
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
小波分析的茶鲜叶全氮含量高光谱监测
[王凡1, 2  , 陈龙跃
, 陈龙跃2, 3 , 段丹丹1, 2, 4, * , 曹琼1, 4 , 赵钰1 , 蓝玩荣5 ]
, 陈龙跃, 曹琼|
|


作者简介: 王 凡, 1994年生, 国家农业信息化工程技术研究中心工程师 e-mail: wfnn9448@163.com
茶是世界上最受欢迎的饮料之一, 而氮素(N)是影响茶叶品质的主要成分之一, 因此快速准确地估算N素含量至关重要。 由于测定N含量的化学方法繁琐耗时, 利用高光谱对茶鲜叶中N含量进行预测, 利用连续小波转换(CWT)提取的小波系数, 探究CWT不同分解层数对于N素含量的估测能力, 并讨论了不同波长选择算法所建模型的预测效果。 首先, 采集广东省英德市茶园的151个茶鲜叶样品高光谱数据, 将获得的原始光谱通过卷积平滑(SG)、 去趋势(Detrending)、 一阶导数(1st)、 多元散射校正(MSC)和标准正态变量变换(SNV)五种预处理方法进行预处理并作为参考。 其次, 采用连续小波对原始光谱进行初步处理生成多尺度小波系数, 并进行相关性分析, 分别利用连续投影算法(SPA)、 竞争性自适应加权采样法(CARS)和变量组合集群分析(VCPA)方法进一步优化CWT变换后光谱数据的变量空间, 最后, 以特征变量为输入使用PLSR建立了N素定量监测模型, 并对比不同尺度不同方法估算N素的效果。 结果表明, 连续小波分析方法可有效提升茶鲜叶光谱对N素含量的估测能力, 明显优于常规光谱处理方法。 经连续小波分解后, 对茶鲜叶N素的预测能力随分解尺度的增加整体呈逐步降低的趋势, 其中在1~6尺度连续小波变换后的光谱与茶鲜叶N素存在良好的相关性, 表明小尺度的连续小波分解可有效应用于茶鲜叶N含量的监测。 基于CWT(1)-VCPA方法建立的模型精度最高, 且变量数相比于全波段减少了99.34%, 其建模与预测 R2达到0.95和0.90, 相比于传统光谱处理方法, 精度提升了11% , 证明CWT-VCPA可以有效降低光谱维度并大幅提升模型精度。 实现了茶叶N素含量的高效量化预测, 为评估茶叶的其他成分提供了可靠技术参考。
Tea is one of the most popular beverages globally, which is greatly affected by the content of nitrogen (N) in quality. Due to the complicated and time-consuming method for determining N content in fresh tea leaves by traditional chemical analysis, this paper proposes a means for N content prediction by hyperspectral technique. The wavelet coefficients extracted by continuous wavelet transform (CWT) technology are used to estimate N content by different decomposition layers of CWT. Moreover, the predictive effects of models built by different wavelength selection algorithms are also discussed. Several 151 hyperspectral data of tea samples were collected from tea gardens in the Yingde City of Guangdong Province. The original spectra data are preprocessed by smoothing (SG), detrending (Detrending), first derivative (1st), multiple scattering correction (MSC), and standard normal variable transformation (SNV) while comparing with CWT. Then, continuous wavelet multi-scale analysis is applied to process the original spectrum for generating wavelet coefficients, and Pearson correlation analysis was also performed. Next, three kinds of methods, including successive projections algorithm (SPA), competitive adaptive weighted sampling (CARS) and variable combination population analysis (VCPA), are adopted to optimize the variable space of the spectral data after CWT transformation. At last, quantitative models of N content prediction are established and compared by PLSR with characteristic variables selected by the three above mentioned methods as input. The overall results show that the continuous wavelet analysis algorithm can improve the model's efficiency for estimating the N content of the fresh tea leaves by hyperspectral data. Furthermore, it has better performance than other conventional spectral preprocessing methods significantly. With continuous wavelet decomposition, the precision of the model for N content prediction gradually decreases with the increase of the decomposition scale.There is a good correlation between the spectrum after the continuous wavelet transforms on the scale of 1~6 and the N in fresh tea leaves,which shows that the small-scale continuous wavelet algorithm can be well applied to monitor N content in fresh tea leaves. The model established by CWT (1scale)-VCPA method has the best performance, andthe number of variables is reduced by 99.34% compared to the full band. The R2 of the calibration model and prediction model respectively, are 0.95 and 0.90. Compared with the traditional spectral processing method, the accuracy is improved by 11%. It is proved that the combination of CWT-VCPA can obviously reduce the spectral dimension and improve the accuracy of the model. This research achieves an efficient way for N content prediction of tea, which provides a technical basis and reliable reference for other components evaluation of tea.
