{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
不同土壤类型的有机质含量的可见-近红外光谱检测模型传递方法研究
[胡国田1, 2, 3  , 尚会威
, 尚会威1, 2, 3 , 谭瑞虹1 , 许翔虎1 , 潘伟东1 ]
, 尚会威|
|


作者简介: 胡国田, 1977年生, 西北农林科技大学机械与电子工程学院副教授, 美国农业部农业研究所访问学者e-mail: hugttrh@163.com
利用可见-近红外光谱分析技术可以准确快速的获取土壤养分含量, 但不同类型土壤间养分含量校正模型的普适性是亟待解决的关键问题。 为提高有机质含量光谱校正模型在多类型土壤之间的普适性和农田在线检测有机质含量速度, 利用美国M107B区66个样品建立基于可见-近红外光谱的土壤有机质含量的粒子群-最小二乘支持向量机(PSO-LSSVM)校正模型, 预测M107B区的23个验证集样品的决定系数 R2=0.859, 相对分析误差RPD=2.660; 将M107B区89个土壤样品作为校正集建模后对N116B区20个验证集样品的有机质含量预测, 预测 R2=0.562, 预测RPD=0.952, 模型的预测 R2和预测RPD分别降低34.6%和64.2%, 表明M107B区土壤有机质含量的可见-近红外光谱校正模型直接用于N116B区时, 预测精度显著降低; 将N116B区部分土壤样品加入到M107B区样品集后重新建模, 并预测N116B区20个验证集样品的有机质含量, 当加入的N116B区土壤样品数量达到35以上, 预测 R2>0.80, 预测RPD>2.0; 加入到校正集的N116B区土壤样品数量从0增加到50, 模型预测 R2从0.562增加到0.811, 预测RPD从0.952增加到2.274, 精度逐渐提高。 结果表明, 在M107B区校正模型中加入N116B区部分土壤样品建模, 能够有效提高M107B区土壤校正模型对N116B区土壤有机质含量的预测精度; 加入的N116B区土壤样品数量达到50以上, 模型预测性能趋于稳定, 预测精度达到实用要求, 成功将M107B区土壤有机质含量校正模型传递给N116B区土壤; 优先选择与M107B区土壤样品的有机质含量或光谱曲线差异较大的N116B区土壤样品参与建模, 可有效避免模型传递时模型性能出现突变。 提出的方法能够有效提高M107B区土壤的有机质校正模型对N116B区土壤的预测精度, 为基于可见-近红外光谱的农田土壤有机质含量实时检测提供一种新的经济可行的模型传递方法, 为提高多类型土壤的有机质含量检测模型的普适性提供一种有效的解决方案。
Soil properties can be estimated accurately and quickly using visible and near-infrared (VNIR) diffuse reflectance spectroscopy. However, a key problem is the lack of universal nutrient content calibration models for different soils. To improve the universality of the soil organic matter (SOM) content calibration model for different types of soils and the speed of online detection of the SOM in farmland, sixty-six samples of soil from M107B in the United States were used to establish the SOM content. Calibration model using the particle swarm optimization-based least squares support vector machines (PSO-LSSVM) method using VNIR spectroscopy. Then this calibration model predicted 23 samples of the validation set from M107B. The results gave the coefficient of determination ( R2) and the ratio of standard deviation to root mean square error of prediction (RPD) of 0.859 and 2.660, respectively. Subsequently, we predicted the SOM content of the validation set, including 20 samples from N116B, by the PSO-LSSVM calibration model of all 89 soil samples from M107B. The results showed decreases in the R2-value (0.562) and RPD (0.952). These decreases in R2 and RPD values by 34.6% and 64.2%, respectively, indicated that the prediction accuracy was significantly decreased when the PSO-LSSVM calibration model of SOM content in M107B was directly used to predict SOM content in N116B. The PSO-LSSVM calibration model established by the calibration set, a combination of some soil samples from N116B and all 89 samples from M107B was also used to predict SOM content of the previous validation set from N116B and gave the R2 values that were more than 0.80 and RPD values that were more than 2.0 when the number of soil samples from N116B was added over 35. In addition, R2 increased from 0.562 to 0.811. RPD increased from 0.952 to 2.274 when the number of soil samples from N116B added to the calibration set increased from 0 to 50. The results showed that calibration model accuracy could be effectively improved by adding some soil samples from N116B to M107B calibration set when predicting SOM content in N116B. The prediction performance of models was stable, whereas the prediction accuracy met practical requirements when the number of soil samples from N116B added to the calibration set was more than 50. In addition, the calibration model of SOM in M107B was successfully transferred to the soil in N116B, and the samples in N116B with large differences in organic matter content or spectral curve from samples in M107B are preferred to adding to the calibration set because this method can effectively avoid the mutation of model transfer performance. In conclusion, the results provided a method to improve the SOM prediction accuracy of N116B soil using the SOM calibration model of M107B soil. Furthermore, the results provided a new, economical and feasible model transfer method for real-time estimating of SOM content in farmland based on VNIR. The results also provided an effective solution to improve the universality of the SOM content calibration model for different soil types.
