种包含焦点损失的损失函数L2
式(7)中, α i, β i和(1-p(yi))γ 分别是不同的控制系数。 通过放大(缩小)一个类别的α i值, 控制该类别对总损失的共享权重大小, 模型会更重视或更不重视该类别的预测。 通过放大(缩小)一个类别的β i值, 控制该类别最小差异性对总的损失的影响。 控制系数(1-p(yi))γ 更加关注于难分类(样本量少)的贝类样本, 减少易分类(样本量多)贝类样本的影响。 根据一个类别真实标签对应的输出概率p(yi)确定该类别对应的γ 。 当一个贝类样本是易分类样本时, p(yi)> 0.5, 则(1-p(yi))γ 就会比较小, 进而该易分类样本对总损失的贡献就会相对比较小; 当一个贝类样本是难分类样本时, p(yi)≤ 0.5, 则(1-p(yi))γ 就会相对比较大, 进而该难分类样本对总的损失的贡献相对比较大。
最后, 提出一种包含正则化项和焦点损失项的混合损失函数, 作为模型的多分类目标函数。
式(8)中, L1是包含正则化项的损失函数。 L2是包含焦点损失项的损失函数。 δ 是一个参数, 用于平衡两个损失项。
贝类图像数据集由大竹蛏、 微黄镰玉螺、 扁玉螺、 日本镜蛤、 紫贻贝、 纵带滩栖螺、 薄片镜蛤、 西施舌等74类贝类组成, 共11 803张。
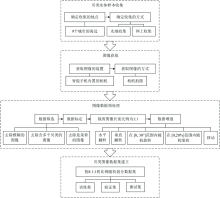
贝类图像数据集的建立主要分为四个阶段, 建立流程如图2所示。
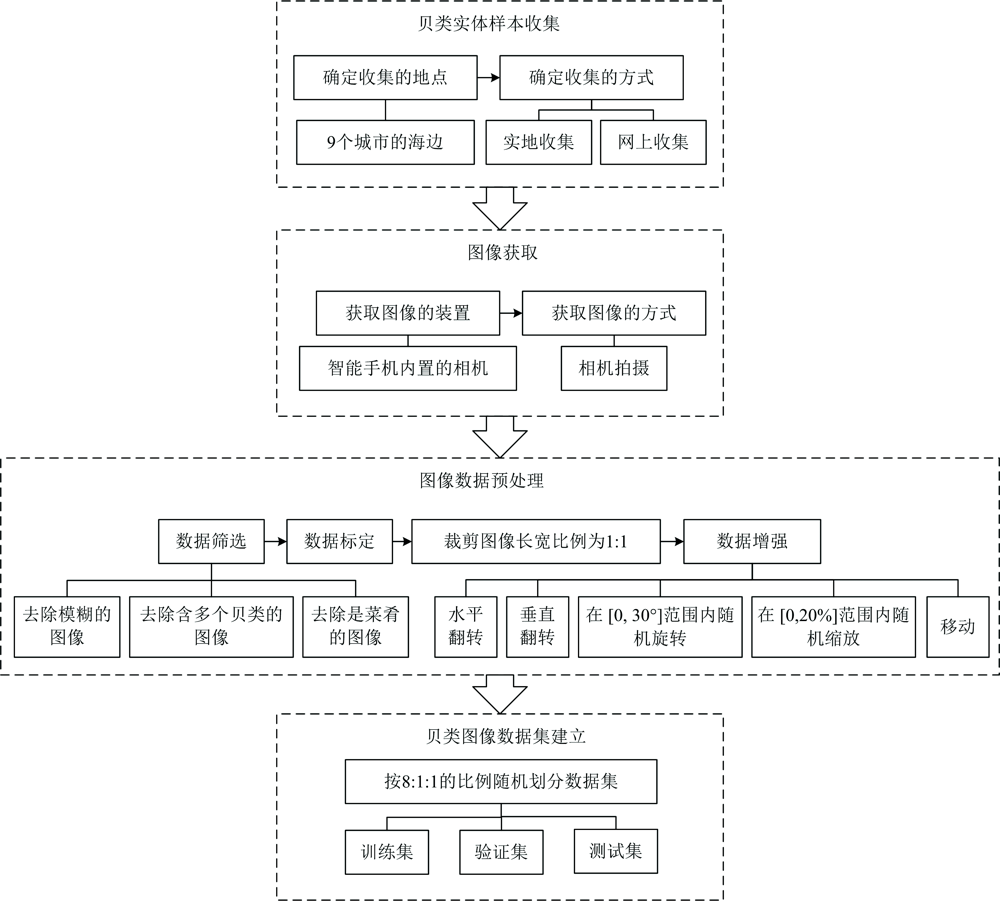 | 图2 贝类图像数据集建立流程Fig.2 The establishment process of the shellfish image dataset |
第一阶段获取贝类实体样本。 从2014年4月至2020年10月获取了贝类实物样本, 主要通过实地收集和网络收集结合的方式收集来自山东省烟台市、 山东省青岛市、 广西壮族自治区北海市和福建省厦门市等9所城市海边的贝类。
第二阶段获取贝类图像。 从2019年9月至2020年10月获取贝类图片, 主要通过智能手机内置的相机拍摄贝类, 设置初始图像大小为3 120× 3 120。 在可见光下, 相机拍摄获得74类贝类图片, 共11 803张。