茶树是世界上广泛种植的作物, 因其独特的滋味以及强大的健康功效而受到人们的喜爱。 众所周知, 氮(N)是植物光合作用和生长必需的元素, 实时进行氮素管理, 对于保证茶叶产量, 减少环境污染[1]具有指导意义。
传统的作物氮素检测方法费时耗力, 对样品具有破坏性, 需具备较高的操作技能, 无法满足实时准确的测定需求[2]。 高光谱作为一种成熟的无损检测技术已被广泛应用于茶叶的营养诊断、 种类识别、 长势检测[3, 4]。 光谱测量植被生化变量中有光谱信息冗余等问题, 易受到噪音和背景因素的影响。 如何从复杂重叠的光谱信息中得到微弱的化学成分变化的有效信息, 提高检测精度, 是光谱分析的关键。 研究表明, 偏最小二乘方法(PLSR), 通过使用主成分分析(PCA)将自变量投影到新空间以概括潜在变量, 可以处理大量的噪声和相关变量, 被证实同样适用于少量变量的情况[5]。 选择合理的特征提取方法可以降低模型的复杂程度并提高预测准确性和鲁棒性, 且少量变量即可提供与原始全光谱波段相媲美的信息。 已有的研究报道了许多方法, 如SPA, UVE, PCA, RF以及CARS等[6, 7], 这些方法都是选择信息变量非常有效的策略, 然而其变量选择方法大多是利用蒙特卡洛采样法在样本变量空间进行重复取样后一次性建模, 却没有考虑到变量之间的组合效应。 此外, 在整个光谱区间进行变量搜索, 这些方法仅消除了非信息性变量而未考虑干扰变量的影响, 当存在干扰变量时, 将无法获得令人满意的结果。 连续小波变换(CWT)用于处理高光谱数据, 通过缩放和移动小波函数将原始光谱分解为多个尺度, 促进对细微特征信号的识别, 从而构建对光谱敏感的生物和化学成分的预测模型, 已广泛应用于植被参数评估。 变量组合集群分析(VCPA)算法, 是基于达尔文进化论的“ 适者生存” 以及依据交叉验证均方根误差(RMSE)的一种变量选择方法[8], 从全光谱数据中选择光谱变量的最佳组合, 利用变量的随机组合考虑变量间的相互作用, 进行多次迭代的分析, 直到剩下的变量没有无信息变量和干扰变量, 在特征提取方面效果较好[9, 10]。 连续投影算法(SPA)、 竞争性自适应重加权算法(CARS)广泛用于高光谱信息筛选中以提高模型性能, 而关于VCPA的应用研究较少; 另外, 基于小波分析的品质参数估算, 在茶鲜叶监测上的应用鲜有报道, 目前尚未有开发CWT与VCPA特征变量选择算法相结合的模型优化方法的应用实例。
以茶鲜叶为研究对象, 利用小波分解对茶鲜叶光谱展开分析, 确定了CWT在茶叶N素含量鉴定中的性能, 结合实验室理化检测茶鲜叶N素含量, 采用SPA, CARS和VCPA特征波段选择算法提取有益信息, 建立茶鲜叶N素含量预测模型, 并探究在小波算法不同分解尺度下, 不同特征波段选择算法对茶鲜叶N素估算精度的影响。