土壤有机质(soil organic matter, SOM)是评价土壤肥力和养分的重要指标, 是科学精准施肥需获取的重要信息。 准确获取土壤有机质含量是保持土壤肥力、 维持良好耕地质量的基础。 传统的土壤有机质含量测量方法虽然精度比较高, 但是操作复杂、 周期长、 破坏性大、 成本较高, 不适合大面积测量。 土壤可见-近红外光谱曲线包含丰富的光谱信息, 能够综合反映多种土壤信息。 近年来, 国内外许多学者针对某一地区或某种土壤开展有机质含量光谱预测研究, 有机质含量的光谱预测精度不断提高[1, 2, 3], 但在进行大范围多类型土壤的有机质含量预测时, 不同类型土壤的光谱差异会影响预测精度。
对多类型土壤建立有机质含量校正模型主要有两种方法, 即用大范围多类型的土壤样品建模和模型传递。 Brown等[4]从全球五大洲采集4 184个独立样本对阳离子交换量、 土壤有机碳、 土壤无机碳、 粘土含量、 游离铁含量等7种土壤属性进行预测, 证明了可见-近红外光谱在全球土壤表征方面的基本可行性。 Krishnan等[5]利用逐步多元线性回归对美国伊利诺斯州4种类型土壤的光谱反射率数据分析, 发现564和623 nm是有机质的敏感波段。 陈昊宇等[6]采用连续小波变换对多种土壤类型光谱数据进行预处理, 提升光谱数据与有机质含量之间的相关系数, 进而提高模型精度。 纪文君等[7]提取了7组不同地区不同类型土壤样品共同的有机质响应波段, 为建立多类型土壤的有机质含量校正模型提供参考。 但若要采集全球所有类型土壤光谱并进行土壤有机质含量预测并不可行, 且模型精度也可能随着土壤类型数量的增加而降低。 针对某一土壤类型的光谱校正模型应用到其他土壤类型的养分含量检测精度显著下降问题, 模型传递提供了一种有效的解决方案。 Padarian等[8]论证了模型传递的有效性, 模型传递前后土壤有机碳、 阳离子交换量、 粘土含量和pH值的预测均方根误差都降低了10%以上。 Panchuk等[9]通过直接校正算法(DS)成功将一定波长范围的杏仁糖近红外光谱定量模型应用于另一台近红外仪器。 国内外许多学者也尝试使用其他模型传递算法如典型相关分析算法[10]、 斜率截距校正法[11]等。
目前, 大多数模型传递研究以不同仪器之间模型传递为主, 主要在改良算法或开发新算法范畴内进行, 通常需要大量的样品来使模型传递更加可靠[12]。 这些算法在解决不同类型土壤之间的模型传递时具有局限性, 难以适应田间土壤养分含量的快速检测需求。 本研究探索在已有土壤类型的有机质含量光谱预测模型基础上, 通过适当增加另一土壤类型的样品参与建模, 优化已有模型, 提高已有模型对新土壤类型的有机质含量检测精度, 为基于可见-近红外光谱的农田多类型土壤的有机质含量实时检测提供一种新的经济可行的模型传递方法, 提高模型的普适性, 为建立大面积小样本的多类型土壤的有机质含量校正模型提供参考。