第三阶段进行图像数据预处理。 获取贝类图像后, 对其进行数据增强等预处理操作。 首先将图像裁剪为长宽比为1:1的图像, 然后对图像进行水平翻转、 垂直翻转、 随机旋转、 在[0, 30° ]范围内旋转、 在[0, 20%]范围内缩放和移动等数据增强操作。 将图像数量从11 803张增加到119 964张。
第四阶段建立数据集。 整个图像数据集按8:1:1的比例随机分为训练集(95 947张)、 验证集(11 996张)和测试集(12 021张)。 部分数据集图片如图3所示。
 | 图3 部分贝类数据集图像Fig.3 Images of part of the shellfish dataset |
该数据集在每一科中包含一个或多个类且每个类只属于一个科, 部分高相似度特征图片如图4所示。 为方便数据存储与读取, 将各贝类图片存储在74个文件夹下。
 | 图4 部分高相似度贝类图片Fig.4 Some images of shellfish with high similarity |
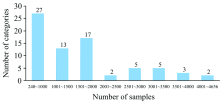
从图4可以看出, 贝类图像表现出类内相似(上3行)及类间相似(下3行), 使得贝类的识别比一般物种的识别更有难度。 不仅如此, 贝类物种具有样本分布不均衡的特点, 样分布情况如图5所示, 样本数量在240~1 000张的贝类有27种, 而样本数量在4 001~4 656张的贝类仅有2种。 贝类样本分布不均衡, 导致贝类分类难度不均衡。
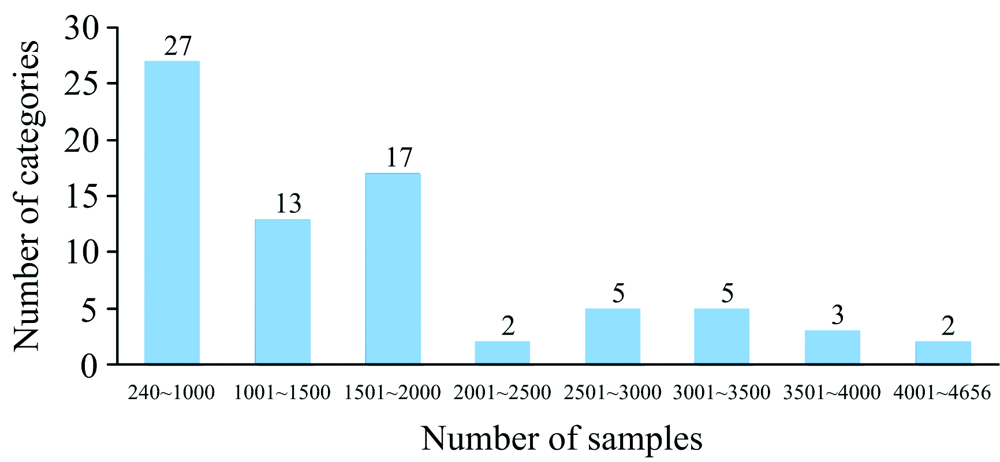 | 图5 样本分布情况柱形图Fig.5 Bar chart of sample distribution |
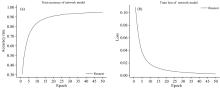
选择Resnest[13]神经网络模型作为识别模型的基准网络来进行贝类数据集的训练, 迁移学习在ImageNet数据集上训练过的预训练模型, 将其应用到贝类识别问题上, 并使用SGD优化器和交叉熵损失函数进行优化。 通过大量实验验证, 选择初始学习率为0.001、 Batch_Size大小为32, 并且卷积核数量、 卷积层数量以及池化层数量均与Resnest模型的数量一致。 但是在全连接层上将输出层类别数目改为74。 为了降低计算复杂度, 将图像大小被调整为224× 224。 