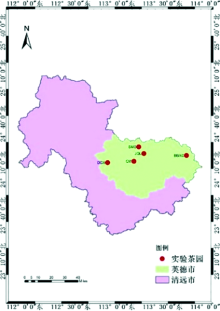
实验区位于广东省清远市英德市积庆里、 创美、 德高信、 八百秀才和石门山5个茶园(图1), 该区域位于北纬24.50° , 东经113.55° , 平均海拔为181 m, 地处南亚热带向中亚热带的过渡地区, 属亚热带季风气候。 茶鲜叶光谱数据采集在2020年5月、 7月和9月开展, 覆盖3个品种(包括主栽品种英红九号, 鸿雁十二号, 金萱), 采样点均匀分布于实验区内, 共选取了151个样本点, 每个样点采集茶鲜叶样品约200 g, 进行化验。
 | 图1 研究区域空间分布Fig.1 Spatial distribution of study area |
叶片的光谱反射率采用美国ASD Fieldspec Pro3光谱仪测量, 其波谱覆盖范围为350~2 500 nm, 光谱重采样间隔为1 nm。 利用叶片夹持器(自带光源)选取叶片的中部较宽的部分进行光谱测定, 手柄中的光源部分直接夹紧茶叶叶片所测部位, 叶片夹持器测定使叶片处于密闭条件下, 且所测面积相同, 保证光谱数据获取的精确性和稳定性。 取10片标准叶片在相同样点采集光谱数据, 10个光谱反射率的平均值作为该样点叶片的光谱反射率。
采集光谱数据后的茶鲜叶放于120 ℃烘箱中杀青固样30 min, 然后置于80~90 ℃下烘至足干。 干燥后的样品磨碎后参照GB5009.5— 2016, 通过凯氏定氮法测量其全氮量。
1.3.1 常规光谱预处理方法
采用卷积平滑(SG)、 去趋势(Detrending)、 一阶导数(1st)、 多元散射校正(MSC)和标准正态变量变换(SNV)五种预处理方法, 对原始光谱数据进行预处理作为参考。
1.3.2 小波变换
连续小波变换(CWT)起源于傅里叶变换信号处理技术, 同时开展频率和时间分析, 从复杂的原始光谱信号中分辨细微的变换, 捕捉有益信息, 表征光谱局部特征信息。 小波变换分析广泛应用于高光谱数据的降维压缩、 噪声去除、 特征选择以及弱信号提取等方面。 小波分析包括连续分解与离散分解两种类型的小波变换, Wang等[11]研究表明离散小波随着分解尺度的增加, 光谱维度减半, 不能对光谱数据进行较好的分析。 连续小波变换是一种连续分解信号的方法, 其输出光谱可以与原始光谱直接进行对比, 比离散小波变换后获得的光谱更易于解释。 通过以式(1)缩放和移动小波母函数
式(1)中, λ 为茶叶叶片高光谱数据的波段数, a和b分别代表伸缩因子(即宽度)和平移因子(即位置), 这两个变量都为正实数。 CWT的输出公式如式(2)
式(2)中, f(λ )为高光谱反射率, CWT系数(Wf(ai, bj), i=1, 2, ..., m; j=1, 2, ..., n)包含两维(即m× n矩阵), 其中一维为波长(1, 2, ..., n), 另一维是分解尺度(1, 2, ..., m), 因此, 小波系数是一个行为尺度, 列为波长的矩阵。