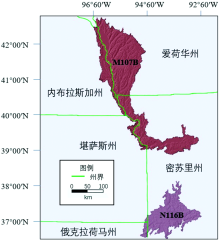
主要土地资源区(major land resource areas, MLRAs)是美国农业部定义的用来描述相似气候、 土壤和土地用途的区域, 是依据土壤、 气候、 水资源或土地利用的显著地理特征进行划分[13]。 本研究土壤样品采自N116B区和M107B区, 两区的地理位置如图1所示。
 | 图1 N116B区和M107B区在美国地图上的位置Fig.1 Locations of N116B & M107B on the map of USA |
N116B区位于斯普林菲尔德平原, 属于亚热带常绿阔叶林气候地带, 年降水集中, 年均降水量为660~1 040 mm, 年均气温8~13 ℃, 牧场面积占比近50%。 M107B区位于爱荷华州和密苏里州中部的黄土丘陵, 属于温带草原气候地带, 其年均降水量1 040~1 145 mm, 年均气温13~15 ℃, 该地区农场较多, 存在水土流失、 土壤中有机物的枯竭和水质差等资源问题。 共采集了259份土壤样品, 其中M107B区土壤样品89份, N116B区土壤样品170份。 所有土壤样品的采样深度均为0~15 cm。 所有样品用烤箱烘干后研磨, 过2 mm孔筛, 再分成两份分别用于实验室理化检测和光谱扫描。 土壤有机质的理化检测使用灼烧法, 在密苏里大学的土壤与植物检测实验室完成, 理化检测得到的源土壤M107B区和目标土壤N116B区的土壤有机质含量统计特征见表1。
| 表1 土壤有机质含量理化分析结果统计 Table 1 Statistics of physical and chemical analysis results of soil organic matter |
从研磨过筛的土壤样品中取约15 cm3土壤装入底部为玻璃的样品杯中, 摇晃样品杯使较细颗粒土壤位于杯底, 卤素灯的光通过玻璃照射土壤样品表面, 反射光通过光纤传输到光谱仪。 光谱仪采用美国ASD公司的FieldSpec Pro FR光谱仪, 该光谱仪由3个不同波段的独立光谱仪组合而成, 波段分别为350~1 100, 1 000~1 900和1 700~2 500 nm, 其总波长范围是350~2 500 nm, 光谱仪分辨率为3 nm(350~1 000 nm), 10 nm(1 000~2 500 nm); 采样间隔为1.4 nm(350~1 000 nm), 2 nm(1 000~2 500 nm); 采样输出数据间隔为1 nm。 计算机安装光谱采集软件FieldSpec RS3记录土壤样品的光谱数据。 采集光谱时, FieldSpec RS3的参数设置为: 光谱平均数30次, 白板扫描平均数50次, 暗电流扫描平均数50次。 