方法在Pytorch上运行实现, 同时在NVIDIA GeForce GTX 1080 Ti图形处理单元(graphics processing unit, GPU)上执行训练了50 epochs。 Resnest对贝类图像数据集的训练结果如图6所示。 实验结果表明, Resnest针对贝类图像的分类, 训练过程中网络模型无异常, 并且训练准确率与损失值得到了收敛, 因此可以保存训练后的模型进行测试。 对训练后的Resnest模型进行测试, 在贝类图像数据集的测试集图像的分类识别上, 误差得到了收敛且平均准确率达到了92.20%。
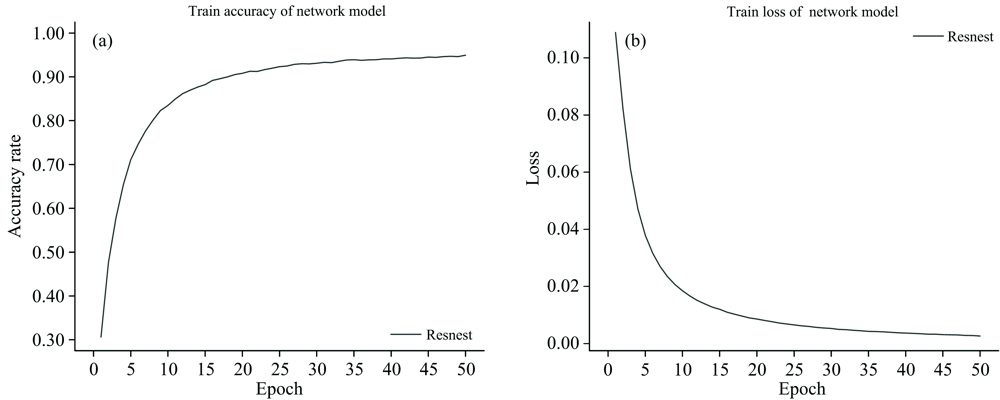 | 图6 Resnest神经网络模型训练结果Fig.6 Training results of Resnest neural network model |
为验证本方法的有效性, 对Resnest网络模型与添加了滤波器信息度量与特征选择方法的网络模型(F_Net)、 添加了改进的贝类分类目标函数的网络模型(L_Net)以及同时添加了两种方法的网络模型(FL_Net)进行了对比分析。 四种网络模型的训练结果见图7, 测试结果见表1。 为保证实验结果的可对比性, 除网络结构外的任何影响因素均保持一致。 结果表明, 本方法准确率在Resnest基础上有明显提高, 在测试集上平均准确率提升了1.18%, 并且在训练时长上缩短了960 s, 验证了本方法的有效性。
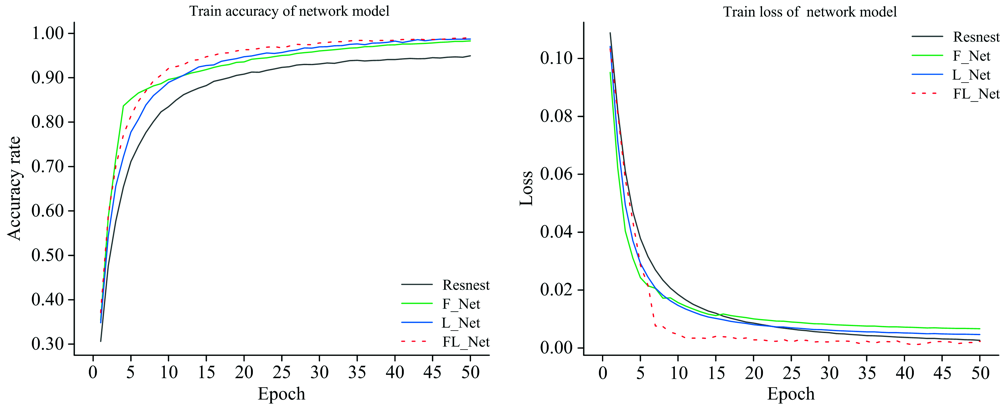 | 图7 四种网络模型训练结果比较Fig.7 Comparison of training results of four network models |
| 表1 四种网络模型测试结果比较 Table 1 Comparison of test results of four network models |
为进一步验证本网络模型(FL_Net)的有效性, 将其与SN_Net[9]和MutualNet[12]两种网络模型进行对比分析, 3种网络模型的实验结果见图8和表2。 为保证实验结果的可对比性, 除网络结构外的任何影响因素均保持一致。 结果表明, FL_Net在测试集上平均准确率优于SN_Net和MutualNet两种模型, 分别提升了4.34%和0.85%, 并且在训练时长上分别缩短了3 180和2 460 s, 验证了本方法的有效性。