由于Mexh小波在高光谱分解方面表现出色[12], 且光谱吸收特性与高斯函数相似, 因此选取Mexh作为小波母函数, 使用连续小波分析(continuous wavelet transformation, CWT)以执行尺度21~210分解反射光谱为10个尺度, 并获取不同分解尺度下的不同波长的一系列小波系数, 进行了小波系数与茶叶N素含量的相关性分析, 并用于构建校准模型。
1.3.3 特征变量选择方法
连续投影(SPA)是一种前向变量选择方法, 使用简单的投影操作来获得具有最小共线性的变量子集, 并可以根据交叉验证的最小均方根误差(RMSE)选择最终的最佳波长。
竞争性自适应重加权采样(CARS)结合蒙特卡洛采样和PLSR, 基于达尔文进化论, 遵循“ 适者生存” 的原则, 根据每个变量的重要性, 以迭代和竞争的方式从N个蒙特卡洛采样顺序中选择N个变量子集。
变量组合集群分析(variable combination population analysis, VCPA)是一种新的有效的变量选择方法, 它由Yun等建立[13]。 VCPA的实现过程分为两个基本步骤, 首先基于“ 适者生存” 原理的指数递减函数(exponentially decreasing function, EDF)选择有用的变量并缩小变量空间, 其次通过二进制矩阵采样(binary matrix sampling, BMS)选择最佳光谱波长子集, 通过生成随机变量组合, 确保每个变量都有机会被选择并产生各种变量子集, 在每个EDF和BMS运行的周期中都采用模型集群分析(model population analysis, MPA)根据较低的RMSECV来确定最优变量子集。 分别利用SPA, CARS和VCPA对连续小波变换处理后的光谱数据进行进一步的特征波段提取。
经过连续小波变换后的光谱, 通过SPA、 CARS和VCPA方法进行变量筛选, 利用偏最小二乘法(partial least squaresreg ression, PLSR)构建茶鲜叶N含量的估测模型。 采用Kennard-Stone(KS)方法以近似3:1比例选取113个样本数据作为建模集, 用于构建估测模型, 剩余的38个样本数据作为验证集, 用于预测模型精度和稳定性的验证。 模型精度采用模型评价参数决定系数(R2)与均方根误差(RMSE)来综合评价模型表现, 其计算方法如式(3)和式(4)
式(3)和式(4)中, n为样本个数, i为样本, YI和Y'I分别是样品的实测与预测值,
使用Matlab R2018b(The Math Works, Natick, USA)、 Unscrambler X10.4(CAMO AS, Oslo, Norway)、 SPSS 26(IBM, USA)、 Origin 2019b(OriginLab, USA)等软件。