暗电流扫描在每个扫描阶段开始时进行, 之后每30 min最少扫描1次。 按0° , 45° 和90° 放置样品杯, 采集各角度下的土壤样品光谱。 若3次所得反射光谱相似, 取其平均值作为该土壤样品的光谱数据; 若3次反射光谱中有1次获得的光谱反射率与另外2次有显著差异, 则去除该次光谱扫描数据, 并以另外2次光谱反射率的均值作为该土壤样品的光谱数据。 每扫描5个土壤样品后进行白板校正以消除参考光谱误差。 光谱扫描完成后去除所有土壤样品的光谱曲线中光谱数据信噪比低的边缘波段350~400和2 451~2 500 nm。 光谱扫描在密苏里大学校内的美国农业部农业研究所完成。
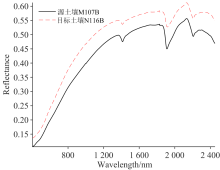
图2为源土壤M107B区和目标土壤N116B区两组土壤样品的平均光谱反射率曲线。 从401~2 450 nm全波段范围的光谱反射率来看, 两个地区土壤的光谱曲线在1 400, 1 900和2 200 nm附近都存在明显的水分吸收谷。 N116B区土壤类型主要为淋育土(Alfisols)、 极育土(Ultisolor)和黑沃土(Mollisols), 大部分土地用地为农场和牧场, 土壤的有机质含量较高; M107B区土壤类型主要为黑沃土, 存在水土流失、 土壤中有机物耗竭等资源问题, 土壤的有机质含量较低; 且M107B区表层土壤的颜色比N116B区的更深。 故N116B区土壤有机质含量高于M107B区(如表1所示), 但N116B区土壤的光谱反射率却比较高。
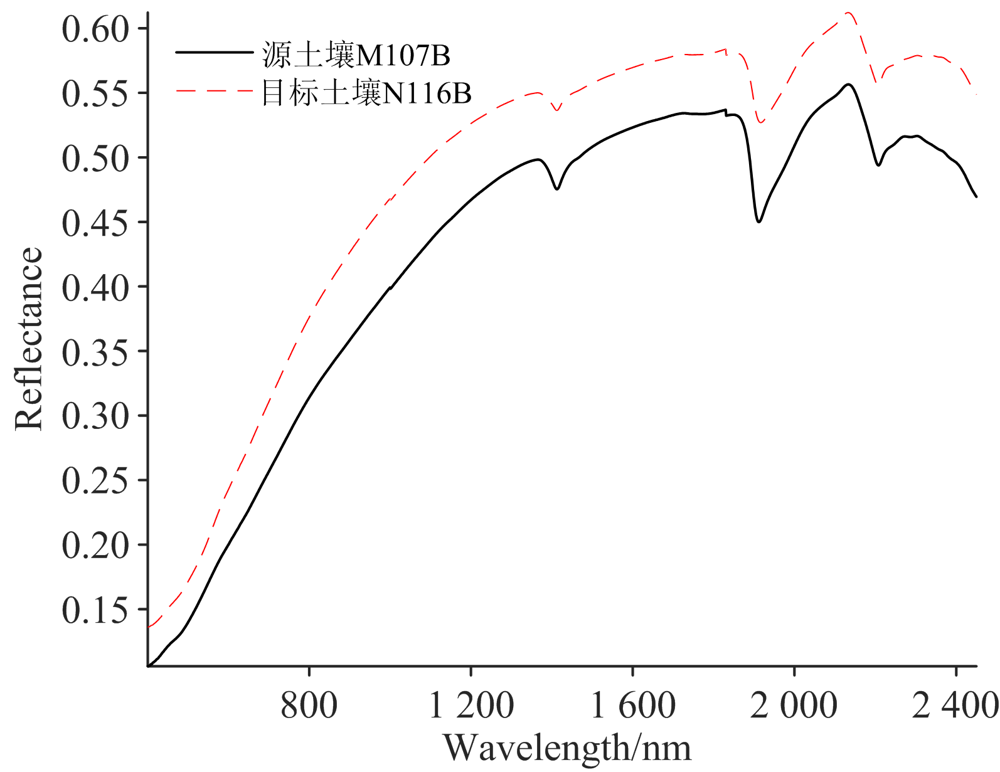 | 图2 源土壤M107B区和目标土壤N116B区的土壤反射率均值曲线Fig.2 Mean reflectance spectra of soil samples from source soil M107B and target soil N116B |
1.2.1 样本集划分
利用Kennard-Stone(KS)算法将M107B区89个土壤样品按照3:1的比例划分为校正集和验证集。 随机挑选出N116B区20个土壤样品作为N116B区验证集, 本研究中后续对N116B区土壤有机质含量进行预测, 均是指对这20个验证集土壤样品进行预测; N116B区剩余150个土壤样品随机划分成30组, 每组包含5个土壤样品, 再根据实验需要加入到M107B区样品集中。
1.2.2 特征波长提取