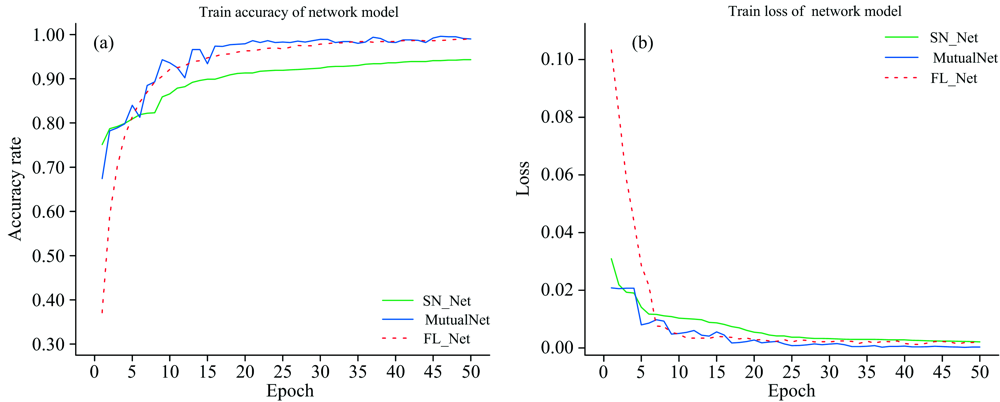 | 图8 三种网络模型训练结果比较Fig.8 Comparison of training results of three network models |
| 表2 三种网络模型测试结果比较 Table 2 Comparison of test results of four network models |
基准网络在本工作贝类图像训练中能够较为快速地收敛到合适的网络结构, 在测试集上的平均准确率为92.20%, 识别率较低。 本文提出了一种新的滤波器信息度量与特征选择方法, 并更新网络为F_Net, 测试集平均正确率达到93.13%; 提出了一种包含正则化项和可变损失项的新的贝类分类目标函数, 并更新网络为L_Net, 测试集平均正确率达到92.57%; 最后, 联合网络为FL_Net, 即为本工作最终更新的网络模型。 FL_Net训练效果优于基准网络、 SN_Net和MutualNet, 在测试集上的分类准确率为93.38%, 分别比基准网络(Resnest)、 SN_Net 和MutualNet高1.18%、 4.34%和高0.85%; 训练时长为22 320 s, 分别比基准网络(Resnest)、 SN_Net 和MutualNet短960, 3 180和2 460 s。
根据贝类图像高度相似的特点, 提出了一种新的滤波器信息度量与特征选择方法, 网络训练过程中抑制贝类特征之间的相关性, 更关注正交特征, 捕获神经网络激活空间中的不同方向, 提升分类模型的特征表达能力。 在滤波器信息度量与特征选择的基础上, 针对贝类样本分类难度不平衡的问题, 提出了一种包含正则化项和可变损失项的新的贝类分类目标函数, 网络训练过程中让模型学习到相互正交的权重, 同时控制各类别样本之间对总损失的共享权重, 通过减少易分类样本的权重, 使得模型在训练时更专注于难分类的样本, 把注意力集中在预测难度大的样本上, 平衡样本分类难度。 本工作对形态相似的海洋贝类图像识别研究, 为基于非成像光谱仪、 数字图像设备搭建贝类种类鉴别的便携式装置积累了相关经验, 为贝类种类的在线分析提供了技术参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|