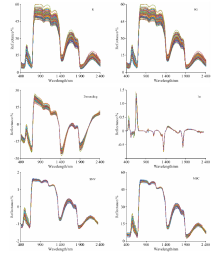
图2展示了5种预处理后的高光谱。 与原始光谱(R)相比, 预处理1st和Detrending方法明显改变了光谱特性, 在具体波段上凸显了光谱信息, 而SG, MSC和SNV预处理方法没有明显改变光谱吸收特性, 光谱特征变化幅度小, 与原始光谱相比更加平滑与集中。 上述5种预处理算法有效地平滑光谱曲线, 且可以保留光谱信息的有用信息。
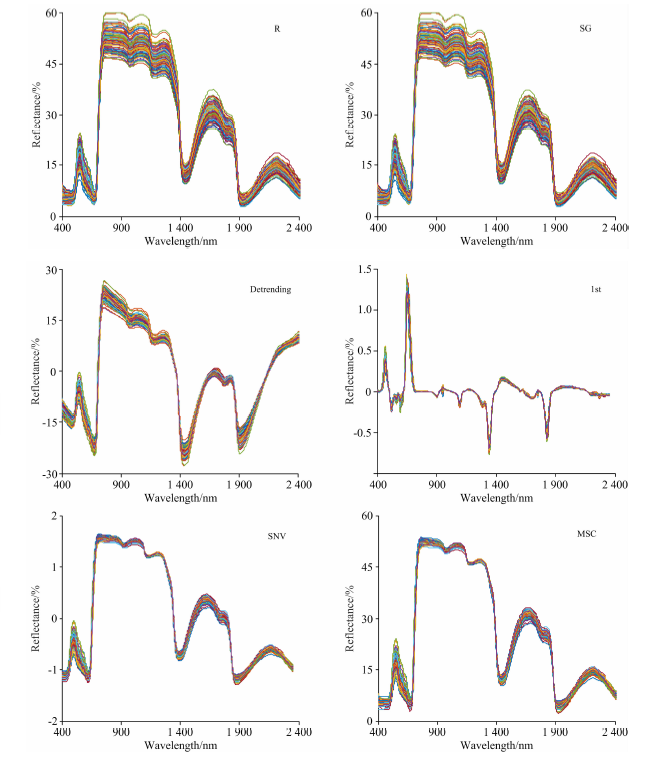 | 图2 不同预处理方法下光谱反射率Fig.2 Reflectance spectra with different pre-processing methods |
2.2.1 基于小波变换的光谱分析
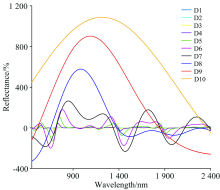
原始光谱经CWT处理后的结果如图3所示, D1— D10分别代表了以21— 210为分解尺度经过CWT分解得到的10层小波能量系数模拟光谱分辨率。 可以看出, 1— 7尺度上的光谱分辨率, 随着分解层数的增加, 光谱吸收、 反射波谱特征均加强, 光谱波动范围加大, 8— 10尺度的光谱反射率起伏变化较大。 总体来看, 随着CWT分解尺度的不断增加, 原始光谱反射率的波峰特征(761, 1 070, 1 217和1 645 nm)与波谷特征(670, 902, 1 447和1 931 nm)被不断放大, 并且均有一定的红移与蓝移现象。 小尺度分解可以较好的保持原始光谱特性, 随着分解层数的增加, 光谱特征在不断凸显的过程中也不断被拉伸, 在大尺度分解中又可以凸显具体波段的细微特征信息。 这是因为CWT是基于光谱曲线的形状特征, 捕获光谱形状的差异并凸显特征[14], 更有利于捕捉原始光谱反射率的微弱变化, 有利于进行N含量对茶叶鲜光谱响应特征的分析。
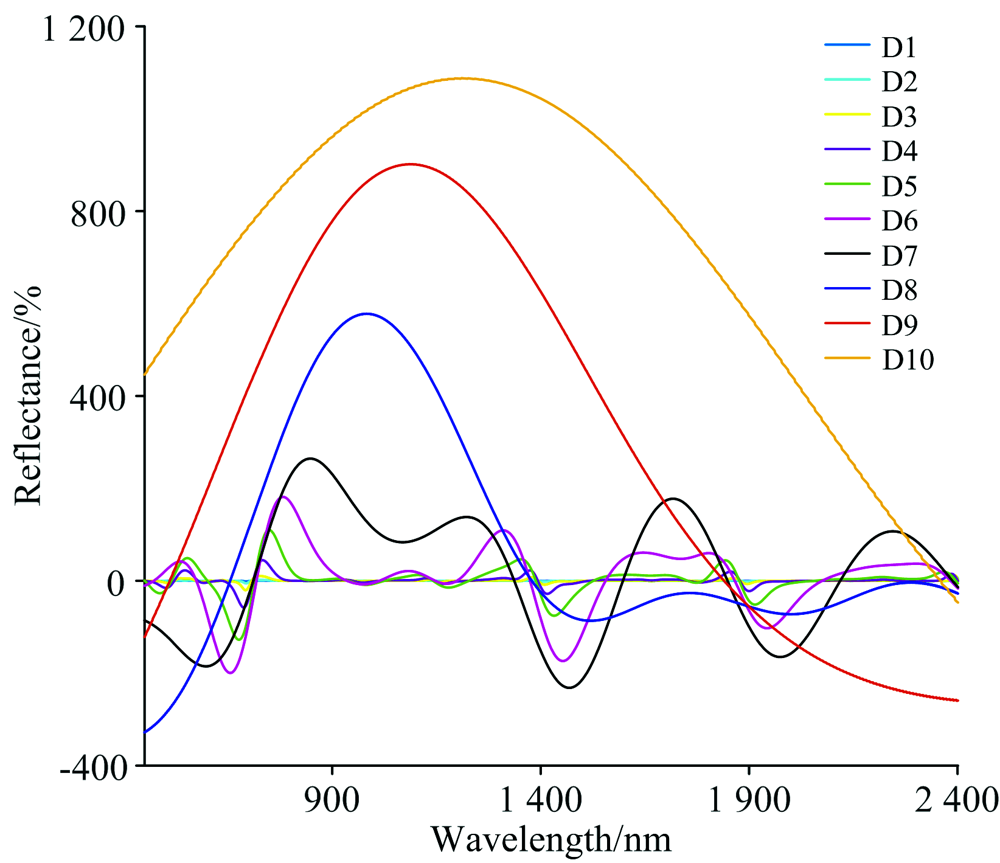 | 图3 小波变换光谱特性Fig.3 Spectral characteristics of wavelet transform |
2.2.2 相关性分析
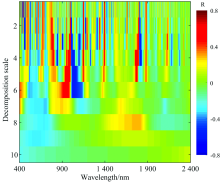
小波系数能量与N素实测数据进行相关性分析, 如图4所示。 可看出各尺度小波系数与茶鲜叶N含量的相关系数差异较大, 且随着分解尺度的增加呈逐渐集中分布的趋势。 由图可知, 相关性较高的波段表现为更明显的红色区域, 相关系数较大的波长主要与N素、 叶绿素以及类胡萝卜素等物质的复杂性有关, 对于选定的493, 987, 1 193, 1 195和1 825 nm, 这些波段大多为N素的重要光谱区域[15], 另外可以看出, 小波变换后的光谱在小尺度分解下与茶鲜叶N素存在良好的相关性, 选取1— 6尺度作进一步分析。