去除光谱曲线中光谱数据信噪比低的边缘波段350~400和2 451~2 500 nm后, 采用窗口竞争性自适应重加权采样(window competitive adaptive reweighted sampling, WCARS)和连续投影算法(successive projections algorithm, SPA)进行波长选择以提高预测精度, 简化模型[14]。 WCARS结合“ 窗口” 与CARS方法的优势, 能有效增强特征波长变量选择的准确性和稳定性。 SPA通过提取最低限度的冗余信息的波长组合, 消除共线问题。 因此, 采用WCARS联合SPA算法获取较少的特征波长。 将M107B区89个土壤样品的光谱数据通过WCARS+SPA挑选后, 确定544, 728, 1 486, 1 830, 1 895, 2 285和2 450 nm等7个特征波长, 并将这7个波长作为SOM特征波长。
最小二乘支持向量机(least squares support vector machines, LSSVM)建模时, 如何对正则参数λ 和核参数σ 进行优化是不可避免的问题。 粒子群算法(particle swarm optimization, PSO)是一种通过更新速度和位置来不断更新到参数最优解的群体优化智能算法, 自提出以来被广泛应用[15]。 本研究通过PSO优化LSSVM, 建立土壤有机质含量校正模型。
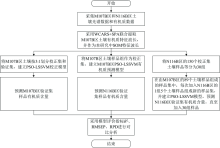
以M107B区土壤样品为源土壤, 以N116B区土壤样品为目标土壤, 从N116B区170个土壤样品中随机挑选出20个作为验证集。 将M107B区89个土壤样品采用KS算法按照3:1划分校正集和验证集, 用WCARS+SPA提取SOM特征波长后, 从3个方面进行实验研究, 研究流程如图3所示。 (1)通过PSO-LSSVM算法对M107B区66个校正集样品建立有机质含量校正模型, 并用该区的验证集验证模型精度; (2)用M107B区89个土壤样品, 建立SOM含量的PSO-LSSVM校正模型, 用该模型预测N116B区的20个验证集土壤样品的有机质含量; (3)将N116B区剩余的150个土壤样品随机等分成30组, 在由M107B区的89个土壤样品组成的样品集中, 每次加入N116B区的1组5个土壤样品组成新的样品集, 以新的样品集为校正集建立校正模型, 再用校正模型对N116B区20个验证集样品进行SOM含量预测, 直至全部加入N116B区的30组土壤样品。 比较M107B区校正模型对M107B区及N116B区SOM含量预测精度, 分析加入建模的N116B区土壤样品数量与模型性能之间的关系。
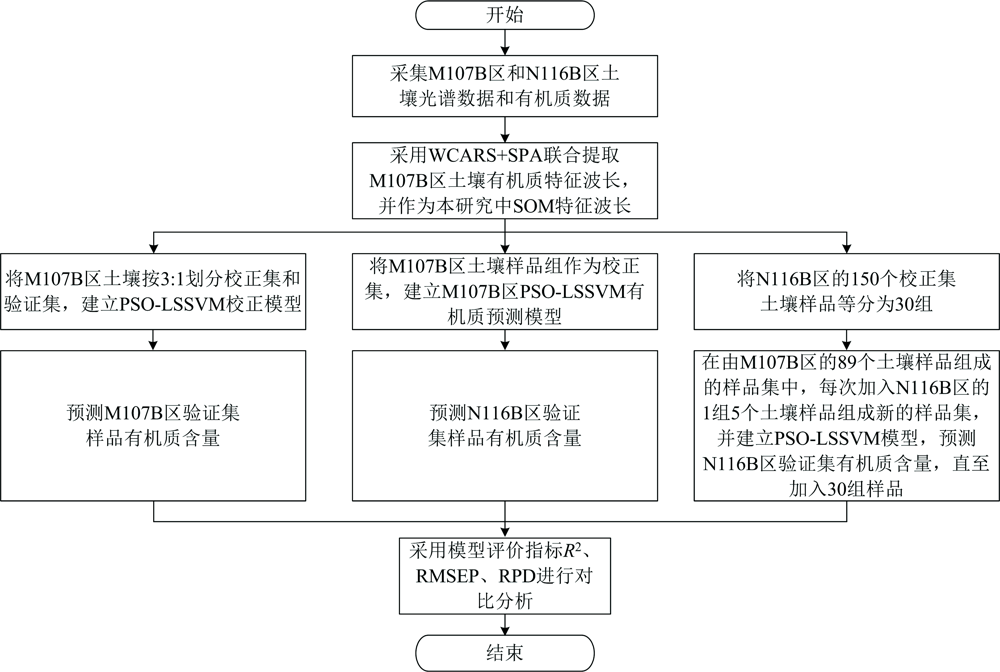 | 图3 实验流程图Fig.3 Experimental flow chart |
以预测决定系数(coefficient of determination, R2)、 预测均方根误差(root mean square error of prediction, RMSEP)和预测相对分析误差(ratio of standard deviation to RMSEP, RPD)对模型评价。
式中, n为验证集样本数; yi为验证集第i个样品用化学方法测定的SOM含量实际值;
实验(1)建立M107B区土壤有机质PSO-LSSVM校正模型并预测验证集土壤有机质含量, 结果如表2所示, 预测R2=0.859, 预测RPD=2.660, 表明模型能有效预测M107B区内部的土壤有机质含量。 实验(2)以M107B区89个土壤样品作为校正集建立土壤有机质含量校正模型, 对N116B区20个验证集土壤样品进行预测, 结果如表2所示, 其模型预测R2=0.562, 预测RPD=0.952, 表明M107B区的校正模型不能有效预测N116B区的土壤有机质含量。 实验(1)和实验(2)建模过程中均只使用M107B区土壤样品, 直接将M107B区土壤有机质含量校正模型用于N116B区土壤样品时模型预测精度显著降低, 预测决定系数R2降低了34.6%, 预测相对分析误差RPD降低了64.2%, 模型传递失败。
| 表2 实验(1)和实验(2)的模型性能 Table 2 Model performances of experiments (1) and (2) |
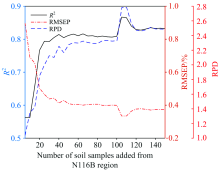
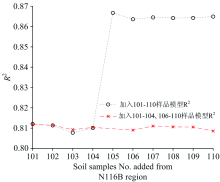
实验(3)用M107B区土壤样品建立有机质含量校正模型时加入部分N116B区土壤校正集样品, 建立校正模型后预测N116B区的验证集土壤有机质含量。 校正模型预测N116B区的验证集土壤有机质含量的R2, RMSEP和RPD值随加入的N116B区土壤校正集样品数量的变化结果如表3和图4所示, 表3中仅列出RPD值变化超过1%的实验数据。 随着加入的N116B区土壤校正集样品数量增加, 校正模型的预测R2和RPD逐渐提高, RMSEP逐渐降低。 当加入样品数量达到35时, 校正模型的预测R2> 0.80, RPD> 2.0; 当加入样品数量达到50以上, 模型精度变化趋于平稳。 但是, 在加入101— 105号N116B区土壤校正集样品后, 校正模型预测R2发生了突变, 这些样本可能对N116B区土壤的预测精度有较大影响, 因此需对101— 105样本进一步研究。
| 表3 实验(3)模型性能 Table 3 Model performances of experiment (3) |
 | 图4 加入不同数量的N116B区土壤样品后的模型性能Fig.4 Model performances when adding different numbers of soil samples from N116B region |