 | 图4 小波变换相关性分析Fig.4 Correlation analysis of wavelet transform |
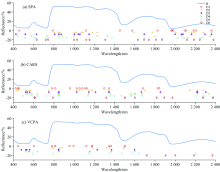
为了比较不同变量筛选方法对茶鲜叶N含量高定量模型的影响, 将经过CWT处理的光谱数据分别利用SPA, CARS和VCPA进行变量筛选。 SPA设置选择的最小和最大变量数的参数分别为1和30, 分别对CWT处理后的小波系数进行光谱特征变量的选取, 结果如图5(a)所示, 光谱变量分别减少到15, 16, 17, 11, 14和18个。 CARS设置蒙特卡洛抽样运行次数为50, 十倍交叉验证用于评估每个子集的效用, 分别对CWT处理后的小波系数进行光谱特征变量的选取。 结果如图5(b)所示, 光谱变量分别减少到16, 19, 17, 16, 15和17个。 VCPA设置EDF剩余变量数为100, 迭代次数为50, 最优子模型的比例为10%, BMS运行次数为1 000, VCPA步骤中每个BMS采样的平均数设置为20, 并采用5折交叉验证分别对CWT处理后的小波系数进行光谱特征变量的选取, 结果如图5(c)所示。 可以看出基于CWT小波分解后的光谱数据通过VCPA的五次迭代将全波段光谱变量分别减少到12, 11, 10, 11, 8和8个。 相比SPA和CARS, VCPA选择的变量更少, 这表明该方法在数据降维方面有着巨大的优势。
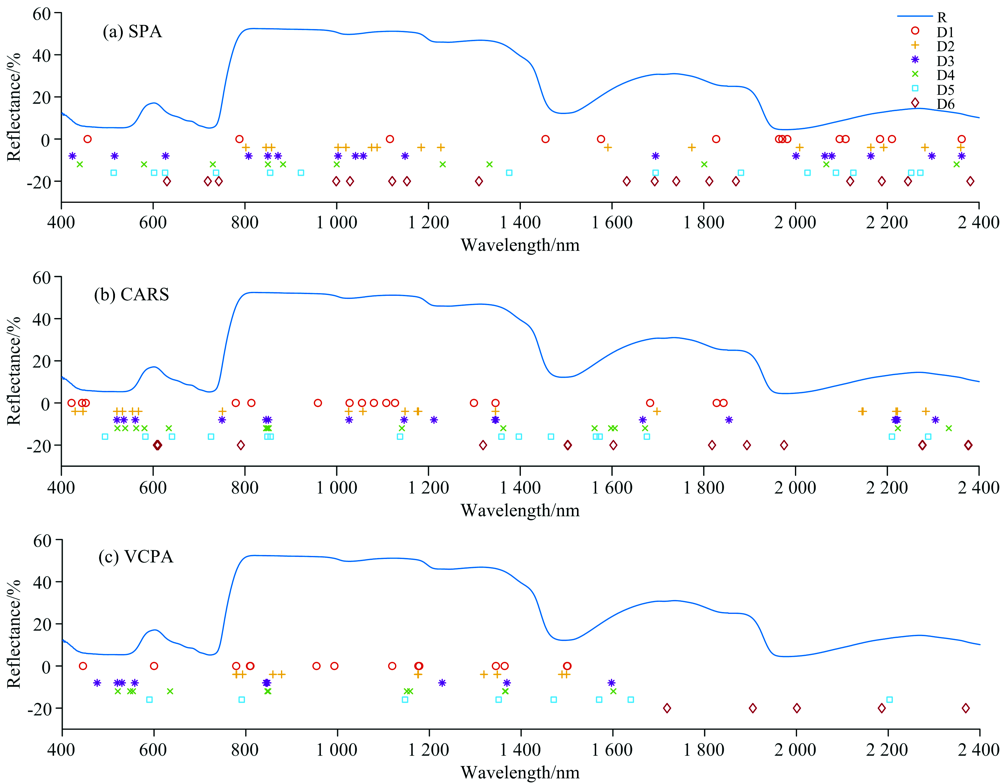 | 图5 SPA, CARS和VCPA筛选的特征变量Fig.5 The variables selected by SPA, CARS and VCPA |
2.4.1 基于常规预处理方法和特征筛选的N素含量预测
采用卷积平滑(SG)、 去趋势(Detrending)、 一阶导数(1st)、 多元散射校正(MSC)和标准正态变量变换(SNV)5种传统光谱处理技术分析茶鲜叶光谱特性, 并采用偏最小二乘算法建立茶鲜叶N素含量预测模型作为参考, 结果如表1所示。
| 表1 基于不同预处理方法和变量选择方法的模型 Table 1 Models based on different preprocessing methods and variables selection methods |
2.4.2 基于小波变换和特征筛选的N素含量预测