加入N116B区101— 105号土壤校正集样品后, 模型精度出现突变(如图4所示)。 为了探明加入单个样品对模型精度的影响, 本节研究将101-110号目标土壤样品提取出来, 每次只新增1个样品到校正集中参与建模, 即: 第一次对M107B区89个土壤样品和N116B区1— 101号样品组成新的校正集建立校正模型, 第二次对M107B区89个土壤样品和N116B区1— 102号样品组成新的校正集建立校正模型, 以此类推, 直到101— 110号样品全部参与建模。 再对N116B区的20个验证集样品进行土壤有机含量预测, 预测R2如图5所示。 结果表明: 当加入105号目标土壤校正集样品时模型R2由0.810提高到0.867。 将105号样品去除后重新建模, 模型决定系数R2如图5, 模型R2不再提高, 因此确定105号样品引起模型R2发生突变。
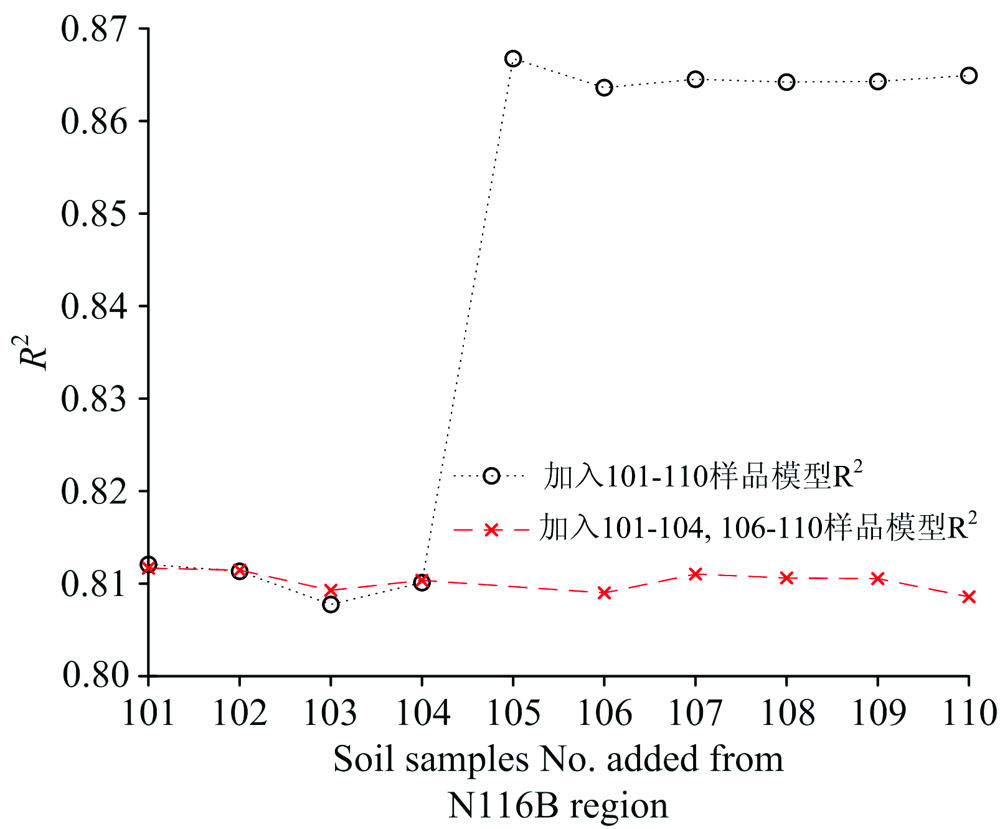 | 图5 加入105号样品和不加入时的模型预测R2对比Fig.5 Comparison of R2 with or without No.105 sample |
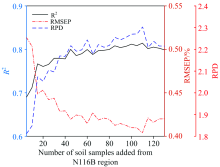
为找出平稳区影响模型R2值发生0.05以上突变的样品的特征, 本研究按照实验(3)方法进行多次重复实验, 共提取出20个与105号样品类似的能使模型R2值提高0.05以上的N116B区校正集土壤样品, 其有机质含量及其特征波长的光谱反射率如表4所示。 由于源土壤M107B区样品的SOM平均浓度低于目标土壤N116B区样品的SOM平均浓度(如表1所示), 且光谱反射率均值低于目标土壤N116B区(如图2所示), 因此, 造成校正模型预测R2值突然提高0.05的原因可能是N116B区这20个土壤样品较M107B区土壤样品的SOM浓度较高或光谱反射率较高。 该20个样品对模型传递精度影响较大, 因此后续研究中, 在加入N116B区土壤样品建模时将这20个特殊样品的优先级提高, 即先加入这20个特殊样品, 再把N116B区其余130个土壤校正集样品随机等分成26组, 每次加入1组5个土壤样品到M107B区土壤样品集中作为新的样品集, 以新的样品集为校正集建立校正模型, 再用校正模型对N116B区20个验证集土壤样品进行有机质含量预测, 直至加入N116B区所有校正集土壤样品。 校正模型预测N116B区的验证集土壤有机质含量的R2, RMSEP和RPD值随加入的N116B区土壤校正集样品数量的变化结果如图6所示, 当加入的N116B区土壤校正集样品数量由5增加到45时, 校正模型预测N116B区验证集土壤有机质含量的R2从0.690逐渐增加到0.800; 当加入的样品数量达到45以后, 校正模型预测R2在± 0.015范围内波动, 逐渐趋于稳定, 未出现模型精度突变情况。 因此, 在将M107B区土壤有机质校正模型传递给N116B区时, 应优先加入比M107B区土壤样品的SOM浓度高或光谱反射率高的N116B区土壤样品参与建模, 以提高模型预测精度和避免模型传递时模型精度出现突变。
| 表4 提高模型R2值0.05以上的N116B区土壤校正集样品数据 Table 4 The data of calibration samples in N116B which improve R2 above 0.05 |
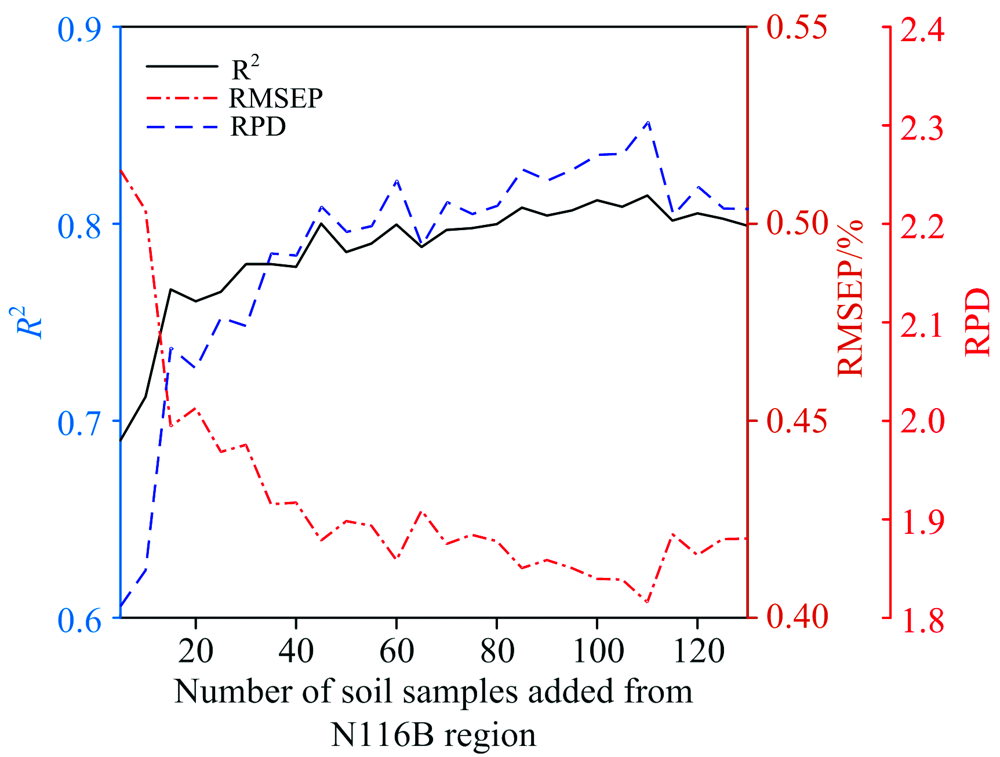 | 图6 加入N116B区除特殊样品外的130个土壤样品的模型性能Fig.6 Model performances when adding 130 soil samples which are not special samples in N116B region |
基于可见-近红外光谱建立M107B区的土壤有机质含量校正模型, 探索将M107B区土壤有机质校正模型应用到N116B区土壤有机质含量预测的模型传递方法。 研究结果表明, M107B区土壤有机质的PSO-LSSVM校正模型R2=0.859, RMSEP=0.334%, RPD=2.660, 可以有效预测M107B区土壤有机质含量。 用M107B区土壤有机质校正模型预测N116B区的土壤验证集样品的有机质含量和预测M107B区土壤验证集样品的有机质含量相比, 预测R2和预测RPD分别降低了34.6%和64.2%, 且预测精度很低, 不能有效预测N116B区土壤有机质含量。 将部分N116B区土壤样品加入M107B区土壤样品集后重新建模, 模型对N116B区土壤的有机质含量预测精度随加入的N116B区土壤样品数量增加逐渐提高。 在加入样品数量达到50后模型精度变化趋于稳定, 且模型预测R2> 0.80, RPD> 2.0, 能有效预测土壤有机质含量, 成功实现M107B区模型预测N116B区土壤有机质含量的模型传递。 为提高模型传递时的预测精度, 应优先加入比M107B区土壤样品的SOM浓度高或光谱反射率高的N116B区土壤样品参与建模。 本文研究M107B区土壤有机质含量校正模型预测N116B区土壤有机质含量的建模方法, 提出了一种新的基于可见-近红外光谱的模型传递方法, 为建立大面积小样本的多类型土壤有机质含量校正模型提供一种有效的解决方案, 为提高大范围多类型土壤的有机质含量农田在线光谱检测的准确性、 减少模型计算量、 降低检测成本提供一种实用方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|