使用CWT处理后的光谱数据筛选后的特征波段作为自变量, 以茶鲜叶N含量为因变量, 采用偏最小二乘法构建茶鲜叶N含量的估测模型(表2)。 由表2可知, 经过CWT处理后光谱构建的模型均表现出较好的拟合精度, 并且随着分解尺度的增加模型精度呈现下降趋势, 说明小规模分解通常能够改善CWT处理后的小波系数对分析物的敏感性, 这与Liu等的研究结果一致[16]。 其中SPA选择变量估测茶鲜叶N含量的精度较低, 1— 6尺度建模R2范围在0.65~0.83, RMSE范围在0.25~0.33, 预测R2范围在0.65~0.83, RMSE范围在0.25~0.33; 以CARS选择变量为因变量, 1— 6尺度建模R2范围在0.73~0.91, RMSE范围在0.19~0.32, 预测R2范围在0.64~0.88, RMSE范围在0.24~0.35; VCPA选择变量估测模型表现最好, 1— 6尺度建模R2范围在0.73~0.95, RMSE范围在0.16~0.29, 预测R2范围在0.73~0.90, RMSE范围在0.23~0.35, 其中在1尺度下的模型拟合效果最高。
| 表2 基于不同分解层数和变量选择方法的模型 Table 2 Models based on different decomposition scales and variables selection methods |
图6所示为不同变量选择方法下最优估测模型实验值与预测值1:1对比图, 可以看出CWT-VCPA模型表现最优, 训练集和验证集的R2分别为0.95和0.90, RMSE分别为0.16和0.23, 二者差异较小, 相比于CWT-SPA和CWT-CARS, 建模及预测集的预测精度最高。 对比各模型可知, CWT方法结合特征变量选择算法明显提升了模型的精度, 且CWT-VCPA筛选变量估算N含量效果最好。
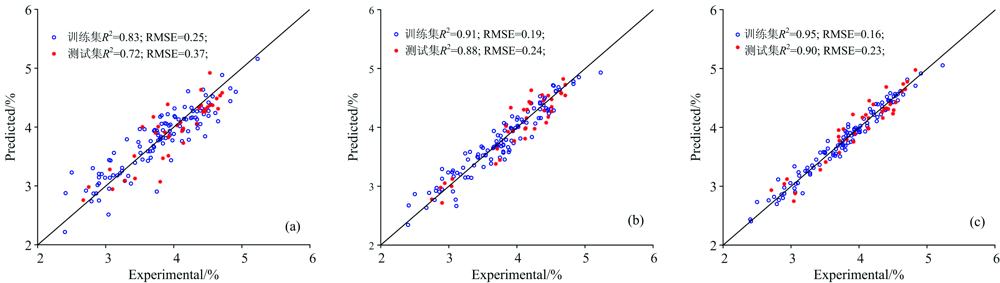 | 图6 基于(a)CWT(1尺度)-SPA-PLSR, (b)CWT(1尺度)-CARS-PLSR和(c)CWT(1尺度)-VCPA-PLSR的氮含量最佳模型的拟合1:1拟合图Fig.6 Fitting diagrams of the optimal models of tea nitrogen based on (a) CWT (1 scale)-SPA-PLS, (b) CWT (1 scale)-CARS-PLS and (c) CWT (1 scale)-VCPA-PLS |
以茶鲜叶为研究对象, 构建并对比分析了常用5种光谱处理与连续小波分解方法的N含量估测模型。 研究结果表明, 与常规光谱处理方法相比, 小波变换方法可明显提升茶鲜叶光谱对N含量的响应, 且模型精度与稳定性均较高。 这是由于在常规的光谱预处理方法中, SNV, MSC和Detrending通常用于校正低频散射信号、 1st可以消除信号的基线漂移, 而CWT可以同时消除光谱信号中的高频和低频噪声, 并且连续小波分解本质上是一种基于相关性的方法, 可以捕获对茶多酚含量最敏感的小波特征, 这种频谱相关性的方法在凸显光谱细微变化特征方面效果显著, 更有利于后续对光谱特征波段的提取。 随着分解尺度的增加, 模型预测精度逐步降低, 主要原因是光谱中含有较多的噪声, 造成了光谱的有益信息与噪声的分布波段区间有较高的重叠性, 且随着CWT分解尺度的增加, 其内含的有益信息与无益噪声信息重新分配, 导致引入的噪声信息较多从而降低模型的预测精度。 在1— 6尺度模型精度达到最低时相较于传统光谱变换仍然有一定程度的提升, 表明CWT能提取光谱特征中的有益信息, 并一定程度上分离无用噪声, 提升光谱信息信噪比。 基于三种不同波段筛选方法(SPA, CARS和VCPA)都可以在减少变量的同时提升模型预测效果, 且相比于SPA和CARS, VCPA选择的变量更少, 预测效果更好。 这归因于EDF对变量的连续收缩, 在EDF的每次运行中, 都会消除一些贡献较小的变量。 此外, 还与BMS和MPA的使用有关, BMS是一种采样策略, 它为所有变量提供了相同的机会进行采样, 使用不同的变量组合用于子模型的构建。 MPA用于提取子模型中包含的最佳变量组合, 比较每个子模型的RMSECV, 保留最佳10%子模型中具有最高频率的变量[17]。 因此, VCPA通过最少的选择变量, 保证了光谱数据集更好的可预测性。 当将最佳波长与全光谱进行比较时, 基于CWT分解光谱结合VCPA筛选特征变量的PLSR模型比其他光谱变换的PLSR模型具有更高的性能(R2=0.95), 并且减少了全光谱数据变量的99.34%, 极大的简化了建模过程。 综上可知, CWT-VCPA方法在实现对茶鲜叶N含量的定量监测方面具有强大的潜力。
采用传统光谱处理技术和连续小波技术对光谱分别开展处理和分析, 并通过SPA, CARS和VCPA方法进一步筛选特征波段, 建立预测茶鲜叶N素含量的模型。 旨在研究基于连续小波技术结合特征变量选择方法预测茶鲜叶N素含量的最优模型, 结论如下:
(1)相比于传统光谱处理方法, 经过CWT分解光谱结合变量选择方法构建的茶鲜叶N含量估算模型均表现出令人满意的结果, 且随着分解层数的增加, 模型的精度整体有逐步下降的规律。 表明CWT处理可有效提升光谱对N的敏感性, 且小规模分解通常能够改善这种关系, 提高模型性能。
(2)以SPA, CARS和VCPA筛选出的特征变量为模型输入因子均在CWT分解尺度为1时达到最佳估算效果, CWT-SPA-PLSR建模R2为0.83, RMSE为0.25; CWT-CARS-PLSR建模R2为0.91, RMSE为0.19; CWT-VCPA-PLSR建模R2为0.95, RMSE为0.16。
(3)经过1尺度CWT分解结合VCPA所构建的模型表现最佳(
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|